curl 4.8 was released in 1998 and contained 46 command line options. curl --help would list them all. A decent set of options.
When we released curl 7.72.0 a few weeks ago, it contained 232 options… and curl --help still listed all available options.
What was once a long list of options grew over the decades into a crazy long wall of text shock to users who would enter this command and option, thinking they would figure out what command line options to try next.
–help me if you can
We’ve known about this usability flaw for a while but it took us some time to figure out how to approach it and decide what the best next step would be. Until this year when long time curl veteran Dan Fandrich did his presentation at curl up 2020 titled –help me if you can.
Emil Engler subsequently picked up the challenge and converted ideas surfaced by Dan into reality and proper code. Today we merged the refreshed and improved --help behavior in curl.
Perhaps the most notable change in curl for many users in a long time. Targeted for inclusion in the pending 7.73.0 release.
help categories
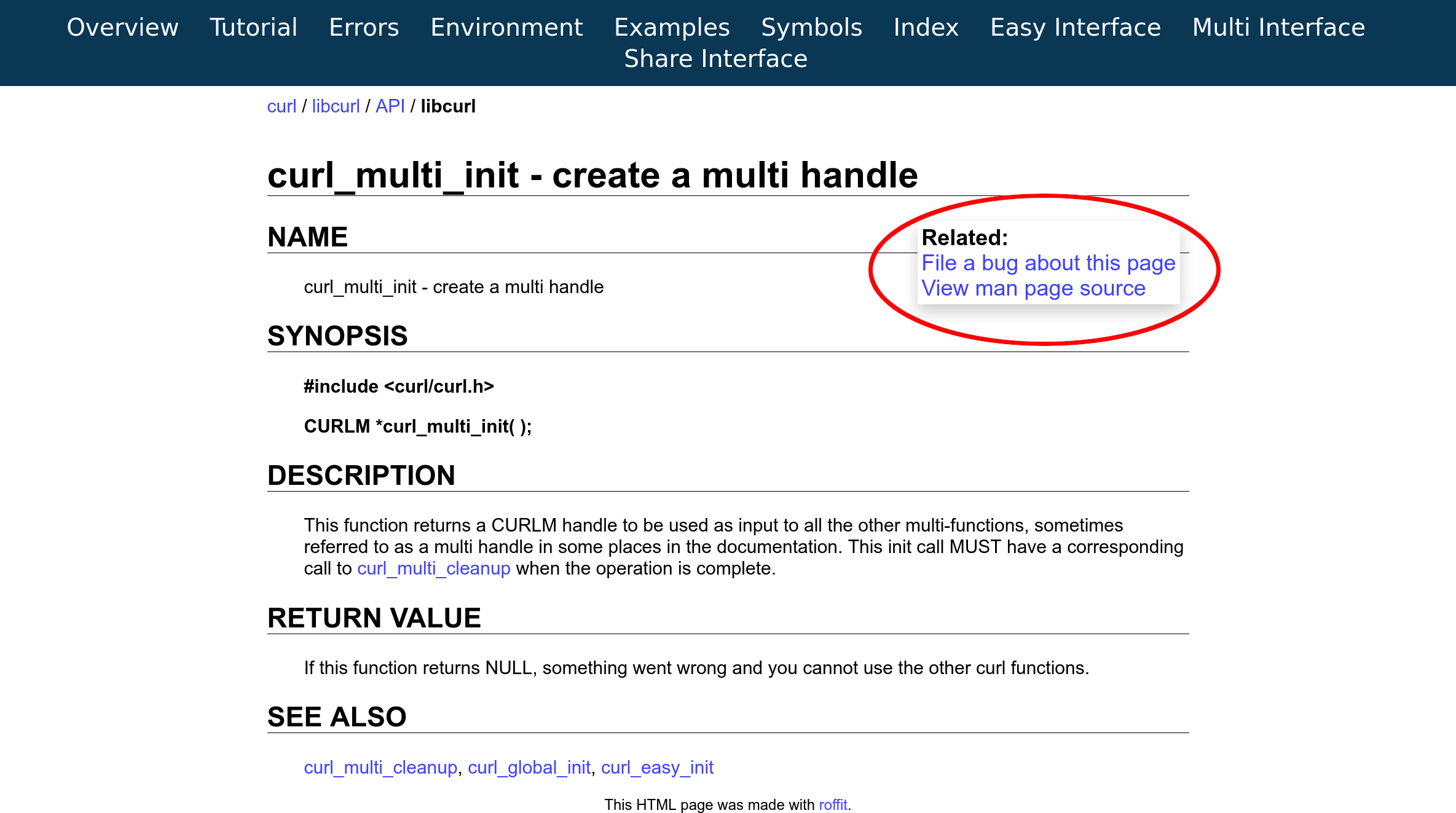
First out, curl --help will now by default only list a small subset of the most “important” and frequently used options. No massive wall, no shock. Not even necessary to pipe to more or less to see proper.
Then: each curl command line option now has one or more categories, and the help system can be asked to just show command line options belonging to the particular category that you’re interested in.
For example, let’s imagine you’re interested in seeing what curl options provide for your HTTP operations:
$ curl --help http Usage: curl [options…] http: HTTP and HTTPS protocol options --alt-svc Enable alt-svc with this cache file --anyauth Pick any authentication method --compressed Request compressed response -b, --cookie Send cookies from string/file -c, --cookie-jar Write cookies to after operation -d, --data HTTP POST data --data-ascii HTTP POST ASCII data --data-binary HTTP POST binary data --data-raw HTTP POST data, '@' allowed --data-urlencode HTTP POST data url encoded --digest Use HTTP Digest Authentication [...]
list categories
To figure out what help categories that exists, just ask with curl --help category, which will show you a list of the current twenty-two categories: auth, connection, curl, dns, file, ftp, http, imap, misc, output, pop3, post, proxy, scp, sftp, smtp, ssh, telnet ,tftp, tls, upload and verbose. It will also display a brief description of each category.
Each command line option can be put into multiple categories, so the same one may be displayed in both in the “http” category as well as in “upload” or “auth” etc.
--help all
You can of course still get the old list of every single command line option by issuing curl --help all. Handy for grepping the list and more.
“important”
The meta category “important” is what we use for the options that we show when just curl --help is issued. Presumably those options should be the most important, in some ways.
Credits
Code by Emil Engler. Ideas and research by Dan Fandrich.