

(Clearly a much better word than simplification.)
I believe we generally accept the truth that we should write simple and easy to read code in order to make it harder to create bugs and cause security problems. The more complicated code we write, the easier it gets to slip up, misunderstand or forget something along the line.
And yet, at the same time, over time functions tend to grow and become more and more complicated as we address edge cases and add new funky features we did not anticipate when we first created the code many decades ago.
Complexity
Cyclomatic complexity is a metric used to indicate the complexity of a program. You can click the link there and read all the fine details, but it boils down to: a higher number means a more complex function. A function that contains many statements and code paths.
There is this fine old command line tool called pmccabe that is able to scan C code and output a summary of all functions and their corresponding complexity scores.
Invoking this tool on your own C code is a perfect way to get a toplist of functions possibly in need of refactor. While of course the idea of what a complex function is and exactly how to count the score is not entirely objective, I believe this method works to a decently sufficient degree.
curl
Last year I created a graph to the curl dashboard that shows the complexity scores of the worst function in curl as well as the 99th percentile. Later, I also added a plot for 90th percentile.
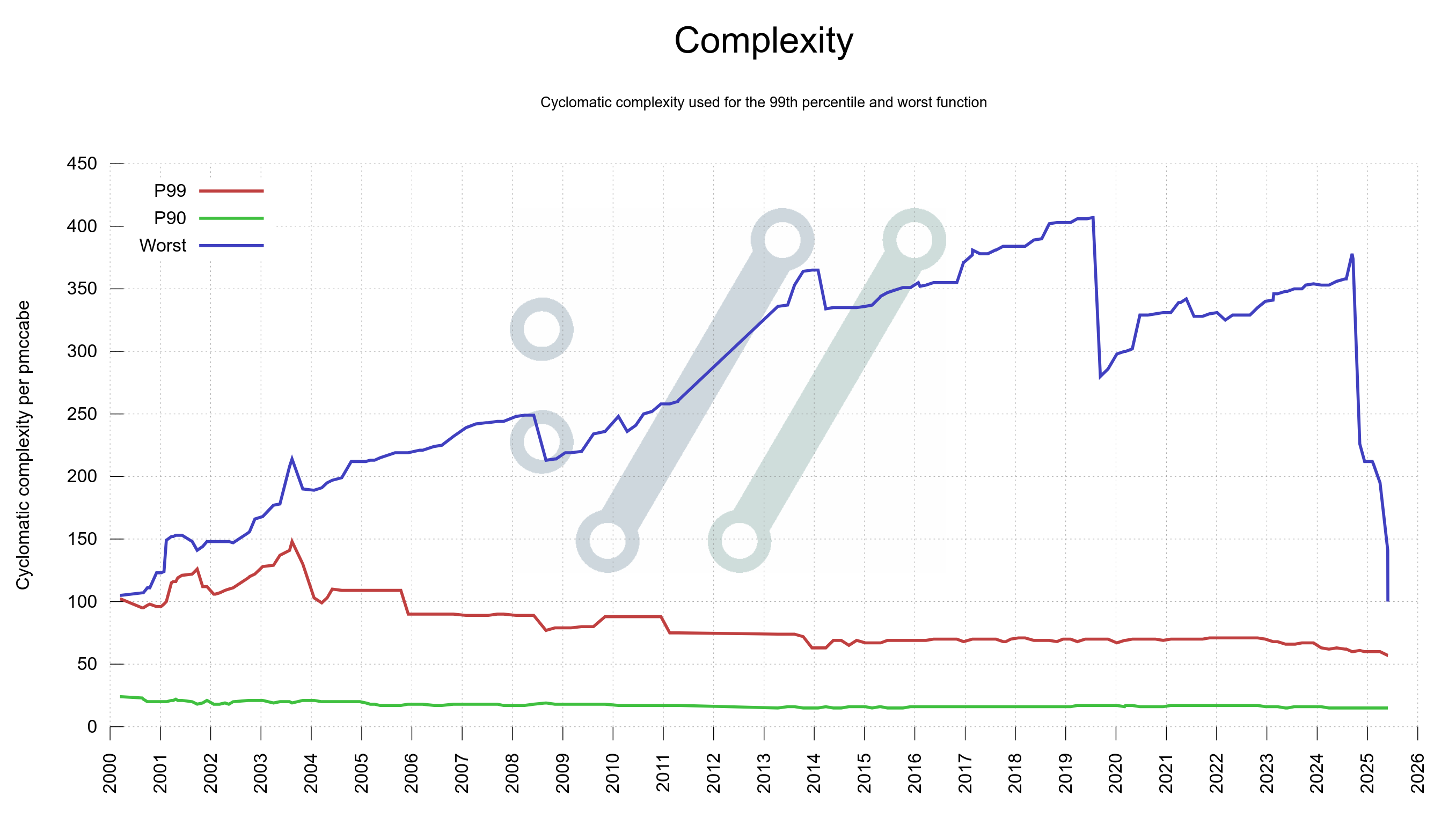
This graph shows how the worst complexity in curl has shifted over time – and like always when there is a graph or you measure something – suddenly we get the urge to do something about the bad look of that graph. Because it looked bad.
The worst
I grabbed my scalpel and refactored a few of the most complex functions we had, and I basically halved the complexity score of the worst-in-curl functions. The steep drop at the right side of the graph felt nice.
I left the state there then for a while, quite pleased with having at least improved the state of things.
A few months later I returned back to the topic. I figured we could do more as the worst was still quite bad. We should have a goal set to extinguish (improve really) all functions in the curl code with a score higher than N.
A goal
In my mail to the team I proposed the acceptable complexity limit to be 100, which is not super aggressive. When I sent the email, there were seven functions ranked over 100 and the worst offender scored 196. After all, only a couple of months earlier, the worst function had scored over 350.
Maybe we could start with 100 as a max and lower it going forward if that works?
To get additional visualization of the curl code complexity (and ideally how we improve the situation) I also created two more graphs for the dashboard.
Graph complexity distribution
The first one gets the function’s complexity score for every line of source code and then shows how large percentage of the source code that has which complexity scores. The ideal of course being that almost the entire thing should have low scores.

This graph shows 100% of the source code, independent of its size at any given time because I think that is what is relevant: the complexity distribution at any particular point in time independent of the size. The size of the code has grown almost linearly all through the period this graph shows, so of course 50% of the code in 2010 was much less code than what 50% is today.
This graph shows how we have had periods of quite a lot of code with complexity over 200 and that today we finally have erased all complexity above 100. It’s a little hard to see in the graph, but the yellow field goes all the way up as of May 28 2025.
Graph average complexity
The second graph would get the same complexity score per source code line, and then calculate the average complexity score of all lines of code at that point in time. Ideally, that line should shrink over time.
It now shows a rather steep drop in mid 2025 after our latest efforts. The average complexity has more than halved since 2022.

Analyzers like it too
Static code analyzers also get better results and fewer false positives when they get to work with smaller and simpler functions. It too helps produce better code.
Refactors could shake things up
Of course, refactoring a complex function into several smaller and simpler functions can be anywhere from straight forward to quite complicated. A refactor in the name of simplification that might be hard. An oxymoron and one that of course might shake things up and could potentially rather add bugs than fix them.
Doing this of course needs to be done with care and there needs to be a solid test suite around the functions to validate that most of the functionality is still there and with the same behavior as before the refactor.
Function length
The most complex functions are also the longest, as there is a strong correlation. For that reason, I also produce a graph for the worst and the 99th percentile function lengths used in curl source code.
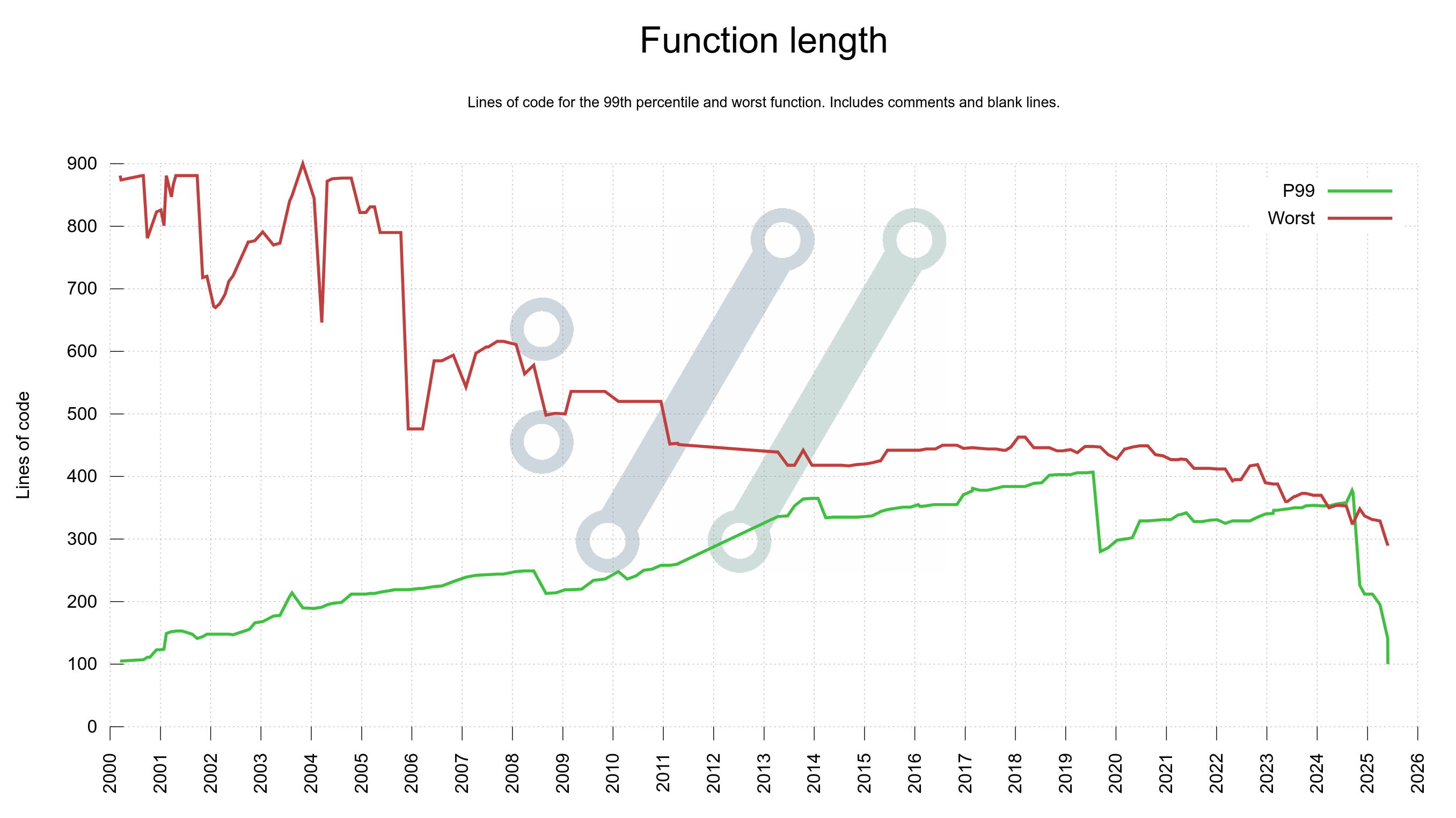
(something is wrong in this graph, as the P99 cannot be higher than the worst but the plot seems to indicate it was that in late 2024?)
A CI job to keep us honest
To make absolutely sure not a single function accidentally increases complexity above the permitted level in a pull-request, we created a script that makes a CI job turn red if any function goes over 100 in the complexity check. It is now in place. Maybe we can lower the limit going forward?
Towards the goal
The goal is not so much a goal as a process. An attempt to make us write simpler code, which in turn should help us write better and more secure code. Let’s see where we are in ten years!
As of this writing, here is the toplist of the most complex functions in curl right now. The ones with scores over 70:
100 lib/vssh/libssh.c:myssh_statemach_act
99 lib/setopt.c:setopt_long
92 lib/urlapi.c:curl_url_get
91 lib/ftplistparser.c:parse_unix
88 lib/http.c:http_header
83 src/tool_operate.c:single_transfer
80 src/config2setopts.c:config2setopts
79 lib/setopt.c:setopt_cptr
79 lib/vtls/openssl.c:cert_stuff
75 src/tool_cb_wrt.c:tool_write_cb
73 lib/socks.c:do_SOCKS5
72 lib/vssh/wolfssh.c:wssh_statemach_act
71 lib/vtls/wolfssl.c:Curl_wssl_ctx_init
71 lib/rtsp.c:rtsp_do
71 lib/socks_sspi.c:Curl_SOCKS5_gssapi_negotiate
This is just a snapshot of the moment. I hope things will continue to improve going forward. If even a little slower perhaps as we now have fixed all the most terrible cases.
Everything is public
All the scripts for this, the graphs shown, and the data behind them all are of course publicly available.