I’m doing Open Source primarily because I love it. The social aspects, the for-the-good angle and for the challenge of engineering this to work for everyone. I also do it because it is my full-time job and getting food on the table and provide for my family is not unimportant. It may come as a shock, but I am not in this game for the money or the extravagant life style.
I have been working full-time on curl since 2019. For me, this typically means doing 50 hour work weeks, as I spend all days on it and then I top them off with a few more hours every late night – all days of the week, I spend all this time on curl because it is a work of love and it is both my job and my spare time hobby and no one counts my hours anyway. (And no, I do not recommend anyone else to do the same. I’m not suggesting this for others.)
I consider my primary work-related mission in life to be to make curl the best transfer library and tool possible and make it qualify as a top project in Open Source, quality, performance and not the least, security. I believe we generally meet these lofty goals.
I founded the curl project, I am still a lead developer in the project almost thirty years later. While I always clearly state that curl is not a one-man shop and that curl would absolutely not be what it is without my awesome curl team mates, a large part of the world still thinks of curl as my project and sometimes more or less equals curl with my person.
I cannot help to take curl issues personally. When someone critiques curl, it is by extension a complaint on decisions and choices I stand by and behind – and many cases I made the calls. curl is personal to me. curl has formed my life forever.
I have two kids. They were both born many years after I started working on curl and they are both adults and independent individuals now. I love them dearly. Life passes by but curl remains. We’ve had slow times and busy times. The decades pass.
Later this year the curl project celebrates thirty years. We typically repeat that the number of curl installations in the world is perhaps thirty billion.
Things changed
Over the last years I have done numerous blog posts on the state of security reports submitted to curl. They have gradually switched over from complaints on stupid LLMs, to stupid AI slop reports, closing the bug bounty over to the current high quality chaos which for us started maybe at some point in March 2026.
We have seen many spectacular security failures through the years, in Internet products, in software infrastructure and in Open Source. Every time we read about those events, we get reminded about how curl is everywhere and how we really really really do not want anything such to happen to us or our users. And we take another lap around the project, tighten every bolt a little more, add a few more checks, tests and guidelines to ideally make the curl ship ever so slightly less likely to ever leak or sink.
Scrutinized
Recently, after I pointed out that Mythos only found a single low severity problem in curl in its first scan, countless people have repeated the claim that curl is one of the most scrutinized, most reviewed, most fuzzed and most verified source codes you can imagine. Perhaps that’s true, but I just want to mention this: that’s not by mistake. That’s not an accident or a happy circumstance. That’s the result of relentless work and attention to details through decades. Software engineering done right. Iterative improvements over time that simply never ends is an effective method.
This does not however mean that we don’t have bugs or that we don’t have security problems left, because we do. We have hundreds of thousands of lines of source code that is doing highly parallel networking for many protocols on all imaginable operating systems and CPU architectures – in C. So we fix the problems, patch them up and ship new releases. Over and over.
Thirty billion installations world-wide means that everyone reading this blog post has curl installed multiple times in stuff they own. In phones, tablets, cars, TVs, printers, game consoles, kitchen equipment and more. Not to mention all the online digital services we use and those devices communicate with. I cannot stress the importance of curl security and I would guess that most of you agree with me.
I am jealous of those projects that shipped a horrible bug at some point in the past that made the world burn for a while. They got attention and some of them then got funding and financial muscles to get them staff and hire multiple full time engineers. I sometimes think we would be better off if we also had one of those.
Never-before experienced
A thirty years old project could make you think you’ve seen most things already, but we have not been in this situation before.
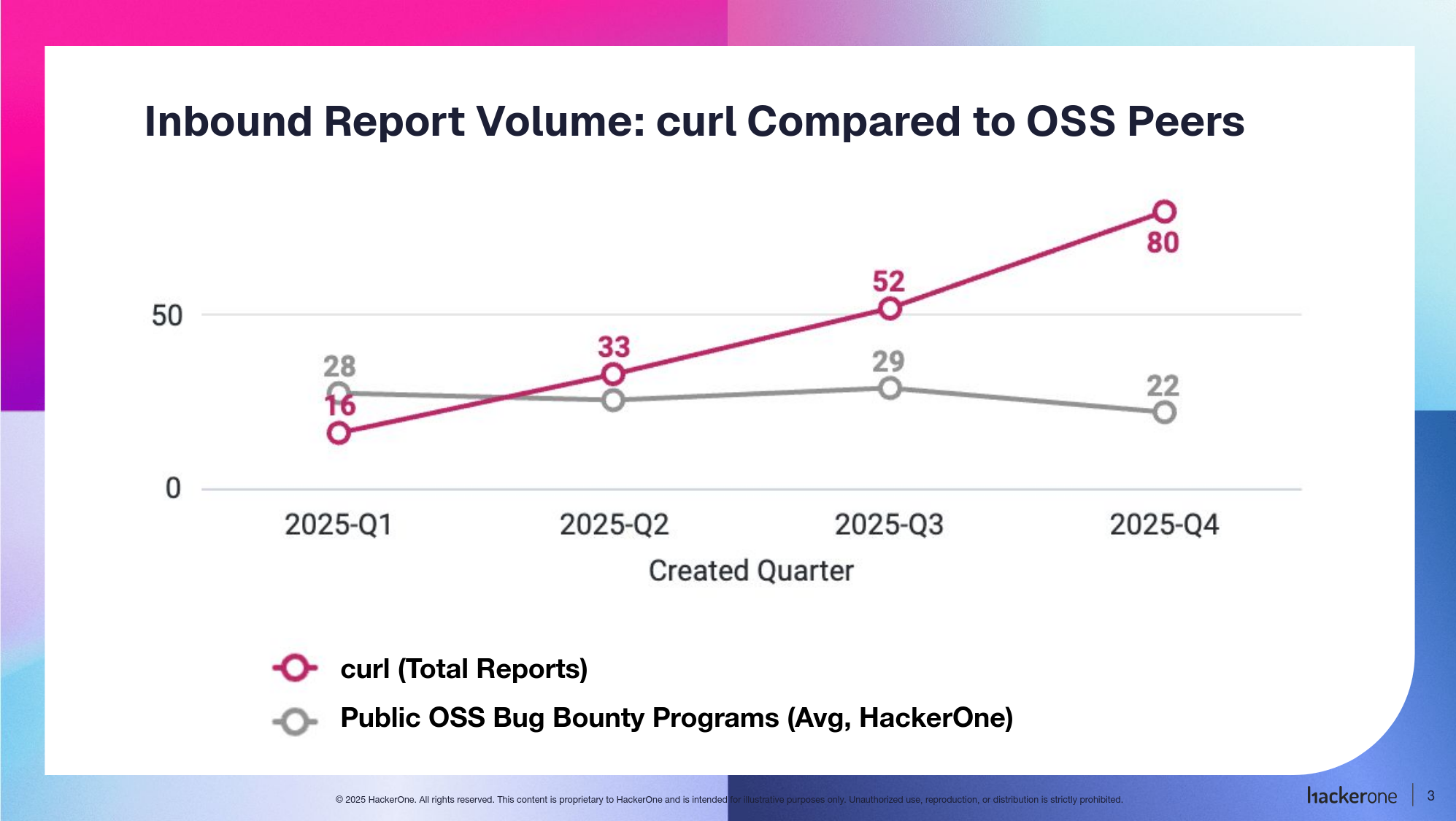
The rate of incoming security reports is 4-5 times higher than it was in 2024 and double the speed of 2025 – meaning that on average we now get more than one report per day. The quality is way higher than ever before. The reports are typically very detailed and long.
In order to manage this incoming flood of submissions, we need to make sure to handle them as soon as possible as we know there are more coming. If we don’t take care of them roughly at the same speed they arrive, the backlog just grows and having that list of potential security problems in a list that you don’t have control over takes a mental toll.
I spend almost all my days right now working through the list of reported security issues that we have on Hackerone. Verify the claim, assess the importance, write a patch, figure out when the bug was introduced, understand the vulnerability, write a detailed advisory explaining the problem to the world and communicate all this with the security researcher and the rest of the curl security team.
A health concern
For the first time in my life, my wife voiced concerns about my work hours and my imbalanced work/life situation. I work more than I’ve done before, but the flood keeps coming. People in my surrounding, I guess reading between the lines, have asked me how I and we cope with this deluge and want to make sure we don’t burn in the process. I am concerned for my team mates.
I might soon have to reduce my work hours to allow myself more breathing time.
This is a never-before seen or experienced pressure on the curl project and its security team members. An avalanche of high priority work that trumps all other things in the project that is primarily mental because we certainly could ignore them all if we wanted, but we feel a responsibility, we have a conscience and we are proud about our work. We feel obliged to fix security problems in the software we have helped shipped to every device on the globe. This is personal to us.
With about half the release cycle left until the pending release ships, we already have twelve confirmed vulnerabilities meaning twelve pending CVE announcements. That’s a new project record and it also means we will reach thirty published CVEs in 2026 even before half the calendar year has passed. The projected total amount of curl CVEs published through the whole year is therefore at least double this number!
Assistance
What help would we like? Short term it is a little late. We already have work up to our ears.
I wish more companies that use and depend upon curl or libcurl in commercial software and services would chime in their part to fund us. We could then pay more developers to distribute the work load across. That would be great. Feel free to contact me to discuss how you can contribute to this. Get your employer to pay for a support contract!
Fortunately we have customers who already do this, so some of us can work on curl full time.
I am a pragmatic (and a bit of a cynic) and I have danced this dance for a long time already. I have no illusions that anything significant is going to change in this area even if we are in an unparalleled situation and in a tighter spot than ever before. I totally expect us to ride out this storm by ourselves. Like we are used to. We will survive. We will endure. It might just be a bit of a shaky period in the project and in the world at large as we try to maneuver our way through this. There’s a tsunami coming over us and all we can do is swim, there are no life boats for us.
The curl project is not owned by a company. We are not part of any umbrella organization. This makes us a little under-powered at times, but it also gives us maximum freedom and flexibility. We act solely in the interest of making curl as good as possible for the world and curl users.
The good part
Fixing bugs and problems is good. Every reported problem implies a fixed issue. curl becomes a better product.
What is also a good trend: almost no one finds terrible vulnerabilities. All vulnerabilities found the last few years in curl have all been deemed severity LOW or MEDIUM. I’m not saying there won’t be any more HIGH ever, but at least they are rare. The most recent severity high curl CVE was published in October 2023.
Pressure
Right now we are under a little pressure. Forgive us if we are a little slow to respond sometimes.
Credits
Image by Brian Merrill from Pixabay