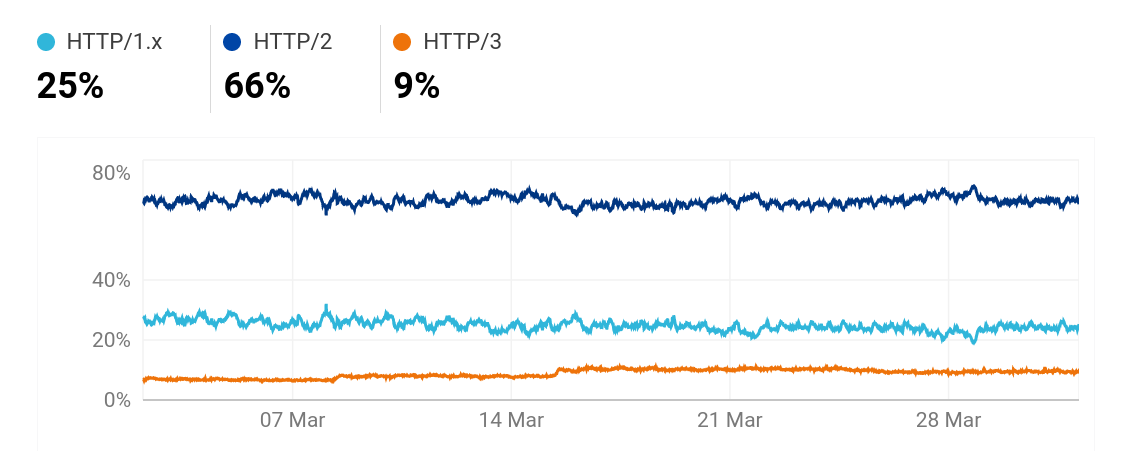
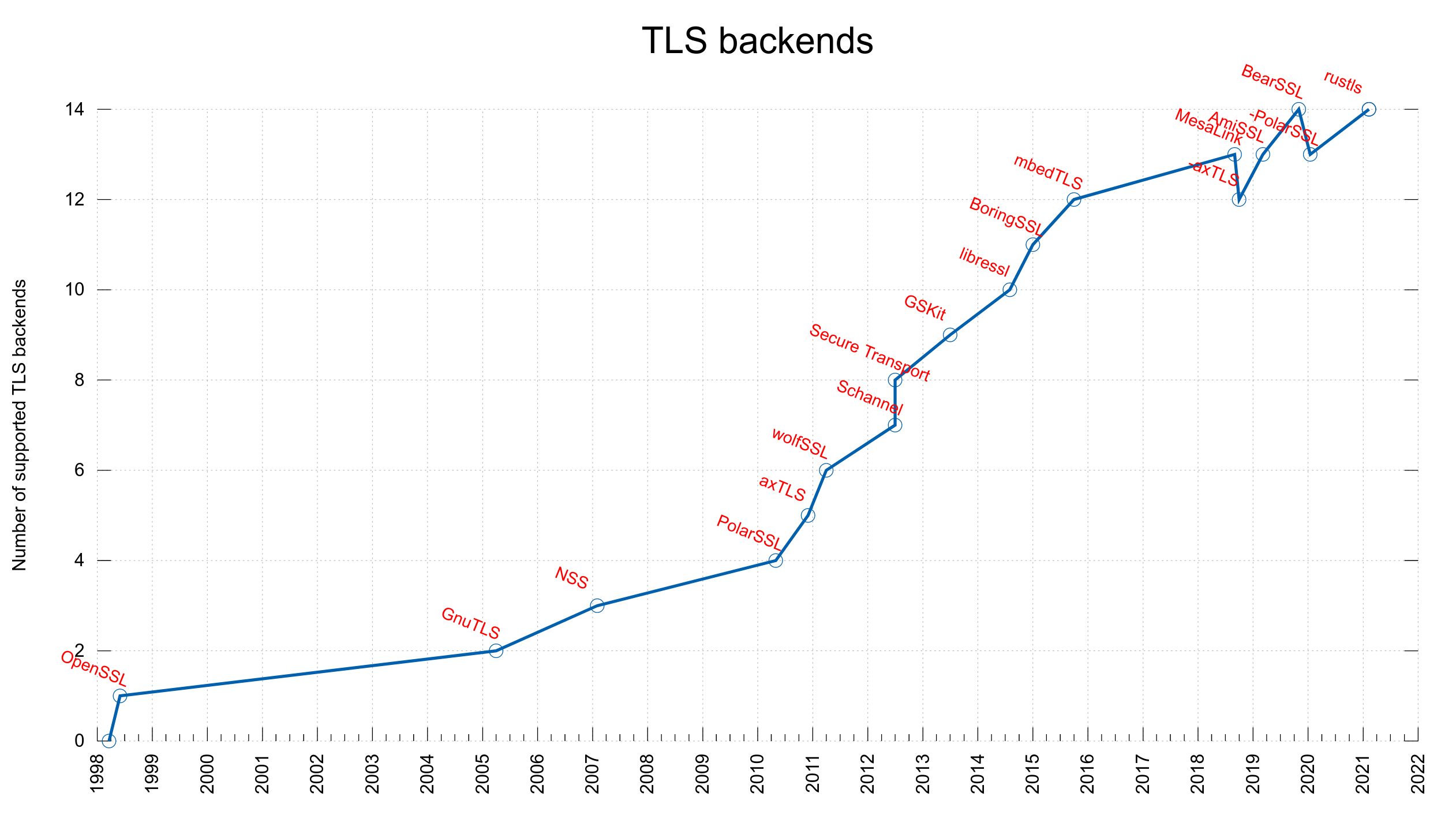
When a client connects to a TLS server it gets sent one or more certificates during the handshake.
Those certificates are verified by the client, to make sure that the server is indeed the right one: the server the client expects it to be; no impostor and no man in the middle etc.
When such a server certificate is signed by a Certificate Authority (CA), that CA’s certificate is normally not sent by the server but the client is expected to have it already in its CA store.
What certs?
Ever since the day SSL and TLS first showed up in the 1990s user have occasionally wanted to be able to save the certificates provided by the server in a TLS handshake.
The openssl tool has offered this ability since along time and is actually one of my higher ranked stackoverflow answers.
Export the certificates with the tool first, and then in subsequent transfers you can tell curl to use those certificates as a CA store:
$ echo quit | openssl s_client -showcerts -connect curl.se:443 > cacert.pem
$ curl --cacert cacert.pem https://curl.se/This is of course most convenient when that server is using a self-signed certificate or something otherwise unusual.
(WARNING: The above shown example is an insecure way of reaching the host, as it does not detect if the host is already MITMed at the time when the first command runs. Trust On First Use.)
OpenSSL
A downside with the approach above is that it requires the openssl tool. Albeit, not a big downside for most people.
There are also alternative tools provided by wolfSSL and GnuTLS etc that offer the same functionality.
QUIC
Over the last few years we have seen a huge increase in number of servers that run QUIC and HTTP/3, and tools like curl and all the popular browsers can communicate using this modern set of protocols.
OpenSSL cannot. They decided to act against what everyone wanted, and as a result the openssl tool also does not support QUIC and therefore it cannot show the certificates used for a HTTP/3 site!
This is an inconvenience to users, including many curl users. I decided I could do something about it.
CURLOPT_CERTINFO
Already back in 2016 we added a feature to libcurl that enables it to return a list of certificate information back to the application, including the certificate themselves in PEM format. We call the option CURLOPT_CERTINFO.
We never exposed this feature in the command line tool and we did not really see the need as everyone could use the openssl tool etc fine already.
Until now.
curl -w is your friend
curl supports QUIC and HTTP/3 since a few years back, even if still marked as experimental. Because of this, the above mentioned CURLOPT_CERTINFO option works fine for that protocol version as well.
Using the –write-out (-w) option and the new variables %{certs} and %{num_certs} curl can now do what you want. Get the certificates from a server in PEM format:
$ curl https://curl.se -w "%{certs}" -o /dev/null > cacert.pem
$ curl --cacert cacert.pem https://curl.se/You can of course also add --http3 to the command line if you want, and if you like to get the certificates from a server with a self-signed one you may want to use --insecure. You might consider adding --head to avoid the response body. This command line uses -o to write the content to /dev/null because it does not care about that data.
The %{num_certs} variable shows the number of certificates returned in the handshake. Typically one or two but can be more.
%{certs} outputs the certificates in PEM format together with a number of other details and meta data about the certificates in a “name: value” format.
Availability
These new -w variables are only supported if curl is built with a supported TLS backend: OpenSSL/libressl/BoringSSL/quictls, GnuTLS, Schannel, NSS, GSKit and Secure Transport.
Support for these new -w variables has been merged into curl’s master branch and is scheduled to be part of the coming release of curl version 7.88.0 on February 15th, 2023.