If you missed it. I already described day one.
Caffeinated and ready, we all gathered in the same spacious room as yesterday, but seated in new places as “suggested” by our captain. Some of us even remembered to move over the name tags we wrote yesterday to our new seats.
No time was wasted on introductions today. We dove straight in at the deep end.
How AI is changing how HTTP is implemented.
Is the future of software that we check-in the AI prompts in the git repository and trust it to generate the correct code? Are specifications the new level o
f abstraction for source code? These questions triggered long discussions with a huge mix of opinions and experiences getting shared about how AI is used, should be used and could be used now and in the future.
Observations and Measurements of HTTP/2 During Large-Scale Web Crawls
The Common Crawl spidering upgraded to using HTTP/2 for their scan and as an end result, I believe 61% of the responses used HTTP/2 and the entire round ended a few percent faster than before, which when you traverse a few billion URLs really makes a difference. They apparently use a locally patched version of Apache Nutch for this.
HTTP/1.1 behavior divergence
The HTTP probe project runs a lot of tests on HTTP/1 servers and compares how they behave in a lot of different aspects and then generates these awesome tables. Looks like something for every server implementer team to have a look at and decide what of these red boxes that should rather be converted into green alternatives.
Request smuggling test suite
HTTP Zoll is a new test suite for intermediaries that tests intermediaries (what we often call proxies) for a large amount of request and response smuggling issues. Some real world problems found were discussed and as this project aims at going Open Source words were expressed on what kind of precautions and checks that maybe should be done first. I hope we get to hear more about this project soon.
Server performance & measurement
The HTTP Arena is another project that does performance and measurements. They test HTTP server frameworks and present the results in various ways on their site.
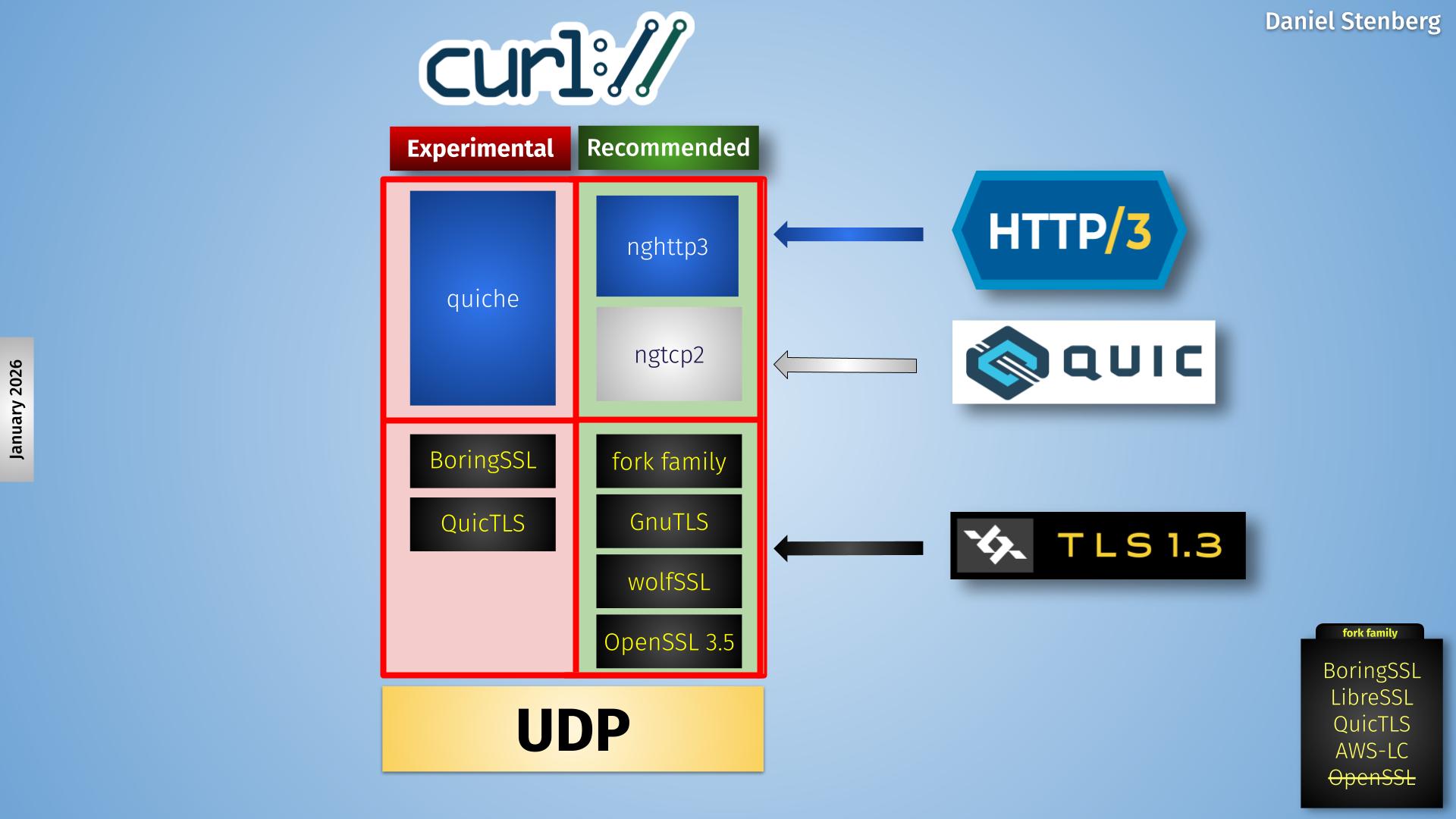
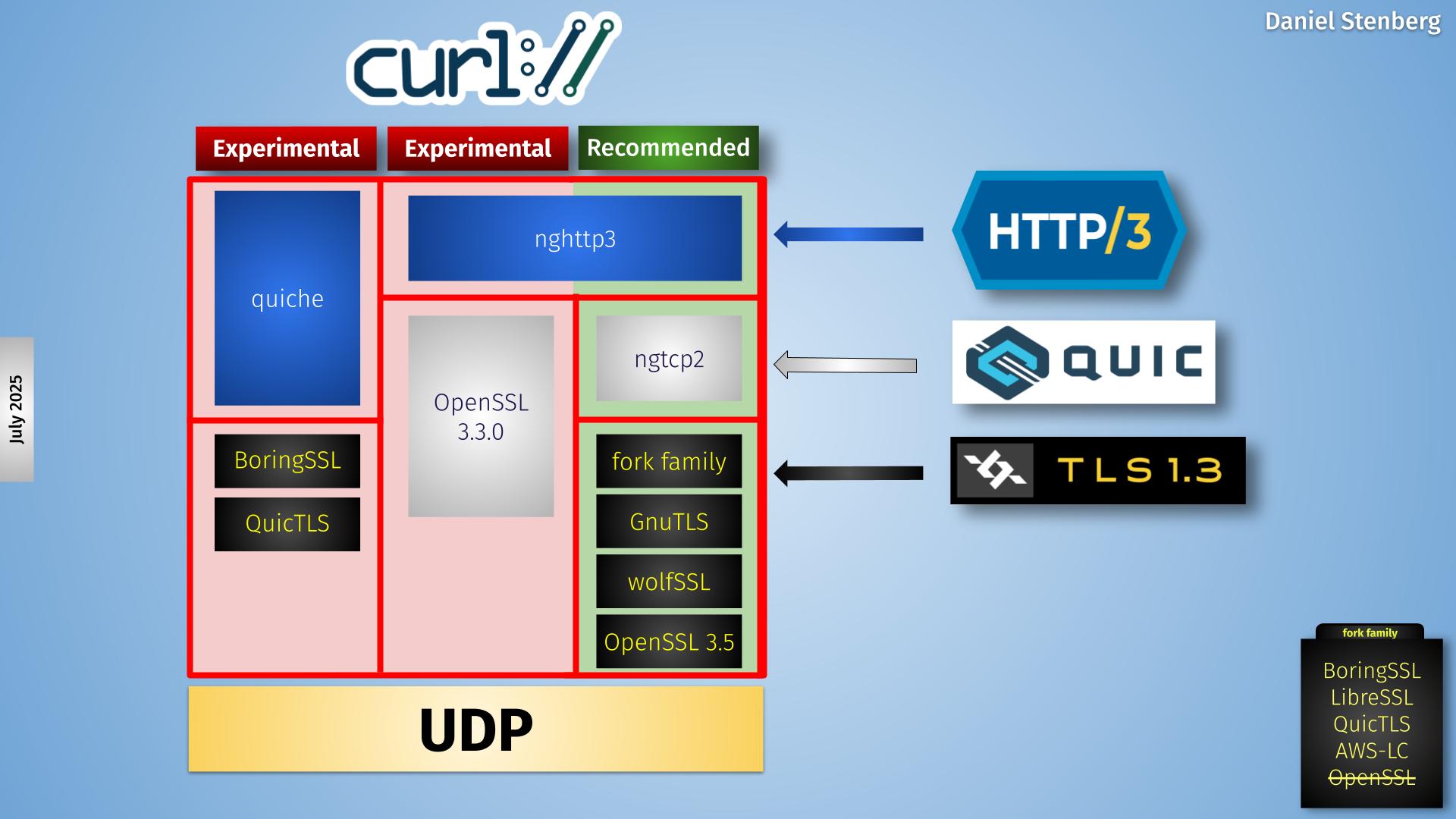
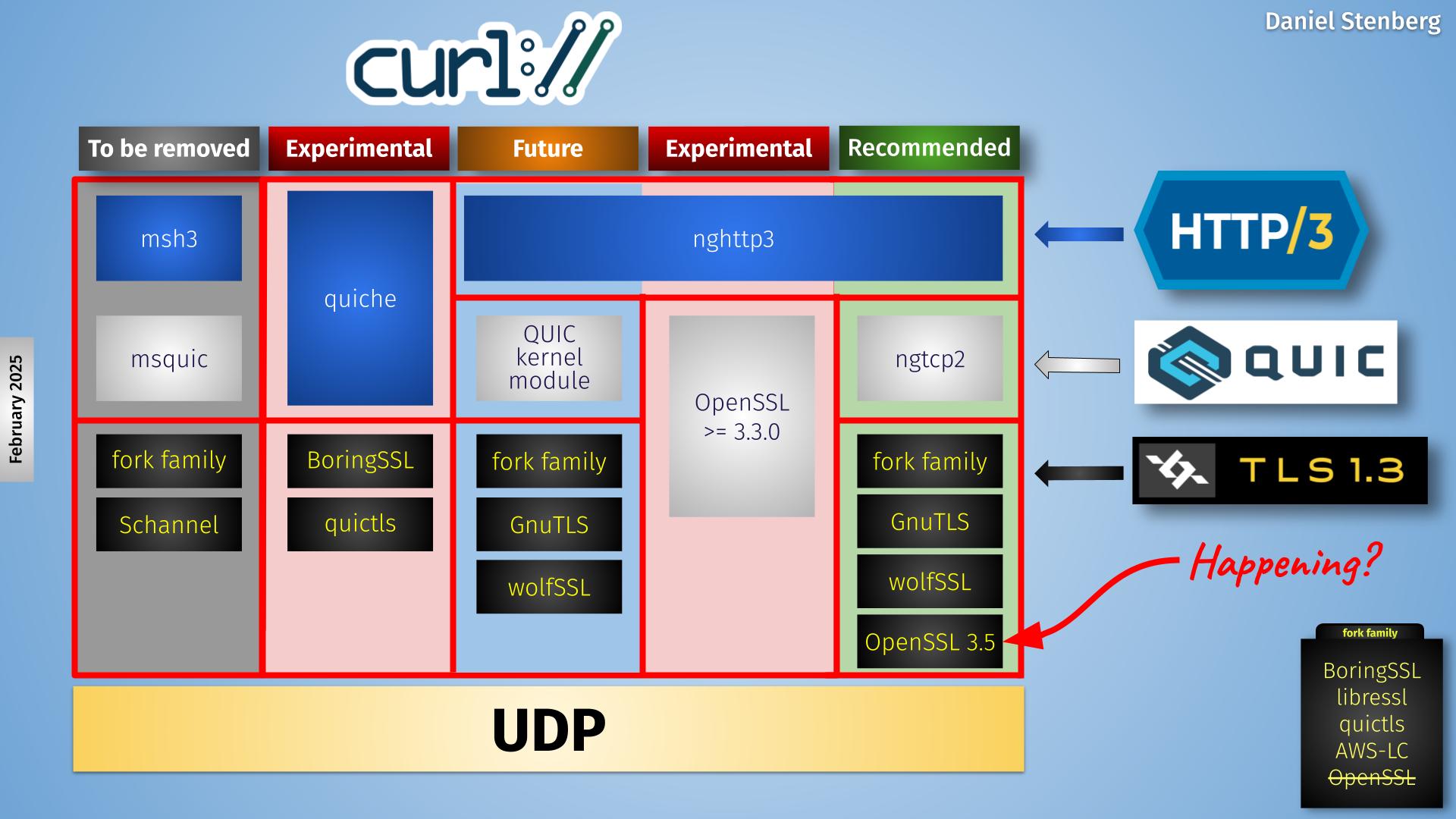
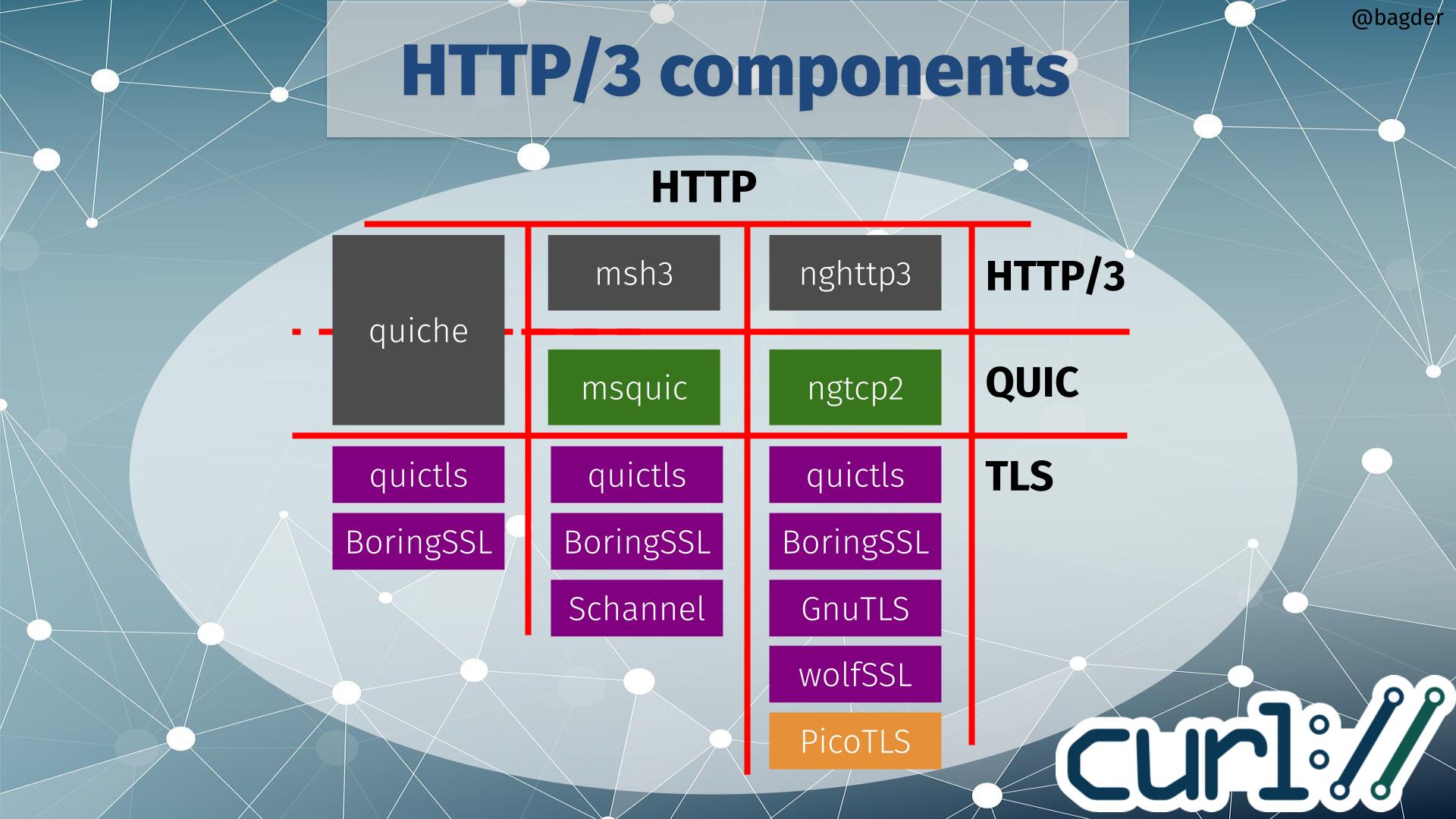
Increase and evolve HTTP/3 & QUIC
In this presentation, we were presented with different HTTP/3 deployment numbers from different sources and the associated reasoning around why they differ but then more importantly. what can and should be done to increase HTTP/3 usage.
Anti-virus interceptions, enterprise blocks and server-side performance not yet on par with TCP were mentioned as reasons for holding back the numbers.
Reasons for using HTTP/3 include use cases that encourage QUIC adoption: WebTransport, Media over QUIC and MASQUE (HTTP/3 proxies and HTTP/3 proxies over older HTTP proxies).
Using HTTPS-RR for upgrade was promoted, as every alt-svc response that is returned with an ALPN using h3 should perhaps also offer h3 over DNS. Why doesn’t your server announce its h3 support over HTTPS-RR?
QUIC v2 is deployed on an amazing 0.003% of all QUIC v1 domains and there was a discussion why this is so and the common sentiment in the room seemed to be that very few saw a reason for deploying v2 and several expressed a concern that doing so might in fact introduce issues. Someone (you can probably guess who) in the room increased that number a lot by quietly mentioning that haxproxy.org certainly supports it.
QMUX
QUIC multiplexing over bi-directional streams is a proposal on how to do QUIC-style multiplexing over TLS (or anything else really). It has been adopted by the IETF QUIC working group and there was a somewhat extended discussion about what the HTTPbis group should or should not do with it. The biggest interest might be for data center use, but is that then something IETF should bother about? This is not the first time I blog about this, and even if there did not seem to be a strong demand or need for this, it also did not seem to be completely dead. I bet we will hear more about this later.
Multiplexed proxying: challenges in H2 and H3
Doing a TLS terminating MITM proxy has its challenges and we were given some insights and experiences on the challenges of doing HTTP/2 and HTTP/3 to the server.
The browsers refuse to do HTTP/3 when they detect custom CA certs installed, which apparently is mostly because of lots of past bad experiences with anti-virus software that in particular seems to break QUIC and for users it is not obvious where the blame should go. This then makes browsers not do HTTP/3 over any MITM proxy.
Some time was spent on how allowing different clients to the proxy uses a shared h2 connection to the target server is complicated and not used, even though in theory it should be possible. An argument was made that it could even lead to worse performance than when using HTTP/1 but I could not quite follow that reasoning. I’m sure I missed some subtle detail in that explanation.
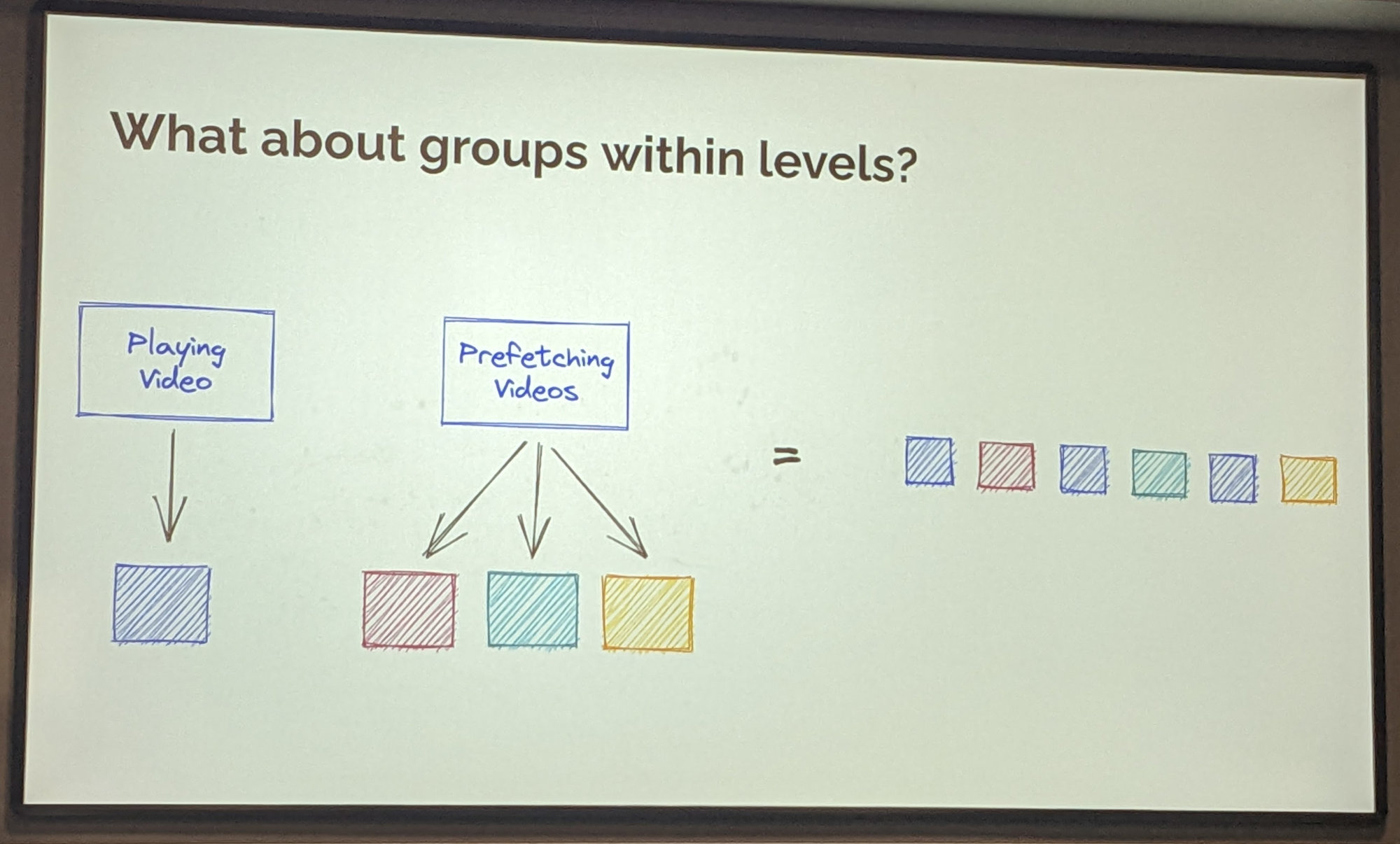
Making the Web QUICer with Rapid Start
When the afternoon is running late and we have been promised beer and snacks after the final talk, what is better than a hard core technical presentation with lots of graphs and numbers showing how QUIC performance can be improved by tweaking the congestion control algorithm and send more data in the startup phase of a new QUIC connections? This new approach is called Rapid Start and it looks like a promising and yet simple improvement. According to experiments done on real world traffic, the time to last byte was reduced by 14.7% on average. Not bad at all.
Drinks and food
Our meeting sponsor Adobe graciously sponsored drinks and food so we got to linger around for a few extra hours and talk even more HTTP and networking until the personal firmly insistent they needed us to leave the room and we instead continued solving world problems elsewhere. Topics around the table included the famous HTTP/2 spec coin flip, the QUIC spin bit, the SCONE situation for QUIC, the timeline behind the QUERY method and many more great stories.
Thanks for the beer!
Now we can’t wait for day three.