

Thank you everyone who has helped out in making curl into what it is today.
We make an effort to note the names of and say thanks to every single individual who ever reported bugs, fixed problems, ran tests, wrote code, polished the website, spell-fixed documentation, assisted debug sessions, helped interpret protocol standards, reported security problems or co-authored code etc.
In 2005 I decided to go back through the project history and make sure all names that had been involved up to that point in time would also be mentioned in the THANKS file. This is the reason for the visible bump in the graph.
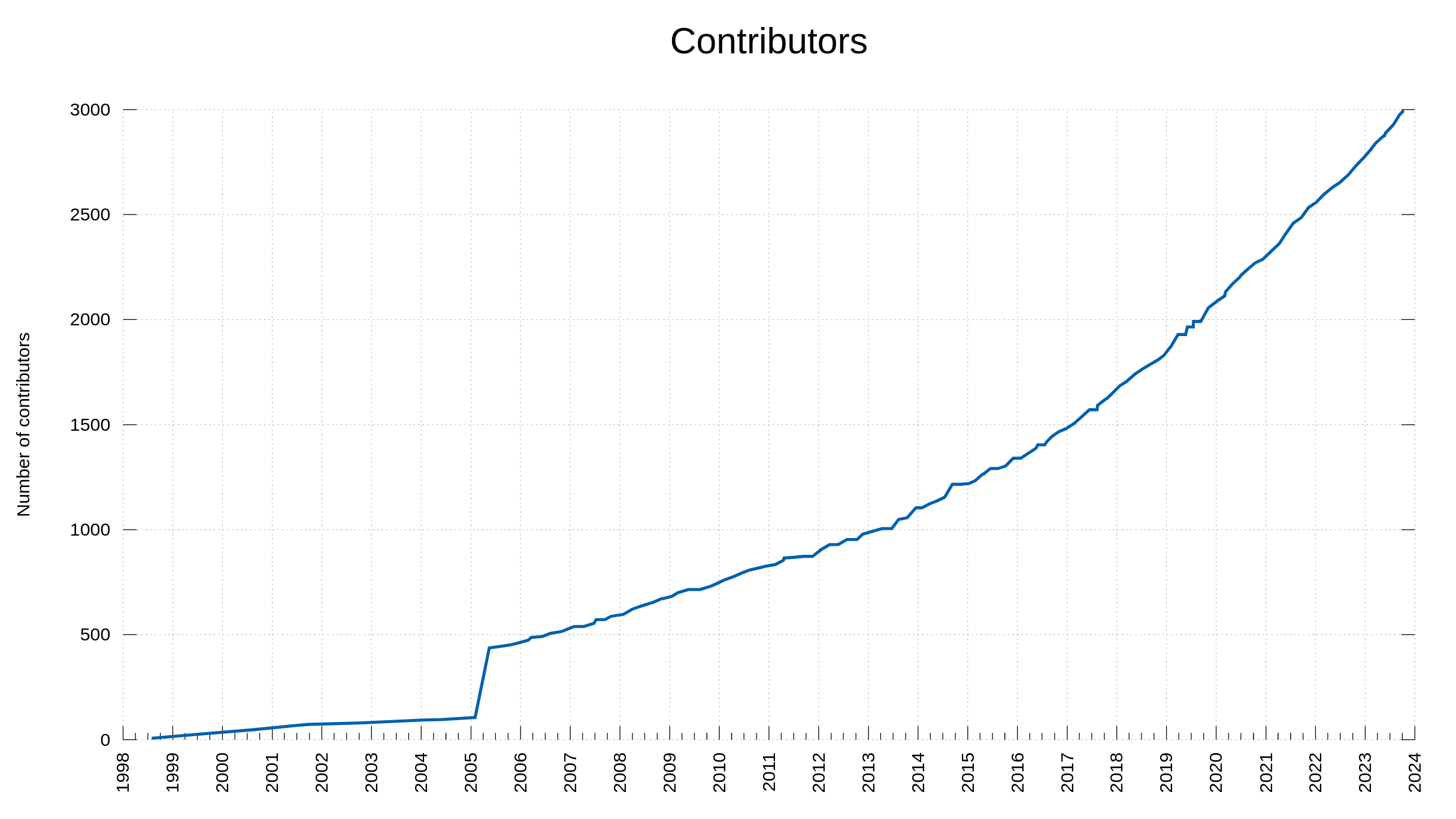
Since then, we add the names of all the helpers. We say thanks and give credits in commit messages and we have scripts to help us collect them and mention them as contributors. We probably miss occasional ones but I hope and believe that most of all the awesome people that ever helped us are recorded accordingly and given credit.
We are nothing without out dear contributors.
Today, this list of people we are thankful for, reached 3,000 entries when Alex Klyubin’s pull request was merged. (The list of names on the website is synced every once in a while so it actually typically shows slightly fewer people than we have logged in git.)
The team behind curl. 3,000 persons over almost 27 years.
We reached 2,000 contributors less than four years ago, in October 2019, so we have added about 250 new names per year to this list the last four years.
We reached 1,000 contributors in March 2013, meaning from then it took about 6.5 years to get the next 1,000. Roughly 150 new names per year.
The first 1,000 took over 16 years to reach.
You too can see it quite clearly in the graph above as well: the rate of which we get new contributors to help out in the project is increasing.
curl has existed for 9338 days. That equals one new contributor every 3.1 days for over 25 years, on average.
Non-code or code alike
It is oftentimes said that Open Source projects in general have a hard time to properly recognize and appreciate non-code contributions. In the curl project, we try hard to not differentiate between help and help.
If a person helps out to take the curl project further, even if just by a little, we say thank you very much and add their name to the list. We need and are grateful for code and non-code contributions alike. One of the most important parts of the curl project is the documentation, and that is clearly not code.
About the contributors
We cannot say much about the contributors because in an effort to lower the bars and reduce friction, we also do not ask them about details. We only know the name they provide the help under, which could be a pseudonym and in some cases clearly are nicknames. We do not know where in the world they originate from or which company they work for, we can’t tell their gender, skin color, religion or other human “properties”. And we don’t care much about those specifics. Our job is to bring curl forward.
This said: there is a risk that we have added the same contributors twice or more, if they have helped out using several different names. That is just not something we can detect or avoid. Unless the contributor themself informs us.
There is also a risk that some of the persons that contributed to curl are not nice people or that they work for reprehensible organizations. We focus on the quality of their submissions and if they hide who they are, we will never know if they actually are animal-hurting nazis hiding behind pseudonyms.
(Lack of) Diversity
As far as I can tell, we have a lousy contributor diversity. I am pretty sure the majority of all help come from old white middle-class western men. Like myself.
I cannot fully know this for sure because I only actually know a small fraction of all the contributors, but out of the ones I have met this is true and I believe I have met or at least communicated with the ones who have done the vast majority of all the changes.
I would much rather see us have many more contributors from other parts of the world, female, and with non-christian backgrounds, but I cannot control who comes to us. I can only do my best to take care of all and appreciate every contribution without discrimination.
Commit authors
This day when we reach 3,000 contributors, we also count 1,201 commit authors. Persons with their names as authors of at least one commit in the curl source repository. 40% of the contributors are committers. Almost 65% of the committers only ever committed once.
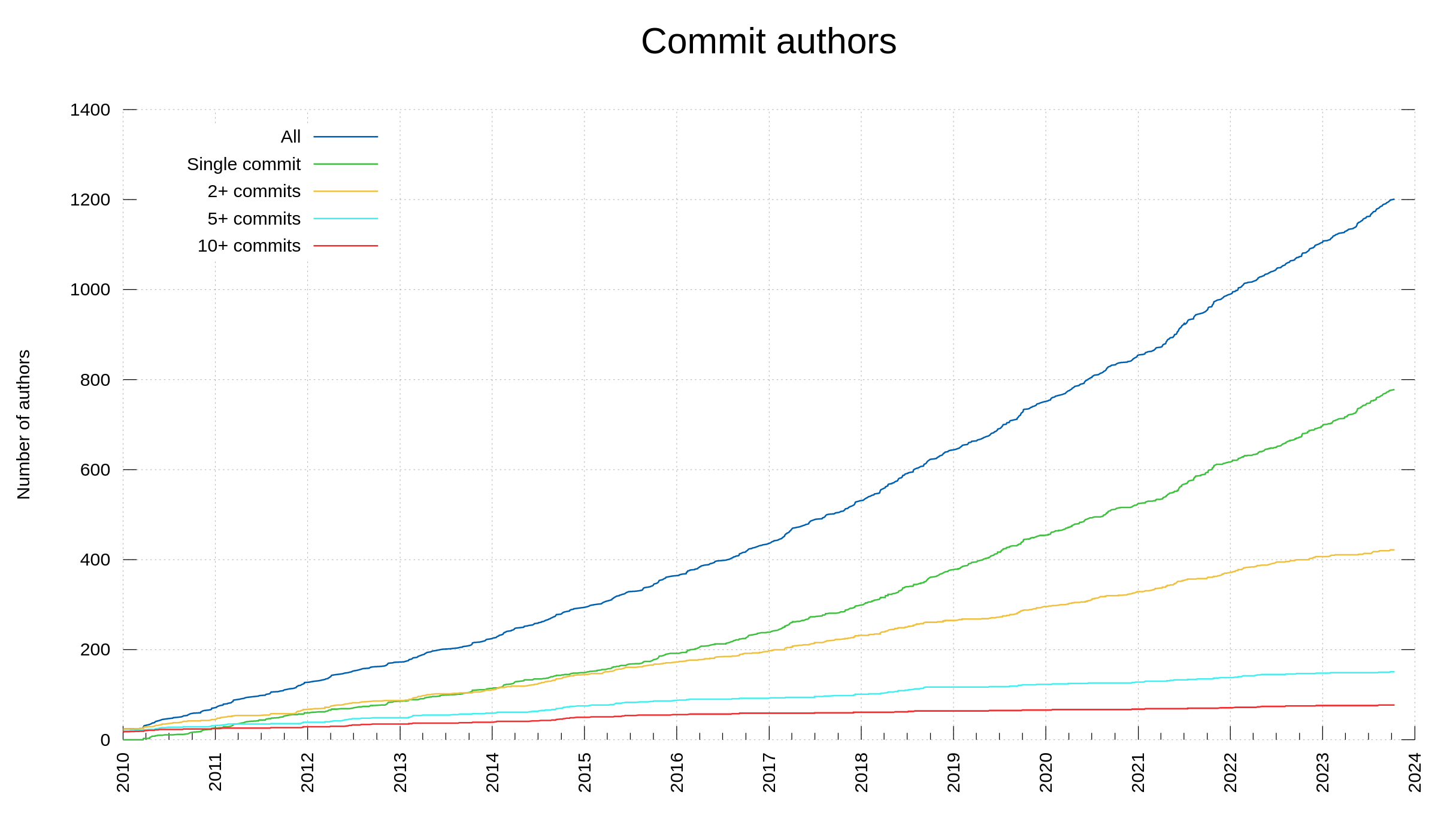
3,000 visualized
The top image of this blog post is a photo from FOSDEM a few years back when I did a presentation in front of a packed room with some 1,400 attendees. The largest room at FOSDEM is said to fit 1415 persons. So not even two such giant rooms would be enough to hold all the curl contributors if it would have been possible to get them all in one place…
You too?
You too can be a curl contributor. We are friendly. It is not hard. There is lots to do. Your contributions can end up getting used by literally billions of humans.













