SFTP, the SSH File Transfer Protocol, is a misleading name. It gives you the impression that it might be something like a secure version of FTP, perhaps something like FTPS but modeled over SSH instead of SSL. But it isn’t!
I think a more suitable name would’ve been SNFS or FSSSH. That is: networked file system operations over SSH, as that is in fact what SFTP is. The SFTP protocol is closer to NFS in nature than FTP. It is a protocol for sending and receiving binary packets over a (secure) SSH channel to read files, write files, and so on. But not on the basis of entire files, like FTP, but by sending OPEN file as FILEHANDLE, “WRITE this piece of data at OFFSET using FILEHANDLE” etc.
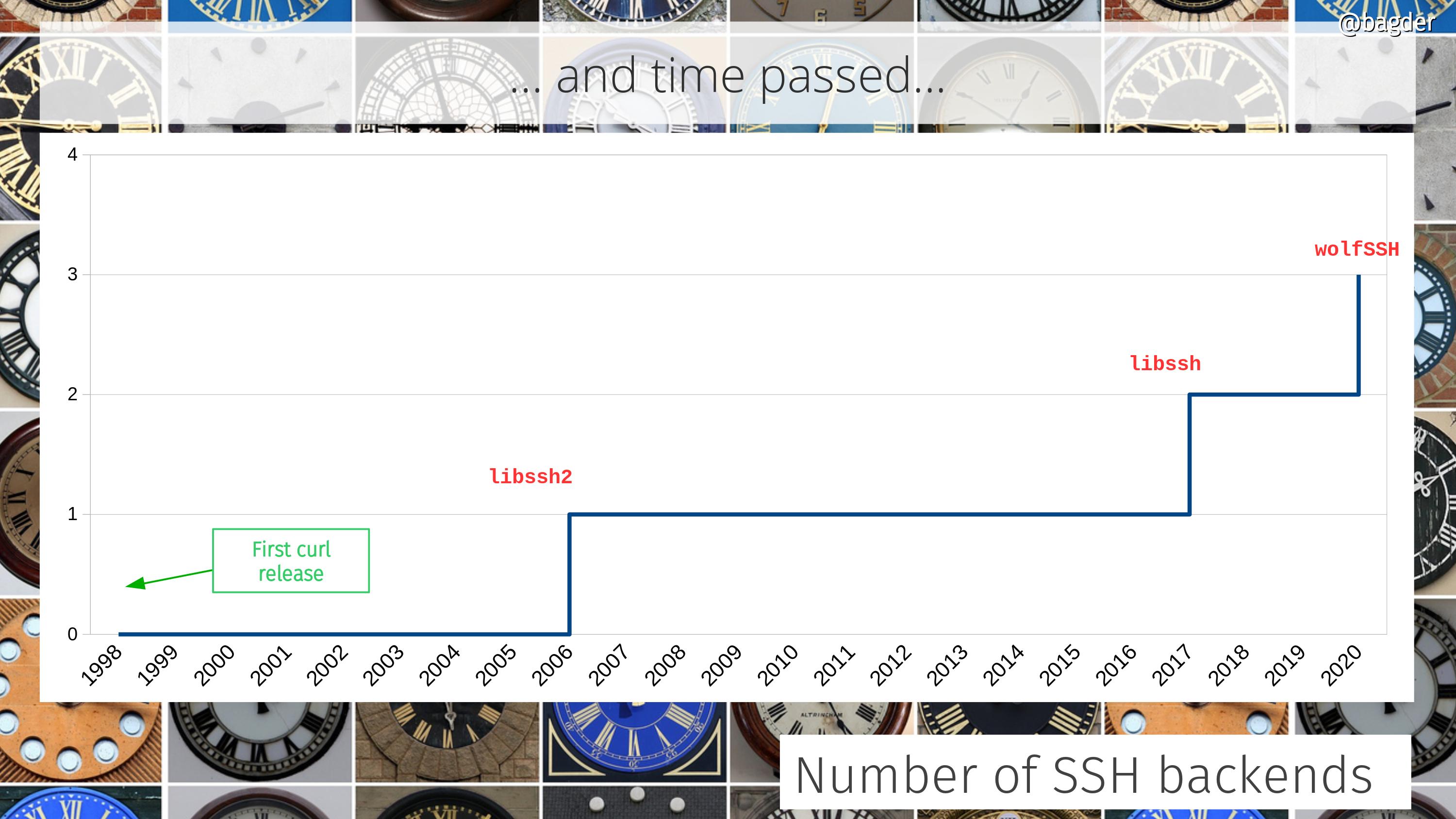
SFTP was being defined by a working group with IETF but the effort died before any specification was finalized. I wasn’t around then so I don’t know how this happened. During the course of their work, they released several drafts of the protocol using different protocol versions. Version 3, 4, 5 and 6 are the ones most used these days. Lots of SFTP implementations today still only implement the version 3 draft. (like libssh2 does for example)
Each packet in the SFTP protocol gets a response from the server to acknowledge it was received. It also includes an error code etc. So, the basic concept to write a file over SFTP is:
[client] OPEN <filehandle>
[server] OPEN OK
[client] WRITE <data> <filehandle> <offset 0> <size N>
[server] WRITE OK
[client] WRITE <data> <filehandle> <offset N> <size N>
[server] WRITE OK
[client] WRITE <data> <filehandle> <offset N*2> <size N>
[server] WRITE OK
[client] CLOSE <filehandle>
[server] CLOSE OK
This example obviously assumes the whole file was written in three WRITE packets. A single SFTP packet cannot be larger than 32768 bytes so if your client could read the entire file into memory, it can only send it away using very many small chunks. I don’t know the rationale for selecting such a very small maximum packet size, especially since the SSH channel layer over which SFTP packets are transferred over doesn’t have the same limitation but allows much larger ones! Interestingly, if you send a READ of N bytes from the server, you apparently imply that you can deal with packets of that size as then the server can send packets back that are N bytes (plus header)…
Enter network latency.
More traditional transfer protocols like FTP, HTTP and even SCP work on entire files. Roughly like “send me that file and keep sending until the entire thing is sent”. The use of windowing in the transfer layer (TCP for FTP and HTTP and within the SSH channels for SCP) allows flow control to work without having to ACK every single little packet. This is a great concept to keep the flow going at high speed and still allow the receiver to not get drowned. Even if there’s a high network latency involved.
The nature of SFTP and its ACK for every small data chunk it sends, makes an initial naive SFTP implementation suffer badly when sending data over high latency networks. If you have to wait a few hundred milliseconds for each 32KB of data then there will never be fast SFTP transfers. This sort of naive implementation is what libssh2 has offered up until and including libssh2 1.2.7.
To achieve speedy transfers with SFTP, we need to “pipeline” the packets. We need to send out several packets before we expect the answers to previous ones, to make the sending of an SFTP packet and the checking of the corresponding ACKs asynchronous. Like in the above example, we would send all WRITE commands before we wait for/expect the ACKs to come back from the server. Then the round-trip time essentially becomes a non-factor (or at least a very small one).

We’ve worked on implementing this kind of pipelining for SFTP uploads in libssh2 and it seems to have paid off. In some measurements libssh2 is now one of the faster SFTP clients.
In tests I did over a high-latency connection, I could boost libssh2’s SFTP upload performance 8 (eight) times compared to the former behavior. In fact, that’s compared to earlier git behavior, comparing to the latest libssh2 release version (1.2.7) would most likely show an even greater difference.
My plan is now to implement this same concept for SFTP downloads in libssh2, and then look over if we shouldn’t offer a slightly modified API to allow applications to use pipelined transfers better and easier.