

In order to ship a quality product – once every eight weeks – we need lots of testing. This is what we do to test curl and libcurl.
checksrc
We have basic script that verifies that the source code adheres to our code standard. It doesn’t catch all possible mistakes, but usually it complains with enough details to help contributors to write their code to match the style we already use. Consistent code style makes the code easier to read. Easier reading makes less bugs and quicker debugging.
By doing this check with a script (that can be run automatically when building curl), it makes it easier for everyone to ship properly formatted code.
We have not (yet) managed to convince clang-format or other tools to reformat code to correctly match our style, and we don’t feel like changing it just for the sake of such a tool. I consider this a decent work-around.
make test
The test suite that we bundle with the source code in the git repository has a large number of tests that test…
- curl – it runs the command line tool against test servers for a large range of protocols and verifies error code, the output, the protocol details and that there are no memory leaks
- libcurl – we then build many small test programs that use the libcurl API and perform tests against test servers and verifies that they behave correctly and don’t leak memory etc.
- unit tests – we build small test programs that use libcurl internal functions that aren’t exposed in the API and verify that they behave correctly and generate the presumed output.
- valgrind – all the tests above can be run with and without valgrind to better detect memory issues
- “torture” – a special mode that can run the tests above in a way that first runs the entire test, counts the number of memory related functions (malloc, strdup, fopen, etc) that are called and then runs the test again that number of times and for each run it makes one of the memory related functions fail – and makes sure that no memory is leaked in any of those situations and no crash occurs etc. It runs the test over and over until all memory related functions have been made to fail once each.
Right now, a single “make test” runs over 1100 test cases, varying a little depending on exactly what features that are enabled in the build. Without valgrind, running those tests takes about 8 minutes on a reasonably fast machine but still over 25 minutes with valgrind.
Then we of course want to run all tests with different build options…
CI
For every pull request and for every source code commit done, the curl source is built for Linux, mac and windows. With a large set of different build options and TLS libraries selected, and all the tests mentioned above are run for most of these build combinations. Running ‘checksrc’ on the pull requests is of course awesome so that humans don’t have to remark on code style mistakes much. There are around 30 different builds done and verified for each commit.
If any CI build fails, the pull request on github gets a red X to signal that something was not OK.
We also run test case coverage analyses in the CI so that we can quickly detect if we for some reason significantly decrease test coverage or similar.
We use Travis CI, Appveyor and Coveralls.io for this.
Autobuilds
Independently of the CI builds, volunteers run machines that regularly update from git, build and run the entire test suite and then finally email the results back to a central server. These setups help us cover even more platforms, architectures and build combinations. Just with a little longer turn around time.
With millions of build combinations and support for virtually every operating system and CPU architecture under the sun, we have to accept that not everything can be fully tested. But since almost all code is shared for many platforms, we can still be reasonably sure about the code even for targets we don’t test regularly.
Static code analyzing
We run the clang scan-build on the source code daily and we run Coverity scans on the code “regularly”, about once a week.
We always address defects detected by these analyzers immediately when notified.
Fuzzing
We’re happy to be part of Google’s OSS-fuzz effort, which with a little help with integration from us keeps hammering our code with fuzz to make sure we’re solid.
OSS-fuzz has so far resulted in two security advisories for curl and a range of other bug fixes. It hasn’t been going on for very long and based on the number it has detected so far, I expect it to keep finding flaws – at least for a while more into the future.
Fuzzing is really the best way to hammer out bugs. When we’re down to zero detected static analyzer detects and thousands of test cases that all do good, the fuzzers can still continue to find holes in the net.
External
Independently of what we test, there are a large amount of external testing going on, for each curl release we do.
In a presentation by Google at curl up 2017, they mentioned their use of curl in “hundreds of applications” and how each curl release they adopt gets tested more than 400,000 times. We also know a lot of other users also have curl as a core component in their systems and test their installations extensively.
We have a large set of security interested developers who run tests and fuzzers on curl at their own will.
(image from pixabay)

 Unless the issue is critical, we prefer to schedule a fix and announcement of the issue in association with the pending next release, and as we do releases every 8 weeks like clockwork, that’s never very far away.
Unless the issue is critical, we prefer to schedule a fix and announcement of the issue in association with the pending next release, and as we do releases every 8 weeks like clockwork, that’s never very far away. we should introduce processes, tests and checks to make sure we detect other similar mistakes now and in the future.
we should introduce processes, tests and checks to make sure we detect other similar mistakes now and in the future. Unfortunately we don’t have any bug bounties on our own in the curl project. We simply have no money for that. We actually don’t have money at all for anything.
Unfortunately we don’t have any bug bounties on our own in the curl project. We simply have no money for that. We actually don’t have money at all for anything.


 I think the highest risk scenario is when users download pre-built curl or libcurl binaries from various places on the internet that isn’t the official curl web site. How can you know for sure what you’re getting then, as you couldn’t review the code or changes done. You just put your trust in a remote person or organization to do what’s right for you.
I think the highest risk scenario is when users download pre-built curl or libcurl binaries from various places on the internet that isn’t the official curl web site. How can you know for sure what you’re getting then, as you couldn’t review the code or changes done. You just put your trust in a remote person or organization to do what’s right for you. Some people argue that projects could or should pledge for every release that there’s no deliberate backdoor planted so that if the day comes in the future when a three-letter secret organization forces us to insert a backdoor, the lack of such a pledge for the subsequent release would function as an alarm signal to people that something is wrong.
Some people argue that projects could or should pledge for every release that there’s no deliberate backdoor planted so that if the day comes in the future when a three-letter secret organization forces us to insert a backdoor, the lack of such a pledge for the subsequent release would function as an alarm signal to people that something is wrong.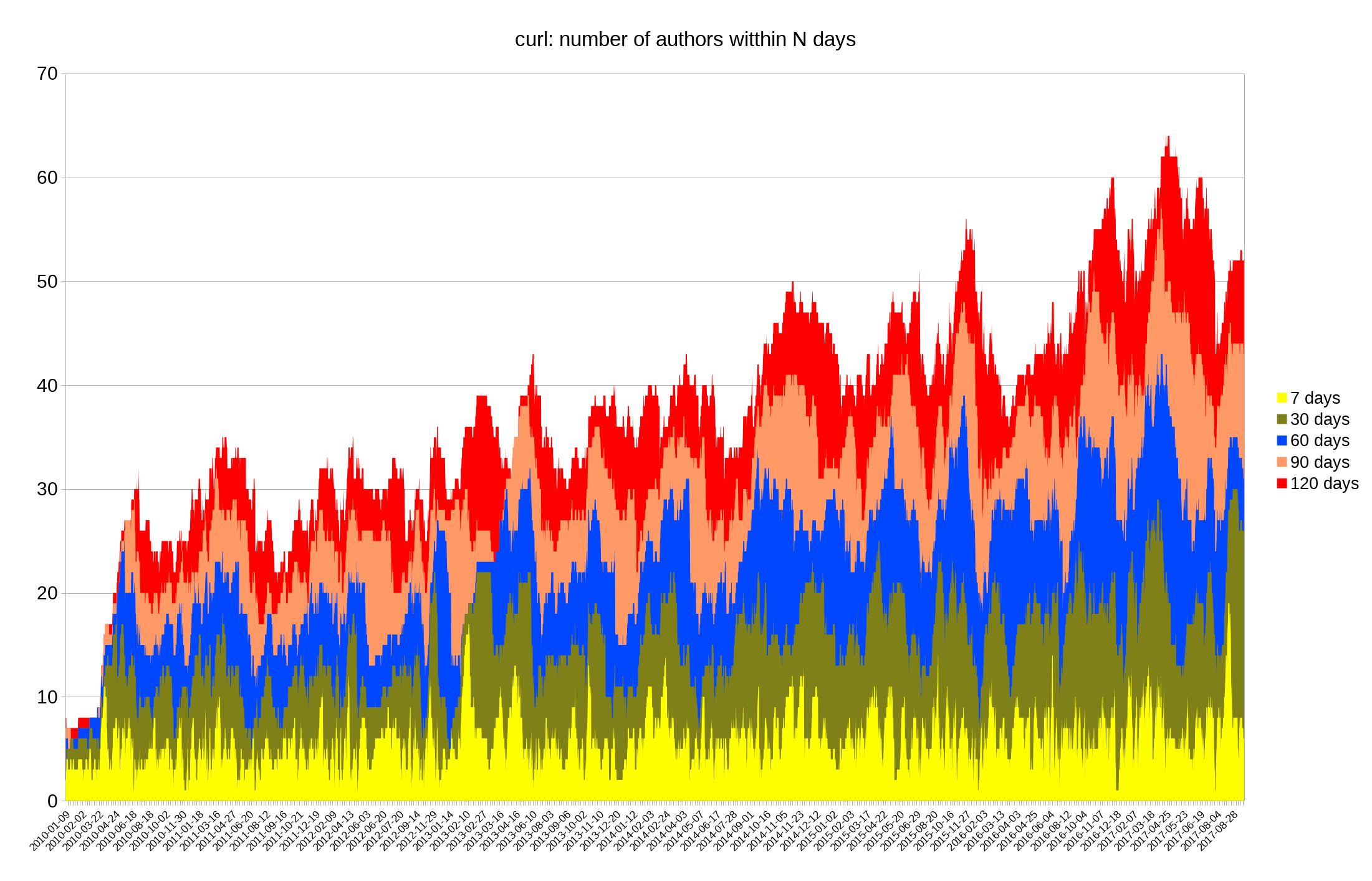

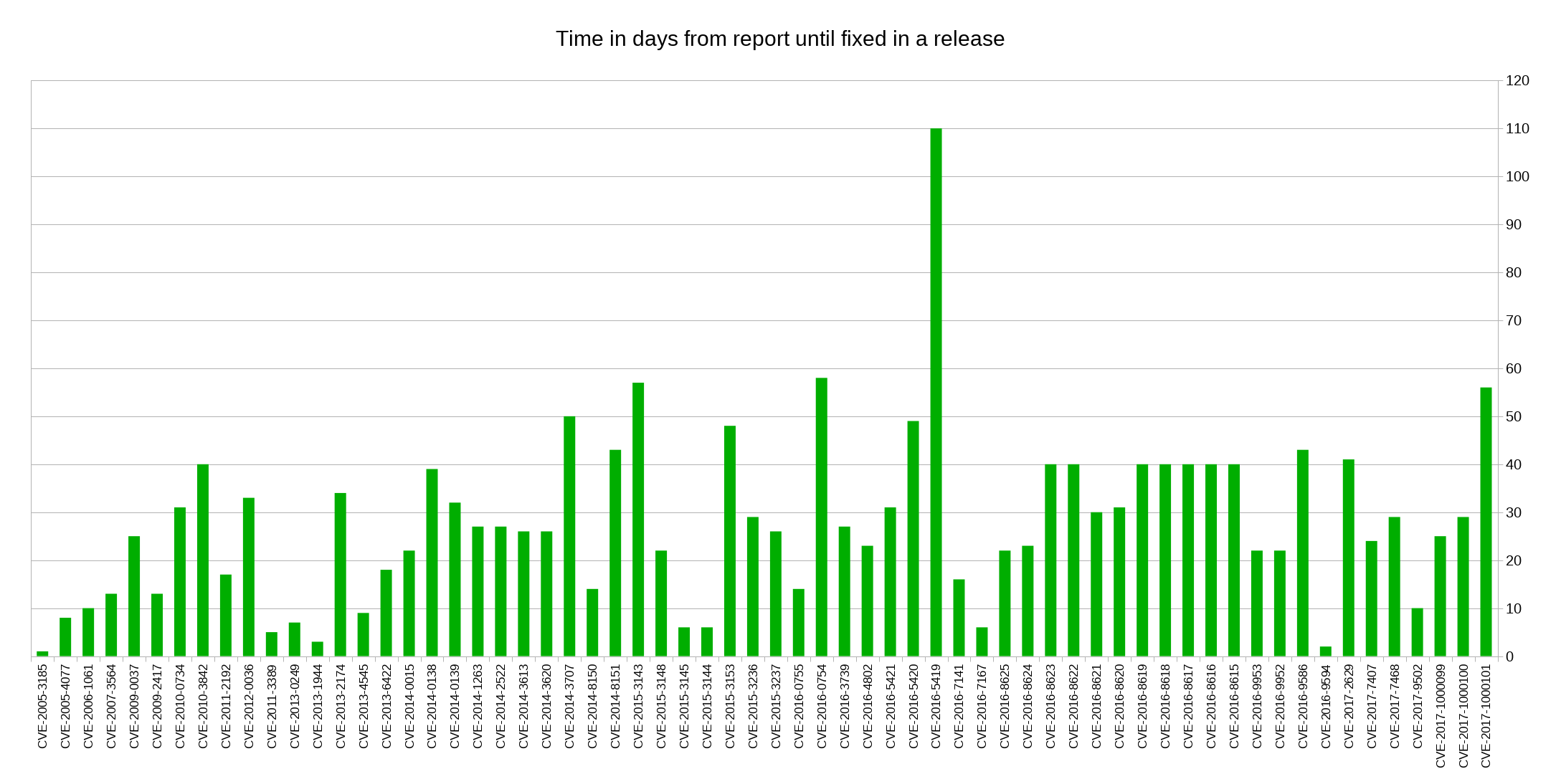
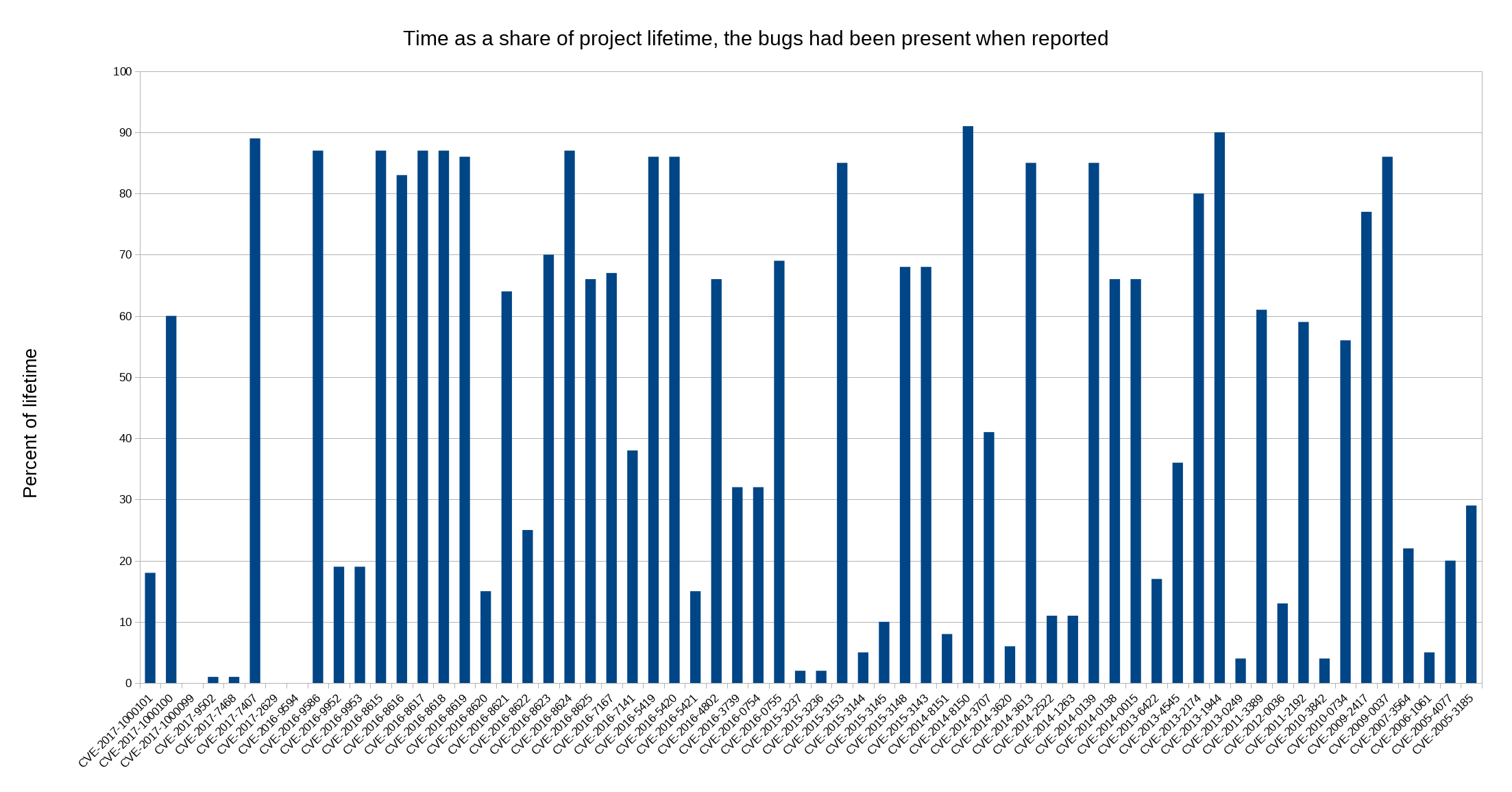
 I decided to look closer at security problems and the age of the reported issues in
I decided to look closer at security problems and the age of the reported issues in 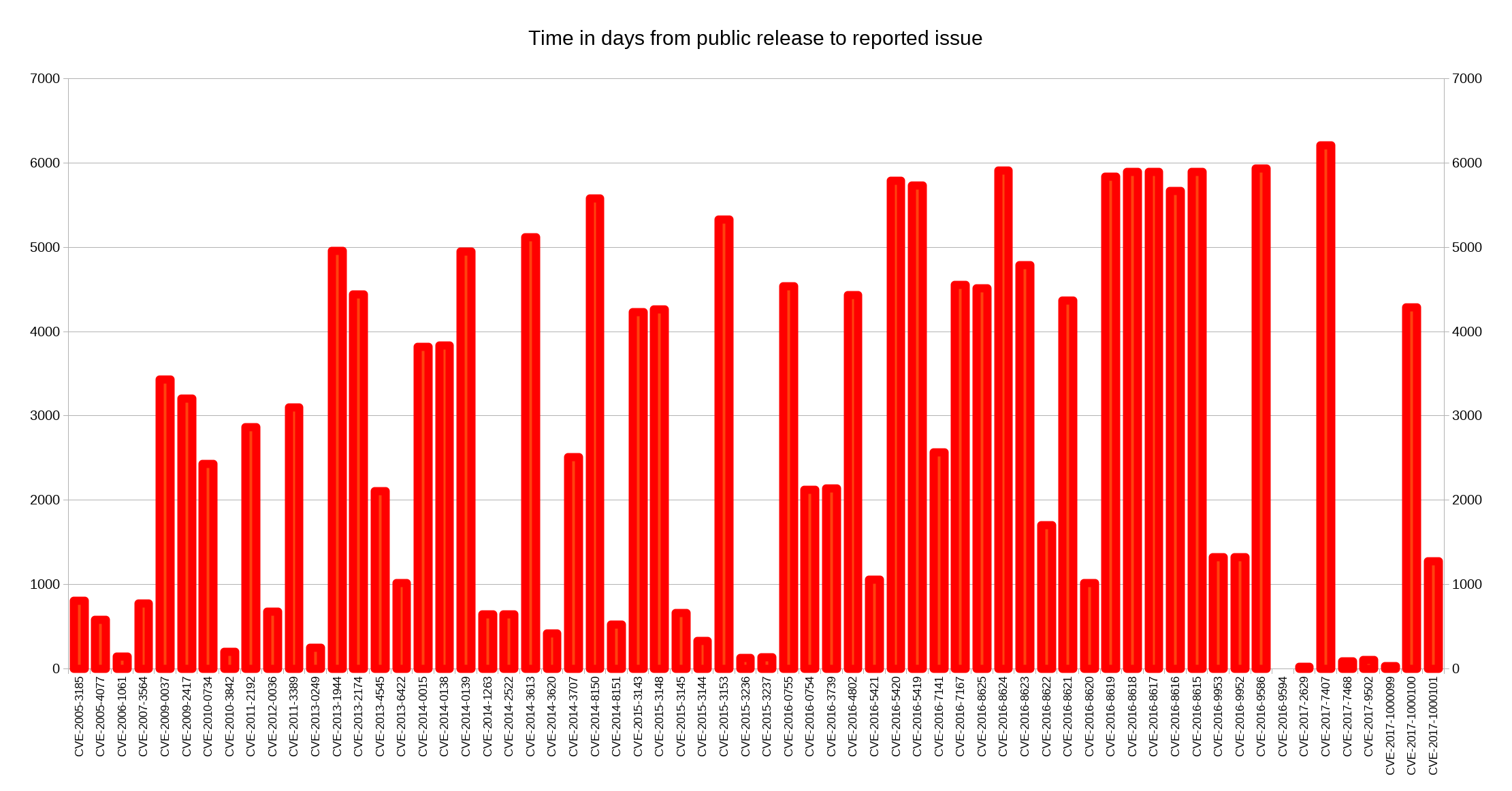



 The lady who delivered this message to me this early Monday morning, worked behind the check-in counter at the Arlanda airport. I was there, trying to check-in to my two-leg trip to San Francisco to the Mozilla “all hands” meeting of the summer of 2017. My chance for a while ahead to meet up with colleagues from all around the world.
The lady who delivered this message to me this early Monday morning, worked behind the check-in counter at the Arlanda airport. I was there, trying to check-in to my two-leg trip to San Francisco to the Mozilla “all hands” meeting of the summer of 2017. My chance for a while ahead to meet up with colleagues from all around the world. Mark Nottingham
Mark Nottingham