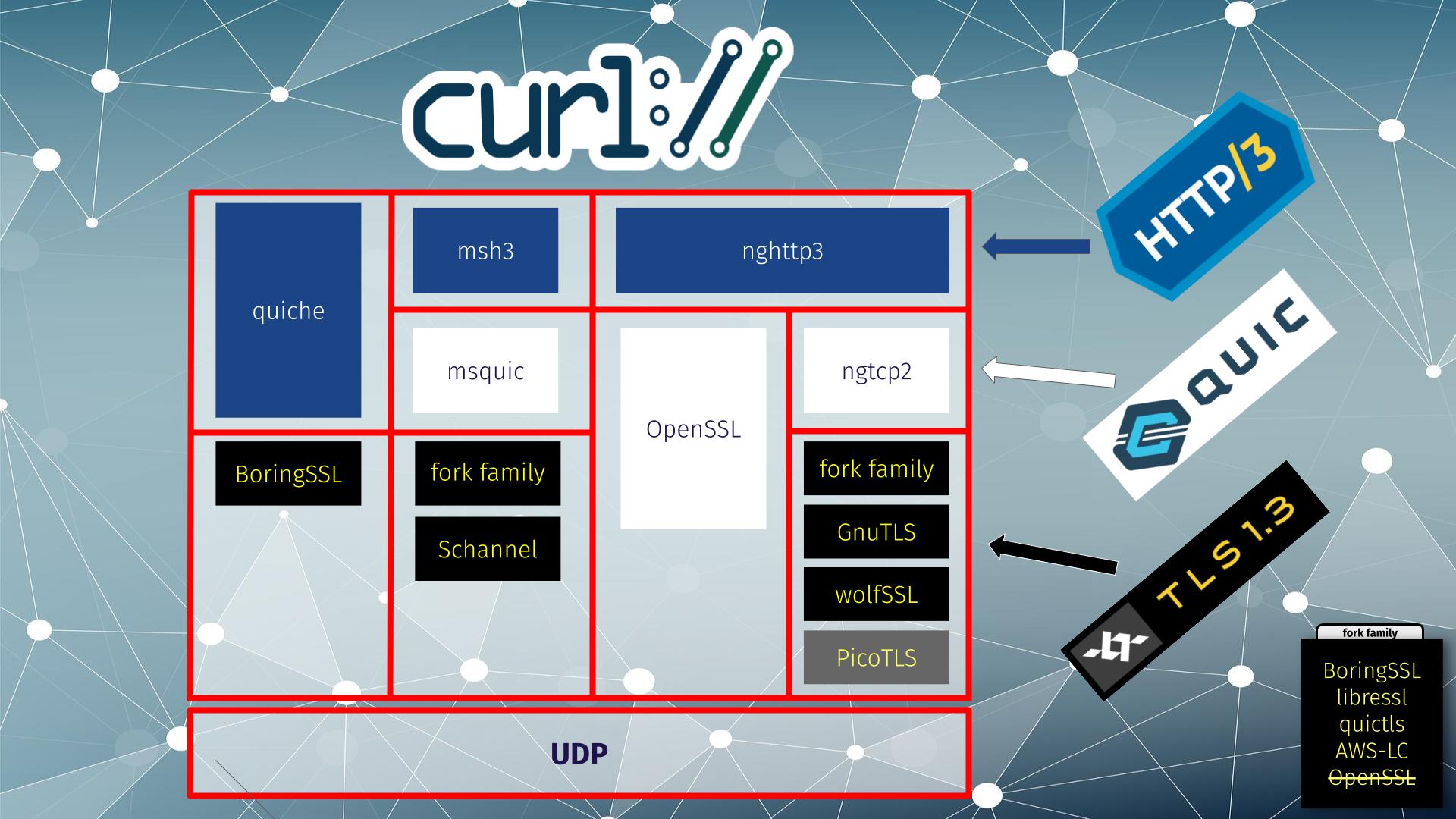
There is again a pull-request submitted to the curl project to bring support for the Gemini protocol. It seems like a worthwhile effort that I support, even if it is also a lot of work involved and it might take some time before it reaches the state in which it can be merged. A previous attempt at doing this was abandoned a while ago.
This renewed interest made me take a fresh tour through the current Gemini protocol spec and I decided to write down some observations for you. So here I am. These are comments based on my reading of the 0.16.1 version of the protocol spec. I have implemented Internet application protocols client side for some thirty years. I have not actually implemented the Gemini protocol.
Motivations for existence
Gemini is the result of a kind of a movement that tries to act against some developments they think are wrong on the current web. Gemini is not only a new wire protocol, but also features a new documentation format and more. They also say its not “the web” at all but a new thing. As a sign of this, the protocol is designed by the pseudonymous “Solderpunk” – and the IETF or other suitable or capable organizations have not been involved – and it shows.
Counter surveillance
Gemini has no cookies, no negotiations, no authentication, no compression and basically no (other) headers either in a stated effort to prevent surveillance and tracking. It instead insists on using TLS client certificates (!) for keeping state between requests.
A Gemini response from a server is just a two-digit response code, a single media type and the binary payload. Nothing else.
Reduce complexity
They insist that thanks to reduced complexity it enables more implementations, both servers and clients, and that seems logical. The reduced complexity however also makes it less visually pleasing to users and by taking shortcuts in the protocol, it risks adding complexities elsewhere instead. Its quite similar to going back to GOPHER.
Form over content
This value judgement is repeated among Gemini fans. They think “the web” favors form over content and they say Gemini intentionally is the opposite. It seems to be true because Gemini documents certainly are never visually very attractive. Like GOPHER.
But of course, the protocol is also so simple that it lacks the power to do a lot of things you can otherwise do on the web.
The spec
The only protocol specification is a single fairly short page that documents the over-the-wire format mostly in plain English (undoubtedly featuring interpretation conflicts), includes the URL format specification (very briefly) and oddly enough also features the text/gemini media type: a new document format that is “a kind of lightweight hypertext format, which takes inspiration from gophermaps and from Markdown“.
The spec says “Although not finalised yet, further changes to the specification are likely to be relatively small.” The protocol itself however has no version number or anything and there is no room for doing a Gemini v2 in a forward-compatible way. This way of a “living document” seems to be popular these days, even if rather problematic for implementers.
Gopher revival
The Gemini protocol reeks of GOPHER and HTTP/0.9 vibes. Application protocol style anno mid 1990s with TLS on top. Designed to serve single small text documents from servers you have a relation to.
Short-lived connections
The protocol enforces closing the connection after every response, forcibly making connection reuse impossible. This is terrible for performance if you ever want to get more than one resource off a server. I also presume (but there is no mention of this in the spec) that they discourage use of TLS session ids/tickets for subsequent transfers (since they can be used for tracking), making subsequent transfers even slower.
We know from HTTP and a primary reason for the introduction of HTTP/1.1 back in 1997 that doing short-lived bursty TCP connections makes it almost impossible to reach high transfer speeds due to the slow-starts. Also, re-doing the TCP and TLS handshakes over and over could also be seen a plain energy waste.
The main reason they went with this design seem to be to avoid having a way to signal the size of payloads or do some kind of “chunked” transfers. Easier to document and to implement: yes. But also slower and more wasteful.
Serving an average HTML page using a number of linked resources/images over this protocol is going to be significantly slower than with HTTP/1.1 or later. Especially for servers far away. My guess is that people will not serve “normal” HTML content over this protocol.
Gemini only exists done over TLS. There is no clear text version.
GET-only
There are no other methods or ways to send data to the server besides the query component of the URL. There are no POST or PUT equivalents. There is basically only a GET method. In fact, there is no method at all but it is implied to be “GET”.
The request is also size-limited to a 1024 byte URL so even using the query method, a Gemini client cannot send much data to a server. More on the URL further down.
Query
There is a mechanism for a server to send back a single-line prompt asking for “text input” which a client then can pass to it in the URL query component in a follow-up request. But there is no extra meta data or syntax, just a single line text prompt (no longer than 1024 bytes) and free form “text” sent back.
There is nothing written about how a client should deal with the existing query part in this situation. Like if you want to send a query and answer the prompt. Or how to deal with the fact that the entire URL, including the now added query part, still needs to fit within the URL size limit.
Better use a short host name and a short path name to be able to send as much data as possible.
TOFU
the strongly RECOMMENDED approach is to implement a lightweight “TOFU” certificate-pinning system which treats self-signed certificates as first- class citizens.
(From the Gemini protocol spec 0.16.1 section 4.2)
Trust on first use (TOFU) as a concept works fairly well when you interface a limited set of servers with which you have some relationship. Therefore it often works fine for SSH for example. (I say “fine” for even with ssh, people often have the habit of just saying yes and accepting changed keys even when they perhaps should not.)
There are multiple problems with doing TOFU for a client/server document browsing system like Gemini.
A challenge is of course that on the first visit a client cannot spot an impostor, and neither can it when the server updates its certificates down the line. Maybe an attacker did it? It trains users on just saying “yes” when asked if they should trust it. Since you as a user might not have a clue about how runs that particular server or whatever the reason is why the certificate changes.
The concept of storing certificates to compare against later is a scaling challenge in multiple dimensions:
- Certificates need to be stored for a long time (years?)
- Each host name + port number combination has its own certificate. In a world that goes beyond thousands of Gemini hosts, this becomes a challenge for clients to deal with in a convenient (and fast) manner.
- Presumably each user on a system has its own certificate store. What user A trusts, user B does not necessarily have to trust.
- Does each Gemini client keep its own certificate store? Do they share? Who can update? How do they update the store? What’s the file format? A common db somehow?
- When storing the certificates, you might also want to do like modern SSH does: not store the host names in cleartext as it is a rather big privacy leak showing exactly which servers you have visited.
I strongly suspect that many existing Gemini clients avoid this huge mess by simply not verifying the server certificates at all or by just storing the certificates temporarily in memory.
You can opt to store a hash or fingerprint of the certificate instead of the whole one, but that does not change things much.
I think insisting on TOFU is one of Gemini’s weakest links and I cannot see how this system can ever scale to a larger audience or even just many servers. I foresee that they need to accept Certificate Authorities or use DANE in a future.
Gemini Proxying
By insisting on passing on the entire URL in the requests, it is primarily a way to solve name based virtual hosting, but it is also easy for a Gemini server to act as a proxy for other servers. On purpose. And maybe I should write “easy”.
Since Gemini is (supposed to be) end-to-end TLS, proxying requests to another server is not actually possible while also maintaining security. The proxy would have to for example respond with the certificate retrieved from the remote server (in addition to its own) but the spec mentions nothing of this so we can guess existing clients and proxies don’t do it. I think this can be fixed by just adjusting the spec. But would add some rather kludgy complexity for a maybe a not too exciting feature.
Proxying to gopher:// URLs should be possible with the existing wording because there is no TLS to the server end. It could also proxy http:// URLs too but risk having to download the entire thing first before it can send the response.
URLs
The Gemini URL scheme is explained in 138 words, which is of course very terse and assumes quite a lot. It includes “This scheme is syntactically compatible with the generic URI syntax defined in RFC 3986“.
The spec then goes on to explain that the URL needs be UTF-8 encoded when sent over the wire, which I find peculiar because a normal RFC 3986 URL is just a set of plain octets. A Gemini client thus needs to know the charset that was used for or to assume for the original URL in order to convert it to UTF-8.
Example: if there is a %C5 in the URL and the charset was ISO-8859-1. That means the octet is a LATIN CAPITAL LETTER A WITH RING ABOVE. The UTF-8 version of said character is the two-byte sequence 0xC3 0x85. But if the original charset instead was ISO-8859-6, the same %C5 octet means ARABIC LETTER ALEF WITH HAMZA BELOW, encoded as 0xD8 0xA5 in UTF-8.
To me this does not rhyme well with reduced complexity. This conversion alone will cause challenges when done in curl because applications pass an RFC 3986 URL to the library and it does not currently have enough information on how to convert that to UTF-8. Not to mention that libcurl completely lacks UTF-8 conversion functions.
This makes me suspect that the intention is probably that only the host name in the URL should be UTF-8 encoded for IDN reasons and the rest should be left as-is? The spec could use a few more words to explain this.
One of the Gemini clients that I checked out to see how they do this, in order to better understand the spec, even use the punycode version of the host name quoting “Pending possible Gemini spec change”. What is left to UTF-8 then? That client did not UTF-8 encode anything of the URL, which adds to my suspicion that people don’t actually follow this spec detail but rather just interoperate…
The UTF-8 converted version of the URL must not be longer than 1024 bytes when included in a Gemini request.
The fact that the URL size limit is for the UTF-8 encoded version of the URL makes it hard to error out early because the source version of the URL might be shorter than 1024 bytes only to have it grow past the size limit in the encoding phase.
Origin
The document is carelessly thinking “host name” is a good authority boundary to TLS client certificates, totally ignoring the fact that “the web” learned this lesson long time ago. It needs to restrict it to the host name plus port number. Not doing that opens up Gemini for rather bad security flaws. This can be fixed by improving the spec.
Media type
The text/gemini media type should simply be moved out the protocol spec and be put elsewhere. It documents content that may or may not be transferred over Gemini. Similarly, we don’t document HTML in the HTTP spec.
Misunderstandings?
I am fairly sure that once I press publish on this blog post, some people will insist that I have misunderstood parts or most of the protocol spec. I think that is entirely plausible and kind of my point: the spec is written in such an open-ended way that it will not avoid this. We basically cannot implement this protocol by only reading the spec.
Future?
It is impossible to tell if this will fly for real or not. This is not a protocol designed for the masses to replace anything at high volumes. That is of course totally fine and it can still serve its community perfectly fine. There seems to be interest enough to keep the protocol and ecosystem alive for the moment at least. Possibly for a long time into the future as well.
What I would change
As I believe you might have picked up by now, I am not a big fan of this protocol but I still believe it can work and serve its community. If anyone would ask me, here are a few things I would consider changing in order to take it up a few notches.
- Split the spec into three separate ones: protocol, URL syntax, media type. Expand the protocol parts with more exact syntax descriptions and examples to supplement the English.
- Clarify the client certificate use to be origin based, not host name.
- Drop the TOFU idea, it makes for a too weak security story that does not scale and introduces massive complexities for clients.
- Clarify the UTF-8 encoding requirement for URLs. It is confusing and possibly bringing in a lot of complexity. Simplify?
- Clarify how proxying is actually supposed to work in regards to TLS and secure connections. Maybe drop the proxy idea completely to keep the simplicity.
- Consider a way to re-use connections, even if that means introducing some kind of “chunks” HTTP-style.
Discussion
Hacker news