I trust you’ve heard by now that HTTP/3 is coming. It is the next destined HTTP version, targeted to get published as an RFC in July 2019. Not very far off.
HTTP/3 will not be done over TCP. It will only be performed over QUIC, which is a transport protocol replacement for TCP that always is done encrypted. There’s no clear-text version of QUIC.
TLS 1.3
The encryption in QUIC is based on TLS 1.3 technologies which I believe everyone thinks is a good idea and generally the correct decision. We need to successively raise the bar as we move forward with protocols.
However, QUIC is not only a transport protocol that does encryption by itself while TLS is typically (and designed as) a protocol that is done on top of TCP, it was also designed by a team of engineers who came up with a design that requires APIs from the TLS layer that the traditional TLS over TCP use case doesn’t need!
New TLS APIs
A QUIC implementation needs to extract traffic secrets from the TLS connection and it needs to be able to read/write TLS messages directly – not using the TLS record layer. TLS records are what’s used when we send TLS over TCP. (This was discussed and decided back around the time for the QUIC interim in Kista.)
These operations need APIs that still are missing in for example the very popular OpenSSL library, but also in other commonly used ones like GnuTLS and libressl. And of course schannel and Secure Transport.
Libraries known to already have done the job and expose the necessary mechanisms include BoringSSL, NSS, quicly, PicoTLS and Minq. All of those are incidentally TLS libraries with a more limited number of application users and less mainstream. They’re also more or less developed by people who are also actively engaged in the QUIC protocol development.
The QUIC libraries in progress now are typically using either one of the TLS libraries that already are adapted or do what ngtcp2 does: it hosts a custom-patched version of OpenSSL that brings the needed functionality.
Matt Caswell of the OpenSSL development team acknowledged this situation already back in September 2017, but so far we haven’t seen this result in updated code shipped in a released version.
curl and QUIC
curl is TLS library agnostic and can get built with around 12 different TLS libraries – one or many actually, as you can build it to allow users to select TLS backend in run-time!
OpenSSL is without competition the most popular choice to build curl with outside of the proprietary operating systems like macOS and Windows 10. But even the vendor-build and provided mac and Windows versions are also built with libraries that lack APIs for this.
With our current keen interest in QUIC and HTTP/3 support for curl, we’re about to run into an interesting TLS situation. How exactly is someone going to build curl to simultaneously support both traditional TLS based protocols as well as QUIC going forward?
I don’t have a good answer to this yet. Right now (assuming we would have the code ready in our end, which we don’t), we can’t ship QUIC or HTTP/3 support enabled for curl built to use the most popular TLS libraries! Hopefully by the time we get our code in order, the situation has improved somewhat.
This will slow down QUIC deployment
I’m personally convinced that this little API problem will be friction enough when going forward that it will slow down and hinder QUIC deployment at least initially.
When the HTTP/2 spec shipped in May 2015, it introduced a dependency on the fairly new TLS extension called ALPN that for a long time caused head aches for server admins since ALPN wasn’t supported in the OpenSSL versions that was typically installed and used at the time, but you had to upgrade OpenSSL to version 1.0.2 to get that supported.
At that time, almost four years ago, OpenSSL 1.0.2 was already released and the problem was big enough to just upgrade to that. This time, the API we’re discussing here is not even in a beta version of OpenSSL and thus hasn’t been released in any version yet. That’s far worse than the HTTP/2 situation we had and that took a few years to ride out.
Will we get these APIs into an OpenSSL release to test before the QUIC specification is done? If the schedule sticks, there’s about six months left…
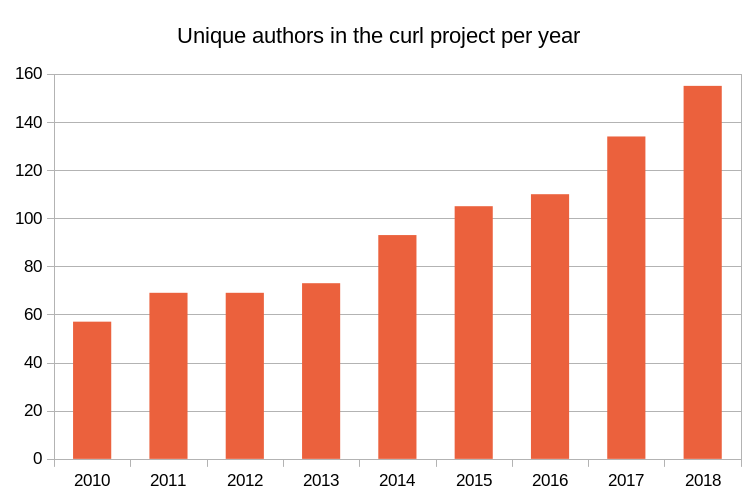
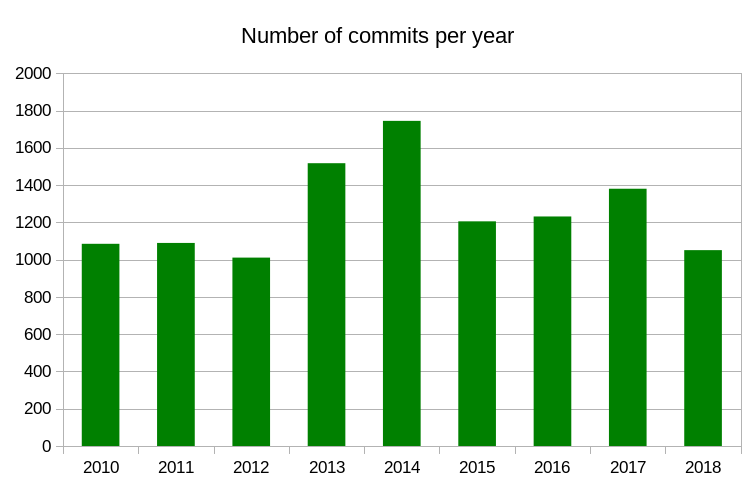
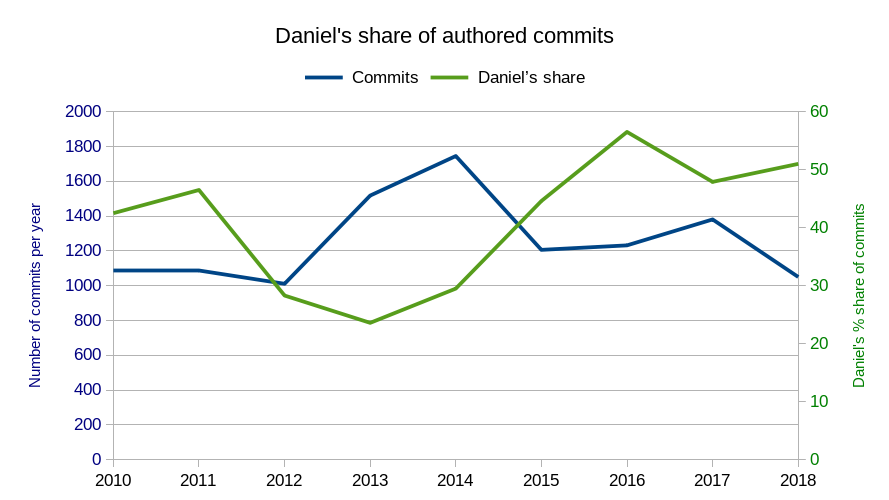
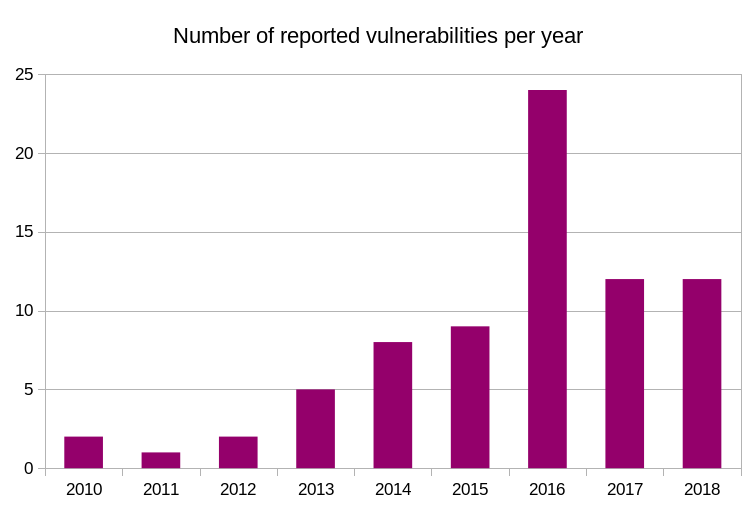




 It’s been
It’s been  I was involved in the IETF HTTPbis working group for many years before I joined Mozilla (for over ten years now!) and I hope to be involved for many years still. I still have a lot of things I want to do with curl and to keep curl the champion of its class I need to stay on top of the game.
I was involved in the IETF HTTPbis working group for many years before I joined Mozilla (for over ten years now!) and I hope to be involved for many years still. I still have a lot of things I want to do with curl and to keep curl the champion of its class I need to stay on top of the game.