

You know I spend all my days working on curl and related matters. I also spend a lot of time thinking on the project; like how we do things and how we should do things.
The security angle of this project is one of the most crucial ones and an area where I spend a lot of time and effort. Dealing with and assessing security reports, handling the verified actual security vulnerabilities and waiving off the imaginary ones.
150 vulnerabilities
The curl project recently announced its 150th published security vulnerability and its associated CVE. 150 security problems through a period of over 25 years in a library that runs in some twenty billion installations? Is that a lot? I don’t know. Of course, the rate of incoming security reports is much higher in modern days than it was decades ago.
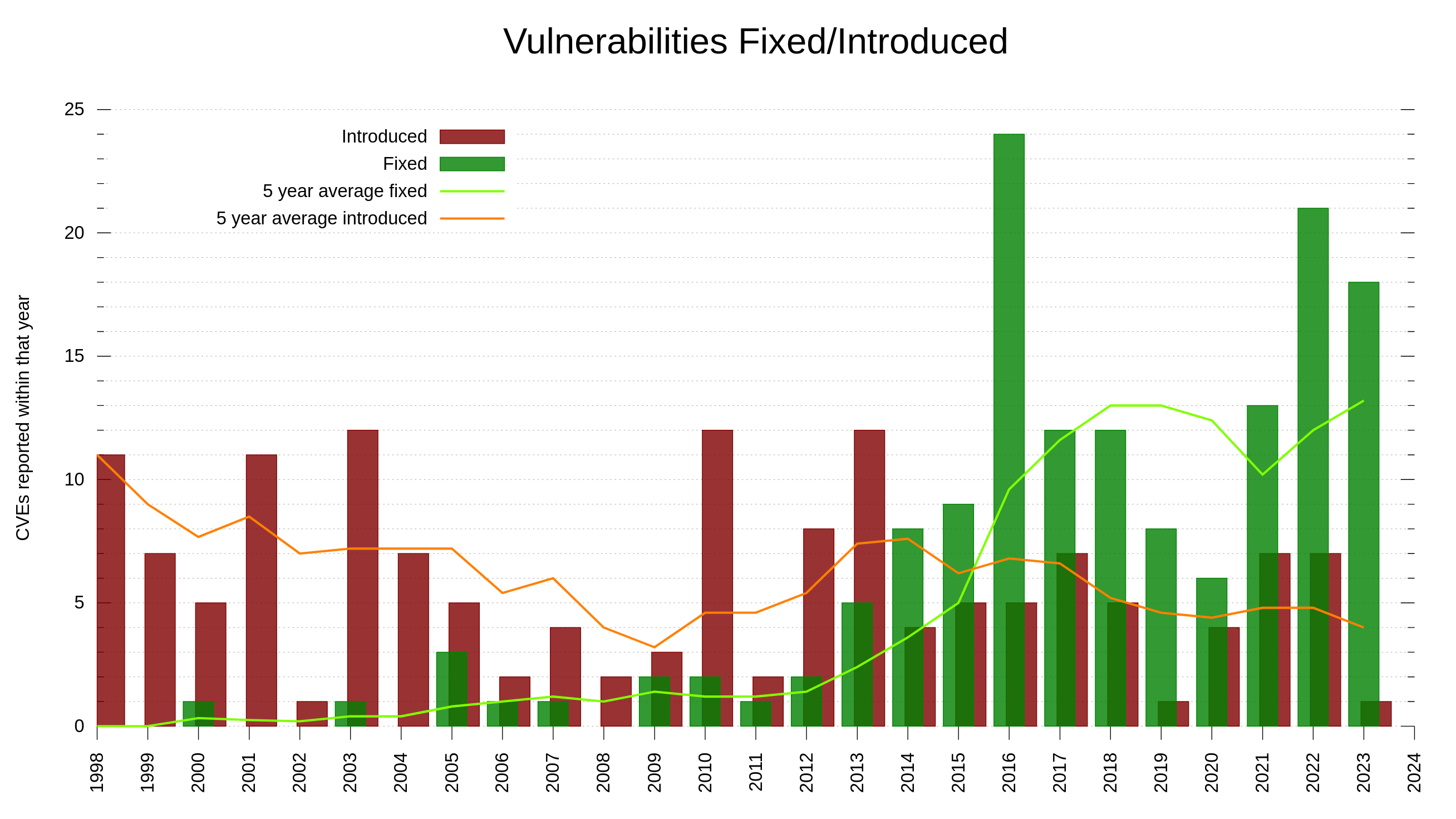
Out of the 150 published vulnerabilities, 60 were reported and awarded money through our bug-bounty program. In total, the curl bug-bounty has of today paid 71,400 USD to good hackers and security researchers. The monetary promise is an obvious attraction to researchers. I suppose the fact that curl also over time has grown to run in even more places, on more architectures and in even more systems also increases people’s interest in looking into and scrutinize our code. curl is without doubt one of the world’s most widely installed software components. It requires scrutiny and control. Do we hold up our promises?
curl is a C program running in virtually every internet connect device you can think of.
Trends
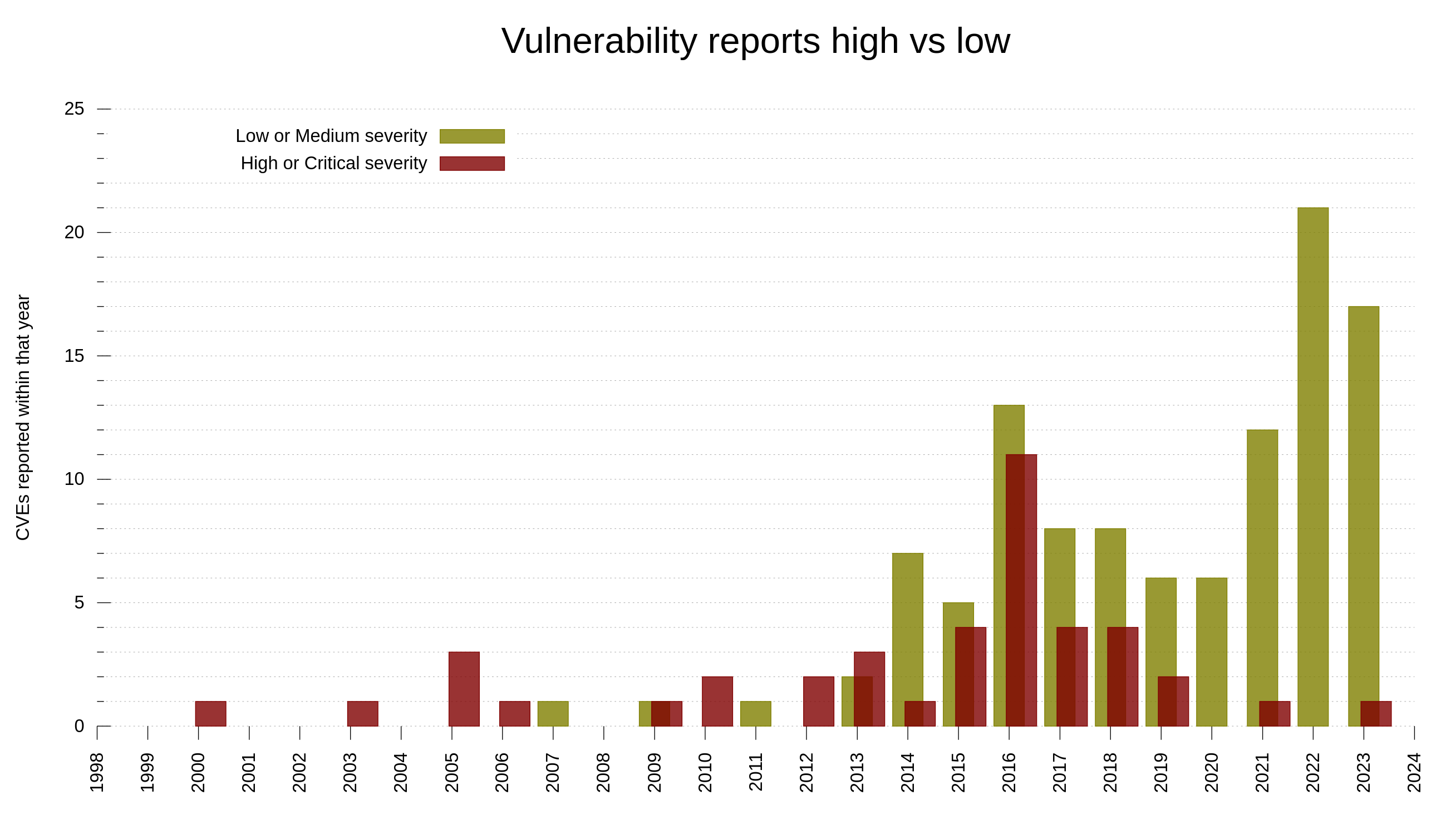
Another noticeable trend among the reports the last decade is that we are getting way more vulnerabilities reported with severity level low or medium these days, while historically we got more ones rated high or even critical. I think this is partly because of the promise of money but also because of a generally increased and sharpened mindset about security. Things that in the past would get overlooked and considered “just a bug” are nowadays more likely to get classified as security problems. Because we think about the problems wearing our security hats much more now.
Memory-safety
Every time we publish a new CVE people will ask about when we will rewrite curl in a memory-safe language. Maybe that is good, it means people are aware and educated on these topics.
I will not rewrite curl. That covers all languages. I will however continue to develop it, also in terms of memory-safety. This is what happens:
- We add support for more third party libraries written in memory-safe languages. Like the quiche library for QUIC and HTTP/3 and rustls for TLS.
- We are open to optionally supporting a separate library instead of native code, where that separate library could be written in a memory-safe language. Like how we work with hyper.
- We keep improving the code base with helper functions and style guides to reduce risks in the C code going forward. The C code is likely to remain with us for a long time forward, no matter how much the above mention areas advance. Because it is the mature choice and for many platforms still the only choice. Rust is cool, but the language, its ecosystem and its users are rookies and newbies for system library level use.
Step 1 and 2 above means that over time, the total amount of executable code in curl gradually can become more and more memory-safe. This development is happening already, just not very fast. Which is also why number 3 is important and is going to play a role for many years to come. We move forward in all of these areas at the same time, but with different speeds.
Why no rewrite
Because I’m not an expert on rust. Someone else would be a much more suitable person to lead such a rewrite. In fact, we could suspect that the entire curl maintainer team would need to be replaced since we are all old C developers maybe not the most suitable to lead and take care of a twin project written in rust. Dedicated long-term maintainer internet transfer library teams do not grow on trees.
Because rewriting is an enormous project that will introduce numerous new problems. It would take years until the new thing would be back at a similar level of rock solid functionality as curl is now.
During the initial years of the port’s “beta period”, the existing C project would continue on and we would have two separate branches to maintain and develop, more than doubling the necessary work. Users would stay on the first version until the second is considered stable, which will take a long time since it cannot become stable until it gets a huge amount of users to use it.
There is quite frankly very little (if any) actual demand for such a rewrite among curl users. The rewrite-it-in-rust mantra is mostly repeated by rust fans and people who think this is an easy answer to fixing the share of security problems that are due to C mistakes. Typically, the kind who has no desire or plans to participate in said venture.
C is unsafe and always will be
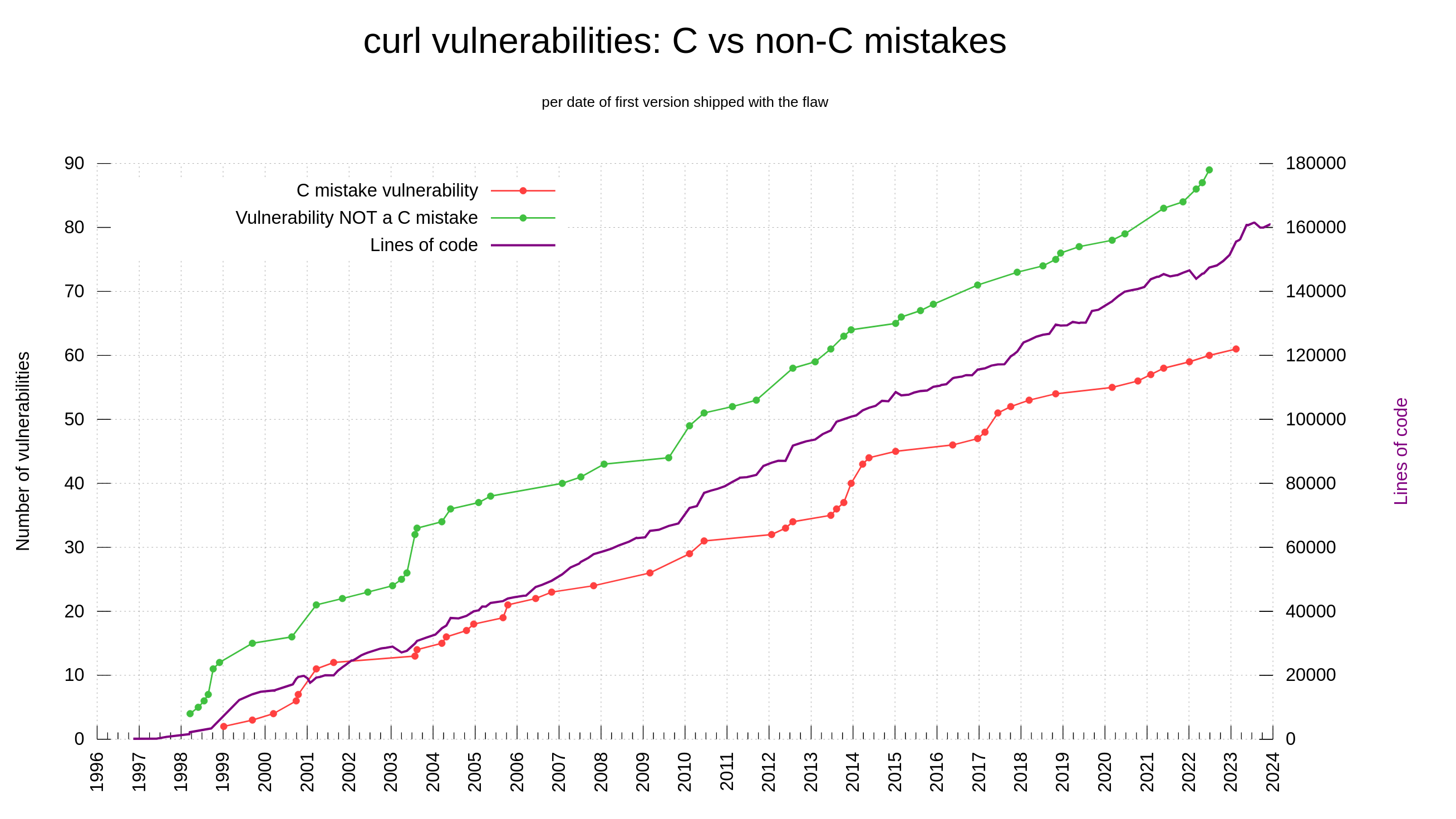
The C programming language is not memory-safe. Among the 150 reported curl CVEs, we have determined that 61 of them are “C mistakes”. Problems that most likely would not have happened had we used a memory-safe language. 40.6% of the vulnerabilities in curl reported so far could have been avoided by using another language.
Rust is virtually the only memory-safe language that is starting to become viable. C++ is not memory-safe and most other safe languages are not suitable for system/library level use. Often because how they fail to interface well with existing C/C++ code.
By June 2017 we had already made 51 C mistakes that ended up as vulnerabilities and at that time Rust was not a viable alternative yet. Meaning that for a huge portion of our problems, Rust was too late anyway.
40 is not 70
In lots of online sources people repeat that when writing code with C or C++, the share of security problems due to lack of memory-safety is in the range 60-70% of the flaws. In curl, looking per the date of when we introduced the flaws (not reported date), we were never above 50% C mistakes. Looking at the flaw introduction dates, it shows that this was true already back when the project was young so it’s not because of any recent changes.
If we instead count the share per report-date, the share has fluctuated significantly over time, as then it has depended on when people has found which problems. In 2010, the reported problems caused by C mistakes were at over 60%.
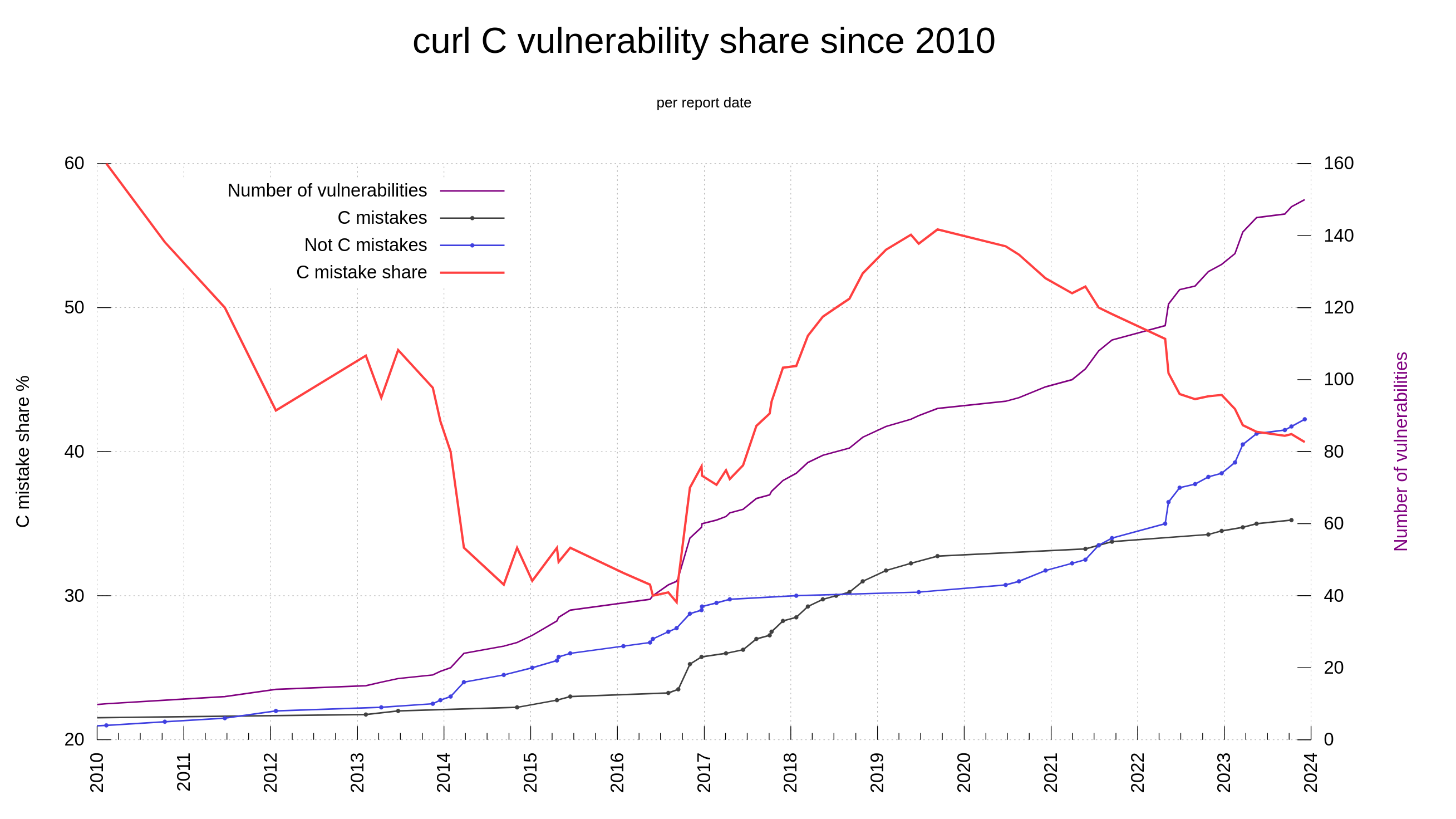
Of course, curl is a single project and not a statistical proof of any sort. It’s just a 25 year-old project written in C with more knowledge of and introspection into these details than most other projects.
Additionally, the share of C mistakes is slightly higher among the issues rated with higher severity levels: 51% (22 of 43) of the issues rated high or critical was due to C mistakes.
Help curl authors do better
We need to make it harder to write bad C code and easier to write correct C code. I do not only speak of helping others, I certainly speak of myself to a high degree. Almost every security problem we ever got reported in curl, I wrote. Including most of the issues caused by C mistakes. This means that I too need help to do right.
I have tried to learn from past mistakes and look for patterns. I believe I may have identified a few areas that are more likely than others to cause problems:
- strings without length restrictions, because the length might end up very long in edge cases which risks causing integer overflows which leads to issues
- reallocs, in particular without length restrictions and 32 bit integer overflows
- memory and string copies, following a previous memory allocation, maybe most troublesome when the boundary checks are not immediately next to the actual copy in the source code
- perhaps this is just subset of (3), but strncpy() is by itself complicated because of the padding and its not-always-null-terminating functionality
We try to avoid the above mentioned “problem areas” like this:
- We have general maximum length restrictions for strings passed to libcurl’s API, and we have set limits on all internally created dynamic buffers and strings.
- We avoid reallocs as far as possible and instead provide helper functions for doing dynamic buffers. In fact, avoiding all sorts of direct memory allocations help.
- Many memory copies cannot be avoided, but if we can use a pointer and length instead that is much better. If we can snprintf() a target buffer that is better. If not, try do the copy close to the boundary check.
- Avoid strncpy(). In most cases, it is better to just return error on too long input anyway, and then instead do plain strcpy or memcpy with the exact amount. Ideally of course, just using a pointer and the length is sufficient.
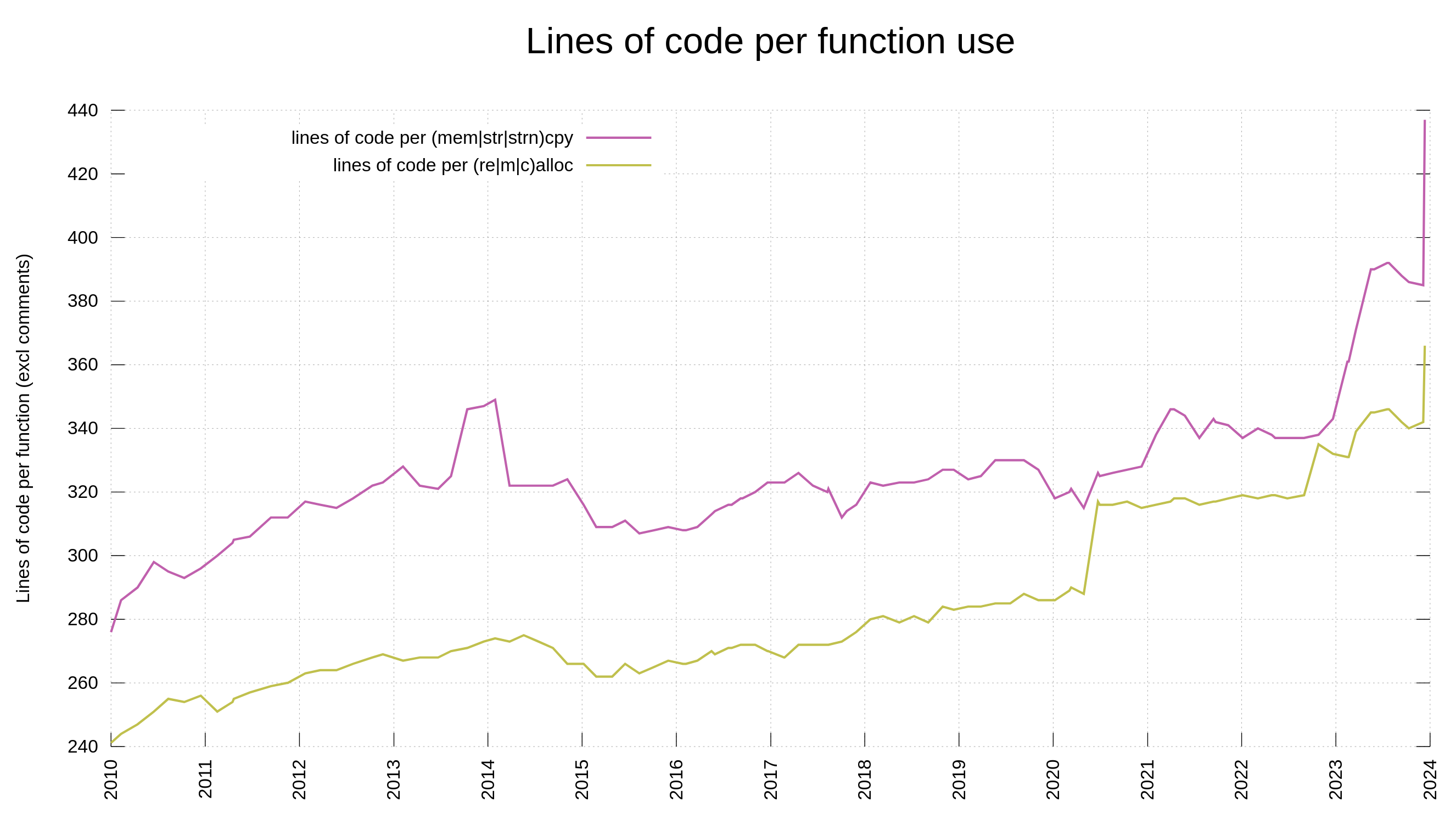
These helper functions and reduction of “difficult functions” in the code are not silver bullets. They will not magically make us avoid future vulnerabilities, they should just ideally make it harder to do security mistakes. We still need a lot of reviews, tools and testing to verify the code.
Clean code
Already before we created these helpers we have gradually and slowly over time made the code style and the requirements to follow it, stricter. When the source code looks and feels coherent, consistent, as if written by a single human, it becomes easier to read. Easier to read becomes easier to debug and easier to extend. Harder to make mistakes in.
To help us maintain a consistent code style, we have tool and CI job that runs it, so that obvious style mistakes or conformance problems end up as distinct red lines in the pull request.
Source verification
Together with the strict style requirement, we also of course run many compilers with as many picky compiler flags enabled as possible in CI jobs, we run fuzzers, valgrind, address/memory/undefined behavior sanitizers and we throw static code analyzers on the code – in a never-ending fashion. As soon as one of the tools gives a warning or indicates that something could perhaps be wrong, we fix it.
Of course also to verify the correct functionality of the code.
Data for this post
All data and numbers I speak of in this post are publicly available in the curl git repositories: curl and curl-www. The graphs come from the curl web site dashboard. All graph code is available.
There is another problem with rewriting a large project: initially intents might be good, but midway it becomes obvious that nobody knows the full list of features, which are progressively rediscovered as code is being analyzed, and that certain choices made upfront (sometimes from idealism) end up sacrificing features that some users rely on. Rewrites often promise a lot, and once done are a big disappointment because they change too many things. Also for the time they take, it’s hard to refrain from changing certain things and you end up with two roughly similar products that fragment the user base. In general the only really useful part of a rewrite is that it forces to completely read and analyze the existing code and that results in finding many bugs in it.
Also regarding the ratio of memory safety bugs, it’s important to keep in mind that once a rewrite could *theoretically* get rid of most of them, all the other ones remain and can even sometimes become harder to fix or can be easier to cause when the language makes code harder to write (typically the case with control bugs that are occasionally induced by trying to shut up compiler warnings). So if after several years of rewrite you end up with a not exactly similar project that only cuts the bug count in half and loses a part of its user base, I’d call that a regression.
It’s time to grow up and start Rust rewrite for Curl.
@Daniel: go ahead, there’s nothing preventing you!
This blog entry is almost 24 years old now, but it’s still relevant. And yes, I was at Netscape through this mess, and I’ve seen similar disasters in other places.
https://www.joelonsoftware.com/2000/04/06/things-you-should-never-do-part-i/