(See how I cleverly did not mention AI in the title!)
You know we have seen more than our fair share of slop reports sent to the curl project so it seems only fair that I also write something about the state of AI when we get to enjoy some positive aspects of this technology.
Let’s try doing this in a chronological order.
The magnitude of things
curl is almost 180,000 lines of C89 code, excluding blank lines. About 637,000 words in C and H files.
To compare, the original novel War and Peace (a thick book) consists of 587,000 words.
The first ideas and traces for curl originated in the httpget project, started in late 1996. Meaning that there is a lot of history and legacy here.
curl does network transfers for 28 URL schemes, it has run on over 100 operating systems and on almost 30 CPU architectures. It builds with a wide selection of optional third party libraries.
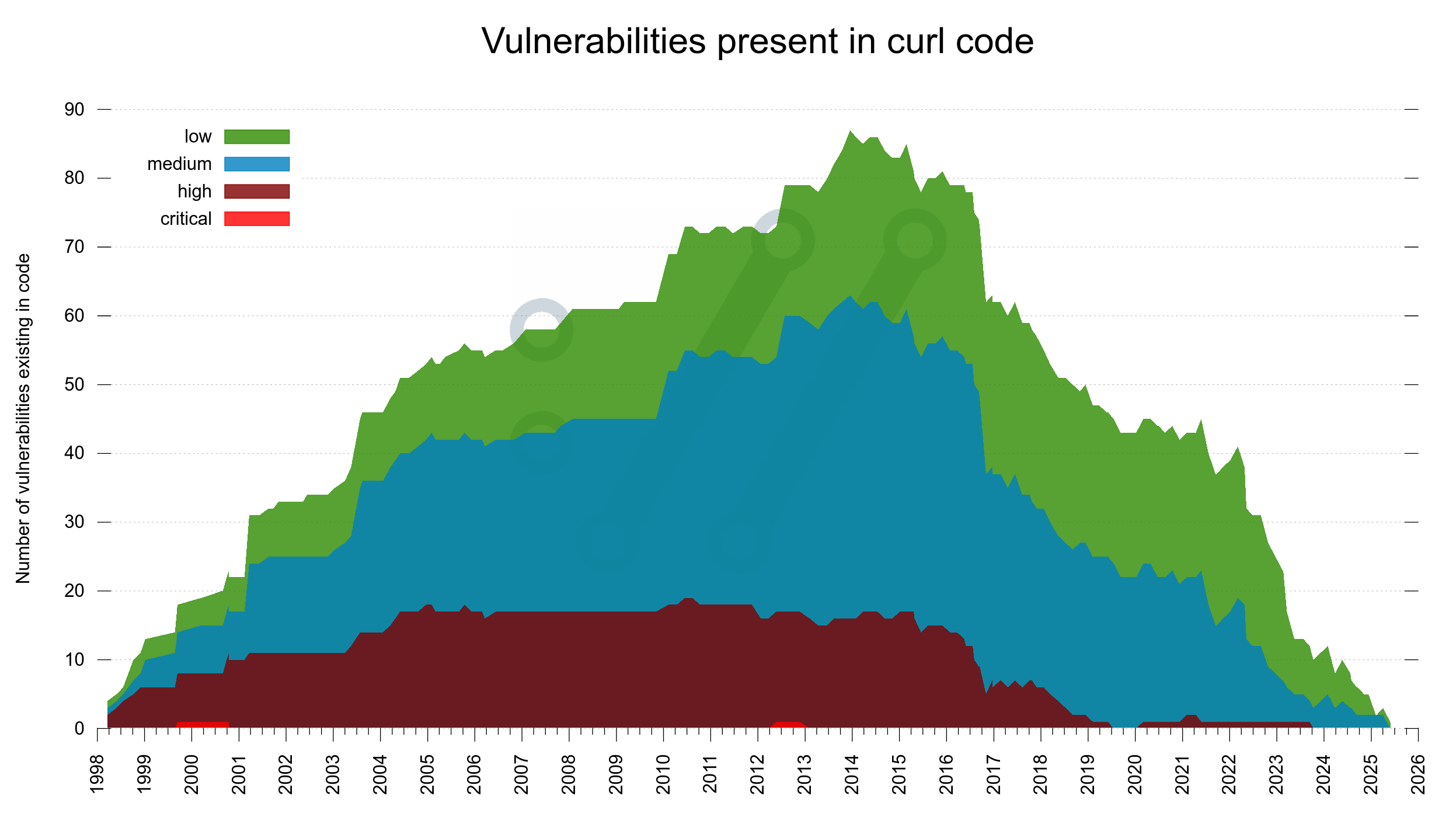
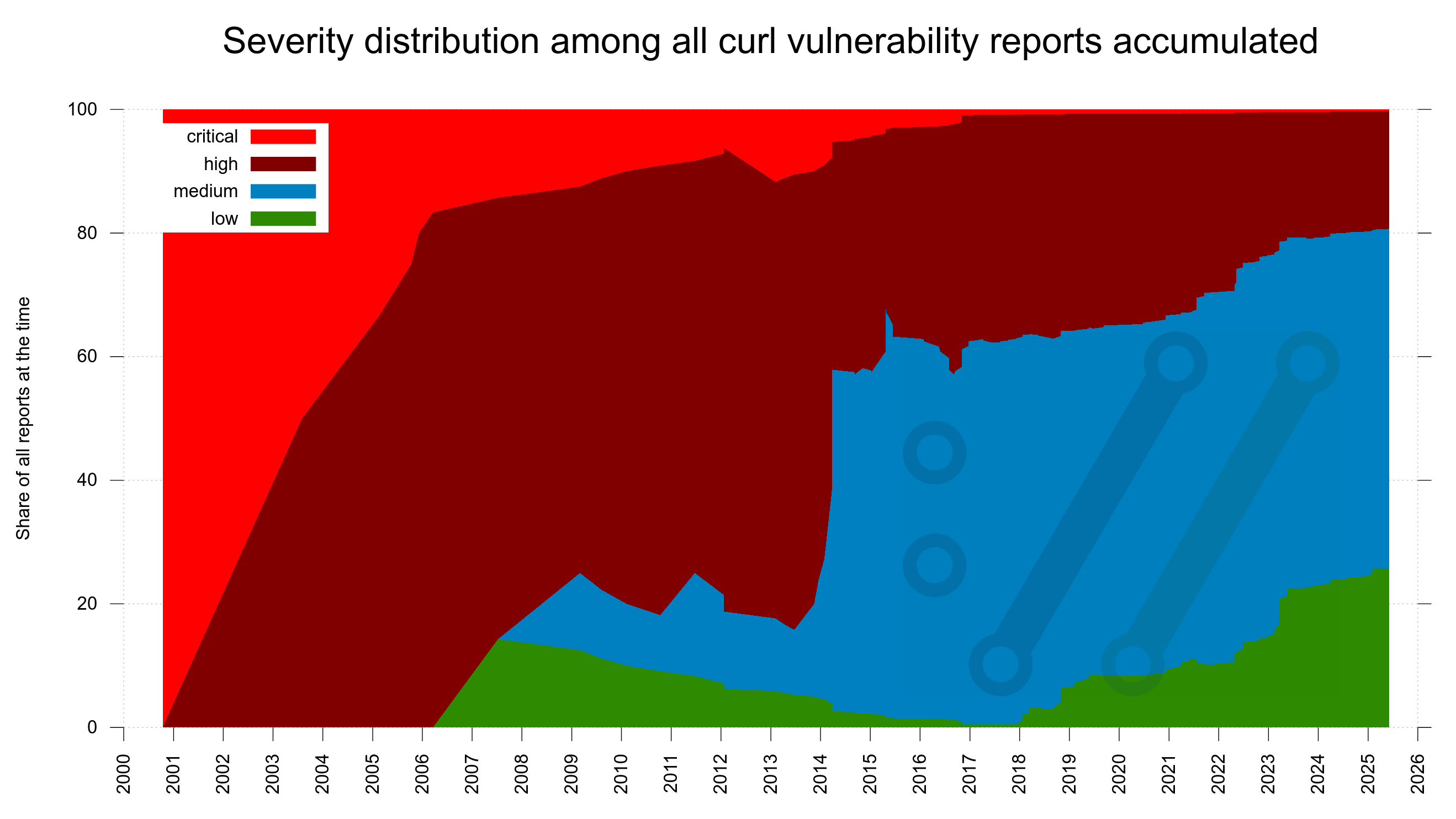
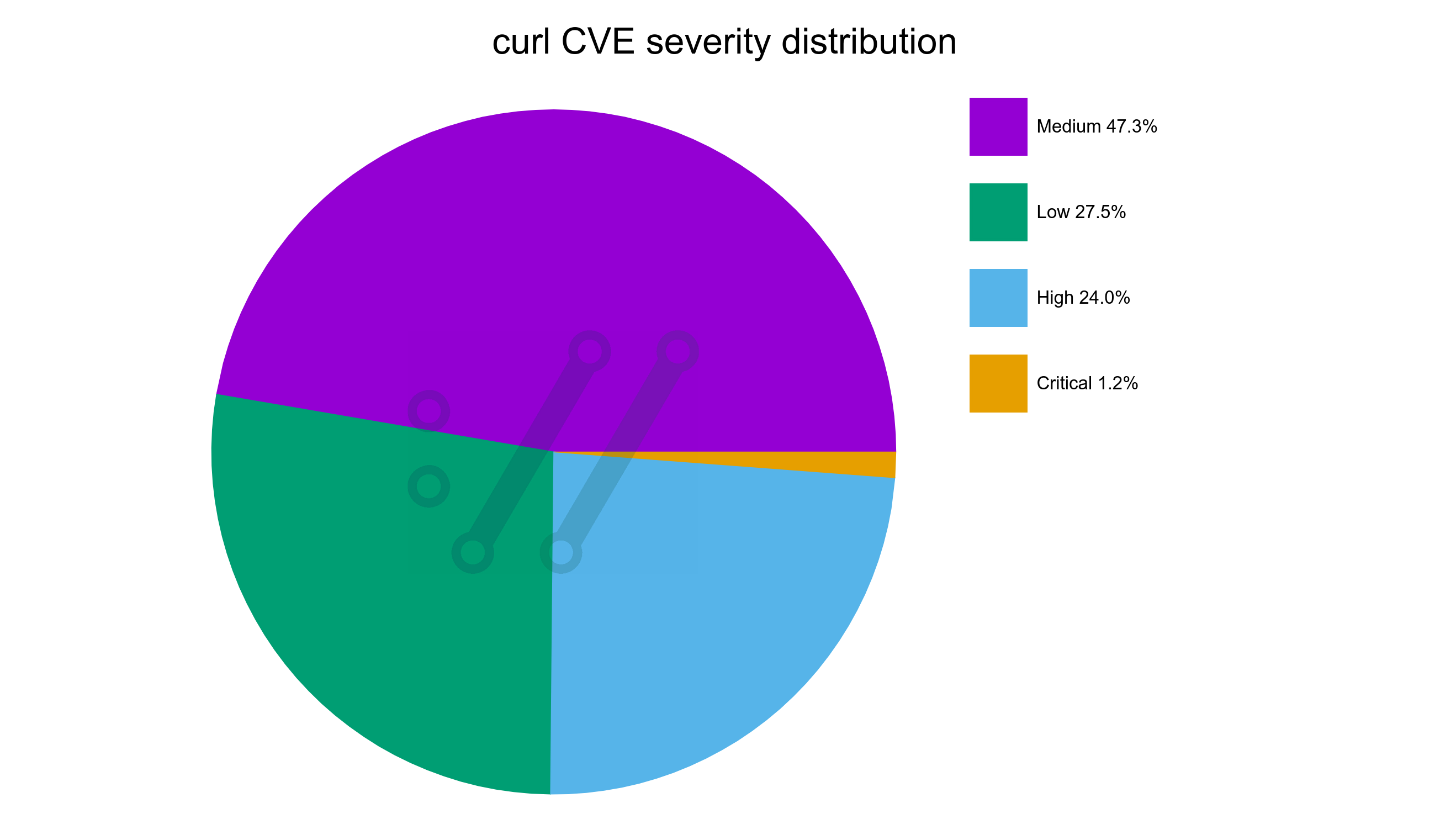
We have shipped over 270 curl releases for which we have documented a total of over 12,500 bugfixes. More than 1,400 humans have contributed with commits merged into the repository, over 3,500 humans are thanked for having helped out.
It is a very actively developed project.
It started with sleep
On August 11, 2025 there was a curl vulnerability reported against curl that would turn out legitimate and it would later be published as CVE-2025-9086. The reporter of this was the Google Big Sleep team. A team that claims they use “an AI agent developed by Google DeepMind and Google Project Zero, that actively searches and finds unknown security vulnerabilities in software”.
This was the first ever report we have received that seems to have used AI to accurately spot and report a security problem in curl. Of course, we don’t know how much AI and how much human that were involved in the research and the report. The entire reporting process felt very human.
krb5-ftp
In mid September 2025 we got new a security vulnerability reported against curl from a security researcher we had not been in contact with before.
The report which accurately identified a problem, was not turned into a CVE only because of sheer luck: the code didn’t work for other reasons so the vulnerability couldn’t actually be reached. As a direct result of this lesson, we ripped out support for krb5-ftp.
ZeroPath
The reporter of the krb5-ftp problem is called Joshua Rogers. He contacted us and graciously forwarded us a huge list of more potential issues that he had extracted. As I understand it, mostly done with the help of ZeroPath. A code analyzer with AI powers.
In the curl project we continuously run compilers with maximum pickiness enabled and we throw scan-build, clang-tidy, CodeSonar, Coverity, CodeQL and OSS-Fuzz at it and we always address and fix every warning and complaint they report so it was a little surprising that this tool now suddenly could produce over two hundred new potential problems. But it sure did. And it was only the beginning.
At three there is a pattern
As we started to plow through the huge list of issues from Joshua, we received yet another security report against curl. This time by Stanislav Fort from Aisle (using their own AI powered tooling and pipeline for code analysis). Getting security reports is not uncommon for us, we tend to get 2 -3 every week, but on September 23 we got another one we could confirm was a real vulnerability. Again, an AI powered analysis tool had been used. (At the time I write this blog entry, this particular issue has not been disclosed yet so I can’t link it.)
A shift in the wind
As I was amazed by the quality and insights in some of the issues in Joshua’s initial list he sent over I tooted about it on Mastodon, which later was picked up by Hacker news, The Register, Elektroniktidningen and more.
These new reported issues feel quite similar in nature to defects reported by code analyzers typically do: small mistakes, omissions, flaws, bugs. Most of them are just plain variable mixups, return code confusions, small memory leaks in weird situations, state transition mistakes and variable type conversions possibly leading to problems etc. Remarkably few of them complete false positives.
The quality of the reports make it feel like a new generation of issue identification. Like in this ladder of tool evolution from the old days. Each new step has taken the notch up a level:
- At some point I think starting in the early 2000s, the C compilers got better at actually warning and detecting many mistakes they just silently allowed back in the dark ages
- Then the code analyzers took us from there to the next level and found more mistakes in the code.
- We added fuzzing to the mix in the mid 2010s and found a whole slew of problems we never realized before we had.
- Now this new breed, almost like a new category, of analyzers that seem to connect the dots better and see patterns previous tools and analyzers have not been able to. And tell us about the discrepancies.
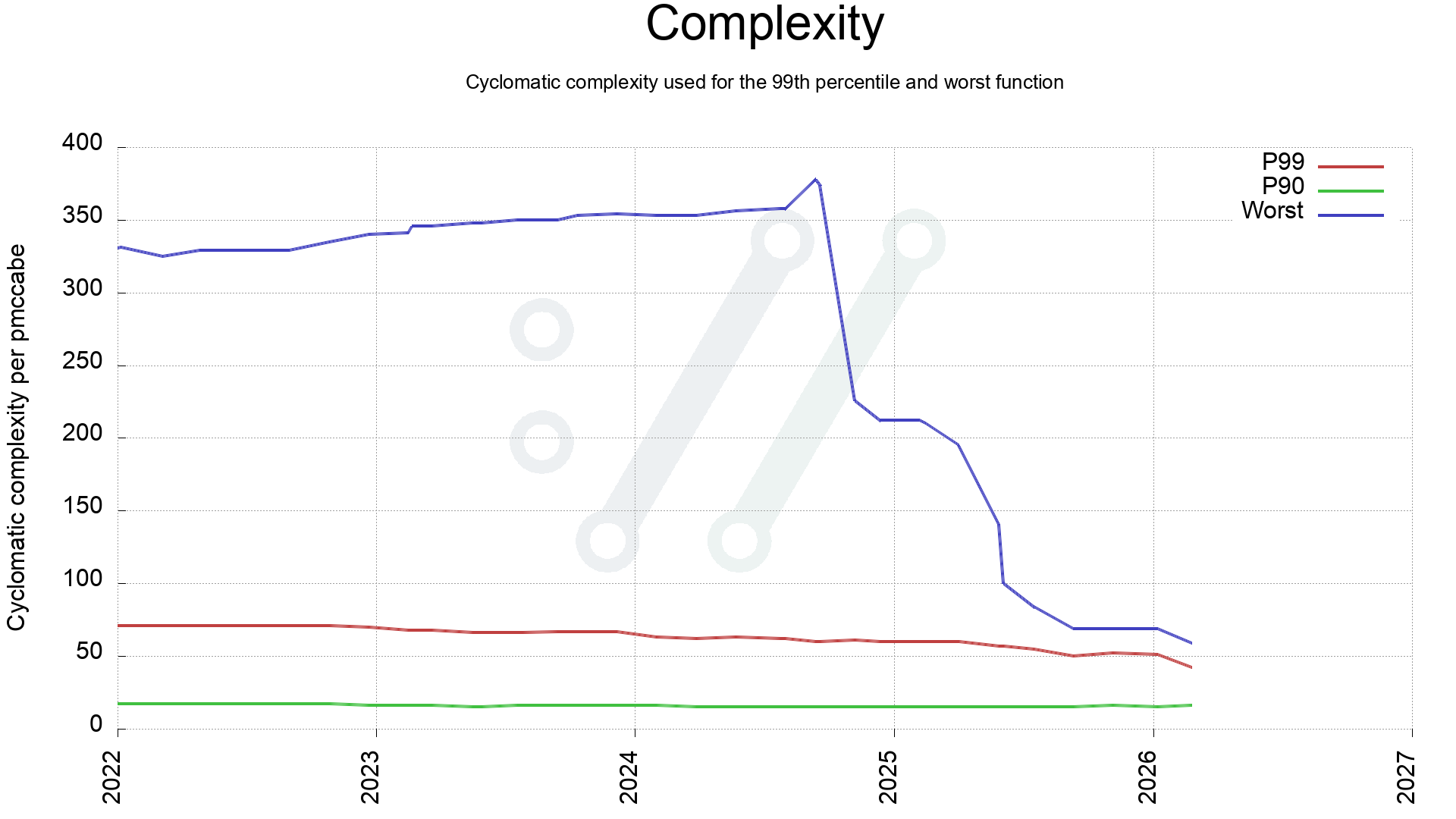
25% something
Out of that initial list, we merged about 50 separately identifiable bugfixes. The rest were some false positives but also lots of minor issues that we just didn’t think were worth poking at or we didn’t quite agree with.
A minor tsunami
We (primarily Stefan Eissing and myself) worked hard to get through that initial list from Joshua within only a couple of days. A list we mistakenly thought was “it”.
Joshua then spiced things up for us by immediately delivering a second list with 47 additional issues. Follow by a third list with yet another 158 additional potential problems. At the same time Stanislav did the similar thing and delivered to us two lists with a total of around twenty possible issues.
Don’t take me wrong. This is good. The issues are of high quality and even the ones we dismiss often have some insights and the rate of obvious false positive has remained low and quite manageable. Every bug we find and fix makes curl better. Every fix improves a software that impacts and empowers a huge portion of the world.
The total amount of suspected issues submitted by these two gentlemen are now at over four hundred. A fair pile of work for us curl maintainers!
Because how these reported issues might include security sensitive problems, we have decided to not publish them but limit access to the reporters and the curl security team.
As I write this, we are still working our way through these reports but it feels reasonable to assume that we will get even more soon…
All code
An obvious and powerful benefit this tool seems to have compared to others is that it scans all source code without having a build. That means it can detect problems in all backends used in all build combinations. Old style code analyzers require a proper build to analyze and since you can build curl in countless combinations with a myriad of backend setups (where several are architecture or OS specific), it is literally impossible to have all code analyzed with such tools.
Also, these tools can inject (parts of) third party libraries as well and find issues in the borderland between curl and its dependencies.
I think this is one primary reason it found so many issues: it checked lots of code barely any other analyzers have investigated.
A few examples
To illustrate the level of “smartness” in this tool, allow me to show a few examples that I think shows it off. These are issues reported against curl in the last few weeks and they have all been fixed. Beware that you might have to understand a thing or two about what curl does to properly follow here.
A function header comment was wrong
It correctly spotted that the documentation in the function header incorrectly said an argument is optional when in reality it isn’t. The fix was to correct the comment.
# `Curl_resolv`: NULL out-parameter dereference of `*entry`
* **Evidence:** `lib/hostip.c`. API promise: "returns a pointer to the entry in the `entry` argument (**if one is provided**)." However, code contains unconditional writes: `*entry = dns;` or `*entry = NULL;`.
* **Rationale:** The API allows `entry == NULL`, but the implementation dereferences it on every exit path, causing an immediate crash if a caller passes `NULL`.
I could add that the fact that it takes comments so seriously can also trick it to report wrong things when the comments are outdated and state bad “facts”. Which of course shouldn’t happen because comments should not lie!
code breaks the telnet protocol
It figured out that a piece of telnet code actually wouldn’t comply with the telnet protocol and pointed it out. Quite impressively I might add.
Telnet subnegotiation writes unescaped user-controlled values (tn->subopt_ttype, tn->subopt_xdisploc, tn->telnet_vars) into temp (lines 948–989) without escaping IAC (0xFF)
In lib/telnet.c (lines 948–989) the code formats Telnet subnegotiation payloads into temp using msnprintf and inserts the user-controllable values tn->subopt_ttype (lines 948–951), tn->subopt_xdisploc (lines 960–963), and v->data from tn->telnet_vars (lines 976–989) directly into the suboption data. The buffer temp is then written to the socket with swrite (lines 951, 963, 995) without duplicating CURL_IAC (0xFF) bytes. Telnet requires any IAC byte inside subnegotiation data to be escaped by doubling; because these values are not escaped, an 0xFF byte in any of them will be interpreted as an IAC command and can break the subnegotiation stream and cause protocol errors or malfunction.
no TFTP address pinning
Another case where it seems to know the best-practice for a TFTP implementation (pinning the used IP address for the duration of the transfer) and it detected that curl didn’t apply this best-practice in code so it correctly complained:
No TFTP peer/TID validation
The TFTP receive handler updates state->remote_addr from recvfrom() on every datagram and does not validate that incoming packets come from the previously established server address/port (transfer ID). As a result, any host able to send UDP packets to the client (e.g., on-path attacker or local network adversary) can inject a DATA/OACK/ERROR packet with the expected next block number. The client will accept the payload (Curl_client_write), ACK it, and switch subsequent communication to the attacker’s address, allowing content injection or session hijack. Correct TFTP behavior is to bind to the first server TID and ignore, or error out on, packets from other TIDs.
memory leaks no one else reported
Most memory leaks are reported when someone runs code and notices that not everything is freed in some specific circumstance. We of course test for leaks all the time in tests, but in order to see them in a test we need to run that exact case and there are many code paths that are hard to travel in tests.
Apart from doing tests you can of course find leaks by manually reviewing code, but history and experience tell us that is an error-prone method.
# GSSAPI security message: leaked `output_token` on invalid token length
* **Evidence:** `lib/vauth/krb5_gssapi.c:205--207`. Short quote:
```c
if(output_token.length != 4) { ... return CURLE_BAD_CONTENT_ENCODING; }
```
The `gss_release_buffer(&unused_status, &output_token);` call occurs later at line 215, so this early return leaks the buffer from `gss_unwrap`.
* **Rationale:** Reachable with a malicious peer sending a not-4-byte security message; repeated handshakes can cause unbounded heap growth (DoS).
This particular bug looks straight forward and in hindsight easy enough to spot, but it has existed like this in plain sight in code for over a decade.
More evolution than revolution
I think I maybe shocked some people when I stated that the AI tooling helped us find 22, 70 and then a 100 bugs etc. I suspect people in general are not aware of and does not think about what kind of bugfix frequency we work on in this project. Fixing several hundred bugs per release is a normal rate for us. Sure, this cycle we will probably reach a new record, but I still don’t grasp for breath because of this.
I don’t consider this new tooling a revolution. It does not massively or drastically change code or how we approach development. It is however an excellent new project assistant. A powerful tool that highlights code areas that need more attention. A much appreciated evolutionary step.
I might of course be speaking too early. Perhaps it will develop a lot more and it can then turn into a revolution.
Ethical and moral decisions
The AI engines burn the forests and they are built by ingesting other people’s code and work. Is it morally and ethically right to use AI for improving Open Source in this way? It is a question to wrestle with and I’m sure the discussion will go on. At least this use of AI does not generate duplicates of someone else’s code for us to use, but it certainly takes lessons from and find patterns based on others’ code. But so do we all, I hope.
Starting from a decent state
I can imagine that curl is a pretty good source code to use a tool of this caliber on, as curl is old, mature and all the minor nits and defect have been polished away. It is a project where we have a high bar and we want to raise it even higher. We love the opportunity to get additional help and figure out where we might have slipped. Then fix those and try again. Over and over until the end of time.
AIxCC
At the DEF CON 33 conference which took place in August 2025, DARPA ran a competition called the AI Cyber Challenge or AIxCC for short. In this contest, the competing teams used AI tools to find artificially injected vulnerabilities in projects – with zero human intervention. One of the projects used in the finals that the teams looked for problems in, was… curl!
I have been promised a report or a list of findings from that exercise, as presumably the teams found something more than just the fake inserted problems. I will report back when that happens.
Going forward
We do not yet have any AI powered code analyzer in our CI setup, but I am looking forward to adding such. Maybe several.
We can ask GitHub copilot for pull-request reviews but from the little I’ve tried copilot for reviews it is far from comparable to the reports I have received from Joshua and Stanislav, and quite frankly it has been mostly underwhelming. We do not use it. Of course, that can change and it might turn into a powerful tool one day.
We now have an established constructive communication setup with both these reporters, which should enable a solid foundation for us to improve curl even more going forward.
I personally still do not use any AI at all during development – apart from occasional small experiments. Partly because they all seem to force me into using VS code and I totally lose all my productivity with that. Partly because I’ve not found it very productive in my experiments.
Interestingly, this productive AI development happens pretty much concurrently with the AI slop avalanche we also see, proving that one AI is not necessarily like the other AI.












{kind=link}