You can of course use curl to access hosts through Tor. (I know you know Tor so I am not going to explain it here.)
SOCKS
The typical way to access Tor is via a SOCKS5 proxy and curl has supported that since some time during 2002. Like this:
curl --socks5-hostname localhost:5432 https://example.com
or
curl --proxy socks5h://localhost:5432 https://example.com
or
export HTTPS_PROXY=socks5h://localhost:5432
curl https://example.com
Name resolving with SOCKS5
You know Tor, but do you know SOCKS5? It is an old and simple protocol for setting up a connection and when using it, the client can decide to either pass on the full hostname it wants to connect to, or it can pass on the exact IP address.
(SOCKS5 is by the way a minor improvement of the SOCKS4 protocol, which did not support IPv6.)
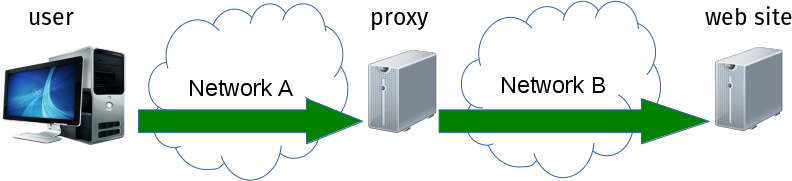
When you use curl, you decide if you want curl or the proxy to resolve the target hostname. If you connect to a site on the public Internet it might not even matter who is resolving it as either party would in theory get the same set of IP addresses.
The .onion TLD
There is a concept of “hidden” sites within the Tor network. They are not accessible on the public Internet. They have names in the .onion top-level domain. For example. the search engine DuckDuckGo is available at https://duckduckgogg42xjoc72x3sjasowoarfbgcmvfimaftt6twagswzczad.onion/.
.onion names are used to provide access to end to end encrypted, secure, anonymized services; that is, the identity and location of the server is obscured from the client. The location of the client is obscured from the server.
To access a .onion host, you must let Tor resolve it because a normal DNS server aware of the public Internet knows nothing about it.
This is why we recommend you ask the SOCKS5 proxy to resolve the hostname when accessing Tor with curl.
The proxy connection
The SOCKS5 protocol is clear text so you must make sure you do not access the proxy over a network as then it will leak the hostname to eavesdroppers. That is why you see the examples above use localhost for the proxy.
You can also step it up and connect to the SOCKS5 proxy over unix domain sockets with recent curl versions like this:
curl --proxy socks5h://localhost/run/tor/socks https://example.com
.onion leakage
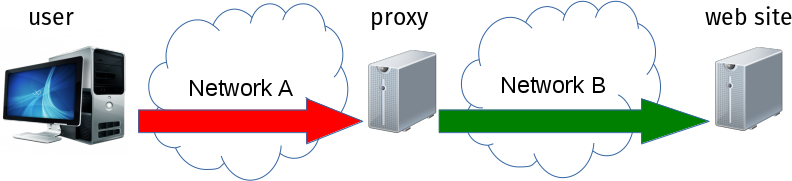
Sites using the .onion TLD are not on the public Internet and it is pointless to ask your regular DNS server to resolve them. Even worse: if you in fact ask your normal resolver you practically advertise your intention of connection to a .onion site and you give the full name of that site to the outsider. A potentially significant privacy leak.
To combat the leakage problem, RFC 7686 The “.onion” Special-Use Domain Name was published in October 2015. With the involvement and consent from people involved in the Tor project.
It only took a few months after 7686 was published until there was an accurate issue filed against curl for leaking .onion names. Back then, in the spring of 2016, no one took upon themselves to fix this and it was instead simply added to the queue of known bugs.
This RFC details (among other things) how libraries should refuse to resolve .onion host names using the regular means in order to avoid the privacy leak.
After having stewed in the known bugs lists for almost five years, it was again picked up in 2023, a pull-request was authored, and when curl 8.1.0 shipped on May 17 2023 curl refused to resolve .onion hostnames.
Tor still works remember?
Since users are expected to connect using SOCKS5 and handing over the hostname to the proxy, the above mention refusal to resolve a .onion address did not break the normal Tor use cases with curl.
Turns out there are other common ways to do it.
A few days before the 8.1.0 release shipped a discussion thread was created: I want to resolve onion addresses.
Every change breaks someone’s workflow

Transparent proxies
Turns out there is a group of people who runs transparent proxies who automatically “catches” all local traffic and redirects it over Tor. They have a local DNS server who can resolve .onion host names and they intercept outgoing traffic to instead tunnel it through Tor.
With this setup now curl no longer works because it will not send .onion addresses to the local resolver because RFC 7686 tells us we should not,
curl of course does not know when it runs in a presumed safe and deliberate transparent proxy network or when it does not. When a leak is not a leak or when it actually is a leak.
torsocks
A separate way to access tor is to use the torsocks tool. Torsocks allows you to use most applications in a safe way with Tor. It ensures that DNS requests are handled safely and explicitly rejects any traffic other than TCP from the application you’re using.
You run it like
torsocks curl https://example.com
Because of curl’s new .onion filtering, the above command line works fine for “normal” hostnames but no longer for .onion hostnames.
Arguably, this is less of a problem because when you use curl you typically don’t need to use torsocks since curl has full SOCKS support natively.
Option to disable the filter?
In the heated discussion thread we are told repeatedly how silly we are who block .onion name resolves – exactly in the way the RFC says, the RFC that had the backing and support from the Tor project itself. There are repeated cries for us to add ways to disable the filter.
I am of course sympathetic with the users whose use cases now broke.
A few different ways to address this have been proposed, but the problem is difficult: how would curl or a user know that it is fine to leak a name or not? Adding a command line option to say it is okay to leak would just mean that some scripts would use that option and users would run it in the wrong conditions and your evil malicious neighbors who “help out” will just add that option when they convince their victims to run an innocent looking curl command line.
The fact that several of the louder voices show abusive tendencies in the discussion of course makes these waters even more challenging to maneuver.
Future
I do not yet know how or where this lands. The filter has now been in effect in curl for a year. Nothing is forever, we keep improving. We listen to feedback and we are of course eager to make sure curl remains and awesome tool and library also for content over Tor.
This discussion is also held within the more proper realms of the tor project itself.