Exactly eighteen years ago today, on October 30 2006, we shipped curl 7.16.0 that among a whole slew of new features and set of bugfixes bumped the libcurl SONAME number from 3 to 4.
ABI breakage
This bump meant that libcurl 7.16.0 was not binary compatible with the previous releases. Users could not just easily and transparently bump up to this version from the previous, but they had to check their use of libcurl and in some cases adjust source code.
This was not the first ABI breakage in the curl project, but at this time our use base was larger than at any of the previous bumps and this time people complained about the pains and agonies such a break brought them.
We took away FTP features
In the 7.16.0 release we removed a few FTP related features and their associated options. Before this release, you could use curl to do “third party” transfers over FTP, and in this release you could no longer do that. That is a feature when the client (curl) connects to server A and instructs that server to communicate with server B and do file transfers among themselves, without sending data to and from the client.
This is an FTP feature that was not implemented well in curl and it was poorly tested. It was also a feature that barely no FTP server allowed and subsequently this was not used by many users. We ripped it out.
A near pitchfork situation
Because so few people used the removed features, barely anyone actually noticed the ABI breakage. It remained theoretical to most users and I believe that detail only made people more upset over the SONAME bump because they did not even see the necessity: we just made their lives more complicated for no benefit (to them).
The Debian project even decided to override our decision “no, that is not an ABI breakage” and added a local patch in their build that lowered the SONAME number back to 3 again in their builds. A patch they would stick to for many years to come.
The obvious friction this bump caused, even when in reality it actually did not affect many users and the loud feedback we received, made a huge impact on me. It had not previously dawned on me exactly how important this was.
I decided there and then to do the utmost to never go through this again. To put ABI compatibility at the top of the priority list. Make it one of the most fundamental key properties of libcurl.
Do. Not. Break. The. ABI
(we don’t break the API either)
A never-breaking ABI
The decision was initially made to avoid the negativity the bump brought, but I have since over time much more come to appreciate the upsides.
Application authors everywhere can always and without risk keep upgrading to the latest libcurl.
It sounds easy and simple, but the impact is huge. The examples, the documentation, the applications, everything can just always upgrade and continue. As libcurl over time has become even more popular and compared to 2006, used in many magnitudes more installations, it has grown into an even more important aspect of the curl life. Possibly the single most important properly of curl.
There is a small caveat here and that is that we occasionally of course have bugs and regressions, so when I say that users can always upgrade, that is true in the sense that we have not broken the ABI since. We have however had a few regressions that sometimes have triggered some users to downgrade again or wait a little longer for the next release that has the bug fixed.
When we took that decision in 2006 we had less than 50,000 lines of product code. Today we are approaching 180,000 lines.
Effects of never breaking ABI
We know that once we adopt a change, we are stuck with it for decades to come. It makes us double-check every knot before we accept new changes.
Once accepted and shipped, we keep supporting code and features that we otherwise could have reconsidered and perhaps removed. Sometimes we think of a better way to do something after the initial merge, but by then it is too late to change. We can then always introduce new and better ways to do things, but we have to keep supporting the old way as well.
A most fundamental effect is that we can never shrink the list of options we support. We can never actually rename something. Doing new things and features consistently over this long time is hard if not impossible, as we learn new things and paradigms vary through the decades.
How
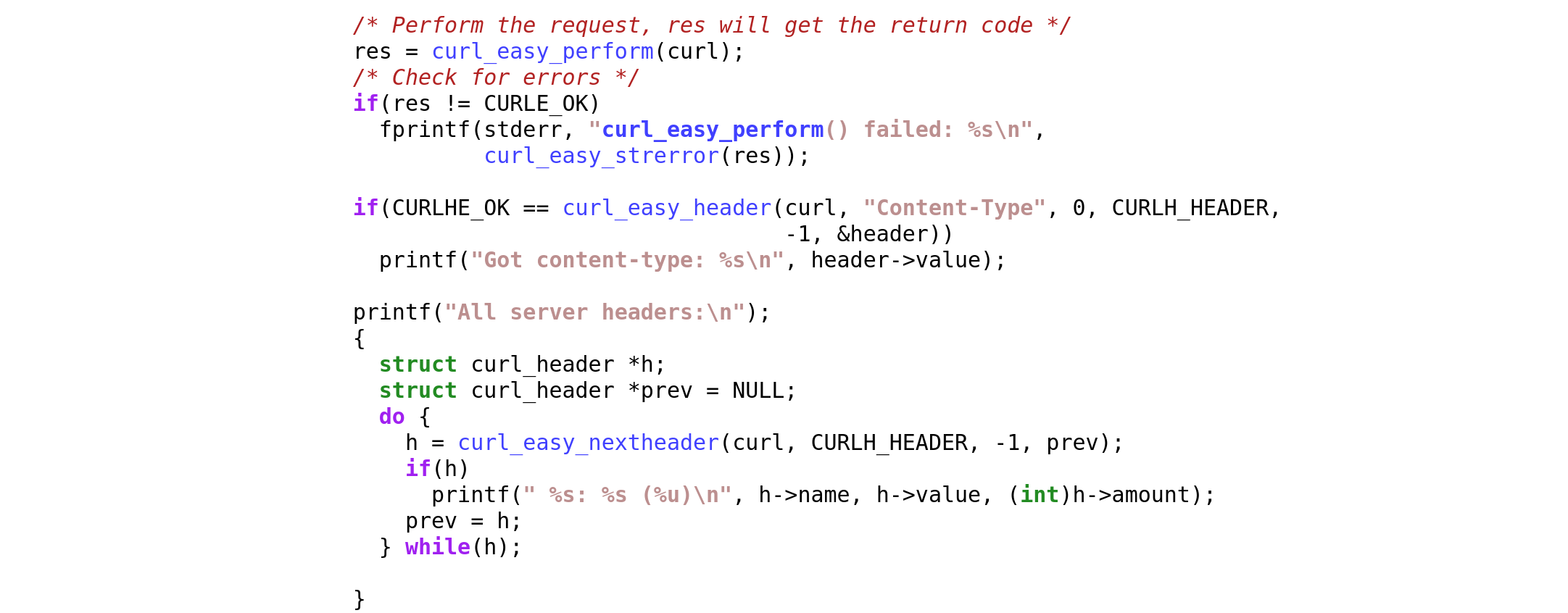
The primary way we maintain this is by manual code view and code inspection of every change. Followed of course by a large range of tests that make sure that assumptions remain.
Occasionally we have (long) discussions around subtle details when someone proposes a change that potentially might be considered an ABI break. Or not.
What exactly is covered by ABI compatibility is not always straight forward or easy to have carved in stone. In particular since the project can be built and run on such a wide range of systems and architectures.
Deprecating
We can still remove functionality if the conditions are right.
Some features and options are documented and work in a way so that something is requested or asked for and libcurl then tries to satisfy that ask. Like for example libcurl once supported HTTP/1 pipelining like that.
libcurl still provides the option to enable pipelining and applications can still ask for it so it is still ABI and API compatible, but a modern libcurl simply will never do it because that functionality has been removed.
Example two: we dropped support for NPN a few years back. NPN being a TLS extension called Next Protocol Negotiation that was used briefly in the early days of HTTP/2 development before ALPN was introduced and replaced NPN. Virtually nothing requires NPN anymore, and users can still set the option asking for it, but it will never actually happen over the wire.
Furthermore, a typical libcurl build involves multiple third party libraries that provide features it needs. For things like TLS, SSH, compression and binary HTTP protocol management. Over the years, we have removed support for several such libraries and introduced support for new, in ways that was never visible in the API or ABI. Some users just had to switch to building curl with different helper libraries.
In reality, libcurl is typically more stable than most existing servers and URLs. The libcurl examples you wrote in 2006 can still be built with the modern libcurl, but the servers and URLs you used back then most probably cannot be used anymore.
If no one can spot it, it did not happen
As blunt as it may sound, it has came down to this fundamental statement several times to judge if a change is an ABI breakage or not:
If no one can spot an ABI change, it is not an ABI change
Of course what makes it harder than it sounds is that it is extremely difficult to actually know if someone will notice something ahead of time. libcurl is used in so ridiculously many installations and different setups, second-guessing whatever everyone does and wants is darned close to impossible.
Adding to the challenge is the crazy long upgrade cycles some of our users seem to sport. It is not unusual to see questions appear on the mailing lists from users bumping from curl versions from eight or ten years ago. The fact that we have not heard users comment on a particular change might just mean that they are still stuck on ancient versions.
Getting frustrated comments from users today about a change we landed five years ago is hard to handle.
Forwards compatible
I should emphasize that all this means that users can always upgrade to a later release. It does not necessarily mean that they can switch back to an older version without problems. We do add new features over time and if you start using a new feature, the application of course will not work, or even still compile, if you would switch to a libcurl version from before that feature was added.
How long is never
What I have laid out here is our plan and ambition. We have managed to stick to this for eighteen years now and there is no particular known blockers in the known future either.
I cannot rule out that we might at some point in the future run into an obstacle so huge or complicated that we will be forced to do the unthinkable. To break the ABI. But until we see absolutely no other way forward, it is not going to happen.