A few weeks ago I mentioned how we fund Stefan’s work on improving HTTP(/3) in curl. Now, in similar spirit we are funding Dan Fandrich to work on further improving test infrastructure. Dan has worked fiercely on the introduction of parallel tests over the recent year or so and this is work that builds on that and continues down that road.
curl contains a regression test suite of over 1900 individual test cases that are run automatically on every commit submission and on every pull request in almost 130 different environments., meaning that every change can result in more than 140,000 tests being run. A spurious test failure rate of a mere 0.001% is likely to cause a perfectly good PR to end up showing with a red failure. A new contributor that doesn’t understand this problem can spend hours poring over his or her patch and the related code in curl, searching for a problem that isn’t there.
Analyzing 140,000 tests for each change to the curl source code to find failure trends (such as flaky tests) demands an automated solution. Dan has created a system (working name Test Clutch) that has been successfully ingesting curl CI test results for much of the past year and has been used by him to find flaky tests as well as permanently failing tests (often submitted under the mistaken impression that the failed test was merely flaky). It collects individual test results from all the CI systems used in the curl project into a database where they can be analyzed.
This system has potential to be useful to a broader base of curl developers to help see test trends, test platform coverage and to better determine which tests are flaky and could use improvement. It has been written in a fashion such that test results for other projects besides curl can also be added and analyzed separately.
Work Projects
Make Test Clutch available
The current test ingestion and analysis system will be productionized and the analysis summary table will be integrated into the curl web site for easy access for developers.
Assist in PR work
This task will involve writing code to trigger the test analysis system to retrieve detailed PR test results when available. It must make a reasonable determination of when all the expected tests have been completed (since not all tests will run for every PR) then commenting on the PR with a summary of the test results and believability of any test failures.
When
These are project that will benefit the project when implemented but they are not time sensitive and Dan is not going to work full time on them. There are no exact end dates set for them.
The result of Dan’s work will become visible in PRs and website updates as we go forward.
The curl test suite was born in November 2000. We wrote our own custom system, dedicated for us.
In May 2001 we changed the file format for individual tests and this is still today the format we use. During the Twenty-two years that have passed we have added some 1600 test cases to the collection and we make sure that they can run on virtually any platform and that each test case themselves specify what curl features they require to work so that builds with those features disabled can skip those tests.
Only a thorough test suite provides the necessary confidence you need to promise to users that we keep existing behaviors and yet we still can and do repeatedly rewrite, refactor and replace large chunks of the internals.
Synchronous in a single thread
In 2000 we all had single cores and single CPUs. We made the test suite run the tests one by one, in a serial fashion. Some are quick, some take a little longer. While CPUs certainly have grown significantly faster over the lifetime of curl, the amount of test cases have also grown.
Today, on my fast modern machine, running all test cases in the main test suite takes about 10 minutes. If we run them with valgrind enabled (it then invokes all curl related commands and functions with the valgrind tool to monitor that it doesn’t do any serious memory violations or leaks), the same process takes close to 30 minutes.
This might not sound terribly bad, but it also not unusual to run the tests on slower machines that spend two or maybe even five times longer to completion. If you want to run the tests on a few different build combinations to make sure they are all happy, you may need to rerun the set a number of times. It all adds up.
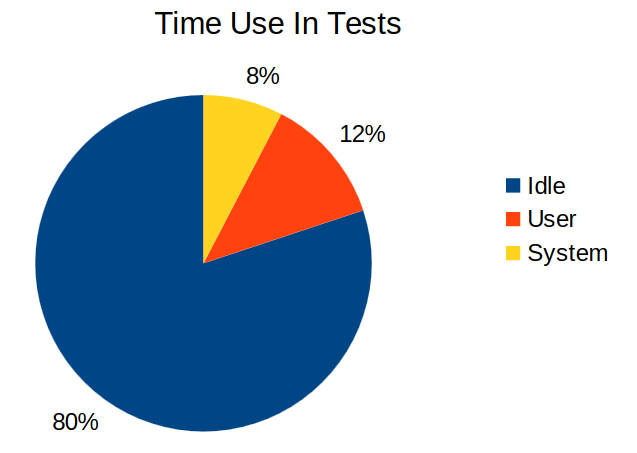
This is a rather ineffective use of time and available system resources. In researching and measuring the current state of curl testing, Dan Fandrich figured out that in a normal test round the CPU is idle 80% of the time! And that’s just one core.
Illustration from Dan’s “curl Parallel Testing Proposal”
Going parallel
In March 2023, Dan brought his curl Parallel Testing proposal (11 page PDF) to us, outlining an idea on how to convert the current single-threaded serial test runner into one that runs many separate worker processes and can run several test cases in parallel.
The general idea being that even on a single-core machine, running tests in parallel has the chance to speed up the process a lot. Because of that 80% number if nothing else.
Most (curl) developers of course also have machine with several or even many cores, making parallelism an even better idea.
We all loved the idea, gave Dan our thumbs up and arranged to fund his work on this improvement.
Port numbers
curl does Internet transfers, and for testing curl we have a set of test servers implemented that curl can talk to and get response back from. The specific tests control exactly how these servers respond and act for each test. To make sure that curl speaks the protocols correctly and consistently in both good and bad situations.
A challenge with this is that the test suite actually has to fire up and run actual networking servers on the local machine for this purpose. Each such server has to listen to a dedicated TCP or UDP port for as long as the tests are still going.
Luckily, we reworked the port number use for test servers recently. Using fixed port numbers for test servers was problematic already with single threaded tests because you could not run a separate test case in a different shell on the same machine etc. They would also sometimes collide with other random services running on developers’ machines.
Since August 2020 all test servers listen on random port numbers. A fundamental criteria for being able to run tests in parallel.
Landed
After a lot of hard work to refactor the test internals, it can now fire up N worker processes, where each such process can run its own set of test servers, then make sure the main scheduler hands out test cases to all of the workers and collects and outputs the test results from all of them. On June 5, Dan merged the commits to master that made it possible for all of us to start test (!) driving this.
First impressions
Dan recommends maybe 7 workers per core, but it might be a little bit limited to how much system memory you have since every such worker might end up running a fairly large amount of test servers. It also depends on if you run the tests with or without valgrind.
I ran a first simple test shot on my machine using 80 workers. A full valgrind enabled round with 1606 tests completed in 87 seconds. That is more than twenty times faster than previously.
Some further polish needed
There are still some issues left that make the parallel test setup a little shakier than the normal serial style, so we do not yet enable this by default for people. We will work on fixing those issues and iron out the last wrinkles so that we can soon get everyone onboard on this.
Every once in a while someone brings up the topic of code coverage in relation to curl. What portion of the code is actually exercised when running the tests?
Honestly, we don’t know. We can’t figure it out. We are not trying to figure it out. We have to live with this.
We used to get a number
A few years back we actually did a build and a test run in our CI setup that used one of those cloud services that would monitor the code coverage and warn if we would commit something that drastically reduced coverage.
This had significant drawbacks:
First, the service was unstable which made it occasionally sound the horns because we had gone down to 0% coverage and that is bad.
Secondly, it made parts of the audience actually believe that what was reported by that service for a single build and a single test run was the final and accurate code coverage number. It was far from it.
We ended up ditching that job as it did very little good but some amount of harm.
Different build combinations – and platforms
Code coverage is typically the number of lines of code that were executed as a share out of the total amount of possible lines (lines that were compiled and used in the build, not lines of code that were not included in the complete source). Since curl offers literally many million build combinations, an evaluated code coverage number can only apply to that specific build combination. When using that exact setup and running a particular set of tests on a fixed platform.
Just getting the coverage rate off one of these builds is easy enough but is hardly representing the true number as we run tests on many build combinations doing many different tests.
Can’t do it all in a single test run
We run many different tests and some of the tests we limit and split up into several different specific CI jobs since they are very slow and by doing a smaller portion of the jobs in separate CI jobs, we allow them to run in parallel and thus complete faster. That is super complicated from a code coverage point of view as we would have to merge coverage data between numerous independent and isolated build runs, possibly running on different services, to get a number approaching the truth.
We don’t even try to do this.
Not the panacea
Eventually, even if we would be able to get a unified number from a hundred different builds and test runs spread over many platforms, what would it tell us?
libcurl has literally over 300 run-time options that can be used in combinations. Running through the code with a few different option combinations could theoretically reach almost complete code coverage and yet only test a fraction of the possibilities.
But yes: it would help us identify source code lines that are never executed when the tests run and it would be very useful.
Instead
We rely on manual (and more error-prone) methods of identifying what parts of the code we need to add more tests for. This is hard, and generally the best way to find weak spots is when someone reports a bug or a regression as that usually means that there was a lack of tests for that area that allowed the problem to sneak in undetected.
Of course we also need to make sure that all new features and functions get test cases added in parallel.
This is a rather weak system but we have not managed to make a better one yet.
A little over a year ago, we ditched Travis CI as a service to use for the curl project.
Up until that day, it had been our preferred and favored CI service for many years. At most, we ran 34 CI jobs on it, for every pull-request and commit. It was the service that we leaned on when we transitioned the curl project into a CI-heavy user. Our use of CI really took off 2017 and has been increasing ever since.
A clean cut
We abruptly cut off over 30 jobs from the service just one day. At the time, that was a third of all our CI. The CI jobs that we rely on to verify our work and to keep things working and stable in the project.
More CI services
At the time of the amputation, we run 99 CI jobs distributed over 5 services, so even with one of them cut off we still ran jobs on AppVeyor, Azure Pipelines, GitHub Actions and Cirrus CI. We were not completely stranded.
New friends
Luckily for us, when one solution goes sour there are often alternatives out there that we can move over to and continue our never-ending path forward.
In our case, friendly people helped moving over almost all ex-Travis jobs to the (for us) new service Zuul CI. In July 2021, we had 29 jobs on it. We also added Circle CI to the mix and started running jobs there.
In July 2021 – a month after the cut – we counted 96 running jobs (a few old jobs were just dropped as we reconsidered their value). While the work involved a lot of adjusting scripts, pulling hair over yaml files and more, it did not cause any significant service loss over an extended period. We managed pretty good.
There was no noticeable glitch in quality or backed up “guilt” in the project because of the transition and small period of lesser CI either. Thanks to the other services still running, we were still in a good shape.
Why all the services
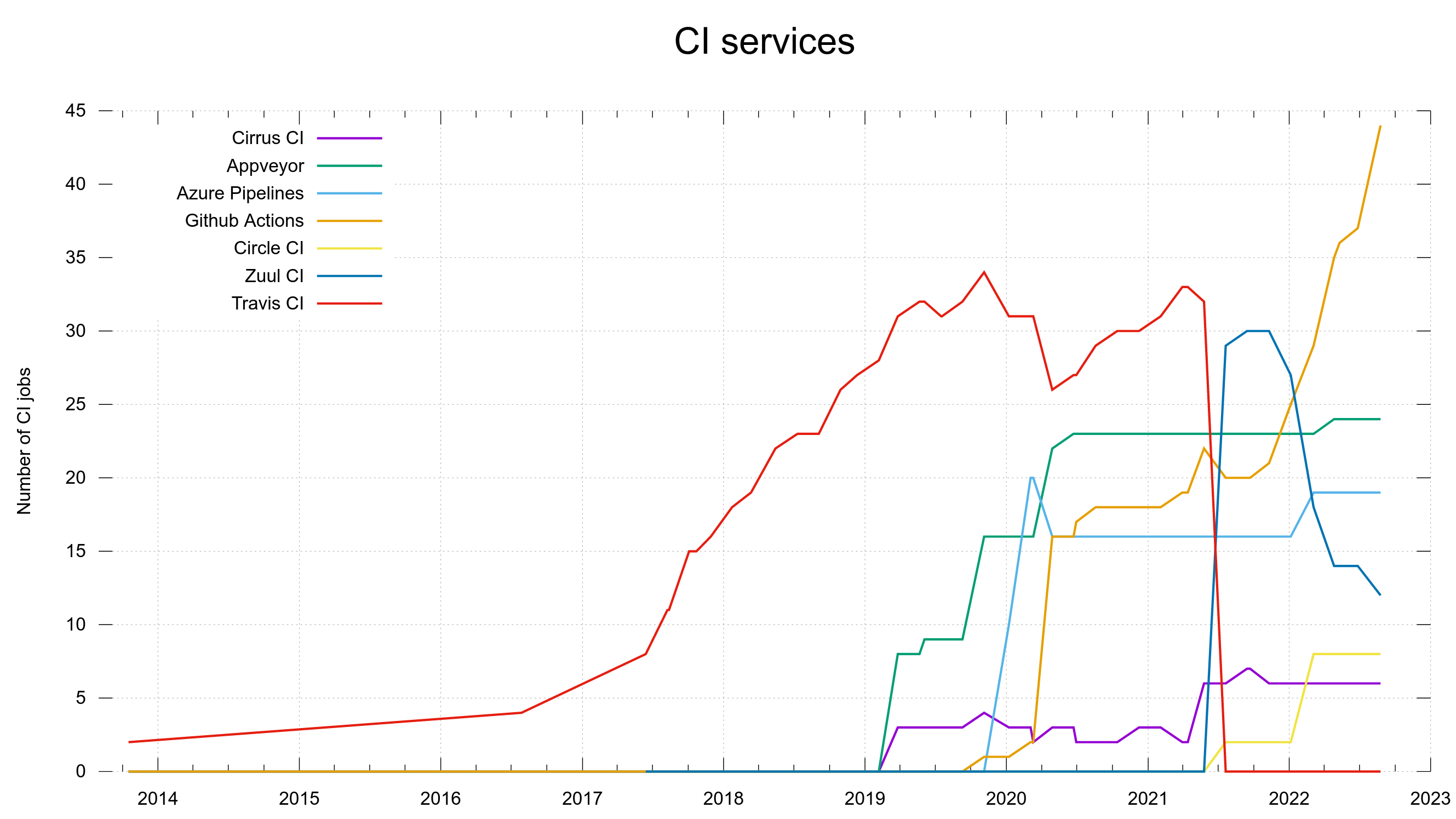
In the end of August 2022 we still use 6 different CI services and we now run 113 CI jobs on them, for every push to master and to pull-requests.
There are primarily three reasons why we still use a variety of services.
load balancing: we get more parallelism by running jobs on many services as they all have a limited parallelism per service.
We also get less problems when one of the services has some glitch or downtime, as then we still work with the others. The not all eggs in the same basket thing.
The various services also have different features, offer different platforms and work slightly differently which for several jobs make them necessary to run on a specific service, or rather they cannot run on most of the other services.
It does not end
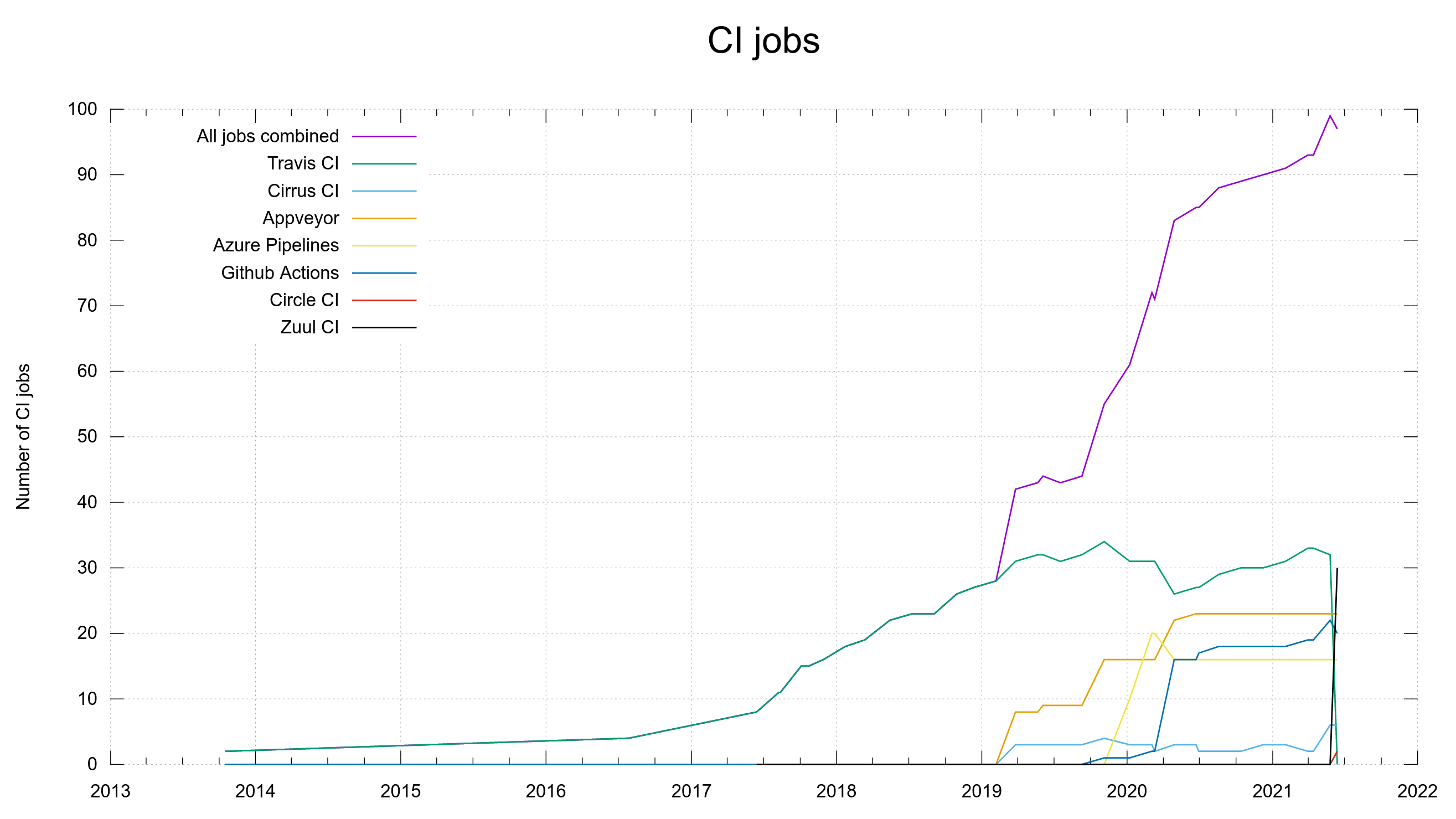
Over the year since the amputation, we have learned that our new friend Zuul CI has turned out to not work quite as reliable and convenient as we would like it. Since a few months back, we are now gradually moving away from this service. Slowly moving over jobs from there to run on one the other five instead.
Over time, our new most preferred CI service has turned out to be GitHub Actions. At the latest count, it now run 44 CI jobs for us. We still have 12 jobs on Zuul targeted for transition.
Our use of different CI services over time in the curl project
Services come and go. We have different ideas and our requirements and ambitions change. I am sure we will continue to service-jump when needed. It is just a natural development. A part of a software development life.
On flakiness
A big challenge and hurdle with our CI setup remains: to maintain the builds and keep them stable and functioning. With over a hundred jobs running on six services and our code and test suite being portable and things being networked and running on many platforms, it is job that we quite often fail at. It has turned out mighty difficult to avoid that at least a few of the jobs are constantly red, “permafailing”, at any single moment.
If this is stuff you like to tinker with, we could use your help!
I’ve talked on this topic before but I realized I never did a proper blog post on the topic. So here it is: how we develop curl to keep it safe. The topic of supply chain security is one that is discussed frequently these days and every so often there’s a very well used (open source) component that gets a terrible weakness revealed.
Don’t get me wrong. Proprietary packages have their share of issues as well, and probably even more so, but for obvious reasons we never get the same transparency, details and insight into those problems and solutions.
If we would find a critical vulnerability in curl, it could potentially exist in every internet-connected device on the globe. We don’t want that.
A critical security flaw in our products would be bad, but we also similarly need to make sure that we provide APIs and help users of our products to be safe and to use curl safely. To make sure users of libcurl don’t accidentally end up getting security problems, to the best of our ability.
In the curl project, we work hard to never have our own version of a “heartbleed moment“. How do we do this?
Always improving
Our method is not strange, weird or innovative. We simply apply all best practices, tools and methods that are available to us. In all areas. As we go along, we tighten the screws and improve our procedures, learning from past mistakes.
There are no short cuts or silver bullets. Just hard work and running tools.
Not a coincidence
Getting safe and secure code into your product is not something that happens by chance. We need to work on it and we need to make a concerned effort. We must care about it.
We all know this and we all know how to do it, we just need to make sure that we also actually do it.
The steps
Write code following the rules
Review written code and make sure it is clear and easy to read.
Test the code. Before and after merge
Verify the products and APIs to find cracks
Bug-bounty to reward outside helpers
Act on mistakes – because they will happen
Writing
For users of libcurl we provide an API with safe and secure defaults as we understand the power of the default. We also document everything with details and take great pride in having world-class documentation. To reduce the risk of applications becoming unsafe just because our API was unclear.
We also document internal APIs and functions to help contributors write better code when improving and changing curl.
We don’t allow compiler warnings to remain – on any platform. This is sometimes quite onerous since we build on such a ridiculous amount of systems.
We encourage use of source code comments and assert()s to make assumptions obvious. (curl is primarily written in C.)
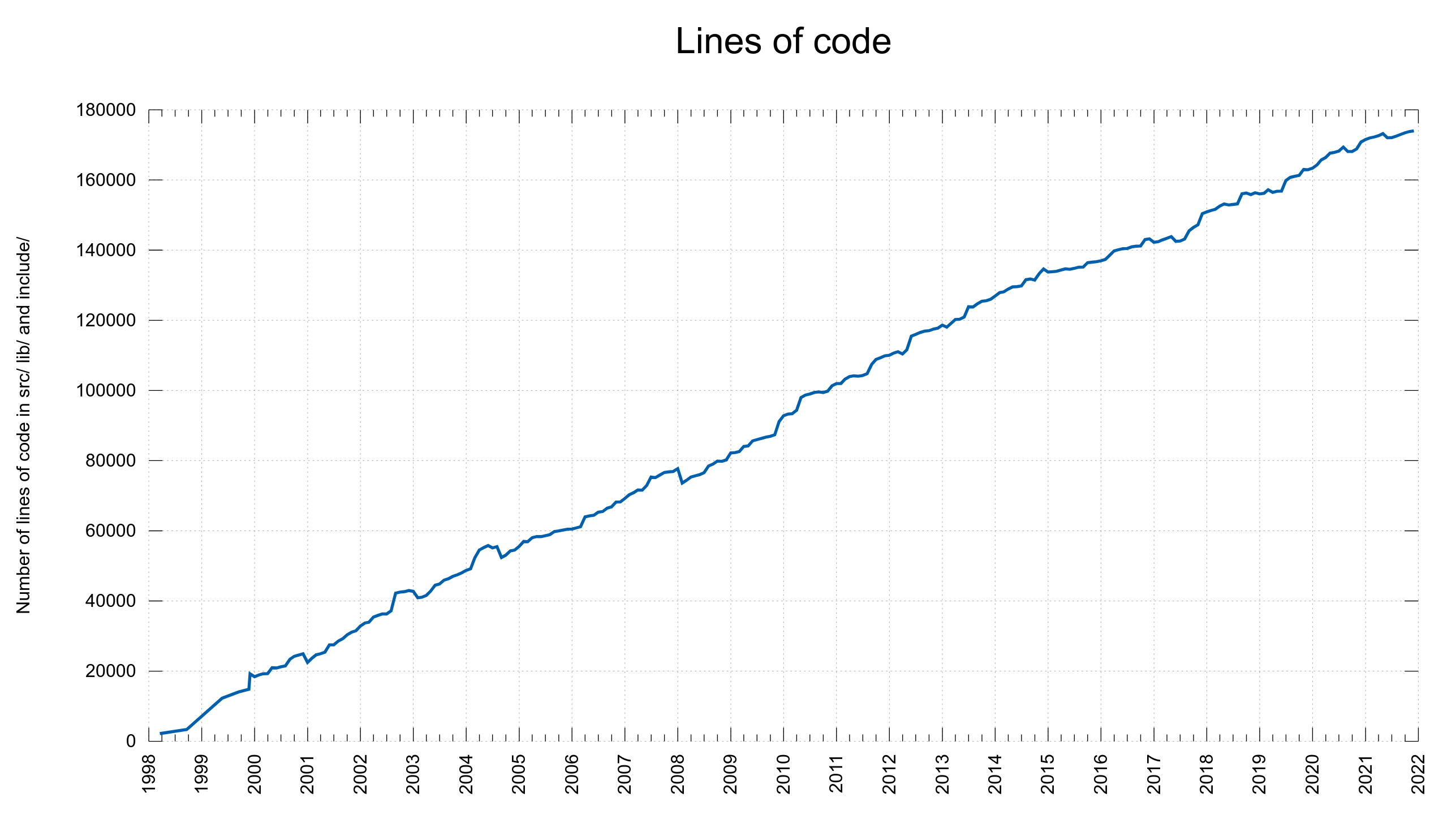
Number of lines of (product) code in the curl project over time.
Review
All code should be reviewed. Maintainers are however allowed to review and merge their own pull-requests for practical reasons.
Code should be easy to read and understand. Our code style must be followed and encourages that: for example, no assignments in conditions, one statement per line, no lines longer than 80 columns and more.
Strict compliance with the code style also means that the code gets a flow and a consistent look, which makes it easier to read and manage. We have a tool that verifies most aspects of the code style, which takes away most of that duty away from humans. I find that PR authors generally take code style remarks better when pointed out by a tool than when humans do it.
A source code change is accompanied with a git commit message that need to follow the template. A consistent commit message style makes it easier to later come back and understand it proper when viewing source code history.
Test
We want everything tested.
Unit tests. We strive at writing more and more unit tests of internal functions to make sure they truly do what expected.
System tests. Do actual network transfers against test servers, and make sure different situations are handled.
Integration tests. Test libcurl and its APIs and verify that they handle what they are expected to.
Documentation tests. Check formats, check references and cross-reference with source code, check lists that they include all items, verify that all man pages have all sections, in the same order and that they all have examples.
“Fix a bug? Add a test!” is a mantra that we don’t always live up to, but we try.
curl runs on 80+ operating systems and 20+ CPU architectures, but we only run tests on a few platforms. This usually works out fine because most of the code is written to run on multiple platforms so if tested on one, it will also run fine on all the other.
curl has a flexible build system that offers many million different build combinations with over 30 different possible third-party libraries in countless version combinations. We cannot test all build combos, but we try to test all the popular ones and at least one for each config option enabled and disabled.
We have many tests, but there are unfortunately still gaps and details not tested by the test suite. For those things we simply have to rely on the code review and then that users report problems in the shipped products.
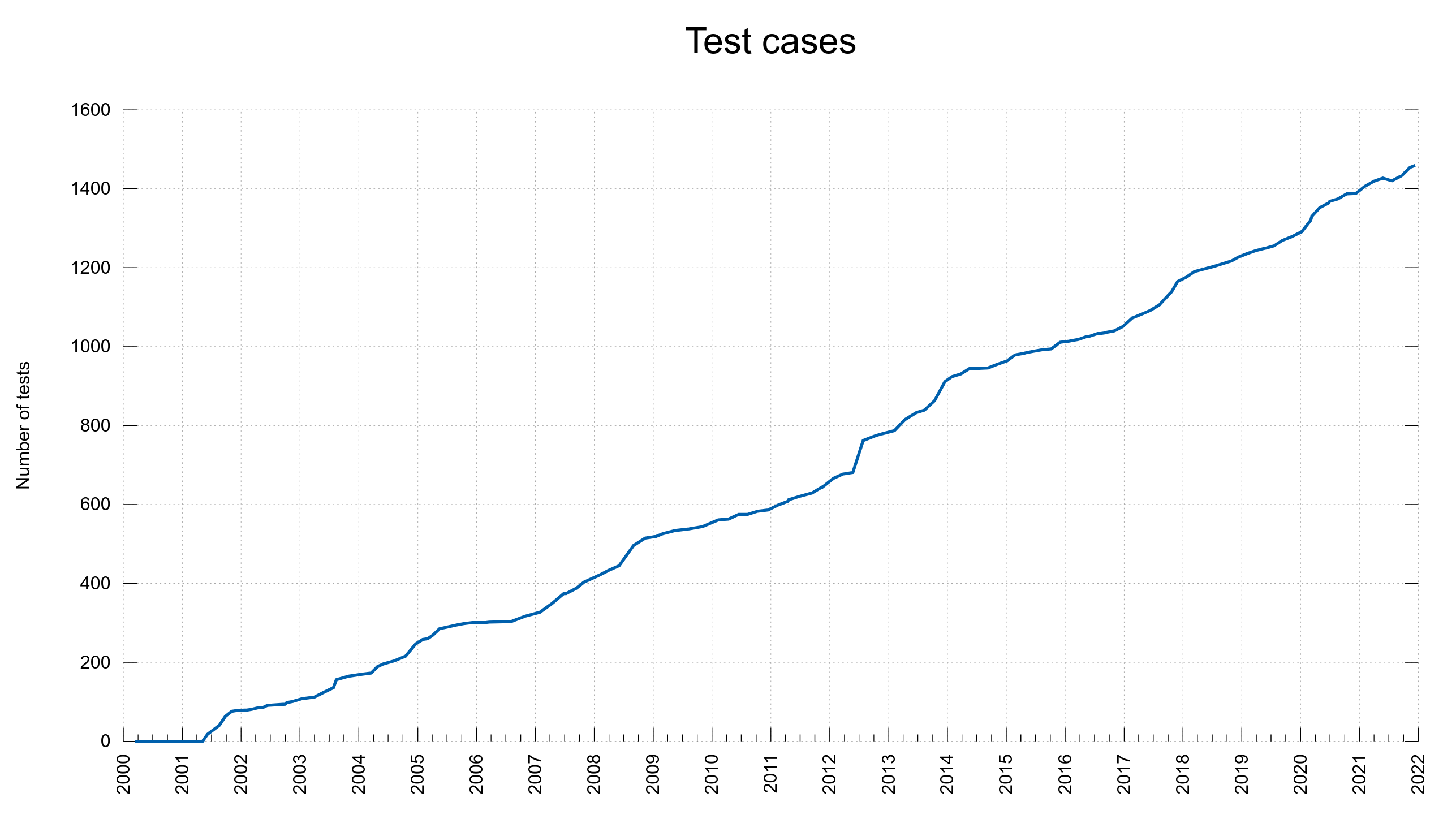
Number of test cases, test files really, over time.
Verify
We run all the tests using valgrind to make sure nothing leaks memory or do bad memory accesses.
We build and run with address, undefined behavior and integer overflow sanitizers.
We are part of the OSS-Fuzz project which fuzzes curl code non-stop, and we run CIFuzz in CI builds, which runs “a little” fuzzing on the curl code in the normal pull-request process.
We do “torture testing“: run a test case once and count the number of “fallible” function calls it makes. Those are calls to memory allocation, file operations, socket read/write etc. Then re-run the test that many times, and for each new iteration we make another one of the fallible functions fail and return error. Verify that no memory leaks or crashes occur. Do this on all tests.
We use several different static code analyzers to scan the code checking for flaws and we always fix or otherwise handle every reported defect. Many of them for each pull-request and commit, some are run regularly outside of that process:
scan-build
clang tidy
lgtm
CodeQL
Lift
Coverity
The exact set has varied and will continue to vary over time as services come and go.
Bug-bounty
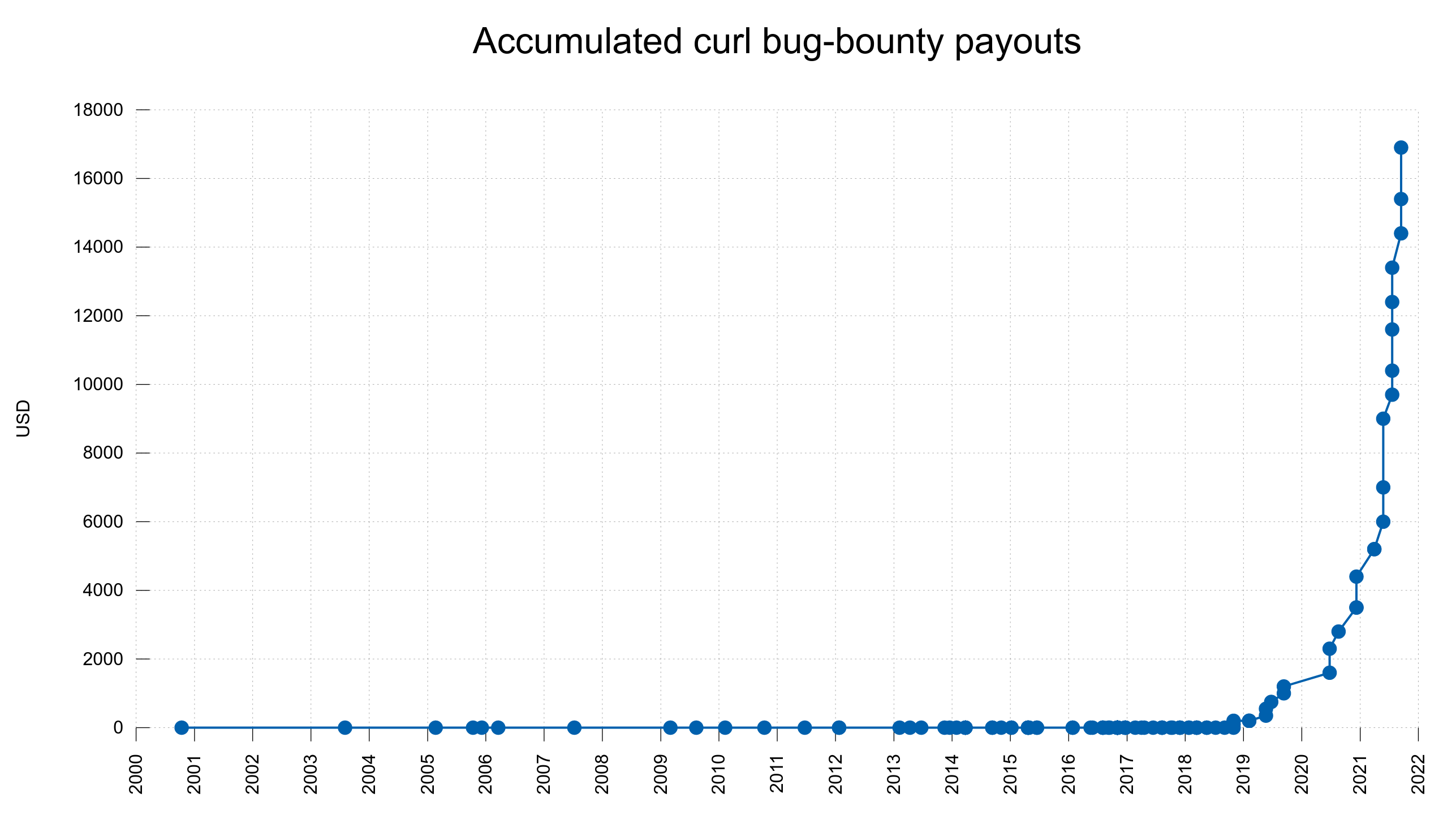
No matter how hard we try, we still ship bugs and mistakes. Most of them of course benign and harmless but some are not. We run a bug-bounty program to reward security searchers real money for reported security vulnerabilities found in curl. Until today, we have paid almost 17,000 USD in total and we keep upping the amounts for new findings.
Accumulated bug-bounty payouts over time
When we report security problems, we produce detailed and elaborate advisories to help users understand every subtle detail about the problem and we provide overview information that shows exactly what versions are vulnerable to which problems. The curl project aims to also be a world-leader in security advisories and related info.
Act on mistakes
We are not immune, no matter how hard we try. Bad things will happen. When they do, we:
Act immediately.
Own the problem, responsibly
Fix it and announce it – as soon as possible
Learn from it
Make it harder to do the same or similar mistakes again
Does it work? Do we actually learn from our history of mistakes? Maybe. Having our product in ten billion installations is not a proof of this. There are some signs that might show we are doing things right:
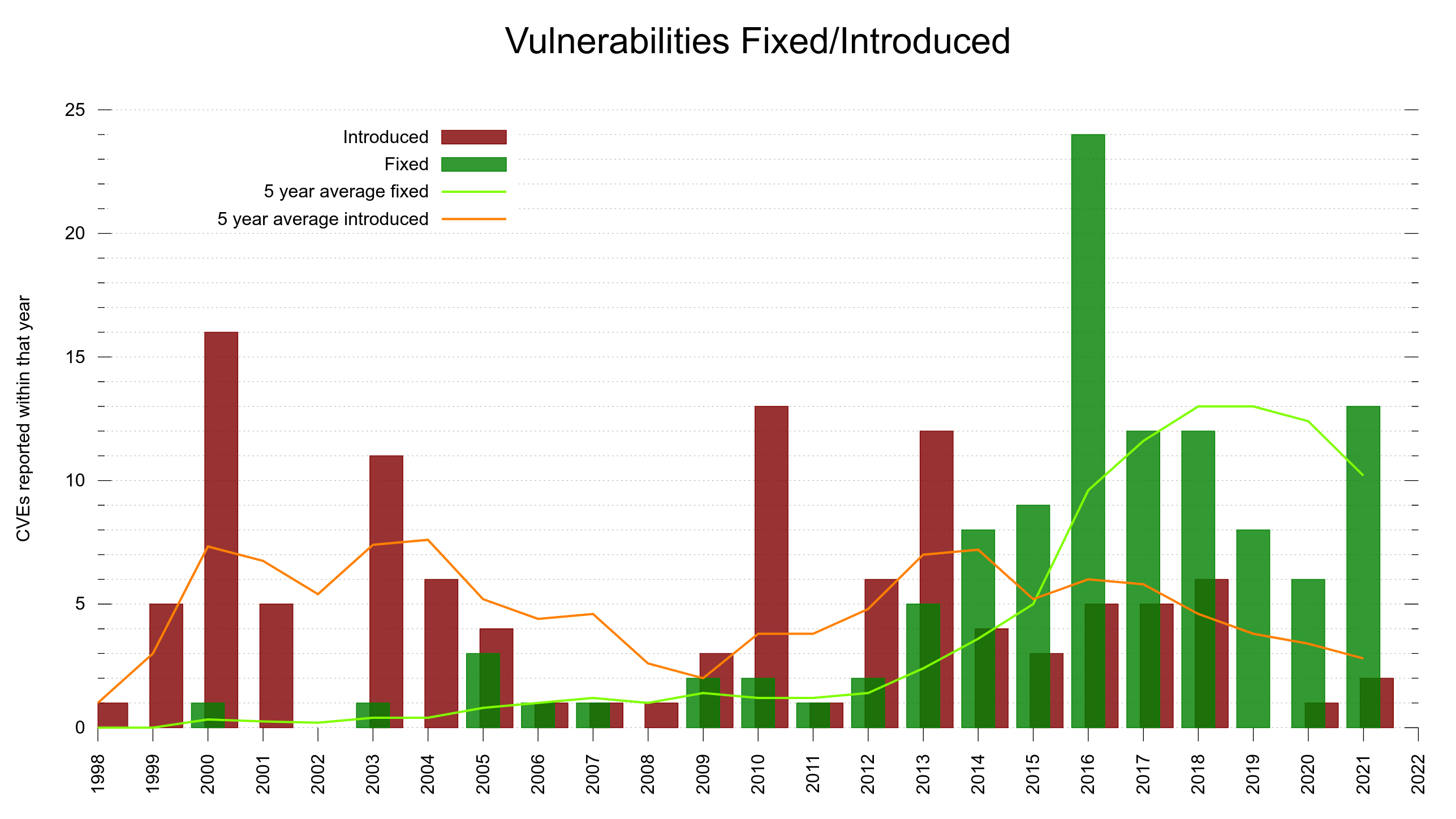
We were reporting fewer CVEs/year the last few years but in 2021 we went back up. It could also be the result of more people looking, thanks to the higher monetary rewards offered. At the same time the number of lines of code have kept growing at a rate of around 6,000 lines per year.
We get almost no issues reported by OSS-Fuzz anymore. The first few years it ran it found many problems.
We are able to increase our bug-bounty payouts significantly and now pay more than one thousand USD almost every time. We know people are looking hard for security bugs.
Security vulnerabilities. Fixed vs Introduced over the years.
Continuous Integration
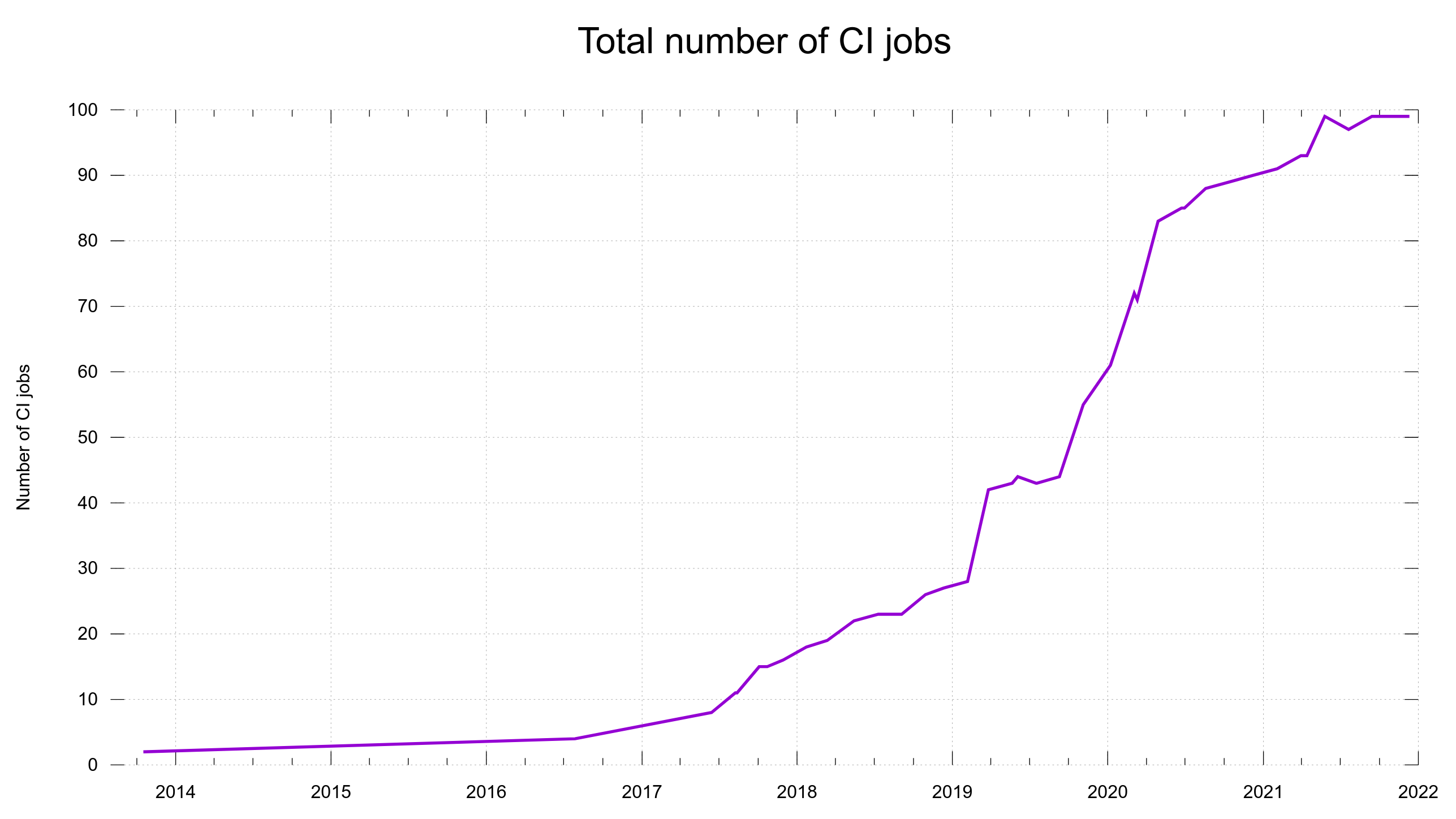
For every pull-request and commit done in the project, we run about 100 different builds + test rounds.
Total number of CI builds per pull-request and commit, over time
Done using several different CI services for maximum performance, widest possible coverage and shortest time to completion.
We currently use the following CI services: Cirrus CI, AppVeyor, Azure Pipelines, GitHub Actions, Circle CI and Zuul CI.
We also have a separate autobuild system with systems run by volunteers that checkout the latest code, build, run all the tests and report back in a continuous manner a few times or maybe once per day.
New habits past mistakes have taught us
We have done several changes to curl internals as direct reactions to past security vulnerabilities and their root causes. Lessons learned.
Unified dynamic buffer functions
These days we have a family of functions for working with dynamically sized buffers. Be using the same set for this functionality we have it well tested and we reduce the risk that new code messes up. Again, nothing revolutionary or strange, but as curl had grown organically over the decades, we found ourselves in need of cleaning this up one day. So we did.
Maximum string sizes
Several past mistakes came from possible integer overflows due to libcurl accepting input string sizes of unrestricted lengths and after doing operations on such string sizes, they would sometimes lead to overflows.
Since a few years back now, no string passed to curl is allowed to be larger than eight megabytes. This limit is somewhat arbitrarily set but is meant to be way larger than the largest user names and passwords ever used etc. We could also update the limit in a future, should we want. It’s not a limit that is exposed in the API or even mentioned. It is there to trap mistakes and malicious use.
Avoid reallocs
Thanks to the previous points we now avoid realloc as far as possible outside of those functions. History shows that realloc in combination with integer overflows have been troublesome for us. Now, both reallocs and integer overflows should be much harder to mess up.
Code coverage
A few years ago we ran code coverage reports for one build combo on one platform. This generated a number that really didn’t mean a lot to anyone but instead rather mislead users to drawing funny conclusions based on the report. We stopped that. Getting a “complete” and representative number for code coverage for curl is difficult and nobody has yet gone back to attempt this.
The impact of security problems
Every once in a while someone discovers a security problem in curl. To date, those security vulnerabilities have been limited to certain protocols and features that are not used by everyone and in many cases even disabled at build-time among many users. The issues also often rely on either a malicious user to be involved, either locally or remotely and for a lot of curl users, the environments it runs in limit that risk.
To date, I’m not aware of any curl user, ever, having been seriously impacted by a curl security problem.
This is not a guarantee that it will not ever happen. I’m only stating facts about the history so far. Security is super hard and I can only promise that we will keep working hard on shipping secure products.
Is it scary?
Changes done to curl code today will end up in billions of devices within a few years. That’s an intimidating fact that could truly make you paralyzed by fear of the risk that the world will “burn” due to a mistake of mine.
Rather than instilling fear by this outlook, I think the proper way to think it about it, is respecting the challenge and “shouldering the responsibility”. Make the changes we deem necessary, but make them according to the guidelines, follow the rules and trust that the system we have setup is likely to detect almost every imaginable mistake before it ever reaches a release tarball. Of course we plug holes in the test suite that we spot or suspect along the way.
The back-door threat
I blogged about that recently. I think a mistake is much more likely to slip-in and get shipped to the world than a deliberate back-door is.
Memory safe components might help
By rewriting parts of curl to use memory safe components, such as hyper for HTTP, we might be able to further reduce the risk of future vulnerabilities. That’s a long game to make reality. It will also be hard in the future to actually measure and tell for sure if it truly made an impact.
How can you help out?
Pay for a curl support contract. This is what enables me to work full time on curl.
Help out with reviews and adding new tests to curl
Help out with fixing issues and improving the code
In the afternoon of October 17, 2013 we merged the first config file ever that would use Travis CI for the curl project using the nifty integration at GitHub. This was the actual introduction of the entire concept of building and testing the project on every commit and pull request for the curl project. Before this merge happened, we only had our autobuilds. They are systems run by volunteers that update the code from git maybe once per day, build and run the tests and then upload all the logs.
Don’t take this wrong: the autobuilds are awesome and have helped us make curl what it is. But they rely on individuals to host and admin the machines and to setup the specific configs that are tested.
With the introduction of “proper” CI, the configs that are tested are now also hosted in git and allows the project members to better control and adjust the tests and configs, plus that we can run them on already on pull-requests so that we can verify code before merge instead of having to first merge the code to master before the changes can get verified.
Seriously. Always.
Travis provided a free service with a great promise.
Promise from Travis website as recently as late 2020.
In 2017 we surpassed 10 jobs per commit, all still on Travis.
In early 2019 we reached 30 jobs per commit, and at that time we started to use and spread out the work on more CI services. Travis would still remain as the one we’d lean on the heaviest. It was there and we had custom-written a bunch of jobs for it and it performed well.
Travis even turned some levers for us so that we got more parallel processing powers than on the regular open source tier, and we listed them as sponsors of the curl project for their gracious help. This may or may not be related to the fact that I met Josh Kalderimis (co-founder of travis) in 2019 and we talked about curl’s use of it and they possibly helping us more.
Transition to death
This year, 2021, the curl project runs around 100 CI jobs per commit and PR. 33 of them ran on Travis when we were finally pushed over from travis-ci.org to their new travis-ci.com domain. A transition they’d been advertising for a while but wasn’t very clearly explained or motivated in my eyes.
The new domain also implied new rules and new tiers, we quickly learned. Now we would have to apply to be recognized as an open source project (after 7.5 years of using their services as an open source project). But also, in order to get to take advantage of their free tier being an open source project was no longer enough. Among the new requirements on the project was this:
Project must not be sponsored by a commercial company or organization (monetary or with employees paid to work on the project)
We’re a small independent open source project, but yes I work on curl full-time thanks to companies paying for curl support. I’m paid to work on curl and therefore we cannot meet that requirement.
Not eligible but still there
I’m not sure why, but apparently we still got free “credits” for running CI on Travis. The CI jobs kept working and I think maybe I sighed a little from relief – of course I did it prematurely as it only took us a few days into the month of June until we had run out of the free credits. There’s no automatic refill but we can apparently ask for more. We asked, but many days after having asked we still had no more credits and no CI jobs could run on Travis anymore. CI on Travis at the same level as before would cost more than 249 USD/month. Maybe not so much “it will always be free”.
The 33 jobs on Travis were there for a purpose. They’re prerequisites for us to develop and ship a quality product. Without the CI jobs running, we risk landing bad code. This was not a sustainable situation.
We looked for alternative services and we quickly got several offers of help and assistance.
New service
Friends from both Zuul CI and Circle CI stepped up and helped us started to get CI jobs transitioned over from Travis over to their new homes.
At June 14th 2021, we officially had no more jobs running on Travis.
Visualized as a graph, we can see the Travis jobs “falling off a cliff” with Zuul rising to the challenge:
Services come and go. There’s no need to get hung up on that fact but instead keep moving forward with our eyes fixed on the horizon.
Thank you Travis CI for all those years of excellent service!
Pay up?
Lots of people have commented and think I’m “whining” about Travis CI charging for something that is useful and that I should rather just pay up. I could probably have gone with that but I dislike their broken promise and that they don’t consider us Open source anymore and I feel I have a responsibility to use the funds we get from gracious donors as wisely and economically as possible, and that includes using no-cost or cheap services rather than services charging thousands of dollars per year.
If there really were no other available and viable options, then paying could’ve been an alternative. Now, moving on to something else was the right choice for us.
The curl test suite fires up a whole bunch of test servers for the various supported protocols, and then command lines using curl or libcurl-using dedicated test apps are run against those servers to make sure curl is acting exactly as it is supposed to.
The curl test suite was introduced back in the year 2000 and has of course grown and been developed substantially since then.
Each test server is invoked and handles a specific protocol or set of protocols, so to make sure curl’s 24 transfer protocols are tested, a lot of test server instances are spun up. The test servers normally don’t shut down after each individual test but instead keep running in case there are more tests for that protocol for speedier operations. When all tests are completed, all the test servers are shut down again.
Port numbers
The protocols curl communicates with are all done over TCP or UDP, and therefore each test server needs to listen to a dedicated port so that the tests can be invoked and curl can use the protocols correctly.
We started the test suite once by using port number 8990 as a default “base port”, and then each subsequent server it invokes gets the next port number. A full round can use up to 30 or so ports.
The script needed to know what port number to use so that it could invoke the tests to use the correct port number. But port numbers are both a scarce resource and a resource that can only be used by one server at a time, so if you would simultaneously invoke the curl test suite a second time on the same machine, it would cause havoc since it would attempt to use the same port numbers again.
Not to mention that when various users run the test suite on their machines, on servers or in CI jobs, just assuming or hoping that we could use a range of 30 fixed port numbers is error-prone and it would occasionally cause us trouble.
Dynamic port numbers
A few months ago, in April 2020, I started the work on changing how the curl test suite uses port numbers for its test servers. Each used test server would instead get fired up on a totally random port number, and then feed back that number to the test script that then would use the actually used port number to run the tests against.
It took some rearranging of internal logic to make sure things still worked and that the comparison of the generated protocol etc still would work. Then it was “just” a matter of converting over all test servers to this new dynamic concept and made sure that there was no old-style assumptions lingering around in the test cases.
Some of the more tricky changes for this new paradigm was the protocol parts that use the port number in data where curl base64 encodes the chunk and sends it to the server.
Reaching the end of that journey
The final fixed port number in the curl test suite was removed when we merged PR 5783 on August 7 2020. Now, every test in curl that needs a port number uses a dynamic port number.
Now we can run “make test” from multiple shells on the same machine in parallel without problems.
It can allow us to improve the test suite further and maybe for example run multiple tests in parallel in order to reduce the total execution time. It will avoid future port collisions. A small, but very good step forward.
Abstract: curl runs in some ten billion installations in the world, in virtually every connected device on the planet and ported to more operating systems than most. In this presentation, curl’s lead developer Daniel Stenberg talks about how the curl project takes on testing, QA, CI and fuzzing etc, to make sure curl remains a stable and secure component for everyone while still getting new features and getting developed further. With a Q&A session at the end for your questions!
Register here at attend the live event. The video will be made available afterward.
In the curl project we produce and ship a rock solid and reliable library for the masses, we must never exit, leak memory or do anything in an ungraceful manner. We must free all resources and error out nicely whatever problem we run into at whatever moment in the process.
To help us stay true to this, we have a way of testing we call “torture tests”. They’re very effective error path tests. They work like this:
Torture tests
They require that the code is built with a “debug” option.
The debug option adds wrapper functions for a lot of common functions that allocate and free resources, such as malloc, fopen, socket etc. Fallible functions provided by the system curl runs on.
Each such wrapper function logs what it does and can optionally either work just like it normally does or if instructed, return an error.
When running a torture test, the complete individual test case is first run once, the fallible function log is analyzed to count how many fallible functions this specific test case invoked. Then the script reruns that same test case that number of times and for each iteration it makes another of the fallible functions return error.
First make function 1 return an error. Then make function 2 return and error. Then 3, 4, 5 etc all the way through to the total number. Right now, a typical test case uses between 100 and 200 such function calls but some have magnitudes more.
The test script that iterates over these failure points also verifies that none of these invokes cause a memory leak or a crash.
Very slow
Running many torture tests takes a long time.
This test method is really effective and finds a lot of issues, but as we have thousands of tests and this iterative approach basically means they all need to run a few hundred times each, completing a full torture test round takes many hours even on the fastest of machines.
In the CI, most systems don’t allow jobs to run more than an hour.
The net result: the CI jobs only run torture tests on a few selected test cases and virtually no human ever runs the full torture test round due to lack of patience. So most test cases end up never getting “tortured” and therefore we miss out verifying error paths even though we can and we have the tests for it!
But what if…
It struck me that when running these torture tests on a large amount of tests, a lot of error paths are actually identical to error paths that were already tested and will just be tested again and again in subsequent tests.
If I could identify the full code paths that were already tested, we wouldn’t have to test them again. But getting that knowledge would require insights that our test script just doesn’t have and it will be really hard to make portable to even a fraction of the platforms we run and test curl on. Not the most feasible idea.
I went with something much simpler.
I simply estimate that most test cases actually have many code paths in common with other test cases. By randomly skipping a few iterations on each test, those skipped code paths might still very well be tested in another test. As long as the skipping is random and we do a large number of tests, chances are we cover most paths anyway. I say most because it certainly will not be all.
Random skips
In my first shot at this (after I had landed to change that allows me to control the torture tests this way) I limited the number of errors to 40 per test case. Now suddenly the CI machines can actually blaze through the test cases at a much higher speed and as a result, they ran torture tests on tests we hadn’t tortured in a long time.
I call this option to the runtests.pl script --shallow.
Already on this my first attempt in doing this, I struck gold and the script highlighted code paths that would create memory leaks or even crashes!
As a direct result of more test cases being tortured, I found and fixed nine independent bugs in curl already before I could land this in the master branch, and there seems to be more failures that pop up after the merge too! The randomness involved may of course delay the detection of some problems.
Room for polishing
The test script right now uses a fixed random seed so that repeated invokes will make it work exactly the same. Which is good when you want to reproduce it elsewhere. It is bad in the way that each test will have the exact same tests skipped every test round – as long as the set of fallible functions are unmodified.
The seed can be set by a command line argument so I imagine a future improvement would be to set the random seed based on the git commit hash at the point where the tests are run, or something. That way, torture tests on subsequent commits would get a different random spread.
Alternatively, I will let the CI systems use a true random seed to make it test a different set every time independent of git etc – as when it detects an error the informational output will still be enough for a user to reproduce the problem without the need of a seed.
Further, I’ve started out running --shallow=40 (on the Ubuntu version) which is highly unscientific and arbitrary. I will experiment altering this amount both up and down a bit to see what I learn from that.
Torture via strace?
Another idea that’s been brewing in my head for a while but I haven’t yet actually attempted to do this.
The next level of torture testing is probably to run the tests with strace and use its error injection ability, as then we don’t even need to build a debug version of our code and we don’t need to write wrapper code etc.