Tldr; test and verify as much as possible also in the documentation.
I’m a sloppy typist. When I write several words in a row, like for example when creating complete sentences for something like a blog post, one or two of the words end up slightly misspelled.
Sure, many editors and systems have runtime spellchecks these days and they make it easy to quickly fix typos, but not all systems are like that and there are also situations where there are many false positives due to formatting or just the range of “special” words. They also rarely yell at me when I overuse the word “very” or start sentences with “But”.
curl documentation
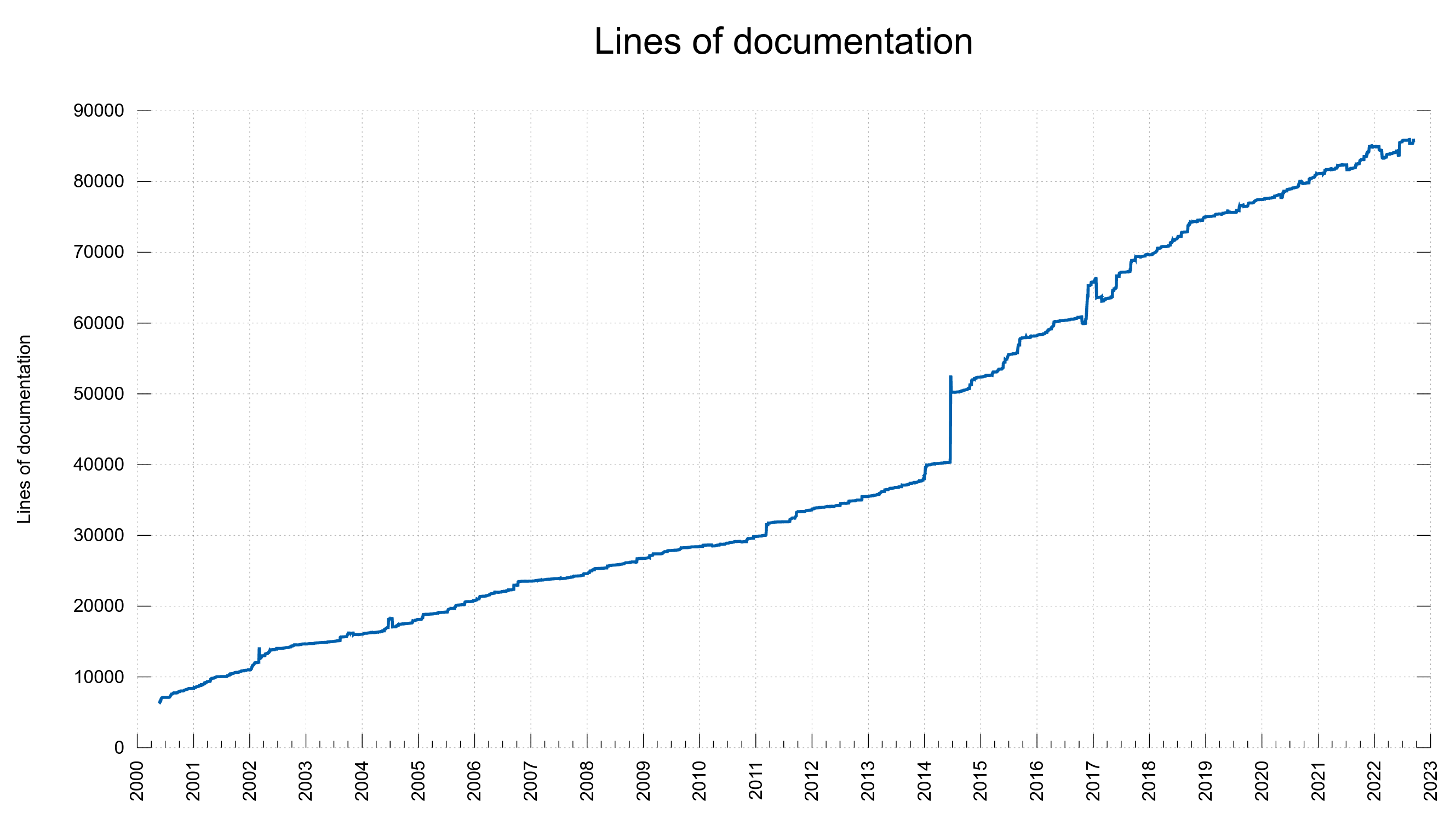
I work fiercely on making the curl and libcurl documentation top-notch state of the art good and complete. I want my users to feel that. Everything is documented; clearly and with details and examples.
I want and aim for libcurl to be the best documented software library in the world.
Good documentation does not come for free or easily. It requires dedicated work and a lot of effort put into it.
This is of course a never-ending effort as things change over time and we have an almost ridiculous amount of options and details to document.
The key to improve ourselves is of course two good old classics: tests and CI jobs. This works great even for documentation, and perhaps in particular for technical documentation that includes lots of symbols and name references that need to be correct.
As I have recently worked on tightening some bolts and made it harder to land typos, I wanted to take the opportunity to describe some of our ways.
symbols-in-versions
Early 2009 I had some interactions with people in the git project and we discussed their use of libcurl. As we introduce new features to curl over time, users who build with curl may want to write their code to conditionally use the new stuff if they have a new enough libcurl installed, or just skip those features if the installation is too old. git is an application like that. They use libcurl a lot and they offer to build with libcurl installations that are maybe a dozen years old.
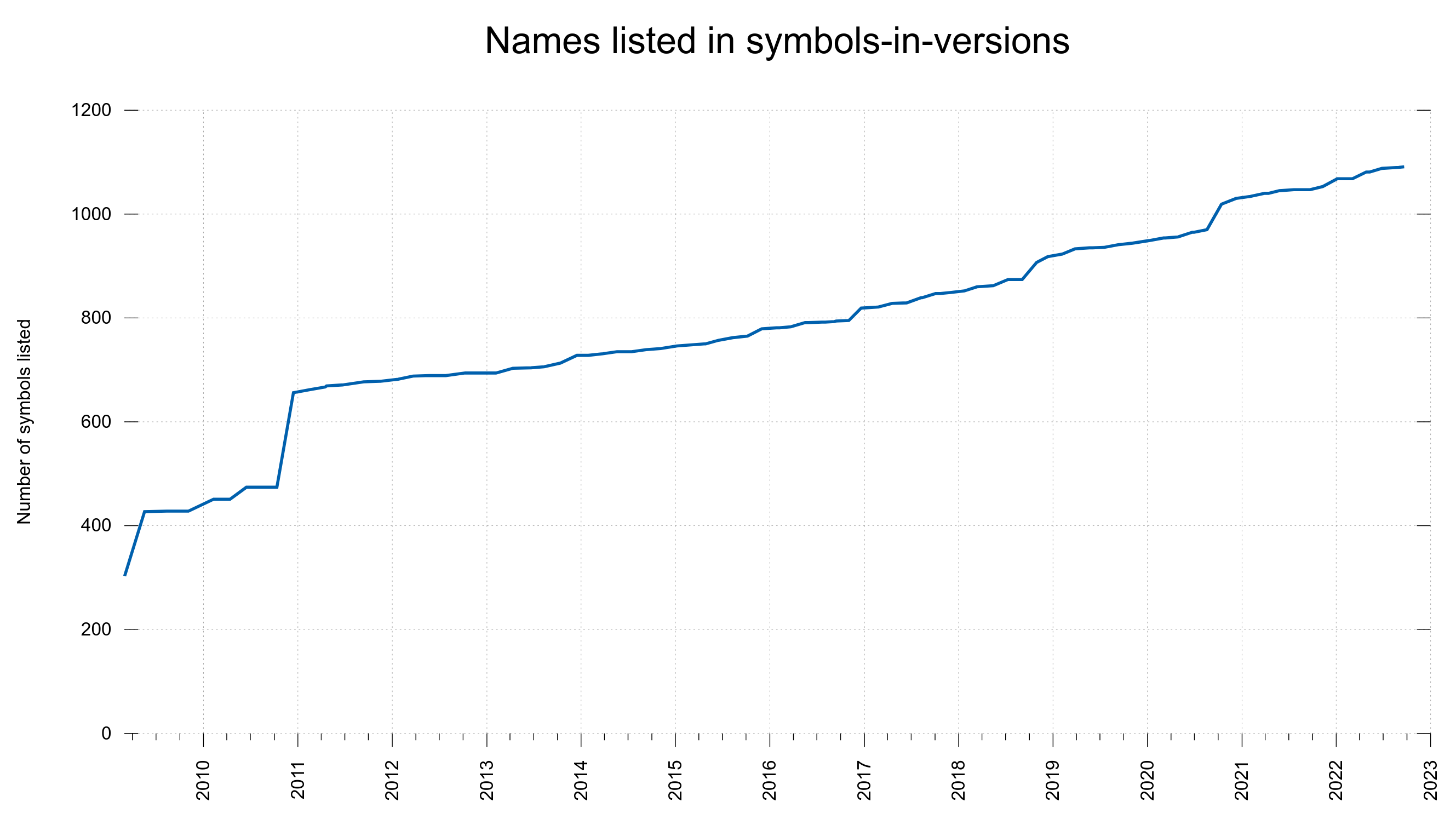
I then created a file in the libcurl git repository that I named symbols-in-versions. It lists all publicly provided curl symbols and in which libcurl release they were introduced. A good resource for libcurl users. It took quite an effort to figure them all out after the fact.
Over time, the number of entries in this file has grown significantly.
Tests
Of course, in order to do good CI jobs, they need to have tests to run so we start there.
I will mention some test numbers below. The test numbers in curl do not have any inherent meaning, they are just unique identifiers. To help us find the test source files and refer to tests and their failures easily.
Test 1119
Test 1119 was introduced in November 2010 as I realized I needed to make sure that symbols-in-versions (SIV) is kept up-to-date. It will be a useless document if it lags behind or misses symbols. It needs to include them all and the info needs to be correct.
I wrote a script that extracts all globally provided symbols in some curl header files and then verifies that they are all listed in SIV.
This test now made it very clear when we forgot to add a name to SIV, and it also pointed out if one of the names in SIV for example had a typo.
Test 1139
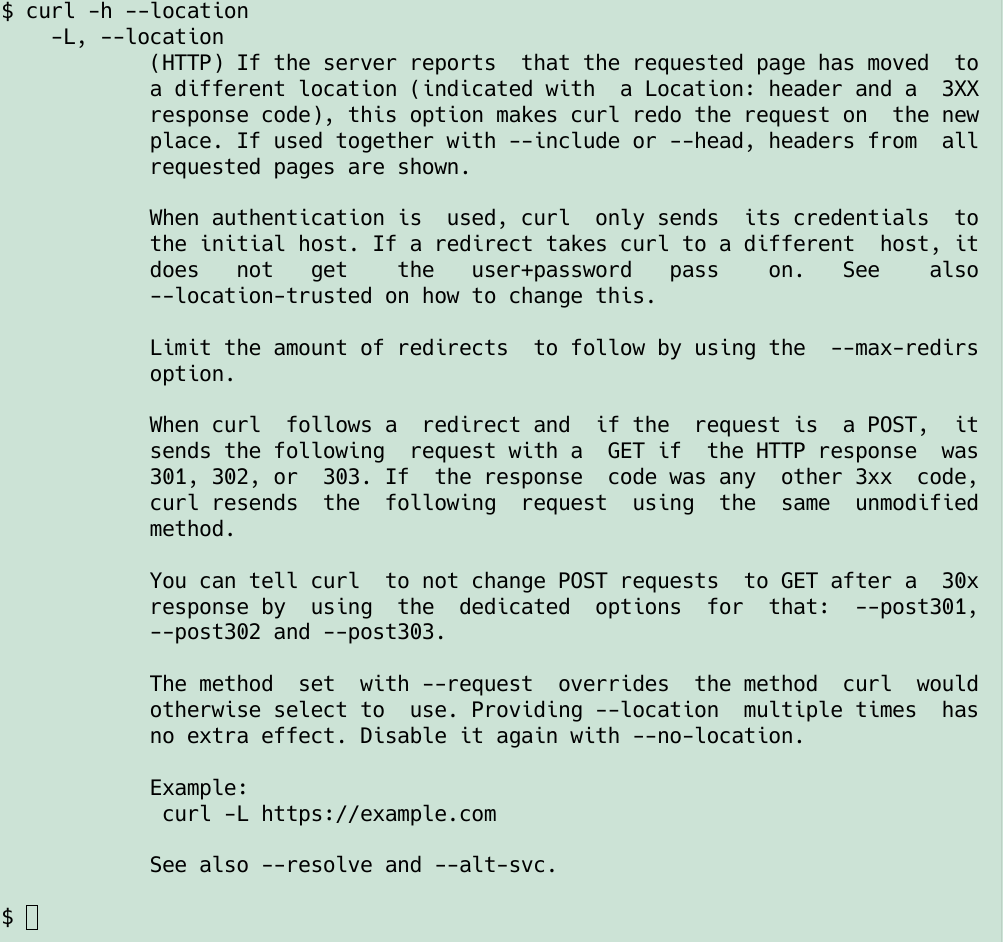
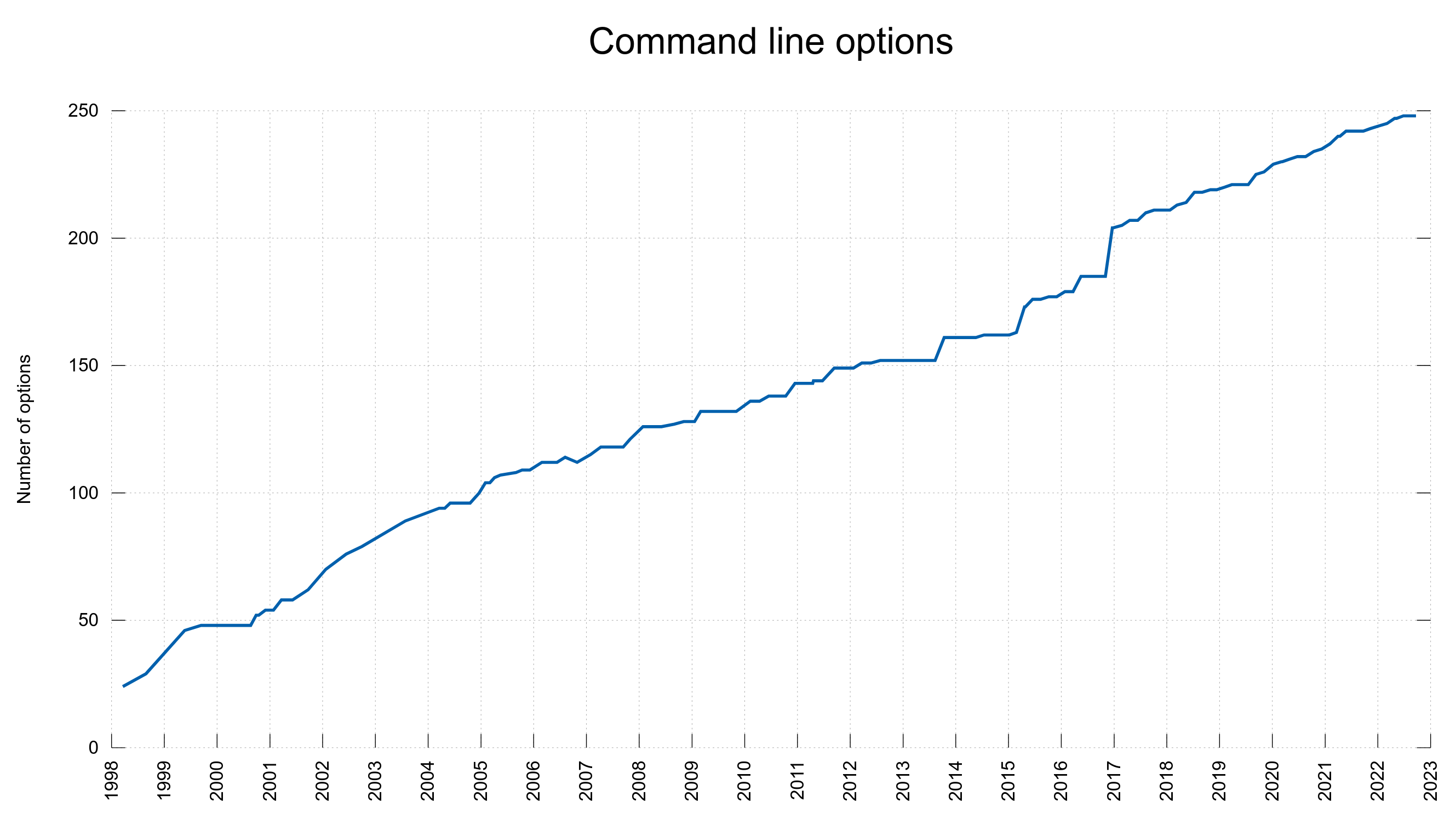
Scan SIV, figure out all existing options provided for three key libcurl functions: curl_easy_setopt, curl_multi_setopt and curl_easy_getinfo. Then verify that they all are mentioned in the respective “main” man page (curl_easy_setopt.3 etc), where they refer to the individual separate page for the option.
This test also verifies that the curl tool’s man page (curl.1) lists exactly the same set of command line options as is listed in the tool’s source code file tool_getparam.c and that is shown in the tool’s --help output. Consistency is king.
Test 1167
To make sure the symbols we provide in libcurl header files all use the correct name space we created test 1167. Using the correct name space in this context means that all publicly provided symbols need to start with curl of libcurl, case insensitively. It is important for several reasons, first of course because a good library does not pollute the name space to risk collisions and problems, but also using the correct prefix is important so that test 1119 finds all the symbols correctly. So they need to use the right prefix, and when they do, they are scanned and verified correctly.
Test 1173
For libcurl we have several function calls that take options. In some cases these functions accept a very large amount of different options. Every such option is documented in its own dedicated man page. Over time, with lots of contributors working on the project, the different man pages were not all including the same information in the same order and a huge portion of them even missed one of the most important details in programming documentation: examples.
Test 1173 checks all libcurl man pages and verifies that they have the eight mandatory libcurl sections present (NAME, SYNOPSIS, DESCRIPTION etc) and that they all are in the right order and that there is an example section that is more than 2 lines.
This test also does basic nroff formatting verification so that we know the page will look decent in a man page viewer too.
Helps us greatly – especially when we add new man pages.
Proselint
The tool that taught me to stop using the word “very” also finds a lot of other common bad takes on English is called proselint. Since a while back we run a CI job that runs proselint on all markdown files in the curl git repository. It helps us detect and edit away some amount of bad language.
Spellcheck
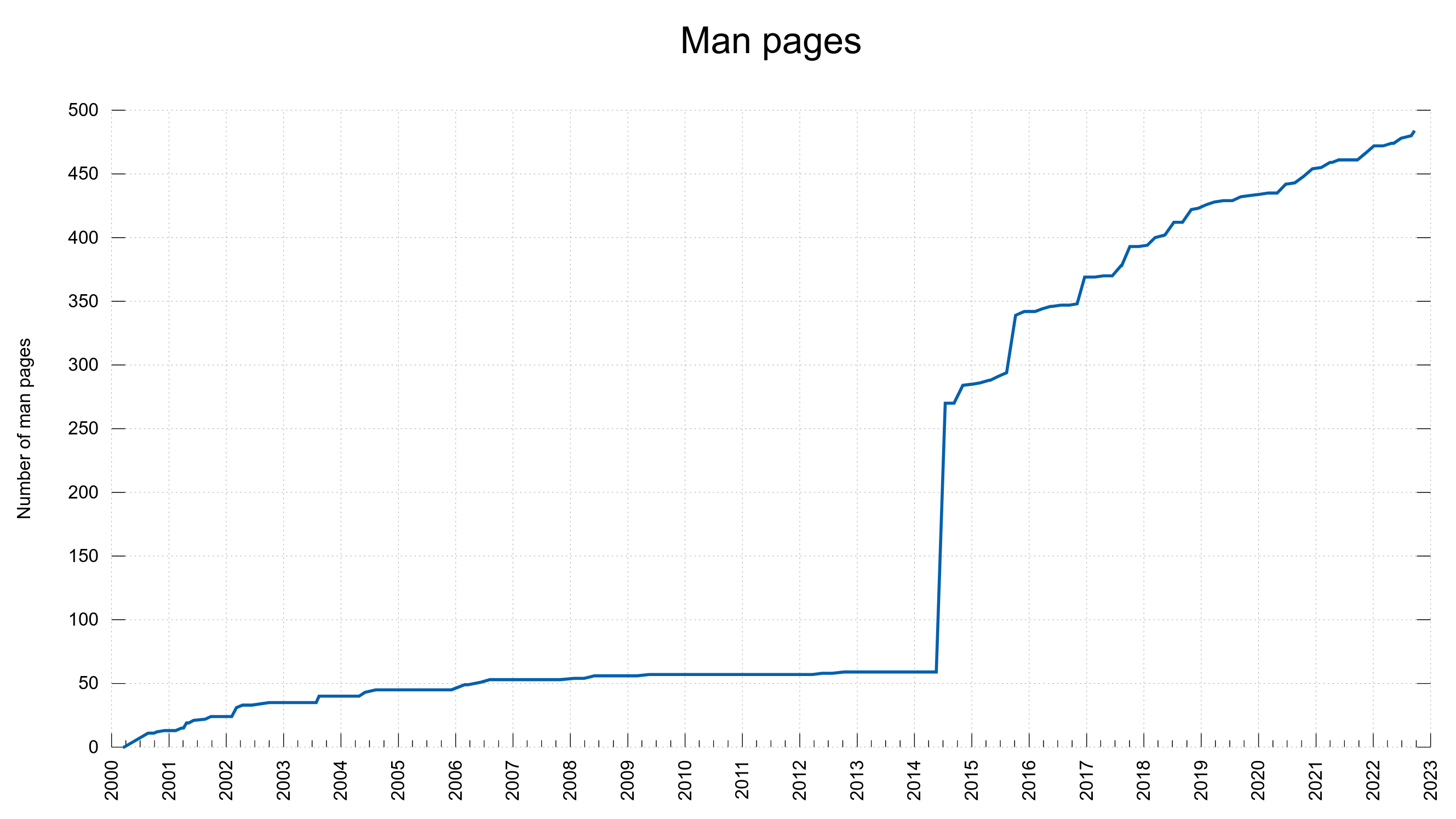
At the time of this writing, there are 482 individual libcurl related man pages and there is a total of around 85,000 lines of documentation in the project. I decided we should run a spellcheck on these man pages in an attempt to reduce the number of typos and mistakes.
The CI job I created for this first strips out some sections from the man pages that we deem too hard to spellcheck: the SYNOPSIS and the EXAMPLES sections for example. The script also removes all names that look like public curl symbols, as spellchecking them with a normal spellchecker is just impossible and they need special treatment. See further below for that.
Finally, we convert the stripped man page versions into markdown – because we have no spellchecker tools for nroff – and then spellcheck those.
It took far many more hours than I had anticipated to eradicate all the spelling mistakes and we ended up with an custom dictionary with over 800 words that aspell does not like but that I insist are valid for us.
Verify curl symbols
As I mentioned above, we strip out the curl symbols to hide them from the spellchecker.
Instead I extended the test 1119 mentioned above to also scan through all the libcurl man pages and find every single mention of something that looks like the name of a public curl symbol – and then match those against the names present in SIV and output an error if a symbol was referenced that was not documented already and therefore not actually a public curl symbol. With this, no man page can reference a non-existing curl symbol. Every such typo is detected.
Links for reporting on docs bugs
No matter how hard we try, there will always be errors that sneak in anyway and there will be sentences and phrasing that might have felt good at the time of writing but later, in the view of someone else, do not communicate the right message or maybe mislead users to misunderstand functionality.
Bug reports on documentation is key to finding such warts so that we can correct them. In the curl project we make it as easy as possible to report bugs in documentation by providing direct links on virtually all man pages shown on the website. The link takes you directly to the “new issue” page with a template subject filled in with the man page’s name.
This convenience unfortunately leads to a certain amount of “issue spam” but I think that is still a fairly cheap price to pay.
Everything curl
The book is a treasure trove of additional and complementary curl documentation but it is actually written and maintained outside of the curl repository. It has its own set of CI tests, including proselint and spellchecks.
Further
All these tests have been added gradually and slowly over a long period. It gives us time to polish and work out possible flaws in the tests and lets us make sure the work as intended and don’t block development.
I don’t have any immediate pending new pull requests for checking the curl documentation but if there still are details in there that we can check that we currently do not, I am sure that we will find those over time and make sure we verify them too.
If you have ideas and suggestions, I am all ears.
Related
Making world-class docs takes effort