Abstract: curl runs in some ten billion installations in the world, in virtually every connected device on the planet and ported to more operating systems than most. In this presentation, curl’s lead developer Daniel Stenberg talks about how the curl project takes on testing, QA, CI and fuzzing etc, to make sure curl remains a stable and secure component for everyone while still getting new features and getting developed further. With a Q&A session at the end for your questions!
Register here at attend the live event. The video will be made available afterward.
We have started the work on extending wolfSSL to provide the necessary API calls to power QUIC and HTTP/3 implementations!
Small, fast and FIPS
The TLS library known as wolfSSL is already very often a top choice when users are looking for a small and yet very fast TLS stack that supports all the latest protocol features; including TLS 1.3 support – open source with commercial support available.
As manufacturers of IoT devices and other systems with memory, CPU and footprint constraints are looking forward to following the Internet development and switching over to upcoming QUIC and HTTP/3 protocols, wolfSSL is here to help users take that step.
A QUIC reminder
In case you have forgot, here’s a schematic view of HTTPS stacks, old vs new. On the right side you can see HTTP/3, QUIC and the little TLS 1.3 box there within QUIC.
ngtcp2
There are no plans to write a full QUIC stack. There are already plenty of those. We’re talking about adjustments and extensions of the existing TLS library API set to make sure wolfSSL can be used as the TLS component in a QUIC stack.
One of the leading QUIC stacks and so far the only one I know of that does this, ngtcp2 is written to be TLS library agnostic and allows different TLS libraries to be plugged in as different backends. I believe it makes perfect sense to make such a plugin for wolfSSL to be a sensible step as soon as there’s code to try out.
A neat effect of that, would be that once wolfSSL works as a backend to ngtcp2, it should be possible to do full-fledged HTTP/3 transfers using curl powered by ngtcp2+wolfSSL. Contact us with other ideas for QUIC stacks you would like us to test wolfSSL with!
FIPS 140-2
We expect wolfSSL to be the first FIPS-based implementation to add support for QUIC. I hear this is valuable to a number of users.
When
This work begins now and this is just a blog post of our intentions. We and I will of course love to get your feedback on this and whatever else that is related. We’re also interested to get in touch with people and companies who want to be early testers of our implementation. You know where to find us!
I can promise you that the more interest we can sense to exist for this effort, the sooner we will see the first code to test out.
It seems likely that we’re not going to support any older TLS drafts for QUIC than draft-29.
As so many other events in these mysterious times, the foss-north conference went online-only and on March 30, 2020 I was honored to be included among the champion speakers at this lovely conference and I talked about how to “curl better” there.
The talk is a condensed run-through of how curl works and why, and then a look into how some of the more important HTTP oriented command line options work and how they’re supposed to be used.
As someone pointed out: I don’t do a lot of presentations about the curl tool. Maybe I should do more of these.
curl is widely used but still most users only use a very small subset of options or even just copy their command line from somewhere else. I think more users could learn to curl better. Below is the video of this talk.
Doing a talk to a potentially large audience in front of your laptop in completely silence and not seeing a single audience member is a challenge. No “contact” with the audience and no feel for if they’re all going to sleep or seem interested etc. Still I have the feeling that this is the year we all are going to do this many times and hopefully get better at it over time…
tldr: join in and watch/discuss the curl 2020 roadmap live on Thursday March 26, 2020. Sign up here.
The roadmap is basically a list of things that we at wolfSSL want to work on for curl to see happen this year – and some that we want to mention as possibilities.(Yes, the word “webinar” is used, don’t let it scare you!)
If you can’t join live, you will be able to enjoy a recorded version after the fact.
I shown the image below in curl presentation many times to illustrate the curl roadmap ahead:
The point being that we as a project don’t really have a set future but we know that more things will be added and fixed over time.
Daniel, wolfSSL and curl
This is a balancing act where there I have several different “hats”.
I’m the individual who works for wolfSSL. In this case I’m looking at things we at wolfSSL want to work on for curl – it may not be what other members of the team will work on. (But still things we agree are good and fit for the project.)
We in wolfSSL cannot control or decide what the other curl project members will work on as they are volunteers or employees working for other companies with other short and long term goals for their participation in the curl project.
We also want to try to communicate a few of the bigger picture things for curl that we want to see done, so that others can join in and contribute their ideas and opinions about these features, perhaps even add your preferred subjects to the list – or step up and buy commercial curl support from us and get a direct-channel to us and the ability to directly affect what I will work on next.
As a lead developer of curl, I will of course never merge anything into curl that I don’t think benefits or advances the project. Commercial interests don’t change that.
Webinar
Sign up here. The scheduled time has been picked to allow for participants from both North America and Europe. Unfortunately, this makes it hard for all friends not present on these continents. If you really want to join but can’t due to time zone issues, please contact me and let us see what we can do!
I’m going to FOSDEM again in 2020, this will be my 11th consecutive year I’m travling to this awesome conference in Brussels, Belgium.
At this my 11th FOSDEM visit I will also deliver my 11th FOSDEM talk: “HTTP/3 for everyone“. It will happen at 16:00 Saturday the 1st of February 2020, in Janson, the largest room on the campus. (My third talk in the main track.)
For those who have seen me talk about HTTP/3 before, this talk will certainly have overlaps but I’m also always refreshing and improving slides and I update them as the process moves on, things changes and I get feedback. I spoke about HTTP/3 already at FODEM 2019 in the Mozilla devroom (at which time there was a looong line of people who tried, but couldn’t get a seat in the room) – but I think you’ll find that there’s enough changes and improvements in this talk to keep you entertained this year as well!
If you come to FOSDEM, don’t hesitate to come say hi and grab a curl sticker or two – I intend to bring and distribute plenty – and talk curl, HTTP and Internet transfers with me!
You will most likely find me at my talk, in the cafeteria area or at the wolfSSL stall. (DM me on twitter to pin me down! @bagder)
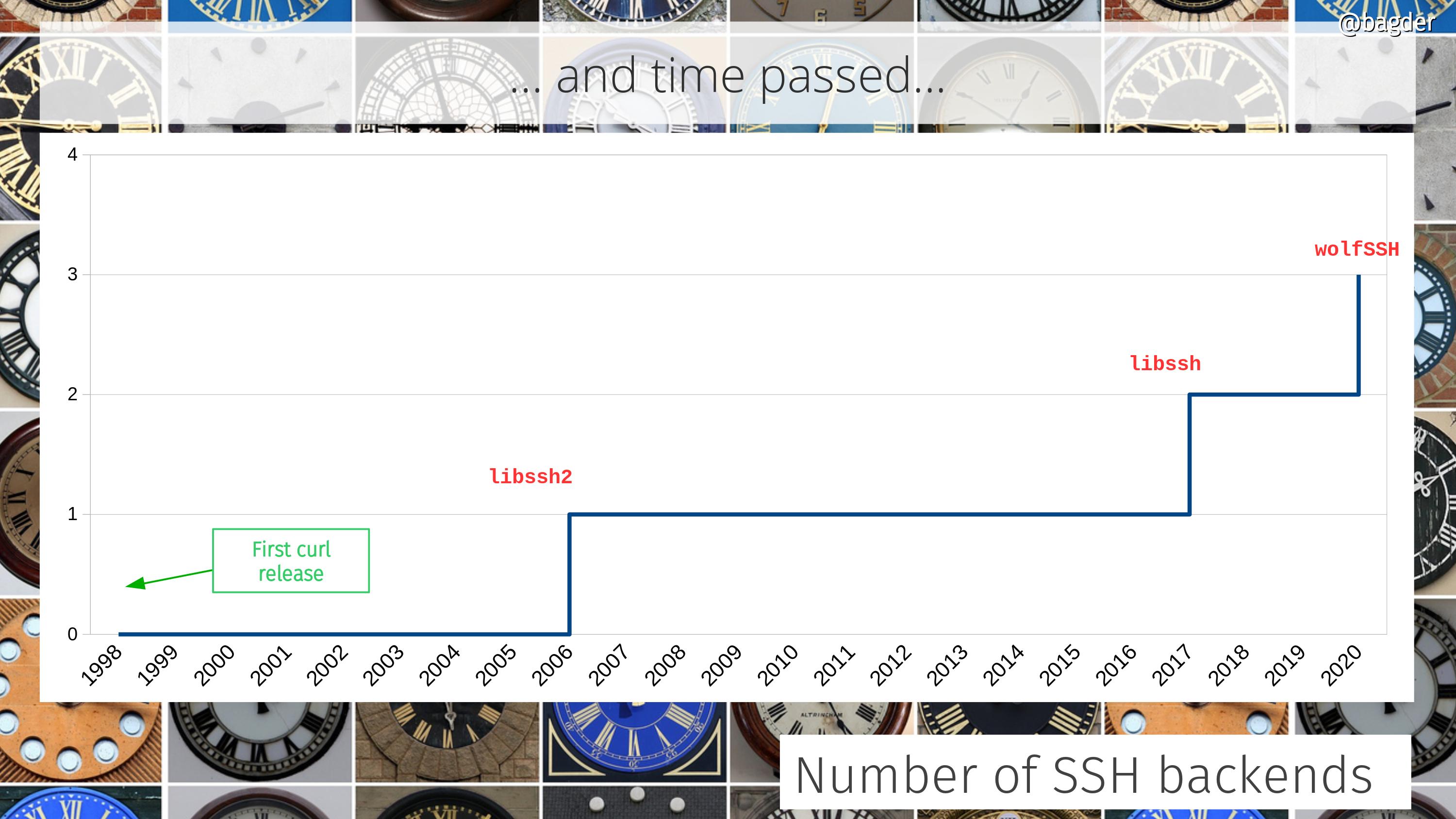
I’m happy to announce that curl now supports a third SSH library option: wolfSSH. Using this, you can build curl and libcurl to do SFTP transfers in a really small footprint that’s perfectly suitable for embedded systems and others. This goes excellent together with the tiny-curl effort.
SFTP only
The initial merge of this functionality only provides SFTP ability and not SCP. There’s really no deeper thoughts behind this other than that the work has been staged and the code is smaller for SFTP-only and it might be that users on these smaller devices are happy with SFTP-only.
Work on adding SCP support for the wolfSSH backend can be done at a later time if we feel the need. Let me know if you’re one such user!
Build time selection
You select which SSH backend to use at build time. When you invoke the configure script, you decide if wolfSSH, libssh2 or libssh is the correct choice for you (and you need to have the correct dev version of the desired library installed).
The initial SFTP and SCP support was added to curl in November 2006, powered by libssh2 (the first release to ship it was 7.16.1). Support for getting those protocols handled by libssh instead (which is a separate library, they’re just named very similarly) was merged in October 2017.
Number of supported SSH backends over time in the curl project.
WolfSSH uses WolfSSL functions
If you decide to use the wolfSSH backend for SFTP, it is also possibly a good idea to go with WolfSSL for the TLS backend to power HTTPS and others.
A plethora of third party libs
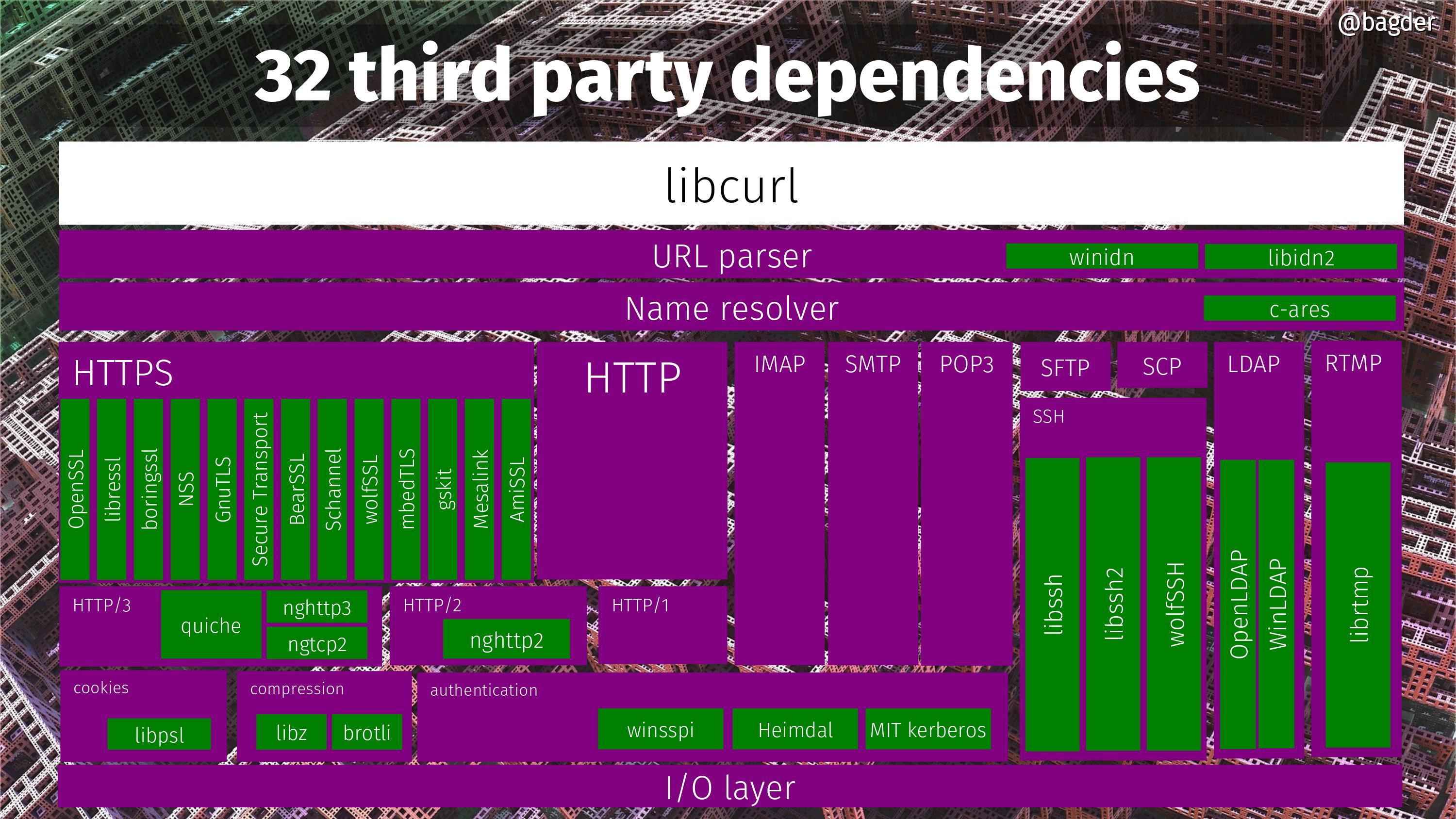
WolfSSH becomes the 32nd third party component that curl can currently be built to use. See the slide below and click on it to get the full resolution version.
32 possible third party dependencies curl can be built to use
Credits
I, Daniel, wrote the initial new wolfSSH backend code. Merged in this commit.
I’m please to invite you to our live webinar, “Why everyone is using curl and you should too!”, hosted by wolfSSL. Daniel Stenberg (me!), founder and Chief Architect of curl, will be live and talking about why everyone is using curl and you should too!
This is planned to last roughly 20-30 minutes with a following 10 minutes Q&A.
Space is limited so please register early!
When: Jan 14, 2020 08:00 AM Pacific Time (US and Canada) (16:00 UTC)
Register in advance for this webinar!
After registering, you will receive a confirmation email containing information about joining the webinar.
Not able to attend? Register now and after the event you will receive an email with link to the recorded presentation.
2019 is special in my heart. 2019 was different than many other years to me in several ways. It was a great year! This is what 2019 was to me.
curl and wolfSSL
I quit Mozilla last year and in the beginning of the year I could announce that I joined wolfSSL. For the first time in my life I could actually work with curl on my day job. As the project turned 21 I had spent somewhere in the neighborhood of 15,000 unpaid spare time hours on it and now I could finally do it “for real”. It’s huge.
Just in November 2018 the name HTTP/3 was set and this year has been all about getting it ready. I was proud to land and promote HTTP/3 in curl just before the first browser (Chrome) announced their support. The standard is still in progress and we hope to see it ship not too long into next year.
curl
Focusing on curl full time allows a different kind of focus. I’ve landed more commits in curl during 2019 than any other year going back all the way to 2005. We also reached 25,000 commits and 3,000 forks on github.
We’ve added HTTP/3, alt-svc, parallel transfers in the curl tool, tiny-curl, fixed hundreds of bugs and much, much more. Ten days before the end of the year, I’ve authored 57% (over 700) of all the commits done in curl during 2019.
We also (re)started our own curl Bug Bounty in 2019 together with Hackerone and paid over 1000 USD in rewards through-out the year. It was so successful we’re determined to raise the amounts significantly going into 2020.
Public speaking
I’ve done 28 talks in six countries. A crazy amount in front of a lot of people.
When Github had their Github Universe event in November and talked about their new sponsors program on stage (which I am part of, you can sponsor me) this huge quote of mine was shown on the big screen.
Maybe not media, but in no less than two Mr Robot episodes we could see curl commands in a TV show!
$ cd $HOME/src
$ unzip wolfssl-4.1.0-gplv3-fips-ready.zip
$ cd wolfssl-4.1.0-gplv3-fips-ready
Build the fips-ready wolfSSL and install it somewhere suitable
$ ./configure --prefix=$HOME/wolfssl-fips --enable-harden --enable-all
$ make -sj
$ make install
Download curl, the normal curl package. (in my case I got curl 7.65.3)
Unzip the source code somewhere suitable
$ cd $HOME/src
$ unzip curl-7.65.3.zip
$ cd curl-7.65.3
Build curl with the just recently built and installed fips ready wolfSSL version.
$ LD_LIBRARY_PATH=$HOME/wolfssl-fips/lib ./configure --with-wolfssl=$HOME/wolfssl-fips --without-ssl
$ make -sj
Now, verify that your new build matches your expectations by:
$ ./src/curl -V
It should show that it uses wolfSSL and that all the protocols and features you want are enabled and present. If not, iterate until it does!
“FIPS Ready means that you have included the FIPS code into your build and that you are operating according to the FIPS enforced best practices of default entry point, and Power On Self Test (POST).”