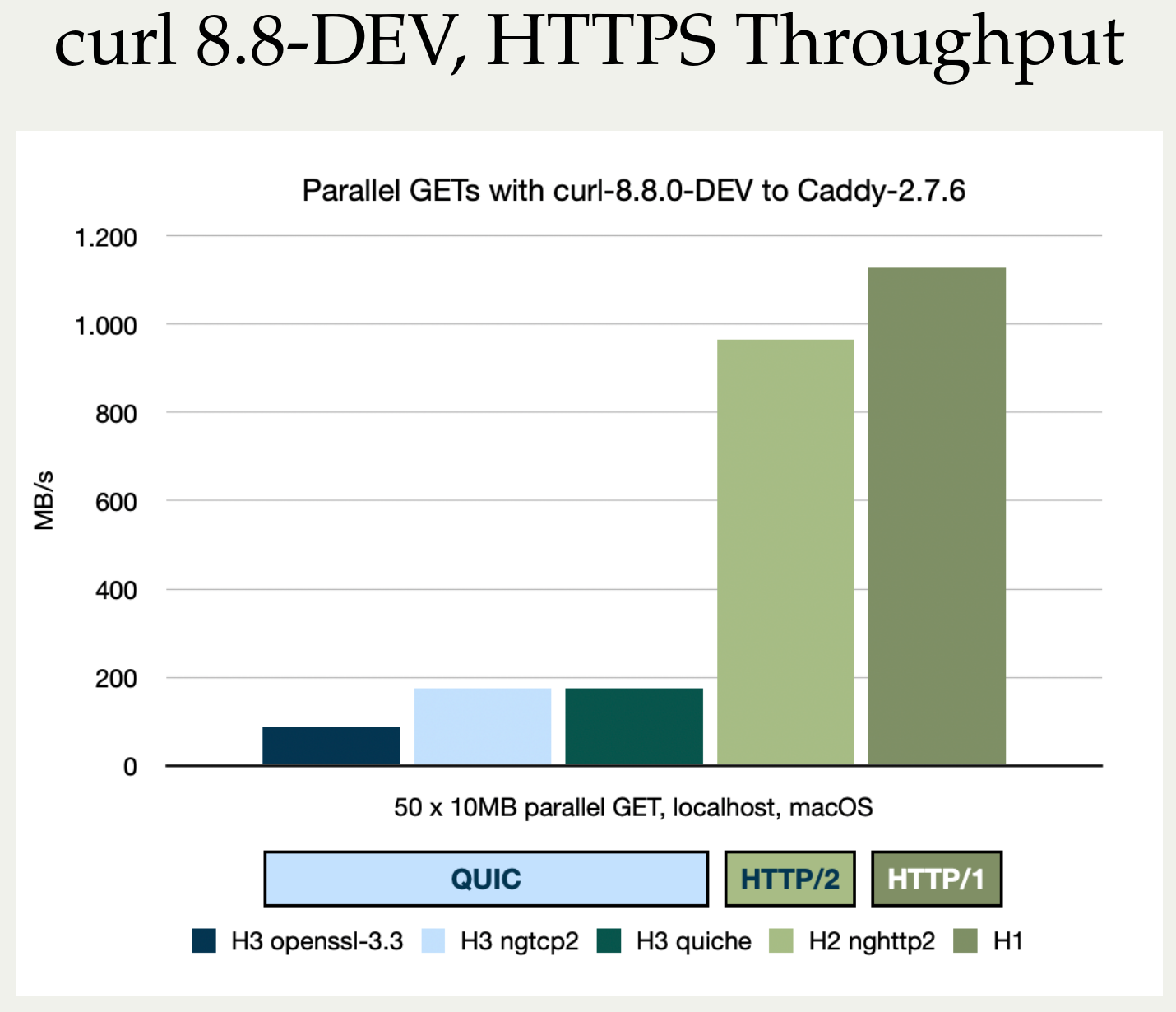
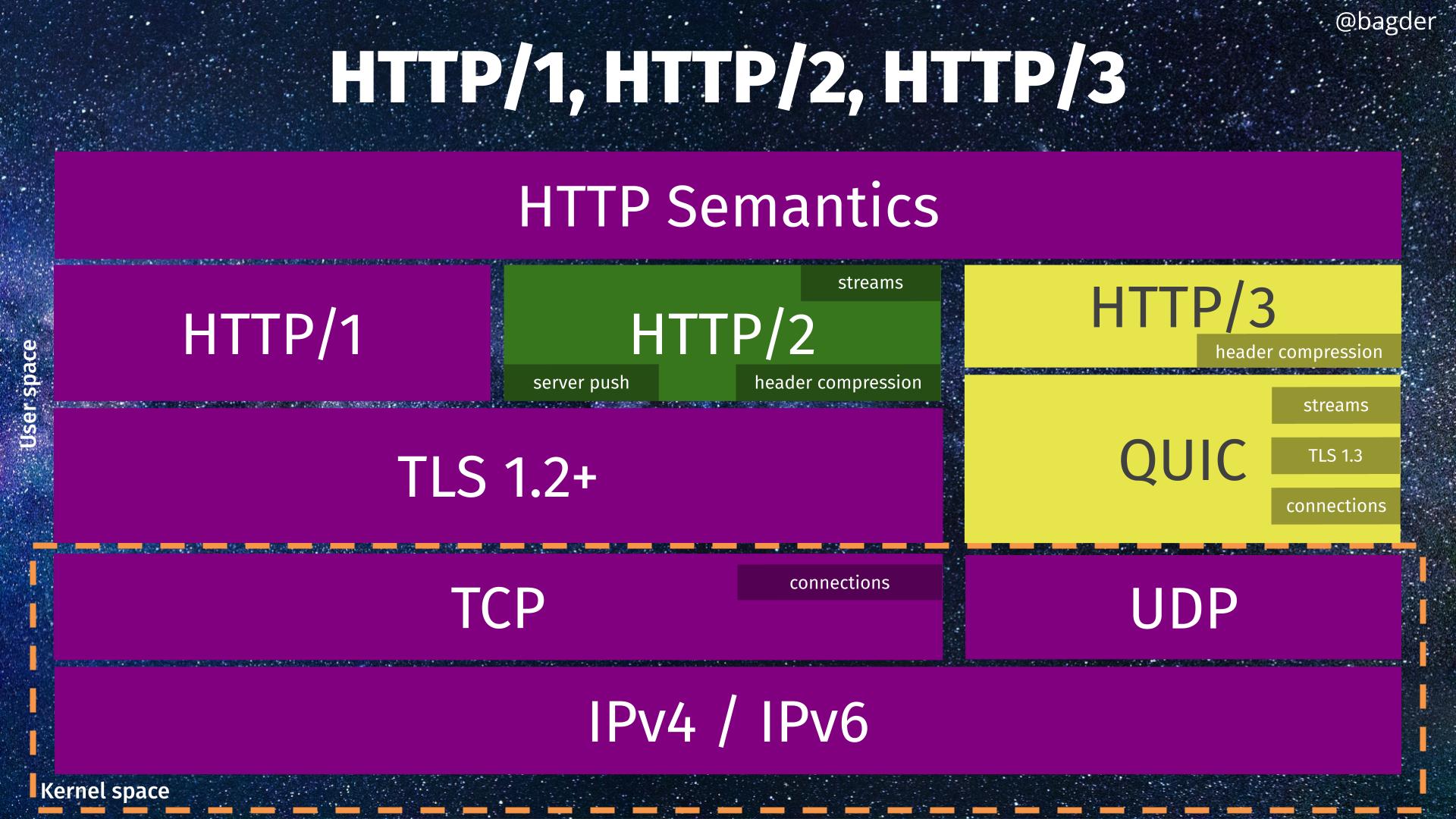
There is only one thing that is better than two days of HTTP workshop, and that is of course three days of HTTP workshop. The final day of this edition of the series started out with us again shuffling around where we parked ourselves around the big table. Except Mr captain of course who once again got to herd us forward through another day from the same seat.
Why MOQ is going to replace HTTP live streaming
MOQ (Media over QUIC transport) is not HTTP, but it uses QUIC so it is at least tangentially interesting and it involves a lot of the same people so this status update still felt welcome and suitable. Compared to existing HTTP based solutions, MOQ is supposed to offer less complexity and lower latency. The moon landing was broadcasted with less latency than current live-streamed TV and maybe MOQ can make us come close to those numbers again. In MOQ clients subscribe to a track that then contains a lot of objects that are delivered. It’s not the request + response approach of HTTP. The fact that this is not HTTP of course brings a lot of questions and well, doubts, and we lingered on various aspects of this topic for quite a while.
Reverse HTTP
My prize for the best slides of the HTTP workshop 2026 goes to [redacted] for the excellent use of potato images in their presentation.
PTTH is HTTP spelled backwards, commonly pronounced as PoTaToH. A client sets up the connection but the actual HTTP request is sent from the server to the client. One of the intended use cases for this, is to allow an origin server to connect to the CDN proxy and then be able to deliver traffic to the world, rather than to have the CDN connect to the origin the way they usually do. Apparently most CDNs already have custom and proprietary solutions for exactly this kind of feature, so maybe doing it in a standard way instead makes sense?
Resumable uploads
The draft explains the new proposed way to continue a previously interrupted upload over HTTP. The upload request gets a Location: header back for the resource being uploaded, and if it gets stopped prematurely, a client can then HEAD that resource, figure out the size and then do a second upload (using the PATCH method) request that tells the server that this transfer should start at offset X.
Exactly how this should be supported in browser’ upload forms seemed a little bit uncertain. For my own sake I can see a challenge to implement this nicely for curl in particular when the upload is using formpost upload (curl’s -F flag) which after all still is a very common way to do uploads on the current web. I’ll return to this topic at a later time when I written an implementation to test…
io_uring vs. multithreaded server runtimes vs HTTP mismatch
io_uring is a Linux asynchronous I/O framework that avoids the overhead of traditional system calls. It uses two shared ring buffers between user space and the kernel, allowing applications to batch I/O operations with zero-copy efficiency.
The feature is disabled by Google in ChromeOS, Android and in production Google servers which certainly holds back some use of it.
io_uring can be helpful to speed up things, but might be complicated to use in existing software architectures and the presentation went into some details on why this is so.
Modern UDP I/O for Firefox in Rust
A walk-through of some of the recent developments and improvements in Firefox’s UDP networking stack. Going from single datagrams to the modern ways to ship large chunks of data offloaded to the kernel to speed things up. Upload throughput in Firefox is up 60-90% over the last 11 releases. Lots of fun graphs and metrics were shown. This work is based on the quinn-udp stack.
Rollout of Happy Eyeballs v3 in Firefox
Happy Eyeballs v3 is coming and Firefox is implementing it. It now takes into account many more data sources than before, including alt-svc and HTTPS-RR and races connections against each other to use the one that connects first. There are some recommended timers in the specification and parts of the discussion was around how maybe the timers could instead be tightened a bit, and maybe the delay between the subsequent attempts could then use an exponential backoff instead sticking to a fixed interval?
(I know I’ll discuss some of these details with my curl hacker friends and see what we should adjust… curl already supports most of the Happy Eyeballs v3 specification.)
Shorter ones
As we approached the end of the day a few shorter topics were ventilated to give us a little more to consider before going home:
- Why is there no UTF8 in URIs? “If we would do it again, we would have allowed UTF8 in there” was said by someone who was there in the mid 1990s…
- Optimistic DNS is a draft. Use stale DNS cache data while getting the new. Connection remains alive for 120 seconds while DNS data is often not cached for even 30 seconds. No one in the room seemed to hate it. Let’s do this!
- The journey to QUERY. One of the primary authors of the RFC took us through what it took to make it happen. It was sixteen years since the most previous registered HTTP method and maybe this was the last one ever?
The end for this time
With this, the seventh HTTP workshop had ended. Again a very fine event. This time graciously sponsored and arranged by Adobe. Thank you everyone!
The general idea is to continue with these events roughly every second year and I support this. The HTTP workshops are definitely one of my favorite events.
Credits
The top image on this post was used in the final presentation and the author told me he is aware of the AI errors in there, “of which there are at least two”.