Last spring I wrote a blog post about our ongoing work in the background to gradually simplify the curl source code over time.
This is a follow-up: a status update of what we have done since then and what comes next.
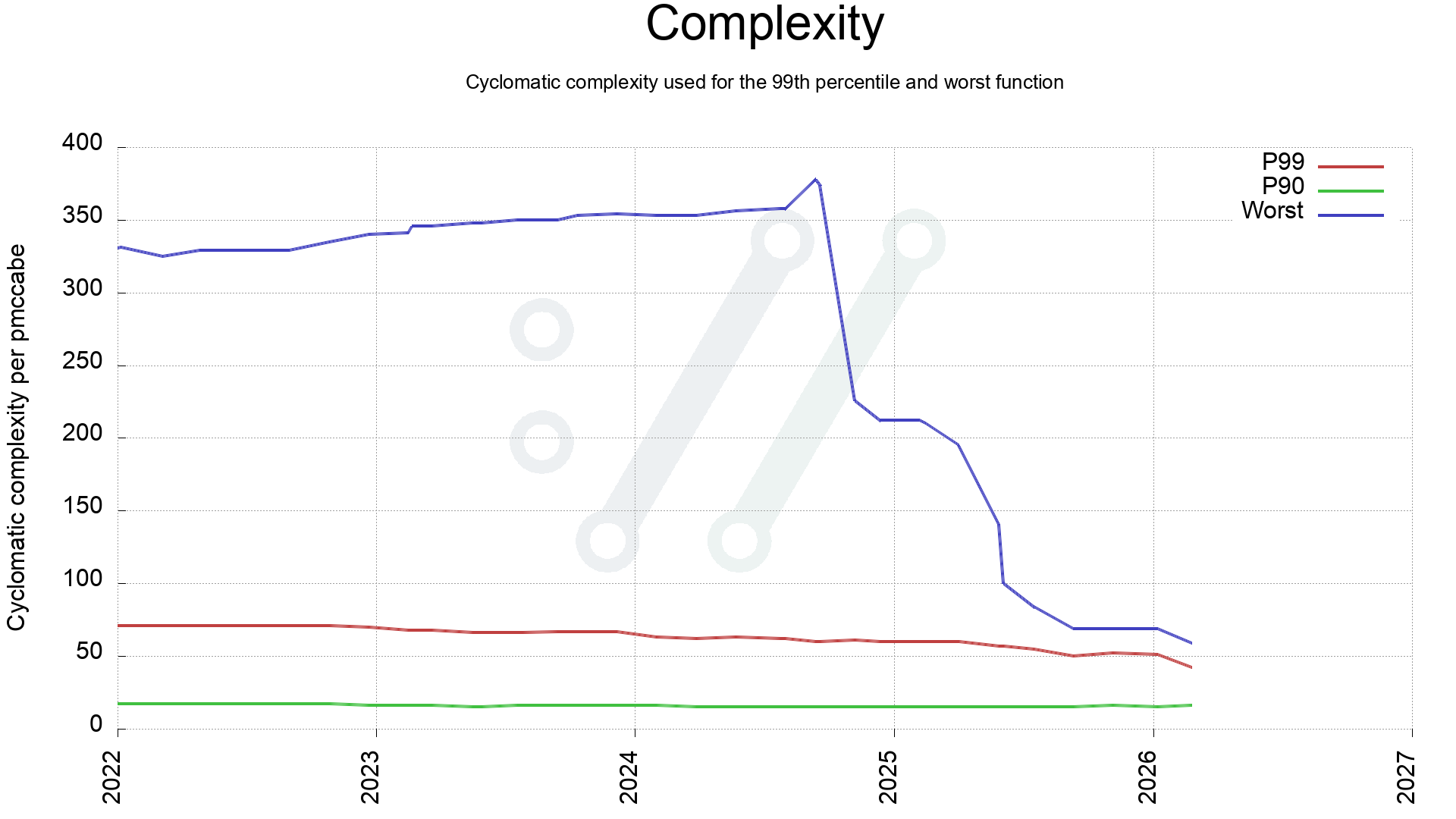
In May 2025 I had just managed to get the worst function in curl down to complexity 100, and the average score of all curl production source code (179,000 lines of code) was at 20.8. We had 15 functions still scoring over 70.
Almost ten months later we have reduced the most complex function in curl from 100 to 59. Meaning that we have simplified a vast number of functions. Done by splitting them up into smaller pieces and by refactoring logic. Reviewed by humans, verified by lots of test cases, checked by analyzers and fuzzers,
The current 171,000 lines of code now has an average complexity of 15.9.
Complexity
The complexity score in this case is just the cold and raw metric reported by the pmccabe tool. I decided to use that as the absolute truth, even if of course a human could at times debate and argue about its claims. It makes it easier to just obey to the tool, and it is quite frankly doing a decent job at this so it’s not a problem.
How to simplify
In almost all cases the main problem with complex functions is that they do a lot of things in a single function – too many – where the functionality performed could or should rather be split into several smaller sub functions. In almost every case it is also immediately obvious that when splitting a function into two, three or more sub functions with smaller and more specific scopes, the code gets easier to understand and each smaller function is subsequently easier to debug and improve.
Development
I don’t know how far we can take the simplification and what the ideal average complexity score of a the curl code base might be. At some point it becomes counter-effective and making functions even smaller then just makes it harder to follow code flows and absorbing the proper context into your head.
Graphs
To illustrate our simplification journey, I decided to render graphs with a date axle starting at 2022-01-01 and ending today. Slightly over four years, representing a little under 10,000 git commits.
First, a look a the complexity of the worst scored function in curl production code over the last four years. Comparing with P90 and P99.
The most complex function in curl over time
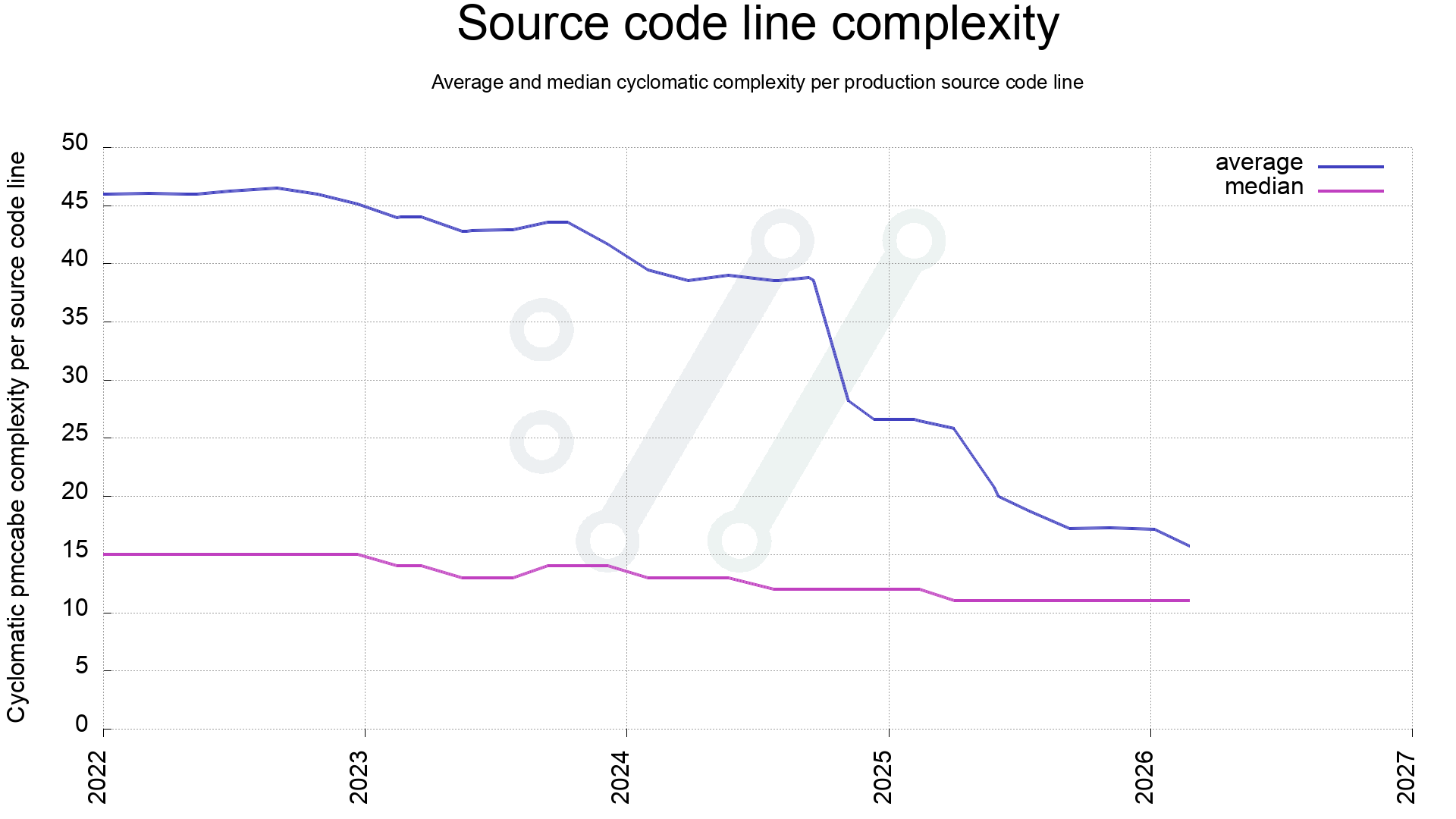
Identifying the worst function might not say too much about the code in general, so another check is to see how the average complexity has changed. This is calculated like this:
All functions get a complexity score by pmccabe
Each function has a number of lines
For all functions, add its function-score x function-length to a total complexity score, and in the end, divide that total complexity score on total number of lines used for all functions. Also do the same for a median score.
Average and median complexity per source code line in curl, over time.
When 2022 started, the average was about 46 and as can be seen, it has been dwindling ever since, with a few steep drops when we have merged dedicated improvement work.
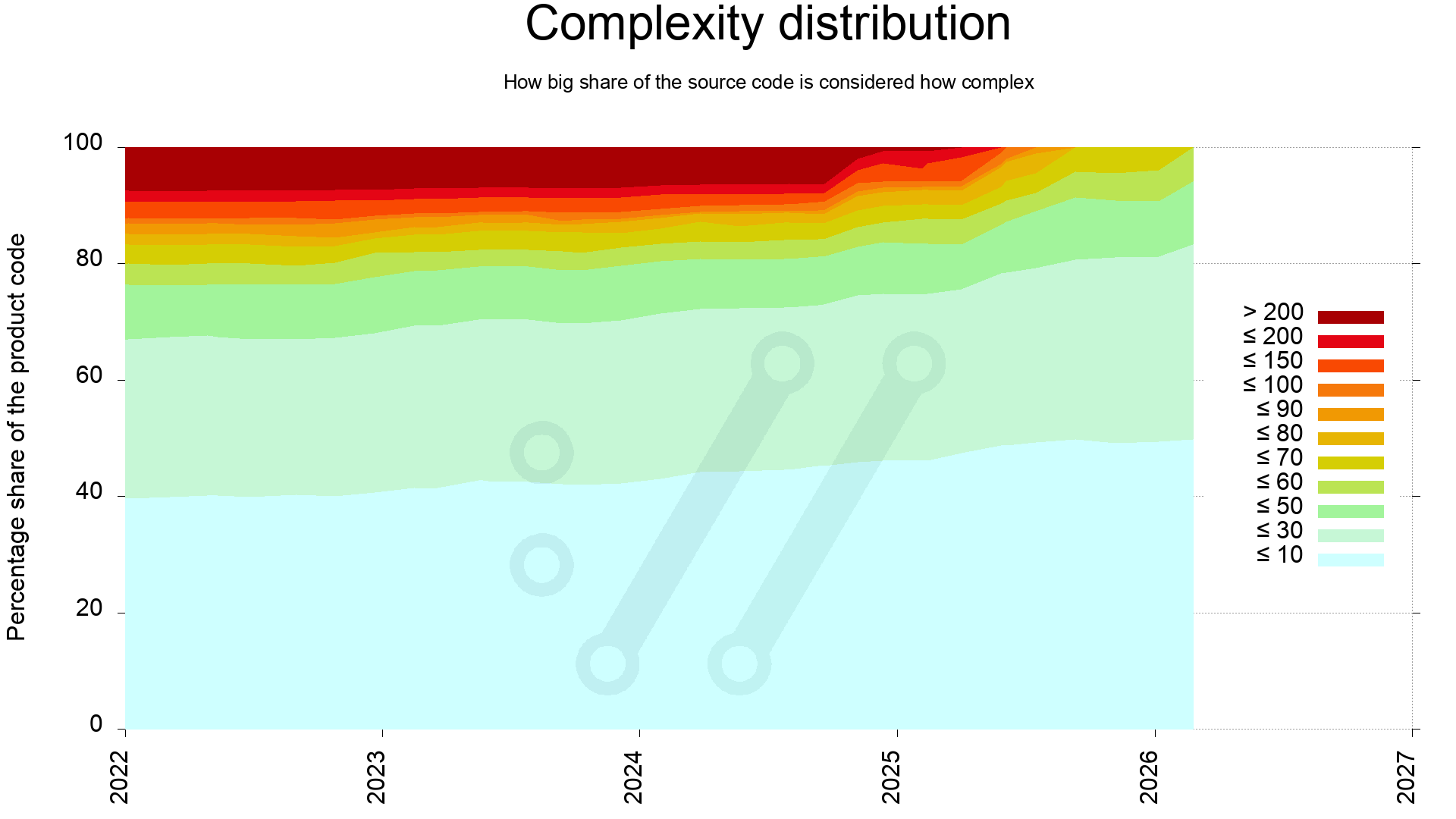
One way to complete the average and median lines to offer us a better picture of the state, is to investigate the complexity distribution through-out the source code.
How big portion of the curl source code is how complex
This reveals that the most complex quarter of the code in 2022 has since been simplified. Back then 25% of the code scored above 60, and now all of the code is below 60.
It also shows that during 2025 we managed to clean up all the dark functions, meaning the end of 100+ complexity functions. Never to return, as the plan is at least.
Does it matter?
We don’t really know. We believe less complex code is generally good for security and code readability, but it is probably still too early for us to be able to actually measure any particular positive outcome of this work (apart from fancy graphs). Also, there are many more ways to judge code than by this complexity score alone. Like having sensible APIs both internal and external and making sure that they are properly and correctly documented etc. The fact that they all interact together and they all keep changing, makes it really hard to isolate a single factor like complexity and say that changing this alone is what makes an impact.
Additionally: maybe just the refactor itself and the attention to the functions when doing so either fix problems or introduce new problems, that is then not actually because of the change of complexity but just the mere result of eyes giving attention on that code and changing it right then.
Maybe we just need to allow several more years to pass before any change from this can be measured?
In the standard libc API set there are multiple functions provided that do ASCII numbers to integer conversions.
They are handy and easy to use, but also error-prone and quite lenient in what they accept and silently just swallow.
atoi
atoi() is perhaps the most common and basic one. It converts from a string to signed integer. There is also the companion atol() which instead converts to a long.
Some problems these have include that they return 0 instead of an error, that they have no checks for under or overflow and in the atol() case there’s this challenge that long has different sizes on different platforms. So neither of them can reliably be used for 64-bit numbers. They also don’t say where the number ended.
Using these functions opens up your parser to not detect and handle errors or weird input. We write better and stricter parser when we avoid these functions.
strtol
This function, along with its siblings strtoul() and strtoll() etc, is more capable. They have overflow detection and they can detect errors – like if there is no digit at all to parse.
However, these functions as well too happily swallow leading whitespace and they allow a + or – in front of the number. The long versions of these functions have the problem that long is not universally 64-bit and the long long version has the problem that it is not universally available.
The overflow and underflow detection with these function is quite quirky, involves errno and forces us to spend multiple extra lines of conditions on every invoke just to be sure we catch those.
curl code
I think we in the curl project as well as more or less the entire world has learned through the years that it is usually better to be strict when parsing protocols and data, rather than be lenient and try to accept many things and guess what it otherwise maybe meant.
As a direct result of this we make sure that curl parses and interprets data exactly as that data is meant to look and we error out as soon as we detect the data to be wrong. For security and for solid functionality, providing syntactically incorrect data is not accepted.
This also implies that all number parsing has to be exact, handle overflows and maximum allowed values correctly and conveniently and errors must be detected. It always supports up to 64-bit numbers.
strparse
I have previously blogged about how we have implemented our own set of parsing function in curl, and these also include number parsing.
curlx_str_number() is the most commonly used of the ones we have created. It parses a string and stores the value in a 64-bit variable (which in curl code is always present and always 64-bit). It also has a max value argument so that it returns error if too large. And it of course also errors out on overflows etc.
This function of ours does not allow any leading whitespace and certainly no prefixing pluses or minuses. If they should be allowed, the surrounding parsing code needs to explicitly allow them.
The curlx_str_number function is most probably a little slower that the functions it replaces, but I don’t think the difference is huge and the convenience and the added strictness is much welcomed. We write better code and parsers this way. More secure. (curlx_str number source code)
History
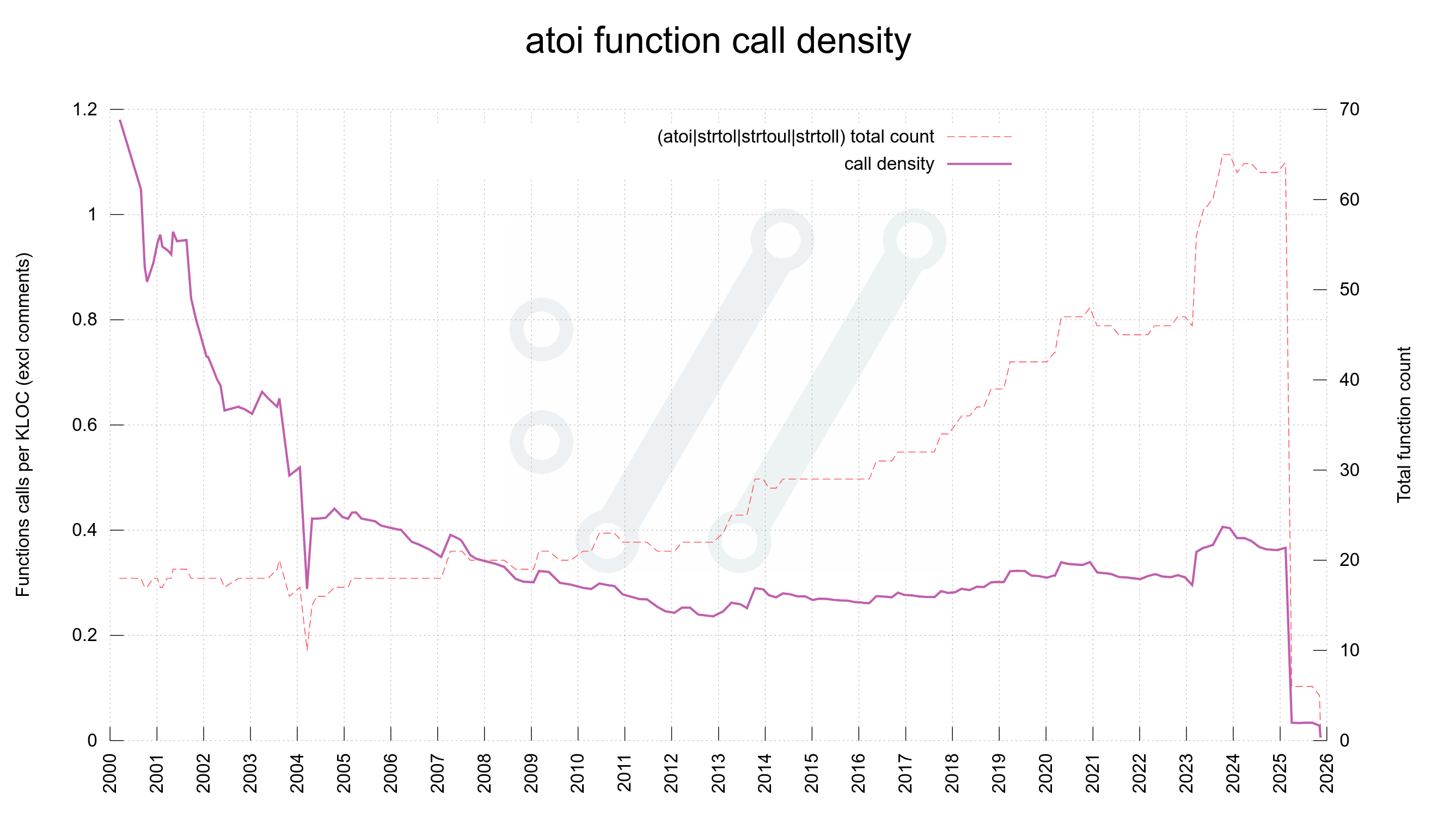
As of yesterday, November 12 2025 all of those weak functions calls have been wiped out from the curl source code. The drop seen in early 2025 was when we got rid of all strtrol() variations. Yesterday we finally got rid of the last atoi() calls.
libc number function call density in curl production code
The function mentioned above uses a ‘curlx’ prefix. We use this prefix in curl code for functions that exist in libcurl source code but that be used by the curl tool as well – sharing the same code without them being offered by the libcurl API.
A thing we do to reduce code duplication and share code between the library and the command line tool.
One of the most common reactions or questions I get about curl when I show up at conferences somewhere and do presentations:
— is curl still being actively developed?
How many more protocols can there be? This of course being asked by people without very close proximity or insight into the curl project and probably neither into the internet protocol world – which frankly probably is most of the civilized world. Still, these questions keep surprising me. Can projects actually ever get done?
(And do people really believe that adding protocols is the only thing that is left to do?)
Everything changes
There are new car models being made every year in spite of the roads being mostly the same for the last decades and there are new browser versions shipped every few weeks even though the web to most casual observers look roughly the same now as it did a few years ago. Etc etc. Even things such as shoes or bicycles are developed and shipped in new versions every year.
In spite of how it may appear to casual distant observers, very few things remain the same over time in this world. This certainly is also true for internet, the web and how to do data transfers over them. Just five years ago we did internet transfers differently than how we (want to) do them today. New tweaks and proposals are brought up at least on a monthly basis.
Not evolving implies stagnation and eventually… death.
As standards, browsers and users update their expectations, curl does as well. curl needs to adapt and keep up to stay relevant. We want to keep improving it so that it can match and go beyond what people want from it. We want to help drive and push internet transfer technologies to help users to do better, more efficient and more secure operations. We like carrying the world’s infrastructure on our shoulders.
It might evolve for decades to come
One of the things that actually have occurred to me, after having worked on this project for some decades by now – and this is something I did not at all consider in the past, is that there is a chance that the project will remain alive and in use the next few decades as well. Because of exactly this nothing-ever-stops characteristic of the world around us, but also of course because of the existing amount of users and usage.
Current development should be done with care, a sense of responsibility and with the anticipation that we will carry everything we merge today with us for several more decades – at least. At the latest curl up meeting, I had session I called 100 year curl where I brought up thoughts for us as a project that we might need to work on and keep in mind if indeed we believe the curl project will and should be able to celebrate its 100th birthday in a future. It is a slightly overwhelming (terrifying even?) thought but in my opinion not entirely unrealistic. And when you think about it, we have already traveled almost 30% of the way towards that goalpost.
But it looks the same
— I used curl the first time decades ago and it still looks the same.
This is a common follow-up statement. What have we actually done during all this time that the users can’t spot?
A related question that to me also is a little amusing is then:
— You say you worked on curl full time since 2019, but what do you actually do all days?
We work hard at maintaining backwards compatibility and not breaking existing use cases. If you cannot spot any changes and your command lines just keep working, it confirms that we do things right. curl is meant to do its job and stay out of the way. To mostly be boring. A dull stack is a good stack.
We have refactored and rearranged the internal architecture of curl and libcurl several times in the past and we keep doing it at regular intervals as we improve and adapt to new concepts, new ideas and the ever-evolving world. But we never let that impact the API, the ABI or by breaking any previously working curl tool command lines.
I personally think that this is curl’s secret super power. The one thing we truly have accomplished and managed to stick to: stability. In several aspects of the word.
curl offers stability in an unstable world.
Now more than ever
Counting commit frequency or any other metric of project activity, the curl project is actually doing more development now and at a higher pace than ever before during its entire lifetime.
We do this to offer you and everyone else the best, the most reliable, the fastest, the most feature rich, the best documented and the most secure internet transfer library on the planet.
Sprout is the name of my new machine that just arrived. The crowd-funded laptop. Since this beauty is graciously sponsored by a large crowd of people I felt I should share a little bit of its journey and entry into my life.
First I needed a name for it, and since it is small and is meant to grow with me a bit, I think Sprout feels apt.
The crowd-funding
Starting the initiative on a Saturday afternoon might not have been the most clever thing to get widest possible reach, but it seems it did not matter. We reached the goal of 3,500 USD within 90 minutes and people have kept on donating even after that and the counter is now at 7,000 USD. Amazing.
As mentioned: all surplus ends up in the general curl fund and will be used solely and exclusively to cover expenses that benefit and favor curl and its development. That is a promise. The curl fund is also completely open and transparent so everyone who wants to can in fact monitor our finances to verify this.
Specs
I decided to go with a Framework laptop because I like and want to support their concept of modular and upgradable laptops. After the overwhelming funding round, I decided to go with the top of the line AMD CPU alternative they offer, 96GB of RAM and 4TB of storage. This should make the laptop last a while I think.
CPU: AMD Ryzen AI 9 HX 370. Up to 5.1 GHz. 12 cores, 24 threads.
Graphics (integrated): AMD Radeon 890M. Up to 2.9GHz. 16 Graphics Cores
The laptop has four slots available for ports. I have USB-C, USB-A, HDMI and external Ethernet modules. I bought a few more than four, because I don’t know which exact setup I will prefer and they are interchangeable so I can change them according to the situation I’m in.
Dimensions compared to the old
My old laptop was a Lenovo T470S 14″.
Dimensions: 18.8 mm x 331 mm x 226.8 mm Weight 1.32 kg
So the new one is 3 mm thinner, 3 cm narrower and pretty much the same depth (+2mm) and pretty much the same weight.
Assembling
Ordered without Windows installed (of course), this thing arrived like an IKEA flat-pack and there was some assembly required. The necessary screwdriver comes included and I could complete the task in under ten minutes. Not at all complicated.
The Framework 13 as shipped: without memory, storage, keyboard, bezel etc.
Linux
I noticed two different Linux distributions offered as “easy installs” with guides from Framework, but as none of them were Debian I opted to take the more complicated route.
Debian
I downloaded a DVD iso image for Debian testing, copied it onto a USB stick and booted up Sprout with it. The installation went like a breeze and it detected the Wifi networking just fine.
Once the system came up for real without the USB stick, I edited the necessary files and took it up to current Debian Unstable over wifi with no problems.
Initial glitches
I experienced some glitches (X or the keyboard or something would stop accepting input after 5-15 minutes of use), which I first thought was due to an older Linux kernel as I had friends tell me that I might need 6.15+ for proper hibernation support and Debian unstable only has a 6.12 one just now. I switched to the Debian experimental kernel (6.16-rc7) but the issue remained. Hm?
I then remembered I hadn’t upgraded the laptop BIOS to its latest version yet, and after having invoked
fwupdmgr refresh --force
fwupdmgr get-updates
fwupdmgr update
and done a reboot, it first seemed to have fixed the problems but I was wrong. Is it X11 related? I have now switched my desktop to Plasma/Wayland to see if it fixes the problem. I might switch around a little bit more if I see it again because it is clearly a software glitch and not a hardware problem. Hardly Framework’s fault but instead more of a thing that happens occasionally when you run bleeding edge stuff. I’ll sort it out.
Console
Having a small but high DPI screen and trying to use the console with its default (tiny) font is next to impossible, at least with my aging eyes, so I spent a few minutes to figure out how to use setfont and then to invoke dpkg-reconfigure console-setup.
I find it a little curious that the Debian installer doesn’t have any easy provided option to do this already at install time.
A message
A few days after I had received my laptop I received a package via FedEx, and as I opened it I found this lovely note and some presents from Framework!
I know some of my followers tagged and mentioned Framework during the crowdfunding campaign but I of course didn’t expect anything from that.
A note from the Framework founderGifts from Framework
The thing that looks like a CD-R among the gifts is actually a mouse mat, slightly larger than a CD. The small packages are USB-C modules for the laptop.
This little message still holds and shows more appreciation than what I have received from most companies that ever used my Open Source. It’s not a high bar. I truly appreciate it – said entirely without sarcasm.
Impressions and Performance
Just to give you a small idea of the performance difference, I decided to compare a simple but common operation I do. Build curl. It basically requires three command lines:
autoreconf -fi
This invokes a series of tools to setup the build.
Sprout: 4.8 seconds
Old: 9.3 seconds
Diff: 1.9 times faster
configure –with-openssl
A long series of single-threaded tests of the environment. Lots of invokes of gcc to check for features, functions etc.
Sprout: 10.4 seconds
Old: 11.1 seconds
Diff: 1.1 times faster
make -sj
This invokes gcc and forks off lots of new processes. The old machine’s 4 threads vs the new 24 threads probably plays a role here.
This is not a full-time development machine for me and I have never been fully productive on a laptop and I don’t expect to be on this new one either. I don’t think a laptop keyboard exists that can satisfy me the way a proper one can.
The Framework one does not have dedicated page up/down keys for example. The keys still feel decently fine to press and I think I will adjust to the layout over time.
Stickers
I offered everyone who donated 200 USD or more for the laptop sticker space on my cover, but so far not a single one has reached out to make this reality. To honor my promise I intend to wait a little while before I put my first stickers on it.
For reference this is what my old laptop looks like.
It is a somewhat common question to me: how do we write C in curlto make it safe and secure for billions of installations? Some precautions we take and decisions we make. There is no silver bullet, just guidelines. As I think you can see for yourself below they are also neither strange nor surprising.
The ‘c’ in curl does not and never did stand for the C programming language, it stands for client.
Disclaimer
This text does in no way mean that we don’t occasionally merge security related bugs. We do. We are human. We do mistakes. Then we fix them.
Testing
We write as many tests as we can. We run all the static code analyzer tools we can on the code – frequently. We run fuzzers on the code non-stop.
C is not memory-safe
We are certainly not immune to memory related bugs, mistakes or vulnerabilities. We count about 40% of our security vulnerabilities to date to have been the direct result of us using C instead of a memory-safe language alternative. This is however a much lower number than the 60-70% that are commonly repeated, originating from a few big companies and projects. If this is because of a difference in counting or us actually having a lower amount of C problems, I cannot tell.
Over the last five years, we have received no reports identifying a critical vulnerability and only two of them were rated at severity high. The rest ( 60 something) have been at severity low or medium.
We currently have close to 180,000 lines of C89 production code (excluding blank lines). We stick to C89 for widest possible portability and because we believe in continuous non-stop iterating and polishing and never rewriting.
Readability
Code should be easy to read. It should be clear. No hiding code under clever constructs, fancy macros or overloading. Easy-to-read code is easy to review, easy to debug and easy to extend.
Smaller functions are easier to read and understand than longer ones, thus preferable.
Code should read as if it was written by a single human. There should be a consistent and uniform code style all over, as that helps us read code better. Wrong or inconsistent code style is a bug. We fix all bugs we find.
We have tooling that verify basic code style compliance.
Narrow code and short names
Code should be written narrow. It is hard on the eyes to read long lines, so we enforce a strict 80 column maximum line length. We use two-spaces indents to still allow us to do some amount of indent levels before the column limit becomes a problem. If the indent level becomes a problem, maybe it should be split up in several sub-functions instead?
Also related: (in particular local) identifiers and names should be short. Having long names make them hard to read, especially if there are multiple ones that are similar. Not to mention that they can get hard to fit within 80 columns after some amount of indents.
So many people will now joke and say something about wide screens being available and what not but the key here is readability. Wider code is harder to read. Period. The question could possibly be exactly where to draw the limit, and that’s a debate for every project to have.
Warning-free
While it should be natural to everyone already, we of course build all curl code entirely without any compiler warning in any of the 220+ CI jobs we perform. We build curl with all the most picky compiler options that exist with the set of compilers we use, and we silence every warning that appear. We treat every compiler warning as an error.
Avoid “bad” functions
There are some C functions that are just plain bad because of their lack of boundary controls or local state and we avoid them (gets, sprintf, strcat, strtok, localtime, etc).
There are some C functions that are complicated in other ways. They have too open ended functionality or do things that often end up problematic or just plain wrong; they easily lead us into doing mistakes. We avoid sscanf and strncpy for those reasons.
We have tooling that bans the use of these functions in our code. Trying to introduce use of one of them in a pull request causes CI jobs to turn red and alert the author about their mistake.
Buffer functions
Years ago we found ourselves having done several mistakes in code that were dealing with different dynamic buffers. We had too many separate implementations working on dynamically growing memory areas. We unified this handling with a new set of internal help functions for growing buffers and now made sure we only use these. This drastically reduces the need for realloc(), which helps us avoid mistakes related to that function.
Each dynamic buffer also has its own maximum size set, which in its simplicity also helps catching mistakes. In the current libcurl code, we have 80 something different dynamic buffers.
Parsing functions
I mentioned how we don’t like sscanf. It is a powerful function for parsing, but it often ends up parsing more than what the user wants (for example more than one space even if only one should be accepted) and it has weak (non-existing) handling of integer overflows. Lastly, it steers users into copying parsed results around unnecessarily, leading to superfluous uses of local stack buffers or short-lived heap allocations.
Instead we introduced another set of helper functions for string parsing, and over time we switch all parser code in curl over to using this set. It makes it easier to write strict parsers that only match exactly what we want them to match, avoid extra copies/mallocs and it does strict integer overflow and boundary checks better.
Monitor memory function use
Memory problems often involve a dynamic memory allocation followed by a copy of data into the allocated memory area. Or perhaps, if the allocation and the copy are both done correctly there is no problem but if either of them are wrong things can go bad. Therefor we aim toward minimizing that pattern. We rather favor strdup and memory duplication that allocates and copies data in the same call – or uses of the helper functions that may do these things behind their APIs. We run a daily updated graph in the curl dashboard that shows memory function call density in curl. Ideally, this plot will keep falling over time.
Memory function call density in curl production code over time
It can perhaps also be added that we avoid superfluous memory allocations, in particular in hot paths. A large download does not need any more allocations than a small one.
Double-check multiplications
Integer overflows is another area for concern. Every arithmetic operation done needs to be done with a certainty that it does not overflow. This is unfortunately still mostly a manual labor, left for human reviews to detect.
64-bit support guaranteed
In early 2023 we dropped support for building curl on systems without a functional 64-bit integer type. This simplifies a lot of code and logic. Integer overflows are less likely to trigger and there is no risk that authors accidentally believe they do 64-bit arithmetic while it could end up being 32-bit in some rare builds like could happen in the past. Overflows and mistakes can still happen if using the wrong type of course.
Maximum string length
To help us avoid mistakes on strings, in particular with integer overflows, but also with other logic, we have a general check of all string inputs to the library: they do not accept strings longer than a set limit. We deem that any string set that is longer is either just a blatant mistake or some kind of attempt (attack?) to trigger something weird inside the library. We return error on such calls. This maximum limit is right now eight megabytes, but we might adjust this in the future as the world and curl develop.
keep master golden
At no point in time is it allowed to break master. We only merge code into master that we believe is clean, fine and runs perfect. This still fails at times, but then we do our best at addressing the situation as quickly as possible.
Always check for and act on errors
In curl we always check for errors and we bail out without leaking any memory if (when!) they happen. This includes all memory operations, I/O, file operations and more. All calls.
Some developers are used to modern operating systems basically not being able to return error for some of those, but curl runs in many environments with varying behaviors. Also, a system library cannot exit or abort on errors, it needs to let the application take that decision.
APIs and ABIs
Every function and interface that is publicly accessible must never be changed in a way that risks breaking the API or ABI. For this reason and to make it easy to spot the functions that need this extra precautions, we have a strict rule: public functions are prefixed with “curl_” and no other functions use that prefix.
Everyone can do it
Thanks to the process of human reviewers, plenty of automatic tools and an elaborate and extensive test suite, everyone can (attempt to) write curl code. Assuming you know C of course. The risk that something bad would go in undetected, is roughly equal no matter who the author of the code is. The responsibility is shared.
Heading towards curl release number 266 we have decided to spice up our release cycle with release candidates in an attempt to help us catch regressions better earlier.
It has become painfully obvious to us in the curl development team that over the past few years we have done several dot-zero releases in which we shipped quite terrible regressions. Several times those regressions have been so bad or annoying that we felt obligated to do quick follow-up releases a week later to reduce friction and pain among users.
Every such patch release have caused pain in our souls and have worked as proof that we to some degree failed in our mission.
We have thousands of tests. We run several hundred CI jobs for every change that verify them. We simply have too many knobs, features, build configs, users and combinations of them all to be able to catch all possible mistakes ourselves.
Release candidates
Decades ago we sometimes did release candidates, but we stopped. We have instead shipped daily snapshots, which is basically what a release would look like, packaged every day and made available. In theory this should remove the need and use of release candidates as people can always just get the latest snapshots, try those out and report problems back to us.
Are release candidates really going to make a difference? I don’t know. I figure it is worth a shot. Maybe it is a matter of messaging and gathering the troops around these specific snapshots and by calling out the need for the testing to get done, maybe it will happen at least to some extent?
Let’s attempt this for a while and then come back in a few years and evaluate if it has seemed to help or otherwise improve the regression rate or not.
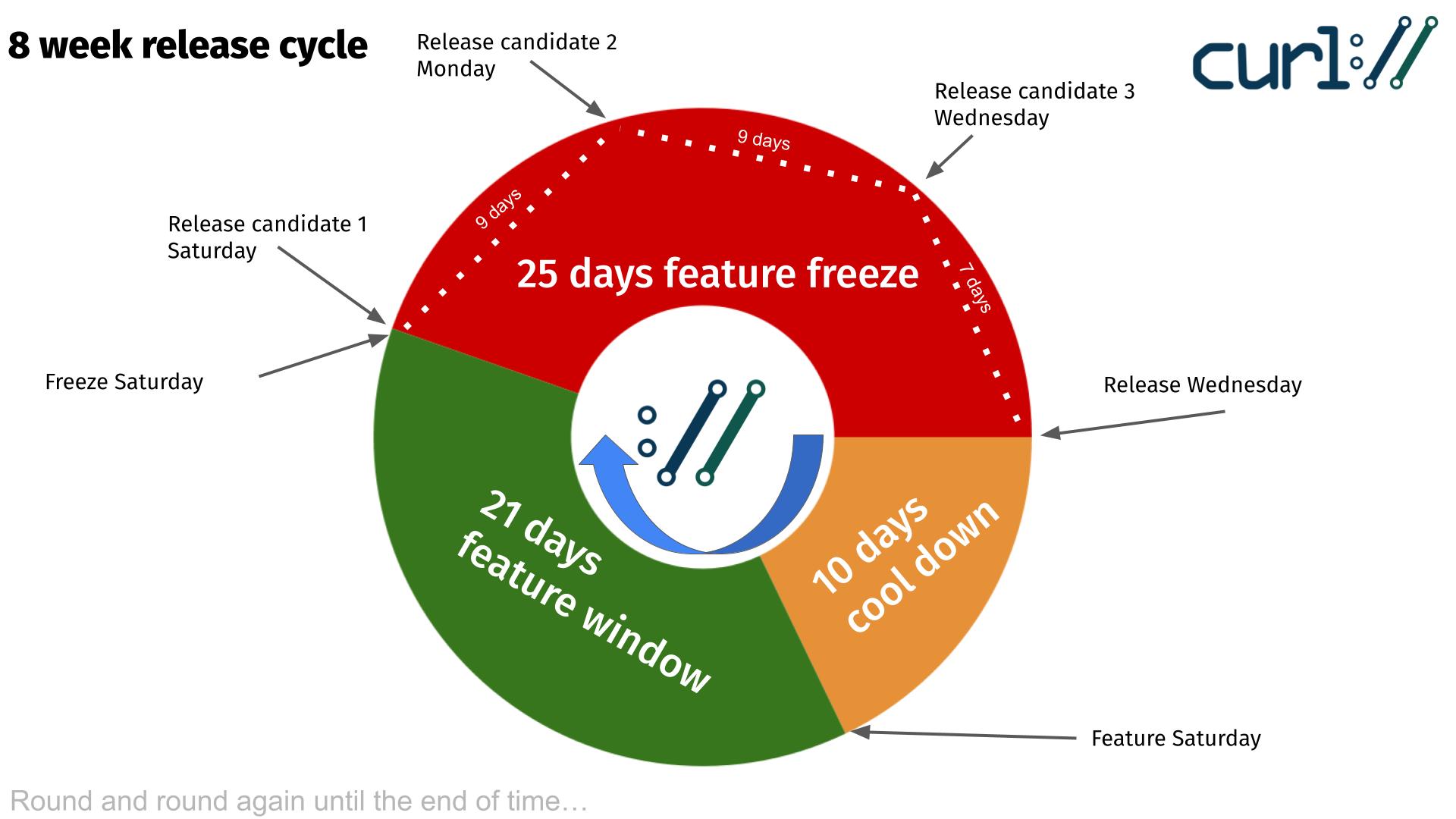
Release cycle
We have a standard release cycle in the curl project that is exactly eight weeks. When things run smoothly, we ship a new release on a Wednesday every 56 days.
The release cycle is divided into three periods, or phases, that control what kind of commits us maintainers are permitted to merge. Rules to help us ship solid software.
The curl release cycle, illustrated
Immediately after a release, we have a ten day cool down period during which we absorb reactions and reports from the release. We only merge bugfixes and we are prepared to do a patch release if we need to.
Ten days after the release, we open the feature window in which we allow new features and changes to the project. The larger things. Innovations, features etc. Typically these are the most risky things that may cause regressions. This is a three-week period and those changes that do not get merged within this window get another chance again next cycle.
The longest phase is the feature freeze that kicks in twenty-five days before the pending release. During this period we only merge bugfixes and is intended to calm things down again, smooth all the frictions and rough corners we can find to make the pending release as good as possible.
Adding three release candidates
The first release candidate (rc1) is planned to ship on the same day we enter feature freeze. From that day on, there will be no more new features before the release so all the new stuff can be checked out and tested. It does not really make any sense to do a release candidate before that date.
We will highlight this release candidate and ask that everyone who can (and want) tests this one out and report every possible issue they find with it. This should be the first good opportunity to catch any possible regressions caused by the new features.
Nine days later we ship rc2. This will be done no matter what bugreports we had on rc1 or what possible bugs are still pending etc. This candidate will have additional bugfixes merged.
The final and third release candidate (rc3) is then released exactly one week before the pending release. A final chance to find nits and perfect the pending release.
I hope I don’t have to say this, but you should not use the release candidates in production, and they may contain more bugs than what a regular curl release normally does.
Technically
The release candidates will be created exactly like a real release, except that there will not be any tags set in the git repository and they will not be archived. The release candidates are automatically removed after a few weeks.
They will be named curl-X.Y.Z-rcN, where x.y.z is the version of the pending release and N is the release candidate number. Running “curl -V” on this build will show “x.y.x-rcN” as the version. The libcurl includes will say it is version x.y.z, so that applications can test out preprocessor conditionals etc exactly as they will work in the real x.y.z release.
You can help!
You can most certainly help us here by getting one of the release candidates when they ship and try it out in your use cases, your applications, your pipelines or whatever. And let us know how it runs.
I will do something on the website to help highlight the release candidates once there is one to show, to help willing contributors find them.
The transition from Ubuntu 22 to 24 for ubuntu-latest on GitHub actions started recently with the associated version bumps of a lot of applications. As expected.
One of the version bumps is for clang: it now uses clang 18 by default. clang 18 introduced some changes that turned out to be relevant for me and other curl developers. Yeah, surely for some others as well.
clang and gcc
In my daily developer life I just typically use gcc for building local stuff – mostly out of old habits. I rebuild and test curl dozens of times every day. In my normal work process I use a couple of different build combinations that enable a lot of third party dependencies and I almost always build curl and libcurl with debug enabled and only statically. It is a debug-friendly setup.
Of course I also have clang installed so that I can try out building with it when I want to, and I have a large set of alternative config setups that I use when I have a particular reason to check or debug such a build.
CI to the rescue
There are literally many millions of build combinations of curl, and we do some of the most important ones automatically for every pull request and commit in the source repository. They help us avoid regressions. Currently we do almost two hundred different jobs.
Two of those CI jobs build curl using clang and enable some sanitizers: address, memory, undefined and signed-integer-overflow and use those builds to run through the test suite to help us verify that everything still looks fine.
Since it gets done in the CI for every change, I don’t have to run it myself locally very often. We have thus been using the default clang version shipped in Ubuntu 22.04 for this for quite some time now.
Undefined behavior sanitizer
When the clang version for the Ubuntu jobs on GitHub was bumped up to version 18, the undefined behavior sanitizer job suddenly found plenty of new problems in curl.
In code that had been running without problems for a long time (decades in some cases) on countless systems and on almost every imaginable architecture. Unexpected.
Picky function prototypes
Here is the reason:
The sanitizer now keeps track of exactly how a function pointer prototype is declared and verifies that the function actually called via that pointer is using an identical prototype.
This is generally probably a good idea and a sound sanity check for most programs but since the checker insists on identical prototypes, I believe it goes beyond what is undefined behavior – I believe some discrepancies are handled just fine. For example a signed vs unsigned pointer or void vs char pointers. I am however not a compiler developer and neither am I an expert in the C language specifications so maybe I am wrong.
Example
A function pointer defined to call a function that returns a void and gets a single char pointer input
char *data = "string"; name = (name_func)target; name(data);
In libcurl we set function pointers (callbacks) via a setopt() style function, which cannot validate the pointer at compile time.
When the code example above is tested with the undefined behavior sanitizer and its -fsanitize=function check (I believe), it complains about the mismatching prototypes between the pointer and the actually called function.
How this became annoying
For the example above, the sanitizer report is most welcome, even if I think it goes beyond what is actually undefined behavior. It helps us clean up the code.
For libcurl, we have a CURL * type returned for a handle from curl_easy_init(). This handle is used as an input argument to multiple functions and it is also used as an input argument to several callbacks an application can tell libcurl to call, etc.
This made us get a more descriptive pointer for the type when we build libcurl. For convenience.
The function pointer is defined internally for libcurl as a struct pointer, but outside in the application land as a void pointer. This works great.
Until this new sanitizer check. Now it complaints loudly because the prototypes for the function called does not match the prototype for the function pointer. The struct vs the void pointers. The sanitizer stores and uses “resolved” typedefs in its checks, not the name of the types visible in code.
The fix
Since we can’t have build breakage in the CI jobs, I fixed this.
We are back to how we did it in the past. With a plain
typedef void CURL;
… even when we build libcurl. To make sure the pointer and the final function have the same prototypes. To hush up the undefined behavior sanitizer.
This is now in master and how the code in the pending curl 8.11.0 release will look.
Disabling the check is not enough
While we could disable this particular check in our CI jobs, that would not suffice since we want everyone to be able to run these tools against curl without any warnings or errors.
We also want application authors in general who use libcurl to be able to similarly run this sanitizer against their tools to not get error reports like this.
Is this a clang issue?
Maybe. I just can’t see how this could happen by mistake, and since it is a feature that has existed for quite a while now already I have not bothered to submit an issue or have any argument or discussion with the clang team. I have simply accepted that this is the way they want to play this and adapt accordingly.
A historic footnote
In 2016 I wanted to change the type universally to just
typedef struct Curl_easy CURL;
… as I thought we could do that without breaking neither API nor ABI. I still believe I was right, but the change still caused an “uproar” among some users who had already built code and done things based on the assumption that it was and would always remain a void pointer. Changing the type thus caused build errors at places to a level that made us retract that change and revert back to the #ifdef version showed above.
And now we had to retract even the #ifdef and thus we are back to the pre 2016 way.
Post-publish update
It has been pointed out to me that the way the C standard is phrased, this tool seems to be correct. More discussions around that can be found in a long OpenSSL issue from last year.
Screenshot from a recent pull request merged in the curl project on GitHub
Contributors to the curl project on GitHub tend to notice the above sequence quite quickly: pull requests submitted do not generally appear as “merged” with its accompanying purple blob, instead they are said to be “closed”. This has been happening since 2015 and is probably not going to change anytime soon.
Screenshot showing how GitHub otherwise shows merges
If you make a pull request based on a single commit, the initial PR message is based on the commit message but when follow-up fixes are done and perhaps force-pushed, the PR message is not updated accordingly with the commit message’s updates.
Commit messages with style
I believe having good commit messages following a fixed style and syntax helps the project. It makes the git history better and easier to browse. It allows us to write tools and scripts around git and the git history. Like how we for example generate release notes and project stat graphs based on git log basically.
We also like and use a strictly linear history in curl, meaning that all commits are rebased on the master branch. Lots of the scripting mentioned above depends on this fact.
Manual merges
In order to make sure the commit message is correct, and in fact that the entire commit looks correct, we merge pull requests manually. That means that we pull down the pull request into a local git repository, clean up the commit message to adhere to project standards.
And then we push the commit to git. One or more of the commit messages in such a push then typically contains lines like:
Fixes #[number] and Closes #[number]. Those are instructions to GitHub and we use them like this:
Fixes means that this commit fixed an issue that was reported in the GitHub issue with that id. When we push a commit with that instruction, GitHub closes that issue.
Closes means that we merged a pull request with this id. (GitHub has no way for us to tell it that we merged the pull request.) This instruction makes GitHub closes the corresponding pull request: “[committer] closed this in [commit hash]”.
We do not let GitHub dictate how we do git. We use git and expect GitHub to reflect our git activity.
We COULD but we won’t
We could in theory fix and cleanup the commits locally and manually exactly the way we do now and then force-push them to the remote branch and then use the merge button on the GitHub site and then they would appear as “merged”.
That is however a clunky, annoying and time-consuming extra-step that not only requires that we (always) push code to other people’s branches, it also triggers a whole new round of CI jobs. This, only to get a purple blob instead of a red one. Not worth it.
If GitHub would allow it, I would disable the merge button in the GitHub PR UI for curl since it basically cannot be used correctly in the project.
Squashing all the commits in the PR is also not something we want since in many cases the changes should be kept as more than one commit and they need their own dedicated and correct commit message.
What GitHub could do
GitHub could offer a Merged keyword in the exact same style as Fixed and Closes, that just tells the service that we took care of this PR and merged it as this commit. It’s on me. My responsibility. I merged it. It would help users and contributors to better understand that their closed PR was in fact merged as that commit.
It would also have saved me from having to write this blog post.
In some post-publish discussions I have seen people ask about credits. This method to merge commits does not break or change how the authors are credited for their work. The commit authors remain the commit authors, and the one doing the commits (which is I when I do them) is stored separately. Like git always do. Doing the pushes manually this way does in no way change this model. GitHub will even count the commits correctly for the committer – assuming they use an email address their GitHub account does (I think).
In the beginning and for many years, the curl project used no CI services at all. It instead used a distributed build and test systems where volunteers ran machines that pulled the latest code repeatedly, built curl, ran the tests and reported back the results to a central server.
One
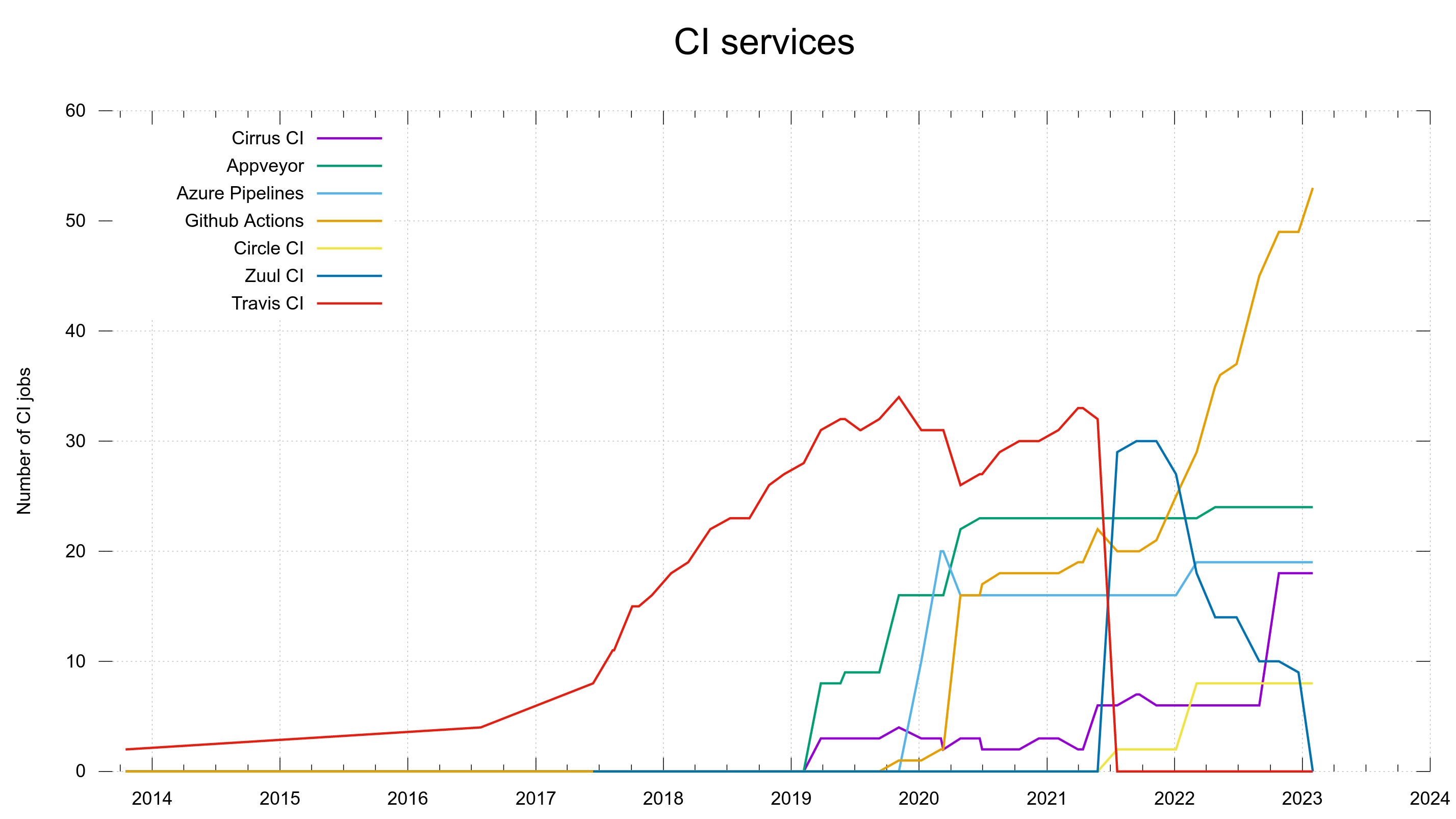
In 2013, the year curl turned 15, we created our first CI jobs on Travis CI. With only a single CI service life was easy for a few years.
Two, three
This single service had a limited feature set and in particular a limited set of supported platforms. To also do automatic testing on FreeBSD and Windows we had to use two additional services because Travis did not support them. Now they were three, early 2019. Cirrus CI and AppVeyor.
Four
When we use free services, we need to live with the limitations of what the good providers offer for free or at low cost. In the case of CI services, they tend to reduce CPU time and parallelisms for users of the free tier and so did Travis.
When the number of CI jobs on Travis surpassed 30, and we had already gotten a small performance boost just because of their good will, we created the next few new CI jobs on GitHub Actions instead to increase the parallelism for no extra money. If I recall things correctly, the macOS support was also much better on GitHub since it was rather limited on Travis.
GitHub later graciously bumped our service level for even more power and parallelism. Increased parallelism, not the least thanks to the use of several independent CI services, made sure that the complete set of CI jobs would still complete within a reasonable time.
Five
When working on extending and improving our Windows CI testing in late 2019, our previous Windows CI provider AppVeyor was not good enough so we opted to add jobs on Azure Pipelines. This was also because GitHub Actions could not run the images we have and wanted to use for this purpose.
Redundancy
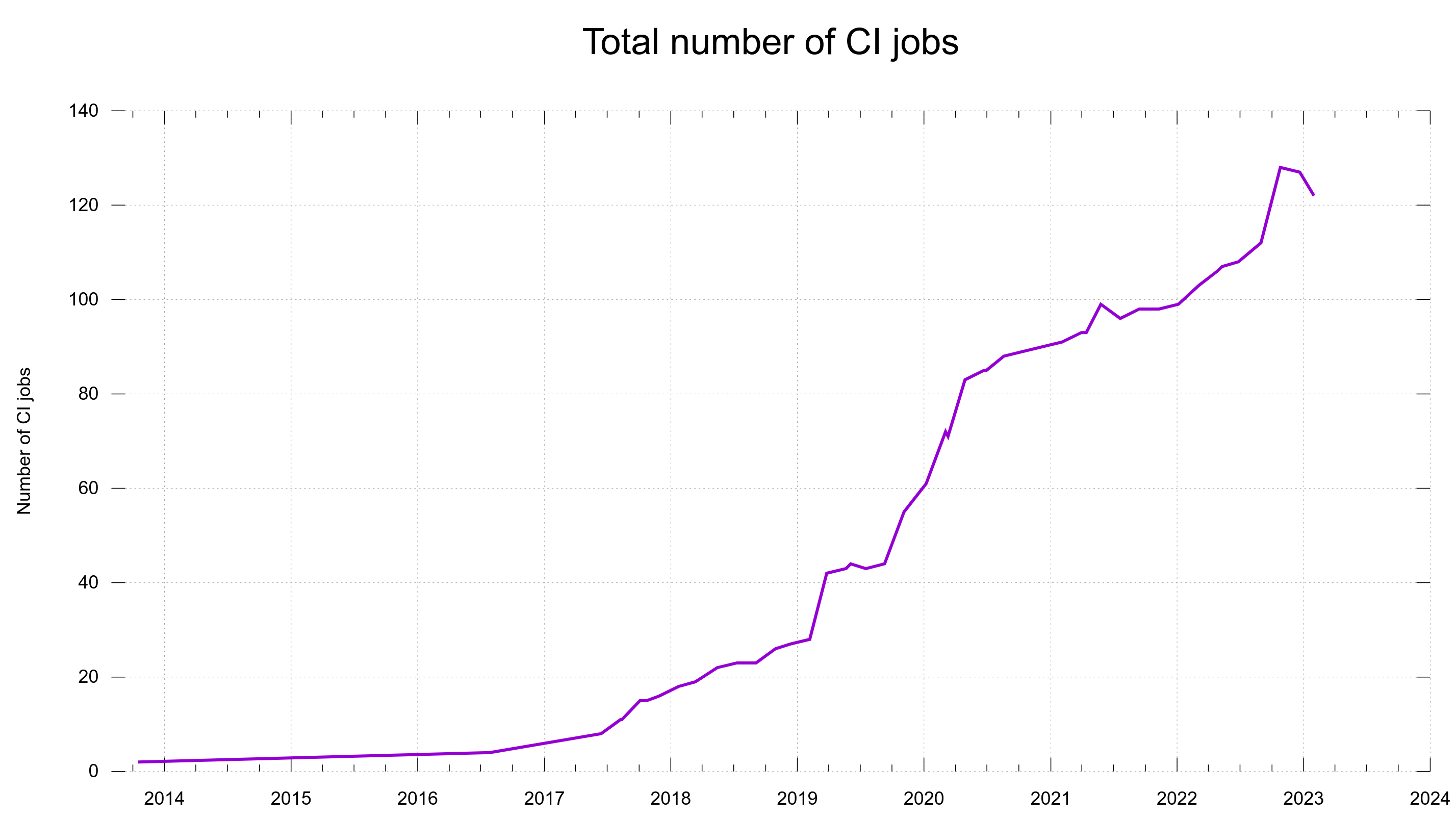
When we entered the year 2020 we were at 60 CI jobs and having them run on several different CI services often turned out useful when one of them acted up: at least a lot of other jobs would still work and help us assess and verify proposed changes. No all eggs in the same basket problem.
Services come and go
Redundancy also helps soften the blow when a service goes away. If you are in the race long enough, all services will go away or go sour eventually. This includes CI services.
In 2021, Travis CI changed their policies and suddenly we could not keep using them unless we paid up a few K USD per year and we would rather avoid that.
We had to move the 30+ CI jobs from Travis to something else. Thanks to a generous offer, volunteers showed up and helped transition the Travis jobs over to a new service: Zuul CI. It softened the repercussions from the “jump” and the CI jobs kept helping us ship quality code.
Five, Six
To manage the Travis CI eviction, Zuul took over most of the curl CI jobs and a few of them were added on Circle CI, which then appeared as CI service number six. Primarily because of their at the time early and convenient support for arm.
Zuul CI
We were grateful for the help we got to move over to Zuul from Travis, but soon it became apparent to us that Zuul CI is more “crude” than some of the other services and it left us wanting more. It’s UI is way less sophisticated, to the level that it is almost difficult for a casual PR submitted to read and understand build errors. Also, it was slightly buggy, which could result in Zuul jobs not showing up in the GitHub UI at all or simply failing to trigger the new jobs. When the responses from the Zuul side to our problems were somewhere between slow to non-existent I felt with had no other choice but to transition away from this service as well.
The change took its time. At the end of 2021 we had 30 CI jobs on Zuul, and just days ago in late January 2023, we removed the final curl jobs from it.
Five
We use five services now and we could possibly consolidate down to four if we really wanted to, but I see no reason to do that now when things are working and huffing along.
GitHub Actions have really taken off as our primary CI service and now runs almost half of the entire set. Thanks to it being convenient, well integrated, well documented and us having good parallelism on it.
We do what we need
Whatever is good for the project we will consider doing. We have gotten to this point with this set of CI services because they help the project. If someone proposes a change that improve things and that change reduces the number of CI services, then we might go that way next. Or maybe we add one? We have not planned what comes next.
What we run in CI
We build curl and run tests with numerous different build configurations on several architectures on different operating systems. With and without debug enabled. With and without using valgrind. Most builds also run checksrc , which verifies source code style.
We run dedicated jobs that do “deeper” testing, such as building with address and undefined behavior-analyzers and running the complete curl test suite in “torture mode”.
We run markdown and man page spell checkers
We run English prose checking (using proselint) of markdown files
We run static code analyzers and fuzzers
We confirm the copyright and license situation of all files in git
We verify links within markdowns
We have a few “bot services” that can set the “hacktoberfest-accepted” label, and a labeler service that tries to automatically set proper categories for pull requests.
We verify that the release tarball looks right and works when generated from the current set of files in git
… and probably a few other things I have forgot now
Of course we have graphs
These graphs were screenshotted from the dashboard on February 1st, 2023.
The total number of CI jobs done for each PR and commit, over time
Number of CI jobs running on which CI service, over time
CI job distribution over platforms
Future
Whatever helps the project and whatever someone offers to help us make that happen, we might do. That may mean using more services, it might mean using less.
The important part is that these services are used to improve and strengthen the curl project and the products we ship.
Uncurled – everything I know and learned about running and maintaining Open Source projects for three decades.
This is me, doing a live English-speaking presentation/webinar on these topics that I cover in my book: Uncurled.
Recording
Date: Tuesday August 23, 2022
Time: 10: 00 UTC (12:00 CEST)
Where: over zoom [Sign up]
The plan is to record this session and make it available after the fact on YouTube. This post will be updated with a link to that once it exists.
Agenda
Here’s the outlook on what I hope to be able to cover in a 40 minutes talk.
This will be followed by a Q&A-session with me answering any questions you might have. Feel most welcome and encouraged to submit your questions ahead of time if you already have some! (comment here, email me, comment or DM on Twitter, send a carrier pigeon, anything!)
I have not done this presentation before. I know the subject very intimately so I have no worries about that. The timing of the thing is what is going to be my bigger challenge I think. I aim for no more than 40 minutes of me blabbing.