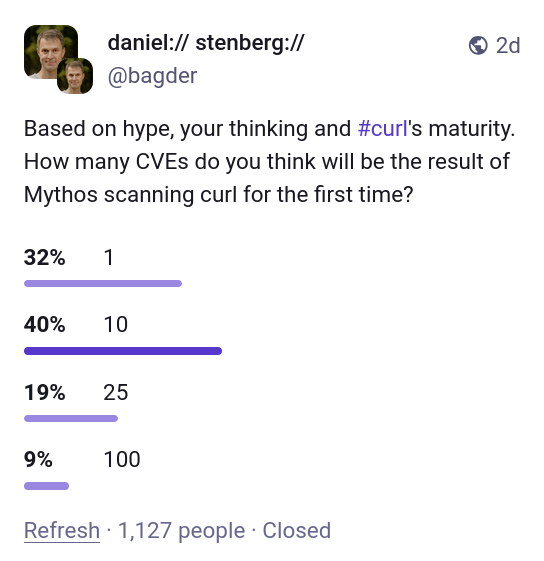
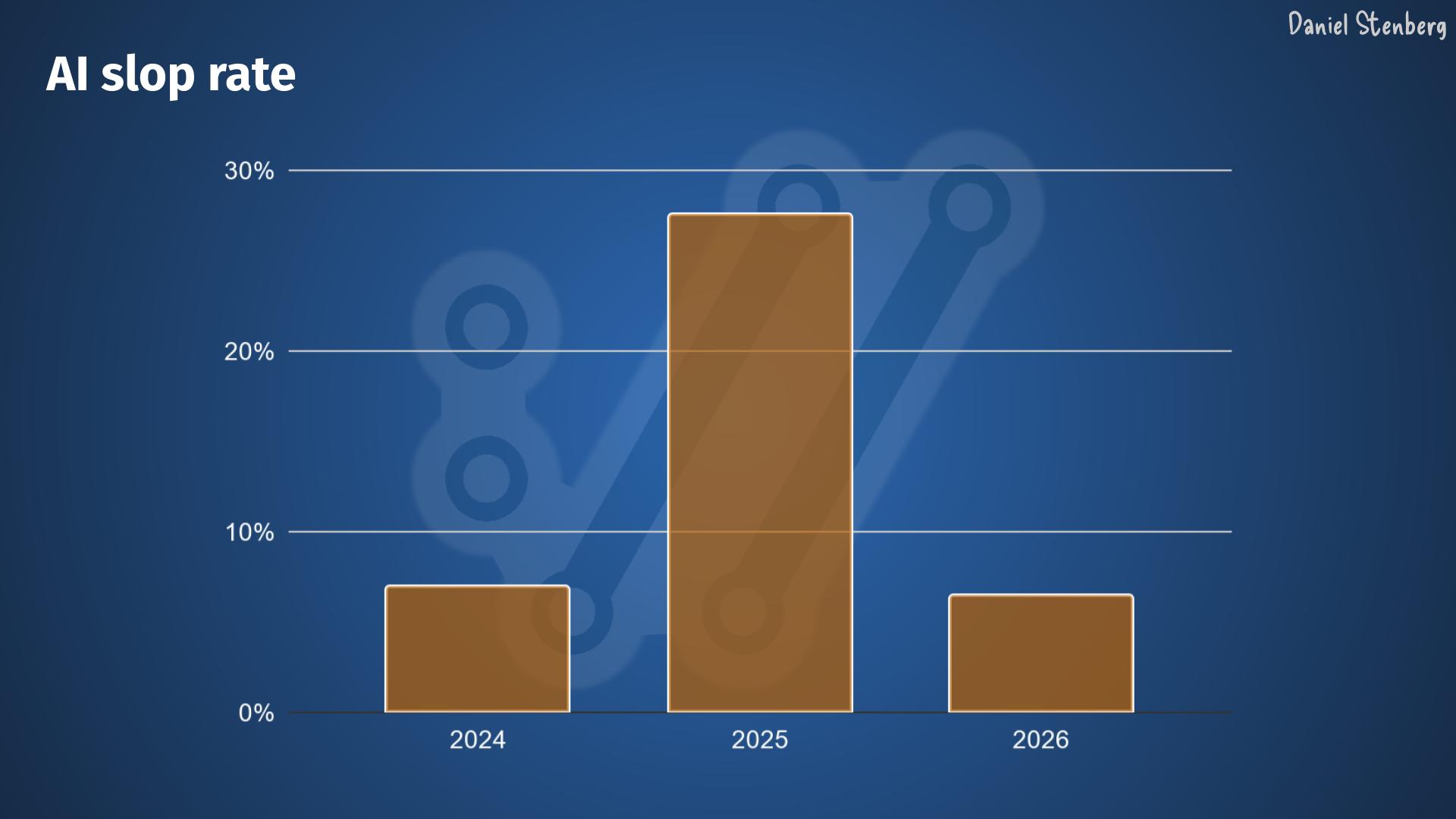
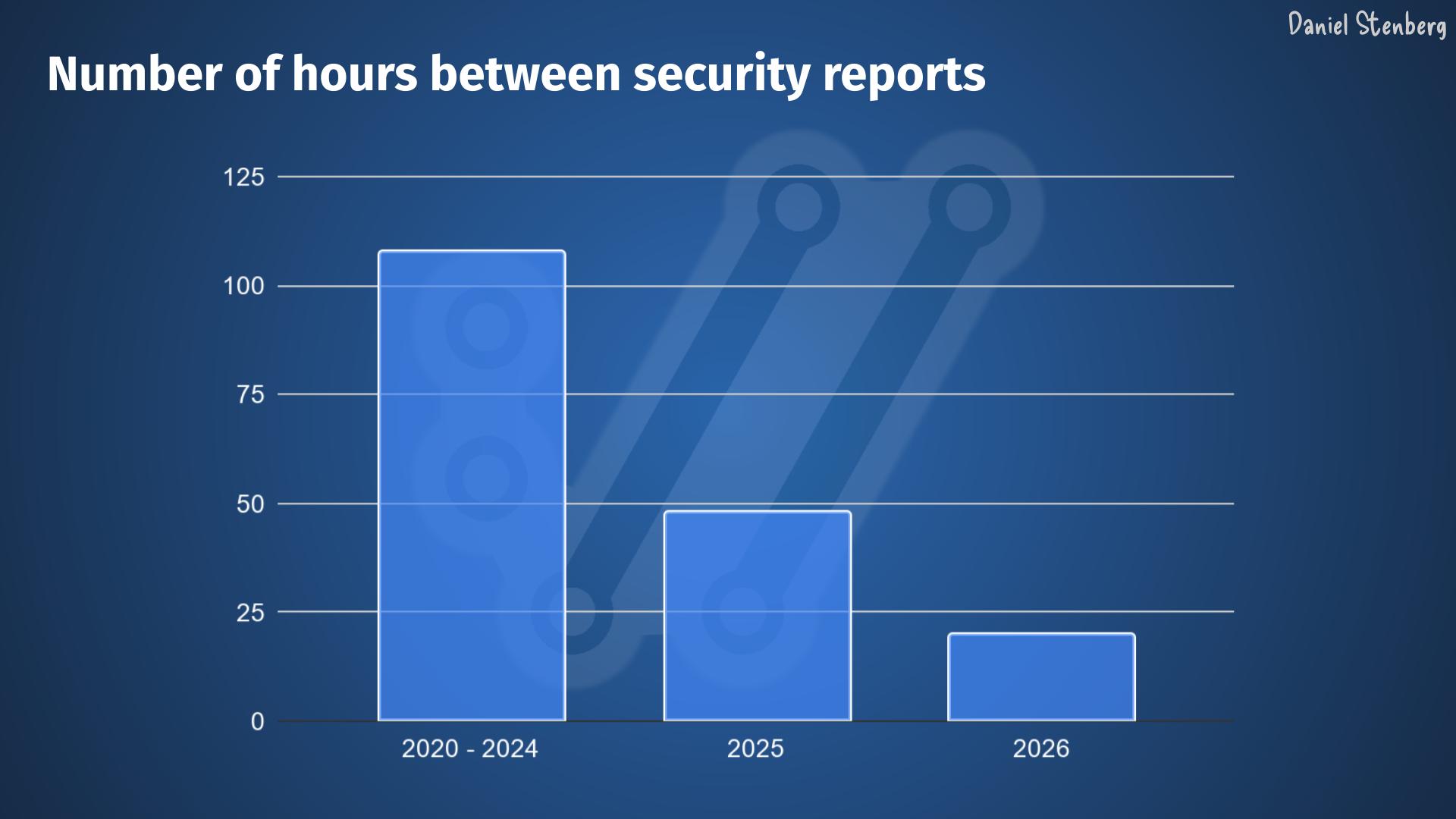
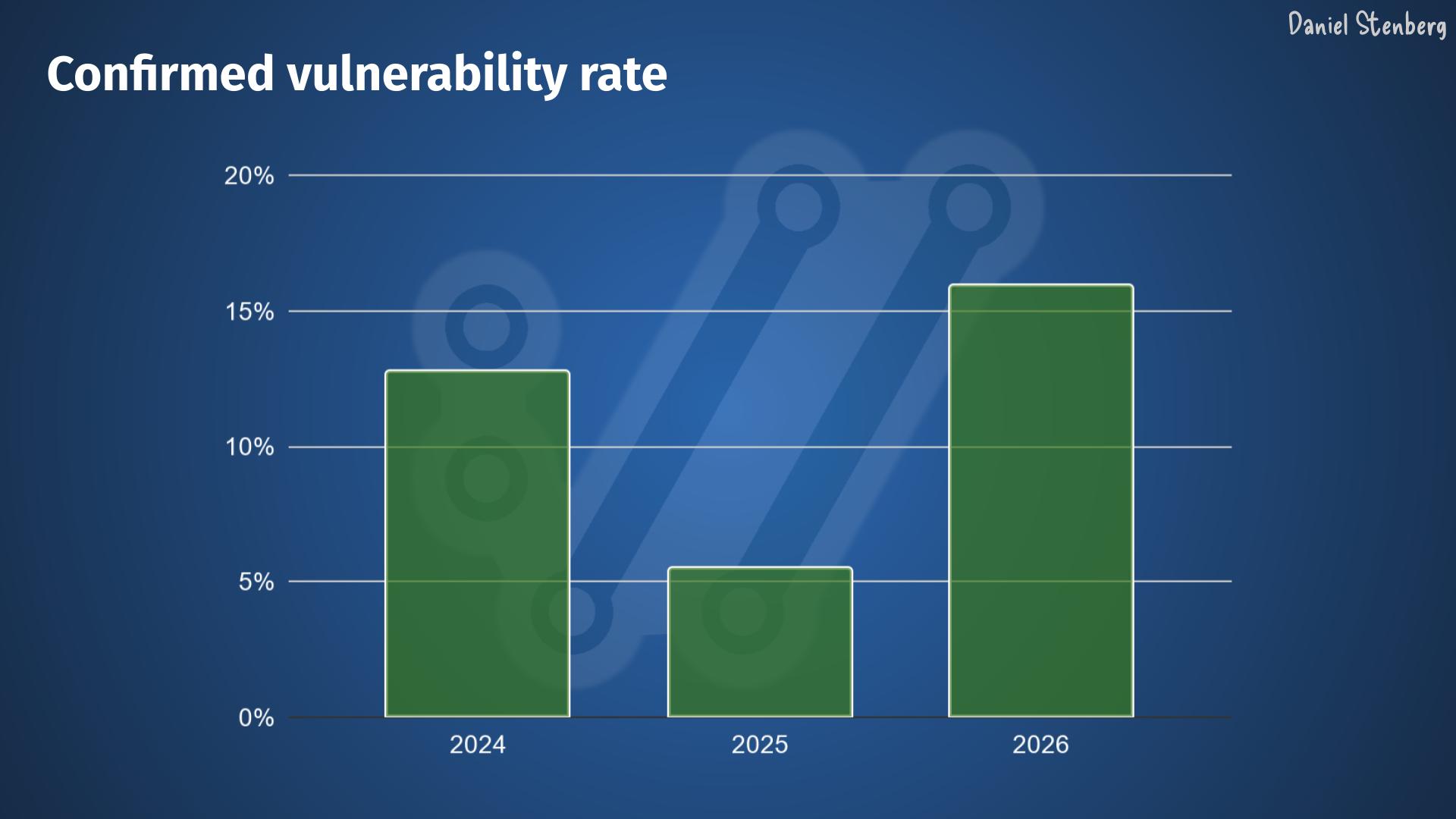
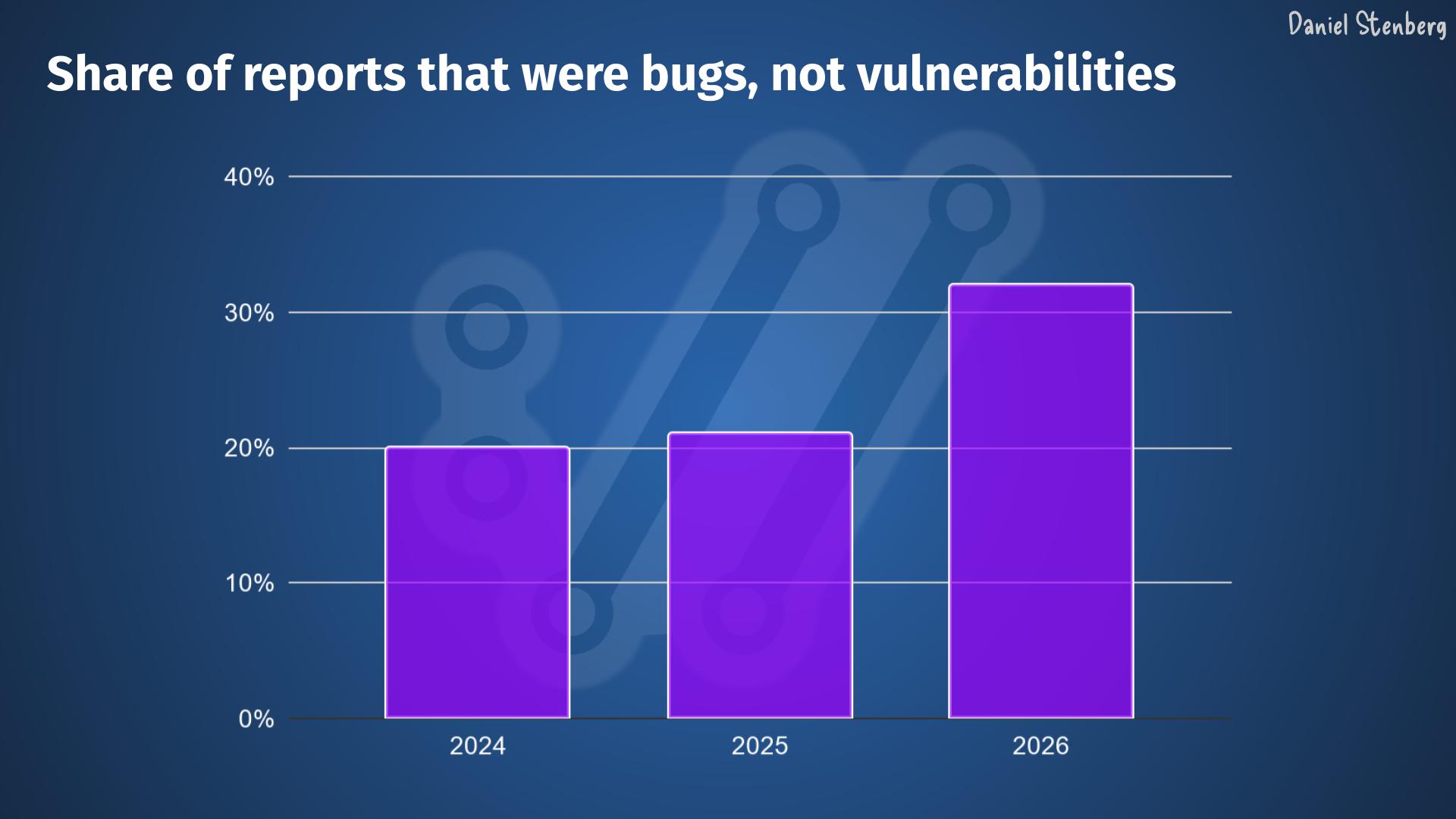
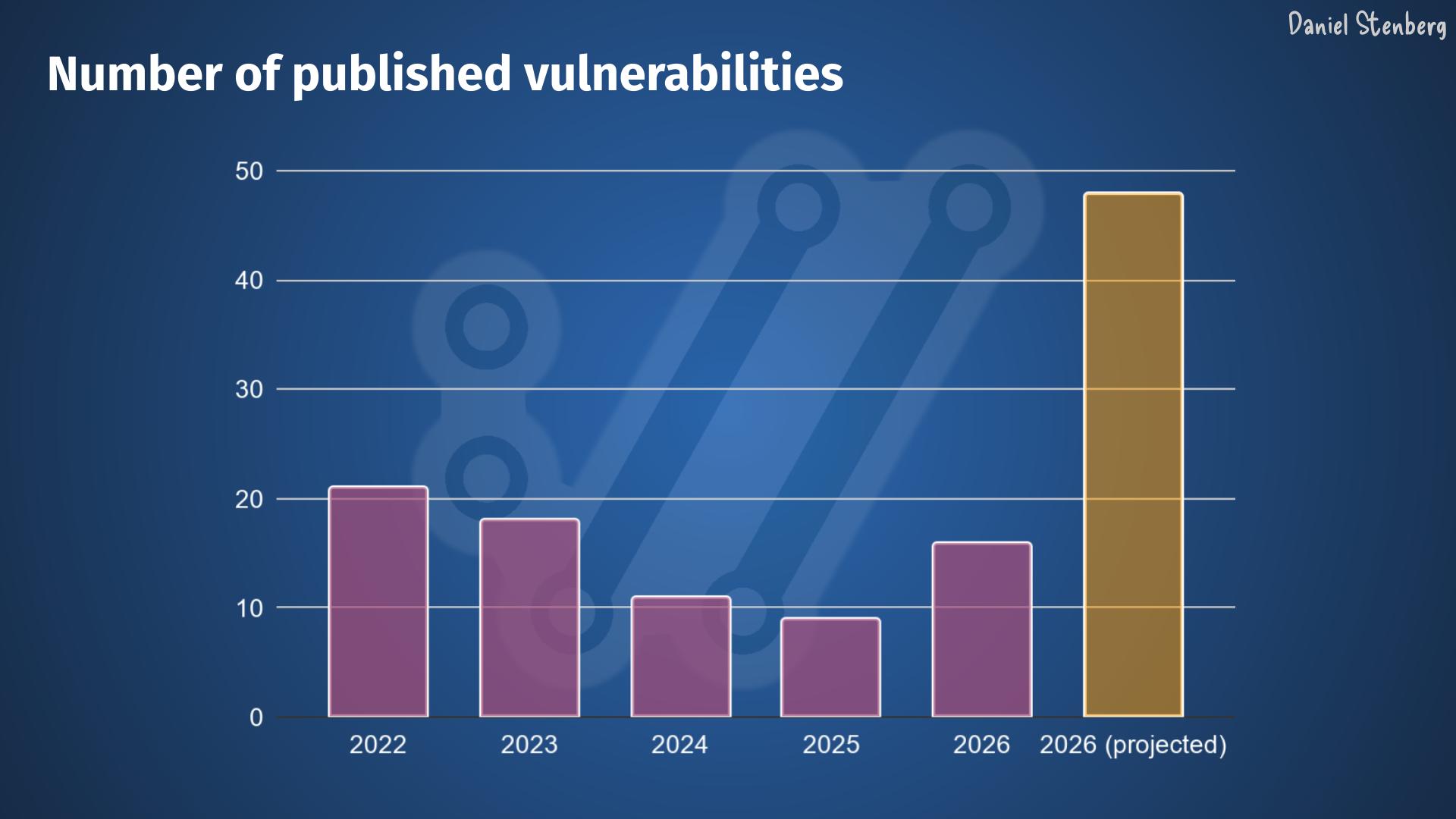
Over the years, we have received, read and handled way over one thousand vulnerability reports filed against curl. We have seen most kinds.
It is time for me to try to help future reporters by providing a short guide on how to submit a truly excellent vulnerability report to an Open Source project.
Researchers
We tend to call everyone who reports a security problem a security researcher, because by the act of the submission itself they fulfill the definition. There are however many different kinds of people who submit reports; from the most rookie youngster with limited experience, to the multi-decade experienced senior in the field.
Most reports submitted to a project like curl come from reporters who never submitted anything to the project before and are completely previously unknown. Many reporters use hacker handles or pseudonyms, so there is not a lot to learn about the person behind the report either. We don’t know the reporters’ age, experience level, employer, sex or on which continent they live. But also: none of those things matter.
When you submit a vulnerability report, consider telling the project how you want to get credited, should they consider your report real.
There is a potentially almost unlimited amount of security researchers that can find problems in a project. The project receiving your report only has a limited small number of overloaded maintainers that take care of the reports. Consider this imbalance. Make your report as easy as possible for the team to manage.
Finding
To us maintainers who receive a steady stream of vulnerability reports, it rarely matters exactly how the problem was detected. Whether you fell over it by accident, you found it by reading every single line of source code or if an AI pointed it out to you, it has little relevance to the security team. The team primarily cares about if the problem is real and if it is, how serious the impact is.
Really?
If the problem is documented, then it likely isn’t a vulnerability. This is a common theme in curl: people report that they can find something strange or peculiar to happen when they do something, only to have one of us point out that the action is either documented to have that side-effect, or the action was done in spite of clear warnings in the documentation.
To make a good vulnerability report, you should make sure you understand what the software is supposed to do – and what the documentation says its limitations and conditions are. A good Open Source project has those things documented.
Where
Figure out where and how to submit your report. If you found several problems, it is considered polite to ask the team how they want to receive the rest. As separate individual submissions or maybe as a curated list. Perhaps paced at a slow rate to avoid overflow.
Never circumvent the submission method suggested by the project. That is impolite.
Consider the initial submitting of the issue to be the first step in a multi-step communication process with the project that will continue for as long as at least one of your reported issues has not been resolved or dismissed. This can be days, weeks or in some cases even months.
Expect responses and follow-up questions. Be prepared to clarify, expand and maybe provide more code and reasoning. Remember that you submit vulnerability reports in order to help and improve the project.
Report
These days people like to create enormously long and detailed reports that have all the details, often explained three times and with several embedded lists using bullet points describing impact and providing more or less good analysis attempts.
Your first paragraph of the report should be a human-written, brief explainer of what the problem is and what badness it leads to. You should be able to explain that in just a few sentences. It is a reality-check, because if you can’t do this, if you don’t understand the flaw enough yourself to write such a paragraph, then you have homework to do. Figure it out, then come back and write the intro paragraph.
Having a quality intro saves a lot of time for the security team receiving your report.
Be aware that the Open Source project you contact may be overloaded, on vacation or seeing your report as yet another duplicate they already saw reported seven times.
Be helpful and respect that you add a load to a small team that probably consists of volunteers working on this in their spare time.
Even if you have used a lot of or just a little AI when finding the issue and writing up the report, you must make sure that you communicate as a human. With your human communication skills.
Reproducer
Your report should contain a reproducer. Ideally a fully contained and stand-alone script or source code that the security team can build and run to see the vulnerability trigger.
A reproducer helps prove to the team that the problem is real or maybe already an accepted risk or behavior. It is also convenient for the developers to first understand and reproduce the issue, and then they can convert the reproducer into a project test case for the pending fix.
Without providing a reproducer in your report, you instead push that work to the receiving end. We still need the reproducer. We still need a test case.
Patch
Provide a patch for the problem.
If you can figure out a way to fix the code to make your finding no longer trigger, that is great information for the security team and such a patch usually helps them understand the issue better and get a speedier result. It reduces the load.
Sure, such a patch is often perhaps not perfect and it can usually be improved and expanded as the developers have a different view and a more nuanced understanding of the problem and the software architecture involved. It still helps. Getting 80% towards the target is still valuable.
Versions
Usually you should look for vulnerabilities in the latest version of the software, often even using an up-to-date git repository. Whatever version you used to find it, you need to specify that in your report.
If the problem turns out to be real, which your report claims and you should never report anything if you don’t think so, it is then also immediately interesting to know when this problem first appeared. Which is the earliest version of the software that you can trigger this problem with?
The project will want to know this to write up a proper advisory for the issue. You can help figuring this out by bisecting etc.
Collaborate
Remain available after your initial submission.
In the curl project at least, we want to work with the reporter to make sure we get every angle and detail right. First, when trying to understand and assess the initial report and agreeing on a severity for it.
Then, we jointly produce and agree to a remedy (patch) for the problem, which ideally means taking the reporter’s version and massaging it into perfection.
If the problem is serious enough, there could be reasons to discuss a rushed patch release at an earlier date than the pending release would otherwise happen on. To reduce the time users in the wild remain vulnerable.
Finally, we collaborate on the description and explainer for the problem that goes into the security advisory.
Advisory
For every CVE that is registered and assigned to a particular vulnerability, there needs to be a detailed security advisory written. It should ideally describe the issue, how it triggers, what it means, the impact, the affected version ranges and more. Everything related to the vulnerability that we can think might help users.
Your job as a security researcher is to make sure the description in the advisory matches your finding, your understanding of the problem and that the description is understandable.
Learn
For every confirmed security report, the receiving project will try to learn from it and fix code and practices to avoid making the same mistake again.
As a reporter, your job is to learn from the submission experience and try to improve your reporting procedure and approach for the next time.
Then submit your next report!