Trailing dots after hostnames in URLs remain my worst enemies. I wrote about several problems with them in the past that involved those nasty things. They are still painful. When we shipped curl 8.21.0 on June 24 2026 we fixed at least three brand new problems that involved trailing dots. C’mon, follow me down the trailing dot rabbit hole, episode two. I can just feel that there will be a third episode as well in a future…
IPv4 numerical address
Let’s for a second imagine that you create a URL that uses a numerical IPv4 address. Not entirely uncommon. For example lots of people use 127.0.0.1 in local tests etc. Used everywhere since the dawn of time.
Now imagine that you add a trailing dot to this hostname, like “192.168.0.1.”. What does the trailing dot even mean here?
This particular trailing dot caused a problem in curl. To figure out if curl should allow wildcard certificates when connecting to a TLS server, it needs to know if the given hostname is a numerical IP or a hostname. The check uses inet_pton() on the provided hostname extracted from the URL – which incidentally returns false for an IPv4 address that ends with dot! So if it isn’t a numerical address it is a hostname and then we allow wildcards… Argh.
I decided to solve this particular problem like this: if the address is a valid IPv4 address and there is only a single dot afterwards, that dot is “swallowed” as part of the regular IPv4 normalization process that curl always does for IPv4 addresses when parsing URLs. This way, a numerical IPv4 address with a trailing dot will never be passed on to curl internals anymore. And the meaning of the trailing dot for this use case is clear: it is a mistake so we get rid of it. (This also seems to be what browsers do.) Shipping in curl 8.21.0.
This choice has already been reported problematic by at least one user who expected a transfer for a URL like this to return error… I suppose this means that the jury is still out on what the best approach for this trailing dot is.
Double trailing dots HSTS
What could be more fun than trailing dots if not two trailing dots!
Two trailing dots is not possible to use as a hostname when resolving hostnames using DNS. It is an illegal name and causes an error. But as curl provides other ways to populate the DNS cache with a provided name, and you can provide names in /etc/hosts etc you can make curl work with URLs where the hostname has two trailing dots. Or rather, you could up until recently until I made sure it is properly banned always because of the trouble they cause internally.
A double-dot is correctly treated as a host with a trailing dot, but it turns out that in for example the HSTS logic that became problematic as removing the trailing dot for some functions would still have a trailing dot there when there were two of them to begin with… and it would get confused and act up.
No more double trailing dots. One is annoying enough. Shipping in curl 8.21.0.
Cookie domain
HTTP cookies are basically name/value pairs set by the server and held by the client to get sent back to the server again in later communications. The server can specify for which domain a cookie should apply to, so that it can be used across multiple domains. (Yes, it is a little crazy,)
To prevent the server from being able to set the cookie on a too wide domain cookie clients check if the specified domain is Public Suffic Domain (PSL) or not. A server is not allowed to set cookies for PSL domains, as that allows it to create “super cookies” that work across domains in ways that are not allowed. Cookies attempted to get set for such a name should be rejected.
In libcurl we check domains against the PSL using the libpsl library.
Turns out this too could be tricked by trailing dots. If you communicate with the URL “example.co.uk.” (with a trailing dot) and it sets a cookie for for “co.uk.” (with a trailing dot), the internal check would ask libpsl about the PSL status and… it did not work with trailing dots. The exact same process without trailing dots correctly says it is a PSL and the cookie is refused. But with the trailing dots present it was fooled and curl would allow the cookie to get stored and later sent back to such a host…
This particular issue ended up considered a vulnerability known as CVE-2026-8924. Fix shipped in curl 8.21.0.
We should consider these things
Yes, you can of course quite correctly argue that none of these things are actually new or sudden changes. Trailing dots are there, they have always been there and people will continue to use them in the future. I’m not blaming anyone else. I’m just expressing my frustration.
I’ve talked on this topic before but I realized I never did a proper blog post on the topic. So here it is: how we develop curl to keep it safe. The topic of supply chain security is one that is discussed frequently these days and every so often there’s a very well used (open source) component that gets a terrible weakness revealed.
Don’t get me wrong. Proprietary packages have their share of issues as well, and probably even more so, but for obvious reasons we never get the same transparency, details and insight into those problems and solutions.
If we would find a critical vulnerability in curl, it could potentially exist in every internet-connected device on the globe. We don’t want that.
A critical security flaw in our products would be bad, but we also similarly need to make sure that we provide APIs and help users of our products to be safe and to use curl safely. To make sure users of libcurl don’t accidentally end up getting security problems, to the best of our ability.
In the curl project, we work hard to never have our own version of a “heartbleed moment“. How do we do this?
Always improving
Our method is not strange, weird or innovative. We simply apply all best practices, tools and methods that are available to us. In all areas. As we go along, we tighten the screws and improve our procedures, learning from past mistakes.
There are no short cuts or silver bullets. Just hard work and running tools.
Not a coincidence
Getting safe and secure code into your product is not something that happens by chance. We need to work on it and we need to make a concerned effort. We must care about it.
We all know this and we all know how to do it, we just need to make sure that we also actually do it.
The steps
Write code following the rules
Review written code and make sure it is clear and easy to read.
Test the code. Before and after merge
Verify the products and APIs to find cracks
Bug-bounty to reward outside helpers
Act on mistakes – because they will happen
Writing
For users of libcurl we provide an API with safe and secure defaults as we understand the power of the default. We also document everything with details and take great pride in having world-class documentation. To reduce the risk of applications becoming unsafe just because our API was unclear.
We also document internal APIs and functions to help contributors write better code when improving and changing curl.
We don’t allow compiler warnings to remain – on any platform. This is sometimes quite onerous since we build on such a ridiculous amount of systems.
We encourage use of source code comments and assert()s to make assumptions obvious. (curl is primarily written in C.)
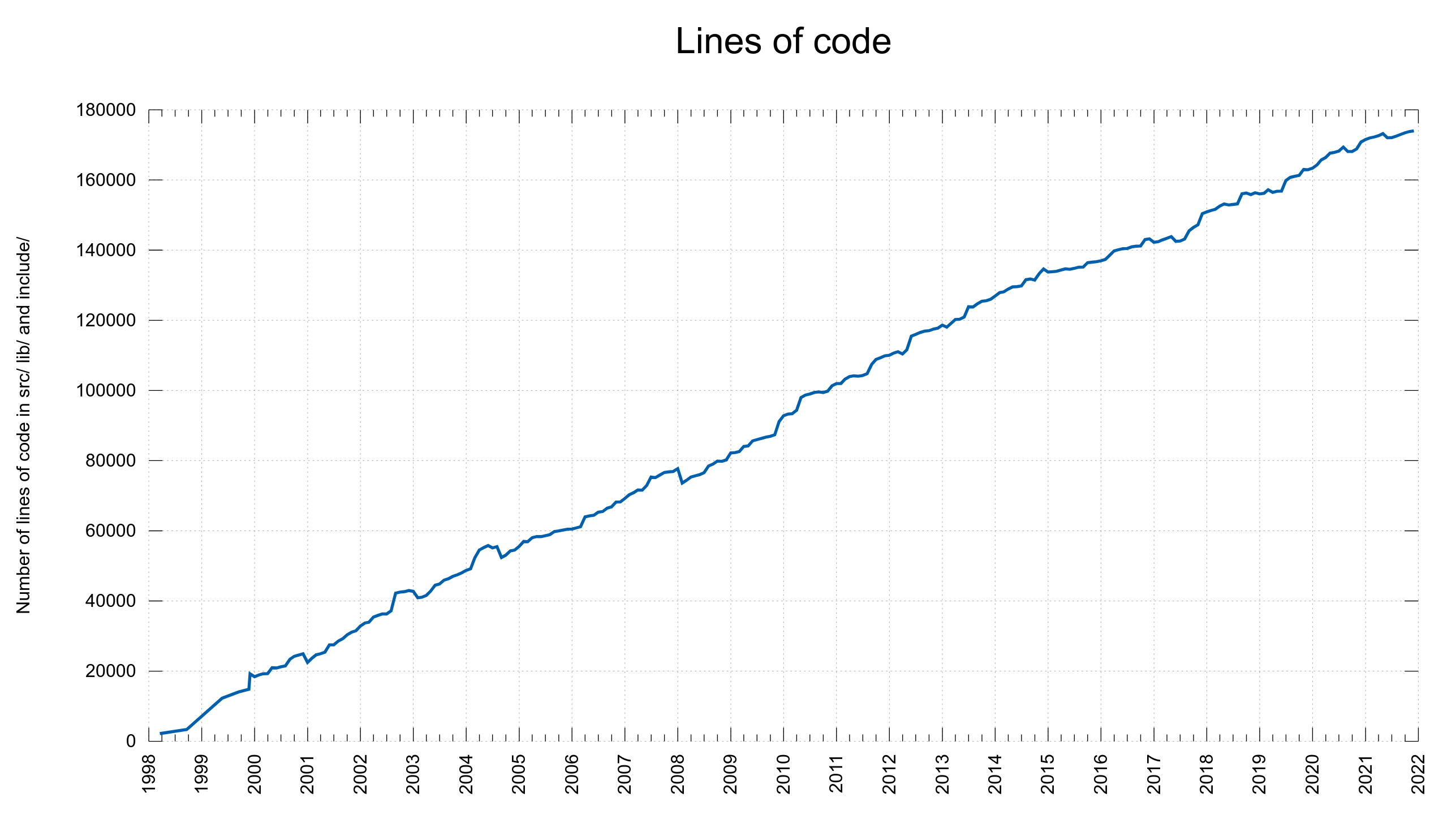
Number of lines of (product) code in the curl project over time.
Review
All code should be reviewed. Maintainers are however allowed to review and merge their own pull-requests for practical reasons.
Code should be easy to read and understand. Our code style must be followed and encourages that: for example, no assignments in conditions, one statement per line, no lines longer than 80 columns and more.
Strict compliance with the code style also means that the code gets a flow and a consistent look, which makes it easier to read and manage. We have a tool that verifies most aspects of the code style, which takes away most of that duty away from humans. I find that PR authors generally take code style remarks better when pointed out by a tool than when humans do it.
A source code change is accompanied with a git commit message that need to follow the template. A consistent commit message style makes it easier to later come back and understand it proper when viewing source code history.
Test
We want everything tested.
Unit tests. We strive at writing more and more unit tests of internal functions to make sure they truly do what expected.
System tests. Do actual network transfers against test servers, and make sure different situations are handled.
Integration tests. Test libcurl and its APIs and verify that they handle what they are expected to.
Documentation tests. Check formats, check references and cross-reference with source code, check lists that they include all items, verify that all man pages have all sections, in the same order and that they all have examples.
“Fix a bug? Add a test!” is a mantra that we don’t always live up to, but we try.
curl runs on 80+ operating systems and 20+ CPU architectures, but we only run tests on a few platforms. This usually works out fine because most of the code is written to run on multiple platforms so if tested on one, it will also run fine on all the other.
curl has a flexible build system that offers many million different build combinations with over 30 different possible third-party libraries in countless version combinations. We cannot test all build combos, but we try to test all the popular ones and at least one for each config option enabled and disabled.
We have many tests, but there are unfortunately still gaps and details not tested by the test suite. For those things we simply have to rely on the code review and then that users report problems in the shipped products.
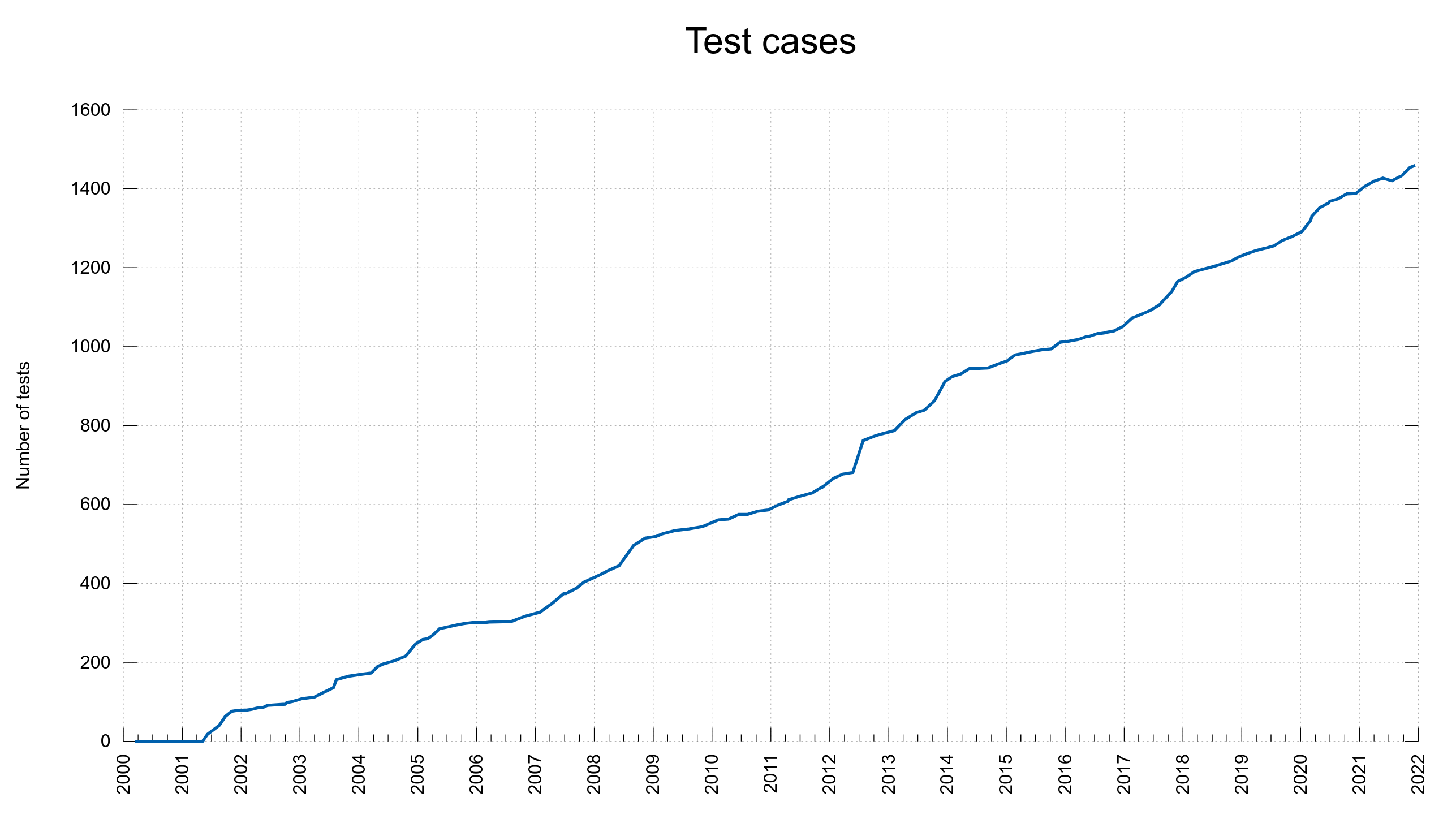
Number of test cases, test files really, over time.
Verify
We run all the tests using valgrind to make sure nothing leaks memory or do bad memory accesses.
We build and run with address, undefined behavior and integer overflow sanitizers.
We are part of the OSS-Fuzz project which fuzzes curl code non-stop, and we run CIFuzz in CI builds, which runs “a little” fuzzing on the curl code in the normal pull-request process.
We do “torture testing“: run a test case once and count the number of “fallible” function calls it makes. Those are calls to memory allocation, file operations, socket read/write etc. Then re-run the test that many times, and for each new iteration we make another one of the fallible functions fail and return error. Verify that no memory leaks or crashes occur. Do this on all tests.
We use several different static code analyzers to scan the code checking for flaws and we always fix or otherwise handle every reported defect. Many of them for each pull-request and commit, some are run regularly outside of that process:
scan-build
clang tidy
lgtm
CodeQL
Lift
Coverity
The exact set has varied and will continue to vary over time as services come and go.
Bug-bounty
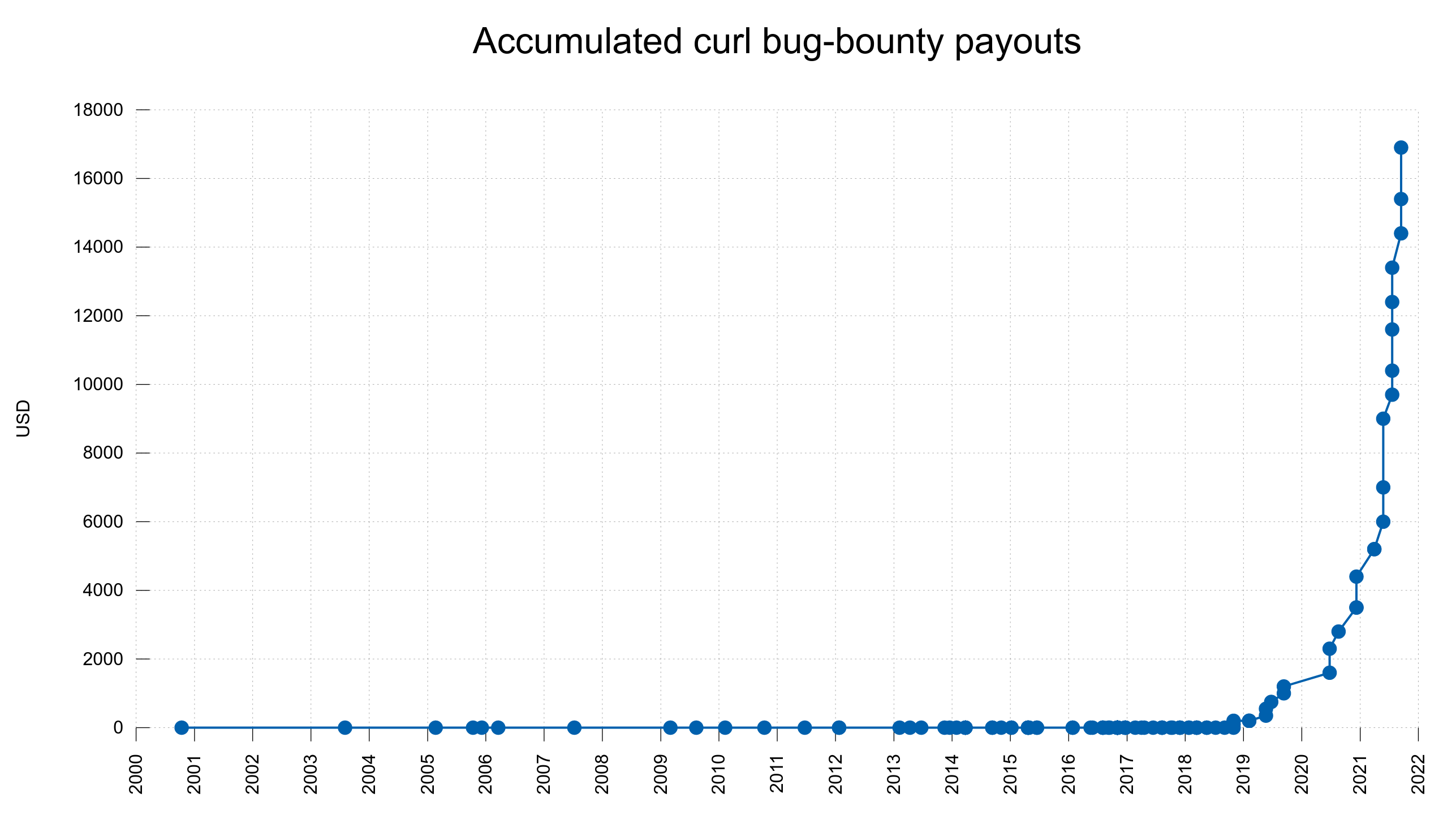
No matter how hard we try, we still ship bugs and mistakes. Most of them of course benign and harmless but some are not. We run a bug-bounty program to reward security searchers real money for reported security vulnerabilities found in curl. Until today, we have paid almost 17,000 USD in total and we keep upping the amounts for new findings.
Accumulated bug-bounty payouts over time
When we report security problems, we produce detailed and elaborate advisories to help users understand every subtle detail about the problem and we provide overview information that shows exactly what versions are vulnerable to which problems. The curl project aims to also be a world-leader in security advisories and related info.
Act on mistakes
We are not immune, no matter how hard we try. Bad things will happen. When they do, we:
Act immediately.
Own the problem, responsibly
Fix it and announce it – as soon as possible
Learn from it
Make it harder to do the same or similar mistakes again
Does it work? Do we actually learn from our history of mistakes? Maybe. Having our product in ten billion installations is not a proof of this. There are some signs that might show we are doing things right:
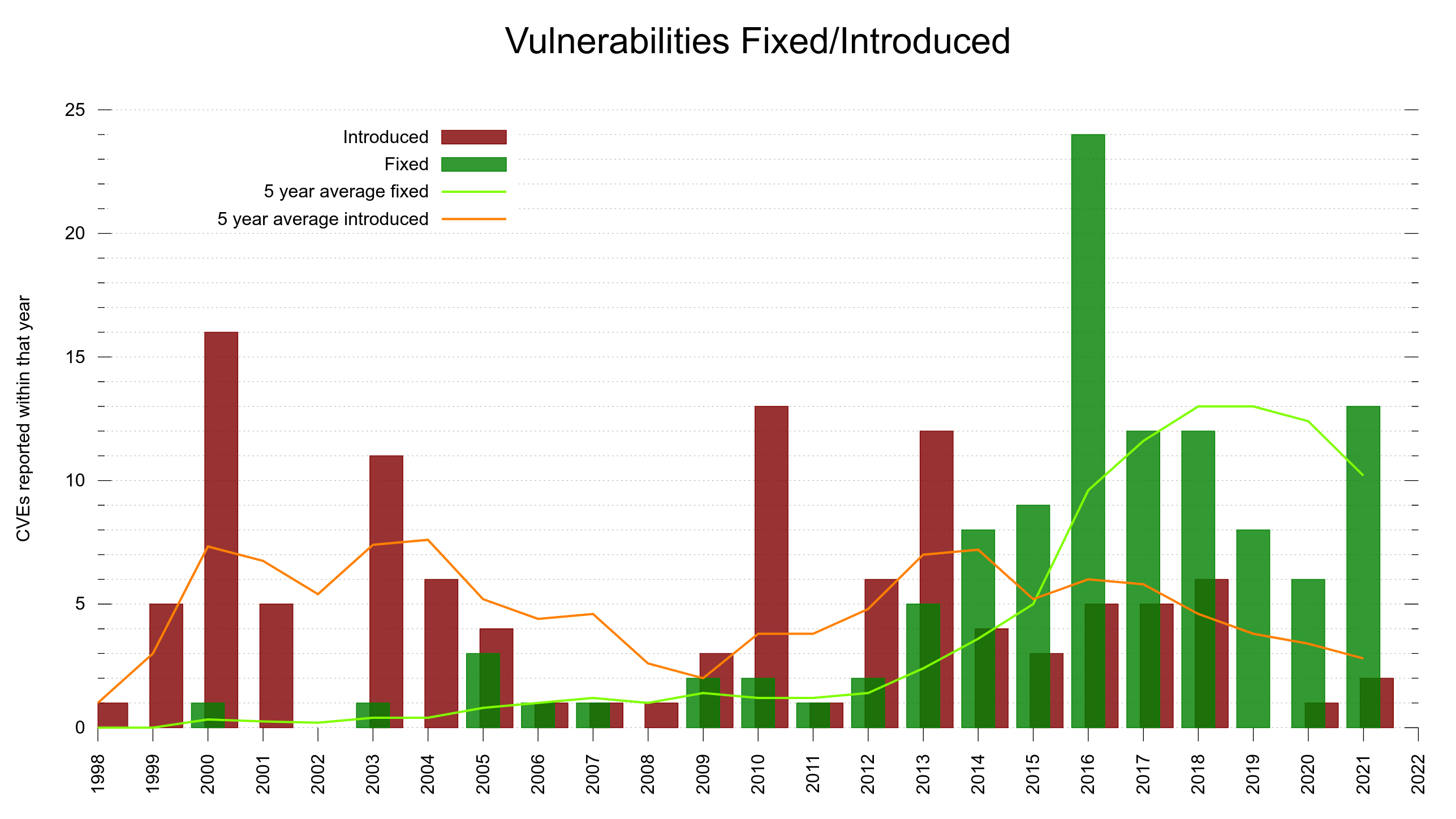
We were reporting fewer CVEs/year the last few years but in 2021 we went back up. It could also be the result of more people looking, thanks to the higher monetary rewards offered. At the same time the number of lines of code have kept growing at a rate of around 6,000 lines per year.
We get almost no issues reported by OSS-Fuzz anymore. The first few years it ran it found many problems.
We are able to increase our bug-bounty payouts significantly and now pay more than one thousand USD almost every time. We know people are looking hard for security bugs.
Security vulnerabilities. Fixed vs Introduced over the years.
Continuous Integration
For every pull-request and commit done in the project, we run about 100 different builds + test rounds.
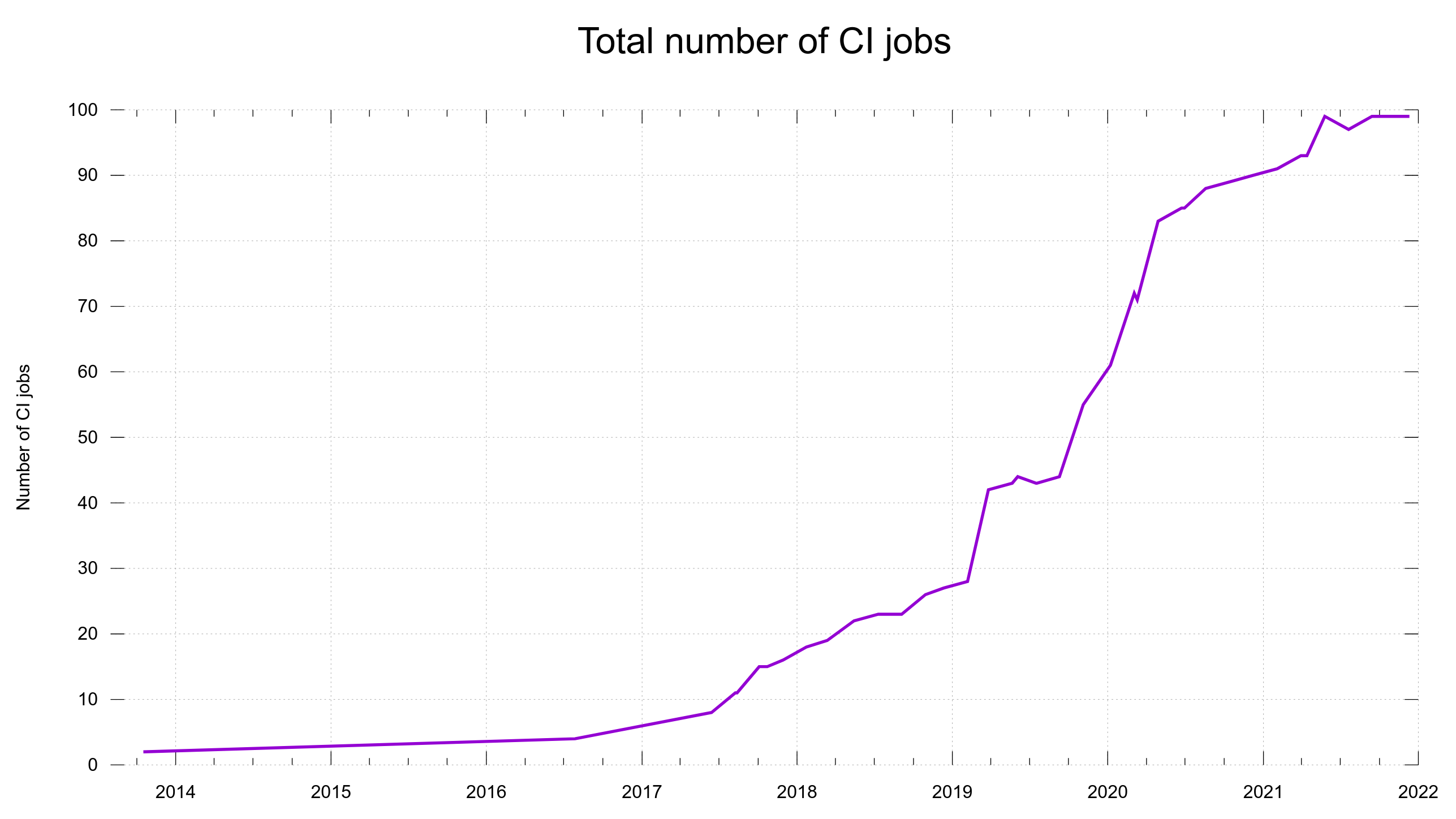
Total number of CI builds per pull-request and commit, over time
Done using several different CI services for maximum performance, widest possible coverage and shortest time to completion.
We currently use the following CI services: Cirrus CI, AppVeyor, Azure Pipelines, GitHub Actions, Circle CI and Zuul CI.
We also have a separate autobuild system with systems run by volunteers that checkout the latest code, build, run all the tests and report back in a continuous manner a few times or maybe once per day.
New habits past mistakes have taught us
We have done several changes to curl internals as direct reactions to past security vulnerabilities and their root causes. Lessons learned.
Unified dynamic buffer functions
These days we have a family of functions for working with dynamically sized buffers. Be using the same set for this functionality we have it well tested and we reduce the risk that new code messes up. Again, nothing revolutionary or strange, but as curl had grown organically over the decades, we found ourselves in need of cleaning this up one day. So we did.
Maximum string sizes
Several past mistakes came from possible integer overflows due to libcurl accepting input string sizes of unrestricted lengths and after doing operations on such string sizes, they would sometimes lead to overflows.
Since a few years back now, no string passed to curl is allowed to be larger than eight megabytes. This limit is somewhat arbitrarily set but is meant to be way larger than the largest user names and passwords ever used etc. We could also update the limit in a future, should we want. It’s not a limit that is exposed in the API or even mentioned. It is there to trap mistakes and malicious use.
Avoid reallocs
Thanks to the previous points we now avoid realloc as far as possible outside of those functions. History shows that realloc in combination with integer overflows have been troublesome for us. Now, both reallocs and integer overflows should be much harder to mess up.
Code coverage
A few years ago we ran code coverage reports for one build combo on one platform. This generated a number that really didn’t mean a lot to anyone but instead rather mislead users to drawing funny conclusions based on the report. We stopped that. Getting a “complete” and representative number for code coverage for curl is difficult and nobody has yet gone back to attempt this.
The impact of security problems
Every once in a while someone discovers a security problem in curl. To date, those security vulnerabilities have been limited to certain protocols and features that are not used by everyone and in many cases even disabled at build-time among many users. The issues also often rely on either a malicious user to be involved, either locally or remotely and for a lot of curl users, the environments it runs in limit that risk.
To date, I’m not aware of any curl user, ever, having been seriously impacted by a curl security problem.
This is not a guarantee that it will not ever happen. I’m only stating facts about the history so far. Security is super hard and I can only promise that we will keep working hard on shipping secure products.
Is it scary?
Changes done to curl code today will end up in billions of devices within a few years. That’s an intimidating fact that could truly make you paralyzed by fear of the risk that the world will “burn” due to a mistake of mine.
Rather than instilling fear by this outlook, I think the proper way to think it about it, is respecting the challenge and “shouldering the responsibility”. Make the changes we deem necessary, but make them according to the guidelines, follow the rules and trust that the system we have setup is likely to detect almost every imaginable mistake before it ever reaches a release tarball. Of course we plug holes in the test suite that we spot or suspect along the way.
The back-door threat
I blogged about that recently. I think a mistake is much more likely to slip-in and get shipped to the world than a deliberate back-door is.
Memory safe components might help
By rewriting parts of curl to use memory safe components, such as hyper for HTTP, we might be able to further reduce the risk of future vulnerabilities. That’s a long game to make reality. It will also be hard in the future to actually measure and tell for sure if it truly made an impact.
How can you help out?
Pay for a curl support contract. This is what enables me to work full time on curl.
Help out with reviews and adding new tests to curl
Help out with fixing issues and improving the code
The idea is that sponsors donate money to the bounty fund, and we will use that fund to hand out rewards for reported issues. It is a way for the curl project to help compensate researchers for the time and effort they spend helping us improving our security.
Right now the bounty fund is very small as we just started this project, but hopefully we can get a few sponsors interested and soon offer “proper” rewards at decent levels in case serious flaws are detected and reported here.
If you’re a company using curl or libcurl and value security, you know what you can do…
Already before, people who reported security problems could ask for money from Hackerone’s IBB program, and this new program is in addition to that – even though you won’t be able to receive money from both bounties for the same issue.
Q: You have launched a self-managed bug bounty program for the first time. Earlier, IBB used to pay out for most security issues in libcurl. How do you think the idea of self-management of a bug bounty program, which has some obvious problems such as active funding might eventually succeed?
First, this bounty program is run on bountygraph.com so I wouldn’t call it “self-managed” since we’re standing on a lot of infra setup and handled by others.
To me, this is an attempt to make a bounty program that is more visible as clearly a curl bounty program. I love Hackerone and the IBB program for what they offer, but it is A) very generic, so the fact that you can get money for curl flaws there is not easy to figure out and there’s no obvious way for companies to sponsor curl security research and B) they are very picky to which flaws they pay money for (“only critical flaws”) and I hope this program can be a little more accommodating – assuming we get sponsors of course.
Will it work and make any differences compared to IBB? I don’t know. We will just have to see how it plays out.
Q: How do you think the crowdsourcing model is going to help this bug bounty program?
It’s crucial. If nobody sponsors this program, there will be no money to do payouts with and without payouts there are no bounties. Then I’d call the curl bounty program a failure. But we’re also not in a hurry. We can give this some time to see how it works out.
My hope is though that because curl is such a widely used component, we will get sponsors interested in helping out.
Q: What would be the maximum reward for most critical a.k.a. P0 security vulnerabilities for this program?
Right now we have a total of 500 USD to hand out. If you report a p0 bug now, I suppose you’ll get that. If we just get sponsors, I’m hoping we should be able to raise that reward level significantly. I might be very naive, but I think we won’t have to pay for very many critical flaws.
It goes back to the previous question: this model will only work if we get sponsors.
Q: Do you feel there’s a risk that bounty hunters could turn malicious?
I don’t think this bounty program particularly increases or reduces that risk to any significant degree. Malicious hunters probably already exist and I would assume that blackhat researchers might be able to extract more money on the less righteous markets if they’re so inclined. I don’t think we can “outbid” such buyers with this program.
Q: How will this new program mutually benefit security researchers as well as the open source community around curl as a whole?
Again, assuming that this works out…
Researchers can get compensated for the time and efforts they spend helping the curl project to produce and provide a more secure product to the world.
curl is used by virtually every connected device in the world in one way or another, affecting every human in the connected world on a daily basis. By making sure curl is secure we keep users safe; users of countless devices, applications and networked infrastructure.
Update: just hours after this blog post, Dropbox chipped in 32,768 USD to the curl bounty fund…
The curl project is a project driven by volunteers with no financing at all except for a few sponsors who pay for the server hosting and for contributors to work on features and bug fixes on work hours. curl and libcurl are used widely by companies and commercial software so a fair amount of work is done by people during paid work hours.
This said, we don’t have any money in the project. Nada. Zilch. We can’t pay bug bounties or hire people to do specific things for us. We can only ask people or companies to volunteer things or services for us.
This is not a complaint – far from it. It works really well and we have a good stream of contributions, bugs reports and more. We are fortunate enough to make widely used software which gives our project a certain impact in the world.
I think more flaws in libcurl could’ve met the criteria, but I suspect more people than me haven’t been aware of this possibility for bounties.
I was glad to find out that this bounty program pays out money for libcurl issues and I hope it will motivate people to take an extra look into the inner workings of libcurl and help us improve.
What qualifies?
The bounty program is run and administered completely out of control or insight from the curl project itself and I must underscore that while libcurl issues can qualify, their emphasis is on fixing vulnerabilities in Internet software that have a potentially big impact.
To qualify for this bounty, vulnerabilities must meet the following criteria:
Be implementation agnostic: the vulnerability is present in implementations from multiple vendors or a vendor with dominant market share. Do not send vulnerabilities that only impact a single website, product, or project.
Be open source: finding manifests itself in at least one popular open source project.
In addition, vulnerabilities should meet most of the following criteria:
Be widespread: vulnerability manifests itself across a wide range of products, or impacts a large number of end users.
Have critical impact: vulnerability has extreme negative consequences for the general public.
Be novel: vulnerability is new or unusual in an interesting way.
If your libcurl security flaw matches this, go ahead and submit your request for a bounty. If you’re at a company using libcurl at scale, consider joining that program as a bounty sponsor!
A while ago Sourceforge gave me the offer to upgrade curl’s bug tracker to “the new one” they offer. They do offer some arguments to why you would want to do this but they don’t elaborate much on the transition for existing projects. Since I’ve been annoyed and disappointed on the old one for years I decided to dive right in. I decided to post this blog entry to possibly encourage others as well, or at least explain how upgrading worked for us.
I’ll start by explaining a bit about what’s so bad about the old Sourceforge bug tracker. Anyone who has tried to use it for anything “real” most likely already know about these things and then I figure my list can be used for a comparison if we’ve gotten annoyed by the same things.
They use a global bug id which makes all bug entries get very large numbers that aren’t in sequence and are fairly hard to remember.
You can’t respond to bug reports by mail, so you are forced to use the heavy ad-filled web site.
Ridiculous URLs to the bug tracker and each individual bug entry. I created a bounce CGI years ago on the curl web site to avoid having to use the overly long ones anywhere.
When sending out email notifications, it prepends the new comments while having the older ones below which basically is an odd-order top-posting style a lot of people and projects have a hard time to get accustomed to.
The new tracker addresses all of these issues and I agreed to allow it to make curl use their new tracker. And this is the outcome:
All the existing bug tracker entries were converted. They all now get numbered sequentially in a private number series so no more bug #31234234 and instead the 1100 or so bug reports became bug #1 to bug #1169.
The new bug entries have a different set of meta-data but the ‘status’ and ‘owner’ etc seemed to get translated pretty good. The new ‘milestone’ got populated wrongly for me, but it didn’t matter much to me because I simply cleared it.
There’s no visible way to translate from old style bug numbers to the new bug numbers. When I go to the URL for the old number it redirects me to the new bug so clearly sourceforge has created a look-up table it can use.
It splits up a the comments to a single report into several “pages” far too early and forces you to click through annoying “page 2” or “next page” links to see the latest comments.
Summary: the upgrade was totally worth it. A much better bug tracker with much more useful interfaces, both the web interface and the ability to respond to it by email etc. And still room for improvements!
yassl is a (in comparison) small SSL/TLS library that libcurl can be built to use instead of using one of the other SSL/TLS libraries libcurl supports (OpenSSL, GnuTLS, NSS and QSSL). However, yassl differs somewhat from the others in the way that it provides an OpenSSL-emulating API layer so that in libcurl we pretty much use exactly the same code for OpenSSL as we do for yassl.
yassl claimed this libcurl support for several years ago and indeed libcurl builds fine with it and you can even do some basic SSL operations with it, but the emulation is just not good enough to let the curl test suite go through so lots of stuff breaks when libcurl is built with yassl.
I did this same test 15 months ago and it had roughly the same problems then.
As far as I know, the other three main libraries are much more stable (the QSSL/QsoSSL library is only available on the AS/400 platform and thus I don’t personally know much about how it performs) and thus they remain the libraries I recommend users to select from if they want something that’s proven working.
On scan.coverity.com, the nice guys at Coverity run scans on open source projects to check for flaws in their source code. Their list currently includes 265 projects, and curl is one of them. I have only good words to say about their scanning, as they found no less than 27 flaws in curl 7.16.1 and only one of them was a false positive. All the others were valid and true flaws that we could fix. I don’t think anyone was any serious security risk, but still. 26 bugs detected in one go.
On January 8th 2008, Coverity announced their “rung 2” for eleven projects that had zero flaws left in rung 1 and the rung 2 projects get an upgraded analysis. curl was also at zero flaws left, but it isn’t clear to me what else we could to do to reach rung 2 or even how we can get them to do a follow-up scan on a newer release since 7.16.1 is quite old by now and with all the changes in the code over time there’s always the risk new nasty bugs have crept in… So we’re at rung 1 still with no recent release scanned.







 I think more flaws in libcurl could’ve met the criteria, but I suspect more people than me haven’t been aware of this possibility for bounties.
I think more flaws in libcurl could’ve met the criteria, but I suspect more people than me haven’t been aware of this possibility for bounties.