We make long term support releases of curl that we call Rock-solid curl.
We support each release branch for at least five years.
We only merge security fixes and important stability bugfixes into these branches for updates. No new features. No surprises.
We offer Rock-solid curl downloads to existing support customers. It means that there is no free and open access to these releases. To get access, become a customer!
Rock-solid curl is meant to greatly reduce the risk of regressions and yet be a safe and secure solution with full support. For the companies who want this extra level of attention. An even smoother ride.
We plan to make new Rock-solid curl release branches roughly every 18-24 months.
The first Rock-solid curl release
Rock-solid curl 8.9.2 is the first long-term support curl version. As the version number implies, it is based on the curl 8.9.1 release that we shipped back in July, with two security fixes and a small number of stability patches applied.
Once you have a contract with us, you can get it.
Who is doing this?
I, Daniel Stenberg, will be the primary support person for Rock-solid curl and I will do the releases, and most of the patching and the back-porting of what is deemed necessary.
Customers sign contracts with wolfSSL for this. wolfSSL pays my salary. I have worked for and with wolfSSL with this business setup since 2019.
What about “the normal” curl?
Nothing changes with or happens to the curl project and the regular curl releases because of this. No one is going anywhere. The curl license remains the same. The curl releases and the release cadence remain intact.
Support customers help fund the project by allowing us to pay developers.
Downloads and all Rock-solid curl information is hosted on the dedicated rock-solid.curl.dev site, separate from the open source project on curl.se.
On curl
Born in the late 1990s, curl is a client-side Internet transfer engine. Installed in over twenty billion instances it serves virtually everything that is internet connected: phones, tablets, cars, television sets, printers, medical devices, game consoles, helicopters on other planets, etc and it is an embedded component in a significant share of our most used and beloved apps, tools, games and services.
curl is the fruit and outcome from hard work by thousands of volunteers and is completely free and Open Source. The curl project is independent. It is not part of any umbrella organization or foundation and it is not owned nor controlled by any company.
curl is secure, fast and feature-rich. It is a defacto standard and key infrastructure.
Starting now, there are official curl releases for QNX hosted on the curl.se website. See https://curl.se/qnx.
QNX is a commercial real-time operating system and these curl release packages are produced as a result of a business arrangement.
The plan is to from now on ship curl tarballs for three different QNX versions, and each archive contains curl and libcurl built for several different targets. The curl for QNX releases should be possible to release in sync with the regular releases, but they can also be updated out of sync if need be.
Every curl release from here on out will be packaged for QNX and made available.
curl and libcurl have been functional on QNX since decades – the first mention of curl and QNX together that I could find is from October 2000. curl releases for QNX were previously packaged and provided to end users by the QNX team themselves.
This move will allow QNX users to get the latest curl faster and make them able to keep up better with curl development. For features, bugfixes and perhaps most of all security.
We will also make sure that curl keeps building fine for QNX straight from the tarball.
The complete set of build and setup scripts for curl on QNX are maintained in the curl-for-qnx git repository. Of course we will appreciate submitted issues and pull requests in that repository as well.
This commercial agreement is between Blackberry and wolfSSL. I am employed by wolfSSL. If you want your operating system to have equally fancy and always up-to-date releases, you know who to contact.
Five years ago now, on February 2nd 2019, I started working for wolfSSL doing curl full time. I have now worked longer for wolfSSL than I previously did for Mozilla.
I have said it before and I will say it again: working full time on curl is my definition of living the dream.
Joining wolfSSL was not just me changing employer, it changed everything for me. First, I am not just a regular employee, I am the lead curl developer and the curl support we offer for commercial customers is unparalleled. No other business or individuals can offer the same level of support, knowledge, experience, insights and ability to merge fixes and changes back into curl mainline.
At wolfSSL we offer commercial services around and support for curl and libcurl. Contract development of new features, debugging, fixing problems and just about every other aspect of getting users get better use of (lib)curl in their products and services.
I think this change has been good for curl and curl project as well. The last five years have seen more and faster development than any other previous five year period. I have been able to work intensely and a lot on curl, When fixing bugs and adding features for customers, but even more just the general improving of things for everyone that the money from support customers makes possible.
I am happy to announce that curl receives funding from The Sovereign Tech Fund. This funding is directed towards three specific projects that we have identified as interesting and worthwhile to push forward as ways to improve curl and the life of curl users.
This “investment” will fund two developers to work on curl over a period of six months: Stefan Eissing and myself. The three projects are explained at some detail below. Of course everyone and anyone is welcome to join in and help out with these projects. Everything will be done in the open, as usual.
At the end of the period, we will produce some kind of report or summary of how things turned out.
The three projects we are getting funded have been especially created and crafted (by me) to be good solid projects that we really want to see done. This funding is different than many others we have gotten over the years in that we got to decide and plan what we wanted done. These are things that are meant to improve curl as a project and to generally make Internet transfers better and more powerful for a vast amount of users.
Project 1 – known bugs cleanup
The curl project currently lists 120+ items as known bugs (up from 77 just two years ago).
The items in that list are reported problems that were recognized as problems at the time of their submission but as nobody worked on the issues at the time they were added to this list. The list includes everything from smaller irks up to big things that will either take a long time to fix or be (almost) impossible to address.
There is a good chance that the list will be extended during the project period just because some new bugs fall into the description mentioned above.
This project is an effort to go through as many as possible to make sure they are correctly categorized/described and work on fixing the issues or whatever is necessary to get them off the list.
The process would entail an initial proper research round to extend the description and increase the understanding of each entry, followed by a rough assessment of the amount of work it would take to fix them. Possibly with a 1 (easy) to 5 (extreme) scale.
The action would then be to address the issues, possibly in an easy to hard order. Addressing the issues could be to fix the code to remove the issue, dismiss it as not actually intended to work or document it as not working or even moving it over to the TODO document if it is more of a good idea for the future.
The goal being to reduce the list to zero entries and thus polish off numerous rough corners and annoyances in the project.
This will be done by Daniel Stenberg over a period of 6 months.
Project 2 – HTTP/3
Make HTTP/3 release-ready.
curl features experimental HTTP/3 and QUIC support already since a few years back, but there are several details still lacking:
known bugs
proper multiplexing: doing multiple transfers to the same host should be able to reuse an existing connection and multiplex over that, just as curl already does when using HTTP/2
HTTP/3 support for the test suite (and CI jobs) need to be done for us to be able to consider the support release ready. Cooperation can be had with QUIC libraries such as ngtcp2 to consider where/how some of the testing is best performed.
considerations for 0-RTT connection establishments (if anything needs to be done)
support for early data: to send off the HTTP request to the server faster.
connection migration:, a QUIC feature that allows a server to move over a live connection from one server to another without disruption
fallback to h1/h2 if the QUIC connection fails. The failure rate for QUIC connections are still in the 3-7% rate generally, so having a good fallback mechanism or documented for how applications can go back to an older HTTP version instead, is important.
HTTPS RR. This fairly new DNS resource record might contain information about the target server’s support for HTTP/3. If such a record is provided, curl can avoid superfluous round-trips to get the Alt-Svc header and rather connect directly to the HTTP/3 server.
All features and changes need to be documented. Functionality needs to be verified by test cases. Interop with real world servers is of course implied and assumed.
Stefan Eissing will spend 4 months on this project.
Project 3 – HTTP/2 over proxy
curl has provided support for doing network transfers via HTTP proxies since decades, and this is a very commonly used feature and network setup.
curl however only supports using HTTP version 1 over proxies. This makes applications less effective as it sometimes leads to many more TCP connections being used than otherwise would be necessary if HTTP/2 could be used. In particular when applications behind a proxy operate against many different hosts on the other side of the proxy.
It can also be noted that in many enterprise setups, this kind of HTTP proxy is used for all kinds of network operations through the use of the CONNECT method, so this functionality is not limited to plain HTTP(S), it should work for all TCP based protocols libcurl supports and which already work over HTTP/1 proxies.
The project will require adding new options to enable this functionality, to both the library and the command line tool. With associated documentation.
It will require creating or extending the HTTP/2 support in the curl test suite so that this new functionality can be verified and proven to work at a satisfactory level.
Considerations must be taken so that this work does not close the door for future extending this to support HTTP/3 over proxy. Time permitting, work should be taken to pave the road for that or even perhaps gently start the work to support that as well.
Stefan Eissing will spend 2 months on this project.
The outcome(s)
I hope and presume that the results of these projects will appear as a stream of pull-requests for curl that will be done and managed through-out the project period and not saved up to the end or anything. The review, test and merge process of these pull requests will follow our normal and standard project guidelines and procedures.
The projects are fully packed and (over) ambitious. There is a high risk that we will not be able to complete all the details for these projects within the time frame. But we will try.
Disclaimer: I work for wolfSSL but I don’t speak for wolfSSL. I state my own opinions and I try to be as honest and transparent as possible. As always.
QUIC API
Back in the summer of 2020 I blogged about QUIC support coming in wolfSSL. That work never actually took off, primarily I believe because the team kept busy with other projects and tasks that had more customer focus and interest and yeah, there was not really any noticeable customer demand for QUIC with wolfSSL.
Time passed.
On July 21 2022, Stefan Eissing submitted his work on introducing a QUIC API and after reviews and updates, it was merged into the wolfSSL master branch on August 9th.
The QUIC API is planned to appear “for real” in a coming wolfSSL release version. Until then, we can play with what is available in git.
Let me be clear here: the good people at wolfSSL has not decided to write a full QUIC implementation, because that would be insane when so many good alternatives are already being worked on. This is just a set of new functions to allow wolfSSL to be used as TLS component when a QUIC stack is created.
Having QUIC support in wolfSSL is just one (but important) step along the way as it makes it possible to use wolfSSL to build a QUIC implementation but there are some more steps needed to turn this baby into full HTTP/3.
ngtcp2
Luckily, ngtcp2 exists and it is an established QUIC implementation that was written to be TLS agnostic from the beginning. This “only” needs adaptions provided to make sure it can be built and used with wolSSL as the TLS provider.
Stefan brought wolfSSL support to ngtcp2 in this PR. Merged on August 13th.
nghttp3
nghttp3 is the HTTP/3 library that uses ngtcp2 for QUIC, so once ngtcp2 supports wolfSSL we can use nghttp3 to do HTTP/3.
curl
curl can (as one of the available options) get built to use nghttp3 for HTTP/3, and if we just make sure we use an underlying ngtcp2 built to use a wolfSSL version with QUIC support, we can now do proper curl HTTP/3 transfers powered by wolfSSL.
Stefan made it possible to build curl with the wolfSSL+ngtcp2 combo in this PR. Merged on August 15th.
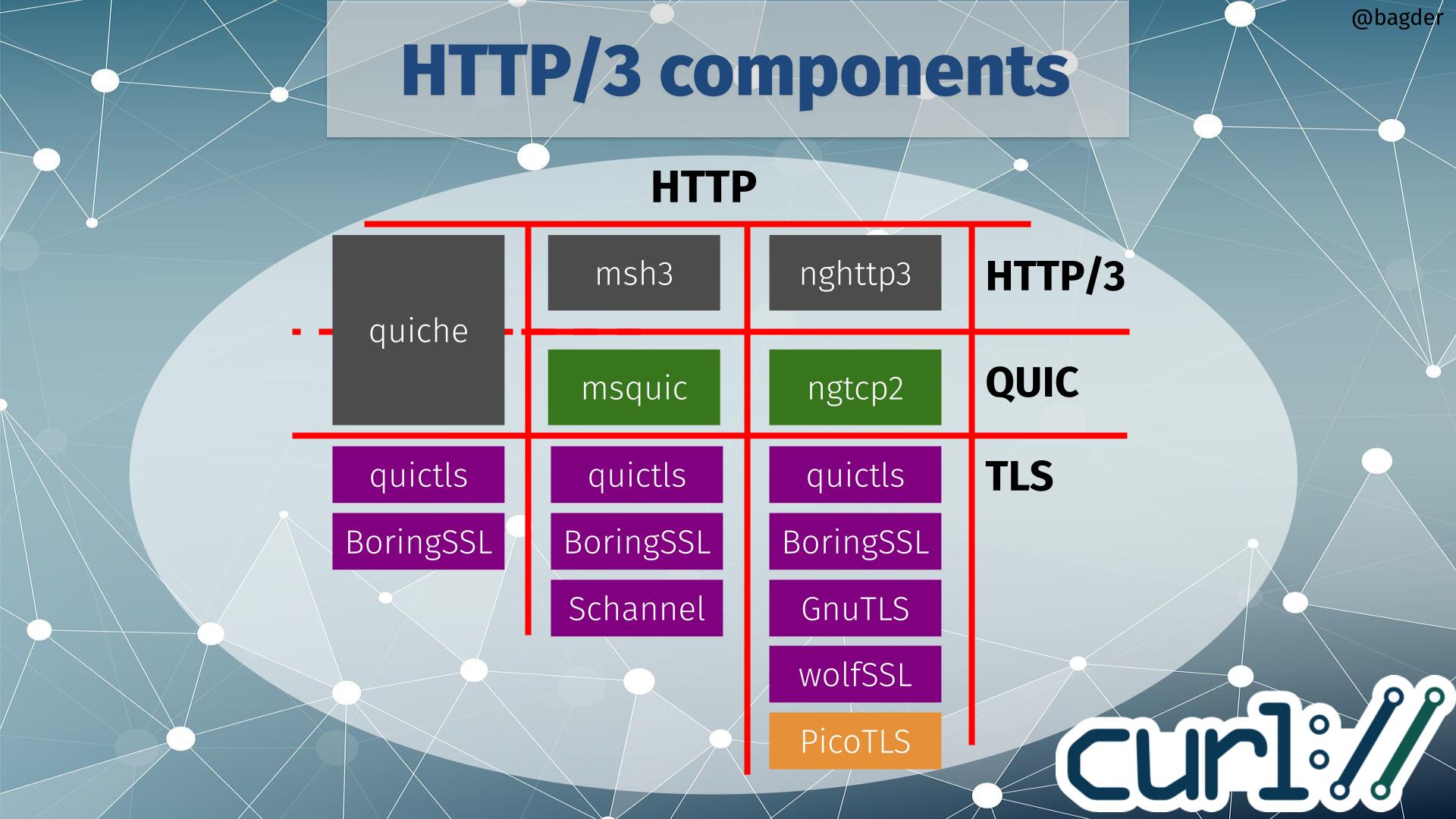
Available HTTP/3 components
With this new ecosystem addition, the chart of HTTP/3 components for curl did not get any easier to parse!
If you start by selecting which HTTP/3 library (or maybe I should call it HTTP/3 vertical) to use when building, there are three available options to go with: quiche, msh3 or nghttp3. Depending on that choice, the QUIC library is given. quiche does QUIC as well, but the two other HTTP/3 libraries use dedicated QUIC libraries (msquic and ngtcp2 respectively).
Depending on which QUIC solution you use, there is a limited selection of TLS libraries to use. The image above shows TLS libraries that curl also supports for other protocols, meaning that if you pick one of those you can still use that curl build to for example do HTTPS for HTTP version 1 or 2.
TLS options
If you instead rather pick TLS library first, only quictls and BoringSSL are supported by all QUIC libraries (quictls is an OpenSSL fork with a BoringSSL-like QUIC API patched in). If you rather build curl to use Schannel (that’s the native Windows TLS API), GnuTLS or wolfSSL you have also indirectly chosen which QUIC and HTTP/3 libraries to use.
Picotls
ngtcp2 supports Picotls shown in orange in the image above because that is a TLS 1.3-only library that is not supported for other TLS operations within curl. If you build curl and opt to go with a ngtcp2 build using Picotls for QUIC, you would need to have use an second TLS library for other TLS-using protocols. This is possible, but is rarely what users prefer.
No OpenSSL option
It should probably be especially highlighted that the plain vanilla OpenSSL is not an available option. Primarily because they decided that the already created API was not good enough for them so they will instead work on implementing their own QUIC library to be released at some point in the future. That also implies that if we want to build curl to do HTTP/3 with OpenSSL in the future, we probably need to add support for a forth QUIC library – and someone would also have to write a HTTP/3 library to use OpenSSL for QUIC.
Why wolfSSL adding QUIC is good for HTTP/3
People in general want to build applications and infrastructure using released, official and supported libraries and the sad truth is that there is a clear shortage in such TLS libraries with QUIC support.
In your typical current Linux distribution, quictls and BoringSSL are usually not viable options. The first since it is an OpenSSL fork not many even ship as a package and the second because it is done by Google for Google and they don’t do releases and generally care little for outside-Google users.
For the situations where those two TLS options are out of the game, the image above shows you the grim reality: your HTTP/3 options are limited. On Windows you can go with msh3 since it can use Schannel there, but on non-Windows you can only use ngtcp2/nghttp3 and before this wolfSSL support the only TLS option was GnuTLS.
For many embedded solutions, or even FIPS requirements, wolfSSL is now the only viable option for doing HTTP/3 with curl.
I work a lot on my own. I mean, I plan a lot of what to do on a daily basis myself, I execute a lot of it myself and I push my code and changes to various git repositories, often solo. I work quite a lot.
In a lot of the cases, I work together with one or more persons in each individual case, but very often that’s one or a few different persons involved in each and every one.
Yet I work at a company with colleagues, friends, managers and sales people who occasionally wonder what I’ve been up to recently and what I’m working on right now.
Weekly reports
To share information, to combat my feeling of working in complete solitude and to better sync work with colleagues, I’ve been sending out a weekly report every Friday. It briefly explains what I did this week, what I blogged about and what I’m up to the next week.
I’ve done this on and off since I joined wolfSSL, and a while ago it dawned on me that since I do most of my work on open source code and in general in the open, I could just as well just make my “reports” available to the entire world. Or rather: those who care and are interested can find them and read them!
Minor details are still hush hush
Since I do commercial curl work with and for other companies, I need to not spill the beans on things like actual secrets and most company names will be anonymized. I hope that won’t interfere too much.
GitHub
I decided to make it available on GitHub like this:
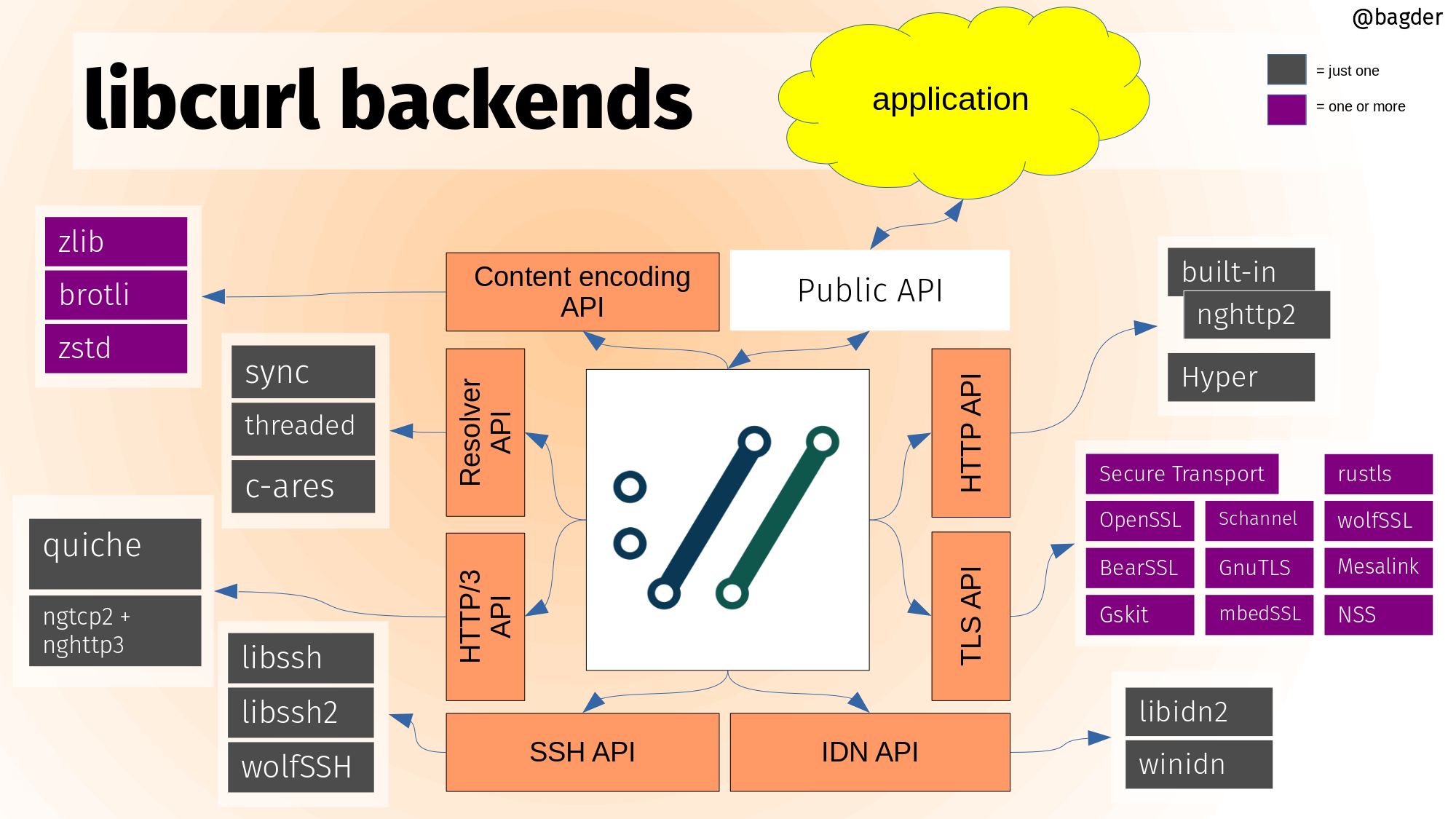
Thanks to funding by ISRG (via Google), we merged the hyper powered HTTP back-end into curl earlier this year as an alternative HTTP/1 and HTTP/2 implementation. Previously, there was only one way to do HTTP/1 and 2 in curl.
Backends
Core libcurl functionality can be powered by optional and alternative backends in a way that doesn’t change the API or directly affect the application. This is done by featuring internal APIs that can be implemented by independent components. See the illustration below (click for higher resolution).
curl 7.75.0 became the first curl release that could be built with hyper. The support for it was labeled “experimental” as while most of all common and basic use cases were supported, we still couldn’t run the full test suite when built with it and some edge cases even crashed.
We’ve subsequently fixed a few of the worst flaws so the Hyper powered curl has gradually and slowly improved since then.
Going further
Our best friends at ISRG has now once again put up funding and I’ll spend more work hours on making sure that more (preferably all) tests can run with hyper.
I’ve already started. Right now I’m sitting and staring at test case 154 which is doing a HTTP PUT using Digest authentication and an Expect: 100-continue header and this test case currently doesn’t work correctly when built to use Hyper. I’ll report back in a few weeks and let you know how it goes – and then I don’t mean with just test 154!
Consider yourself invited to join the #curl IRC channel and chat if you want live reports or want to help out!
Fund
You too can fund me to do curl work. Get in touch!
I founded the curl project early 1998 but had already then been working on the code since November 1996. The source code was always open, free and available to the world. The term “open source” actually wasn’t even coined until early 1998, just weeks before curl was born.
In the beginning of course, the first few years or so, this project wasn’t seen or discovered by many and just grew slowly and silently in a dusty corner of the Internet.
Already when I shipped the first versions I wanted the code to be open and freely available. For years I had seen the cool free software put out the in the world by others and I wanted my work to help build this communal treasure trove.
License
When I started this journey I didn’t really know what I wanted with curl’s license and exactly what rights and freedoms I wanted to give away and it took a few years and attempts before it landed.
The early versions were GPL licensed, but as I learned about resistance from proprietary companies and thought about it further, I changed the license to be more commercially friendly and to match my conviction better. I ended up with MIT after a brief experimental time using MPL. (It was easy to change the license back then because I owned all the copyrights at that point.)
To be exact: we actually have a slightly modified MIT license with some very subtle differences. The reason for the changes have been forgotten and we didn’t get those commits logged in the “big transition” to Sourceforge that we did in late 1999… The end result is that this is now often recognized as “the curl license”, even though it is in effect the MIT license.
The license says everyone can use the code for whatever purpose and nobody is required to ship any source code to anyone, but they cannot claim they wrote it themselves and the license/use of the code should be mentioned in documentation or another relevant location.
As licenses go, this has to be one of the most frictionless ones there is.
Copyright
Open source relies on a solid copyright law and the copyright owners of the code are the only ones who can license it away. For a long time I was the sole copyright owner in the project. But as I had decided to stick to the license, I saw no particular downsides with allowing code and contributors (of significant contributions) to retain their copyrights on the parts they brought. To not use that as a fence to make contributions harder.
Today, in early 2021, I count 1441 copyright strings in the curl source code git repository. 94.9% of them have my name.
I never liked how some projects require copyright assignments or license agreements etc to be able to submit code or patches. Partly because of the huge administrative burden it adds to the project, but also for the significant friction and barrier to entry they create for new contributors and the unbalance it creates; some get more rights than others. I’ve always worked on making it easy and smooth for newcomers to start contributing to curl. It doesn’t happen by accident.
Spare time
In many ways, running a spare time open source project is easy. You just need a steady income from a “real” job and sufficient spare time, and maybe a server to host stuff on for the online presence.
The challenge is of course to keep developing it, adding things people want, to help users with problems and to address issues timely. Especially if you happen to be lucky and the user amount increases and the project grows in popularity.
I ran curl as a spare time project for decades. Over the years it became more and more common that users who submitted bug reports or asked for help about things were actually doing that during their paid work hours because they used curl in a commercial surrounding – which sometimes made the situation almost absurd. The ones who actually got paid to work with curl were asking the unpaid developers to help them out.
I changed employers several times. I started my own company and worked as my own boss for a while. I worked for Mozilla on network stuff in Firefox for five years. But curl remained a spare time project because I couldn’t figure out how to turn it into a job without risking the project or my economy.
Earning a living
For many years it was a pipe dream for me to be able to work on curl as a real job. But how do I actually take the step from a spare time project to doing it full time? I give away all the code for free, and it is a solid and reliable product.
The initial seeds were planted when I met and got to know Larry (wolfSSL CEO) and some of the other good people at wolfSSL back in the early 2010s. This, because wolfSSL is a company that write open source libraries and offer commercial support for them – proving that it can work as a business model. Larry always told me he thought there was a possibility waiting here for me with curl.
Apart from the business angle, if I would be able to work more on curl it could really benefit the curl project, and then of course indirectly everyone who uses it.
It was still a step to take. When I gave up on Mozilla in 2018, it just took a little thinking before I decided to try it. I joined wolfSSL to work on curl full time. A dream came true and finally curl was not just something I did “on the side”. It only took 21 years from first curl release to reach that point…
I’m living the open source dream, working on the project I created myself.
Food for free code
We sell commercial support for curl and libcurl. Companies and users that need a helping hand or swift assistance with their problems can get it from us – and with me here I dare to claim that there’s no company anywhere else with the same ability. We can offload engineering teams with their curl issues. Up to 24/7 level!
We also offer custom curl development, debugging help, porting to new platforms and basically any other curl related activity you need. See more on the curl product page on the wolfSSL site.
curl (mostly in the shape of libcurl) runs in ten billion installations: some five, six billion mobile phones and tablets – used by several of the most downloaded apps in existence, in virtually every website and Internet server. In a billion computer games, a billion Windows machines, half a billion TVs, half a billion game consoles and in a few hundred million cars… curl has been made to run on 82 operating systems on 22 CPU architectures. Very few software components can claim a wider use.
“Isn’t it easier to list companies that are not using curl?”
Wide use and being recognized does not bring food on the table. curl is also totally free to download, build and use. It is very solid and stable. It performs well, is documented, well tested and “battle hardened”. It “just works” for most users.
Pay for support!
How to convince companies that they should get a curl support contract with me?
Paying customers get to influence what I work on next. Not only distant road-mapping but also how to prioritize short term bug-fixes etc. We have a guaranteed response-time.
You get your issues first in line to get fixed. Customers also won’t risk getting their issues added the known bugs document and put in the attic to be forgotten. We can help customers make sure their application use libcurl correctly and in the best possible way.
I try to emphasize that by getting support from us, customers can take away some of those tasks from their own engineers and because we are faster and better on curl related issues, that is a pure net gain economically. For all of us.
This is not an easy sell.
Sure, curl is used by thousands of companies everywhere, but most of them do it because it’s free (in all meanings of the word), functional and available. There’s a real challenge in identifying those that actually use it enough and value the functionality enough that they realize they want to improve their curl foo.
Most of our curl customers purchased support first when they faced a complicated issue or problem they couldn’t fix themselves – this fact gives me this weird (to the wider curl community) incentive to not fix some problems too fast, because it then makes it work against my ability to gain new customers!
We need paying customers for this to be sustainable. When wolfSSL has a sustainable curl business, I get paid and the work I do in curl benefits all the curl users; paying as well as non-paying.
Dual license
There’s clearly business in releasing open source under a strong copyleft license such as GPL, and as long as you keep the copyrights, offer customers to purchase that same code under another more proprietary- friendly license. The code is still open source and anyone doing totally open things can still use it freely and at no cost.
We’ve shipped tiny-curl to the world licensed under GPLv3. Tiny-curl is a curl branch with a strong focus on thetiny part: the idea is to provide a libcurl more suitable for smaller systems, the ones that can’t even run a full Linux but rather use an RTOS.
Consider it a sort of experiment. Are users interested in getting a smaller curl onto their products and are they interested in paying for licensing. So far, tiny-curl supports two separate RTOSes for which we haven’t ported the “normal” curl to.
Keeping things separate
Maybe you don’t realize this, but I work hard to keep separate things compartmentalized. I am not curl, curl is not wolfSSL and wolfSSL is not me. But we all overlap greatly!
The Daniel + curl + wolfSSL trinity
I work for wolfSSL. I work on curl. wolfSSL offers commercial curl support.
Reserved features
One idea that we haven’t explored much yet is the ability to make and offer “reserved features” to paying customers only. This of course as another motivation for companies to become curl support customers.
Such reserved features would still have to be sensible for the curl project and most likely we would provide them as specials for paying customers for a period of time and then merge them into the “real” open source curl project. It is very important to note that this will not in any way make the “regular curl” worse or a lesser citizen in any way. It would rather be a like a separate product, a curl+ with extra stuff on top of vanilla curl.
Since we haven’t ventured into this area yet, we haven’t worked out all the details. Chances are we will wander into this territory soon.
Other food-generators
I do occasional speaking gigs on curl and HTTP related topics but even if I charge for them this activity never brings much more than some extra pocket money. I do it because it’s fun and educational.
It has been suggested that I should create a web shop to sell curl branded merchandise in, like t-shirts, mugs, etc but I think that grossly over-estimates the user interest and how much margin I could put on mundane things just because they’d have a curl logo glued on them. Also, I would have a difficult time mentally to sell curl things and claim the profit personally. I rather keep giving away curl stash (mostly stickers) for free as a means to market the project and long term encourage users into buying support.
Donations
We receive money to the curl project through donations, most of them via our opencollective account. It is important to note that even if I’m a key figure in the project, this is not my money and it’s not my project. Donated money is spent on project related expenses, which so far primarily is our bug bounty program. We’ve avoided to spend donated money on direct curl development, and especially such that I could provide or benefit from myself, as that would totally blur the boundaries. I’m not ruling out taking that route in a future though. As long as and only if it is to the project’s benefit.
Donations via GitHub to me personally sponsors me personally and ends up in my pockets. That’s not curl money but I spend it mostly on curl development, equipment etc and it makes me able to not have to think twice when sending curl stickers to fans and friends all over the world. It contributes to food on my table and I like to think that an occasional beer I drink is sponsored by friends out there!
The future I dream of
We get a steady number of companies paying for support at a level that allows us to also pay for a few more curl engineers than myself.
Here’s the complete timeline of events. From my first denial to travel to the US until I eventually received a tourist visa. And then I can’t go anyway.
December 5-11, 2016
I spent a week on Hawaii with Mozilla – my employer at the time. This was my 12th visit to the US over a period of 19 years. I went there on ESTA, the visa waiver program Swedish citizens can use. I’ve used it many times, there was nothing special this time. The typical procedure with ESTA is that we apply online: fill in a form, pay a 14 USD fee and get a confirmation within a few days that we’re good to go.
I took this photo at the hotel we stayed at during the Mozilla all-hands on Hawaii 2016.
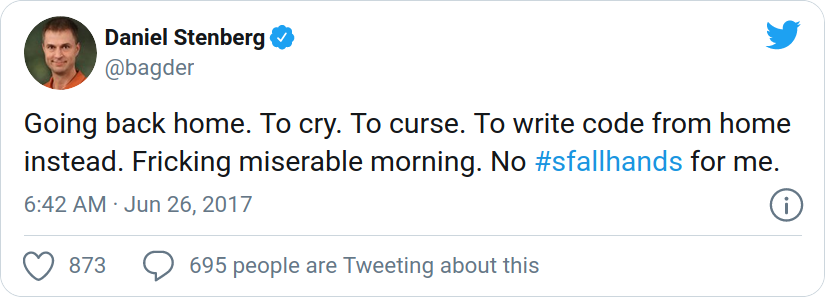
June 26, 2017
In the early morning one day by the check-in counter at Arlanda airport in Sweden, I was refused to board my flight. Completely unexpected and out of the blue! I thought I was going to San Francisco via London with British Airways, but instead I had to turn around and go back home – slightly shocked. According to the lady behind the counter there was “something wrong with my ESTA”. I used the same ESTA and passport as I used just fine back in December 2016. They’re made to last two years and it had not expired.
Tweeted by me, minutes after being stopped at Arlanda.
People engaged by Mozilla to help us out could not figure out or get answers about what the problem was (questions and investigations were attempted both in the US and in Sweden), so we put our hopes on that it was a human mistake somewhere and decided to just try again next time.
April 3, 2018
I missed the following meeting (in December 2017) for other reasons but in the summer of 2018 another Mozilla all-hands meeting was coming up (in Texas, USA this time) so I went ahead and applied for a new ESTA in good time before the event – as I was a bit afraid there was going to be problems. I was right and I got denied ESTA very quickly. “Travel Not Authorized”.
Rejected from the ESTA program.
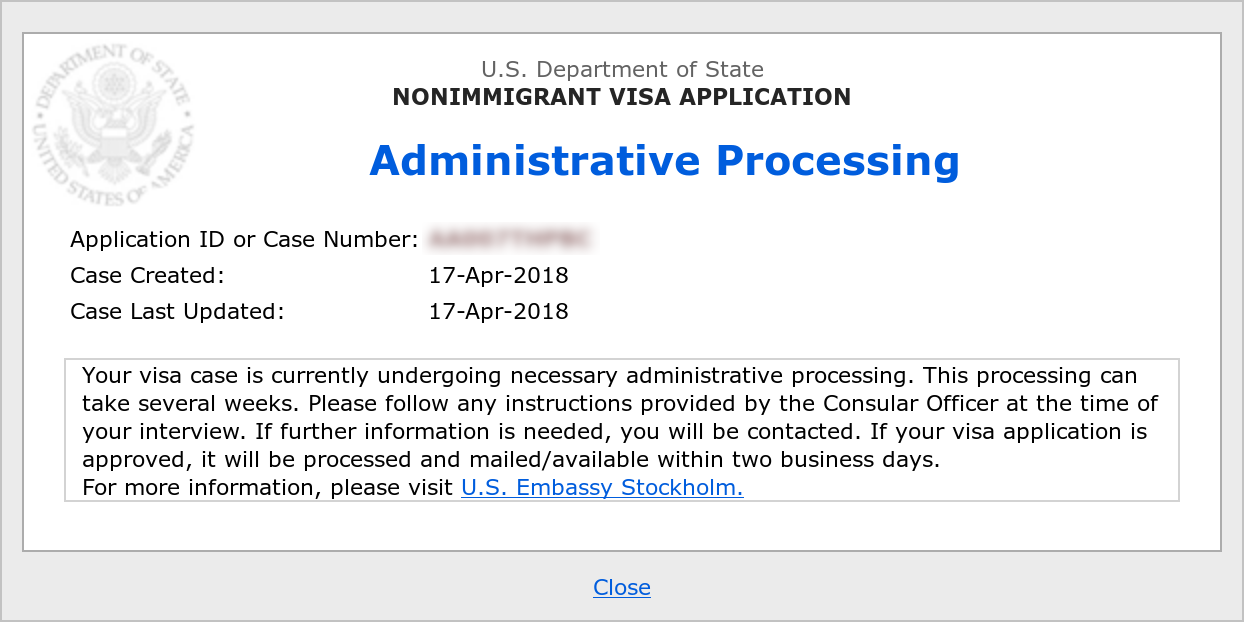
Day 0 – April 17, 2018
Gaaah. It meant it was no mistake last year, they actually mean this. I switched approach and instead applied for a tourist visa. I paid 160 USD, filled in a ridiculous amount of information about me and my past travels over the last 15 years and I visited the US embassy for an in-person interview and fingerprinting.
This is day 0 in the visa process, 296 days after I was first stopped at Arlanda.
Day 90 – July 2018
I missed the all-hands meeting in San Francisco when I didn’t get the visa in time.
Day 240 – December 2018
I quit Mozilla, so I then had no more reasons to go to their company all-hands…
Day 365 – April 2019
A year passed. “someone is working on it” the embassy email person claimed when I asked about progress.
Day 651- January 28, 2020
I emailed the embassy to query about the process
Screenshotted email
The reply came back quickly:
Dear Sir,
All applications are processed in the most expeditious manner possible. While we understand your frustration, we are required to follow immigration law regarding visa issuances. This process cannot be expedited or circumvented. Rest assured that we will contact you as soon as the administrative processing is concluded.
Day 730 – April 2020
Another year had passed and I had given up all hope. Now it turned into a betting game and science project. How long can they actually drag out this process without saying either yes or no?
Day 871 – September 3, 2020
A friend of mine, a US citizen, contacted his Congressman – Gerry Connolly – about my situation and asked for help. His office then subsequently sent a question to the US embassy in Stockholm asking about my case. While the response that arrived on September 17 was rather negative…
your case is currently undergoing necessary administrative processing and regrettably it is not possible to predict when this processing will be completed.
… I think the following turn of events indicates it had an effect. It unclogged something.
Day 889 – September 22, 2020
After 889 days since my interview on the embassy (only five days after the answer to the congressman), the embassy contacted me over email. For the first time since that April day in 2018.
Your visa application is still in administrative processing. However, we regret to inform you that because you have missed your travel plans, we will require updated travel plans from you.
My travel plans – that had been out of date for the last 800 days or so – suddenly needed to be updated! As I was already so long into this process and since I feared that giving up now would force me back to square one if I would stop now and re-attempt this again at a later time, I decided to arrange myself some updated travel plans. After all, I work for an American company and I have a friend or two there.
Day 900 – October 2, 2020
I replied to the call for travel plan details with an official invitation letter attached, inviting me to go visit my colleagues at wolfSSL signed by our CEO, Larry. I really want to do this at some point, as I’ve never met most of them so it wasn’t a made up reason. I could possibly even get some other friends to invite me to get the process going but I figured this invite should be enough to keep the ball rolling.
Day 910 – October 13, 2020
I got another email. Now at 910 days since the interview. The embassy asked for my passport “for further processing”.
Day 913 – October 16, 2020
I posted my passport to the US embassy in Stockholm. I also ordered and paid for “return postage” as instructed so that they would ship it back to me in a safe way.
Day 934 – November 6, 2020
At 10:30 in the morning my phone lit up and showed me a text telling me that there’s an incoming parcel being delivered to me, shipped from “the Embassy of the United State” (bonus points for the typo).
Day 937 – November 9, 2020
I received my passport. Inside, there’s a US visa that is valid for ten years, until November 2030.
The upper left corner of the visa page in my passport…
As a bonus, the visa also comes with a NIE (National Interest Exception) that allows me a single entry to the US during the PP (Presidential Proclamations) – which is restricting travels to the US from the European Schengen zone. In other words: I am actually allowed to travel right away!
The timing is fascinating. The last time I was in the US, Trump hadn’t taken office yet and I get the approved visa in my hands just days after Biden has been announced as the next president of the US.
Will I travel?
Covid-19 is still over us and there’s no end in sight of the pandemic. I will of course not travel to the US or any other country until it can be deemed safe and sensible.
When the pandemic is under control and traveling becomes viable, I am sure there will be opportunities. Hopefully the situation will improve before the visa expires.
Thanks to
All my family and friends, in the US and elsewhere who have supported me and cheered me up through this entire process. Thanks for keeping inviting me to fun things in the US even though I’ve not been able to participate. Thanks for pushing for events to get organized outside of the US! I’m sorry I’ve missed social gatherings, a friend’s marriage and several conference speaking opportunities. Thanks for all the moral support throughout this long journey of madness.
A special thanks go to David (you know who you are) for contacting Gerry Connolly’s office. I honestly think this was the key event that finally made things move in this process.
I started learning how to program in my teens, well over thirty years ago and I’ve worked as a software engineer and developer since the early 1990s. My first employment as a developer was in 1993. I’ve since worked for and with lots of companies and I’ve worked on a huge amount of (proprietary) software products and devices over many years. Meaning: I certainly didn’t start my life open source. I had to earn it.
When I was 20 years old I did my (then mandatory) military service in Sweden. After having endured that, I applied to the university while at the same time I was offered a job at IBM. I hesitated, but took the job. I figured I could always go to university later – but life took other turns and I never did. I didn’t do a single day of university. I haven’t regretted it.
I learned to code in the mid 80s on a Commodore 64 and software development has been one of my primary hobbies ever since. One thing it taught me well, that I still carry with me, is to spend a few hours per day in front of my home computer.
And then I shipped curl
In the spring of 1998 I renamed my little pet project of the time again and I released the first ever curl release. I have told this story many times, but since then I have spent two hours or so of my spare time on that project – every day for over twenty years. While still working as a software engineer by day.
Over time, curl gradually grew popular and attracted more users. There was no sudden moment in time where I struck gold and everything took off. It was just slowly gaining ground while me and my fellow project members kept improving and polishing curl. At some point in time I happened to notice that curl and libcurl would appear in more and more acknowledgements and in open source license collections in products and devices.
It was still just a spare time project.
Proprietary Software for years
I’d like to emphasize that I worked as a contract and consultant developer for many years (over 20!), primarily on proprietary software and custom solutions, before I managed to land myself a position where I could primarily write open source as part of my job.
Mozilla
In 2014 I joined Mozilla and got the opportunity to work on the open source project Firefox for a living – and doing it entirely from my home. This was the first time in my career I actually spent most of my days on code that was made public and available to the world. They even allowed me to spend a part of my work hours on curl, even if that didn’t really help them and curl was not a fundamental part of any Mozilla work or products. It was still great.
I landed that job for Mozilla a lot thanks to my many years and long experience with portable network coding and running a successful open source project at this level.
My work setup with Mozilla made it possible for me to spend even more time on curl, apart from the (still going) two daily spare time hours. Nobody at Mozilla cared much about (my work with) curl and no one there even asked me about it. I worked on Firefox for a living.
For anyone wanting to do open source as part of their work, getting a job at a company that already does a lot of open source is probably the best path forward. Even if that might not be easy either, and it might also mean that you would have to accept working on some open source projects that you might not yourself be completely sold on.
In late 2018 I quit Mozilla, in part because I wanted to try to work with curl “for real” (and part other reasons that I’ll leave out here). curl was then already over twenty years old and was used more than ever before.
wolfSSL
I now work for wolfSSL. We sell curl support and related services to companies. Companies pay wolfSSL, wolfSSL pays me a salary and I get food on the table. This works as long as we can convince enough companies that this is a good idea.
The vast majority of curl users out there of course don’t pay anything and will never pay anything. We just need a small number of companies to do it – and it seems to be working. We help customers use curl better, we make curl better for them and we make them ship better products this way. It’s a win win. And I can work on open source all day long thanks to this.
My open source life-style
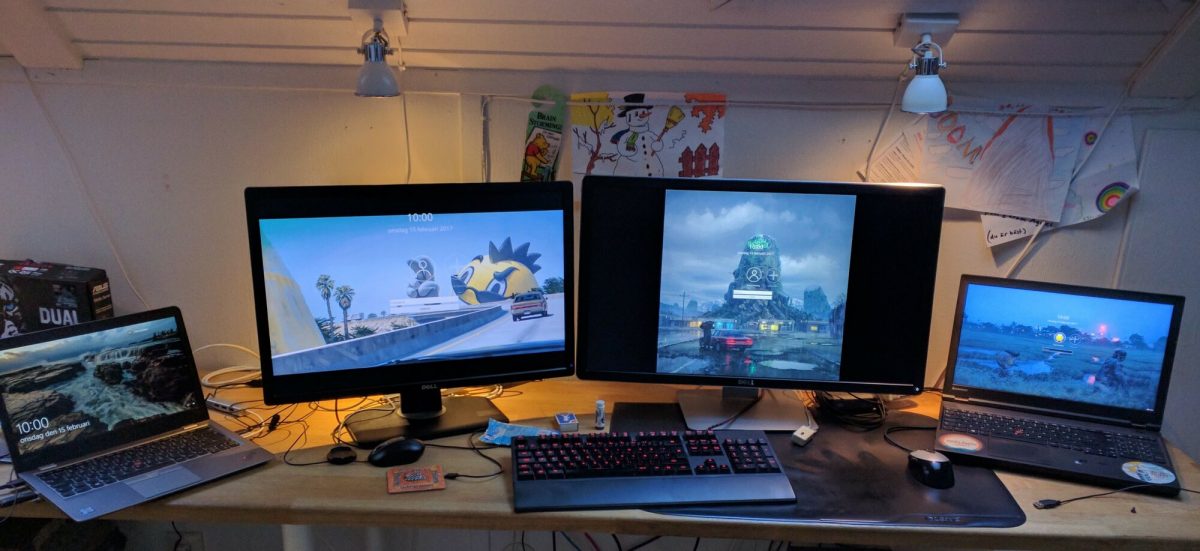
A normal day in the work week, I get up before 7 in the morning and I have breakfast with my family members: my wife and my two kids. Then I grab my first cup of coffee for the day and take the thirteen steps up the stairs to my “office”.
I sit down in front of my main development (Linux) machine with two 27″ screens and get to work.
Photo of my work desk from a few years ago but it looks very similar still today.
What work and in what order?
I lead the curl project. It means many questions and decisions fall down to me to have an opinion about or say on, and it’s a priority for me to make sure that I unblock such situations as soon as possible so that developers wanting to do things with curl can continue doing that.
Thus, I read and respond to email about curl all hours I’m awake and have network access. Of course incoming messages actually rarely require immediate responses and then I can queue them up and instead do them later. I also try to read and assess all new incoming curl issues as soon as possible to see if there’s something urgent I should deal with immediately, or otherwise figure out how to deal with them going forward.
I usually have a set of bugs or features to work on so when there’s no alarming email or GitHub issue left, I context-switch over to the curl source code tree and the particular branch in which I work on right now. I typically have 20-30 different branches of development of various stages and maturity going on. If I get stuck on something, or if I create a pull-request for one of them that needs time to get all the CI jobs done, I switch over to one of the others.
Customers and their needs of course have priority when I decide what to work on. The exception would perhaps be security vulnerabilities or other really serious bugs being reported, but thankfully they are rare. But after that, I go by ear and work on what I think is fun and what I think users might appreciate.
If I want to go forward with something, for my own sake or for a customer’s, and that entails touching or improving other software in other projects, then I don’t shy away from submitting pull requests for them – or at least filing an issue.
Spare time open source
Yes, I still spend my spare time hours on open source, mostly curl. This means I often end up spending 50-55 hours per week on curl and curl related activities. But I don’t count or measure work hours and I rarely have to report any to anyone. This is a work of love.
Lots of people will say that they don’t have time because of life, family, kids etc. I have of course been very fortunate over the years to have had the opportunity and ability to spend all this time on what I want to do, but let’s not forget that people in general spend lots of time on their hobbies; on watching TV, on playing computer games and on socializing with friends and why not: to sleep. If you cut down on all of those things (yes, including the sleeping) there could very well be opportunities. It’s often a question of priorities. I’ve made spare time development a priority in my life.
curl support?
Any company that uses curl or libcurl – and they are plenty – could benefit from buying support from us instead of wasting their own time and resources. We at wolfSSL are probably much better at curl already and we can find and fix the issues much faster, which ends up cheaper and better long-term.
Credits
The top photo is taken by Anja Stenberg, my wife. It’s me in a local forest, summer 2020.