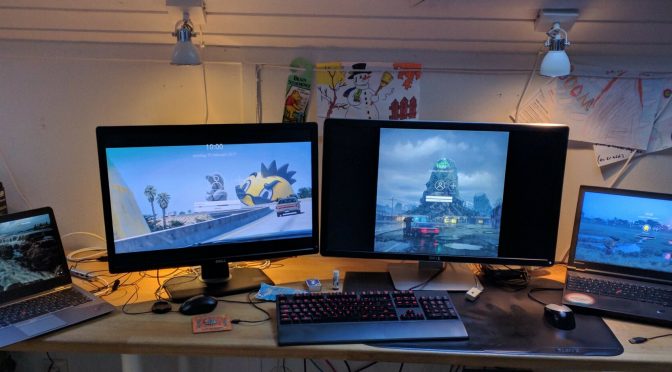
My home office was featured over at Hacker Stations where I also detailed stuff in my workplace and offer a few more photos.
I have been working exclusively from home for nine years straight now.

My home office was featured over at Hacker Stations where I also detailed stuff in my workplace and offer a few more photos.
I have been working exclusively from home for nine years straight now.
My desktop computer is my trusted work machine that I do the majority of all my (curl) development on. When the 15th computer I’ve owned through the times was ten years old the time was ripe to bump things up a notch.
I don’t do games (as in: never) and I don’t do any other 3D stuff. I just need my two 4K monitors to display my desktops and browser windows fine.
In my ordinary days I compile C code and I run tests. CPU and memory will be used to build and test faster and to be able to run separate VM runtimes in parallel without problems. I rarely even build very large or complicated software projects. (The days of building Firefox are long gone…)
Ideally, this upgrade will last for a long time again so I’ve tried to push it a little to increase those chances.
This new baby is (of course) built from components and I’ve relied heavily on advice, research and help by my brother Björn for this.

I’m a sucker for maximum single-thread performance. Lots of things I do still run in single-threaded in a single core so I think this is good for me.
The Intel Core i7-13700K at 3.4 GHz is benchmarked at a CPU Mark that is over 7 times faster than the CPU of my old machine. 16 cores, Socket 1700 Raptor Lake. “13th gen”
On cpubenchmark.net, this model is currently ranked 4th among all current CPUs in single-thread performance.

I think I’m not alone in having past happy experiences with Noctua. This time I use the Noctua NH-U12A, which I have gotten reports does a good job for this CPU.

Something to host the CPU that just does the job. MSI PRO B660M-A DDR4 is a small board, but I don’t need anything more.
Turned out to require a little dance to make it accept my CPU since the BIOS it shipped with did not support it, so we had to insert an older CPU first just in order to upgrade the BIOS to make it boot with the intended CPU!
My plan is to start trying out the built-in Intel video capabilities. Nothing extra. Lots of space in the box!

I don’t think I’ve experienced a situation when I have run out of my memory in my current 32GB setup, so my original plan was to go with 64GB in this new machine. However it turned out that the motherboard does not work with all four slots using my 3600MHz memories at full speed and I decided it is better to start out with 32 really fast gigabytes than 64GB at 2100MHz (which was the alternative)!
Corsair Vengeance RGB PRO SL / 3600MHz / DDR4 / CL18. Two 16GB modules installed makes it 32GB in total. I can go 2x32GB in a future when if this turns out to be too limited.
RGB-LEDs on the memory modules is apparently a thing now.
Should be >50% faster than my old memory.

I am not a data hoarder. On the disks in my current machine I use just a few hundred gigabytes. 2 TB will give me sufficient space to play with for a while. My old machine had a 3 TB spinning disk so this is less room than before, but I don’t expect that to be a problem. This storage is speced doing 14 times faster reads than my previous SSD.
The Samsung 980 Pro series SSD 2TB M.2 (MZ-V8P2T0)

The Kolink Enclave / 600W / 80+ Gold is nothing special. A modular and cheap alternative that my preferred supplier happened to offer. Again, I will not run any power hungry graphics cards.

Me and friends have been happy with Fractal Design cases in the past and a friend of mine mentioned that he recently purchased this model and is very happy, so I went with the Fractal Design Define 7 Compact / Solid.

This is a big case for a what is otherwise a very small computer (need). Partly because of the recommendation but also partly because that my preferred supplier did not offer any smaller Fractal Design case at the moment. At least there will be lots of air in the box.
This case looks almost identical to my old case which will make my machine upgrade at least physically impossible to detect in my home office once installed.
Front interface from left to right: Reset button, Audio I/O, 1x USB 3.1 Gen 2 Type-C, Power button, 2x USB 2.0, 2x USB 3.0,

Here’s how the new beast compares to the old box when doing a few of my regular every day tasks.
On a typical curl debug build of mine, identical setups. Run-time in seconds on the new machine vs the old.
| Task | Old | New |
| build curl with make -sj | 13.1 | 2.7 |
| autoreconf -fi | 13.2 | 5.6 |
| configure | 19.3 | 10.1 |
| build in curl’s test directory | 30.1 | 7.6 |
| run the first 200 curl tests with valgrind | 331 | 194 |
Downloading 100 GB from http://localhost to /dev/null with curl. Old: 2248MB/sec. New: 4281MB/sec.
For C programmers like me, who want to write portable programs that can get built and run on the widest possible array of machines and platforms, we often need to write conditional code. Code that use #ifdefs for particular conditions.
Such ifdefs expressions often need to check for a particular compiler, an operating system or perhaps even a specific version of of one those things.
Back in April 2002, Bjørn Reese created the predef project and started collecting this information on a page on Sourceforge. I found it a super useful idea and I have tried to contribute what I have learned through the years to the effort.
The collection of data has been maintained and slowly expanded over the years thanks to contributions from many friends.
The predef documents have turned out to be a genuine goldmine and a resource I regularly come back to time and time again, when I work on projects such as curl, c-ares and libssh2 and need to make sure they remain functional on a plethora of systems. I can only imagine how many others are doing the same for their projects. Or maybe should do the same…
Now, in July 2022, the team is moving the predef documents over to a brand new GitHub organization. The point being to making it more accessible and allow edits and future improvements using standard pull-requests to make ease the maintenance of them.
You find all the documentation here:
https://github.com/cpredef/predef
If you find errors, mistakes or omissions, we will of course be thrilled to see issues and pull requests filed.
Back in 2008, I had a revelation when it dawned on me that the POSIX function called strcasecmp() compares strings case insensitively, but locale dependent. Because of this, “file” and “FILE” is not actually a case insensitive match in Turkish but is a match in most other locales. curl would sometimes fail in mysterious ways due to this. Mysterious to the users, now we know why.
Of course this behavior was no secret. The knowledge about this problem was widespread already then. It was just me who hadn’t realized this yet.
To work around that problem for curl, we immediately implemented our own custom comparison replacement function that doesn’t care about locales. Internet protocols work the same way no matter which locale the user happens to prefer.
We did not go the POSIX route. The POSIX function for case insensitive string comparisons that ignores the locale is called strcasecmp_l() but that uses a special locale argument and also doesn’t exist on non-POSIX platforms.
curl has used its custom set of functions since 7.19.1, released in early November 2008.
Fast forward to May 2022. OpenSSL released their version 3.0.3. In the change-log for this release we learned that they now offer public functions for case insensitive string comparisons. Whatdoyouknow! They too have learned about the Turkish locale. Apparently to the degree that they feel they need to offer those functions in their already super-huge API set. Oh well, that is certainly their choice.
I can relate since we too have such functions in libcurl, but I have always regretted that we added them to the API since comparing strings is not libcurl’s core business. We did wrong then and we still live with the consequences several decades later.
OpenSSL however took the POSIX route and based their implementation on strcasecmp_l() and use a global variable for the locale and an elaborate system to initialize that global and even a way to make things work if string comparisons are needed before that global variable is initialized etc.
This new system was complicated to the degree that it broke the library on several platforms, which curl users running Windows 7 figured out almost instantly. curl with OpenSSL 3.0.3 simply does not work on Windows 7 – at all.
Libraries should only provide functions that are within their core objective. Not fluffy might be useful things. Reasons for this include:
I think there is a software law that goes something like this
eventually, all C libraries implement their own case insensitive string comparison functions
When I proposed they should implement their own custom function in discussions in one of the issues about this OpenSSL problem, the suggestion was shot down fairly quickly because of how hard it is to implement a such function that is as fast as the glibc version.
In my ears, that sounds like they prefer to stick with an overworked and complicated error-prone system, because an underlying function is faster, rather than going with simplicity and functionality at the price of sightly slower performance. In fairness, they say that case insensitive string comparisons are “6-7%” of the time spent in some (to me unknown) performance test they referred to. I have no way or intention to argue with that.
I think maybe they couldn’t really handle that idea from an outsider and they might just need a little more time to figure out the right way forward on their own. Then go with simple.
I am of course not in the best position to say how they should act on this. I’m just a spectator here. I may be completely wrong.
In a separate PR (4 days after this blog post went live), OpenSSL suddenly implemented their own and it was deemed that it would not hurt performance noticeably. Merged on May 23. Almost like they followed my recommendation!
OpenSSL’s current tolower() implementation used in the comparison function is similar to curl’s old one so I suspect curl’s current function is a tad bit faster.
glibc truly has really fast string comparison implementations, with optimized assembly versions for the common architectures. Versions written in plain C tend to be slower.
However, the API and way to use those functions to make them locale independent is horrific because of the way it forces the caller to provide a locale argument (which could be the “C” locale – the equivalent of no locale).
That talk about the slowness of custom string functions made us start discussing this topic a little in the curl IRC channel and we bounced around some ideas of what things the curl function does not already do and what it could do and how it compares against the glibc assembly version.
Also: the string comparisons in curl are certainly not that performance critical as they seem to be in OpenSSL and while used a lot in curl they are not used in the most important performance critical transfer-data code paths.
Frank Gevaerts took the lead and after some rounds and discussions backed up with tests, he ended up with an updated function that is 1.6 to 1.7 times faster than before his work. We dropped non-ASCII support in curl a while ago, which also made this task more straight-forward.
The two improvements:
toupper() implementation instead of the previous simple condition + math.The glibc assembler versions are still faster than curl’s custom functions and the exact speed improvements the above mentioned changes provide will of course depend both on platform and the test set.
The faster libcurl functions will ship in curl 7.84.0. I doubt anyone will notice the difference!
Three Open Source hackers were invited to this meeting with the CSRB and I was one of them.

The board with this name is part of CISA, a US government effort that received a presidential order to work on “Improving the Nation’s Cybersecurity“. Where “the Nation” here is the US.
I’m not in the US and I’m not a US citizen but I felt I should help out when asked and I was able to.
On April 21 2022, I joined the video meeting together with an OpenSSL and a Tomcat contributor and several members of the board. (I am not naming any names of participants in this post because I have not asked for permission nor do I think the names are important here.)
For about an hour we talked to the board how we develop Open Source, how we take on security problems and how we work on making sure we do things as securely as we can. It was striking how similarly the three of us looked at the issues and how we work in our project, despite our projects all being different and having our own specifics.
As projects, we believe we have pretty well-established and working procedures for getting problems reported and we think we fix the issues fairly swiftly. We ship fixes, advisories and updates not long after the issues get known. The CVE system where we register and publish security vulnerabilities in a global registry is working adequately. (I’m not saying things are perfect.)
It was pretty clear to me that we agreed that the biggest problem in the Open Source supply chain today is the slow uptake in patching vulnerable software.
Lots of vendors and products have not been made or have any plans for how to handle upgrades when vulnerabilities are found. Many of those that do act, do that with such glacier like speeds that users of such products remain exposed for attackers for a long period after the flaws are already fixed and have become known.
My own analysis of this is that such vendors of course do this because its the cheapest way. Plain capitalistic reasons.
If we had any easy fixes for this, we would already have them in progress. We were also asked by the board what kind of systems that we would not like to see.
Will Software Bill Of Materials (SBOM) fix this? Maybe it can help, by exposing to the world what software and versions are used in products, but it will certainly depend on how it is used and enforced. If done too heavy-handed, it risks causing overhead and added complications but in the other end it might end up too wishy-washy.
This was just an hour of conversation with a few follow-up clarifying emails. I hope that we were able to provide insights into how Open Source is made but I have no illusions of us changing anything in drastic ways.
I felt honored to represent “my kind” and help sharing knowledge of Open Source to areas of the world that might not always get informed about it.
curl supports a large number of third party libraries. In a build, those libraries become “dependencies”. These components offer functionality and features that we don’t implement ourselves but still have been deemed interesting or even crucial to support to do Internet transfers the way we want.
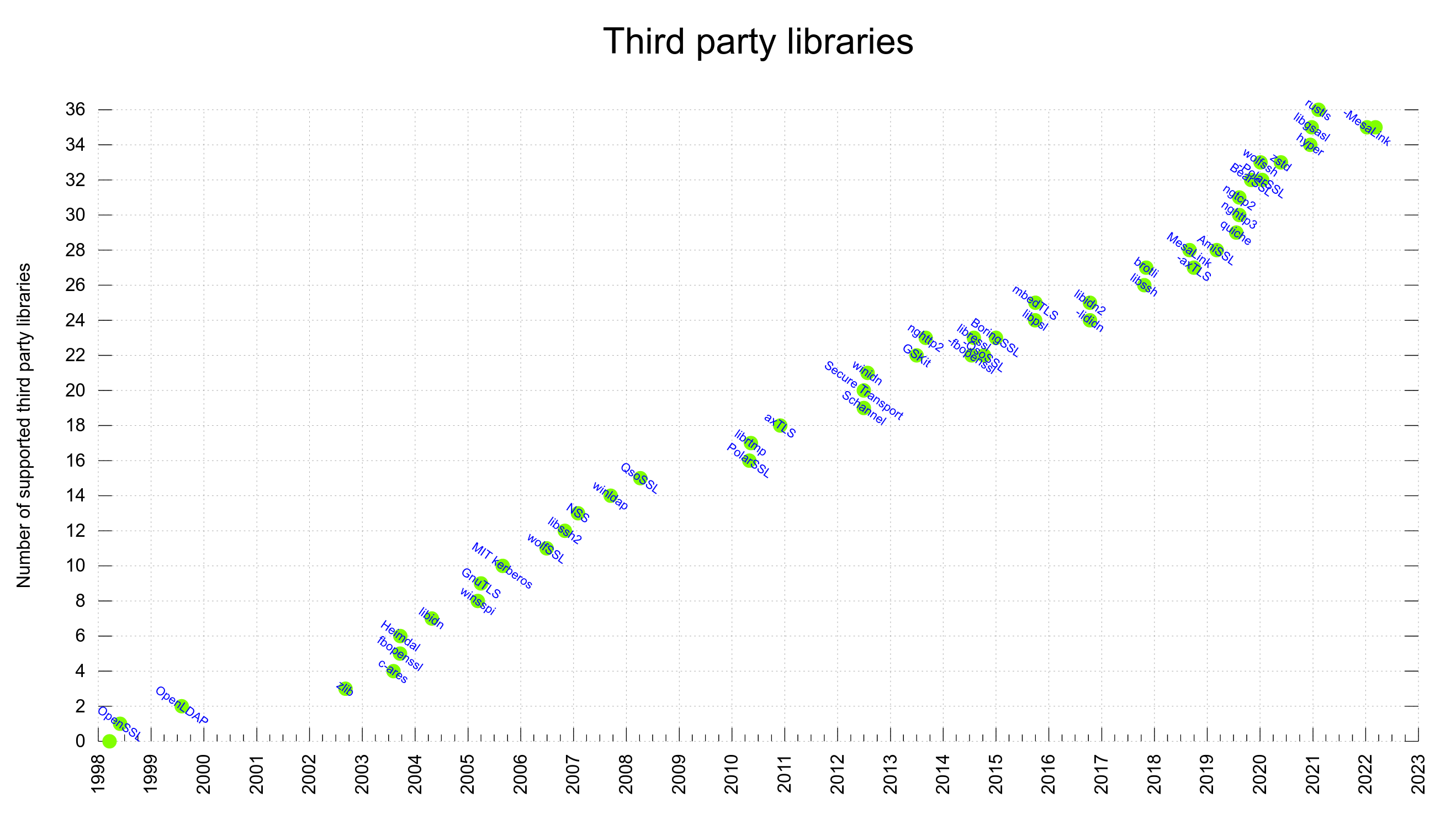
A curl build done today can use one or more out of 35 different libraries. No build can actually use all of them at once as many are mutually exclusive and most of them only work on one or a subset of platforms.
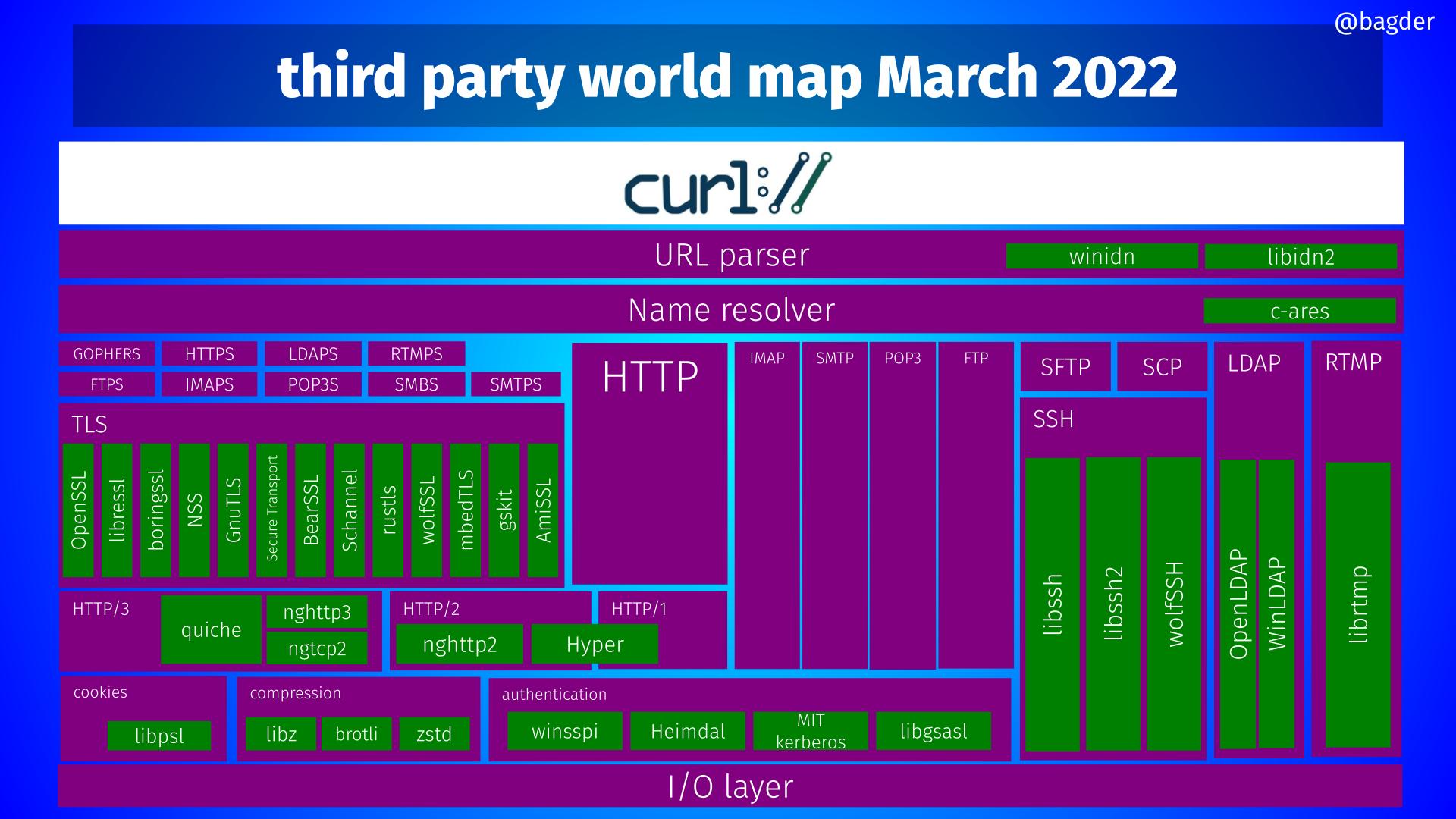
Every now and then we learn that one of the 3rd party libraries we can build curl to use has ceased development or has in some other way started to decay into a state where we feel is no longer healthy to the level that we can no longer recommend our users to use it.
We do this as a service to our users. If users build curl with a dependency we support, I think we should at least have some rudimentary knowledge that the dependencies we help users to use are not terrible. It’s not a guarantee, but we try. To help strengthen the ecosystem. To sweep our own backyard.
Also, getting rid of old code is good.
There are of course also indirect dependencies in the form of libraries our direct dependencies use (or even libraries the indirect used libraries use), and we try to also include them in the “package” when we consider dependencies, but especially if they are optional we need to put less attention on them.
We have no automatic checks or even fixed set of rules or conditions to help us make this distinction. It would of course be cool to have that, but we don’t.
Ideally, it would be awesome if all dependencies would be top-rated on bestpractices, as that would greatly help us figure this out. But unfortunately too many projects are still not even added to that effort so this doesn’t work – plus we also support a number of proprietary dependencies that can’t be rated there.
Instead, we need to rely on old-fashioned human checks and asking users and maintainers.
We have declined to add functionality to curl in the past just because the proposed 3rd party dependency it would use just didn’t live up to our standards. I don’t mean that we need to raise the bar to ridiculous levels, but if a casual browsing of the 3rd party library found issues and there were not satisfying answers in a reasonable time on how those should be addressed, then that library is probably not ready to be used by curl. There’s no need to “lure” curl users into a possibly bad situation if we can save them from it.
Sometimes work officially stops on a library we support. That’s a strong sign we should also stop.
Since curl is being developed, extended and bug-fixed at a fairly high pace, we can be fairly sure that if a dependency is actually being used, it needs to get fixed every now and then to keep up. If support code for a dependency hasn’t been updated or touched for many years, there’s a strong suspicion that there aren’t many users of it in modern curl.
Sometimes that can be verified to be the case when we notice a blatant bug that’s been present in the code for a good while without anyone noticing, but more often we need to ask users. Anyone using this anymore? (Which also is complicated because we often lack connections to users who don’t read any of our mailing lists and generally only upgrade curl once every decade so it might take a while until those users notice changes…)
A dependency that has stopped making new releases can be a signal that it on its way downwards. It could also be a sign that it has matured and doesn’t need much more to be done to it.
How do we even know they stopped? Maybe they just take forever from the previous release…
A library that is used by curl is almost required to have some level of developer activity over time. Nobody writes bug-free code unless its scope is razor-sharp-narrow and the project spent a lot of time perfecting it. No commits or developer activity for a long time means that clearly nobody takes care of the bug reports.
Slowly deteriorating projects are probably the hardest to handle. Are they still good enough?
But we just ship source code.
In the end of the day, the people who package curl or libcurl decide what third party libraries to actually get used. They are the ones who decide what dependencies users of their build rely on. In many cases this means the maintainers of the curl packages in Linux distros and other operating systems. Manufacturers of devices and tools that use libcurl often build their own and then they can decide and cherry-pick individually between all provided choices.
This makes it possible for such maintainers to add extra conditions and checks and only go with the dependencies they like.
The only binary packages the curl project itself provides, are the ones for Windows, and we try to go with only solid, reliable and conservative choices for those.
I’m the lead developer in the curl project. We make the command line tool curl and the library libcurl, for doing Internet transfers. The command line tool uses the library for all the internet transfer heavy lifting.
The command line tool is somewhat of a shell binding to access libcurl.
We make these things. We recently surpassed 1,000 authors. I lead the project and I have done the most number of commits per month in curl for the last 79 months, and in fact in 222 of the 267 months we have stats for.
curl was born in 1998 as a command line tool only. Two years in, we (well, mostly me actually) remodeled some internals and shipped the first libcurl to the world in August 2000. The idea was (and still is) to provide the same Internet transfer powers the tool has to any application or device out there that need it.
The library side of things is right now about 85% of the total product code. A little over 120,000 lines right now, including comments.
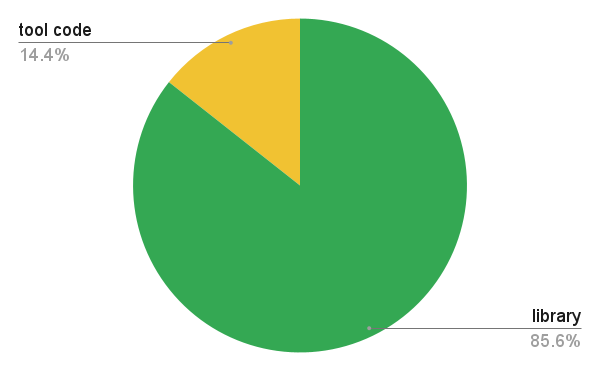
Many users think of the curl project as equivalent to the curl tool and the command line tool certainly has a lot of users. It is available for and on all the popular platforms. It is impossible to count curl command users, but millions should not be an exaggeration.
While it seems likely that more users are using the tool than is writing applications that use libcurl, each product, service or device that uses libcurl can themselves scale up the volumes. A single libcurl user can use libcurl in an application used by billions. A few hundreds or thousands of libcurl users populate the world with things transferring data with our library. (A noticeable share of the current Internet traffic is likely driven by libcurl.)
The net result is therefore that libcurl runs in several thousand times more installations than the tool.
If we visualize the number of curl users as a yellow ball and the libcurl installations as a green ball, putting them next to each other would look something like this:

(Image math: 3 million curl users, 10 billion libcurl installations. Yellow sphere radius is 90 vs the green’s 1340)
Making a command line tool is much easier than doing a library. The command line tool has just one entry point and the interface is limited. A command line and associated files and pipes to read from. In our case, the tool lets libcurl deal with a lot of platform specifics which makes the command line code generic and mostly identical on all platforms it runs on.
A library has many more entry points, each that needs to be written to care for what the users might pass in to them. libcurl has code to work with millions of build combinations, and (right now) up to 35 different external libraries. (13 different TLS libraries, 3 different SSH libraries, 2 different QUIC/HTTP/3 libraries, 3 different compression libraries etc.)
libcurl is used in many more challenging environments such as niche operating systems, scaled up to thousands of concurrent transfers, systems that never exits and in builds with a creative set of features disabled at build-time.
Compared to the curl tool, libcurl is way more advanced. A bug in the command line tool is often much easier to fix than one in the library. Such bugs are also rarer since it is much simpler and a smaller amount of code.
Because of what I have outlined above, I focus my curl work on library related changes. Both when it comes to bug-fixes and adding features. It scales better to the world, and as one of the designers and architects of most solutions used in libcurl I am in many cases a suitable engineer to work on many of the more complicated problems.
It is smarter for the entire project for me to leave the slightly less complicated problems and more easily understood features to be fixed and added by others. It scales better. After all, I have a finite number of hours per week to spend on curl. I want to make the best use of my time as I can.
Therefore, I tend to leave tool-related things for others to work on.
I work on curl for a living. The companies that pay for support have higher priority than almost any other bug reports, and they tend to be libcurl related. Keeping my paying customers happy is crucial to me. And in a funny way also to others, since that work usually end up benefiting all curl users.
As I work on curl full-time during my workdays and also during a good chunk of my spare time, I need to “lighten up” my work at times and get some variation. Sometimes I can go about and find new little things to work on in the project that maybe isn’t top priority by any means, but are things that could use some polish and are different enough from what I spent the rest of my week on. To give me variation. To keep the fun.
Also, sometimes scratching the surface on a new somewhat forgotten place brings up more important stuff.
Years ago I even for a while considered to hand over maintenance of the curl tool to someone else and more distinctly say that I would only work on the library as they are separate entities and could possibly benefit from being worked on independently from each other.
My idea of focusing my work on the more complicated issues, to work on design and architecture and help newcomers find their way into the code doesn’t always work out.
I never gave up maintenance of the tool and a lot of things that someone else could implement or fix in the project aren’t, which makes me eventually get to work on that too anyway. For the good of the project. Also, it makes my work day more varied and fun if I take occasional strolls around the project every now and then and put on some new paint on areas I find could use some.
Most of my work efforts go into libcurl matters. But I work on the tool too.
Some critics think the curl project shouldn’t use GitHub. The reasons for being against GitHub hosting tend to be one or more of:
Some have insisted on craziness like “we let GitHub hold our source code hostage”.
The curl project switched to GitHub (from Sourceforge) almost eleven years ago and it’s been a smooth ride ever since.
We’re on GitHub not only because it provides a myriad of practical features and is a stable and snappy service for hosting and managing source code. GitHub is also a developer hub for millions of developers who already have accounts and are familiar with the GitHub style of developing, the terms and the tools. By being on GitHub, we reduce friction from the contribution process and we maximize the ability for others to join in and help. We lower the bar. This is good for us.
I like GitHub.
Providing even close to the same uptime and snappy response times with a self-hosted service is a challenge, and it would take someone time and energy to volunteer that work – time and energy we now instead can spend of developing the project instead. As a small independent open source project, we don’t have any “infrastructure department” that would do it for us. And trust me: we already have enough infrastructure management to deal with without having to add to that pile.
… and by running our own hosted version, we would lose the “network effect” and convenience for people that already are on and know the platform. We would also lose the easy integration with cool services like the many different CI and code analyzer jobs we run.
While git is open source, GitHub is a proprietary system. But the thing is that even if we would go with a competitor and get our code hosting done elsewhere, our code would still be stored on a machine somewhere in a remote server park we cannot physically access – ever. It doesn’t matter if that hosting company uses open source or proprietary code. If they decide to switch off the servers one day, or even just selectively block our project, there’s nothing we can do to get our stuff back out from there.
We have to work so that we minimize the risk for it and the effects from it if it still happens.
A proprietary software platform holds our code just as much hostage as any free or open source software platform would, simply by the fact that we let someone else host it. They run the servers our code is stored on.
No matter which service we use, there’s always a risk that they will turn off the light one day and not come back – or just change the rules or licensing terms that would prevent us from staying there. We cannot avoid that risk. But we can make sure that we’re smart about it, have a contingency plan or at least an idea of what to do when that day comes.
If GitHub shuts down immediately and we get zero warning to rescue anything at all from them, what would be the result for the curl project?
Code. We would still have the entire git repository with all code, all source history and all existing branches up until that point. We’re hundreds of developers who pull that repository frequently, and many automatically, so there’s a very distributed backup all over the world.
CI. Most of our CI setup is done with yaml config files in the source repo. If we transition to another hosting platform, we could reuse them.
Issues. Bug reports and pull requests are stored on GitHub and a sudden exit would definitely make us lose some of them. We do daily “extractions” of all issues and pull-requests so a lot of meta-data could still be saved and preserved. I don’t think this would be a terribly hard blow either: we move long-standing bugs and ideas over to documents in the repository, so the currently open ones are likely possible to get resubmitted again within the nearest future.
There’s no doubt that it would be a significant speed bump for the project, but it would not be worse than that. We could bounce back on a new platform and development would go on within days.
It’s a rare thing, that a service just suddenly with no warning and no heads up would just go black and leave projects completely stranded. In most cases, we get alerts, notifications and get a chance to transition cleanly and orderly.
Sure there are alternatives. Both pure GitHub alternatives that look similar and provide similar services, and projects that would allow us to run similar things ourselves and host locally. There are many options.
I’m not looking for alternatives. I’m not planning to switch hosting anytime soon! As mentioned above, I think GitHub is a net positive for the curl project.
We’ve switched services several times before and I’m expecting that we will change again in the future, for all sorts of hosting and related project offerings that we provide to the work and to the developers and participators within the project. Nothing lasts forever.
When a service we use goes down or just turns sour, we will figure out the best possible replacement and take the jump. Then we patch up all the cracks the jump may have caused and continue the race into the future. Onward and upward. The way we know and the way we’ve done for over twenty years already.
Image by Elias Sch. from Pixabay
After this blog post went live, some users remarked than I’m “disingenuous” in the list of reasons at the top, that people have presented to me. This, because I don’t mention the moral issues staying on GitHub present – like for example previously reported workplace conflicts and their association with hideous American immigration authorities.
This is rather the opposite of disingenuous. This is the truth. Not a single person have ever asked me to leave GitHub for those reasons. Not me personally, and nobody has asked it out to the wider project either.
These are good reasons to discuss and consider if a service should be used. Have there been violations of “decency” significant enough that should make us leave? Have we crossed that line in the sand? I’m leaning to “no” now, but I’m always listening to what curl users and developers say. Where do you think the line is drawn?
I write and prefer code that fits within 80 columns in curl and other projects – and there are reasons for it. I’m a little bored by the people who respond and say that they have 400 inch monitors already and they can use them.
I too have multiple large high resolution screens – but writing wide code is still a bad idea! So I decided I’ll write down my reasoning once and for all!
There’s a reason newspapers and magazines have used narrow texts for centuries and in fact even books aren’t using long lines. For most humans, it is simply easier on the eyes and brain to read texts that aren’t using really long lines. This has been known for a very long time.
Easy-to-read code is easier to follow and understand which leads to fewer bugs and faster debugging.
I never run windows full sized on my screens for anything except watching movies. I frequently have two or more editor windows next to each other, sometimes also with one or two extra terminal/debugger windows next to those. To make this feasible and still have the code readable, it needs to fit “wrapless” in those windows.
Sometimes reading a code diff is easier side-by-side and then too it is important that the two can fit next to each other nicely.
Having code grow vertically rather than horizontally is beneficial for diff, git and other tools that work on changes to files. It reduces the risk of merge conflicts and it makes the merge conflicts that still happen easier to deal with.
A side effect by strictly not allowing anything beyond column 80 is that it becomes really hard to use those terribly annoying 30+ letters java-style names on functions and identifiers. A function name, and especially local ones, should be short. Having long names make them really hard to read and makes it really hard to spot the difference between the other functions with similarly long names where just a sub-word within is changed.
I know especially Java people object to this as they’re trained in a different culture and say that a method name should rather include a lot of details of the functionality “to help the user”, but to me that’s a weak argument as all non-trivial functions will have more functionality than what can be expressed in the name and thus the user needs to know how the function works anyway.
I don’t mean 2-letter names. I mean long enough to make sense but not be ridiculous lengths. Usually within 15 letters or so.
To make this work, and yet allow a few indent levels, the code basically have to have small indent-levels, so I prefer to have it set to two spaces per level.
If you do a lot of indent levels it gets really hard to write code that still fits within the 80 column limit. That’s a subtle way to suggest that you should not write functions that needs or uses that many indent levels. It should then rather be split out into multiple smaller functions, where then each function won’t need that many levels!
Once upon the time it was of course because terminals had that limit and these days the exact number 80 is not a must. I just happen to think that the limit has worked fine in the past and I haven’t found any compelling reason to change it since.
It also has to be a hard and fixed limit as if we allow a few places to go beyond the limit we end up on a slippery slope and code slowly grow wider over time – I’ve seen it happen in many projects with “soft enforcement” on code column limits.
In curl, we have ‘checksrc’ which will yell errors at any user trying to build code with a too long line present. This is good because then we don’t have to “waste” human efforts to point this out to contributors who offer pull requests. The tool will point out such mistakes with ruthless accuracy.
Image by piotr kurpaska from Pixabay
Every now and then I get questions on how to work with git in a smooth way when developing, bug-fixing or extending curl – or how I do it. After all, I work on open source full time which means I have very frequent interactions with git (and GitHub). Simply put, I work with git all day long. Ordinary days, I issue git commands several hundred times.
I have a very simple approach and way of working with git in curl. This is how it works.
I use git almost exclusively from the command line in a terminal. To help me see which branch I’m working in, I have this little bash helper script.
brname () {
a=$(git rev-parse --abbrev-ref HEAD 2>/dev/null)
if [ -n "$a" ]; then
echo " [$a]"
else
echo ""
fi
}
PS1="\u@\h:\w\$(brname)$ "
That gives me a prompt that shows username, host name, the current working directory and the current checked out git branch.
In addition: I use Debian’s bash command line completion for git which is also really handy. It allows me to use tab to complete things like git commands and branch names.
I of course also have my customized ~/.gitconfig file to provide me with some convenient aliases and settings. My most commonly used git aliases are:
st = status --short -uno
ci = commit
ca = commit --amend
caa = commit -a --amend
br = branch
co = checkout
df = diff
lg = log -p --pretty=fuller --abbrev-commit
lgg = log --pretty=fuller --abbrev-commit --stat
up = pull --rebase
latest = log @^{/RELEASE-NOTES:.synced}..
The ‘latest’ one is for listing all changes done to curl since the most recent RELEASE-NOTES “sync”. The others should hopefully be rather self-explanatory.
The config also sets gpgsign = true, enables mailmap and a few other things.
The main curl development is done in the single curl/curl git repository (primarily hosted on GitHub). We keep the master branch the bleeding edge development tree and we work hard to always keep that working and functional. We do our releases off the master branch when that day comes (every eight weeks) and we provide “daily snapshots” from that branch, put together – yeah – daily.
When merging fixes and features into master, we avoid merge commits and use rebases and fast-forward as much as possible. This makes the branch very easy to browse, understand and work with – as it is 100% linear.
When I start something new, like work on a bug or trying out someone’s patch or similar, I first create a local branch off master and work in that. That is, I don’t work directly in the master branch. Branches are easy and quick to do and there’s no reason to shy away from having loads of them!
I typically name the branch prefixed with my GitHub user name, so that when I push them to the server it is noticeable who is the creator (and I can use the same branch name locally as I do remotely).
$ git checkout -b bagder/my-new-stuff-or-bugfix
Once I’ve reached somewhere, I commit to the branch. It can then end up one or more commits before I consider myself “done for now” with what I was set out to do.
I try not to leave the tree with any uncommitted changes – like if I take off for the day or even just leave for food or an extended break. This puts the repository in a state that allows me to easily switch over to another branch when I get back – should I feel the need to. Plus, it’s better to commit and explain the change before the break rather than having to recall the details again when coming back.
“git stash” is therefore not a command I ever use. I rather create a new branch and commit the (temporary?) work in there as a potential new line of work.
Yes I am the lead developer of the project but I still maintain the same work flow as everyone else. All changes, except the most minuscule ones, are done as pull requests on GitHub.
When I’m happy with the functionality in my local branch. When the bug seems to be fixed or the feature seems to be doing what it’s supposed to do and the test suite runs fine locally.
I then clean up the commit series with “git rebase -i” (or if it is a single commit I can instead use just “git commit --amend“).
The commit series should be a set of logical changes that are related to this change and not any more than necessary, but kept separate if they are separate. Each commit also gets its own proper commit message. Unrelated changes should be split out into its own separate branch and subsequent separate pull request.
git push origin bagder/my-new-stuff-or-bugfix
On GitHub, I then make the newly pushed branch into a pull request (aka “a PR”). It will then become visible in the list of pull requests on the site for the curl source repository, it will be announced in the #curl IRC channel and everyone who follows the repository on GitHub will be notified accordingly.
Perhaps most importantly, a pull request kicks of a flood of CI jobs that will build and test the code in numerous different combinations and on several platforms, and the results of those tests will trickle in over the coming hours. When I write this, we have around 90 different CI jobs – per pull request – and something like 8 different code analyzers will scrutinize the change to see if there’s any obvious flaws in there.
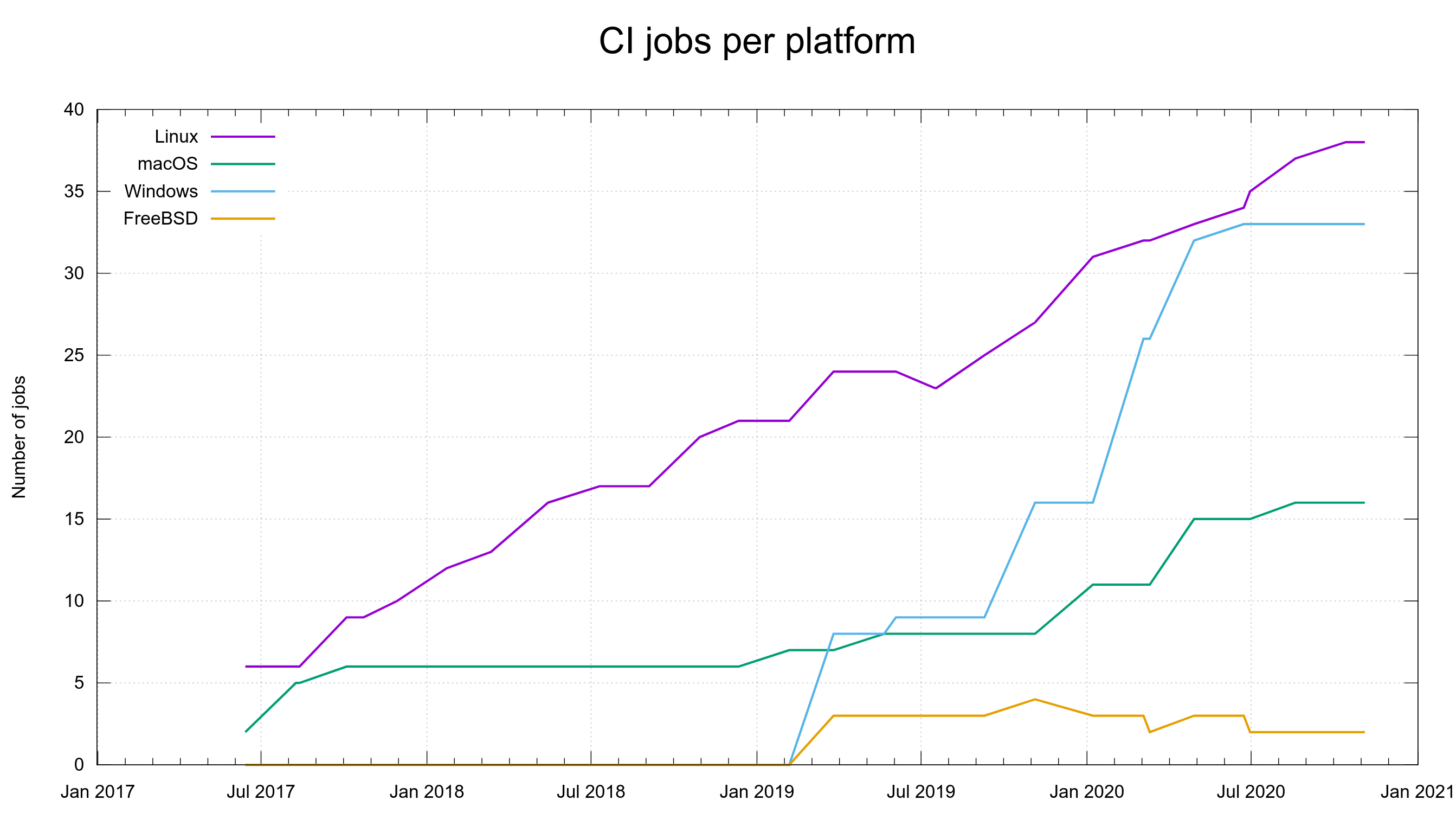
Most contributors who would work on curl would not do like me and make the branch in the curl repository itself, but would rather do them in their own forked version instead. The difference isn’t that big and I could of course also do it that way.
As it will take some time to get the full CI results from the PR to come in (generally a few hours), I switch over to the next branch with work on my agenda. On a normal work-day I can easily move over ten different branches, polish them and submit updates in their respective pull-requests.
I can go back to the master branch again with ‘git checkout master‘ and there I can “git pull” to get everything from upstream – like when my fellow developers have pushed stuff in the mean time.
If a reviewer or a CI job find a mistake in one of my PRs, that becomes visible on GitHub and I get to work to handle it. To either fix the bug or discuss with the reviewer what the better approach might be.
Unfortunately, flaky CI jobs is a part of life so very often there ends up one or two red markers in the list of CI jobs that can be ignored as the test failures in them are there due to problems in the setup and not because of actual mistakes in the PR…
To get back to my branch for that PR again, I “git checkout bagder/my-new-stuff-or-bugfix“, and fix the issues.
I normally start out by doing follow-up commits that repair the immediate mistake and push them on the branch:
git push origin bagder/my-new-stuff-or-bugfix
If the number of fixup commits gets large, or if the follow-up fixes aren’t small, I usually end up doing a squash to reduce the number of commits into a smaller, simpler set, and then force-push them to the branch.
The reason for that is to make the patch series easy to review, read and understand. When a commit series has too many commits that changes the previous commits, it becomes hard to review.
When the pull request is ripe for merging (independently of who authored it), I switch over to the master branch again and I merge the pull request’s commits into it. In special cases I cherry-pick specific commits from the branch instead. When all the stuff has been yanked into master properly that should be there, I push the changes to the remote.
Usually, and especially if the pull request wasn’t done by me, I also go over the commit messages and polish them somewhat before I push everything. Commit messages should follow our style and mention not only which PR that it closes but also which issue it fixes and properly give credit to the bug reporter and all the helpers – using the right syntax so that our automatic tools can pick them up correctly!
As already mentioned above, I merge fast-forward or rebased into master. No merge commits.
There’s a button GitHub that says “rebase and merge” that could theoretically be used for merging pull requests. I never use that (and if I could, I’d disable/hide it). The reasons are simply:
The downside with not using the merge button is that the message in the PR says “closed by [hash]” instead of “merged in…” which causes confusion to a fair amount of users who don’t realize it means that it actually means the same thing! I consider this is a (long-standing) GitHub UX flaw.
If the branch has nothing to be kept around more, I delete the local branch again with “git branch -d [name]” and I remove it remotely too since it was completely merged there’s no reason to keep the work version left.
At any given point in time, I have some 20-30 different local branches alive using this approach so things I work on over time all live in their own branches and also submissions from various people that haven’t been merged into master yet exist in branches of various maturity levels. Out of those local branches, the number of concurrent pull requests I have in progress can be somewhere between just a few up to ten, twelve something.
Not strictly related, but in order to keep interested people informed about what’s happening in the tree, we sync the RELEASE-NOTES file every once in a while. Maybe every 5-7 days or so. It thus becomes a file that explains what we’ve worked on since the previous release and it makes it well-maintained and ready by the time the release day comes.
To sync it, all I need to do is:
$ ./scripts/release-notes.pl
Which makes the script add suggested updates to it, so I then load the file into my editor, remove the separation marker and all entries that don’t actually belong there (as the script adds all commits as entries as it can’t judge the importance).
When it looks okay, I run a cleanup round to make it sort it and remove unused references from the file…
$ ./scripts/release-notes.pl cleanup
Then I make sure to get a fresh list of contributors…
$ ./scripts/contributors.sh
… and paste that updated list into the RELEASE-NOTES. Finally, I get refreshed counters for the numbers at the top of the file by running
$ ./scripts/delta
Then I commit the update (which needs to have the commit message RELEASE-NOTES: synced“) and push it to master. Done!
The most up-to-date version of RELEASE-NOTES is then always made available on https://curl.se/dev/release-notes.html
Picture by me, taken from the passenger seat on a helicopter tour in 2011.