curl and libcurl are written in C. Rather low level components present in many software systems.
They are typically not part of any ecosystem at all. They’re just a tool and a library.
In lots of places on the web when you mention an Open Source project, you will also get the option to mention in which ecosystem it belongs. npm, go, rust, python etc. There are easily at least a dozen well-known and large ecosystems. curl is not part of any of those.
Recently there’s been a push for PURLs (Package URLs), for example when describing your specific package in a CVE. A package URL only works when the component is part of an ecosystem. curl is not. We can’t specify curl or libcurl using a PURL.
SBOM generators and related scanners use package managers to generate lists of used components and their dependencies. This makes these tools quite frequently just miss and ignore libcurl. It’s not listed by the package managers. It’s just in there, ready to be used. Like magic.
It is similarly hard for these tools to figure out that curl in turn also depends and uses other libraries. At build-time you select which – but as we in the curl project primarily just ships tarballs with source code we cannot tell anyone what dependencies their builds have. The additional libraries libcurl itself uses are all similarly outside of the standard ecosystems.
Part of the explanation for this is also that libcurl and curl are often shipped bundled with the operating system many times, or sometimes perceived to be part of the OS.
Most graphs, SBOM tools and dependency trackers therefore stop at the binding or system that uses curl or libcurl, but without including curl or libcurl. The layer above so to speak. This makes it hard to figure out exactly how many components and how much software is depending on libcurl.
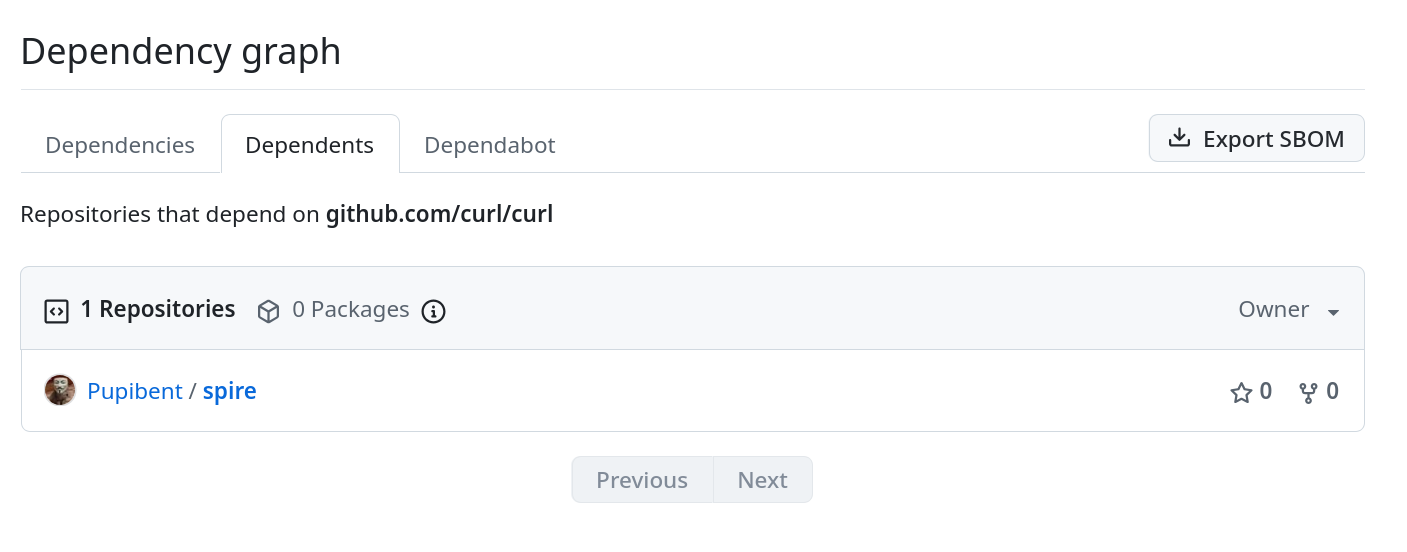
A perfect way to illustrate the problem is to check GitHub and see how many among its vast collection of many millions of repositories that depend on curl. After all, curl is installed in some thirty billion installations, so clearly it used a lot. (Most of them being libcurl of course.)
It lists one dependency for curl.
Repositories that depend on curl/curl: one. Screenshot taken on March 9, 2026
What makes this even more amusing is that it looks like this single dependent repository (Pupibent/spire) lists curl as a dependency by mistake.
When we announced the end of the curl bug-bounty at the end of January 2026, we simultaneously moved over and started accepting curl security reports on GitHub instead of its previous platform.
This move turns out to have been a mistake and we are now undoing that part of the decision. The reward money is still gone, there is no bug-bounty, no money for vulnerability reports, but we return to accepting and handling curl vulnerability and security reports on Hackerone. Starting March 1st 2026, this is now (again) the official place to report security problems to the curl project.
This zig-zagging is unfortunate but we do it with the best of intentions. In the curl security team we were naively thinking that since so many projects are already using this setup it should be good enough for us too since we don’t have any particular special requirements. We wrongly thought. Now I instead question how other Open Source projects can use this. It feels like an area and use case for Open Source projects that is under-focused: proper, secure and efficient vulnerability reporting without bug-bounty.
What we want from a security reporting system
To illustrate what we are looking for, I made a little list that should show that we’re not looking for overly crazy things.
Incoming submissions are reports that identify security problems.
The reporter needs an account on the system.
Submissions start private; only accessible to the reporter and the curl security team
All submissions must be disclosed and made public once dealt with. Both correct and incorrect ones. This is important. We are Open Source. Maximum transparency is key.
There should be a way to discuss the problem amongst security team members, the reporter and per-report invited guests.
It should be possible to post security-team-only messages that the reporter and invited guests cannot see
For confirmed vulnerabilities, an advisory will be produced that the system could help facilitate
If there’s a field for CVE, make it possible to provide our own. We are after all our own CNA.
Closed and disclosed reports should be clearly marked as invalid/valid etc
Reports should have a tagging system so that they can be marked as “AI slop” or other terms for statistical and metric reasons
Abusive users should be possible to ban/block from this program
Additional (customizable) requirements for the privilege of submitting reports is appreciated (rate limit, time since account creation, etc)
What’s missing in GitHub’s setup?
Here is a list of nits and missing features we fell over on GitHub that, had we figured them out ahead of time, possibly would have made us go about this a different way. This list might interest fellow maintainers having the same thoughts and ideas we had. I have provided this feedback to GitHub as well – to make sure they know.
GitHub sends the whole report over email/notification with no way to disable this. SMTP and email is known for being insecure and cannot assure end to end protection. This risks leaking secrets early to the entire email chain.
We can’t disclose invalid reports (and make them clearly marked as such)
Per-repository default collaborators on GitHub Security Advisories is annoying to manage, as we now have to manually add the security team for each advisory or have a rather quirky workflow scripting it. https://github.com/orgs/community/discussions/63041
We can’t edit the CVE number field! We are a CNA, we mint our own CVE records so this is frustrating. This adds confusion.
We want to (optionally) get rid of the CVSS score + calculator in the form as we actively discourage using those in curl CVE records
No CI jobs working in private forks is going to make us effectively not use such forks, but is not a big obstacle for us because of our vulnerability working process. https://github.com/orgs/community/discussions/35165
No “quote” in the discussions? That looks… like an omission.
We want to use GitHub’s security advisories as the report to the project, not the final advisory (as we write that ourselves) which might get confusing, as even for the confirmed ones, the project advisories (hosted elsewhere) are the official ones, not the ones on GitHub
No number of advisories count is displayed next to “security” up in the tabs, like for issues and Pull requests. This makes it hard to see progress/updates.
When looking at an individual advisory, there is no direct button/link to go back to the list of current advisories
In an advisory, you can only “report content”, there is no direct “block user” option like for issues
There is no way to add private comments for the team-only, as when discussing abuse or details not intended for the reporter or other invited persons in the issue
There is a lack of short (internal) identifier or name per issue, which makes it annoying and hard to refer to specific reports when discussing them in the security team. The existing identifiers are long and hard to differentiate from each other.
You quite weirdly cannot get completion help for @nick in comments to address people that were added into the advisory thanks to them being in a team you added to the issue?
There are no labels, like for issues and pull requests, which makes it impossible for us to for example mark the AI slop ones or other things, for statistics, metrics and future research
Email?
Sure, we could switch to handling them all over email but that also has its set of challenges. Including:
Hard to keep track of the state of each current issue when a number of them are managed in parallel. Even just to see how many cases are still currently open or in need of attention.
Hard to publish and disclose the invalid ones, as they never cause an advisory to get written and we rather want the initial report and the full follow-up discussion published.
Hard to adapt to or use a reputation system beyond just the boolean “these people are banned”. I suspect that we over time need to use more crowdsourced knowledge or reputation based on how the reporters have behaved previously or in relation to other projects.
Onward and upward
Since we dropped the bounty, the inflow tsunami has dried out substantially. Perhaps partly because of our switch over to GitHub? Perhaps it just takes a while for all the sloptimists to figure out where to send the reports now and perhaps by going back to Hackerone we again open the gates for them? We just have to see what happens.
We will keep iterating and tweaking the program, the settings and the hosting providers going forward to improve. To make sure we ship a robust and secure set of products and that the team doing so can do that
Gitlab, Codeberg and others are GitHub alternatives and competitors, but few of them offer this kind of security reporting feature. That makes them bad alternatives or replacements for us for this particular service.
The curl project moved over its source code hosting to GitHub in March 2010, but we kept the main bug tracker running like before – on Sourceforge.
It took us a few years, but in 2015 we finally ditched the Sourceforge version fully. We adopted and switched over to the pull request model and we labeled the GitHub issue tracker the official one to use for curl bugs. Announced on the curl website proper on March 9 2015.
GitHub holds issues and pull requests in the same number series, and since a few years back they also added discussions to the mix. This number is another pointless one, but it is large and even so let’s celebrate it!
Issue one in curl’s GitHub repository is from October 2010.
Issue 10,000 was created November 29, 2022. That meant 9,500 issues created in 2,597 days. 3.7 issues/day on average over seven years.
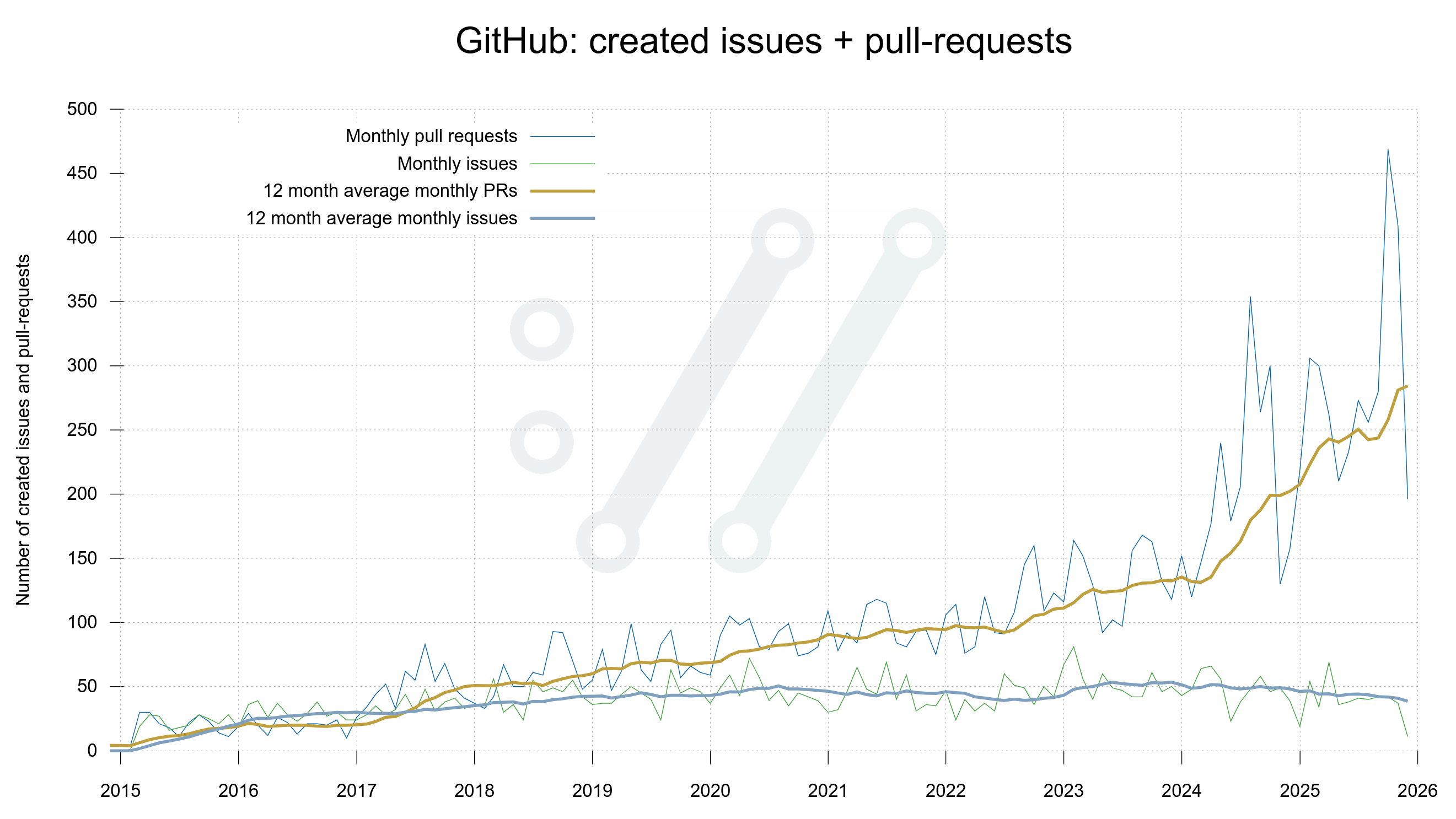
Issue 20,000 (a pull request really) was created today, on December 16, 2025. 10,000 more issues created in 1,113 days. 9 issues/day over the last three years.
The pace of which primarily new pull requests are submitted has certainly gone up over the recent years, as this graph clearly shows. (Since the current month is only half so far, the drop at the right end of the plot is quite expected.)
Number of issues and pull-requests submitted each month
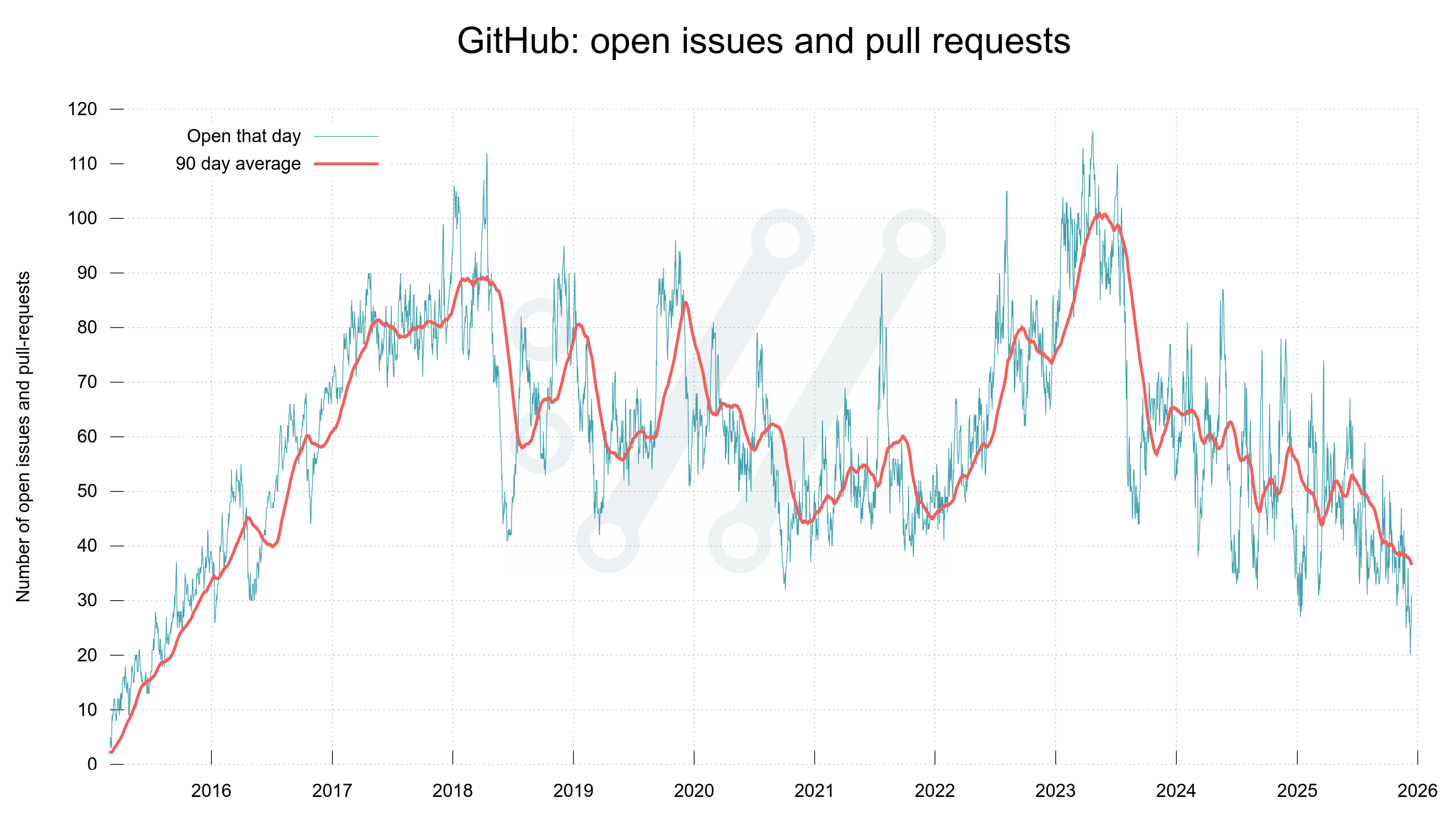
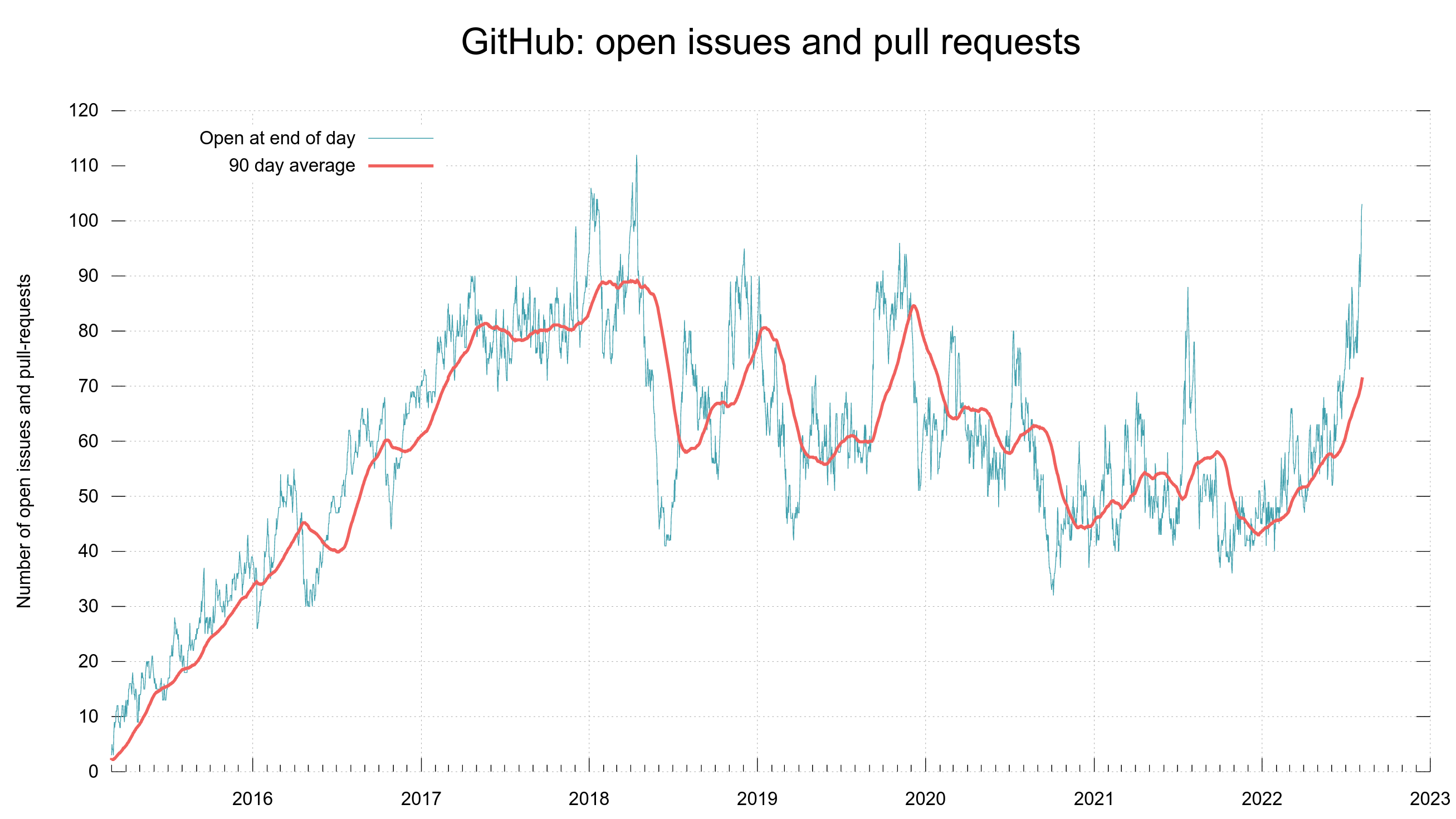
We work hard in the project to keep the number of open issues and pull requests low even when the frequency rises.
Number of open issues and pull requests any given day
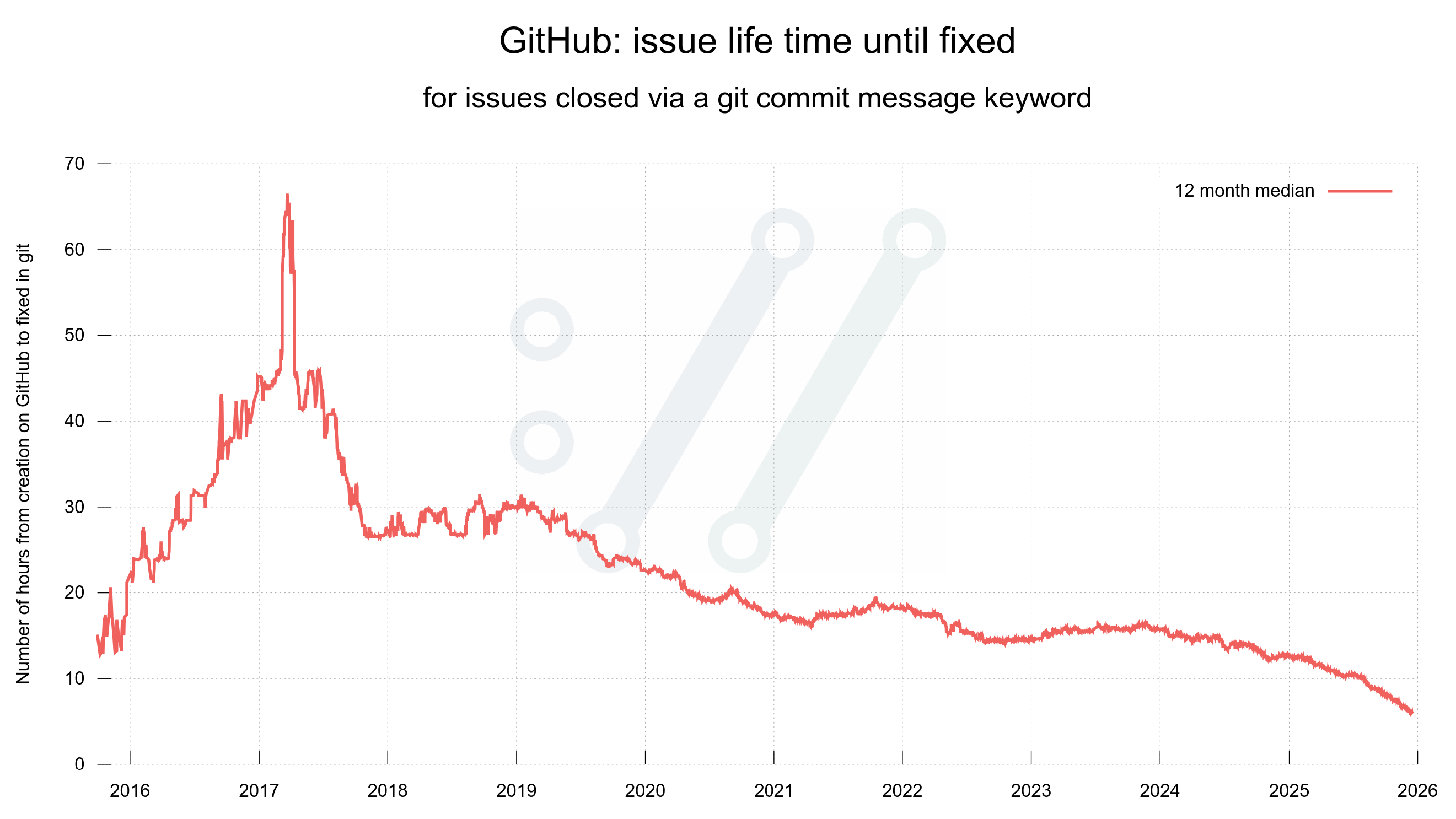
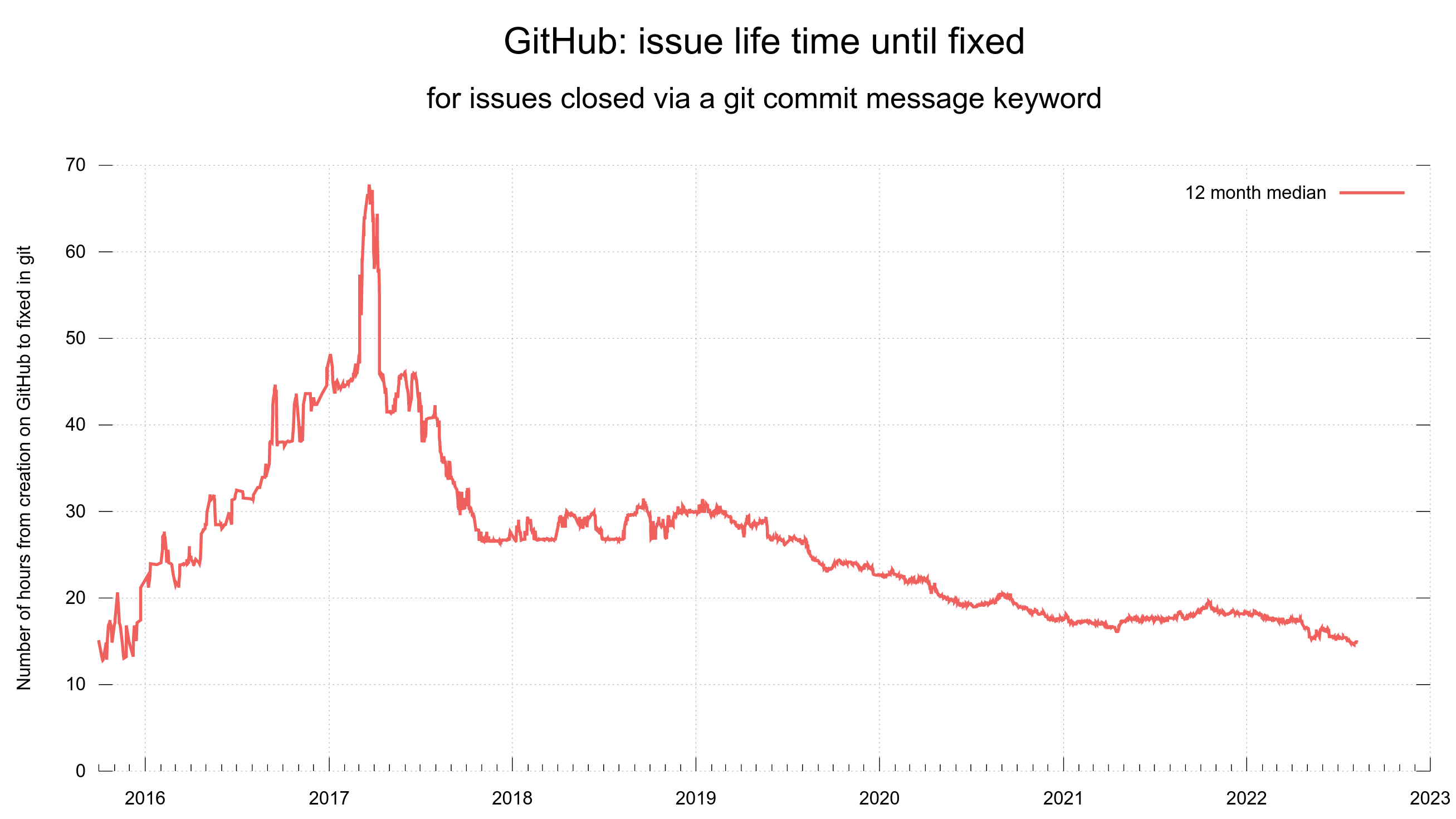
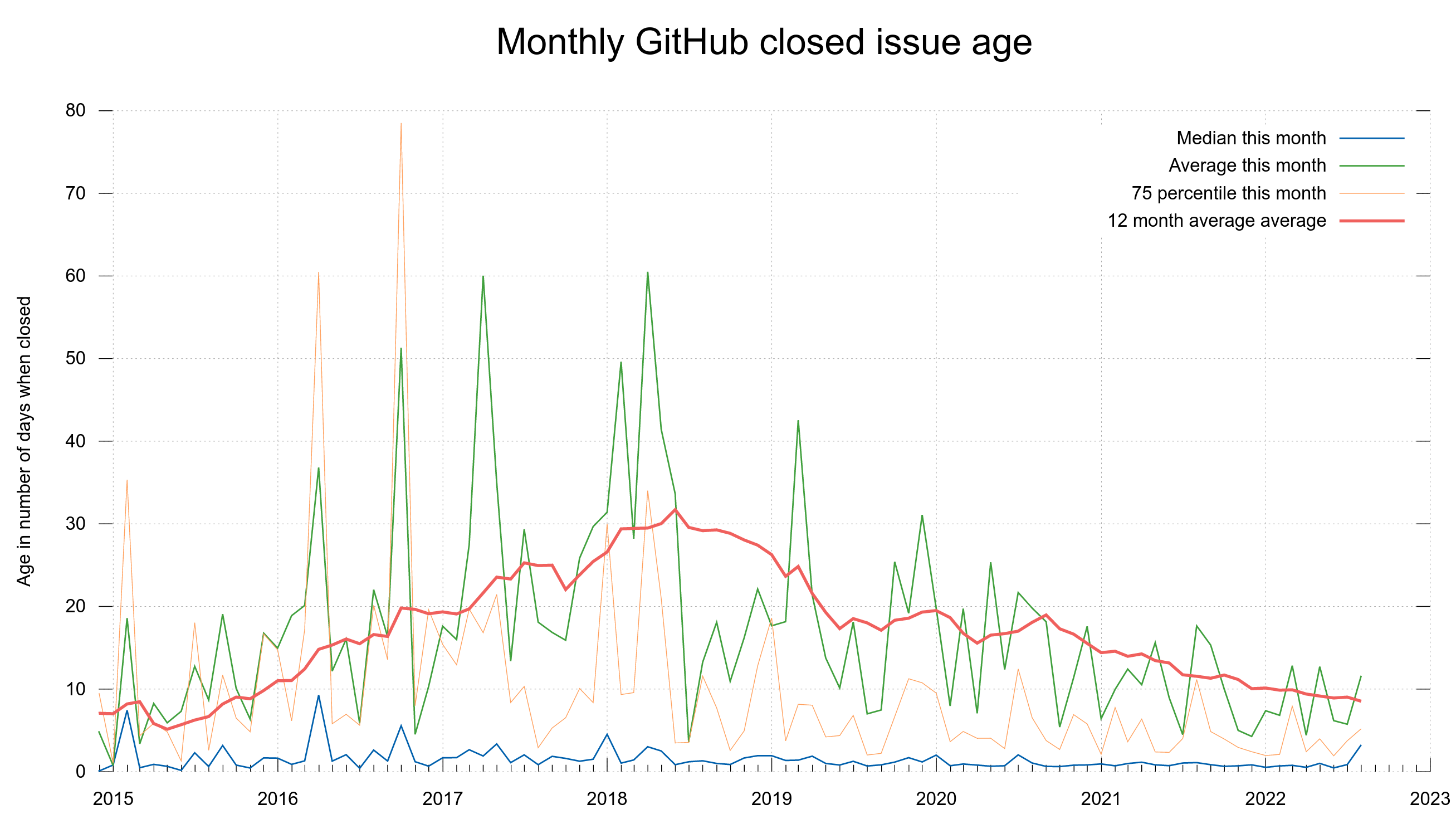
It can also be noted that issues and pull requests are typically closed fast. Out of the ones that are closed with instructions in the git commit message, the trend looks like below. Half of them are closed within 6 hours.
Number of hours until an issue is closed, when closed with git commit instructions
Of course, these graphs are updated daily and shown on the curl dashboard.
Note: we have not seen the AI slop tsunami in the issues and pull requests as we do on Hackerone. This growth is entirely human made and benign.
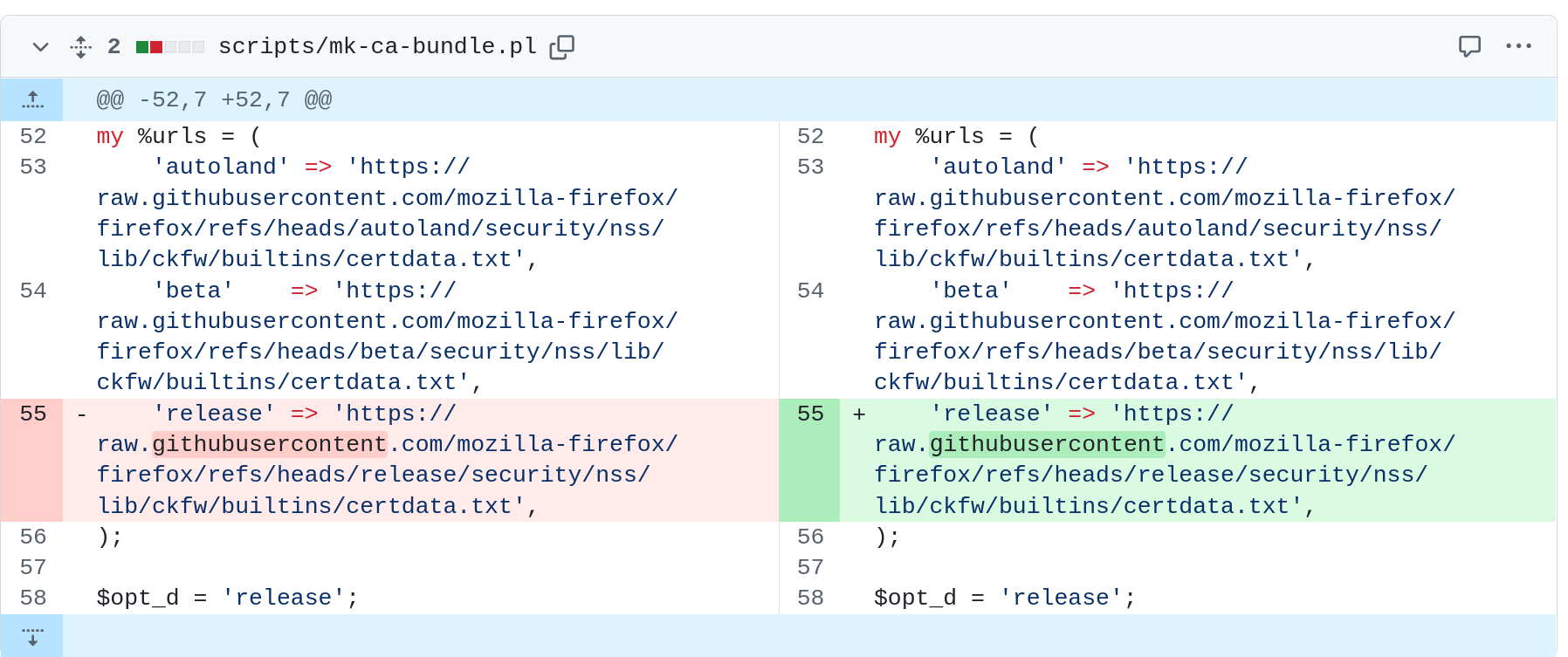
In a recent educational trick, curl contributor James Fuller submitted a pull-request to the project in which he suggested a larger cleanup of a set of scripts.
In a later presentation, he could show us how not a single human reviewer in the team nor any CI job had spotted or remarked on one of the changes he included: he replaced an ASCII letter with a Unicode alternative in a URL.
This was an eye-opener to several of us and we decided we needed to up our game. We are the curl project. We can do better.
GitHub
The replacement symbol looked identical to the ASCII version so it was not possible to visually spot this, but the diff viewer knows there is a difference.
In this GitHub website screenshot below I reproduced a similar case. The right-side version has the Latin letter ‘g’ replaced with the Armenian letter co. They appear to be the same.
GitHub shows a diff. But what is actually the difference?
The diff viewer says there is a difference but as a human it isn’t possible to detect what it is. Is it a flaw? Does it matter? If done “correctly”, it would be done together with a real and expected fix.
The impact of changing one or more letters in a URL can of course be devastating depending on conditions.
When I flagged about this rather big omission to GitHub people, I got barely no responses at all and I get the feeling the impact of this flaw is not understood and acknowledged. Or perhaps they are all just too busy implementing the next AI feature we don’t want.
Warnings
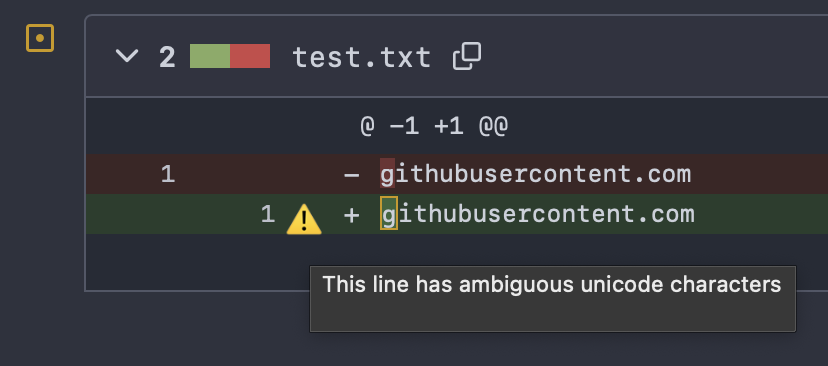
When we discussed this problem on Mastodon earlier this week, Viktor Szakats provided me with an example screenshot of doing a similar stunt with Gitea which quite helpfully highlights that there is something special about the replacement:
Gitea warns that the replacement is using “ambiguous Unicode characters”
I have been told that some of the other source code hosting services also show similar warnings.
As a user, I would actually like to know even more than this, but at least this warns about the proposed change clearly enough so that if this happens I would get the code manually and investigate before accepting such a change.
Detect
While we wait for GitHub to wake up and react (which I have no expectation will actually happen anytime soon), we have implemented checks to help us poor humans spot things like this. To detect malicious Unicode.
We have added a CI job that scans all files and validates every UTF-8 sequence in the git repository.
In the curl git repository most files and most content are plain old ASCII so we can “easily” whitelist a small set of UTF-8 sequences and some specific files, the rest of the files are simply not allowed to use UTF-8 at all as they will then fail the CI job and turn up red.
In order to drive this change home, we went through all the test files in the curl repository and made sure that all the UTF-8 occurrences were instead replaced by other kind of escape sequences and similar. Some of them were also used more or less by mistake and could easily be replaced by their ASCII counterparts.
The next time someone tries this stunt on us it could be someone with less good intentions, but now ideally our CI will tell us.
Confusables
There are plenty of tools to find similar-looking characters in different Unicode sets. One of them is provided by the Unicode consortium themselves:
This was yet another security-related fix reacting on a demonstrated problem. I am sure there are plenty more problems which we have not yet thought about nor been shown and therefore we do not have adequate means to detect and act on automatically.
We want and strive to be proactive and tighten everything before malicious people exploit some weakness somewhere but security remains this never-ending race where we can only do the best we can and while the other side is working in silence and might at some future point attack us in new creative ways we had not anticipated.
That future unknown attack is a tricky thing.
Update
(At 17:30 on the same day of the original post) GitHub has told me they have raised this as a security issue internally and they are working on a fix.
Screenshot from a recent pull request merged in the curl project on GitHub
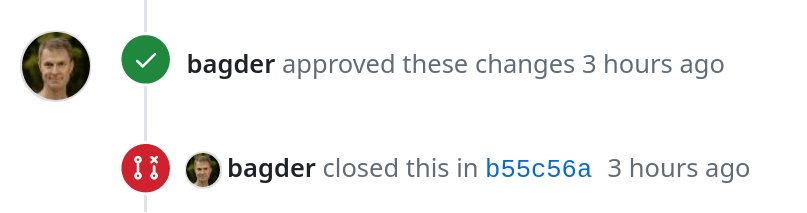
Contributors to the curl project on GitHub tend to notice the above sequence quite quickly: pull requests submitted do not generally appear as “merged” with its accompanying purple blob, instead they are said to be “closed”. This has been happening since 2015 and is probably not going to change anytime soon.
Screenshot showing how GitHub otherwise shows merges
If you make a pull request based on a single commit, the initial PR message is based on the commit message but when follow-up fixes are done and perhaps force-pushed, the PR message is not updated accordingly with the commit message’s updates.
Commit messages with style
I believe having good commit messages following a fixed style and syntax helps the project. It makes the git history better and easier to browse. It allows us to write tools and scripts around git and the git history. Like how we for example generate release notes and project stat graphs based on git log basically.
We also like and use a strictly linear history in curl, meaning that all commits are rebased on the master branch. Lots of the scripting mentioned above depends on this fact.
Manual merges
In order to make sure the commit message is correct, and in fact that the entire commit looks correct, we merge pull requests manually. That means that we pull down the pull request into a local git repository, clean up the commit message to adhere to project standards.
And then we push the commit to git. One or more of the commit messages in such a push then typically contains lines like:
Fixes #[number] and Closes #[number]. Those are instructions to GitHub and we use them like this:
Fixes means that this commit fixed an issue that was reported in the GitHub issue with that id. When we push a commit with that instruction, GitHub closes that issue.
Closes means that we merged a pull request with this id. (GitHub has no way for us to tell it that we merged the pull request.) This instruction makes GitHub closes the corresponding pull request: “[committer] closed this in [commit hash]”.
We do not let GitHub dictate how we do git. We use git and expect GitHub to reflect our git activity.
We COULD but we won’t
We could in theory fix and cleanup the commits locally and manually exactly the way we do now and then force-push them to the remote branch and then use the merge button on the GitHub site and then they would appear as “merged”.
That is however a clunky, annoying and time-consuming extra-step that not only requires that we (always) push code to other people’s branches, it also triggers a whole new round of CI jobs. This, only to get a purple blob instead of a red one. Not worth it.
If GitHub would allow it, I would disable the merge button in the GitHub PR UI for curl since it basically cannot be used correctly in the project.
Squashing all the commits in the PR is also not something we want since in many cases the changes should be kept as more than one commit and they need their own dedicated and correct commit message.
What GitHub could do
GitHub could offer a Merged keyword in the exact same style as Fixed and Closes, that just tells the service that we took care of this PR and merged it as this commit. It’s on me. My responsibility. I merged it. It would help users and contributors to better understand that their closed PR was in fact merged as that commit.
It would also have saved me from having to write this blog post.
In some post-publish discussions I have seen people ask about credits. This method to merge commits does not break or change how the authors are credited for their work. The commit authors remain the commit authors, and the one doing the commits (which is I when I do them) is stored separately. Like git always do. Doing the pushes manually this way does in no way change this model. GitHub will even count the commits correctly for the committer – assuming they use an email address their GitHub account does (I think).
When a security vulnerability has been found and confirmed in curl, we request a CVE Id for the issue. This is a global unique identifier for this specific problem. We request the ID from our CVE Numbering Authority (CNA), Hackerone, which once we make the issue public will publish all details about it to MITRE, which hosts the central database.
In the curl project we have until today requested CVE Ids for and provided information about 135 vulnerabilities spread out over twenty-five years.
A CVE identifier affects a specific product (or set of products), and the problem affects the product from a version until a fixed version. And then there is a severity. How bad is the problem?
CVSS score
The Common Vulnerability Scoring System (CVSS) is a way to grade severity on a scale from zero to ten. You typically use a CVSS calculator, fill in the info as good as you can and voilá, out comes a score.
The ranges have corresponding names:
Name
Range
Low
lower 4
Medium
4.0-6.9
High
7.0-8.9
Critical
9 or higher
CVSS is a shitty system
Anyone who ever gets a problem reported for their project and tries to assess and set a CVSS score will immediately realize what an imperfect, simplified and one-dimensional concept this is.
The CVSS score leaves out several very important factors like how widespread the affected platform is, how common the affected configuration is and yet it is still very subjective as you need to assess as and mark different things as None, Low, Medium or High.
The same bug is therefore likely to end up with different CVSS scores depending on who fills in the form – even when the persons are familiar with the product and the error in question.
curl severity
In the curl project we decided to abandon CVSS years ago because of its inherent problems. Instead we use only the four severity names: Low, Medium, High, and Critical and we work out the severity together in the curl security team as we work on the vulnerability. We make sure we understand the problem, the risks, its prevalence and more. We take all factors into account and then we set a severity level we think helps the world understand it.
All security vulnerabilities are vulnerabilities and therefore security risks, even the ones set to severity Low, but having the correct severity is still important in messaging and for the rest of the world to get a better picture of howserious the issue is. Getting the right severity is important.
NVD
Let me introduce yet another player in this game. The National Vulnerability Database (NVD). (And no, it’s not “national” really).
NVD hosts a database of vulnerabilities. All CVEs that are submitted to MITRE are sucked in into NVD’s database. NVD says it “performs analysis on CVEs that have been published to the CVE Dictionary“.
That last sentence is probably important.
NVD imports CVEs into their database and they in turn offer other databases to import vulnerabilities from them. One large and known user of the NVD database is this I mentioned in a recent blog post: GitHub Security Advisory Database (GHSA DB) .
GHSA DB
This GitHub thing an ambitious database that subsequently hosts a lot of vulnerabilities that people and projects reported themselves in addition to them importing information about all vulnerabilities ever published with CVE Ids.
This creates a huge database that in theory should contain just about every software vulnerability ever reported in the public. Pretty cool.
Enter reality
NVD, in their great wisdom, rescores the CVSS score for CVE Ids they import into their database! (It’s not clear how or why, but they seem to not do it for all issues).
NVD decides they know better than the project that set the severity level for the issue, enters their own answers in the CVSS calculator and eventually sets that new score on the CVEs they import.
NVD clearly thinks they need to do this and that they improve the state of the CVEs by this practice, but the end result is close to scaremongering.
Result
Because NVD sets their own severity level and they have some sort of “worst case” approach, virtually all issues that NVD sets severity for is graded worse or much worse when they do it than how we set the severity levels.
Let’s take an example: CVE-2022-42915: HTTP proxy double-free. We deemed this a medium severity. It was not made higher partly because of the very limited time-window between the two frees, making it harder to take advantage of.
Yes, it makes you wonder what magic insights and knowledge the person/bots on NVD possessed when they did this.
Scaremongering
The different severity levels should not matter too much but people find those inflated ones and they believe them. Users also find the discrepancies, get confused and won’t know what to believe or whom to trust. After all, NVD is trust-inducing brand. People think they know their stuff and if they say critical and the curl project says medium, what are we expected to think?
I claim that NVD overstate their severity levels and there unnecessarily scares readers and make them think issues are worse and more dangerous than they actually are.
The fact that GitHub now imports all CVE data from NVD makes these severity levels get transported, shown and believed as they are now also shown in the GHSA DB.
Look how many critical issues there are!
Not exactly GitHub’s fault
This NVD habit of re-scoring is an old existing habit and I just recently learned it. GitHub’s displaying the severity levels highlighted it for me, especially since users out there seem to trust and use this GitHub database.
I have talked to humans on the GitHub database team and I push for them to ignore or filter out the severity levels as set by NVD, if possible. But me being just a single complaining maintainer I do not expect this to have much of an effect. I would urge NVD to stop this insanity if I had any way to.
Hackerone glitches?
(Updated after first post). It turns out that some CVEs that we have filed from the curl project that uses our CNA hackerone have been submitted to MITRE without any severity level or CVSS score at all. For such issues, I of course understand why someone would put their own score on the issue because then our originally set score/severity is not passed on. Then the “blame” is instead shifted to Hackerone. I have contacted them about it.
Dispute a CVSS
NVD provides a way to dispute their rescores, but that’s just an open free-text form. I have use that form to request that NVD stop rescoring all curl issues. Although I honestly think they should rather stop all rescoring and only do that in the rare occasions where the original score or severity is obviously wrong.
I cannot dispute the severity levels at GitHub. They show the NVD levels.
Lots of people walked around the conference this year with sarcastic or otherwise amusing messages scrolling or blinking on them.
GitHub Social
When a few people at the GitHub Social event on the Saturday evening showed up wearing those badges, this triggered Martin Woodward (VP of DevRel for GitHub) who hosted the event, and he brought out his e-ink programmable badge from GitHub Universe and with a big smile on his face he showed off how cool it was and some of the functionality it holds. Combined with the story behind how he made this happen. Good stuff!
The red led badge immediately felt boring in comparison and in particular my friend Linus expressed his desire to get one. Martin explained how they had a few of them as prizes for the lottery of the evening. You would get one chance to win for every “hash collision” you could find – we all had gotten a hash code each on a sticker when we entered the place. Linus took off and searched for collisions with a frenzy, trying to maximize his chances.
Hash collisions
My fancy t-shirt front of the evening, showing my hash in the top left.
It was a fun and sufficiently nerdy social game that made us talk and mingle around a bit among the other fellow open source maintainers in the room and soon enough we found occasional collisions. I think I ended up finding three, Linus found six. Every time we wrote our names on a piece of paper and put it in a big container.
Socializing, beers, pizza and then eventually the time had come. No more collisions, time to see who had won.
Prizes
GitHub handed out many different prizes apart from the badges: GitHub pro subscriptions, hats and a huge GitHub Led logo.
I got the honors of picking the first five prizes: the pro subscriptions. Out of the five folded papers one of them had my name on it! Me already being a GitHub star (which offers that, and Martin knowing this), my name was instead replaced by another ticket. Still, I had apparently managed to pull my own name out of the hundreds of lottery tickets!
The badges
When the time come to pick the winners for the five badges, someone else fished up five tickets from the box and they were handed over to Martin to who read them, one by one.
Daniel Stenberg – I had won again! What are the odds? It was most hilarious, but then Martin continued, he read another name and then when he unfolded a ticket he looked a little surprised and said a little wondering another Stenberg? Yes, my brother Björn who was also present there then also won of those fun badges. What were the odds of that?!
Linus did not win one.
Linus, Björn and me are friends since over thirty years back (we are haxx.se) and since now two of us had won badges and the person who wanted it the most did not win, we of course could not resist to tease and taunt Linus plenty about it. What are friends for after all?
Leveling up
I knew how much Linus wanted one of these, so while I considered giving him mine, I first did a careful check with Martin. Did he possibly have an extra spare one that I could perhaps get my hands on for Linus?
He probably did. Over at his hotel he might have an extra. He even very graciously offered me that one like the champ he is.
Knowing that this possibility was in the pipeline, we could level up the taunting even more and really rub it in on Linus. Me and Björn thought it was mightily fun. You can probably say we were badgering him.
A midnight image
The GitHub event ended, we all walked out into the Brussels night, aiming to get some sleep to endure another intense FOSDEM full day the following Sunday. At 00:55 Martin messaged me this picture:
Sunday morning
Of course we reminded Linus already at breakfast how some of us actually have these cool badges and then maybe a few more times the following hours. We also shared the secret with other friends so the surrounding had a better understanding of what was going on.
In the meantime, I secretly coordinated a badge drop-off. My personal hero Martin delivered a box for Linus with this badge, I could pick it up and while pausing our badge-teasing, I could hand over the cardboard box to him with his GitHub handle on a sticker.
Here’s one for you
That expression. It took a few seconds for what just happened to sink in, before Linus realized exactly what had been going on since last night.
Priceless.
An e-ink programmable badge
The badge tech itself is a 296 x 128 pixels e-ink display powered by an FP2040 (Raspberry Pi) Dual Arm Cortex M0+ running at up to 133Mhz. Easily programmable too.
If you want one, pimoroni sells these beauties. (I have no relation with them.)
They call this the badger 2040, which is particularly fun since I use the nickname bagder since a long time, on GitHub and elsewhere. A badger badge for bagder.
Today, another 1,000 commits have been recorded as done by me in the curl source code git repository since November 2021. Out of a total of 29,608 commits to the curl source code repository, I have made 17,001. 57.42%.
In 2022, I have done 56% of all the commits in the curl source repository. I am also the only developer who works full time on curl all the time.
In 2022, 179 individuals authored commits that were merged into curl. 115 of them did that for the first time this year. Over curl’s life time, a total of 1104 persons have authored code merged into curl.
Do I ever get bored? Not yet. I will let you know if I do.
The preferred method of providing changes to the curl project, be it source code, documentation or web site contents, is by submitting a pull-request. A “PR”. On the curl repository on GitHub.
When a proposed curl change, bugfix or improvement is submitted as a PR on GitHub, it gets built, checked, tested and verified in countless ways and a few hundred developers get a notification about it.
The first thing I do every morning and the last thing I do every night before I go to bed, is eyeing through the list of open PRs, and especially the ones with recent activities. I of course also get back to them during the day if there is activity that might need my attention – not to mention that I also personally submit by own PRs to curl at an average rate of a few per day.
You can rightly say that my day and my work with curl is extremely PR centered. And by extension, also extremely git and GitHub focused.
Merging the work
When all the CI checks run green and all review comments and concerns have been addressed, the PR has become ripe for merge.
As a general rule, we always work in the master branch as the current development branch that is destined to become the next release when the time comes. An approved PR thus gets merged into the master branch and pushed there. We keep the git history linear and clean, meaning we do merge + rebase before pushing.
Commit messages
One of the key properties of a git commit, is the commit message. The text that describes the particular change in the repository.
In the curl project we have a standard style or template for how to write these messages. This makes them consistent and helps making them useful and get populated with informational meta-data that future versions of ourselves might appreciate when we look back at the changes decades into the future.
The PR review UI on GitHub unfortunately totally ignores commit messages, which means that we cannot comment on them or insist or check that users write them in our preferred style. Arguably, it is also just quicker and easier not to do that and instead just gently brush up the message in the commit locally before the commit is pushed.
Adding correct fixes #xxx and closes #xxx information to the message also helps making sure GitHub closes the associated issues/pull-requests and allows us to map git repository commits with GitHub activities at will – like when running statistic scripts etc.
This strictness and way of working makes it impossible to use the “merge” button in the GitHub UI since we simply cannot ensure that the commit is good enough with it. The button is however not possible to remove from the UI with any settings. We just prohibit its use.
They appear as “closed this in”
This way of working makes most PRs appear as “closed this in #[commit hash]” in the GitHub UI instead of saying “merged by” that same hash. Because in GitHub’s view, the PR was not merged.
GitHub could fix this with a merges keyword, which has been suggested since forever, but clearly they do not see this as a problem.
Occasional users of course get surprised or even puzzled by us closing the PR “instead of merging”, because that is what it looks like. When it really is not.
Ultimately, I consider the state and contents of our git repository and history more important than how the PRs appear on GitHub so I stick to our way of working.
Signed commits
As a little side-note, I of course also always GPG sign my commits so you can verify on GitHub and with git that my commits are genuinely done by me.
Stats
To give you an idea of the issue and pull request frequency and management in curl (the source code repository). Snapshots from the curl dashboard from August 8, 2022.
Update
Several people have mentioned to me after I posted this article that I could squash and edit the commits and force-push the work back to the user’s branch used for the PR before using the “merge” button or auto-merge feature of GitHub.
Sure, I could do it that way, but I think that is an even worse solution and a poor work-around. It is very intrusive method that would make me force-push in every user’s PR branch and I am certain a certain amount of users will be surprised by that and some even downright upset because it removes/overwrites their work. For the sake of working around a GitHub quirk. Nope, I will not do that.
Saturday June 18: I had some curl time in the afternoon and I was just about to go edit the four security advisories I had pending for the next release, to brush up the language and check that they read fine, when it dawned on me.
These particular security advisories were still in draft versions but maybe 90% done. There were details, like dates and links to current in-progress patches, left to update. I also like to reread them a few times, especially in a webpage rendered format, to make sure they are clear and accurate in describing the problem, the solution and all other details, before I consider them ready for publication.
I checked out my local git branch where I expected the advisories to reside. I always work on pending security details in a local branch named security-next-release or something like that. The branch and its commits remain private and undisclosed until everything is ready for publication.
(I primarily use git command lines in terminal windows.)
The latest commits in my git log output did not show the advisories so I did a rebase but git promptly told me there was nothing to rebase! Hm, did I use another branch this time?
It took me a few seconds to realize my mistake. I saw four commits in the git master branch containing my draft advisories and then it hit me: I had accidentally pushed them to origin master and they were publicly accessible!
The secrets I was meant to guard until the release, I had already mostly revealed to the world – for everyone who was looking.
How
In retrospect I can’t remember exactly how the mistake was done, but I clearly committed the CVE documents in the wrong branch when I last worked on them, a little over a week ago. The commit date say June 9.
On June 14, I got a bug report about a problem with curl’s .well-known/security.txt file (RFC 9116) where it was mentioned that our file didn’t have an Expires: keyword in spite of it being required in the spec. So I fixed that oversight and pushed the update to the website.
When doing that push, I did not properly verify exactly what other changes that would be pushed in the same operation, so when I pressed enter there, my security advisories that had accidentally been committed in the wrong branch five days earlier and still were present there were also pushed to the remote origin. Swooosh.
Impact
The advisories are created in markdown format, and anyone who would update their curl-www repository after June 14 would then get them into their local repository. Admittedly, there probably are not terribly many people who do that regularly. Anyone could also browse them through the web interface on github. Also probably not something a lot of people do.
These pending advisories would however not appear on the curl website since the build files were not updated to generate the HTML versions. If you could guess the right URL, you could still get the markdown version to show on the site.
Nobody reported this mistake in the four days they were visible before I realized my own mistake (and nobody has reported it since either). I then tried googling the CVE numbers but no search seemed to find and link to the commits. The CVE numbers were registered already so you would mostly get MITRE and other vulnerability database listings that were still entirely without details.
Decision
After some quick deliberations with my curl security team friends, we decided expediting the release was the most sensible thing to do. To reduce the risk that someone takes advantage of this and if they do, we limit the time window before the problems and their fixes become known. For curl users security’s sake.
Previously, the planned release date was set to July 1st – thirteen days away. It had already been adjusted somewhat to not occur on its originally intended release Wednesday to cater for my personal summer plans.
To do a proper release with several security advisories I want at least a few days margin for the distros mailing list to prepare before we go public with everything. There was also the Swedish national midsummer holiday coming up next weekend and I did not feel like ruining my family’s plans and setup for that, so I picked the first weekday after midsummer: June 27th.
While that is just four days earlier than what we had previously planned, I figure those four days might be important and if we imagine that someone finds a way to exploit one of these problems before then, then at least we shorten the attack time window by four days.
When working with my security advisories, I must pay more attention and be more careful with which branch I commit to.
When pushing commits to the website and I know I have pending security sensitive details locally that have not been revealed yet, I should make it a habit to double-check that what I am about to push is only and nothing but what I expect to be there.
Simultaneously, I have worked using this process for many years now and this is the first time I did this mistake. I do not think we need to be alarmist about it.














{kind=link}