

curl turns twenty-two years old today. Let’s celebrate this by looking at its development, growth and change over time from a range of different viewpoints with the help of graphs and visualizations.
This is the more-curl-graphs-than-you-need post of the year. Here are 22 pictures showing off curl in more detail than anyone needs.
I founded the project back in the day and I remain the lead developer – but I’m far from alone in this. Let me take you on a journey and give you a glimpse into the curl factory. All the graphs below are provided in hires versions if you just click on them.
Below, you will learn that we’re constantly going further, adding more and aiming higher. There’s no end in sight and curl is never done. That’s why you know that leaning on curl for Internet transfers means going with a reliable solution.
Number of lines of code
Counting only code in the tool and the library (and public headers) it still has grown 80 times since the initial release, but then again it also can do so much more.
At times people ask how a “simple HTTP tool” can be over 160,000 lines of code. That’s basically three wrong assumptions put next to each other:
- curl is not simple. It features many protocols and fairly advanced APIs and super powers and it offers numerous build combinations and runs on just all imaginable operating systems
- curl supports 24 transfer protocols and counting, not just HTTP(S)
- curl is much more than “just” the tool. The underlying libcurl is an Internet transfer jet engine.
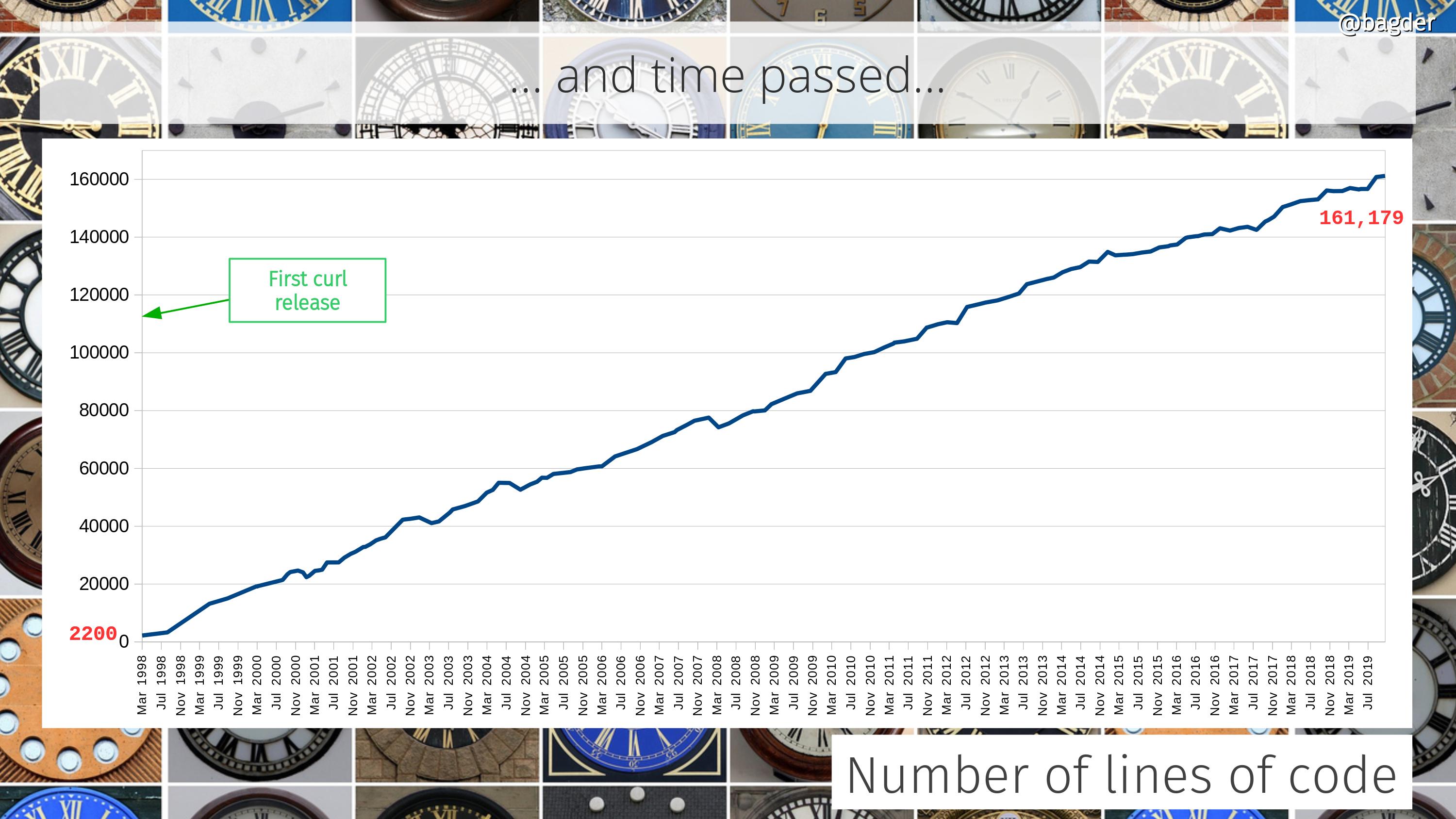
How much more is curl going to grow and can it really continue growing like this even for the next 22 years? I don’t know. I wouldn’t have expected it ten years ago and guessing the future is terribly hard. I think it will at least continue growing, but maybe the growth will slow down at some point?
Number of contributors
Lots of people help out in the project. Everyone who reports bugs, brings code patches, improves the web site or corrects typos is a contributor. We want to thank everyone and give all helpers the credit they deserve. They’re all contributors. Here’s how fast our list of contributors is growing. We’re at over 2,130 names now.
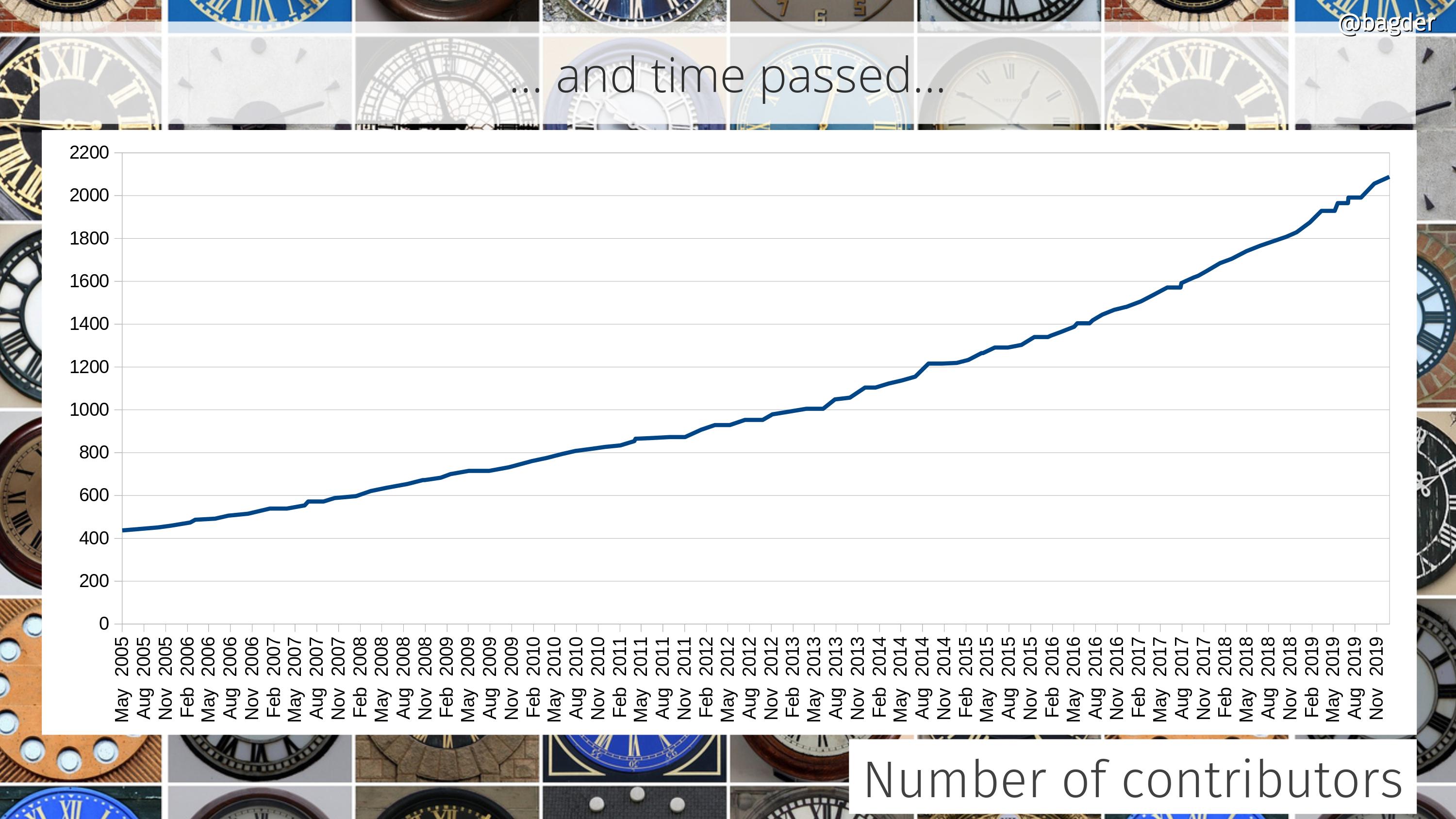
When I wrote a blog post five years ago, we had 1,200 names in the list and the graph shows a small increase in growth over time…
Daniel’s share of total commits
I started the project. I’m still very much involved and I spend a ridiculous amount of time and effort in driving this. We’re now over 770 commits authors and this graph shows how the share of commits I do to the project has developed over time. I’ve done about 57% of all commits in the source code repository right now.
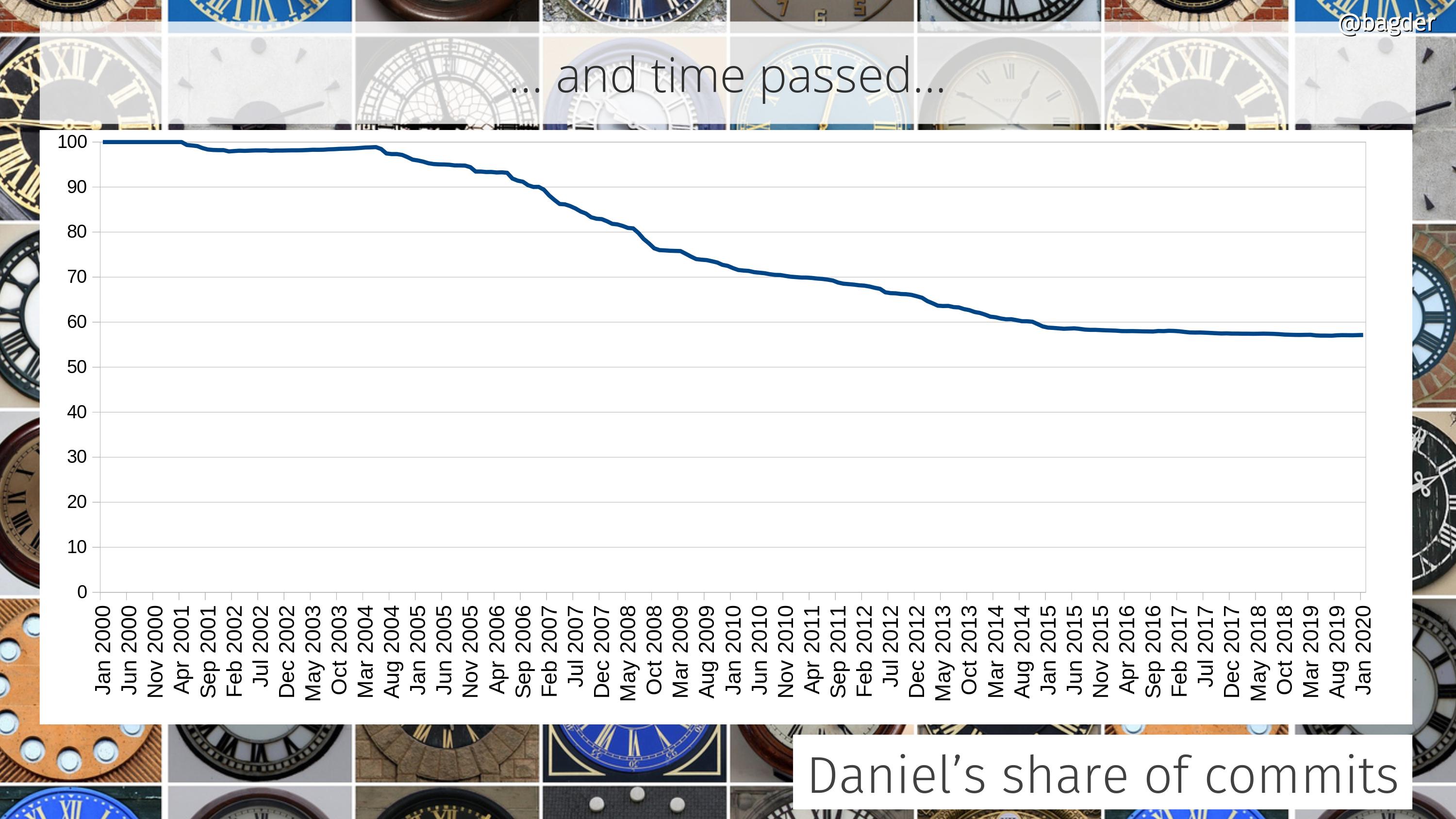
The graph is the accumulated amount. Some individual years I actually did far less than 50% of the commits, which the following graph shows
Daniel’s share of commits per year
In the early days I was the only one who committed code. Over time a few others were “promoted” to the maintainer role and in 2010 we switched to git and the tracking of authors since then is much more accurate.
In 2014 I joined Mozilla and we can see an uptake in my personal participation level again after having been sub 50% by then for several years straight.
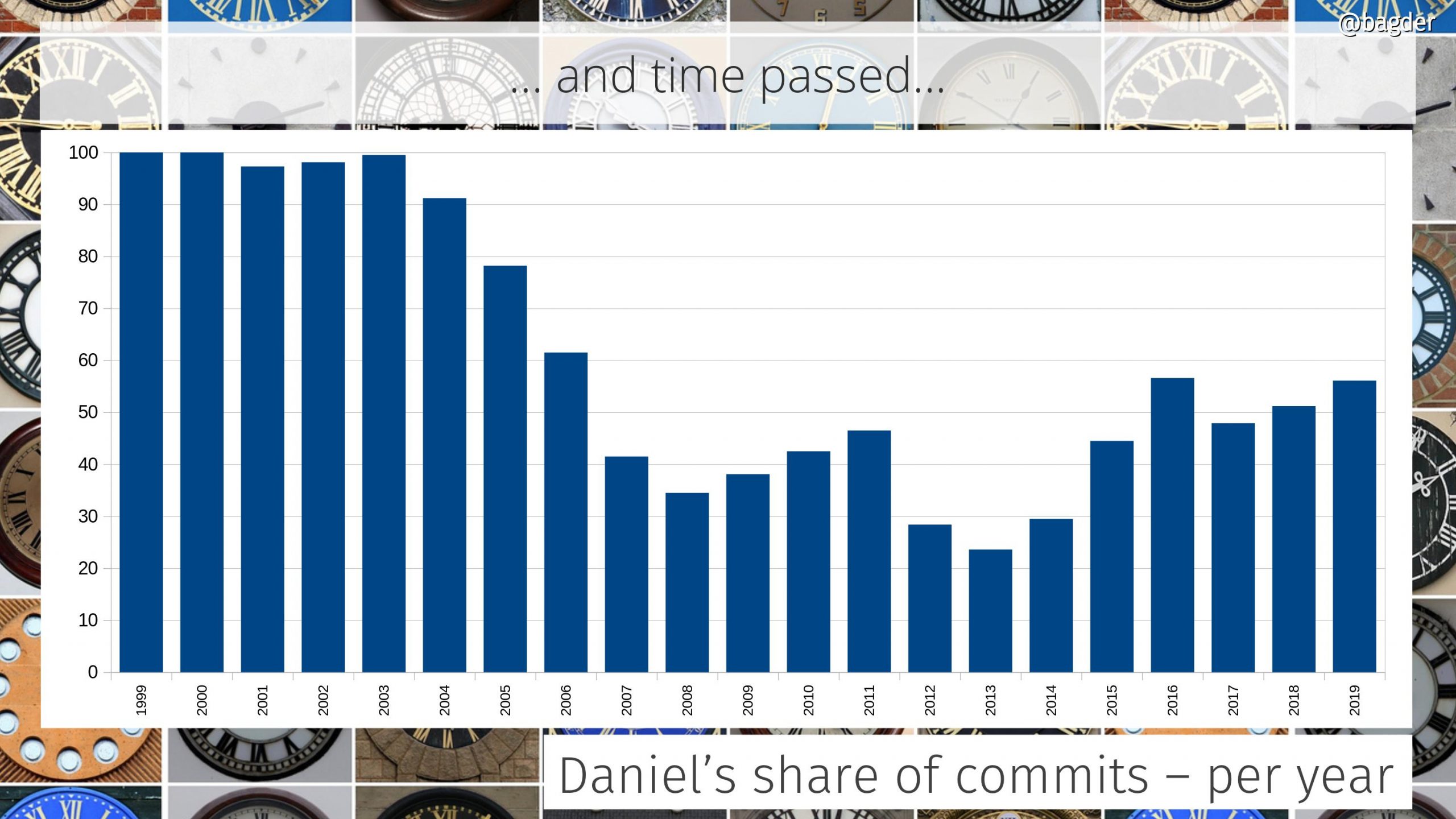
There’s always this argument to be had if it is a good or a bad sign for the project that my individual share is this big. Is this just because I don’t let other people in or because curl is so hard to work on and only I know my ways around the secret passages? I think the ever-growing number of commit authors at least show that it isn’t the latter.
What happens the day I grow bored or get run over by a bus? I don’t think there’s anything to worry about. Everything is free, open, provided and well documented.
Number of command line options
The command line tool is really like a very elaborate Swiss army knife for Internet transfers and it provides many individual knobs and levers to control the powers. curl has a lot of command line options and they’ve grown in number like this.
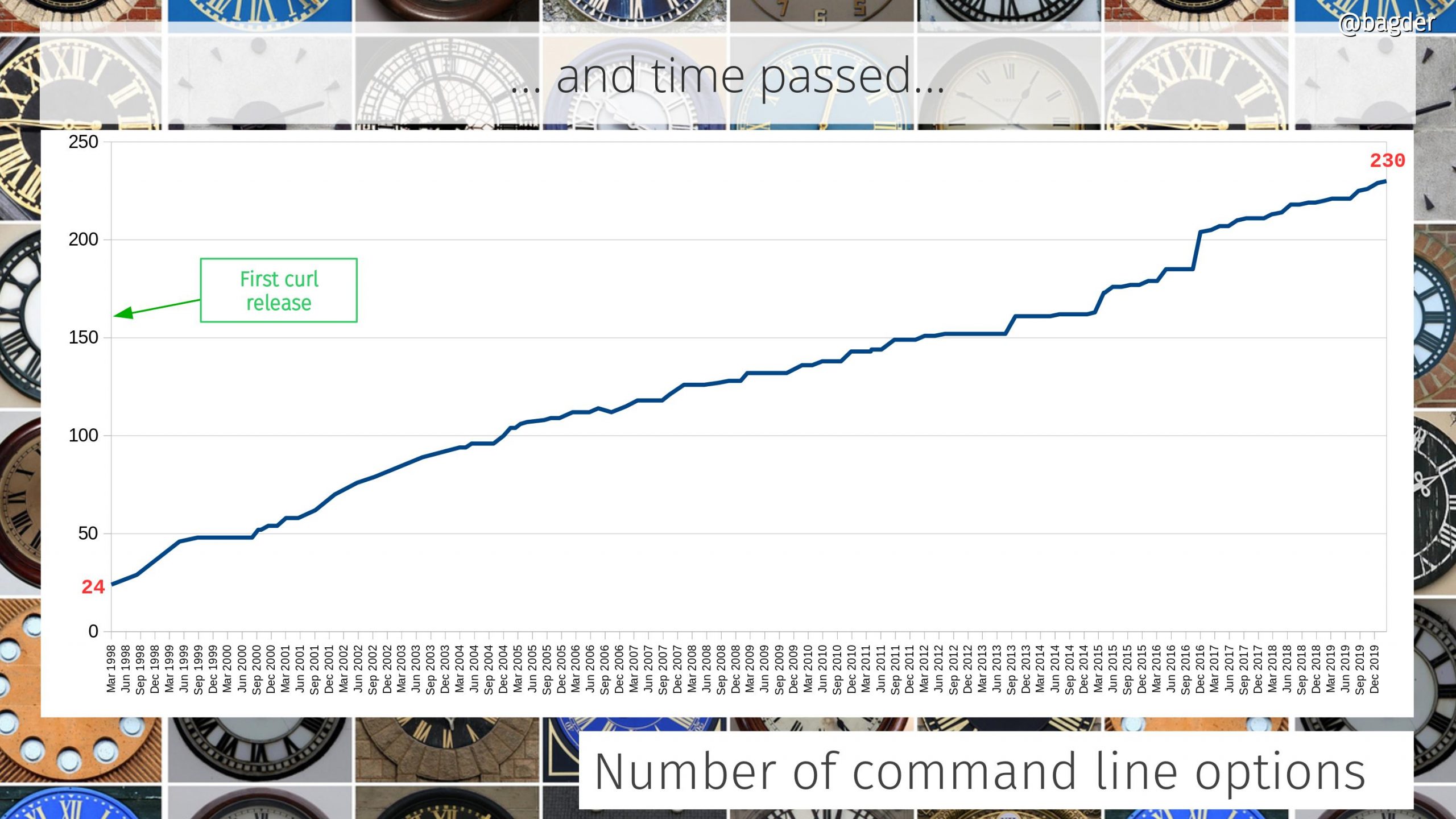
Is curl growing too hard to use? Should we redo the “UI” ? Having this huge set of features like curl does, providing them all with a coherent and understandable interface is indeed a challenge…
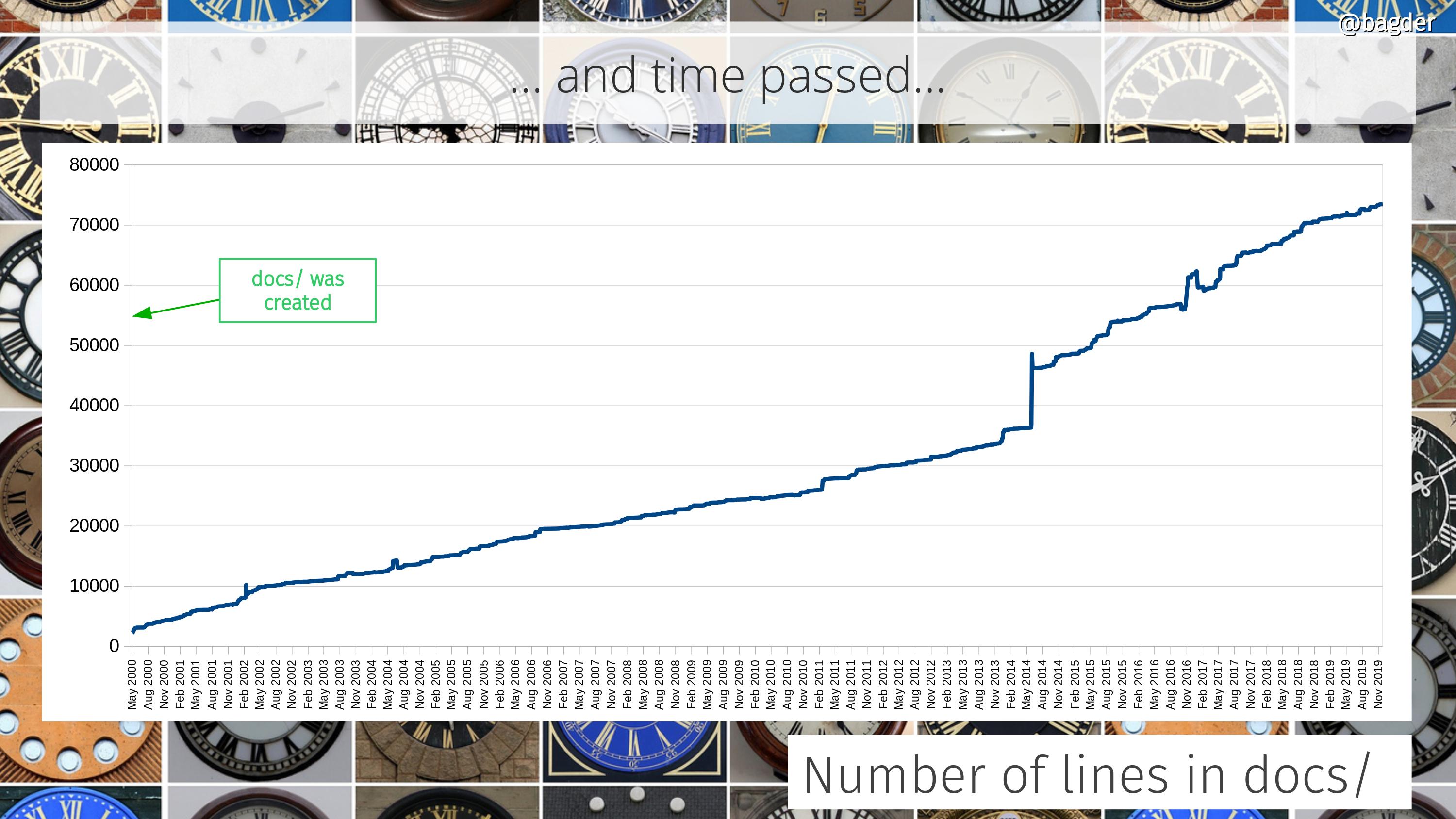
Number of lines in docs/
Documentation is crucial. It’s the foundation on which users can learn about the tool, the library and the entire project. Having plenty and good documentation is a project ambition. Unfortunately, we can’t easily measure the quality.
All the documentation in curl sits in the docs/ directory or sub directories in there. This shows how the amount of docs for curl and libcurl has grown through the years, in number of lines of text. The majority of the docs is in the form of man pages.
Number of supported protocols
This refers to protocols as in primary transfer protocols as in what you basically specify as a scheme in URLs (ie it doesn’t count “helper protocols” like TCP, IP, DNS, TLS etc). Did I tell you curl is much more than an HTTP client?
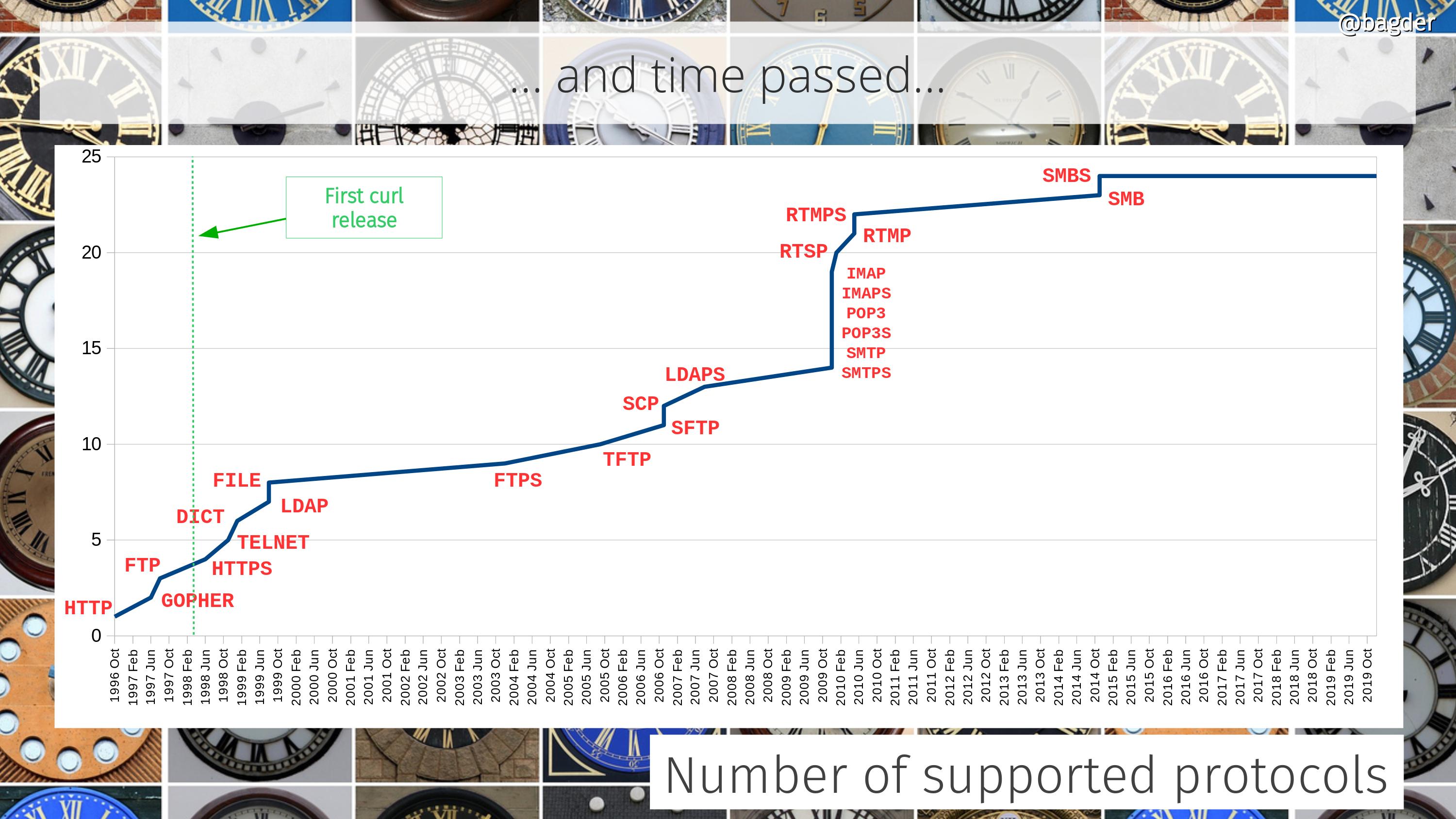
More protocols coming? Maybe. There are always discussions and ideas… But we want protocols to have a URL syntax and be transfer oriented to map with the curl mindset correctly.
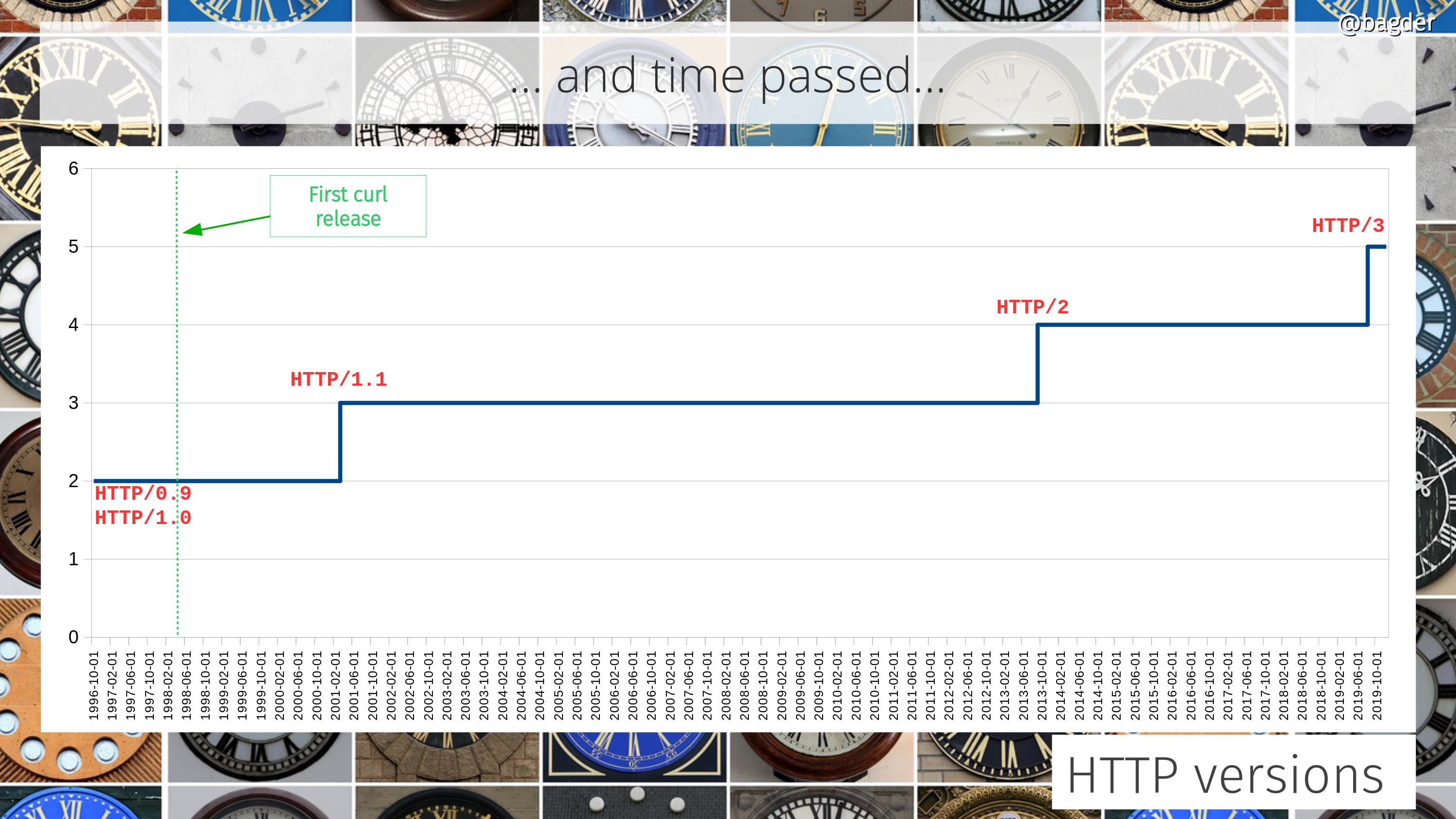
Number of HTTP versions
The support for different HTTP versions has also grown over the years. In the curl project we’re determined to support every HTTP version that is used, even if HTTP/0.9 support recently turned disabled by default and you need to use an option to ask for it.
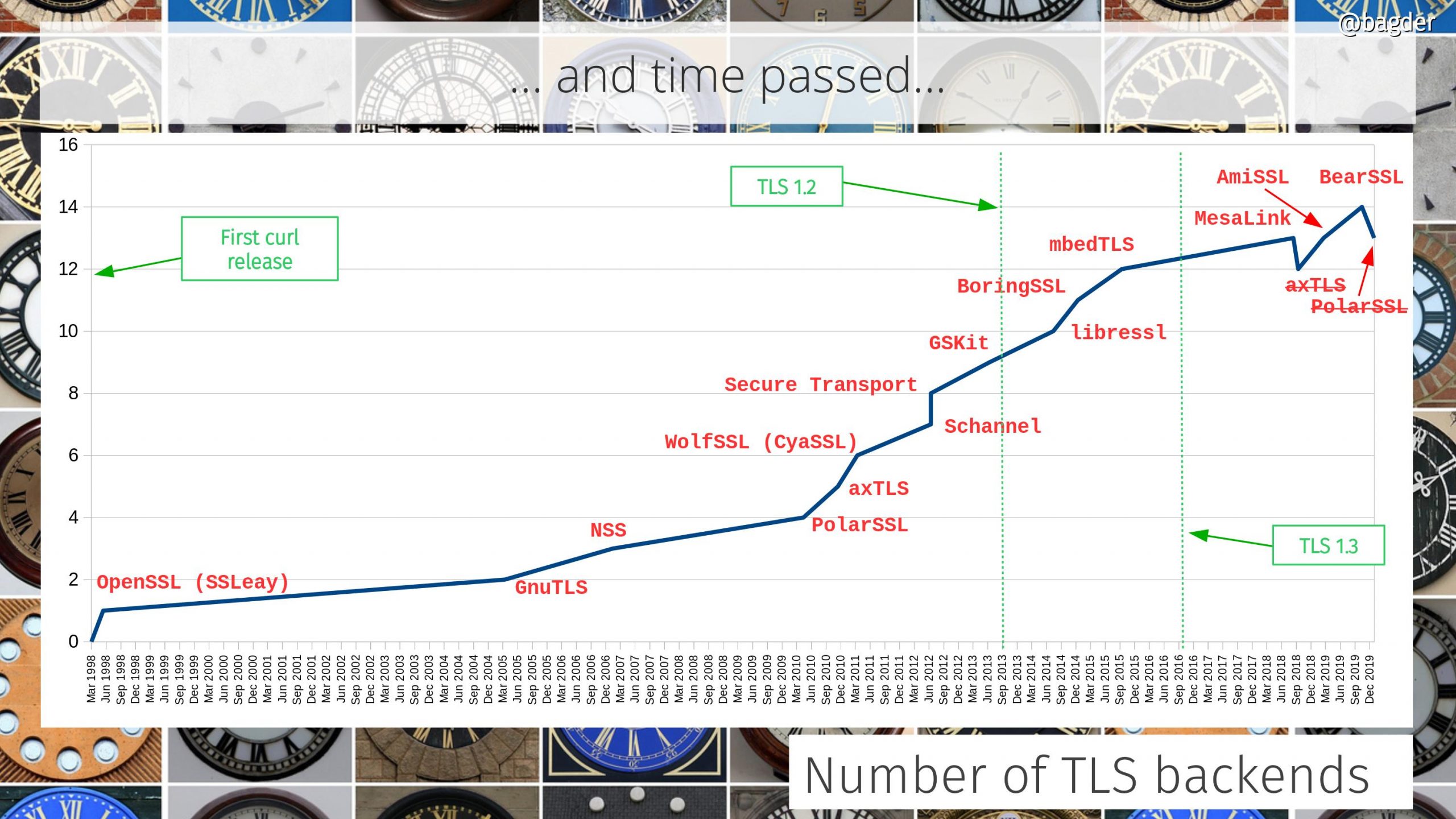
Number of TLS backends
The initial curl release didn’t even support HTTPS but since 2005 we’ve support customizable TLS backends and we’ve been adding support for many more ones since then. As we removed support for two libraries recently we’re now counting thirteen different supported TLS libraries.
Number of HTTP/3 backends
Okay, this graph is mostly in jest but we recently added support for HTTP/3 and we instantly made that into a multi backend offering as well.
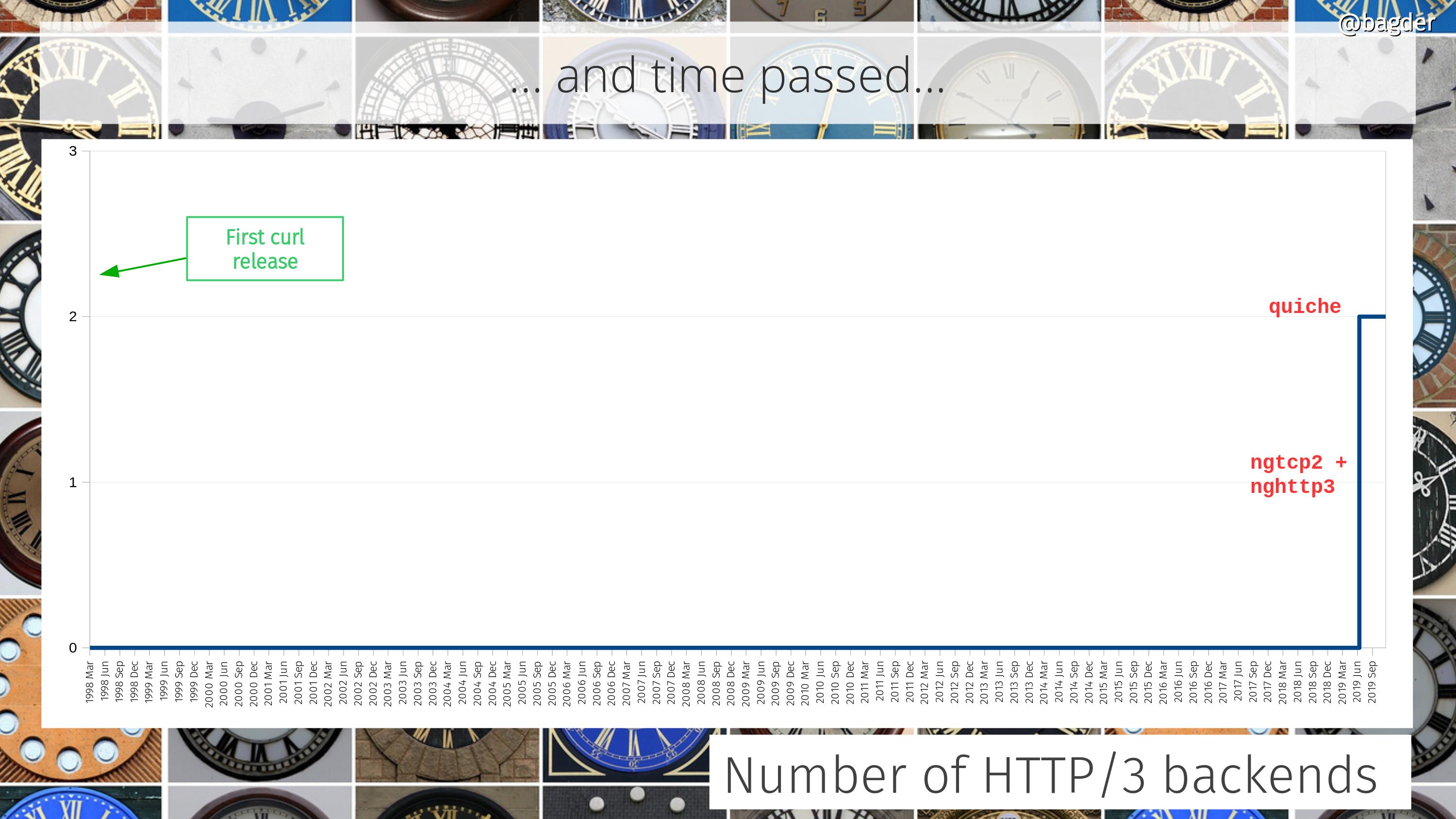
An added challenge that this graph doesn’t really show is how the choice of HTTP/3 backend is going to affect the choice of TLS backend and vice versa.
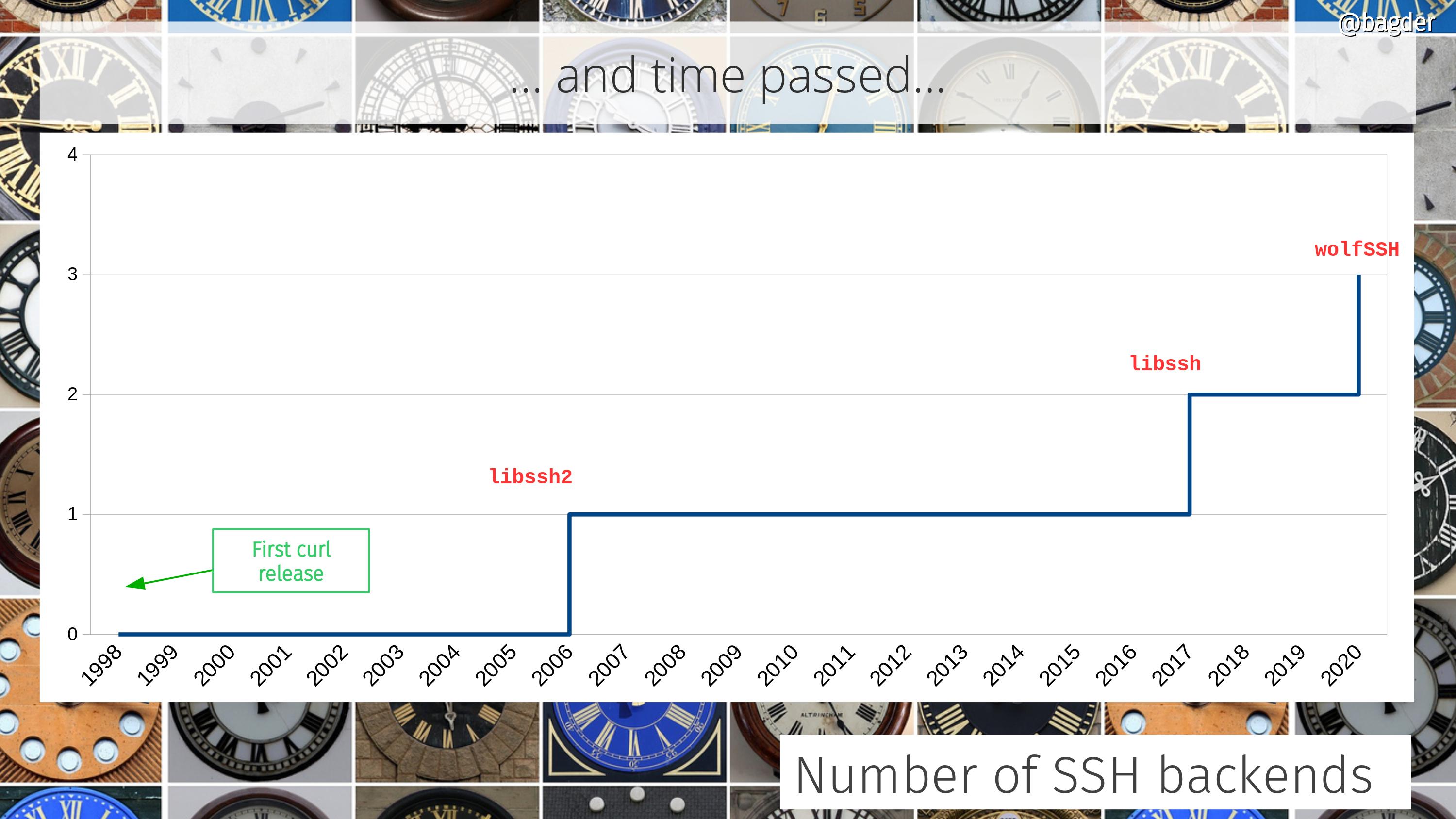
Number of SSH backends
For a long time we only supported a single SSH solution, but that was then and now we have three…
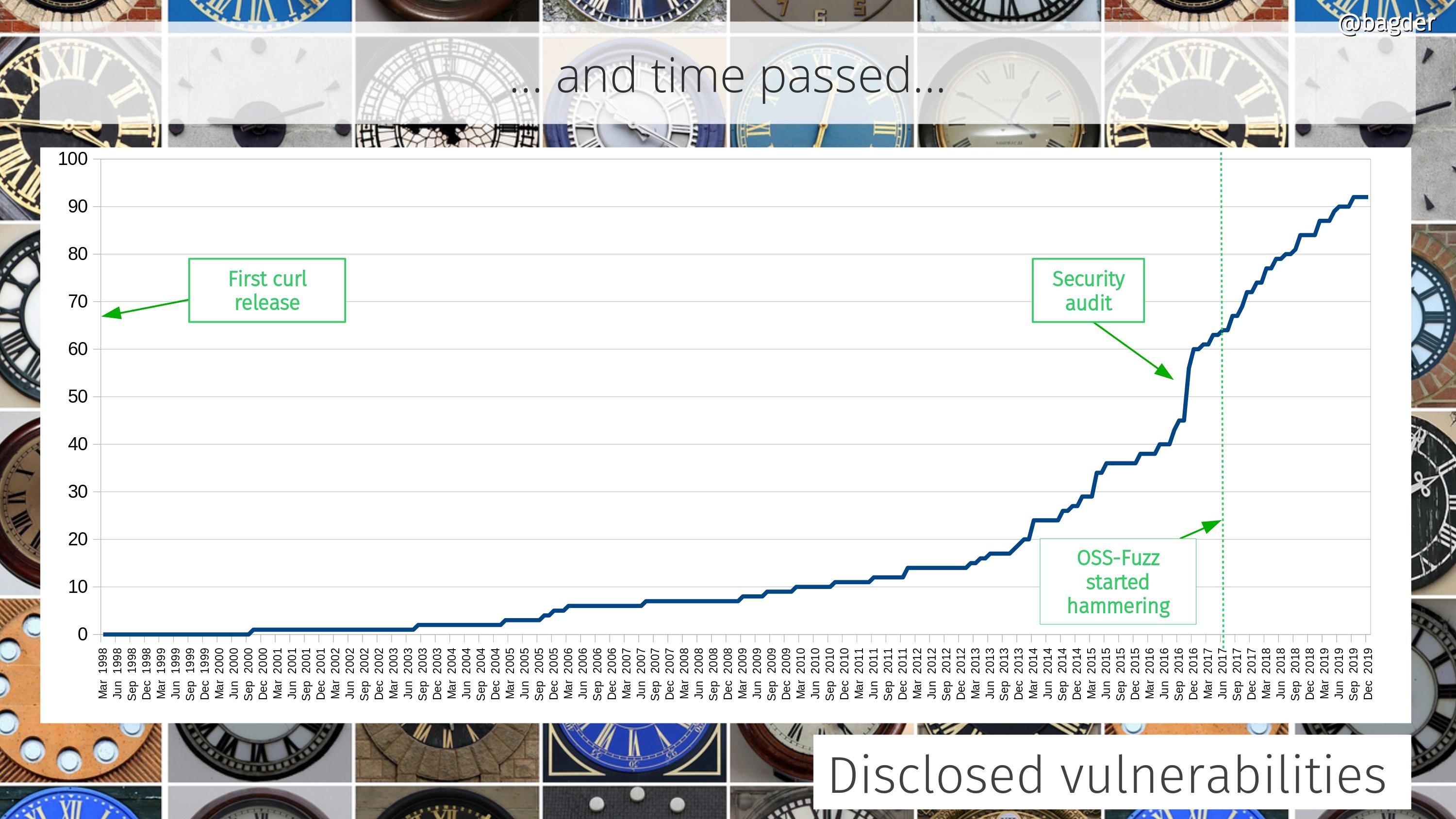
Number of disclosed vulnerabilities
We take security seriously and over time people have given us more attention and have spent more time digging deeper. These days we offer good monetary compensation for anyone who can find security flaws.
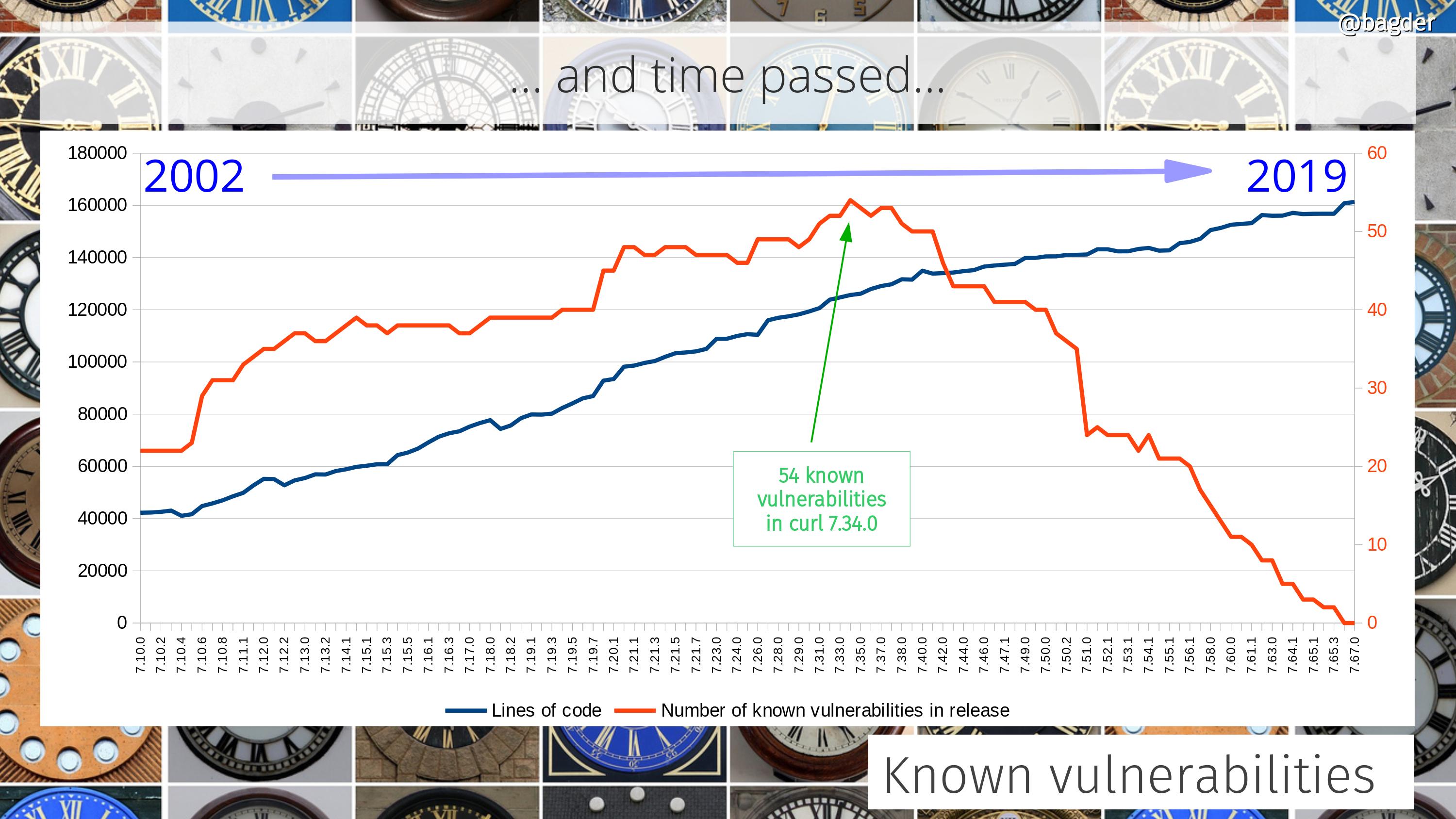
Number of known vulnerabilities
An attempt to visualize how many known vulnerabilities previous curl versions contain. Note that most of these problems are still fairly minor and some for very specific use cases or surroundings. As a reference, this graph also includes the number of lines of code in the corresponding versions.
More recent releases have less problems partly because we have better testing in general but also of course because they’ve been around for a shorter time and thus have had less time for people to find problems in them.
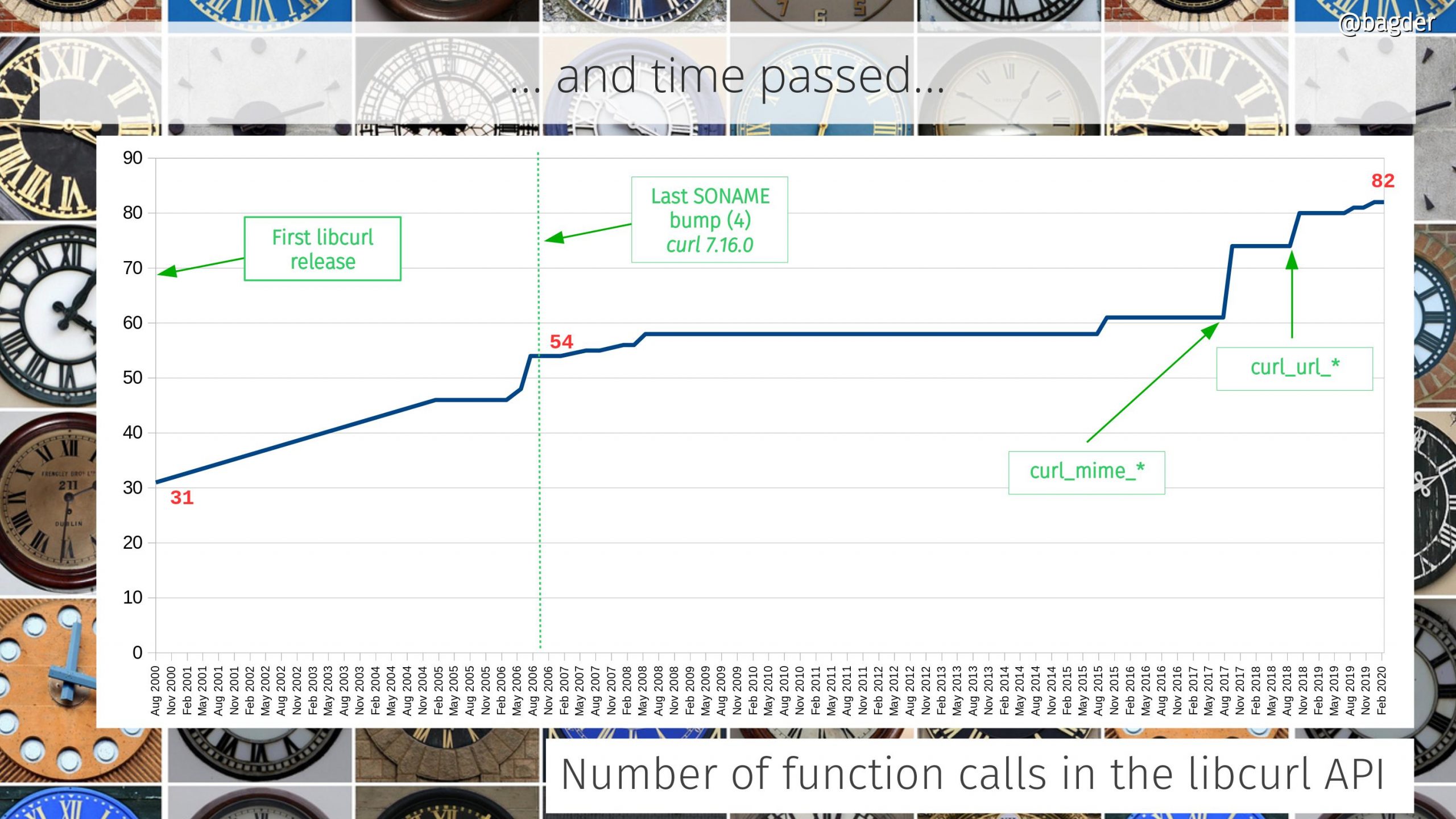
Number of function calls in the API
libcurl is an Internet transfer library and the number of provided function calls in the API has grown over time as we’ve learned what users want and need.
Anything that has been built with libcurl 7.16.0 or later you can always upgrade to a later libcurl and there should be no functionality change and the API and ABI are compatible. We put great efforts into make sure this remains true.
The largest API additions over the last few year are marked in the graph: when we added the curl_mime_* and the curl_url_* families. We now offer 82 function calls. We’ve added 27 calls over the last 14 years while maintaining the same soname (ABI version).
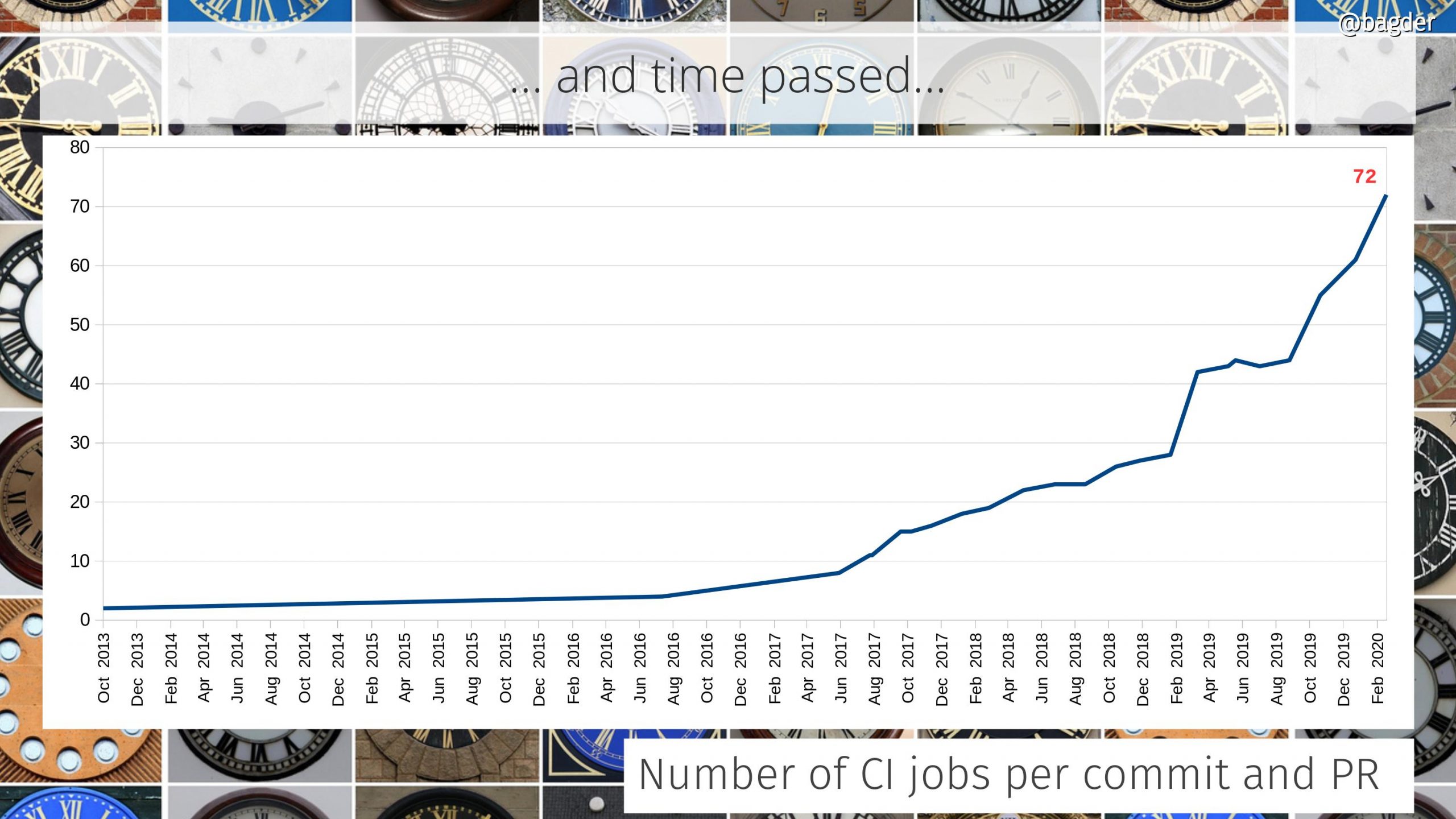
Number of CI jobs per commit and PR
We’ve had automatic testing in the curl project since the year 2000. But for many years that testing was done by volunteers who ran tests in cronjobs in their local machines a few times per day and sent the logs back to the curl web site that displayed their status.
The automatic tests are still running and they still provide value, but I think we all agree that getting the feedback up front in pull-requests is a more direct way that also better prevent bad code from ever landing.
The first CI builds were added in 2013 but it took a few more years until we really adopted the CI lifestyle and today we have 72, spread over 5 different CI services (travis CI, Appveyor, Cirrus CI, Azure Pipelines and Github actions). These builds run for every commit and all submitted pull requests on Github. (We actually have a few more that aren’t easily counted since they aren’t mentioned in files in the git repo but controlled directly from github settings.)
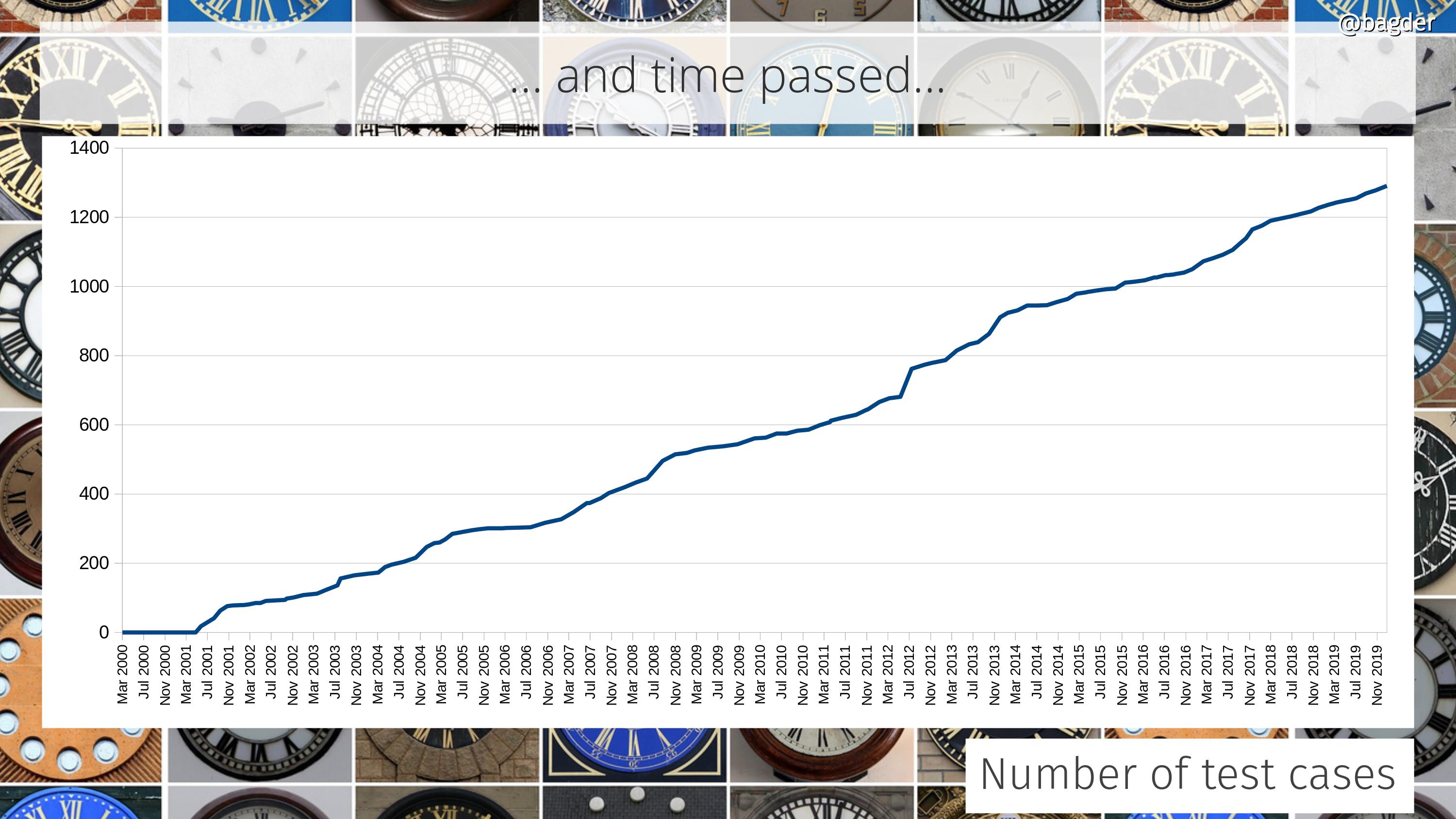
Number of test cases
A single test case can test a simple little thing or it can be a really big elaborate setup that tests a large number of functions and combinations. Counting test cases is in itself not really saying much, but taken together and looking at the change over time we can at least see that we continue to put efforts into expanding and increasing our tests. It should also be considered that this can be combined with the previous graph showing the CI builds, as most CI jobs also run all tests (that they can).
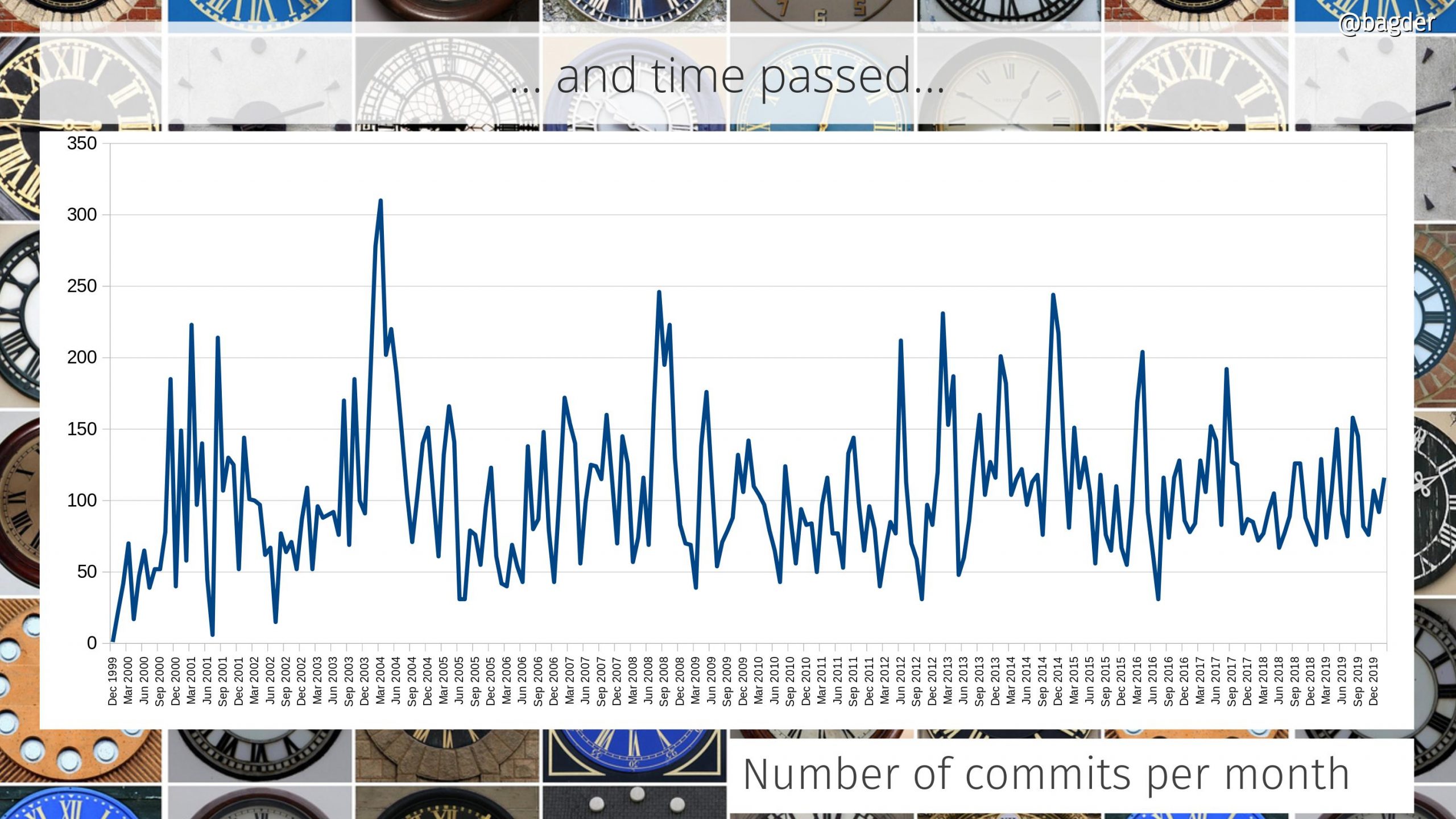
Number of commits per month
A commit can be tiny and it can be big. Counting a commit might not say a lot more than it is a sign of some sort of activity and change in the project. I find it almost strange how the number of commits per months over time hasn’t changed more than this!
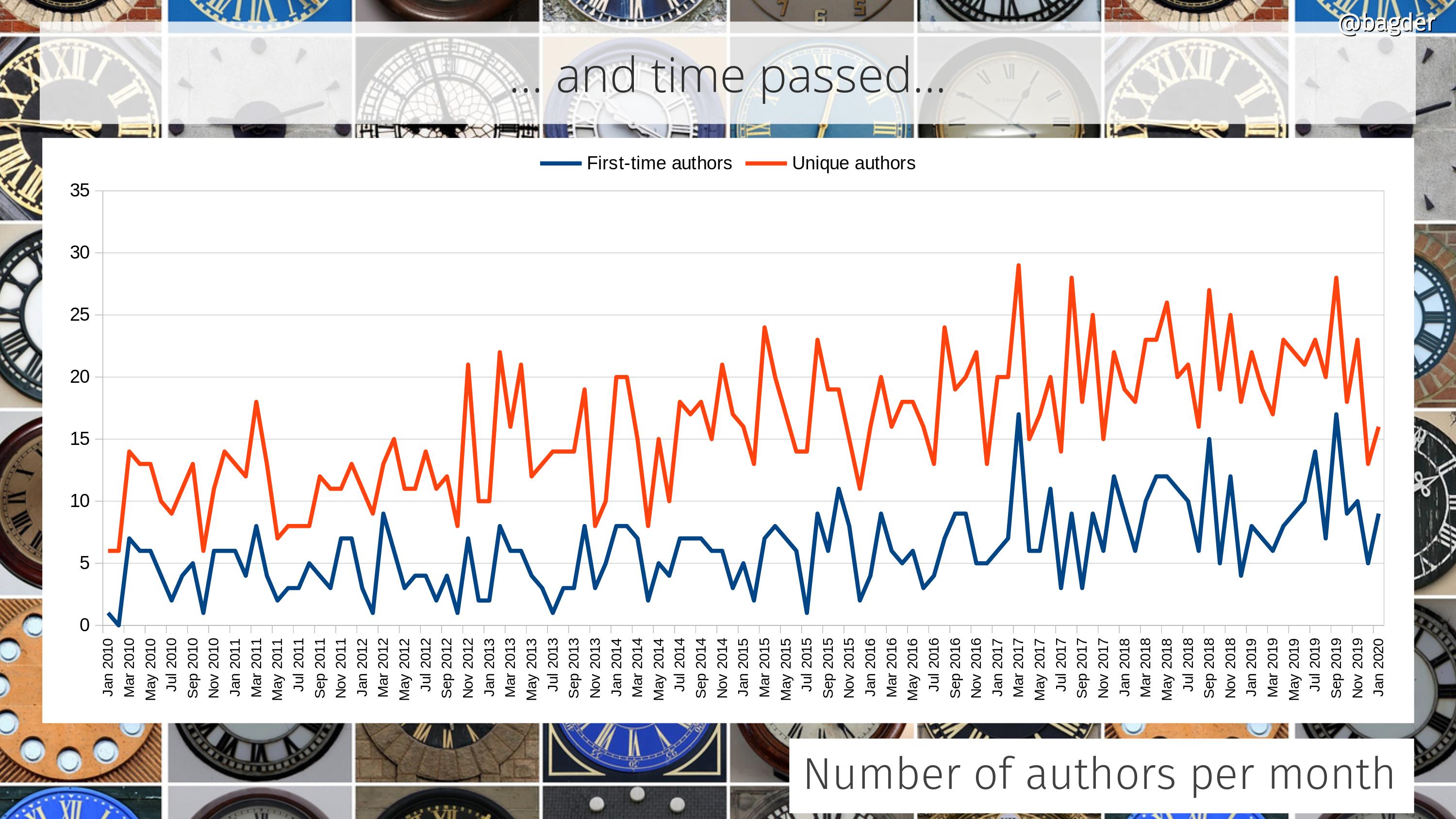
Number of authors per month
This shows number of unique authors per month (in red) together with the number of first-time authors (in blue) and how the amounts have changed over time. In the last few years we see that we are rarely below fifteen authors per month and we almost always have more than five first-time commit authors per month.
I think I’m especially happy with the retained high rate of newcomers as it is at least some indication that entering the project isn’t overly hard or complicated and that we manage to absorb these contributions. Of course, what we can’t see in here is the amount of users or efforts people have put in that never result in a merged commit. How often do we miss out on changes because of project inabilities to receive or accept them?
72 operating systems
Operating systems on which you can build and run curl for right now, or that we know people have ran curl on before. Most mortals cannot even list this many OSes off the top of their heads. If you know of any additional OS that curl has run on, please let me know!

20 CPU architectures
CPU architectures on which we know people have run curl. It basically runs on any CPU that is 32 bit or larger. If you know of any additional CPU architecture that curl has run on, please let me know!

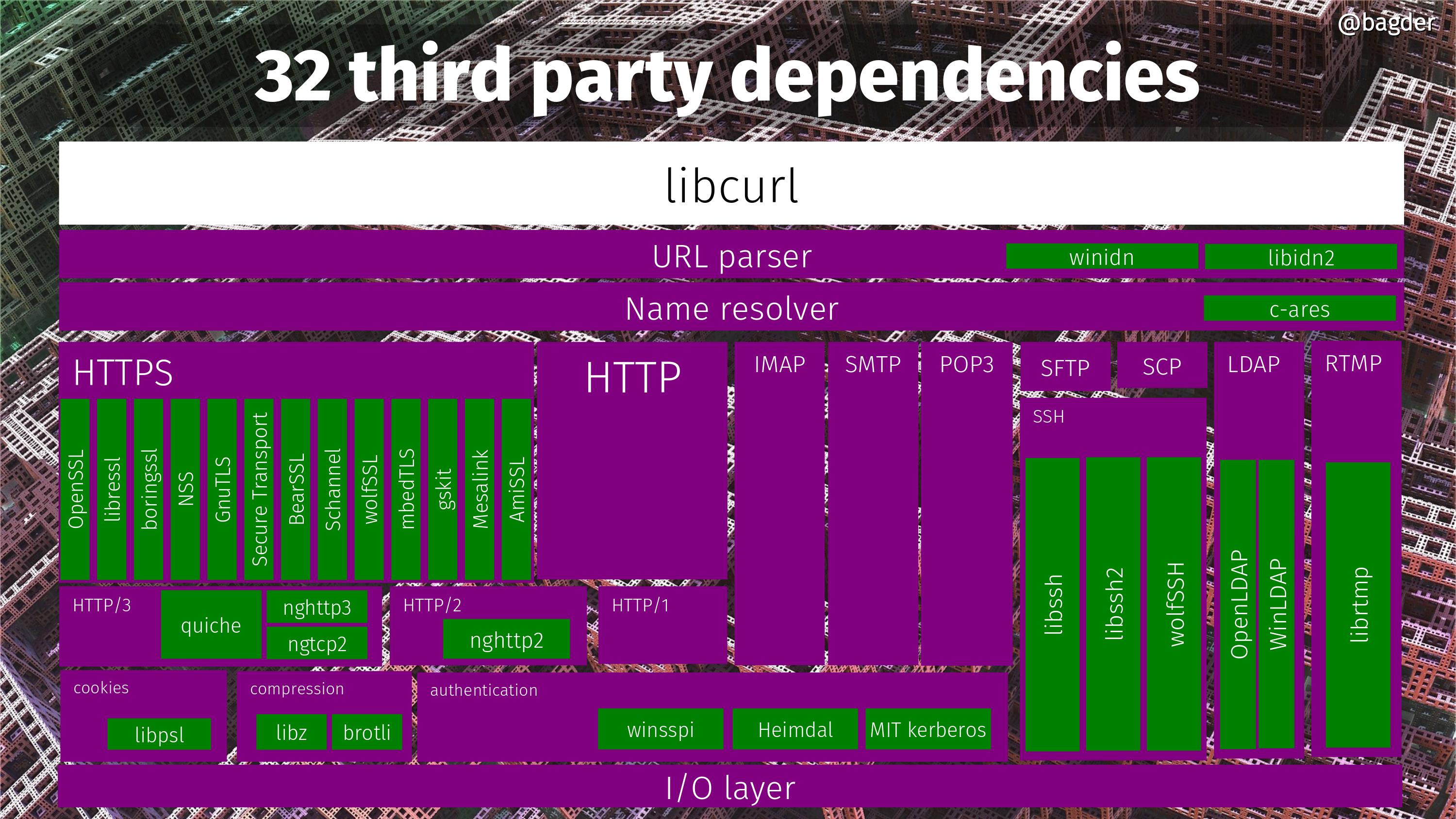
32 third party dependencies
Did I mention you can build curl in millions of combinations? That’s partly because of the multitude of different third party dependencies you can tell it to use. curl support no less than 32 different third party dependencies right now. The picture below is an attempt to some sort of block diagram and all the green boxes are third party libraries curl can potentially be built to use. Many of them can be used simultaneously, but a bunch are also mutually exclusive so no single build can actually use all 32.
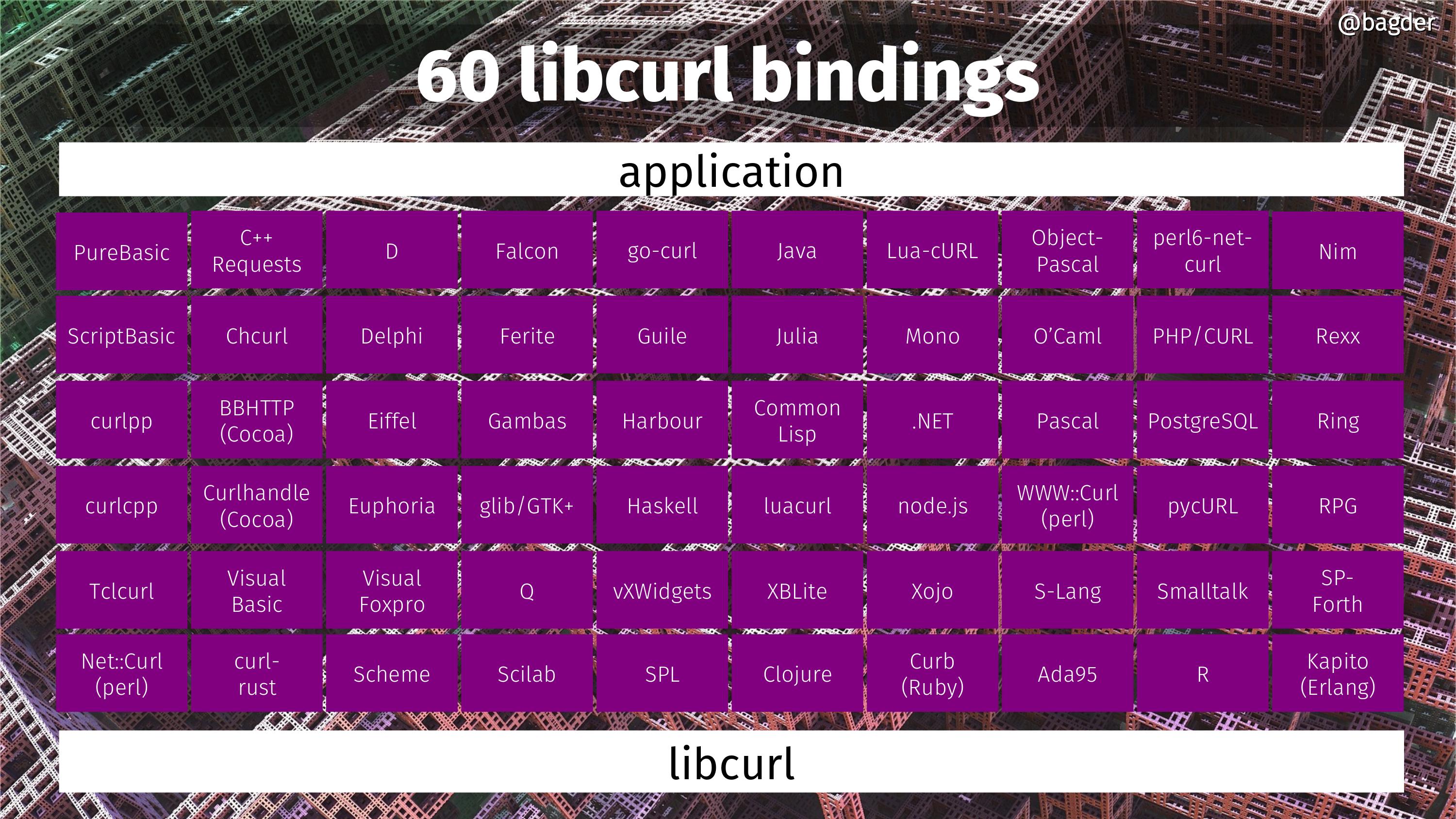
60 libcurl bindings
If you’re looking for more explanations how libcurl ends up being used in so many places, here are 60 more. Languages and environments that sport a “binding” that lets users of these languages use libcurl for Internet transfers.
Missing pictures
“number of downloads” could’ve been fun, but we don’t collect the data and most users don’t download curl from our site anyway so it wouldn’t really say a lot.
“number of users” is impossible to tell and while I’ve come up with estimates every now and then, making that as a graph would be doing too much out of my blind guesses.
“number of graphs in anniversary blog posts” was a contender, but in the end I decided against it, partly since I have too little data.
Future
Every anniversary is an opportunity to reflect on what’s next.
In the curl project we don’t have any grand scheme or roadmap for the coming years. We work much more short-term. We stick to the scope: Internet transfers specified as URLs. The products should be rock solid and secure. The should be high performant. We should offer the features, knobs and levers our users need to keep doing internet transfers now and in the future.
curl is never done. The development pace doesn’t slow down and the list of things to work on doesn’t shrink.
I enjoyed reading this. Loved your chartwork.
(Note some image links broken: Number of function calls in the API, Number of command line options, Number of commits per month.)
@Ray: thanks, I hope I’ve fixed those links now!
Maybe 2020 will be the year I learn to use curl instead of wget… Hmm
Your addiction to numerology is silly! What is next? Maybe transfer files with curl over port 22? 🙂
Hi! I want translate into Spanish this article: Have you considered use a Creative Commons License for it? Best regards from #Venezuela.
@Jimmy: feel free to do that. Thanks for the note about the license. I’ll work on making sure all original content I post here will be creative commons licensed.
Hi Daniel
I made a video of curl’s 20 years in a VCS with gource. The video is downloadable here :
http://src.delhomme.org/download/curl/curl-2000-to-2020-gource-video.ogg
Regards,
Olivier.
Admissions for the post but numerology will change next year 🙂