An external security audit focused especially on curl’s HTTP/3 components and associated source code was recently concluded by Trail of Bits. In particular on the HTTP/3 related curl code that uses and interfaces the ngtcp2 and nghttp3 libraries, as that is so far the only HTTP/3 backend in curl that is not labeled as experimental. The audit was sponsored by the Sovereign Tech Fund via OSTIF.
The audit revealed no major discoveries or security problems but led to improved fuzzing and a few additional areas are noted as suitable to improve going forward. Maybe in particular in the fuzzing department. (If you’re looking for somewhere to contribute to curl, there’s your answer!)
The audit revealed that we had accidentally drastically shrunk the fuzzing coverage a while back without even noticing – which we of course immediately rectified. When fixed, we fortunately did not get an explosion in issues (phew!), which thus confirmed that we had not messed up in any particular way while the fuzzing ability had been limited. But still: several man weeks of professional code inspection and no serious flaws were detected. I am thrilled over this fact.
Because of curl’s use of third party libraries for doing QUIC and HTTP/3, the report advises that there should be follow-up audits of the involved libraries. Fair proposal, but that is of course something that is beyond what we as a project can do.
Trail of Bits is professional and a pleasure to work with. Now having done it twice, I have nothing but good things to say about the team we have worked with.
From curl’s side, I would like to also highlight and thank Stefan Eissing and Dan Fandrich for participating in the process.
The full report is available on the curl website, here.
The third
This is (quite fittingly since it is for HTTP/3) the third external security audit performed on curl source code, even if this was more limited in scope than the previous ones done in 2016 and 2022. Quite becomingly, the amount of detected important issues have decreased for every new audit. We love scrutiny and we take security seriously. I think this shows in the audit reports.
I keep insisting that the CVE system is broken and that the database of existing CVEs hosted by MITRE (and imported into lots of other databases) is full of questionable content and plenty of downright lies. A primary explanation for us being in this ugly situation is that it is simply next to impossible to get rid of invalid CVEs.
First this
I already wrote about the bogus curl CVE-2020-1909 last year and how it was denied being rejected because someone without a name at MITRE obviously knows the situation much better than any curl developer. This situation then forces us, the curl project, to provide documentation to explain how this is a documented CVE but it is not a vulnerability. Completely contrary to the very idea of CVEs.
A sane system would have a concept where rubbish is scrubbed off.
Now this
The curl project registered for and became a CNA in mid January 2024 to ideally help us filter out bad CVE input better. The future will tell if this effort works or not. (It was also recently highlighted that the Linux kernel is now also a CNA for similar reasons and I expect to see many more Open Source projects go the same route.)
However, in late December 2023, just weeks before we became CNA, someone (anonymous again) requested a CVE Id from MITRE for a curl issue. Sure enough they were immediately given CVE-2023-52071, according to how the system works.
This CVE was made public on January 30 2024, and the curl project was of course immediately made aware of it. A quick glance on the specifics was all we needed: this is another bogus claim. This is not a security problem and again this is a fact that does not require an experienced curl developer to analyze, it is quite easily discoverable.
Given the history of previous bogus CVEs, I was soon emailed by CVE db companies asking me for confirmations about this CVE and I was of course honest and told them that no, this is not a security problem. Do not warn your users about this.
We are a CNA now, meaning that we should be able to control curl issues better, even if this CVE was requested before we were officially given the keys to the kingdom. We immediately requested this CVE to be rejected. On the grounds that it was wrongly assigned in the first place.
“Will provide some confusion”
In the first response from MITRE to our rejection request, they insisted that:
We discussed this internally and believe it does deserve a CVE ID. If we transfer, and Curl REJECTS, then the reporter will likely come back to us and dispute which will provide some confusion for the public.
They actually think putting DISPUTED on the issue is less confusing to the public than rejecting it, because rejecting risks an appeal from the original reporter?
They say in this response that they think it actually deserves a CVE Id. If there was any way to have a conversation with these guys I would like to ask them on what grounds they base this on. Then lecture them on how the world works.
This communication has only been done indirectly with MITRE via our root CNA (Red Hat).
DISPUTED vs REJECTED
So it did not fly.
According to the MITRE guidelines: When one party disagrees with another party’s assertion that a particular issue is a vulnerability, a CVE Record assigned to that issue may be designated with a “DISPUTED” tag.
If someone says the earth is flat, we need to say that fact is disputed? No it is not. It is plain wrong. Incorrect. Bad. Stupid. Silly. Remove-the-statement worthy.
This meant I needed to take the fight to the next level. This policy is not good enough and it needs to be adjusted. This is not a disagreement on the facts. I insist that this is not a vulnerability to begin with. It was wrongly assigned a CVE in the first place. It feels ridiculous that the burden of proof falls on me to prove how this is not a security problem instead of the other way around: if someone would just have had the spine to ask the original submitter to explain, prove, hint or suggest how this is a vulnerability then it would never have been a CVE created for this in the first place. Because that person could not have done that.
The plain truth is that there is no system for doing this. There is no requirement on the individual to actually back up or explain what they claim. The system is designed for good-faith reporters against bad-faith product organizations. So that bad companies cannot shut down whistleblowers basically. Instead it allows irresponsible or bad-faith reporters populate the CVE database with rubbish.
Once the CVE is in, the product organization, like curl here, is not allowed to REJECT it. We have to go the lame route and say that the facts in the CVE are DISPUTED. We are apparently in disagreement whether the totally incorrect claim is totally incorrect or not. Bizarre.
Did I mention this is a broken system?
Elevated
Being a CNA at least means we have a foot in the door. An issue has been filed against the policy and guidelines and it has been elevated at MITRE via our root CNA (Red Hat). I cannot say if this eventually will make a difference or not, but I have decided to “take one for the team” and spend this time and effort on this case in the belief that if we manage to nudge the process ever so slightly in the right direction, it could be worth it.
For the sake of everyone. For the sake of my sanity.
Documented
In the curl documentation for CVE-2023-52071, which we unwittingly have to provide even though the issue is bogus, I have included this whole story including quoting the motivations from my email to MITRE as to why this CVE should be rejected in spite of the current procedure not allowing us to.
Future
Hopefully, supposedly, ideally, crossing my fingers, future CVEs against curl or libcurl will immediately be passed via us since we are now a CNA. This is how it is supposed to work. We will of course immediately and with no mercy reject and refuse all attempts in filing silly CVEs for issues that aren’t vulnerabilities.
The “elevated issue” above might (hopefully) lead to non-CNA organizations getting an increased ability to filter off junk from the system – and then perhaps lessen the need for the entire world to become CNAs. I am not overly optimistic that we will reach that position anytime soon, as clearly the system has worked like this for a long time and I expect resistance to change.
I can almost guarantee that I will write more blog posts about CVEs in the future. Hopefully when I have great news about updated CVE rejection policies.
Update
(Feb 23, 21:33 UTC) The CVE records have now been updated by MITRE and according to NVD for example, this CVE is now REJECTED. Wow.
I was not told about this, someone in a discussion thread mentioned it.
The curl project has been accepted as a CVE Numbering Authority (CNA) for vulnerabilities in all products directly made or managed by the project. If I’m counting correctly, we are the 351st CNA.
The official announcement from Mitre states: curl is now a CVE Numbering Authority (CNA) for all products made and managed by the curl project. This includes curl, libcurl, and trurl.
In plain English, this means that we will reserve and manage our own CVEs in the future directly against the CVE database with no middle man, and also that we have a scope for CVEs that is our territory: curl and libcurl. No one else can now register CVEs for our products – without involving us. (There’s an appeals process so someone can still actually file CVEs for issues even if we say no, but at least there’s a process where both sides will argue their points.)
We do not particularly want to be a CNA but we hope that this move will make it harder to file more stupid curl CVEs in the future.
I have held back on writing anything about AI or how we (not) use AI for development in the curl factory. Now I can’t hold back anymore. Let me show you the most significant effect of AI on curl as of today – with examples.
Bug Bounty
Having a bug bounty means that we offer real money in rewards to hackers who report security problems. The chance of money attracts a certain amount of “luck seekers”. People who basically just grep for patterns in the source code or maybe at best run some basic security scanners, and then report their findings without any further analysis in the hope that they can get a few bucks in reward money.
We have run the bounty for a few years by now, and the rate of rubbish reports has never been a big problem. Also, the rubbish reports have typically also been very easy and quick to detect and discard. They have rarely caused any real problems or wasted our time much. A little like the most stupid spam emails.
Our bug bounty has resulted in over 70,000 USD paid in rewards so far. We have received 415 vulnerability reports. Out of those, 64 were ultimately confirmed security problems. 77 of the report were informative, meaning they typically were bugs or similar. Making 66% of the reports neither a security issue nor a normal bug.
Better crap is worse
When reports are made to look better and to appear to have a point, it takes a longer time for us to research and eventually discard it. Every security report has to have a human spend time to look at it and assess what it means.
The better the crap, the longer time and the more energy we have to spend on the report until we close it. A crap report does not help the project at all. It instead takes away developer time and energy from something productive. Partly because security work is consider one of the most important areas so it tends to trump almost everything else.
A security report can take away a developer from fixing a really annoying bug. because a security issue is always more important than other bugs. If the report turned out to be crap, we did not improve security and we missed out time on fixing bugs or developing a new feature. Not to mention how it drains you on energy having to deal with rubbish.
AI generated security reports
I realize AI can do a lot of good things. As any general purpose tool it can also be used for the wrong things. I am also sure AIs can be trained and ultimately get used even for finding and reporting security problems in productive ways, but so far we have yet to find good examples of this.
Right now, users seem keen at using the current set of LLMs, throwing some curl code at them and then passing on the output as a security vulnerability report. What makes it a little harder to detect is of course that users copy and paste and include their own language as well. The entire thing is not exactly what the AI said, but the report is nonetheless crap.
Detecting AI crap
Reporters are often not totally fluent in English and sometimes their exact intentions are hard to understand at once and it might take a few back and fourths until things reveal themselves correctly – and that is of course totally fine and acceptable. Language and cultural barriers are real things.
Sometimes reporters use AIs or other tools to help them phrase themselves or translate what they want to say. As an aid to communicate better in a foreign language. I can’t find anything wrong with that. Even reporters who don’t master English can find and report security problems.
So: just the mere existence of a few give-away signs that parts of the text were generated by an AI or a similar tool is not an immediate red flag. It can still contain truths and be a valid issue. This is part of the reason why a well-formed crap report is harder and takes longer to discard.
Exhibit A: code changes are disclosed
In the fall of 2023, I alerted the community about a pending disclosure of CVE-2023-38545. A vulnerability we graded severity high.
The day before that issue was about to be published, a user submitted this report on Hackerone: Curl CVE-2023-38545 vulnerability code changes are disclosed on the internet
That sounds pretty bad and would have been a problem if it actually was true.
The report however reeks of typical AI style hallucinations: it mixes and matches facts and details from old security issues, creating and making up something new that has no connection with reality. The changes had not been disclosed on the Internet. The changes that actually had been disclosed were for previous, older, issues. Like intended.
In this particular report, the user helpfully told us that they used Bard to find this issue. Bard being a Google generative AI thing. It made it easier for us to realize the craziness, close the report and move on. As can be seen in the report log, we did have to not spend much time on researching this.
Exhibit B: Buffer Overflow Vulnerability
A more complicated issue, less obvious, done better but still suffering from hallucinations. Showing how the problem grows worse when the tool is better used and better integrated into the communication.
On the morning of December 28 2023, a user filed this report on Hackerone: Buffer Overflow Vulnerability in WebSocket Handling. It was morning in my time zone anyway.
Again this sounds pretty bad just based on the title. Since our WebSocket code is still experimental, and thus not covered by our bug bounty it helped me to still have a relaxed attitude when I started looking at this report. It was filed by a user I never saw before, but their “reputation” on Hackerone was decent – this was not their first security report.
The report was pretty neatly filed. It included details and was written in proper English. It also contained a proposed fix. It did not stand out as wrong or bad to me. It appeared as if this user had detected something bad and as if the user understood the issue enough to also come up with a solution. As far as security reports go, this looked better than the average first post.
In the report you can see my first template response informing the user their report had been received and that we will investigate the case. When that was posted, I did not yet know how complicated or easy the issue would be.
Nineteen minutes later I had looked at the code, not found any issue, read the code again and then again a third time. Where on earth is the buffer overflow the reporter says exists here? Then I posted the first question asking for clarification on where and how exactly this overflow would happen.
After repeated questions and numerous hallucinations I realized this was not a genuine problem and on the afternoon that same day I closed the issue as not applicable. There was no buffer overflow.
I don’t know for sure that this set of replies from the user was generated by an LLM but it has several signs of it.
Ban these reporters
On Hackerone there is no explicit “ban the reporter from further communication with our project” functionality. I would have used it if it existed. Researchers get their “reputation” lowered then we close an issue as not applicable, but that is a very small nudge when only done once in a single project.
I have requested better support for this from Hackerone. Update: this function exists, I just did not look at the right place for it…
Future
As these kinds of reports will become more common over time, I suspect we might learn how to trigger on generated-by-AI signals better and dismiss reports based on those. That will of course be unfortunate when the AI is used for appropriate tasks, such as translation or just language formulation help.
I am convinced there will pop up tools using AI for this purpose that actually work (better) in the future, at least part of the time, so I cannot and will not say that AI for finding security problems is necessarily always a bad idea.
I do however suspect that if you just add an ever so tiny (intelligent) human check to the mix, the use and outcome of any such tools will become so much better. I suspect that will be true for a long time into the future as well.
I have no doubts that people will keep trying to find shortcuts even in the future. I am sure they will keep trying to earn that quick reward money. Like for the email spammers, the cost of this ends up in the receiving end. The ease of use and wide access to powerful LLMs is just too tempting. I strongly suspect we will get more LLM generated rubbish in our Hackerone inboxes going forward.
You know I spend all my days working on curl and related matters. I also spend a lot of time thinking on the project; like how we do things and how we should do things.
The security angle of this project is one of the most crucial ones and an area where I spend a lot of time and effort. Dealing with and assessing security reports, handling the verified actual security vulnerabilities and waiving off the imaginary ones.
150 vulnerabilities
The curl project recently announced its 150th published security vulnerability and its associated CVE. 150 security problems through a period of over 25 years in a library that runs in some twenty billion installations? Is that a lot? I don’t know. Of course, the rate of incoming security reports is much higher in modern days than it was decades ago.
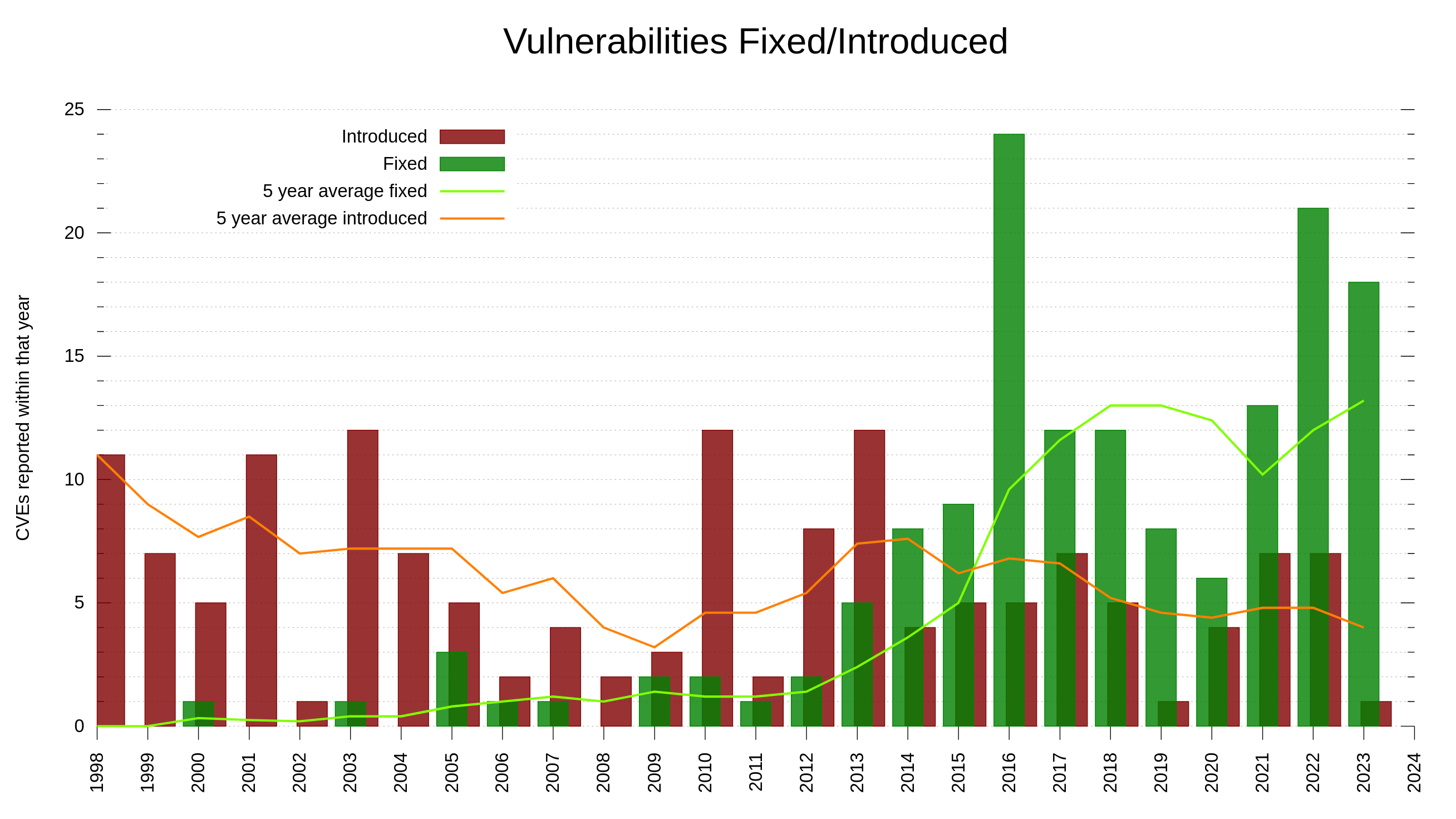
150 curl vulnerabilities, when they were introduced and when they were fixed.
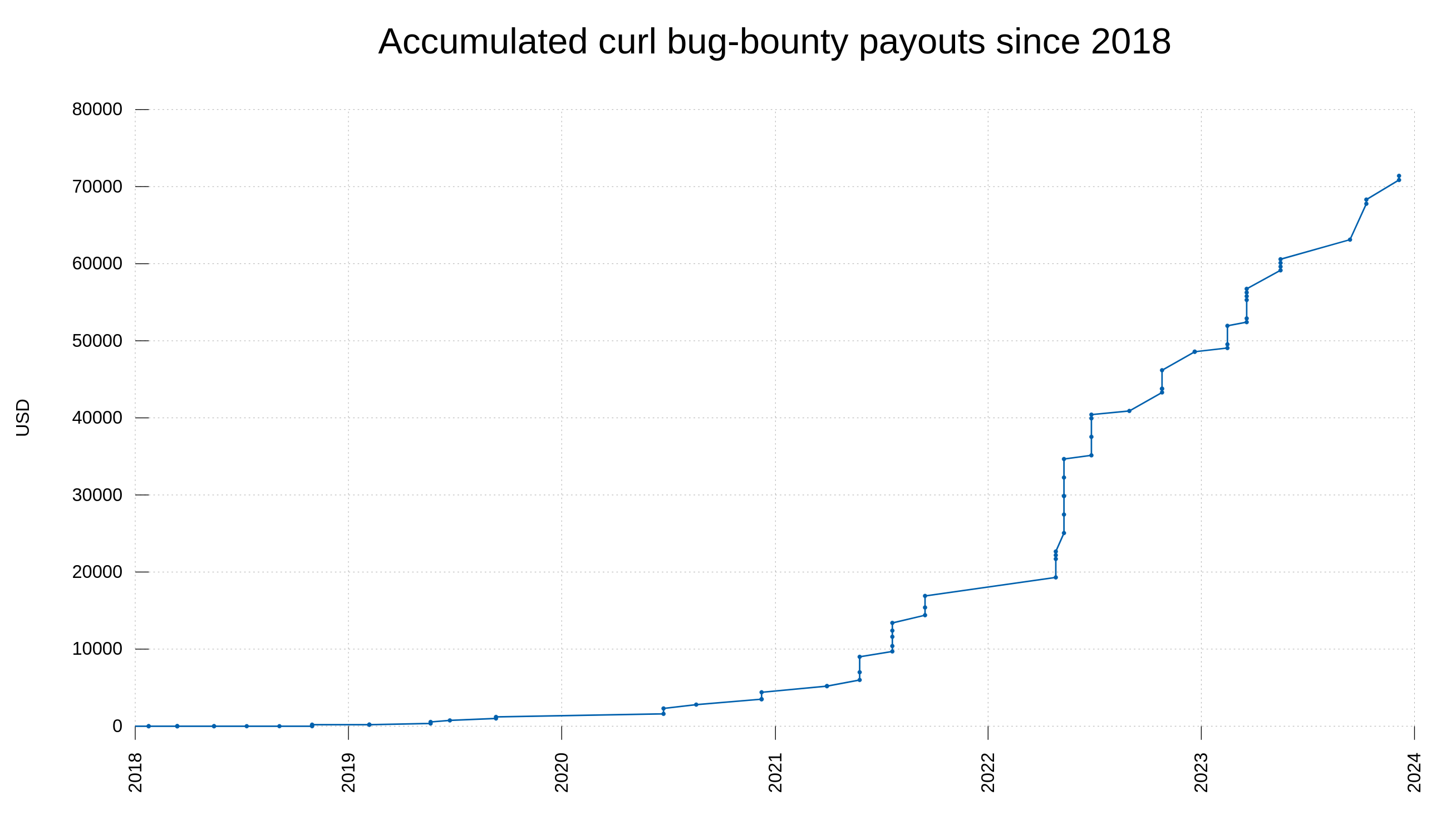
Out of the 150 published vulnerabilities, 60 were reported and awarded money through our bug-bounty program. In total, the curl bug-bounty has of today paid 71,400 USD to good hackers and security researchers. The monetary promise is an obvious attraction to researchers. I suppose the fact that curl also over time has grown to run in even more places, on more architectures and in even more systems also increases people’s interest in looking into and scrutinize our code. curl is without doubt one of the world’s most widely installed software components. It requires scrutiny and control. Do we hold up our promises?
The amount of money paid by curl in bug bounties since 2018
curl is a C program running in virtually every internet connect device you can think of.
Trends
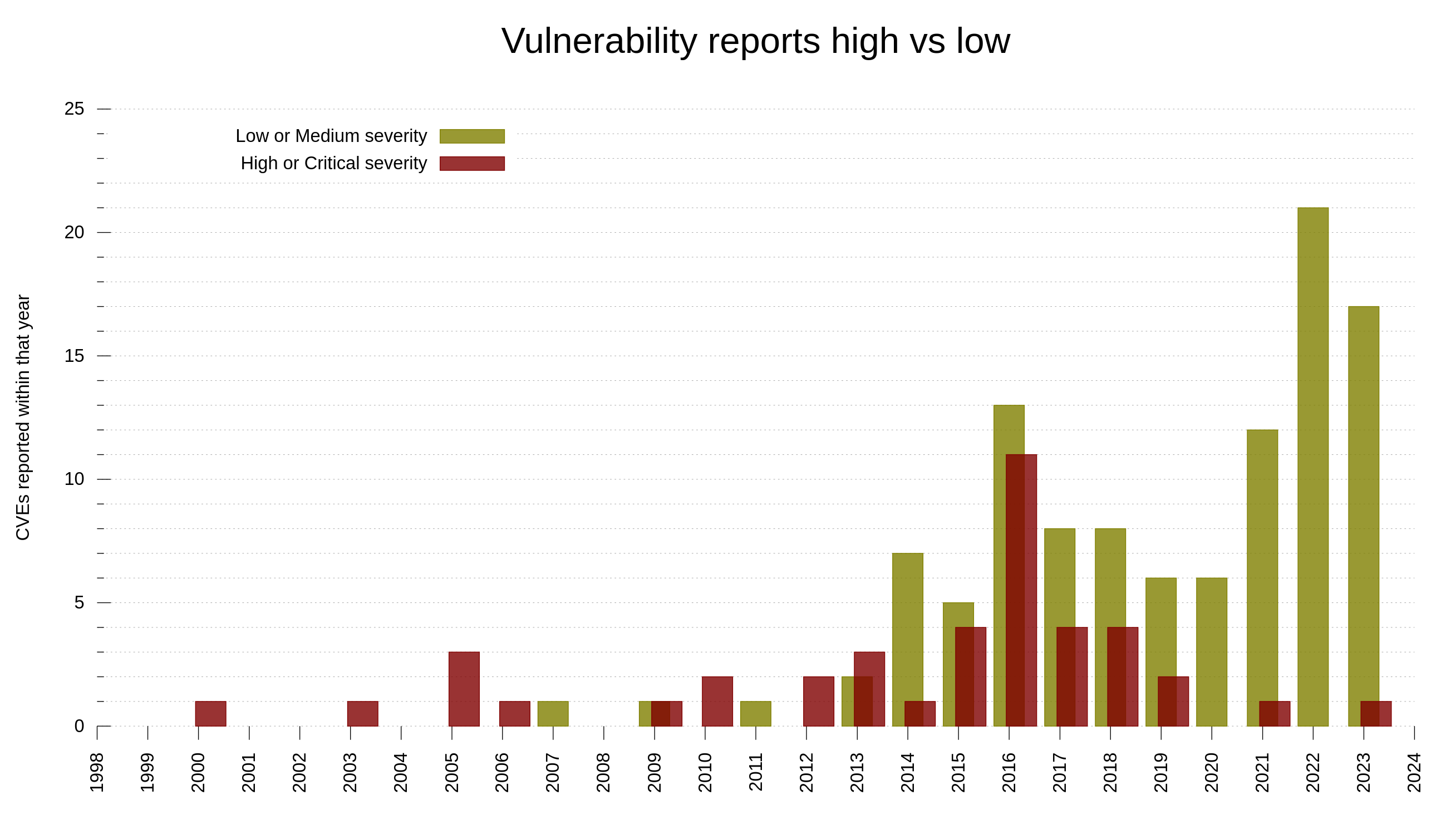
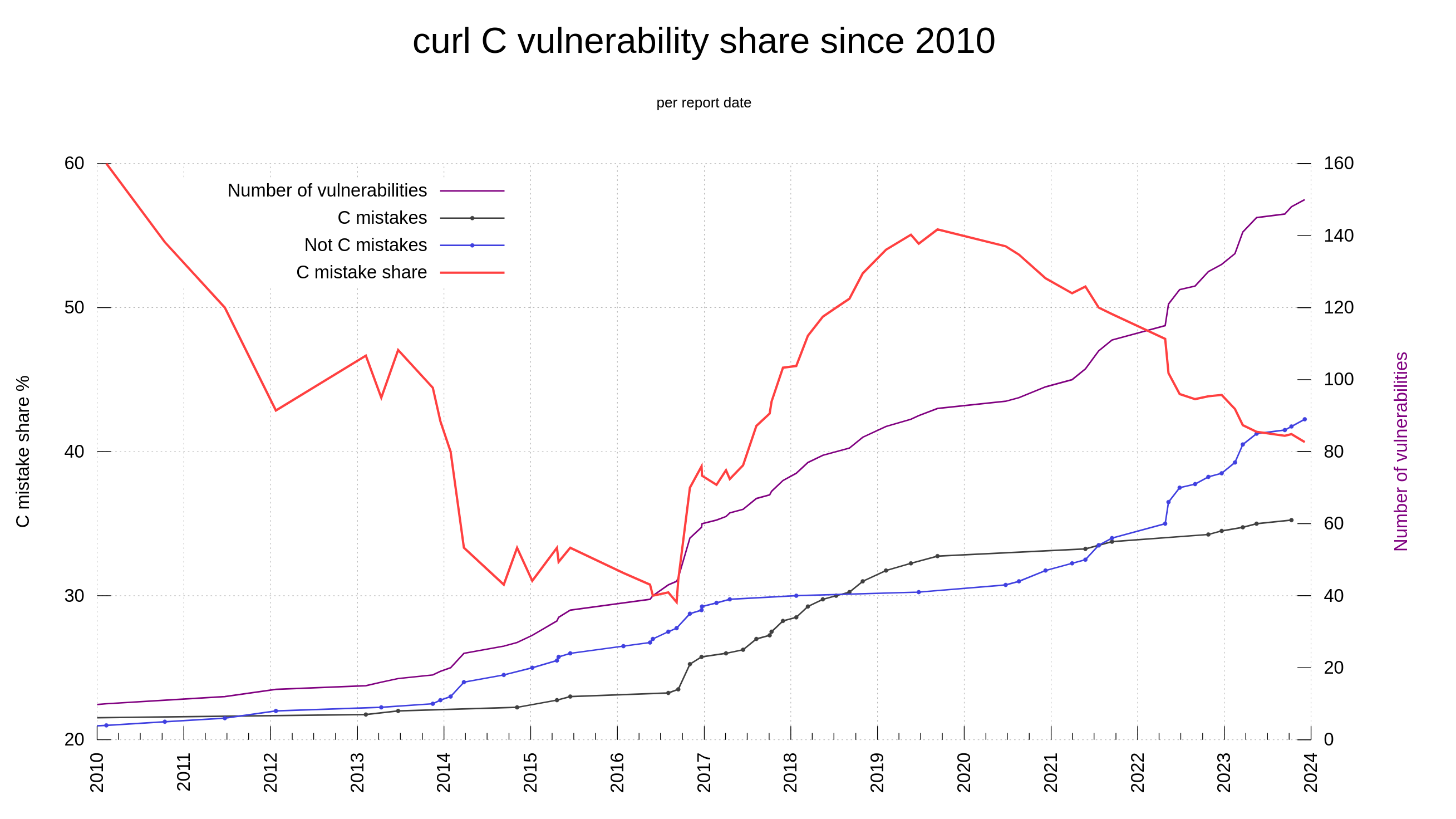
Another noticeable trend among the reports the last decade is that we are getting way more vulnerabilities reported with severity level low or medium these days, while historically we got more ones rated high or even critical. I think this is partly because of the promise of money but also because of a generally increased and sharpened mindset about security. Things that in the past would get overlooked and considered “just a bug” are nowadays more likely to get classified as security problems. Because we think about the problems wearing our security hats much more now.
curl vulnerabilities, distribution of reports low/medium vs high/critical
Memory-safety
Every time we publish a new CVE people will ask about when we will rewrite curl in a memory-safe language. Maybe that is good, it means people are aware and educated on these topics.
I will not rewrite curl. That covers all languages. I will however continue to develop it, also in terms of memory-safety. This is what happens:
We add support for more third party libraries written in memory-safe languages. Like the quiche library for QUIC and HTTP/3 and rustls for TLS.
We are open to optionally supporting a separate library instead of native code, where that separate library could be written in a memory-safe language. Like how we work with hyper.
We keep improving the code base with helper functions and style guides to reduce risks in the C code going forward. The C code is likely to remain with us for a long time forward, no matter how much the above mention areas advance. Because it is the mature choice and for many platforms still the only choice. Rust is cool, but the language, its ecosystem and its users are rookies and newbies for system library level use.
Step 1 and 2 above means that over time, the total amount of executable code in curl gradually can become more and more memory-safe. This development is happening already, just not very fast. Which is also why number 3 is important and is going to play a role for many years to come. We move forward in all of these areas at the same time, but with different speeds.
Why no rewrite
Because I’m not an expert on rust. Someone else would be a much more suitable person to lead such a rewrite. In fact, we could suspect that the entire curl maintainer team would need to be replaced since we are all old C developers maybe not the most suitable to lead and take care of a twin project written in rust. Dedicated long-term maintainer internet transfer library teams do not grow on trees.
Because rewriting is an enormous project that will introduce numerous new problems. It would take years until the new thing would be back at a similar level of rock solid functionality as curl is now.
During the initial years of the port’s “beta period”, the existing C project would continue on and we would have two separate branches to maintain and develop, more than doubling the necessary work. Users would stay on the first version until the second is considered stable, which will take a long time since it cannot become stable until it gets a huge amount of users to use it.
There is quite frankly very little (if any) actual demand for such a rewrite among curl users. The rewrite-it-in-rust mantra is mostly repeated by rust fans and people who think this is an easy answer to fixing the share of security problems that are due to C mistakes. Typically, the kind who has no desire or plans to participate in said venture.
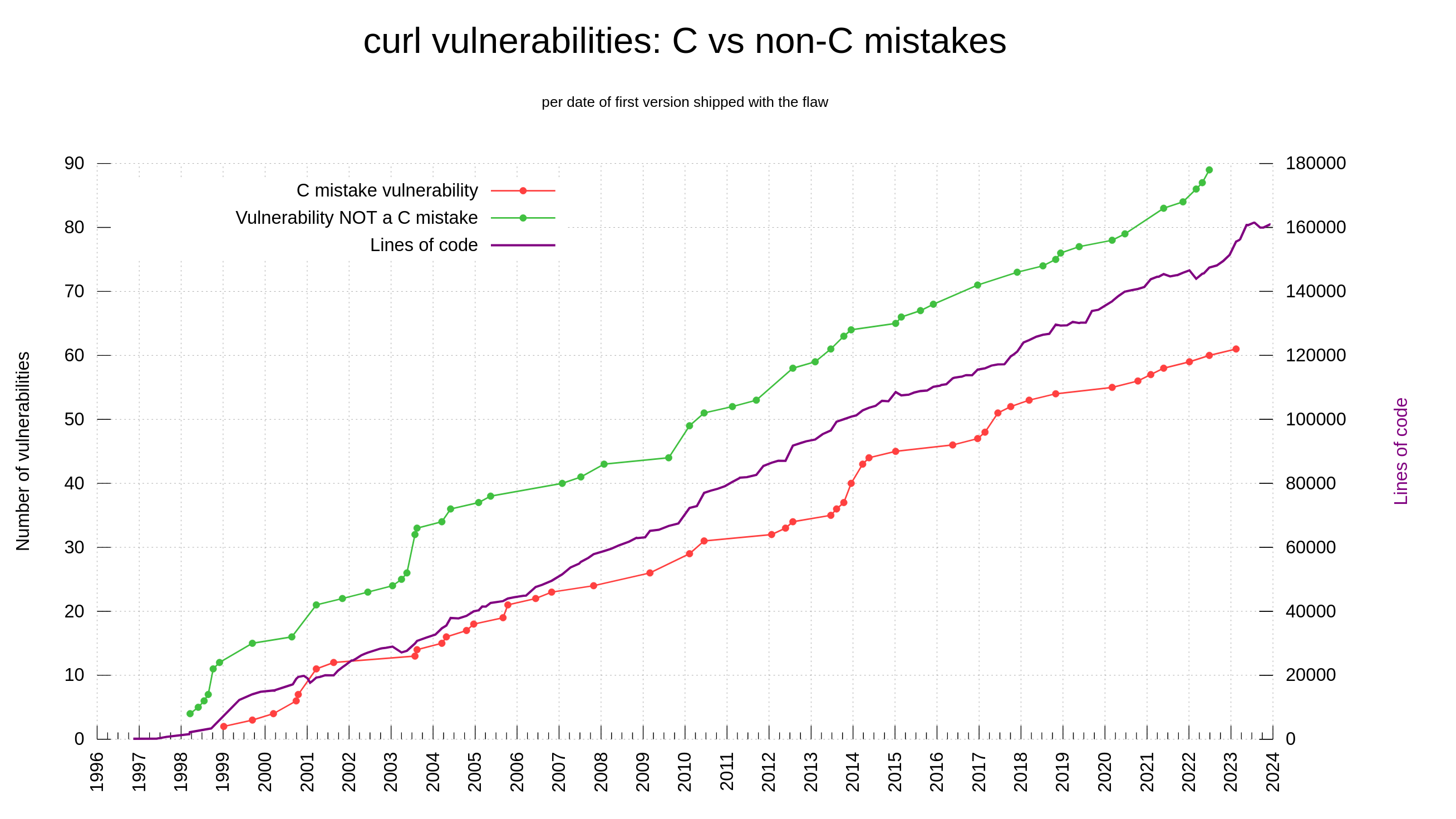
C is unsafe and always will be
The C programming language is not memory-safe. Among the 150 reported curl CVEs, we have determined that 61 of them are “C mistakes”. Problems that most likely would not have happened had we used a memory-safe language. 40.6% of the vulnerabilities in curl reported so far could have been avoided by using another language.
Rust is virtually the only memory-safe language that is starting to become viable. C++ is not memory-safe and most other safe languages are not suitable for system/library level use. Often because how they fail to interface well with existing C/C++ code.
By June 2017 we had already made 51 C mistakes that ended up as vulnerabilities and at that time Rust was not a viable alternative yet. Meaning that for a huge portion of our problems, Rust was too late anyway.
The curl vulnerabilities that are C mistakes and those that are not, per date of introduction
40 is not 70
In lots of online sources people repeat that when writing code with C or C++, the share of security problems due to lack of memory-safety is in the range 60-70% of the flaws. In curl, looking per the date of when we introduced the flaws (not reported date), we were never above 50% C mistakes. Looking at the flaw introduction dates, it shows that this was true already back when the project was young so it’s not because of any recent changes.
If we instead count the share per report-date, the share has fluctuated significantly over time, as then it has depended on when people has found which problems. In 2010, the reported problems caused by C mistakes were at over 60%.
The curl vulnerabilities that are C mistakes and those that are not, per date of reporting
Of course, curl is a single project and not a statistical proof of any sort. It’s just a 25 year-old project written in C with more knowledge of and introspection into these details than most other projects.
Additionally, the share of C mistakes is slightly higher among the issues rated with higher severity levels: 51% (22 of 43) of the issues rated high or critical was due to C mistakes.
Help curl authors do better
We need to make it harder to write bad C code and easier to write correct C code. I do not only speak of helping others, I certainly speak of myself to a high degree. Almost every security problem we ever got reported in curl, I wrote. Including most of the issues caused by C mistakes. This means that I too need help to do right.
I have tried to learn from past mistakes and look for patterns. I believe I may have identified a few areas that are more likely than others to cause problems:
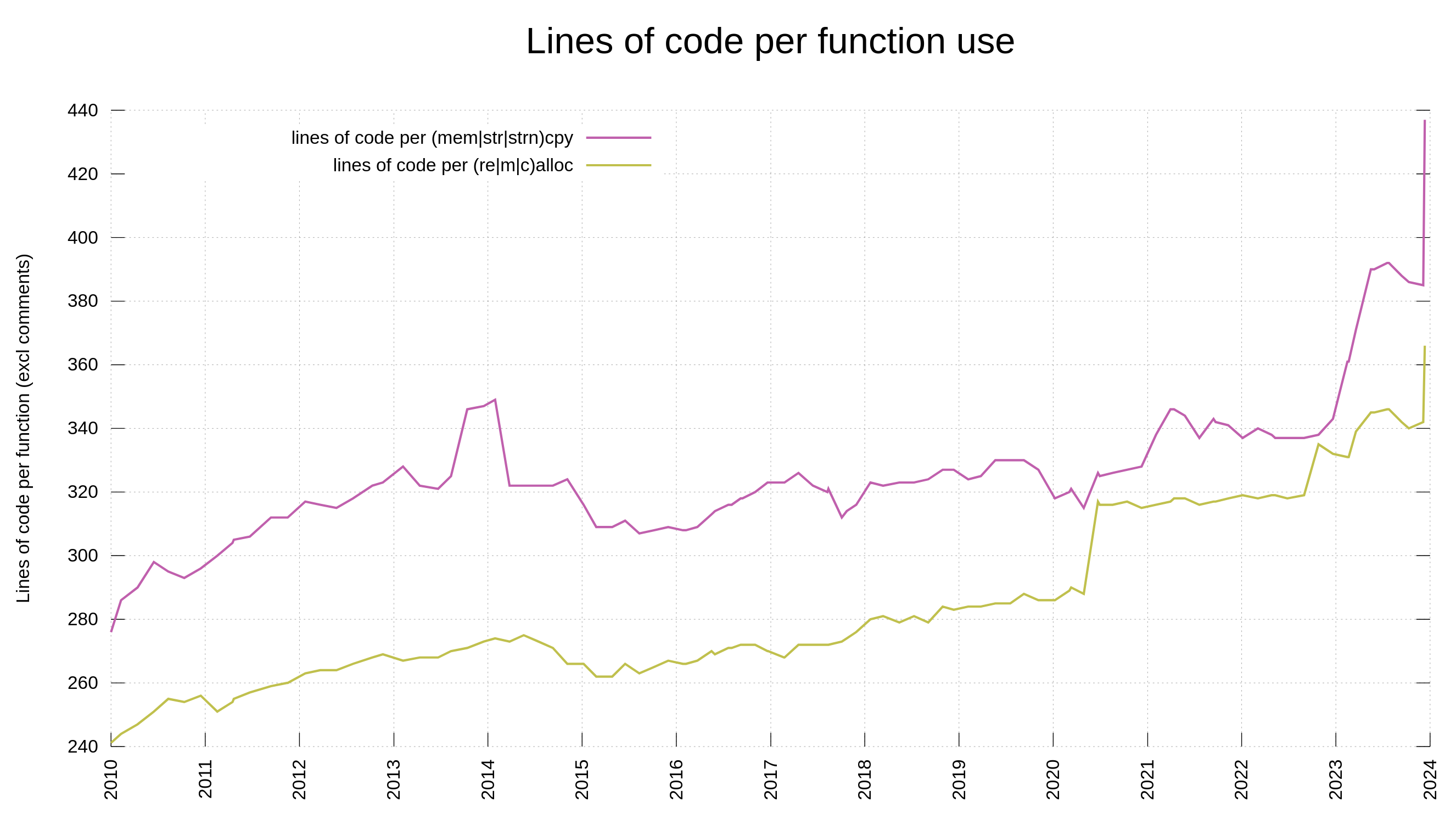
strings without length restrictions, because the length might end up very long in edge cases which risks causing integer overflows which leads to issues
reallocs, in particular without length restrictions and 32 bit integer overflows
memory and string copies, following a previous memory allocation, maybe most troublesome when the boundary checks are not immediately next to the actual copy in the source code
perhaps this is just subset of (3), but strncpy() is by itself complicated because of the padding and its not-always-null-terminating functionality
We try to avoid the above mentioned “problem areas” like this:
We have general maximum length restrictions for strings passed to libcurl’s API, and we have set limits on all internally created dynamic buffers and strings.
We avoid reallocs as far as possible and instead provide helper functions for doing dynamic buffers. In fact, avoiding all sorts of direct memory allocations help.
Many memory copies cannot be avoided, but if we can use a pointer and length instead that is much better. If we can snprintf() a target buffer that is better. If not, try do the copy close to the boundary check.
Avoid strncpy(). In most cases, it is better to just return error on too long input anyway, and then instead do plain strcpy or memcpy with the exact amount. Ideally of course, just using a pointer and the length is sufficient.
Over time, we use fewer “difficult functions” per line of libcurl code even when the code size grows.
These helper functions and reduction of “difficult functions” in the code are not silver bullets. They will not magically make us avoid future vulnerabilities, they should just ideally make it harder to do security mistakes. We still need a lot of reviews, tools and testing to verify the code.
Clean code
Already before we created these helpers we have gradually and slowly over time made the code style and the requirements to follow it, stricter. When the source code looks and feels coherent, consistent, as if written by a single human, it becomes easier to read. Easier to read becomes easier to debug and easier to extend. Harder to make mistakes in.
To help us maintain a consistent code style, we have tool and CI job that runs it, so that obvious style mistakes or conformance problems end up as distinct red lines in the pull request.
Source verification
Together with the strict style requirement, we also of course run many compilers with as many picky compiler flags enabled as possible in CI jobs, we run fuzzers, valgrind, address/memory/undefined behavior sanitizers and we throw static code analyzers on the code – in a never-ending fashion. As soon as one of the tools gives a warning or indicates that something could perhaps be wrong, we fix it.
Of course also to verify the correct functionality of the code.
Data for this post
All data and numbers I speak of in this post are publicly available in the curl git repositories: curl and curl-www. The graphs come from the curl web site dashboard. All graph code is available.
In association with the release of curl 8.4.0, we publish a security advisory and all the details for CVE-2023-38545. This problem is the worst security problem found in curl in a long time. We set it to severity HIGH.
While the advisory contains all the necessary details. I figured I would use a few additional words and expand the explanations for anyone who cares to understand how this flaw works and how it happened.
SOCKS5 is a proxy protocol. It is a rather simple protocol for setting up network communication via a dedicated “middle man”. The protocol is for example typically used when setting up communication to get done over Tor but also for accessing Internet from within organizations and companies.
SOCKS5 has two different host name resolver modes. Either the client resolves the host name locally and passes on the destination as a resolved address, or the client passes on the entire host name to the proxy and lets the proxy itself resolve the host remotely.
In early 2020 I assigned myself an old long-standing curl issue: to convert the function that connects to a SOCKS5 proxy from a blocking call into a non-blocking state machine. This is for example much noticeable when an application performs a large amount of parallel transfers that all go over SOCKS5.
On February 14 2020 I landed the main commit for this change in master. It shipped in 7.69.0 as the first release featuring this enhancement. And by extension also the first release vulnerable to CVE-2023-38545.
A less wise decision
The state machine is called repeatedly when there is more network data to work on until it is done: when the connection is established.
This boolean variable holds information about whether curl should resolve the host or just pass on the name to the proxy. This assignment is done at the top and thus for every invocation while the state machine is running.
The state machine starts in the INIT state, in which the main bug for today’s story time lies. The flaw is inherited from the function from before it was turned into a state-machine.
SOCKS5 allows the host name field to be up to 255 bytes long, meaning a SOCKS5 proxy cannot resolve a longer host name. On finding a too long host name. the curl code makes the bad decision to instead switch over to local resolve mode. It sets the local variable for that purpose to TRUE. (This condition is a leftover from code added ages ago. I think it was downright wrong to switch mode like this, since the user asked for remote resolve curl should stick to that or fail. It is not even likely to work to just switch, even in “good” situations.)
The state machine then switches state and continues.
The issue triggers
If the state machine cannot continue because it has no more data to work with, like if the SOCKS5 server is not fast enough, it returns. It gets called again when there is data available to continue working on. Moments later.
But now, look at the local variable socks5_resolve_local at the top of the function again. It again gets set to a value depending on proxy mode – not remembering the changed value because of the too long host name. Now it again holds a value that says the proxy should resolve the name remotely. But the name is too long…
curl builds a protocol frame in a memory buffer, and it copies the destination to that buffer. Since the code wrongly thinks it should pass on the host name, even though the host name is too long to fit, the memory copy can overflow the allocated target buffer. Of course depending on the length of the host name and the size of the target buffer.
Target buffer
The allocated memory area curl uses to build the protocol frame in to send to the proxy, is the same as the regular download buffer. It is simply reused for this purpose before the transfer starts. The download buffer is 16kB by default but can also be set to use a different size at the request of the application. The curl tool sets the buffer size to 100kB. The minimum accepted size is 1024 bytes.
If the buffer size is set smaller than 65541 bytes this overflow is possible. The smaller the size, the larger the possible overflow.
Host name length
A host name in a URL has no real size limit, but libcurl’s URL parser refuses to accept names longer than 65535 bytes. DNS only accepts host names up 253 bytes. So, a legitimate name that is longer than 253 bytes is unusual. A real name that is longer than 1024 is virtually unheard of.
Thus it pretty much requires a malicious actor to feed a super-long host name into this equation to trigger this flaw. To use it in an attack. The name needs to be longer than the target buffer to make the memory copy overwrite heap memory.
Host name contents
The host name field of a URL can only contain a subset of octets. A range of byte values are plain invalid and would cause the URL parser to reject it. If libcurl is built to use an IDN library, that one might also reject invalid host names. This bug can therefore only trigger if the right set of bytes are used in the host name.
Attack
An attacker that controls an HTTPS server that a libcurl using client accesses over a SOCKS5 proxy (using the proxy-resolver-mode) can make it return a crafted redirect to the application via a HTTP 30x response.
Such a 30x redirect would then contain a Location: header in the style of:
… where the host name is longer than 16kB and up to 64kB
If the libcurl using client has automatic redirect-following enabled, and the SOCKS5 proxy is “slow enough” to trigger the local variable bug, it will copy the crafted host name into the too small allocated buffer and into the adjacent heap memory.
A heap buffer overflow has then occurred.
The fix
curl should not switch mode from remote resolve to local resolve due to too long host name. It should rather return an error and starting in curl 8.4.0, it does.
We now also have a dedicated test case for this scenario.
Credits
This issue was reported, analyzed and patched by Jay Satiro.
This is the largest curl bug-bounty paid to date: 4,660 USD (plus 1,165 USD to the curl project, as per IBB policy)
Classic related Dilbert strip. The original URL seems to no longer be available.
Rewrite it?
Yes, this family of flaws would have been impossible if curl had been written in a memory-safe language instead of C, but porting curl to another language is not on the agenda. I am sure the news about this vulnerability will trigger a new flood of questions about and calls for that and I can sigh, roll my eyes and try to answer this again.
The only approach in that direction I consider viable and sensible is to:
allow, use and support more dependencies written in memory-safe languages and
potentially and gradually replace parts of curl piecemeal, like with the introduction of hyper.
Such development is however currently happening in a near glacial speed and shows with painful clarity the challenges involved. curl will remain written in C for the foreseeable future.
Everyone not happy about this are of course welcome to roll up their sleeves and get working.
Including the latest two CVEs reported for curl 8.4.0, the accumulated total says that 41% of the security vulnerabilities ever found in curl would likely not have happened should we have used a memory-safe language. But also: the rust language was not even a possibility for practical use for this purpose during the time in which we introduced maybe the first 80% of the C related problems.
It burns in my soul
Reading the code now it is impossible not to see the bug. Yes, it truly aches having to accept the fact that I did this mistake without noticing and that the flaw then remained undiscovered in code for 1315 days. I apologize. I am but a human.
It could have been detected with a better set of tests. We repeatedly run several static code analyzers on the code and none of them have spotted any problems in this function.
In hindsight, shipping a heap overflow in code installed in over twenty billion instances is not an experience I would recommend.
Behind the scenes
To learn how this flaw was reported and we worked on the issue before it was made public. Go check the Hackerone report.
On Scott Adams
I use his “I’m going to write myself a minivan”-strip above because it’s a classic. Adams himself has turned out to be a questionable person with questionable opinions and I do not condone or agree with what he says.
(CVE-2023-38546) This flaw allows an attacker to insert cookies at will into a running program using libcurl, if the specific series of conditions are met and the cookies are put in a file called “none” in the application’s current directory.
Changes
IPFS protocols via HTTP gateway
The curl tool now supports IPFS URLs via gateway. I emphasize that it is the tool because this support is not libcurl. The URL needs to be a correct IPFS URL but curl only works with it if you provide an IPFS gateway, it has no actual native IPFS implementation. You want to read the new IPFS section on the curl website for details.
This is new and very simply function added to the libcurl API: it returns all the easy handles that were previously added to it.
dropped support for legacy mingw.org toolchain
The legacy mingw version is deprecated and by dropping support for this we can simplify code a little.
Bugfixes
Some of the things we fixed in this release are…
made cmake more aligned with configure
Numerous smaller and larger fixes went in this cycle to make sure the cmake and configure configs are more aligned and create more similar default builds.
expire the timeout when trying next IP
Iterating over IP addresses when connecting could accidentally do delays, making the process take longer time than necessary.
remove unnecessary cookie struct fields
curl now keeps much less data in memory per cookie
update curl man page references
All curl man pages got their references updated and they are now verified and checked in tests to remain accurate and well formatted.
use per-request counter to check too large http headers
The check that prevents too large accumulated HTTP response headers actually used the wrong counter so it kicked in too early.
aws-sigv4: fix sorting with empty parts
Getting this authentication method to work in all cases turns out to be a real adventure and in this release we fix yet some minor issues.
let the max file size option stop too big transfers
Up until now, the maximum file size option only works on stopping transfers before it even began if libcurl knew the file size was too big. Starting now, it will also stop ongoing transfers if they reach the maximum limit. This should help users avoid unwanted surprises.
lib: use wrapper for curl_mime_data fseek callback
Rewinding files when doing multipart formbased transfers on 32 bit ARM using the legacy libcurl curl_formadd API did not work because of data size incompatibilities. It took some work to find and understand as it still worked fine on x86 32 bit for example!
libssh: cap SFTP packet size sent
The libssh library mostly passes on the data with the same size libcurl passes to it, it turns out. That is not compatible with the SFTP protocol so in order to make libcurl work better, it now caps how much data it can send in a single libssh send call. It probably makes SFTP uploads much slower.
misc: better random boundary separators
The mime boundaries used for multipart formposts now use more random bits than before. Up from 64 to 130 bits. It now produces strings using alphanumerical characters instead of just hex.
quic: set ciphers/curves like for TLS
The same style of support for setting TLS 1.3 ciphers and curves as for regular TLS were added to the QUIC code.
http2: retry on GOAWAY
Improved handling of GOAWAY when wanting to use use connection and then move on to use another.
fall back to http/https proxy env-variable if ws/wss not set
When using one of the WebSocket schemes, curl will now fall back and try the http_proxy and https_proxy environment variables if ws_proxy or wss_proxy is not set.
accept –expand on file names too
The variable --expand functionality did not work for command line options that accept file names, such as --output. It does now.
Next
We have synced the coming release cycles on this release. The next one is thus planned to happen in exactly eight weeks time. On December 6, 2023.
On August 26 I posted details here on my blog about the bogus curl issue CVE-2020-19909. Luckily, it got a lot of attention and triggered discussions widely. Maybe I helped shed light on the brittleness of this system. This was not a unique instance and it was not the first time it happened. This has been going on for years.
Some people did in discussions following my blog post insist that a signed long overflow is undefined behavior in C and since it truly is undefined all bets are off so this could be a security issue.
I am not a fan of philosophical thought exercises around vulnerabilities. They are distractions from the real matters and I find them rather pointless. It is easy to test how this flaw plays out on numerous platforms using numerous compilers. It’s not a security problem on any of them. Even if the retry time would go down to 0, it is not a DOS to do multiple internet transfers next to each other. If it would be, then a browser makes a DOS every time you visit a website – and curl does it when you give it two URLs on the same command line. Unexpected behavior and a silly bug, yes. Security flaw: no.
Not to even mention that no person or script actually would use such numbers on the command line that trigger the bug. This is the bug that never triggered for anyone who did not deliberately try to make it happen.
Who gets to report a CVE
A CVE Id is basically just a bug tracker identifier. You can ask for a number for a problem you found, and by the nature of this you don’t even have to present many details when you ask for it. You are however supposed to provide them when the issue goes public. CVE-2020-19909 certainly failed this latter step. You could perhaps ask why MITRE even allows for CVEs to get published at all if there isn’t more information available.
When you request a CVE Id, there are a few hundred distributed CVE number authorities (CNAs) you can get the number from.
CNA
A CNA can (apparently) require to be consulted if the ask is in regards to their scope. To their products.
I have initiated work on having curl become a CNA; to take responsibility for all CVEs that concern curl or libcurl. I personally think it is rather problematic that this basically is the only available means to prevent this level of crap, but I still intend to attempt this route.
Lots of other Open Source projects (Apache, OpenSSL, Python, etc) already are CNAs, many of them presumably because they realized these things much faster than me. I suspect curl is a smaller shop than most of the existing CNAs, but I don’t think size matters here.
It does of course add administration and work for us which is unfortunate, because that time and energy could be spent on more productive activities, but it still feels like a reasonable thing to try. Hopefully this can also help combat inflated severity levels.
MITRE: Reject 2020-19909 please
The main care-taker of the CVE database is MITRE. They provide a means for anyone to ask for updates to already published CVEs. I submitted my request for rejection using their online form, explaining that this issue is not a security problem and thus should be removed again. With all the info I had, including a link to my blog post.
They denied my request.
Their motivation? The exact quote:
After review there are multiple perspectives on whether the issue information is helpful to consumers of the CVE List, our current preference is in the direction of keeping the CVE ID assignment. There is a valid weakness (integer overflow) that can lead to a valid security impact (denial of service, based on retrying network traffic much more often than is documented/requested).
This is signed CVE Assignment Team, no identifiable human involved.
It is not a Denial of Service. It’s blatant scaremongering and it helps absolutely no one to say that it is.
NVD: Rescore 2020-19909 please
NVD maintains some sort of database and index with all the CVE Ids. They score them and as you may remember, they decided this non-issue is a 9.8 out of 10 severity.
The same evening I learned about this CVE I contacted NVD (nvd@nist.gov), pointed out this silliness and asked them to act on it.
A few days later they responded. From the National Vulnerability Database Team, no identifiable human.
First, they of course think their initial score was a fair assessment:
At the time of analysis, information for this CVE record was particularly sparse. Per NVD policy, if any information is lacking, unclear or conflicts between sources, the NVD policy is to represent the worst-case scenario. The NVD takes this conservative approach to avoid under reporting the possible severity of a given vulnerability.
Meaning: when they don’t know, they make up the worst possible scenario. That is literally what they say and how they act. Panic by default.
However, at this time there are more information sources and clarifications provided that make amendment of the CVSS vector string appropriate. We will break down the various amendments for transparency and to assist in confirmation of the appropriateness of these changes by you or a member of your team.
Meaning: their messed up system requires us to react and provide additional information to them to trigger a reassessment and them updating the score. To lower the panic level.
NVD themselves will not remove any CVE. As long as MITRE says it is a genuine issue, NVD shows it.
Rescore
As a rejection of the CVE was denied, the secondary goal would be to lower NVD’s severity score as much as possible.
The NVD response helped me understand how their research into and analyses of issues are performed.
Their email highlighted three specific items in the CVSS score and how they could maybe re-evaluate them to a lower setting. How do they base and motivate that? Providing links to specific reddit discussions for details of the CVE-2020-19909 problems. Postings done by the ordinary set of pseudonymous persons. Don’t get me wrong, some of those posts are excellent and clearly written by skilled and knowledgeable persons. It just seems a bit… arbitrary.
I did not participate in those discussions and neither did any curl core contributor to my knowledge. There are simply no domain experts involved there.
No reading or pointing to code. No discussions on data input and what changing retry delays mean and not a single word on UB. No mention on why no or a short delay would imply DOS.
Eventually, their proposed updated CVSS ends up with a new score of…
3.3
To be honest, I find CVSS calculations exhausting and I did not care to evaluate their proposal very closely. Again, this is not a security problem.
If you concur with the assessment above based on publicly available information this would change the vector string as follows:
I have not personally checked the scoring very closely. I do not agree with the premise that this is a security problem. It is bad, wrong and hostile to insist that non-issues are security problems. It is counter-productive for the entire industry.
As they set it to 3.3 it at least takes the edge off this silliness and I feel a little bit better. They now also link to my blog post from their CVE-2020-19909 info page, which I think is grand of them.
This is a story consisting of several little building blocks and they occurred spread out in time and in different places. It is a story that shows with clarity how our current system with CVE Ids and lots of power given to NVD is a completely broken system.
CVE-2020-19909
On August 25 2023, we got an email to the curl-library mailing list from Samuel Henrique that informed us that “someone” had recently created a CVE, a security vulnerability identification number and report really, for a curl problem.
I wanted to let you know that there's a recent curl CVE published and it doesn't look like it was acknowledged by the curl authors since it's not mentioned in the curl website: CVE-2020-19909
We can’t tell who filed it. We just know that it is now there.
We own our curl issues
In the curl project we work hard and fierce on security and we always work with security researchers who report problems. We file our own CVEs, we document them and we make sure to tell the world about them. We list over 140 of them with every imaginable detail about them provided. We aim at providing gold-level documentation for everything and that includes our past security vulnerabilities.
That someone else suddenly has submitted a CVE for curl is a surprise. We have not been told about this and we would really have liked to. Now there is a new CVE out there reporting a curl issue and we have no details to say about it on the website. Not good.
I bet curl users soon would like to know the details about this.
Wait 2020?
The new CVE has an ID containing 2020 and that is weird. When you register a CVE you typically get it with the year you request it. Unless you get an ID for an old problem of the past. Is that what they did?
Sources seem to indicate that this was published just days ago.
Integer overflow vulnerability in tool_operate.c in curl 7.65.2 via crafted value as the retry delay.
And then the craziest statement of the year. They grade it a 9.8 CRITICAL issue. With 10 as a maximum, this is close to the worst case possible, right?
The code
Let’s pause NVD in their panic state for a moment because I immediately recognized this description. Brief as it is.
I spend a lot of time in the curl security team receiving reports, reviewing reports, reviewing source code, assessing claims and figuring out curl security issues. I had seen this claim before!
On July 27, 2019, a Jason Lee file an issue on hackerone, where he reported that there was an integer overflow problem in curl’s --retry-delay command line option. The option accepts number of seconds and then internally converts to milliseconds by multiplying the value by 1000. The option sets how long time curl should wait until it makes a retry if the previous transfer failed with a transient error.
This means that on a 64 bit machine, if you write
curl --retry-delay 18446744073709552 ...
The number will overflow the math and instead of waiting until the end of the universe, it might retry again within the next few seconds. The above example apparently made it 384 seconds instead. On Windows, which uses 32 bit longs, you can get the problem already by asking for more than two million seconds (roughly 25 days).
A bug, sure. Security problem? No. I told Jason that in 2019 and then we closed the security report. I then filed a pull-request and fixed the bug. Credits to Jason for the report. We moved on. The fix was shipped in curl 7.66.0, released in September 2019.
Grading issues
In previous desperate attempts from me to reason with NVD and stop their scaremongering and their grossly inflating the severity level of issues, they have insisted that they take in all publicly available data about the problem and make an assessment.
It was obvious already before that NVD really does not try very hard to actually understand or figure out the problem they grade. In this case it is quite impossible for me to understand how they could come up with this severity level. It’s like they saw “integer overflow” and figure that wow, yeah that is the most horrible flaw we can imagine, but clearly nobody at NVD engaged their brains nor looked at the “vulnerable” code or the patch that fixed the bug. Anyone that looks can see that this is not a security problem.
The issue listed by NVD even links to my pull request I mention above. There is no doubt that it is the exact same bug they refer to.
Spreading like a virus
NVD hosts a CVE database and there is an entire world and eco system now that pulls the records from them.
NVD now has this CVE-2020-19909 entry in there, rated 9.8 CRITICAL and now this disinformation spreads across the world. Now when we search for this CVE number we find numerous sites that repeats the same data. “This is a 9.8 CRITICAL problem in curl” – when it is not.
I will object
I learned about this slap in my face just a few hours ago (and I write this past Friday midnight), but I intend to do what I can to reject this CVE.
There is something about having your product installed in over twenty billion instances all over the world and even out of the globe. In my case it helps me remain focused on and committed to working on the security aspects of curl. Ideally, we will never have our heartbleed moment.
Security is also a generally growing concern in the world around us and Open Source security perhaps especially so. This is one reason why NVD making things up is such a big problem.
The National Vulnerability Database (NVD) has a global presence. They host and share information about security vulnerabilities. If you search for a CVE Id using your favorite search engine, it is likely that the first result you get is a link to NVD’s page with information about that specific CVE. They take it upon themselves to educate the world about security issues. A job that certainly is needed but also one that puts a responsibility and requirement on them to be accurate. When they get things wrong they help distributing misinformation. Misinformation makes people potentially draw the wrong conclusions or act in wrong, incomplete or exaggerated ways.
Low or Medium severity issues
There are well-known, recognized and reputable Open Source projects who by policy never issue CVEs for security vulnerabilities they rank severity low or medium. (I will not identify such projects here because it is not the point of this post.)
Such a policy successfully avoids the risk that NVD will greatly inflate their issues since they can already only be high or critical. But is it helping the users and the ecosystem at large?
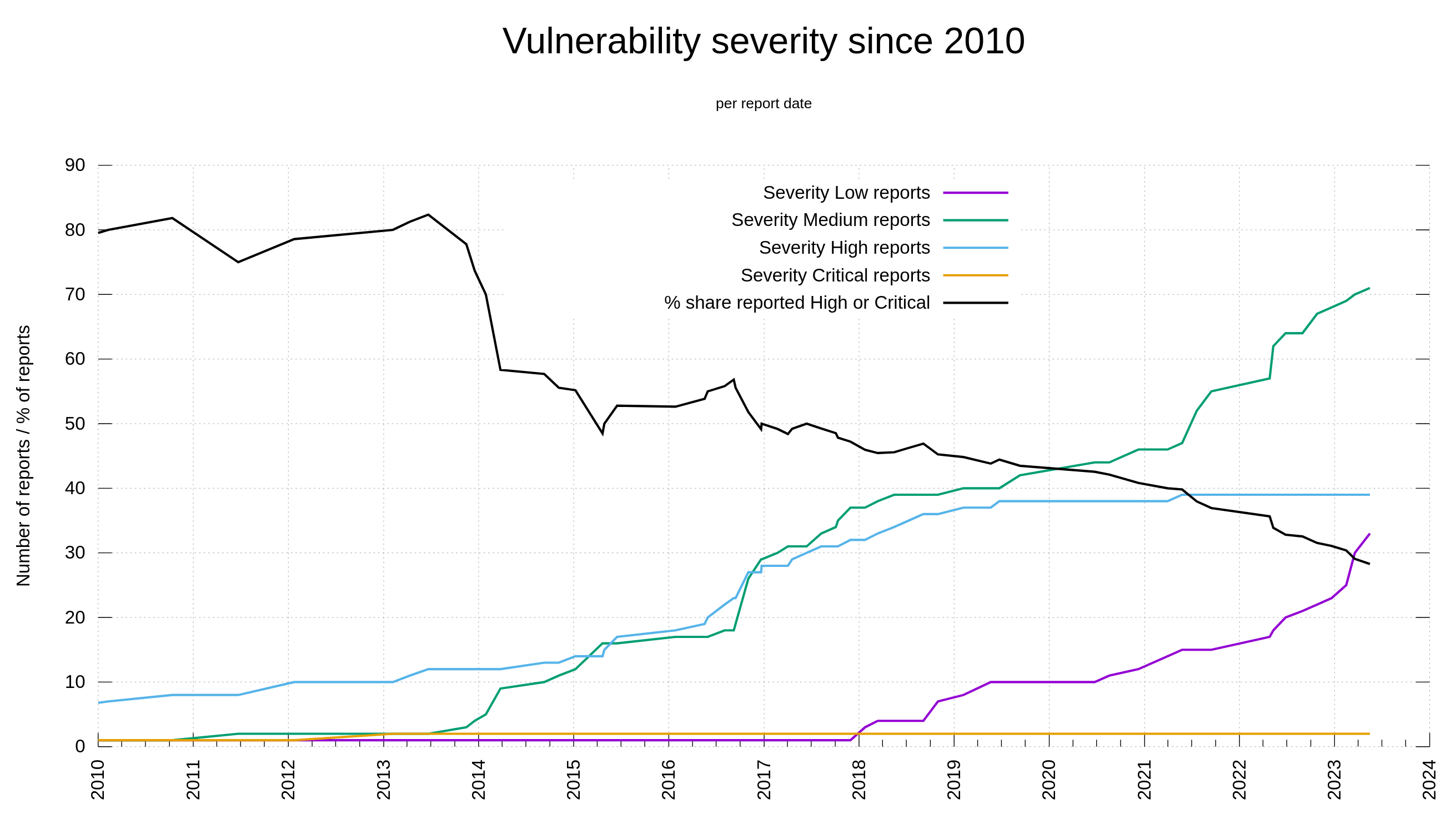
In the curl project we have a policy which makes us register a CVE for every single reported or self-detected problem that can have a security impact. Either at will or by mistake. This includes a fair amount of low and medium issues. The amount of low and medium issues as a total of all issues increases over time as we keep finding issues, but the really bad ones are less frequently reported.
As we have all data recorded and stored, we can visualize this development over time. Below is a graph showing the curl vulnerability and severity level trends since 2010.
Severity distribution in reported curl vulnerabilities since 2010
Out of the 145 published curl security vulnerabilities so far, 28% have been rated severity high or critical while 104 of them were set low or medium by the curl security team.
I think this trend is easy to explain. It is because of two separate developments:
We as a project have matured and have learned over time how to test better, write code better to minimize risk and we have existed for a while to have a series of truly bad flaws already found (and fixed). We make less serious bugs these days.
Since 2010, lots of more people look for security problems and these days we are much better better at identifying problems as security related and we have better tools, while for a few years ago the same problem would just have become “a bug fix”.
Deciding severity
When a security problem is reported to curl, the curl security team and the reporter collaborate. First to make sure we understand the full width of the problem and its security impact. What can happen and what is required for that badness to trigger? Further, we assess what the likeliness that this can be done on purpose or by mistake and how common those situations and required configurations might be. We know curl, we know the code but we also often go back and double-check exactly what the documentation says and promises to better assess what users should be expected to know and do, and what is not expected from them etc. And we re-read the involved code again and again.
curl is currently a little over 160,000 lines of feature packed C code (excluding blank lines). It might not always be straight forward to a casual observer exactly how everything is glued together even if we try to also document internals to help you find deeper knowledge.
I think it is fair to say that it requires a certain amount of experience and time spent with the code to be able to fully understand a curl security issue and what impact it might have. I believe it is difficult or next to impossible for someone without knowledge about how it works to just casually read our security advisories and try to second-guess our assessments and instead make your own.
Yet this is exactly what NVD does. They don’t even ask us for help or for clarifications of anything. They think they can assess the severity of our problems without knowing curl nor fully understanding the reported issues.
A case to prove my point
In March 2023 we published a security advisory for the problem commonly referred to as CVE-2023-27536.
This is potentially a security problem, probably never hurts anyone and is in fact quite unlikely to ever cause a problem. But it might. So after deliberating we accepted it and ranked it severity low.
Bear with me here. I’ll spend two paragraphs revealing some details from the internal libcurl engine:
The problem is of a kind we have had several times in the past: curl has a connection pool and when a user makes a subsequent request which this particular option modified (compared to how it was when the previous connection was setup) it would wrongly reuse the first connection thinking they had the exact same properties.
The second would then accidentally get the wrong rights because it was setup differently. Still, the first connection would need the correct credentials and everything and so would the second one, it would just differ depending on what “GSSAPI delegation” that is allowed.
NVD ranks this
The person or team at NVD whose job it is to make up stuff for security vulnerabilities ranked this as CRITICAL 9.8. Almost as bad as it gets apparently. 10 is the max as you might recall.
When realizing this, at the end of May, I first fell off my chair in shock by this insanity, but after a quick recovery I emailed them (again) and complained (yet again) on setting this severity for *27536. I used the word “ridiculous” in my email to describe their actions. Why and who benefits from them scaremongering the world like this? It makes no sense. On the contrary, this is bad for everyone.
As a reaction to my complaint, someone at NVD went back and agreed to revise the CVSS string they had set and suddenly it was “only” ranked HIGH 7.2. I say “someone” because they never communicate with names and never sign the emails which whomever I talk to. They are just “NVD”.
I objected to their new CVSS string as well. It is just not a high severity security problem!
In my new argument I changed two particular details in the CVSS string (compared to the one they insisted was good) and presented arguments for that. For your pleasure, I include my exact wording below. (Some emphasis is added here for display purposes.)
How I motivated a downgrade
I could possibly live with: AV:N/AC:H/PR:H/UI:N/S:U/C:H/I:N/A:N (4.4) - even if that means Medium and we argue Low.
These are two changes and my motivations:
Attack complexity high - because how this requires that you actually have a working first communication and then do a second is slightly changed and you would expect the second to be different but in reality it accidentally reuse the first connection and therefore gives different/elevated rights.
It is a super-niche and almost impossible attack and there has been no report ever of anyone having suffered from this or even the existence of an application that actually would enable it to happen.
It is more likely to only happen by mistake by an application, but it also seems unlikely to ever be used by an application in a way that would trigger it since having the same user credentials with different values for GSS delegation and assume different access levels seems … weird.
This almost impossible chance of occurring is the primary reason we think this is a Low severity. With CVSS, it seems impossible to reach Low.
Privileges Required high - because the only way you can trigger this flaw is by having full privileges for the *same* user credentials that is later used again but with changed GSS API delegation set. While the previous connection is still live in the connection pool.
It would also only be an attack or a flaw if that second transfer actually assumes to have different access properties, which is probably debatable if users of the API would expect or not
CVSS still sucks
CVSS is a crap system so using this single-dimension number it seems next to impossible to actually get severity low report.
NVD wants “public sources”
NVD does not just take my word for how curl works. I mean, I only wrote a large chunk of it and am probably the single human that knows most about its internals and how it works. I also wrote the patch for this issue, I wrote the connection pool logic and I understand the problem exactly. Nope, just because I say so does not make it true.
My claims above about this issue can of course be verified by reading the publicly available source code and you can run tests to reproduce my claims. Not to mention that the functionality in question is documented.
But no.
They decided to agree to one of my proposed changes, which further downgraded the severity to MEDIUM 5.9. Quite far away from their initial stance. I think it is at least a partial victory.
For the second change to the CVSS string I requested, they demand that I provide more information for them. In their words:
There is no publicly available information about the CVE that clarifies your statement so we must request clarification from you and additionally have this detail added to the HackerOne report or some other public interface for transparency purposes prior to making changes to the CVSS vector.
… which just emphasizes exactly what I have stated already in this post. They set a severity on this without understanding the issue, with no knowledge of the feature that gets this wrong and without clues about what is actually necessary to trigger this flaw in the first place.
For people intimately familiar with curl internals, we actually don’t have to spell out all these facts with excruciating details. We know how the connection pool works, how the reuse of connections should work and what it means when curl gets it wrong. We have also had several other issues in this areas in the past. (It is a tricky area to get right.)
But it does not make this CVE more than a Low severity issue.
Conclusion
This issue is now stuck at this MEDIUM 5.9at NVD. Much less bad than where they started. Possibly Low or Medium does not make a huge difference out there in the world.
I think it is outrageous that I need to struggle and argue for such a big and renowned organization to do right. I can’t do this for every CVE we have reported because it takes serious time and energy, but at the same time I have zero expectation of them getting this right. I can only assume that they are equally lost and bad when assessing security problems in other projects as well.
A completely broken and worthless system. That people seem to actually use.
It is certainly tempting to join the projects that do not report Low or Medium issues at all. If we would stop doing that, at least NVD would not shout wolf and foolishly claim they are critical.
My response
That is a ridiculous request.
I'm stating *verifiable facts* about the flaw and how curl is vulnerable to it. The publicly available information this is based on is the actual source code which is openly available. You can also verify my claims by running code and checking what happens and then you'd see that my statements match what the code does.
The fact that you assess the severity of this (and other) CVE without understanding the basic facts of how it works and what the vulnerability is, just emphasizes how futile your work is: it does not work. If you do not even bother to figure these things out then of course you cannot set a sensible severity level or CVSS score. Now I understand your failures much better.
We in the curl project's security team already know how curl works, we understand this vulnerability and we set the severity accordingly. We don't need to restate known facts. curl functionality is well documented and its source code has always been open and public.
If you have questions after having read that, feel free to reach out to the curl security team and we can help you. You reach us at security@curl.se
I recommend that you (NVD) always talk to us before you set CVSS scores for curl issues so that we can help guide you through them. I think that could make the world a better place and it would certainly benefit a world of curl users who trust the info you provide.
/ Daniel