Do you remember this exact day, twenty years ago? March 20, 1998. What exactly happened that day? I’ll tell you what I did then.
 First a quick reminder of the state of popular culture at the time: three days later, on the 23rd, the movie Titanic would tangent the record and win eleven academy awards. Its theme song “My heart will go on” was in the top of the music charts around this time.
First a quick reminder of the state of popular culture at the time: three days later, on the 23rd, the movie Titanic would tangent the record and win eleven academy awards. Its theme song “My heart will go on” was in the top of the music charts around this time.
I was 27 years old and I worked full-time as a software engineer, mostly with embedded systems. I had already been developing software as a profession for several years then. At this moment in time I was involved as a consultant in a (rather boring) project for Ericsson Telecom ETX, in Nacka Strand in the south eastern general Stockholm area.
At some point during that Friday (I don’t remember the details, but presumably it happened during the late evening), I packaged up the source code of the URL transfer tool we were working on and uploaded it to my personal web site to share it with the world. It was the first release ever of the project under the new name: curl. The tool was already supporting HTTP, FTP and GOPHER – including uploads for the two first protocols.
It would take more than a year after this day until we started hosting the curl project on its own dedicated web site. curl.haxx.nu went live in August 1999, and it was changed again to curl.haxx.se in June the following year, a URL and name we’ve kept since.
![]()
(this is the first curl logo we used, made in 1998 by Henrik Hellerstedt)
In my flat in Solna (just north of Stockholm, Sweden) I already then spent a lot of spare time, mostly late nights, in front of my computer. Back then, an Intel Pentium 120Mhz based desktop PC with a huge 19″ Nokia CRT monitor, on which I dialed up to my work’s modem pool to access the Internet and to log in to the Unix machines there on which I did a lot of the early curl development. On SunOS, Solaris and Linux.
In Stockholm, that Friday started out with sub-zero degrees Celsius but the temperature climbed up to a few positive degrees during the day and there was no snow on the ground. Pretty standard March weather in Stockholm. This is usually a period when the light is slowly coming back (winters are really dark here) but the temperatures remind us that spring still isn’t quite here.
curl 4.0 was just a little more than 2000 lines of C code. It featured 23 command line options. curl 4.0 introduced support for the FTP PORT command and now it could do ftp uploads that append to the remote file. The version number was bumped up from the 3.12 which was the last version number used by the tool under the old name, urlget.
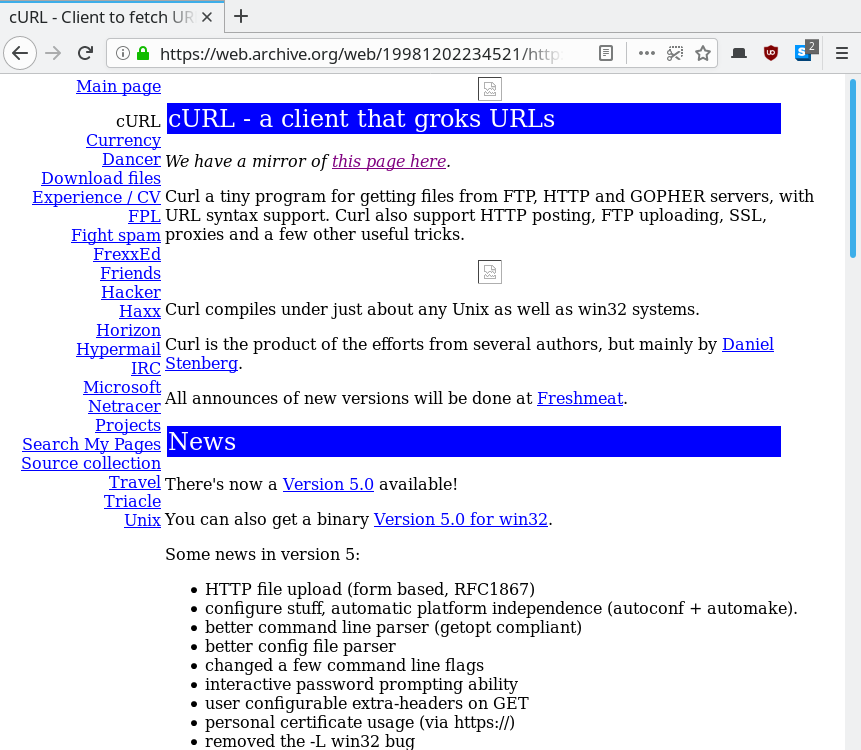
It was far from an immediate success. An old note mentions how curl 4.8 (released the summer of 1998) was downloaded more than 300 times from the site. In August 1999, we counted 1300 weekly visits on the web site. It took time to get people to discover curl and make it into the tool users wanted. By September 1999 curl had already grown to 15K lines of code
In August 2000 we shipped the first version of libcurl: all the networking transfer powers of curl in a library, ready to be used by your applications. PHP was one of the absolutely first users of libcurl and that certainly helped to drive the early use.
A year later, in August 2001, when Apple started shipping curl by default in Mac OS X 10.1 curl was already widely available in Linux and BSD package collections.
By June 2002, we counted 13000 weekly visits on the site and we had grown to 35K lines of code. And it would not stop there…
Twenty years is both nothing at all and at the same time what feels like an eternity. Just three weeks before curl 4.0 shipped, Mozilla was founded. Google wasn’t founded until six months after. This was long before Facebook or Twitter had even been considered. Certainly a different era. Even the term open source was coined just a month prior to this curl release.
Growth factors over 20 years in the project:
Supported protocols: 7.67x
Command line options: 9x
Lines of code: 75x
Contributors: 100x
Weekly web site visitors: 1,400x
End users using (something that runs) the code: 4,000,000x
Stickers with the curl logo: infinity
Twenty years since the first ever curl release. Of course, it took time to make that first release too so the work is older. curl is the third name or incarnation of the project that I first got involved with already in late 1996…