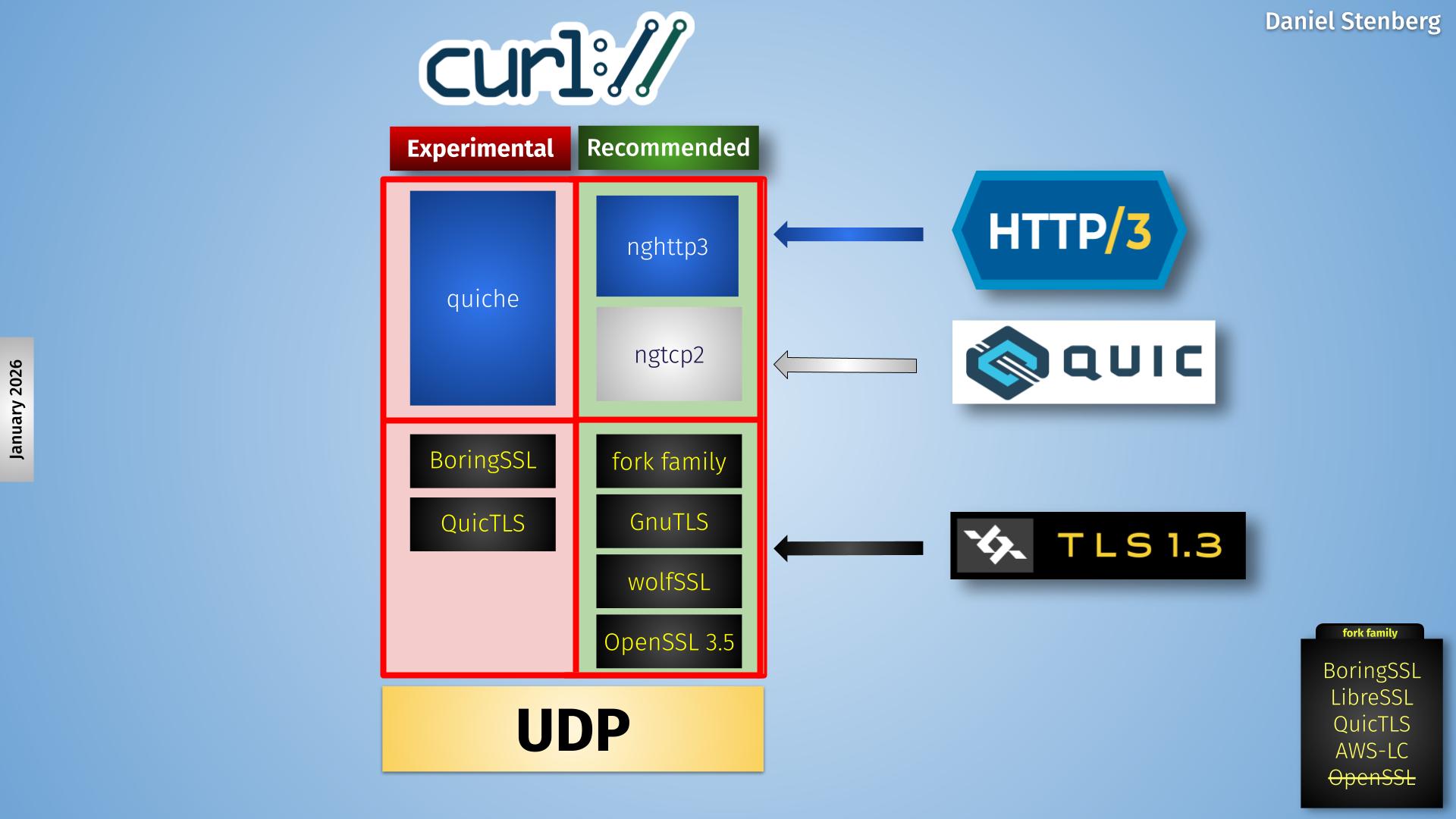
In the curl project we have a long tradition of offering multiple optional backends for specific protocols. In this spirit we have added experimental support for a number of different HTTP/3 + QUIC backends over time. A while ago we dropped one of those experiments, the msh3 backend.
Today we cleanup even more and remove support for yet another backend: the OpenSSL-QUIC stack and we are now down to only supporting two different HTTP/3 alternatives: the ngtcp2 + nghttp3 combo or quiche. And out of those two, the quiche backend is still considered experimental.
The first release shipping with this change will be curl 8.19.0.
OpenSSL-QUIC
This is the QUIC stack implemented and provided by OpenSSL. To make matters a little complicated, this is a separate thing from the QUIC API that OpenSSL also offers. The first one is a full QUIC implementation, the second one is an API that is powerful enough to allow a separate QUIC implementation use OpenSSL for its cryptographic and TLS needs.
A quick recap how history unfolded
2019 – BoringSSL introduced an API for QUIC. QUIC implementations picked it up and it worked. A pull request was made for OpenSSL to allow them to provide the same API so that QUIC stacks all over could use OpenSSL.
2021 – OpenSSL eventually denied merging the pull-request and announced they would instead implement their own QUIC stack – that nobody had asked for.
2023 – OpenSSL 3.2 shipped with support for their own QUIC stack. It was broken in many ways.
2025: OpenSSL version 3.4.1 was released and now the QUIC stack worked decently. In OpenSSL 3.5.0 they announced a QUIC API that now finally allowed independent QUIC stacks to use OpenSSL.
Experimental
Skilled contributors added support for OpenSSL-QUIC to curl primarily to allow people using OpenSSL to still be able to use HTTP/3.
OpenSSL’s own QUIC implementation only reached experimental state in curl meaning that we explicitly and strongly discourage users from using it in production and reserve ourselves the right to change functionality and more between versions.
There are three reasons why it did not graduate from experimental and they are also the reasons why we think we are better off without offering support for it:
The API is lacking. We have communicated with the OpenSSL-QUIC team since even before the API first shipped and it still does not offer the knobs and controls we would like to make it a competitive QUIC alternative. We don’t feel they care much.
The performance is bad. And by bad I mean really bad. The leading QUIC implementation alternative ngtcp2 transfers data much faster in all benchmarks and comparisons. Sometimes up to a factor three difference.
The memory use is abysmal. The amount of more memory required to do transfers with OpenSSL-QUIC compared to ngtcp2 can reach a factortwenty.
A drawing
This makes the curl backend situation simpler in the HTTP/3 and QUIC department as the image below tries to show.
curl added support for OpenSSL immediately when it was first released, as they switched away from SSLeay, in the late 1990s.
We have since supported it over the decades as both OpenSSL and curl have developed.
A while back the OpenSSL project stopped updating their 1.0.x and 1.1.x public branches. This means that unless you are paying for support from someone, and only relies on the public open versions these OpenSSL releases are going to decay and soon be insecure choices. Nothing to rely on.
As a direct result of this, the curl project has decided to drop support for OpenSSL 1.0.2 and 1.1.1 soon.
We stop supporting OpenSSL 1.0.2 in December 2025.
We stop supporting OpenSSL 1.1.1 in June 2026.
Starting in June 2026, we plan to only support OpenSSL 3 and later. Of course with the caveat that we might change our minds or schedule as we go along and things happen.
Part of the reason for us dropping this support is the fact that basically only users who are already paying for OpenSSL support are the ones who are going to be using these versions.
We will offer commercial support for curl with OpenSSL 1.1.1 for as long as customers want it, even when support gets removed from the public curl version.
The forks remain
This news is for OpenSSL support only and does not affect the forks. We intend to keep supporting the whole fork family AmiSSL, AWS-LC, BoringSSL, LibreSSL and QuicTLS going forward as well.
curl supports getting built with eleven different TLS libraries. Six of these libraries are OpenSSL or forks of OpenSSL. Allow me to give you a glimpse of their differences, similarities and some insights into what it takes to support them all.
SSLeay
It all started with SSLeay. This was the first SSL library I found out to exist and we added the first HTTPS support to curl using this library in the spring of 1998. Apparently the SSLeay project was started already back in 1995.
This was back in the days we still only had SSL; TLS would come later.
OpenSSL
This project was created (forked) from the ashes of SSLeay in late 1998 and curl supported it already from its start. SSLeay was abandoned.
OpenSSL always had a quirky, inconsistent and extremely large API set (a good chunk of that was inherited from SSLeay), that is further complicated by documentation that is sparse at best and leaves a lot to the users’ imagination and skill to dig through source code to get the last details answered (still today in 2025). In curl we keep getting occasional problems reported with how we use this library even decades in. Presumably this is the same for every OpenSSL user out there.
The OpenSSL project is often criticized for having dropped the ball on performance since they went to version 3 a few years back. They have also been slow and/or unwilling at adopt new TLS technologies like for QUIC and ECH.
In spite of all this, OpenSSL has become a dominant TLS library especially in Open Source.
LibreSSL
Back in the days of Heartbleed, the LibreSSL forked off and became its own. They trimmed off things they think didn’t belong in the library, they created their own TLS library API and a few years in, Apple ships curl on macOS using LibreSSL. They have some local patches on their build to make it behave differently than others.
LibreSSL was late to offer QUIC, they don’t support SSLKEYLOGFILE, ECH and generally seem to be even slower than OpenSSL to implement new things these days.
curl has worked perfectly with LibreSSL since it was created.
BoringSSL
Forked off by Google in the Heartbleed days. Done by Google for Google without any public releases they have cleaned up the prototypes and variable types a lot, and were leading the QUIC API push. In general, most new TLS inventions have since been implemented and supported by BoringSSL before the other forks.
Google uses this in Android and other places.
curl has worked perfectly with BoringSSL since it was created.
AmiSSL
A fork or flavor of OpenSSL done for the sole purpose of making it build and run properly on AmigaOS. I don’t know much about it but included it here for completeness. It seems to be more or less a port of OpenSSL for Amiga.
curl works with AmiSSL when built for AmigaOS.
QuicTLS
As OpenSSL dragged their feet and refused to provide the QUIC API the other forks did back in the early 2020s (for reasons I have yet to see anyone explain), Microsoft and Akamai forked OpenSSL and produced QuicTLS which has since tried to be a light-weight fork that mostly just adds the QUIC API in the same style BoringSSL and LibreSSL support it. Light-weight in the meaning that they were tracking upstream closely and did not intend to deviate from that in other ways than the QUIC API.
With OpenSSL3.5 they finally shipped a QUIC API that is different than the QUIC API the forks (including QuicTLS) provide. I believe this triggered QuicTLS to reconsider their direction going forward but we are still waiting to see exactly how. (Edit: see below for a comment from Rich Salz about this.)
curl has worked perfectly with QuicTLS since it was created.
AWS-LC
This is a fork off BoringSSL maintained by Amazon. As opposed to BoringSSL, they do actual (frequent) releases and therefore seem like a project even non-Amazon users could actually use and rely on – even though their stated purpose for existing is to maintain a secure libcrypto that is compatible with software and applications used at AWS. Strikingly, they maintain more than “just” libcrypto though.
The API AWS-LC offers is not identical to BoringSSL’s.
curl works perfectly with AWS-LC since early 2023.
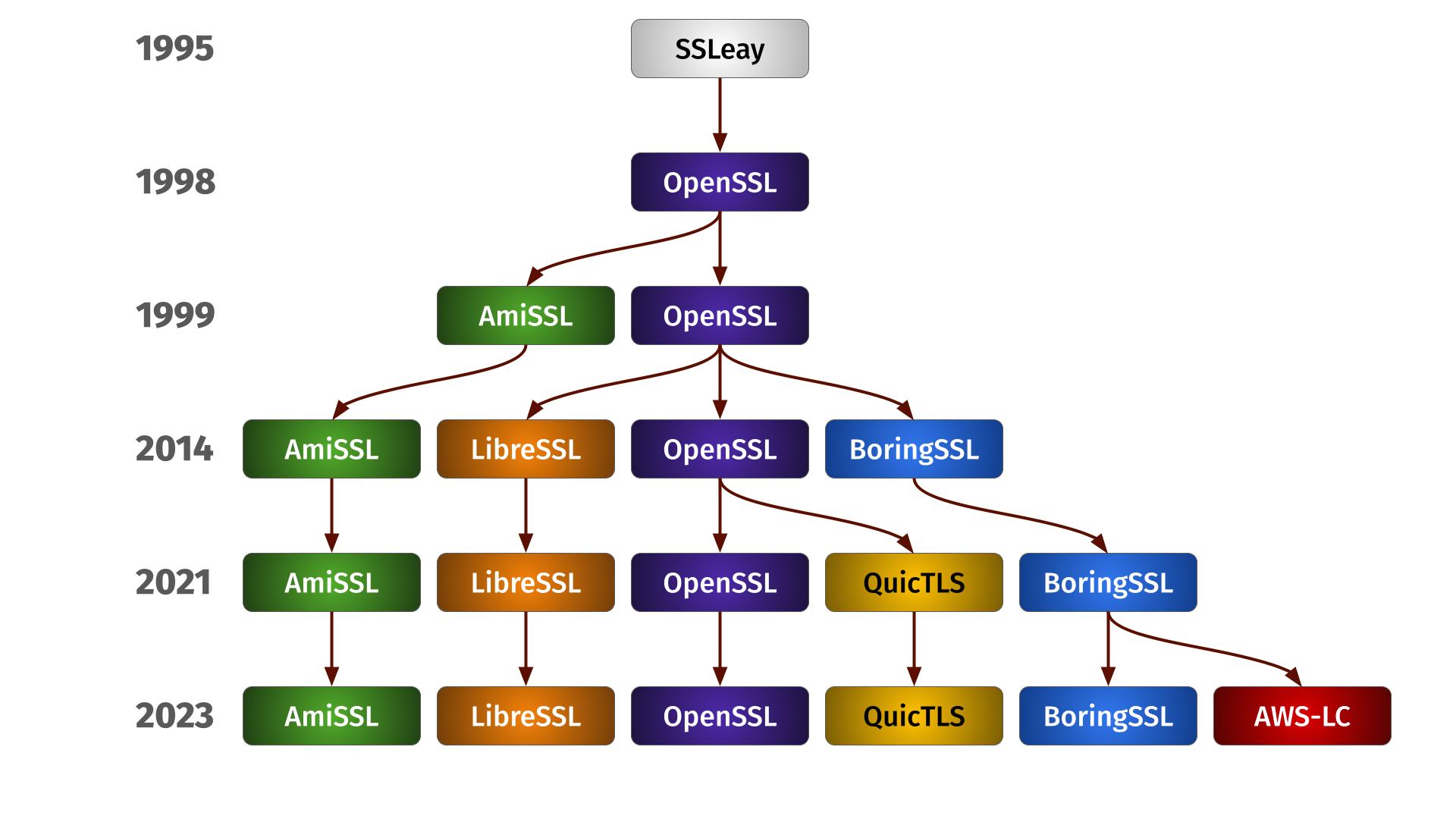
Family Tree
The OpenSSL fork family tree
The family life
Each of these six different forks has its own specifics, APIs and features that also change and varies over their different versions. We remain supporting these six forks for now as people still seem to use them and maintenance is manageable.
We support all of them using the same single source code with an ever-growing #ifdef maze, and we verify builds using the forks in CI – albeit only with a limited set of recent versions.
Over time, the forks seem to be slowly drifting apart more and more. I don’t think it has yet become a concern, but we are of course monitoring the situation and might at some point have to do some internal refactors to cater for this.
Future
I can’t foresee what is going to happen. If history is a lesson, we seem to rather go towards more forks rather than fewer, but every reader of this blog post of course now ponders over how much duplicated efforts are spent on all these forks and the implied inefficiencies of that. On the libraries themselves but also on users such as curl.
I have blogged several times in the past about how OpenSSL decided to not ship the API for QUIC a long time ago, even though the entire HTTP world was hoping for it – or even expecting it. OpenSSL rejected the proposal to merge the proposed API and thereby implicitly decided to obstruct wide QUIC and HTTP/3 adoption outside browsers.
The OpenSSL team instead proclaimed that their ambition and goal was to implement their own QUIC stack and offer that to users. The OpenSSL team took a long time to implement it, but has shipped their own stack implementation and API since OpenSSL 3.2 – first released in November 2023.
Lagging behind
In the curl project we have been on top of this game all the way. We made curl capable of using OpenSSL-QUIC as a backend for QUIC (using nghttp3 for the HTTP/3 parts) as soon as that arrived. We immediately reported obvious flaws and omissions in their API and we have worked with the OpenSSL team over time as they have slowly but gradually addressed most (but not all) of our concerns.
Lots of other QUIC stack implementations have spent years in beta state, working out and polishing their implementations and APIs. OpenSSL went fairly quickly into shipping something they say can be used in production.
OpenSSL-QUIC considered experimental
We still consider the curl backend using the OpenSSL-QUIC implementation as experimental and discourage users from using such builds in production. Now primarily because it is a performance and resource hog compared to the competition.
The OpenSSL-QUIC implementation using curl has been measured up to 4 times (!) slower than ngtcp2 using up to 25 times (!) the amount of memory.
The API is different
The API OpenSSL finally merged on February 10, 2025 is however not the exact same API that was proposed many years ago, the API that BoringSSL, quictls and the others have been offering for many years by now. It is different, and because of this the QUIC implementations that want to use it need to adapt specifically for this and cannot just interchangeably switch between the many OpenSSL forks. It uses a pull concept versus the push of what other provides.
Additionally, the pull requests mentions: At the moment our QUIC stack does not support early data. A significant missing feature compared to what the OpenSSL forks (and other libraries) support.
When I asked the OpenSSL team about how they came to ship such a different API to what everyone else offers and what QUIC implementers have been asking for, the given explanation was:
– The API is layered on what we use internally to plug in our QUIC client and server implementations in a clean manner […] We did get some feedback from other QUIC stacks – but the proof will be in actual usage which we expect will occur most likely after the 3.5 release is out.
Rumors have it that they say they spoke to four QUIC stack authors and they all had planned to support it.
I don’t know which four stacks this was, and I’m curious to see this happen. Most QUIC stacks are not written to handle different TLS libraries with different APIs, so they would either add that support now or switch to a different API all together. Either way, not a trivial undertaking.
Also “planning to support it” is easy to say. Could also just mean at some point in a distant future.
ngtcp2 is the world’s generic QUIC stack
There are multiple QUIC implementations out there, but the only one that has had the idea of being TLS library independent already from its start, is ngtcp2.
Since curl supports ngtcp2 for QUIC, it can then also work with any of the TLS libraries ngtcp2 supports: BoringSSL, AWS-LC, quictls, wolfSSL, GnuTLS. This fits the curl mindset very well.
ngtcp2 is also the only QUIC stack curl supports right now that is not considered experimental.
Could in theory ease HTTP/3 adoption
Assuming the API works, and assuming ngtcp2 can make use of the API in a fine way, this unexpected change of attitude could be the move that suddenly and for real makes HTTP/3 adoption in and with curl take off. OpenSSL has a firm grip of the TLS library landscape (in particular in the Open Source realm) and a huge share of curl users uses it. Starting with the pending OpenSSL version 3.5 in the spring of 2025, building with curl + OpenSSL can then possibly enable HTTP/3.
So will it? I asked a lead developer of the ngtcp2 library if they are going to work on adding an adaptation for the new OpenSSL 3.5 API.
– I have no plan to do that. OpenSSL QUIC API lacks 0rtt support and its pulling crypto data is not ideal for me, other TLS stacks do not do that. Basically, the current state is inferior than what we have proposed 6 years ago. I will revisit this after OpenSSL adds 0rtt support and revise its pull model.
(Clearly they were not one of the four stack authors OpenSSL talked to.)
While this does of course not prevent someone else from doing the work, even thought the 0RTT limitation is something that primarily has to be added to the OpenSSL API, it might imply that it will not happen immediately.
In my opinion, I think it could be useful and educational if the OpenSSL project themselves wrote that adaptation for ngtcp2 to “dogfood” their own API.
curl
An attempt to illustrate the QUIC stack situation in current curl is shown below.
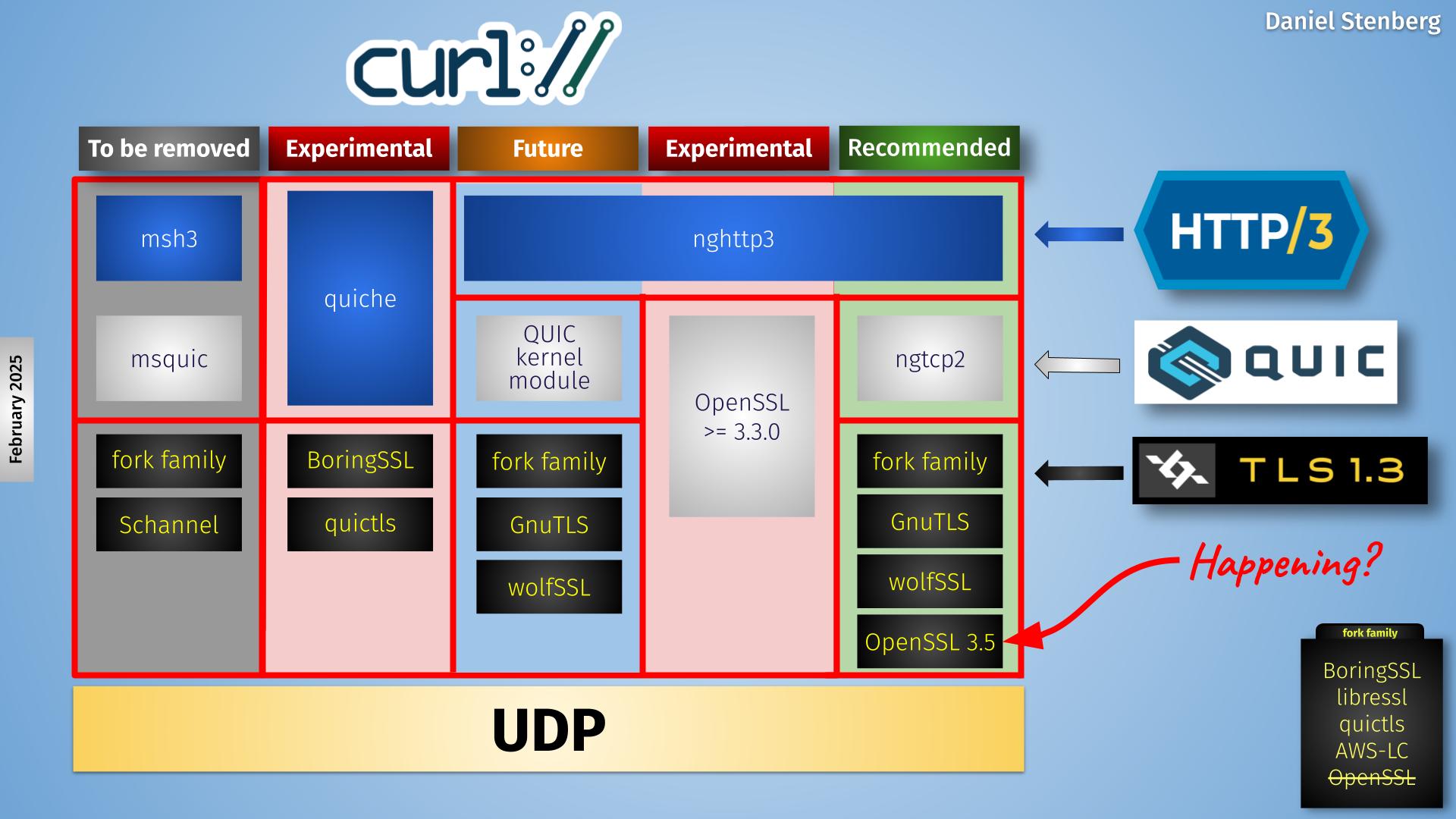
Currently curl supports four backends, out of which one (msh3) is scheduled for removal later this year and one (the kernel module version) is still only proposed for future inclusion – waiting for the kernel module to actually get adopted into the Linux kernel.
This leaves three actively developed backends, out of which one (ngtcp2) is the one we recommend and push for. The quiche and the OpenSSL-QUIC ones are still experimental.
The new OpenSSL API I discuss in this blog post is the one that would populate the lower right box, providing a TLS API for the QUIC library running on top of it. Hence me putting the red “happening?” text for this puzzle piece.
The red column second from the right is the OpenSSL-QUIC solution, using OpenSSL’s QUIC implementation.
Early days
It has not even been a week since this new API was merged into OpenSSL’s git repository, so it is far too early to give any predictions. Presumably it won’t even be used much for real by others until it gets shipped in a public release, planned to happen in April 2025.
Update
On February 26, there was another OpenSSL update: the QUIC API now offers 0-RTT support and they say this will be part of what ships in 3.5.
When a client connects to a TLS server it gets sent one or more certificates during the handshake.
Those certificates are verified by the client, to make sure that the server is indeed the right one: the server the client expects it to be; no impostor and no man in the middle etc.
When such a server certificate is signed by a Certificate Authority (CA), that CA’s certificate is normally not sent by the server but the client is expected to have it already in its CA store.
What certs?
Ever since the day SSL and TLS first showed up in the 1990s user have occasionally wanted to be able to save the certificates provided by the server in a TLS handshake.
This is of course most convenient when that server is using a self-signed certificate or something otherwise unusual.
(WARNING: The above shown example is an insecure way of reaching the host, as it does not detect if the host is already MITMed at the time when the first command runs. Trust On First Use.)
OpenSSL
A downside with the approach above is that it requires the openssl tool. Albeit, not a big downside for most people.
There are also alternative tools provided by wolfSSL and GnuTLS etc that offer the same functionality.
QUIC
Over the last few years we have seen a huge increase in number of servers that run QUIC and HTTP/3, and tools like curl and all the popular browsers can communicate using this modern set of protocols.
OpenSSL cannot. They decided to act against what everyone wanted, and as a result the openssl tool also does not support QUIC and therefore it cannot show the certificates used for a HTTP/3 site!
This is an inconvenience to users, including many curl users. I decided I could do something about it.
CURLOPT_CERTINFO
Already back in 2016 we added a feature to libcurl that enables it to return a list of certificate information back to the application, including the certificate themselves in PEM format. We call the option CURLOPT_CERTINFO.
We never exposed this feature in the command line tool and we did not really see the need as everyone could use the openssl tool etc fine already.
Until now.
curl -w is your friend
curl supports QUIC and HTTP/3 since a few years back, even if still marked as experimental. Because of this, the above mentioned CURLOPT_CERTINFO option works fine for that protocol version as well.
Using the –write-out (-w) option and the new variables %{certs} and %{num_certs} curl can now do what you want. Get the certificates from a server in PEM format:
You can of course also add --http3 to the command line if you want, and if you like to get the certificates from a server with a self-signed one you may want to use --insecure. You might consider adding --head to avoid the response body. This command line uses -o to write the content to /dev/null because it does not care about that data.
The %{num_certs} variable shows the number of certificates returned in the handshake. Typically one or two but can be more.
%{certs} outputs the certificates in PEM format together with a number of other details and meta data about the certificates in a “name: value” format.
Availability
These new -w variables are only supported if curl is built with a supported TLS backend: OpenSSL/libressl/BoringSSL/quictls, GnuTLS, Schannel, NSS, GSKit and Secure Transport.
Support for these new -w variables has been merged into curl’s master branch and is scheduled to be part of the coming release of curl version 7.88.0 on February 15th, 2023.
When setting up a TLS or QUIC connection, a client like curl needs a CA store in order to verify the certificate(s) the server provides in the TLS handshake.
CA store
A CA store is a fancy name for a number of certificates. Certificates for the Certificate Authorities (CAs) that a TLS client trusts. On the curl website, we offer a PEM version of the CA store that Mozilla maintains, for download. This set currently contains 142 certificates and while the exact amount vary a little over time, it has been more than a hundred for many years. A fair amount. And there is nothing in the pipe that will bring down the number significantly anytime soon, to my knowledge. These 142 certificates make up a file that is exactly 225,403 bytes. 1587 bytes per certificate on average.
Load and parse
When setting up a TLS connection, the 142 certificates need to be loaded from the external file into memory and parsed so that the server’s certificate can be verified. So that curl knows that the server it has connected to is indeed the correct server and not a man in the middle, an impostor.
This procedure is a rather costly one, in terms of CPU cycles needed.
Another cache
A classic approach to avoid heavy work is to cache the results from a previous use to be able to reuse them again. Starting in curl 7.87.0 curl introduces a CA store cache.
Now, curl can keep the loaded and parsed CA store in memory associated with the handle and then subsequent requests can avoid re-loading and re-parsing the CA data when new connections are created – if they use the same CA store of course. The performance gain in doing this shortcut can be enormous. After all, most transfers are done using the same single CA store.
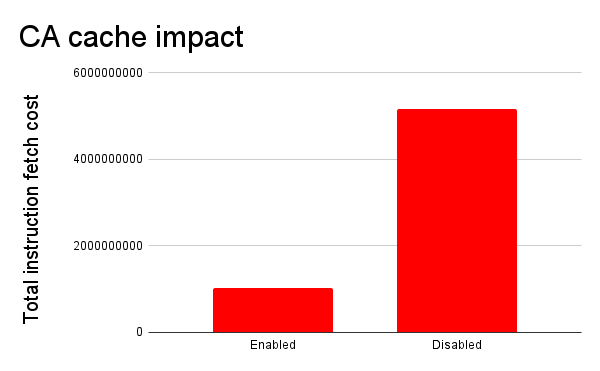
To quote the numbers Michael Drake presented in the pull request for this new feature. He measured number of instructions to load and render a particular web page from BBC with the NetSurf browser (which obviously is using libcurl for its HTTPS transfers). With and without this cache.
CA store cache
Total instruction fetch cost
None
5,168,090,712
Enabled
1,020,984,411
I think a reduction to one fifth of the original cost is significant.
Converted into a little graph they compare like this (smaller is better):
But even in simpler applications and curl command lines this caching should have a measurable impact as soon as multiple TLS connections are done using the same handle. An extremely common usage pattern.
Life-time
Keeping the data around after use potentially changes the behavior a little, but the huge performance gain made us decide to still do this by default. We compensate this a little by setting the default life-time to 24 hours, so applications that keep handles alive for a very long time will still get the cache flushed and read from file again every day.
The CA store is typically not updated more frequently than once every few months or weeks.
This is a new option for libcurl that allows applications to tweak the life-time and CA cache behavior for when the default as described above is not enough.
Details
This CA cache system is so far only supported when curl is built to use OpenSSL or one of its forks. I hope others will get inspired and bring this support for other TLS backends as well as we go forward.
CA cache support for curl was authored by Michael Drake. Thanks!
Back in 2008, I had a revelation when it dawned on me that the POSIX function called strcasecmp() compares strings case insensitively, but locale dependent. Because of this, “file” and “FILE” is not actually a case insensitive match in Turkish but is a match in most other locales. curl would sometimes fail in mysterious ways due to this. Mysterious to the users, now we know why.
Of course this behavior was no secret. The knowledge about this problem was widespread already then. It was just me who hadn’t realized this yet.
A custom replacement
To work around that problem for curl, we immediately implemented our own custom comparison replacement function that doesn’t care about locales. Internet protocols work the same way no matter which locale the user happens to prefer.
We did not go the POSIX route. The POSIX function for case insensitive string comparisons that ignores the locale is called strcasecmp_l() but that uses a special locale argument and also doesn’t exist on non-POSIX platforms.
curl has used its custom set of functions since 7.19.1, released in early November 2008.
OpenSSL 3.0.3
Fast forward to May 2022. OpenSSL released their version 3.0.3. In the change-log for this release we learned that they now offer public functions for case insensitive string comparisons. Whatdoyouknow! They too have learned about the Turkish locale. Apparently to the degree that they feel they need to offer those functions in their already super-huge API set. Oh well, that is certainly their choice.
I can relate since we too have such functions in libcurl, but I have always regretted that we added them to the API since comparing strings is not libcurl’s core business. We did wrong then and we still live with the consequences several decades later.
OpenSSL however took the POSIX route and based their implementation on strcasecmp_l() and use a global variable for the locale and an elaborate system to initialize that global and even a way to make things work if string comparisons are needed before that global variable is initialized etc.
This new system was complicated to the degree that it broke the library on several platforms, which curl users running Windows 7 figured out almost instantly. curl with OpenSSL 3.0.3 simply does not work on Windows 7 – at all.
Reasons for not exposing a string compare API
Libraries should only provide functions that are within their core objective. Not fluffy might be useful things. Reasons for this include:
It adds to the complexity to users. Yet another function in the ever expanding set of function calls in the API.
It increases the documentation size even more and makes the real things harder to find somewhere in there.
It adds “attack surface” and areas where you can make errors and introduce security problems.
You get more work since now you have additional functions to keep ABI and API stable for all eternity and you have to spend developer time and effort on making sure they remain so.
Do a custom one for OpenSSL?
I think there is a software law that goes something like this
eventually, all C libraries implement their own case insensitive string comparison functions
When I proposed they should implement their own custom function in discussions in one of the issues about this OpenSSL problem, the suggestion was shot down fairly quickly because of how hard it is to implement a such function that is as fast as the glibc version.
In my ears, that sounds like they prefer to stick with an overworked and complicated error-prone system, because an underlying function is faster, rather than going with simplicity and functionality at the price of sightly slower performance. In fairness, they say that case insensitive string comparisons are “6-7%” of the time spent in some (to me unknown) performance test they referred to. I have no way or intention to argue with that.
I think maybe they couldn’t really handle that idea from an outsider and they might just need a little more time to figure out the right way forward on their own. Then go with simple.
I am of course not in the best position to say how they should act on this. I’m just a spectator here. I may be completely wrong.
Update (May 23)
In a separate PR (4 days after this blog post went live), OpenSSL suddenly implemented their own and it was deemed that it would not hurt performance noticeably. Merged on May 23. Almost like they followed my recommendation!
OpenSSL’s current tolower() implementation used in the comparison function is similar to curl’s old one so I suspect curl’s current function is a tad bit faster.
However, the API and way to use those functions to make them locale independent is horrific because of the way it forces the caller to provide a locale argument (which could be the “C” locale – the equivalent of no locale).
The curl custom function
That talk about the slowness of custom string functions made us start discussing this topic a little in the curl IRC channel and we bounced around some ideas of what things the curl function does not already do and what it could do and how it compares against the glibc assembly version.
Also: the string comparisons in curl are certainly not that performance critical as they seem to be in OpenSSL and while used a lot in curl they are not used in the most important performance critical transfer-data code paths.
Optimizations
Frank Gevaerts took the lead and after some rounds and discussions backed up with tests, he ended up with an updated function that is 1.6 to 1.7 times faster than before his work. We dropped non-ASCII support in curl a while ago, which also made this task more straight-forward.
The two improvements:
Use a lookup table for our own toupper() implementation instead of the previous simple condition + math.
Better end of loop handling: return immediately on mismatch, and a minor touch-up of the final check when the loop goes all the way to the end.
Measurements
The glibc assembler versions are still faster than curl’s custom functions and the exact speed improvements the above mentioned changes provide will of course depend both on platform and the test set.
Ships in 7.84.0
The faster libcurl functions will ship in curl 7.84.0. I doubt anyone will notice the difference!
In a world that is now gradually adopting HTTP/3 (which, as you know, is implemented over QUIC), the problem with the missing API for QUIC is still a key problem.
There are a number of existing QUIC library implementation now since a few years back, and they are slowly maturing. The QUIC protocol became RFC 9000 and friends, but the most popular TLS libraries still don’t provide the necessary APIs to make QUIC libraries possible to use them.
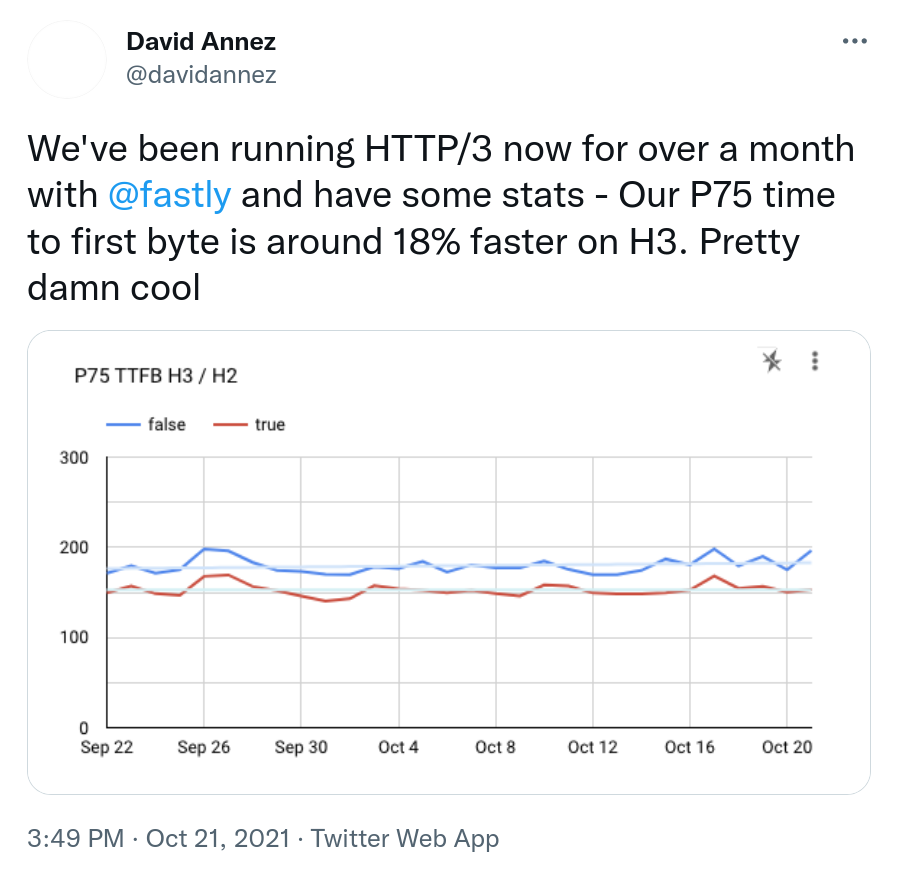
Example that makes people want HTTP/3
Example tweet of what makes people keen on experimenting and deploying HTTP/3.
OpenSSL PR8797
For a long time, many people and projects (including yours truly) in the QUIC community were eagerly following the OpenSSL Pull Request 8797, which introduced the necessary QUIC APIs into OpenSSL. This change brought the same API to OpenSSL that BoringSSL already provides and as such the API has already been used and tested out by several independent implementations.
Implementations have a problem to ship to the world based on BoringSSL since that’s a TLS library without versions and proper releases, so it is not a good choice for the big wide world. OpenSSL is already the most widely used TLS library out there and lots of applications are already made to use that.
Delays made quictls happen
The OpenSSL PR8797 was delayed back in February 2020 on when the OpenSSL management committee (OMC) decreed that they would not deal with that PR until after their pending 3.0.0 release had shipped.
“It is our expectation that once the 3.0 release is done, QUIC will become a significant focus of our effort.”
OpenSSL then proceeded and their 3.0.0 release was delayed significantly compared to their initial time schedule.
In March 2021, Microsoft and Akamai announcedquictls, an OpenSSL fork with the express idea to ship OpenSSL + the QUIC API. They didn’t want to wait for OpenSSL to do it.
Several QUIC libraries can now use quictls. quictls has kept their fork up to date and now offers the equivalent of OpenSSL 3.0.0 + the QUIC API.
While we’ve been waiting for OpenSSL to adopt the API.
OpenSSL makes a turn instead
Then came the next blow to everyone’s expectations. An autumn surprise. On October 13, the OpenSSL OMC announces:
The focus for the next releases is QUIC, with the objective of providing a fully functional QUIC implementation over a series of releases (2-3).
OpenSSL has decided to implement a complete QUIC stack on their own and with the given time line it sounds like it will take them a few years (?) to ship. And instead of providing the API lots of implementers have been been waiting for so long, they explicitly say that it is a non-goal at the start:
The MVP will not contain a library API for an HTTP/3 implementation (it is a non-goal of the initial release).
I didn’t write my own QUIC implementation but I’ve followed the work of several of the implementations fairly closely and it is fairly complicated journey they set out for themselves – for very unclear reasons. There already exist several high quality QUIC libraries, why does OpenSSL think they need to make yet another one? They seem to be overloaded with work already before, which the long delays of the 3.0.0 release seemed to show, how are they going to be able to add a complete new stack implementation of top of this? The future will tell.
PR8797 closed
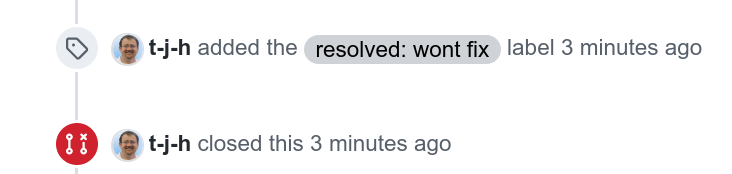
On October 20 2021, the pull request that was created in April 2019, is finally closed for real as a “won’t fix”.
Screenshot of the actual closing of the PR
Where are we now?
The lack of a QUIC API in OpenSSL has held us back and with this move from OpenSSL, it will continue to hold us back for an uncertain amount of time going forward.
QUIC stacks will have to stick to using or switching to other libraries.
I’m disappointed.
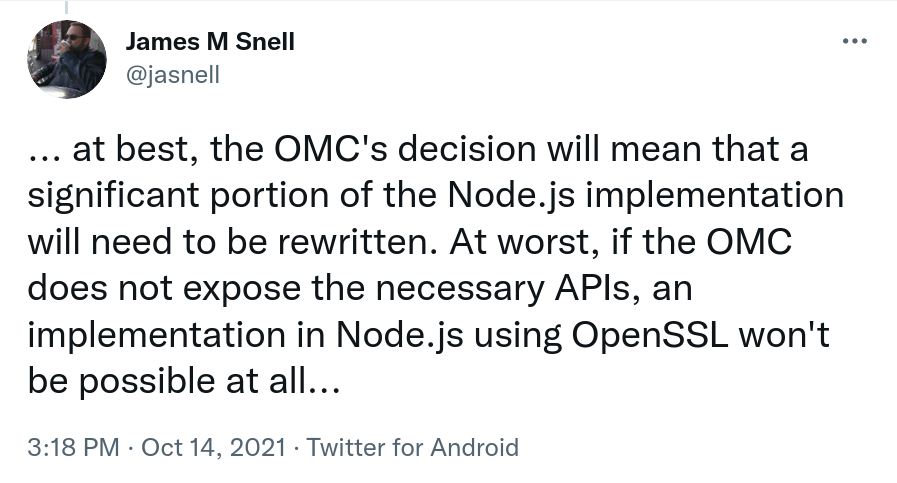
James Snell, one of the key contributors on the QUIC and HTTP/3 work in nodejs tweeted:
tldr: starting now, you need to select which TLS to use when you run curl’s configure script.
How it started
In June 1998, three months after the first release of curl, we added support for HTTPS. We decided that we would use an external library for this purpose – for providing SSL support – and therefore the first dependency was added. The build would optionally use SSLeay. If you wanted HTTPS support enabled, we would use that external library.
SSLeay ended development at the end of that same year, and OpenSSL rose as a new project and library from its ashes. Of course, even later the term “SSL” would also be replaced by “TLS” but the entire world has kept using them interchangeably.
Building curl
The initial configure script we wrote and provided back then (it appeared for the first time in November 1998) would look for OpenSSL and use it if found present.
In the spring of 2005, we merged support for an alternative TLS library, GnuTLS, and now you would have to tell the configure script to not use OpenSSL but instead use GnuTLS if you wanted that in your build. That was the humble beginning of the explosion of TLS libraries supported by curl.
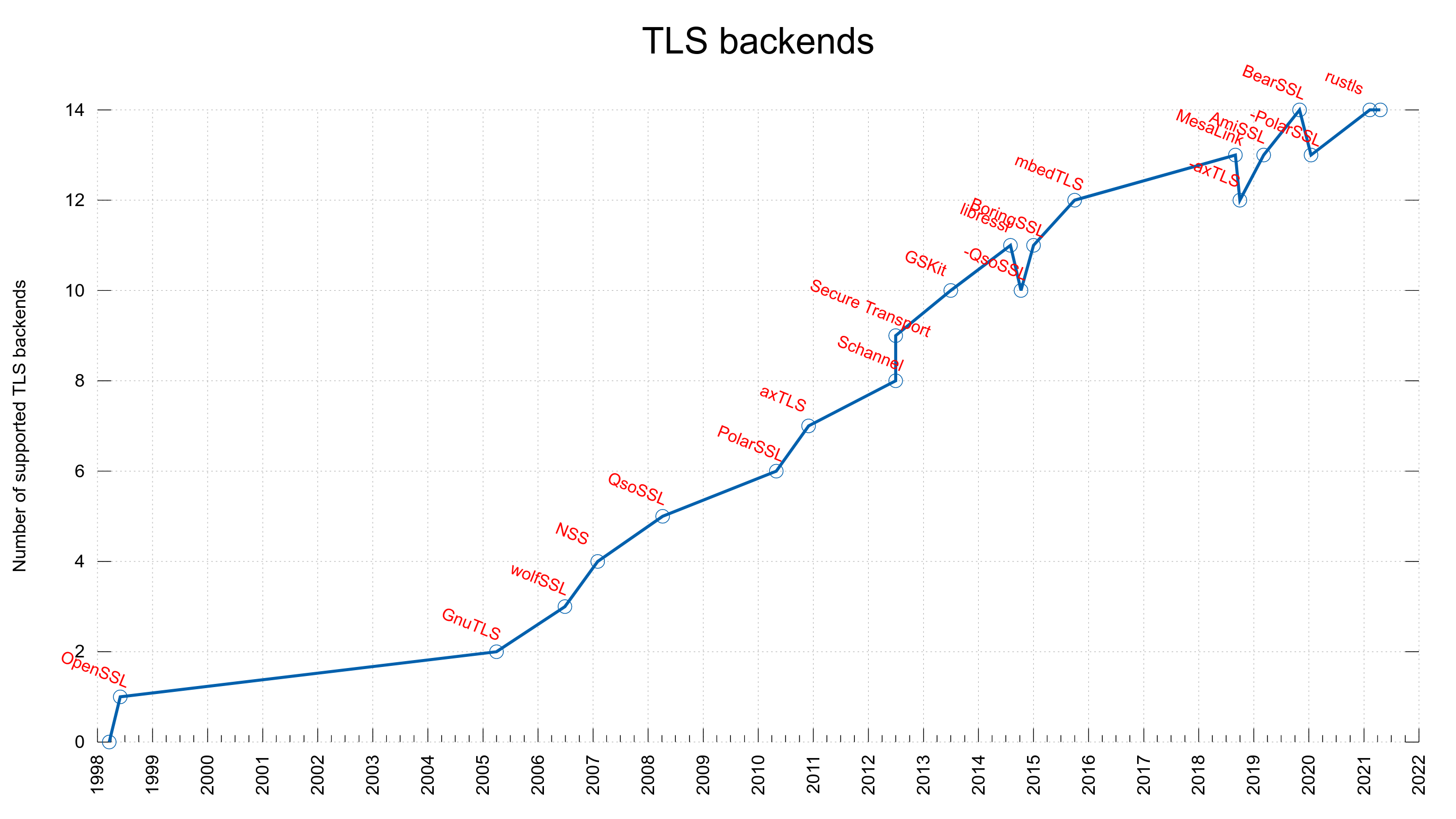
As time went on we added support for more and more TLS libraries, giving the users the choice to select exactly which particular one they wanted their curl build to use. At the time of this writing, we support 14 different TLS libraries.
TLS backends supported in curl, over time
OpenSSL was still default
The original logic from when we added GnuTLS back in 2005 was however still kept so whatever library you wanted to use, you would have to tell configure to not use OpenSSL and instead use your preferred library.
Also, as the default configure script would try to find and use OpenSSL it would result in some surprises to users who maybe didn’t want TLS in their build or even when something was just not correctly setup and configure unexpectedly didn’t find OpenSSL and the build then went on and was made completely without TLS support! Sometimes even without getting noticed for a long time.
Not doing it anymore
Starting now, curl’s configure will not select TLS backend by default.
It will not decide for you which one you use, as there are many decisions involved when selecting TLS backend and there are many users who prefer something else than OpenSSL. We will no longer give any special treatment to that library at build time. We will not impose our bias onto others anymore.
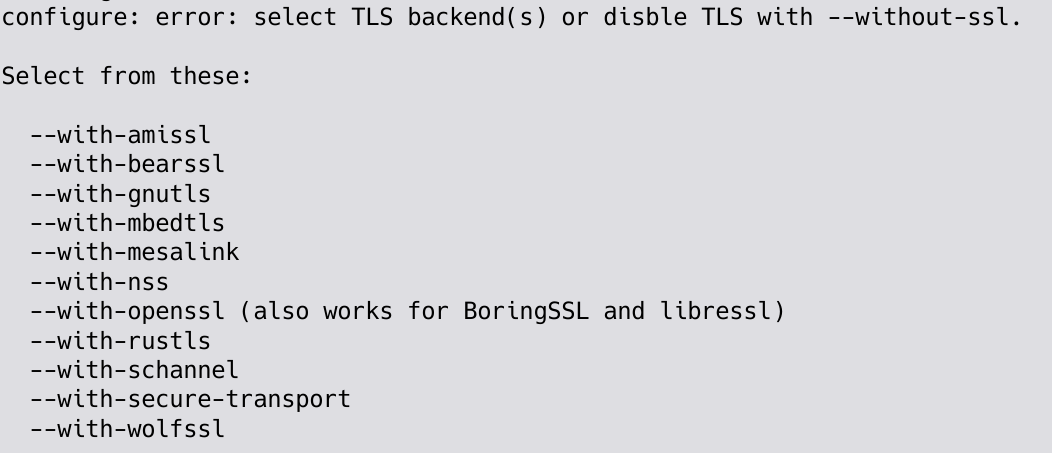
Not selecting any TLS backend at all will just make configure exit quickly with a help message prompting you to make a decision, as shown below. Notice that going completely without a TLS library is still fine but similarly also requires an active decision (--without-ssl).
The list of available TLS backends is sorted alphabetically.
Effect on configure users
With this change, every configure invoke needs to clearly state which TLS library or even libraries (in plural since curl supports building with support for more than one library) to use.
The biggest change is of course for everyone who invokes configure and wants to build with OpenSSL since they now need to add an option and say that explicitly. For virtually everyone else life can just go on like before.
Everyone who builds curl automatically from source code might need to update their build scripts.
The first release shipping with this change will be curl 7.77.0.
tldr: the level of HTTP/3 support in servers is surprisingly high.
The specs
The specifications are all done. They’re now waiting in queues to get their final edits and approvals before they will get assigned RFC numbers and get published as such – they will not change any further. That’s a set of RFCs (six I believe) for various aspects of this new stack. The HTTP/3 spec is just one of those. Remember: HTTP/3 is the application protocol done over the new transport QUIC. (See http3 explained for a high-level description.)
The HTTP/3 spec was written to refer to, and thus depend on, two other HTTP specs that are in the works: httpbis-cache and https-semantics. Those two are mostly clarifications and cleanups of older HTTP specs, but this forces the HTTP/3 spec to have to get published after the other two, which might introduce a small delay compared to the other QUIC documents.
The working group has started to take on work on new specifications for extensions and improvements beyond QUIC version 1.
HTTP/3 Usage
In early April 2021, the usage of QUIC and HTTP/3 in the world is measured by a few different companies.
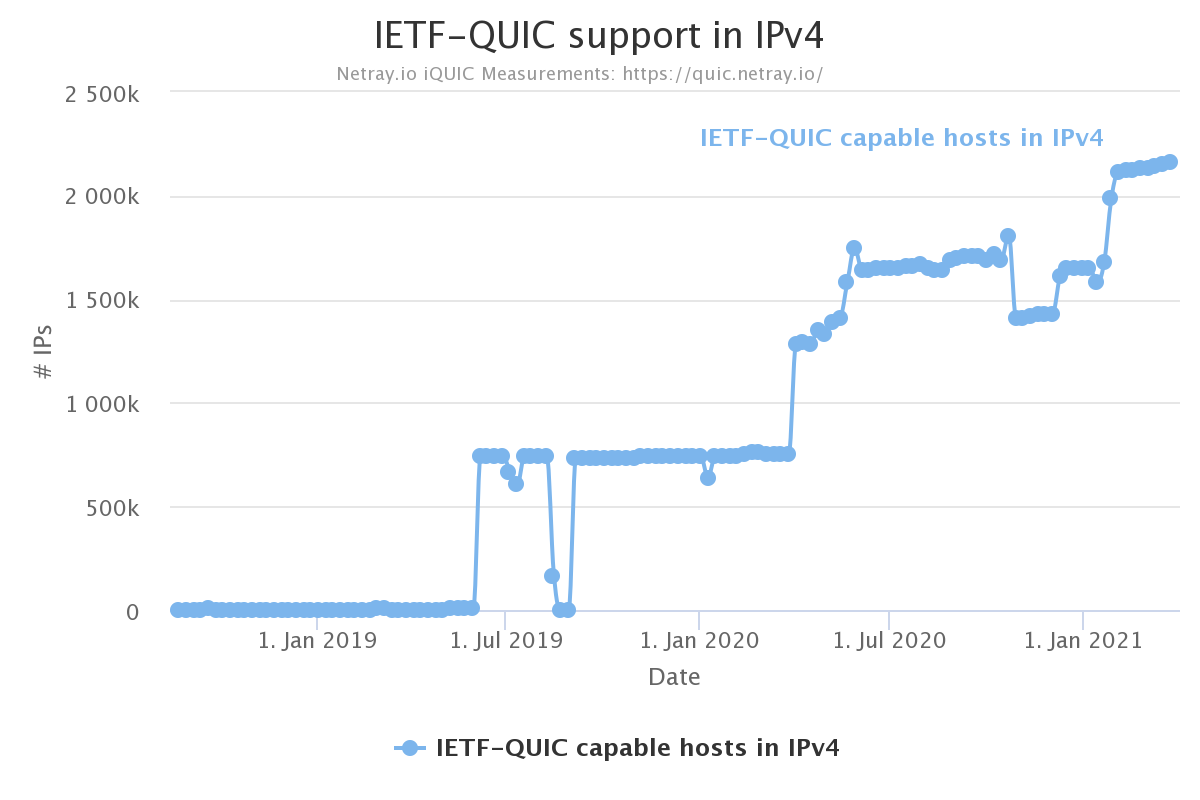
QUIC support
netray.io scans the IPv4 address space weekly and checks how many hosts that speak QUIC. Their latest scan found 2.1 million such hosts.
Arguably, the netray number doesn’t say much. Those two million hosts could be very well used or barely used machines.
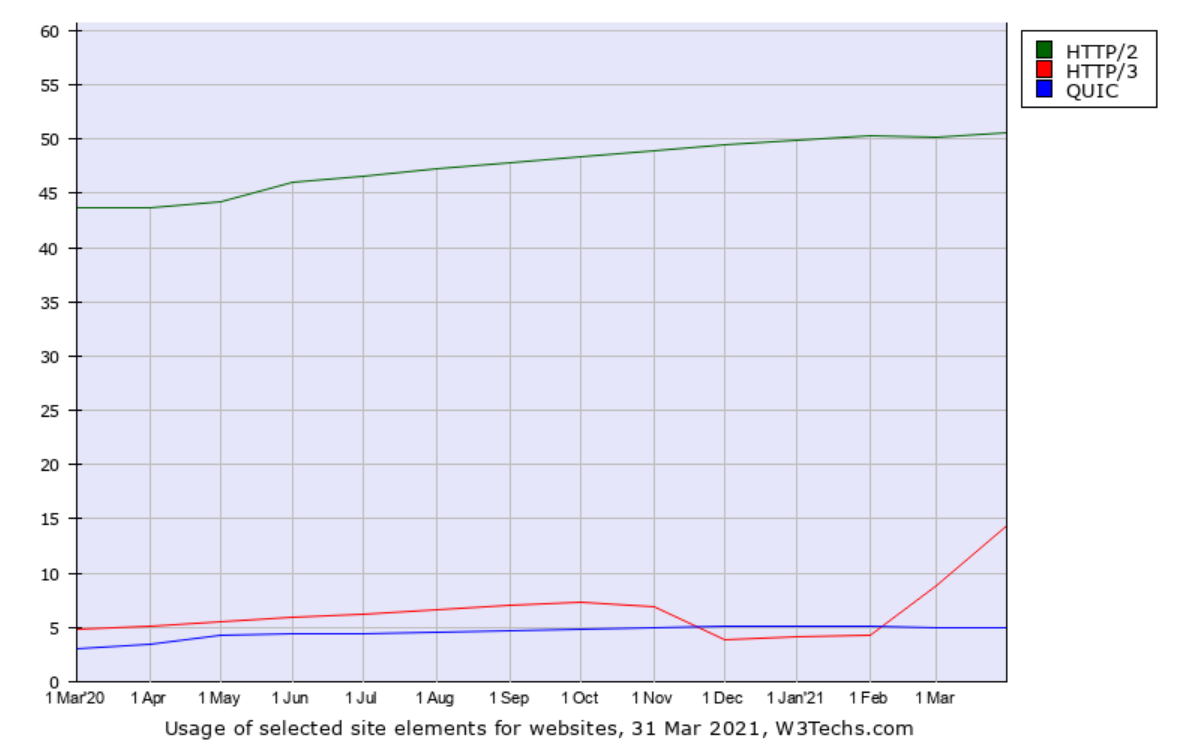
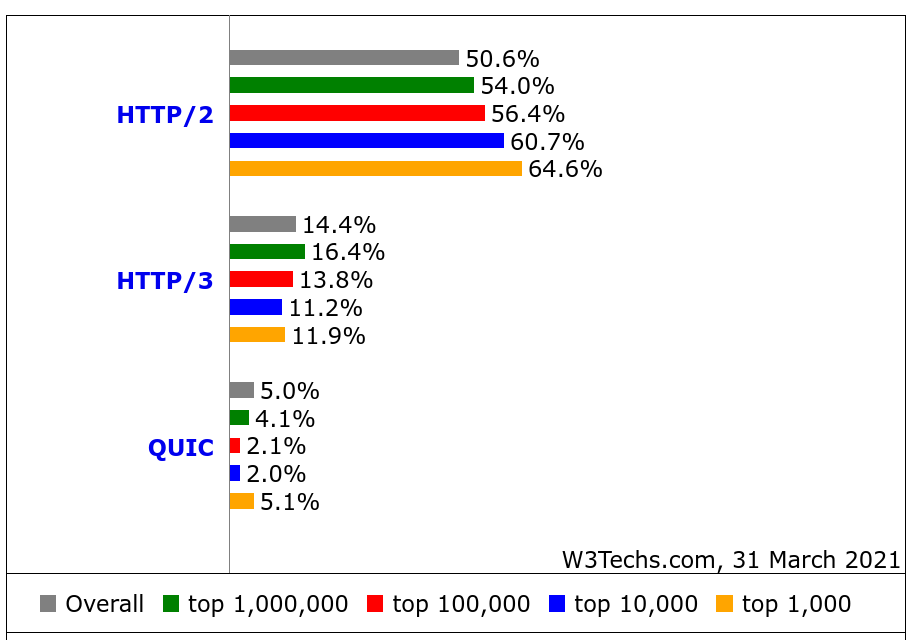
HTTP/3 by w3techs
w3techs.com has been in the game of scanning web sites for stats purposes for a long time. They scan the top ten million sites and count how large share that runs/supports what technologies and they also check for HTTP/3. In their data they call the old Google QUIC for just “QUIC” which is confusing but that should be seen as the precursor to HTTP/3.
What stands out to me in this data except that the HTTP/3 usage seems very high: the top one-million sites are claimed to have a higher share of HTTP/3 support (16.4%) than the top one-thousand (11.9%)! That’s the reversed for HTTP/2 and not how stats like this tend to look.
It has been suggested that the growth starting at Feb 2021 might be explained by Cloudflare’s enabling of HTTP/3 for users also in their free plan.
HTTP/3 by Cloudflare
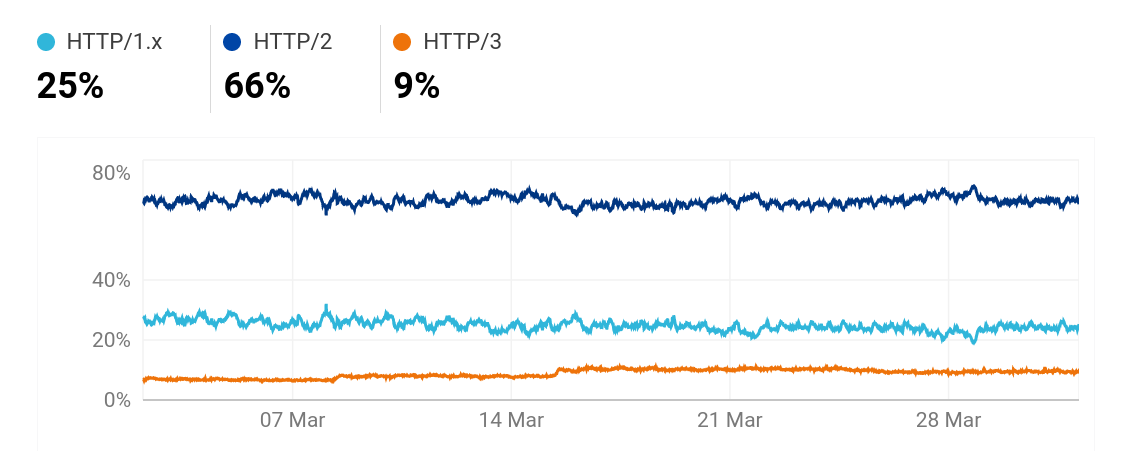
On radar.cloudflare.com we can see Cloudflare’s view of a lot of Internet and protocol trends over the world.
The last 30 days according to radar.cloudflare.com
This HTTP/3 number is significantly lower than w3techs’. Presumably because of the differences in how they measure.
Clients
The browsers
All the major browsers have HTTP/3 implementations and most of them allow you to manually enable it if it isn’t already done so. Chrome and Edge have it enabled by default and Firefox will so very soon. The caniuse.com site shows it like this (updated on April 4):
(Earlier versions of this blog post showed the previous and inaccurate data from caniuse.com. Not anymore.)
curl
curl supports HTTP/3 since a while back, but you need to explicitly enable it at build-time. It needs to use third party libraries for the HTTP/3 layer and it needs a QUIC capable TLS library. The QUIC/h3 libraries are still beta versions. See below for the TLS library situation.
curl’s HTTP/3 support is not even complete. There are still unsupported areas and it’s not considered stable yet.
curl supports 14 different TLS libraries at this time. Two of them have QUIC support landed: BoringSSL and GnuTLS. And a third would be the quictls OpenSSL fork. (There are also a few other smaller TLS libraries that support QUIC.)
OpenSSL
The by far most popular TLS library to use with curl, OpenSSL, has postponed their QUIC work:
At the same time they have delayed the OpenSSL 3.0 release significantly. Their release schedule page still today speaks of a planned release of 3.0.0 in “early Q4 2020”. That plan expects a few months from the beta to final release and we have not yet seen a beta release, only alphas.
Realistically, this makes QUIC in OpenSSL many months off until it can appear even in a first alpha. Maybe even 2022 material?
BoringSSL
The Google powered OpenSSL fork BoringSSL has supported QUIC for a long time and provides the OpenSSL API, but they don’t do releases and mostly focus on getting a library done for Google. People outside the company are generally reluctant to use and depend on this library for those reasons.
The quiche QUIC/h3 library from Cloudflare uses BoringSSL and curl can be built to use quiche (as well as BoringSSL).
quictls
Microsoft and Akamai have made a fork of OpenSSL available that is based on OpenSSL 1.1.1 and has the QUIC pull-request applied in order to offer a QUIC capable OpenSSL flavor to the world before the official OpenSSL gets their act together. This fork is called quictls. This should be compatible with OpenSSL in all other regards and provide QUIC with an API that is similar to BoringSSL’s.
The ngtcp2 QUIC library uses quictls. curl can be built to use ngtcp2 as well as with quictls,
Is HTTP/3 faster?
I realize I can’t blog about this topic without at least touching this question. The main reason for adding support for HTTP/3 on your site is probably that it makes it faster for users, so does it?
According to cloudflare’s tests, it does, but the difference is not huge.
We’ve seen other numbers say h3 is faster shown before but it’s hard to find up-to-date performance measurements published for the current version of HTTP/3 vs HTTP/2 in real world scenarios. Partly of course because people have hesitated to compare before there are proper implementations to compare with, and not just development versions not really made and tweaked to perform optimally.
I think there are reasons to expect h3 to be faster in several situations, but for people with high bandwidth low latency connections in the western world, maybe the difference won’t be noticeable?
Future
I’ve previously shown the slide below to illustrate what needs to be done for curl to ship with HTTP/3 support enabled in distros and “widely” and I think the same works for a lot of other projects and clients who don’t control their TLS implementation and don’t write their own QUIC/h3 layer code.
This house of cards of h3 is slowly getting some stable components, but there are still too many moving parts for most of us to ship.
I assume that the rest of the browsers will also enable HTTP/3 by default soon, and the specs will be released not too long into the future. That will make HTTP/3 traffic on the web increase significantly.
The QUIC and h3 libraries will ship their first non-beta versions once the specs are out.
The TLS library situation will continue to hamper wider adoption among non-browsers and smaller players.
The big players already deploy HTTP/3.
Updates
I’ve updated this post after the initial publication, and the biggest corrections are in the Chrome/Edge details. Thanks to immediate feedback from Eric Lawrence. Remaining errors are still all mine! Thanks also to Barry Pollard who filed the PR to update the previously flawed caniuse.com data.