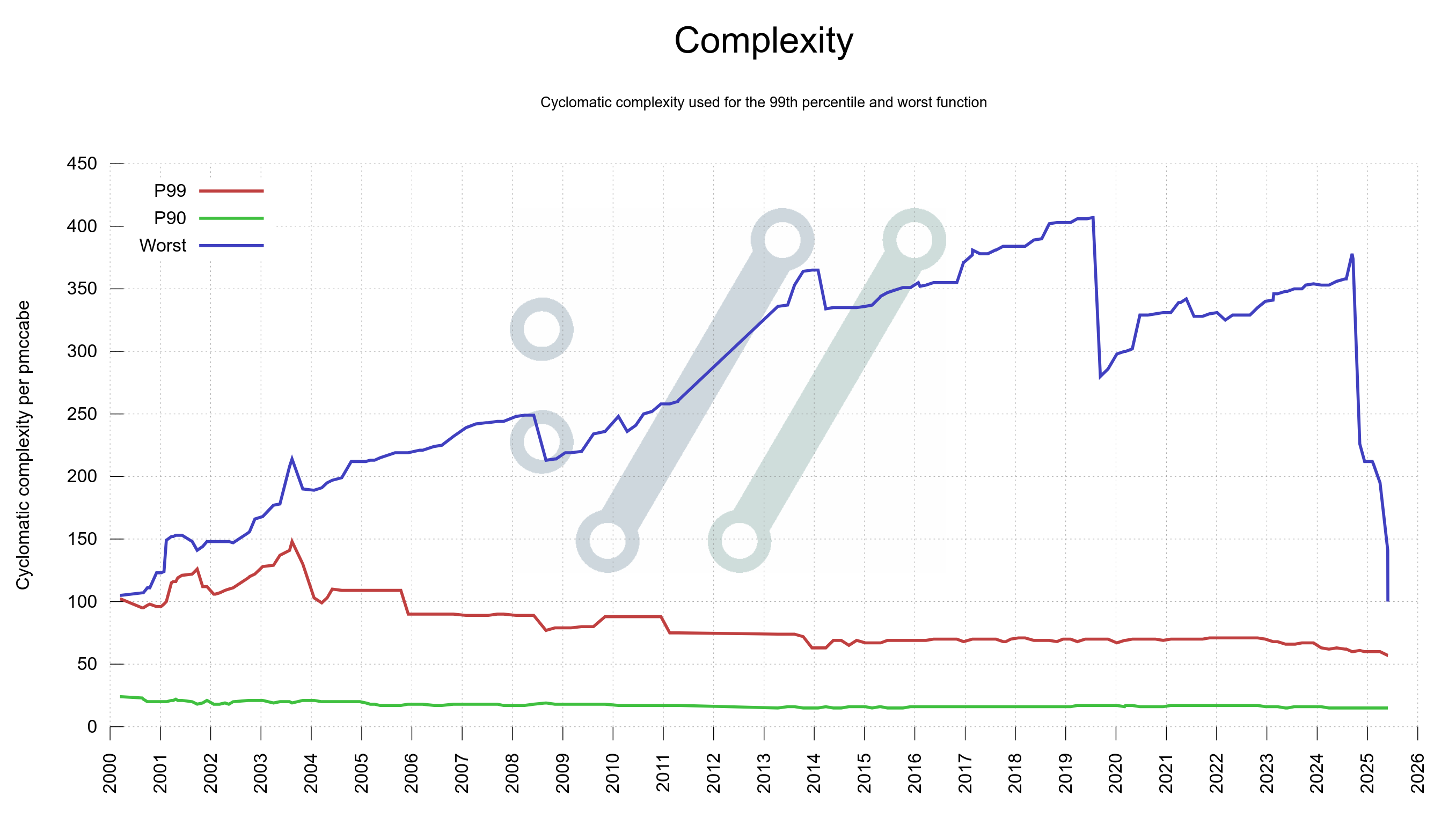
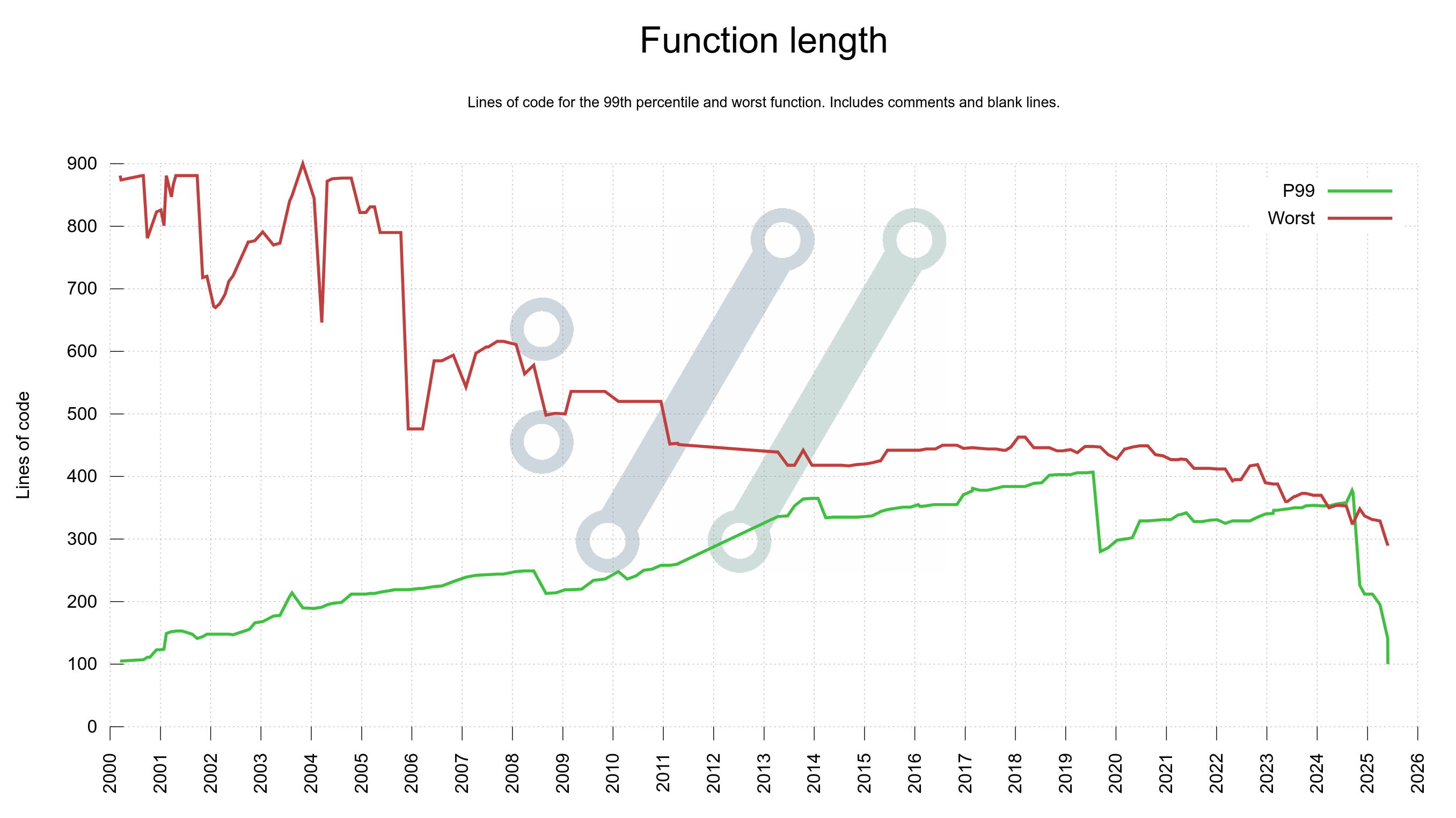
curl supports getting built with eleven different TLS libraries. Six of these libraries are OpenSSL or forks of OpenSSL. Allow me to give you a glimpse of their differences, similarities and some insights into what it takes to support them all.
SSLeay
It all started with SSLeay. This was the first SSL library I found out to exist and we added the first HTTPS support to curl using this library in the spring of 1998. Apparently the SSLeay project was started already back in 1995.
This was back in the days we still only had SSL; TLS would come later.
OpenSSL
This project was created (forked) from the ashes of SSLeay in late 1998 and curl supported it already from its start. SSLeay was abandoned.
OpenSSL always had a quirky, inconsistent and extremely large API set (a good chunk of that was inherited from SSLeay), that is further complicated by documentation that is sparse at best and leaves a lot to the users’ imagination and skill to dig through source code to get the last details answered (still today in 2025). In curl we keep getting occasional problems reported with how we use this library even decades in. Presumably this is the same for every OpenSSL user out there.
The OpenSSL project is often criticized for having dropped the ball on performance since they went to version 3 a few years back. They have also been slow and/or unwilling at adopt new TLS technologies like for QUIC and ECH.
In spite of all this, OpenSSL has become a dominant TLS library especially in Open Source.
LibreSSL
Back in the days of Heartbleed, the LibreSSL forked off and became its own. They trimmed off things they think didn’t belong in the library, they created their own TLS library API and a few years in, Apple ships curl on macOS using LibreSSL. They have some local patches on their build to make it behave differently than others.
LibreSSL was late to offer QUIC, they don’t support SSLKEYLOGFILE, ECH and generally seem to be even slower than OpenSSL to implement new things these days.
curl has worked perfectly with LibreSSL since it was created.
BoringSSL
Forked off by Google in the Heartbleed days. Done by Google for Google without any public releases they have cleaned up the prototypes and variable types a lot, and were leading the QUIC API push. In general, most new TLS inventions have since been implemented and supported by BoringSSL before the other forks.
Google uses this in Android and other places.
curl has worked perfectly with BoringSSL since it was created.
AmiSSL
A fork or flavor of OpenSSL done for the sole purpose of making it build and run properly on AmigaOS. I don’t know much about it but included it here for completeness. It seems to be more or less a port of OpenSSL for Amiga.
curl works with AmiSSL when built for AmigaOS.
QuicTLS
As OpenSSL dragged their feet and refused to provide the QUIC API the other forks did back in the early 2020s (for reasons I have yet to see anyone explain), Microsoft and Akamai forked OpenSSL and produced QuicTLS which has since tried to be a light-weight fork that mostly just adds the QUIC API in the same style BoringSSL and LibreSSL support it. Light-weight in the meaning that they were tracking upstream closely and did not intend to deviate from that in other ways than the QUIC API.
With OpenSSL3.5 they finally shipped a QUIC API that is different than the QUIC API the forks (including QuicTLS) provide. I believe this triggered QuicTLS to reconsider their direction going forward but we are still waiting to see exactly how. (Edit: see below for a comment from Rich Salz about this.)
curl has worked perfectly with QuicTLS since it was created.
AWS-LC
This is a fork off BoringSSL maintained by Amazon. As opposed to BoringSSL, they do actual (frequent) releases and therefore seem like a project even non-Amazon users could actually use and rely on – even though their stated purpose for existing is to maintain a secure libcrypto that is compatible with software and applications used at AWS. Strikingly, they maintain more than “just” libcrypto though.
This fork has shown a lot of activity recently, even in the core parts. Benchmarks done by the HAProxy team in May 2025 shows that AWS-LC outperforms OpenSSL significantly.
The API AWS-LC offers is not identical to BoringSSL’s.
curl works perfectly with AWS-LC since early 2023.
Family Tree
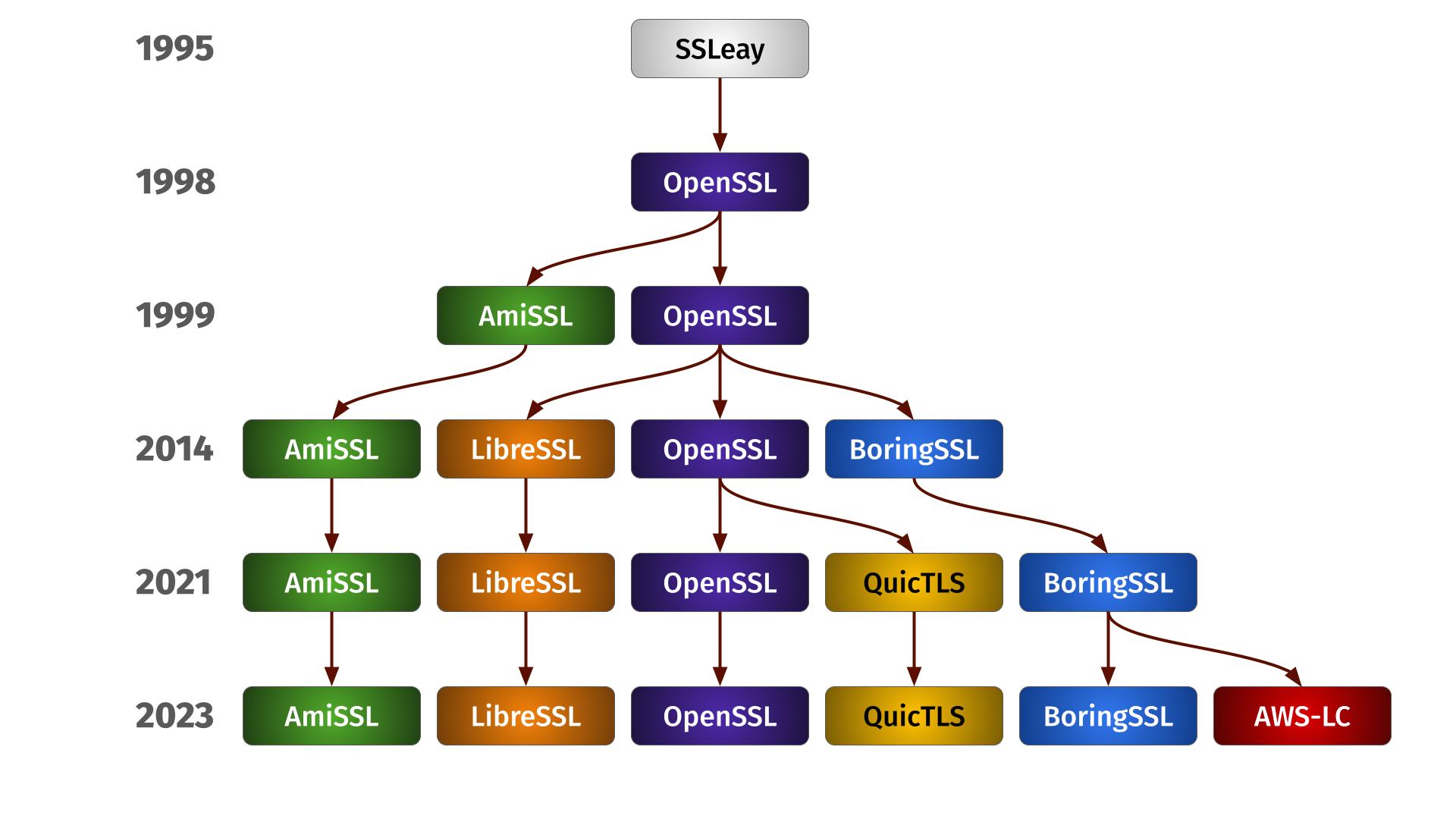
The family life
Each of these six different forks has its own specifics, APIs and features that also change and varies over their different versions. We remain supporting these six forks for now as people still seem to use them and maintenance is manageable.
We support all of them using the same single source code with an ever-growing #ifdef maze, and we verify builds using the forks in CI – albeit only with a limited set of recent versions.
Over time, the forks seem to be slowly drifting apart more and more. I don’t think it has yet become a concern, but we are of course monitoring the situation and might at some point have to do some internal refactors to cater for this.
Future
I can’t foresee what is going to happen. If history is a lesson, we seem to rather go towards more forks rather than fewer, but every reader of this blog post of course now ponders over how much duplicated efforts are spent on all these forks and the implied inefficiencies of that. On the libraries themselves but also on users such as curl.
I suppose we just have to wait and see.