In the beginning and for many years, the curl project used no CI services at all. It instead used a distributed build and test systems where volunteers ran machines that pulled the latest code repeatedly, built curl, ran the tests and reported back the results to a central server.
One
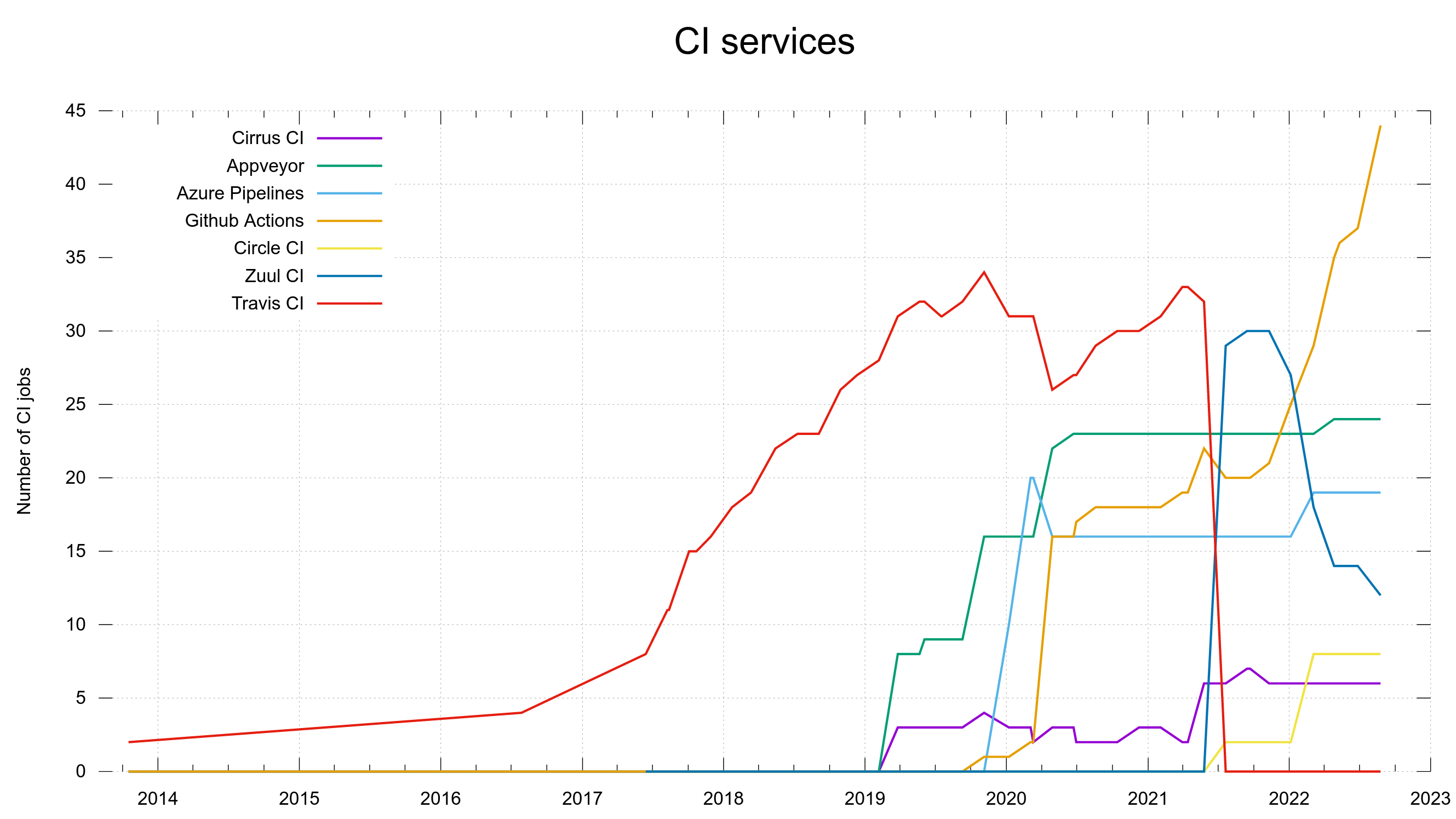
In 2013, the year curl turned 15, we created our first CI jobs on Travis CI. With only a single CI service life was easy for a few years.
Two, three
This single service had a limited feature set and in particular a limited set of supported platforms. To also do automatic testing on FreeBSD and Windows we had to use two additional services because Travis did not support them. Now they were three, early 2019. Cirrus CI and AppVeyor.
Four
When we use free services, we need to live with the limitations of what the good providers offer for free or at low cost. In the case of CI services, they tend to reduce CPU time and parallelisms for users of the free tier and so did Travis.
When the number of CI jobs on Travis surpassed 30, and we had already gotten a small performance boost just because of their good will, we created the next few new CI jobs on GitHub Actions instead to increase the parallelism for no extra money. If I recall things correctly, the macOS support was also much better on GitHub since it was rather limited on Travis.
GitHub later graciously bumped our service level for even more power and parallelism. Increased parallelism, not the least thanks to the use of several independent CI services, made sure that the complete set of CI jobs would still complete within a reasonable time.
Five
When working on extending and improving our Windows CI testing in late 2019, our previous Windows CI provider AppVeyor was not good enough so we opted to add jobs on Azure Pipelines. This was also because GitHub Actions could not run the images we have and wanted to use for this purpose.
Redundancy
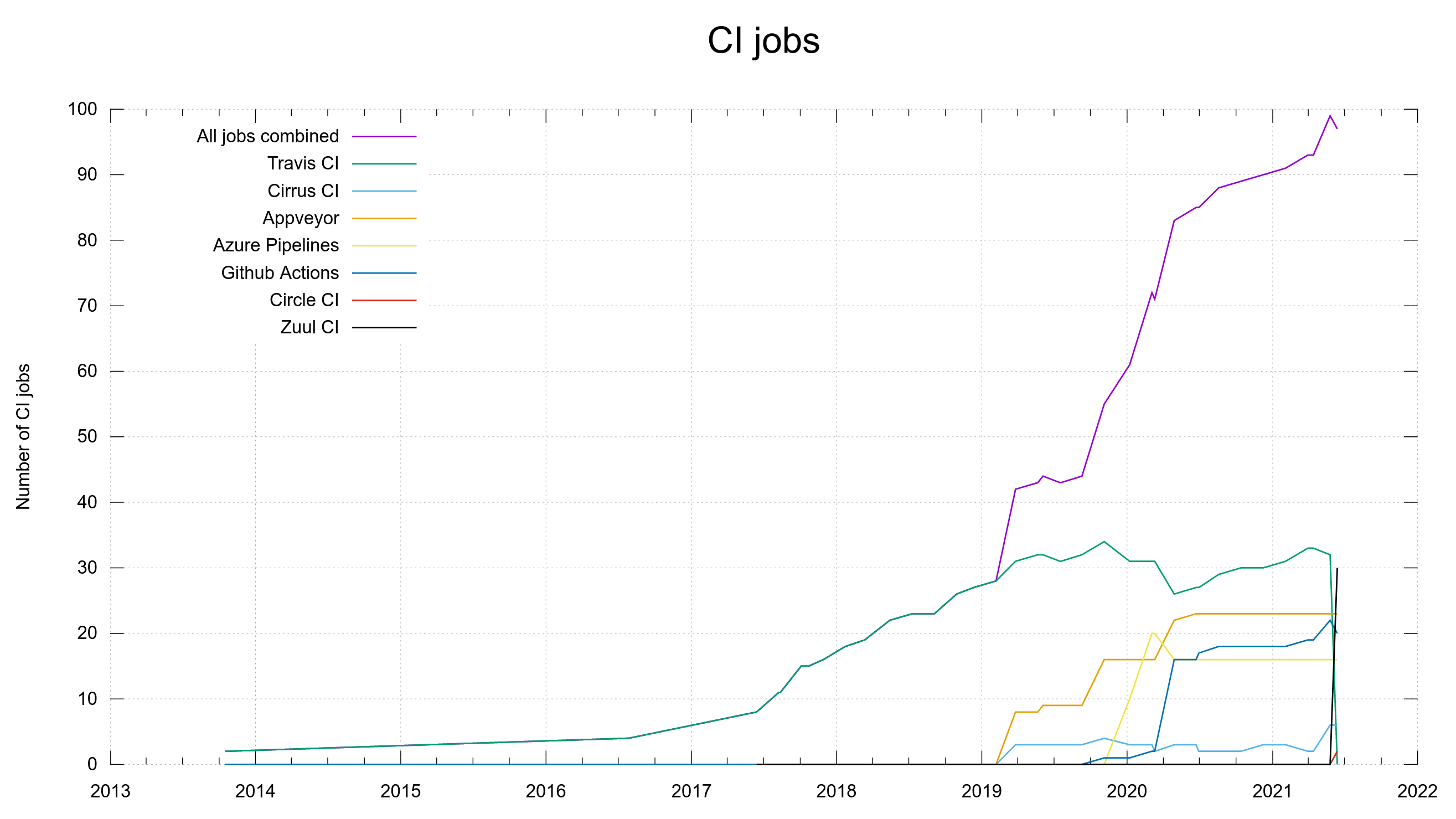
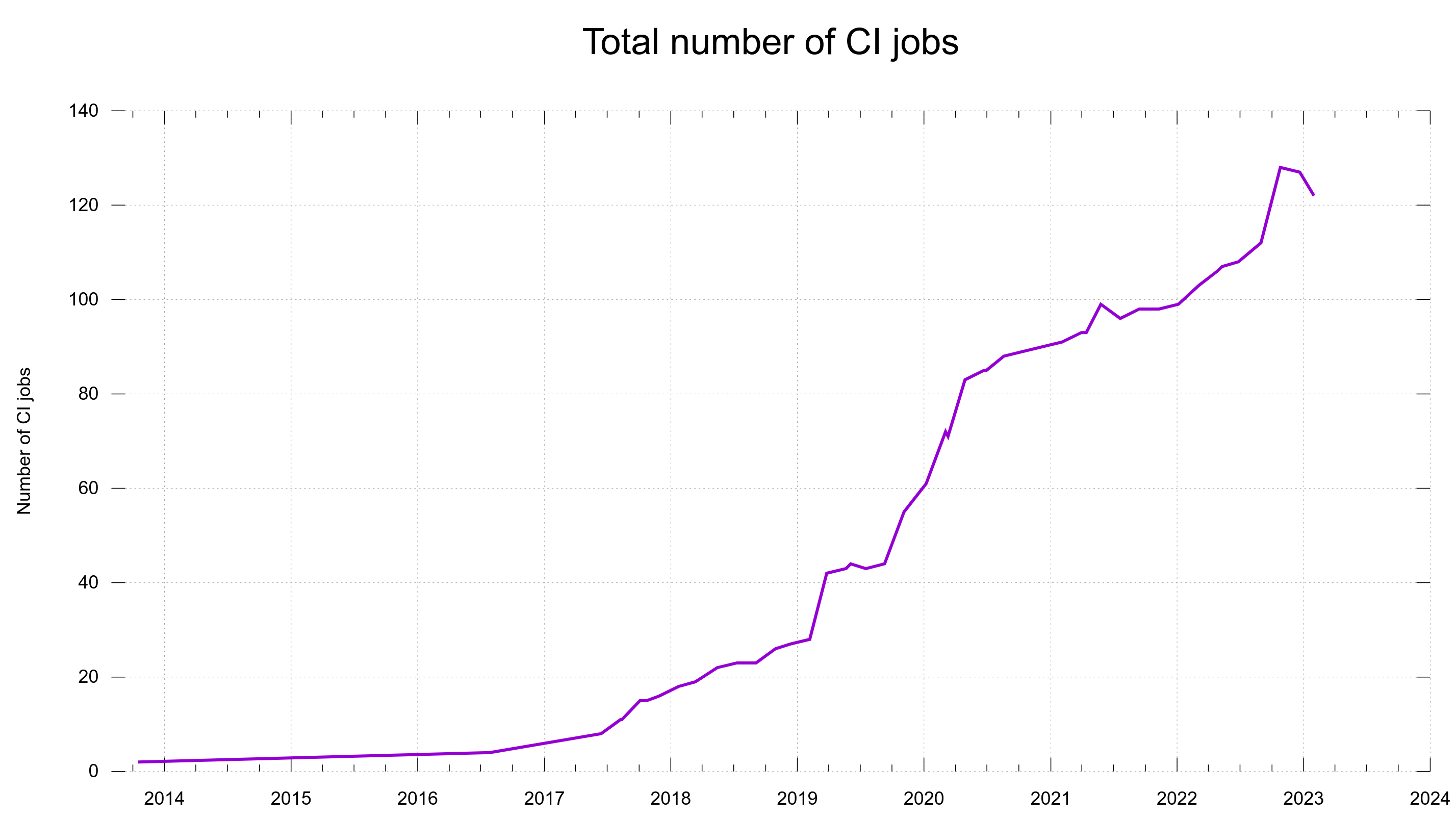
When we entered the year 2020 we were at 60 CI jobs and having them run on several different CI services often turned out useful when one of them acted up: at least a lot of other jobs would still work and help us assess and verify proposed changes. No all eggs in the same basket problem.
Services come and go
Redundancy also helps soften the blow when a service goes away. If you are in the race long enough, all services will go away or go sour eventually. This includes CI services.
In 2021, Travis CI changed their policies and suddenly we could not keep using them unless we paid up a few K USD per year and we would rather avoid that.
We had to move the 30+ CI jobs from Travis to something else. Thanks to a generous offer, volunteers showed up and helped transition the Travis jobs over to a new service: Zuul CI. It softened the repercussions from the “jump” and the CI jobs kept helping us ship quality code.
Five, Six
To manage the Travis CI eviction, Zuul took over most of the curl CI jobs and a few of them were added on Circle CI, which then appeared as CI service number six. Primarily because of their at the time early and convenient support for arm.
Zuul CI
We were grateful for the help we got to move over to Zuul from Travis, but soon it became apparent to us that Zuul CI is more “crude” than some of the other services and it left us wanting more. It’s UI is way less sophisticated, to the level that it is almost difficult for a casual PR submitted to read and understand build errors. Also, it was slightly buggy, which could result in Zuul jobs not showing up in the GitHub UI at all or simply failing to trigger the new jobs. When the responses from the Zuul side to our problems were somewhere between slow to non-existent I felt with had no other choice but to transition away from this service as well.
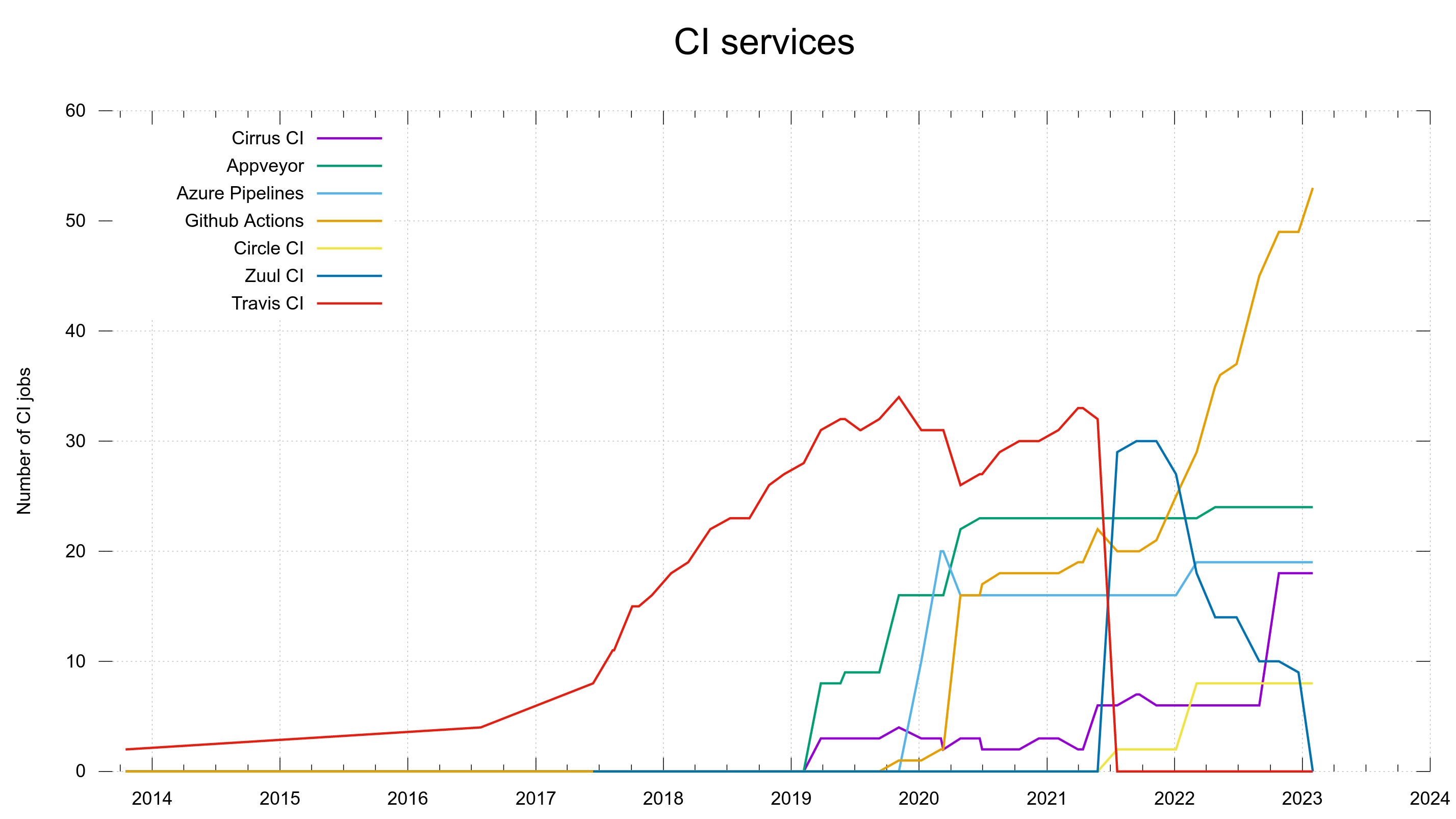
The change took its time. At the end of 2021 we had 30 CI jobs on Zuul, and just days ago in late January 2023, we removed the final curl jobs from it.
Five
We use five services now and we could possibly consolidate down to four if we really wanted to, but I see no reason to do that now when things are working and huffing along.
GitHub Actions have really taken off as our primary CI service and now runs almost half of the entire set. Thanks to it being convenient, well integrated, well documented and us having good parallelism on it.
We do what we need
Whatever is good for the project we will consider doing. We have gotten to this point with this set of CI services because they help the project. If someone proposes a change that improve things and that change reduces the number of CI services, then we might go that way next. Or maybe we add one? We have not planned what comes next.
What we run in CI
- We build curl and run tests with numerous different build configurations on several architectures on different operating systems. With and without debug enabled. With and without using valgrind. Most builds also run
checksrc, which verifies source code style. - We run dedicated jobs that do “deeper” testing, such as building with address and undefined behavior-analyzers and running the complete curl test suite in “torture mode”.
- We run markdown and man page spell checkers
- We run English prose checking (using
proselint) of markdown files - We run static code analyzers and fuzzers
- We confirm the copyright and license situation of all files in git
- We verify links within markdowns
- We have a few “bot services” that can set the “hacktoberfest-accepted” label, and a labeler service that tries to automatically set proper categories for pull requests.
- We verify that the release tarball looks right and works when generated from the current set of files in git
- … and probably a few other things I have forgot now
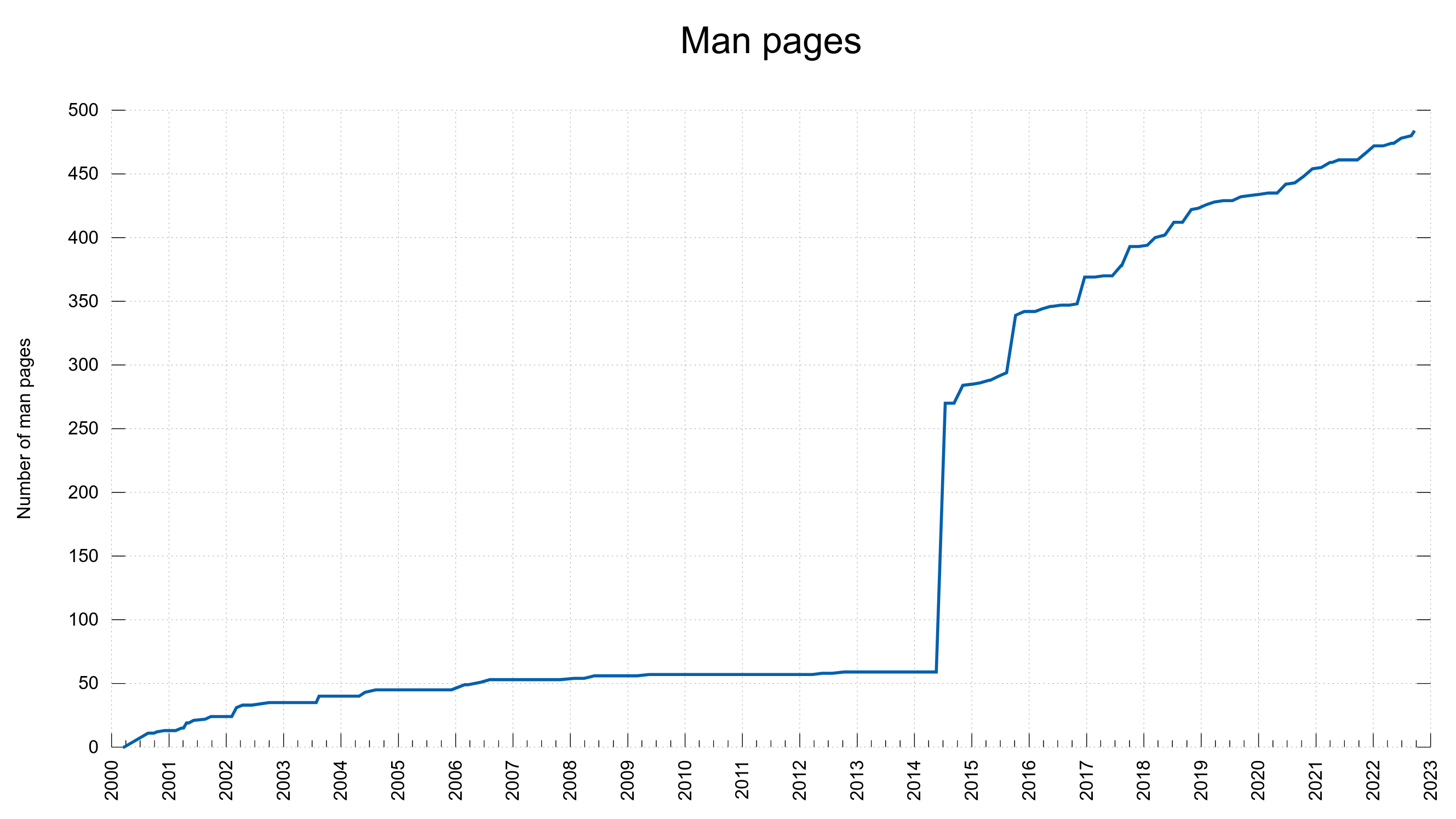
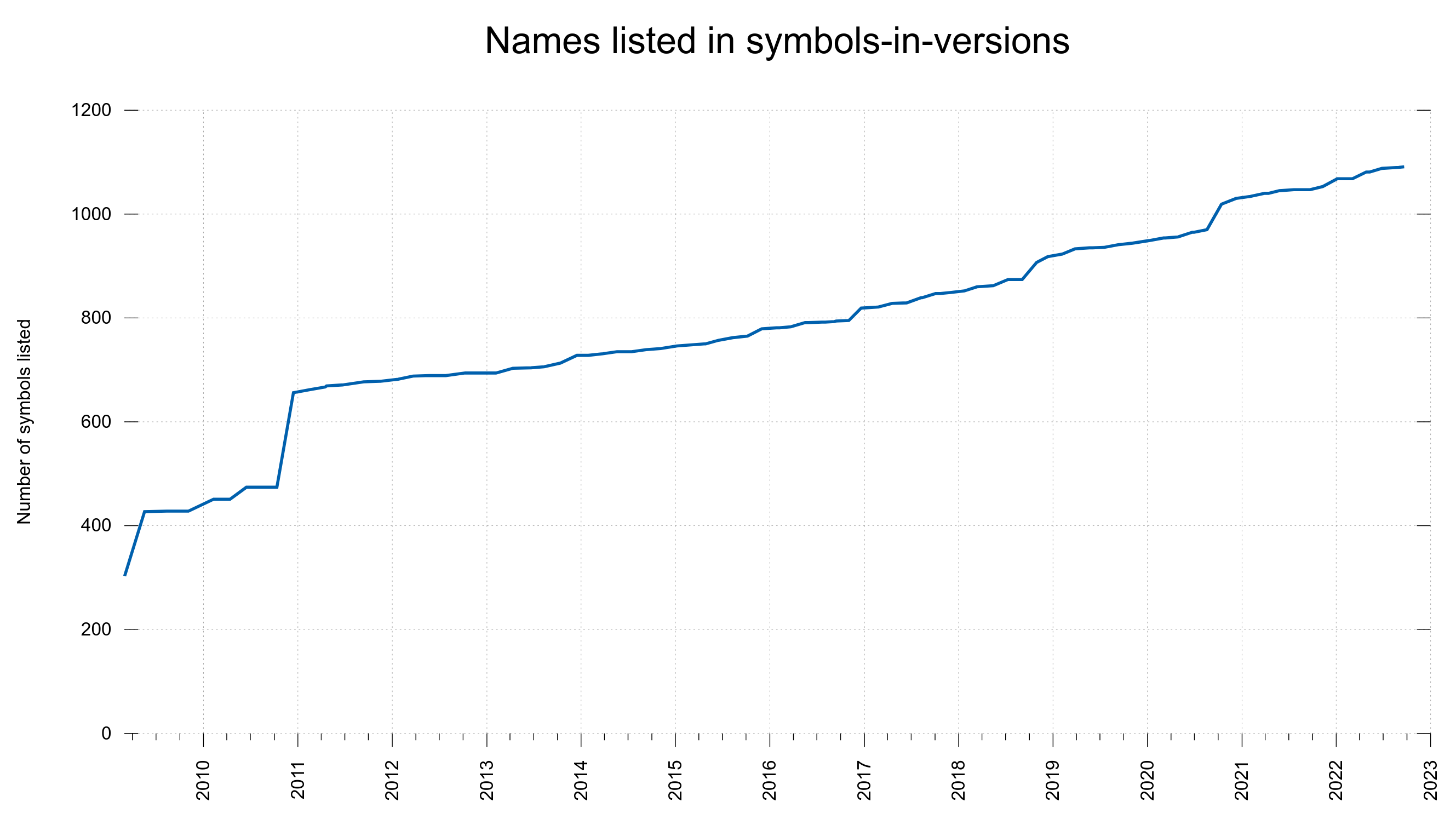
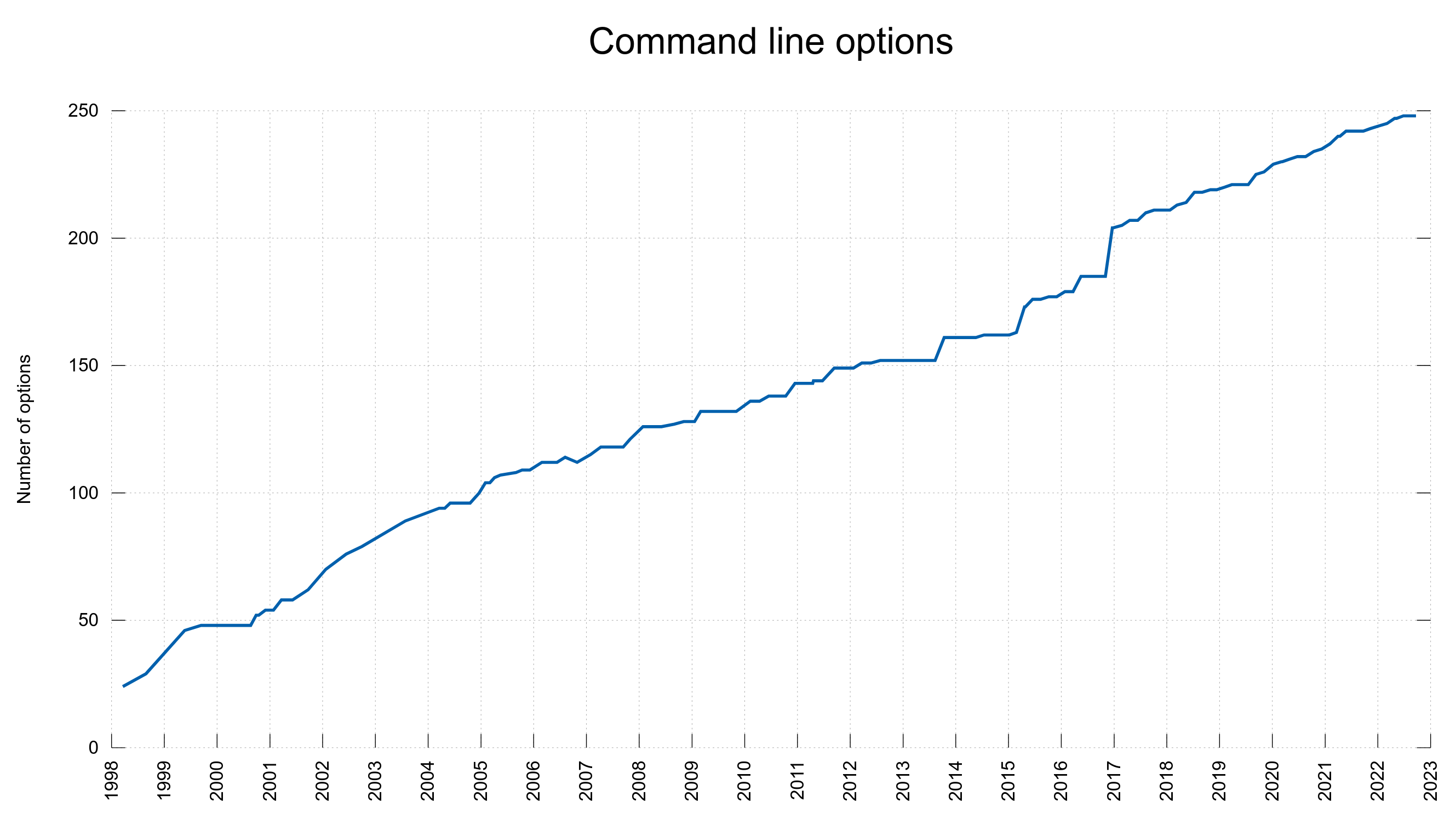
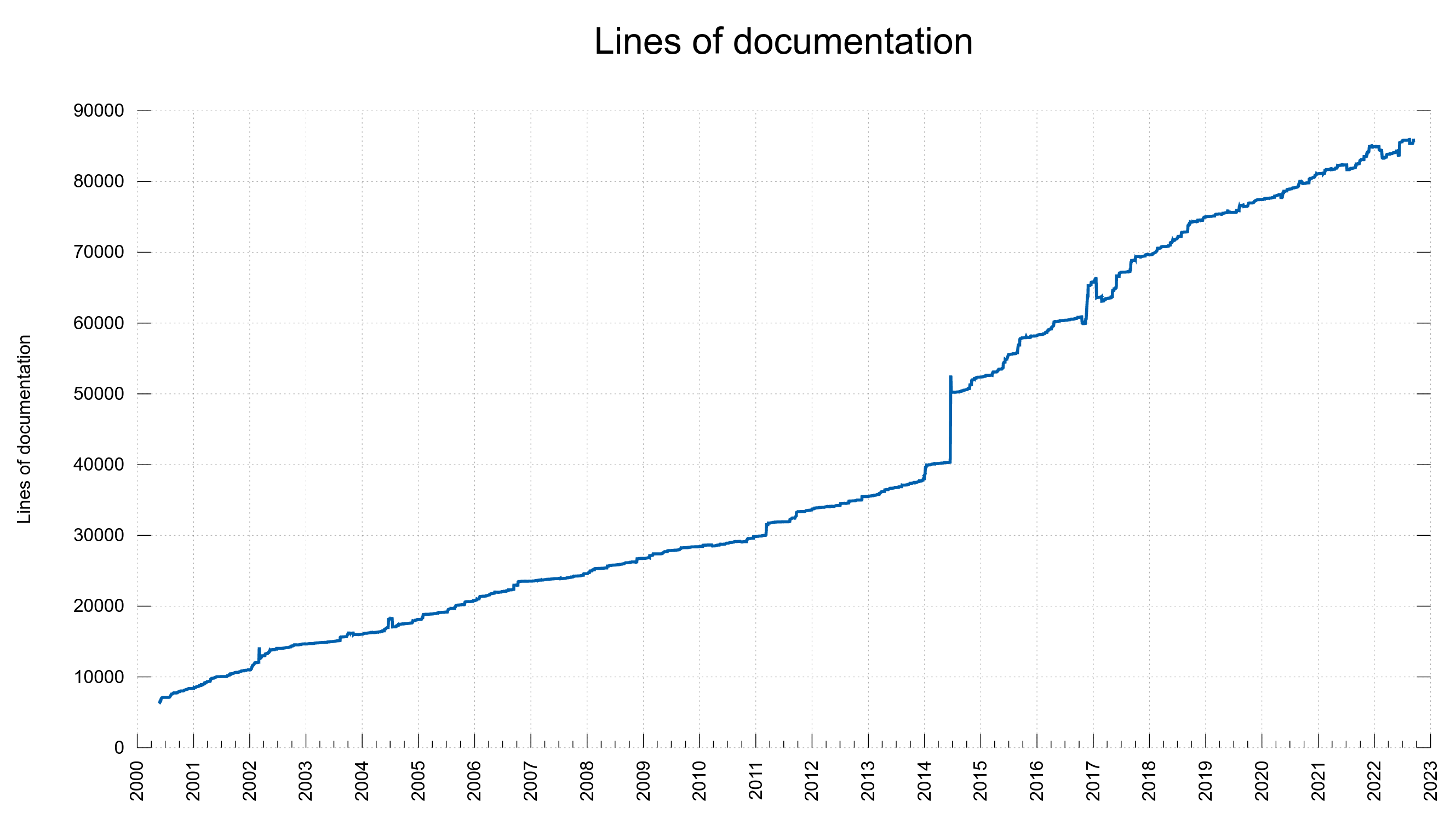
Of course we have graphs
These graphs were screenshotted from the dashboard on February 1st, 2023.

Future
Whatever helps the project and whatever someone offers to help us make that happen, we might do. That may mean using more services, it might mean using less.
The important part is that these services are used to improve and strengthen the curl project and the products we ship.