

In a recent pull-request for curl, I clarified to the contributor that their change would only be accepted and merged into curl’s git code repository if they made sure that the change was done in a way so that it did not break (testing) for and on legacy platforms.
In that thread, I could almost feel how the contributor squirmed as this requirement made their work harder. Not by much, but harder no less.
I insisted that since curl at that point (and still does) already supports 32 bit time_t types, changes in this area should maintain that functionality. Even if 32 bit time_t is of limited use already and will be even more limited as we rush toward the year 2038. Quite a large number of legacy platforms are still stuck on the 32 bit version.
Why do I care so much about old legacy crap?
Nobody asked me exactly that using those words. I am paraphrasing what I suspect some contributors think at times when I ask them to do additional changes to pull requests. To make their changes complete.
It is not so much about the legacy systems. It is much more about sticking to our promises and not breaking things if we don’t have to.
Partly stability and promises
In the curl project we work relentlessly to maintain ABI and API stability and compatibility. You can upgrade your libcurl using application from the mid 2000s to the latest libcurl – without recompiling the application – and it still works the same. You can run your unmodified scripts you wrote in the early 2000s with the latest curl release today – and it is almost guaranteed that it works exactly the same way as it did back then.
This is more than a party trick and a snappy line to use in the sales brochures.
This is the very core of curl and libcurl and a foundational principle of what we ship: you can trust us. You can lean on us. Your application’s Internet transfer needs are in safe hands and you can be sure that even if we occasionally ship bugs, we provide updates that you can switch over to without the normal kinds of upgrade pains software so often comes with. In a never-ending fashion.
Also of course. Why break something that is already working fine?

Partly user numbers don’t matter
Users do matter, but what I mean in this subtitle is that the number of users on a particular platform is rarely a reason or motivator for working on supporting it and making things work there. That is not how things tend to work.
What matters is who is doing the work and if the work is getting done. If we have contributors around that keep making sure curl works on a certain platform, then curl will keep running on that platform even if they are said to have very few users. Those users don’t maintain the curl code. Maintainers do.
A platform does not truly die in curl land until necessary code for it is no longer maintained – and in many cases the unmaintained code can remain functional for years. It might also take a long time until we actually find out that curl no longer works on a particular platform.
On the opposite side it can be hard to maintain a platform even if it has large amount of users if there are not enough maintainers around who are willing and knowledgeable to work on issues specific to that platform.

Partly this is how curl can be everywhere
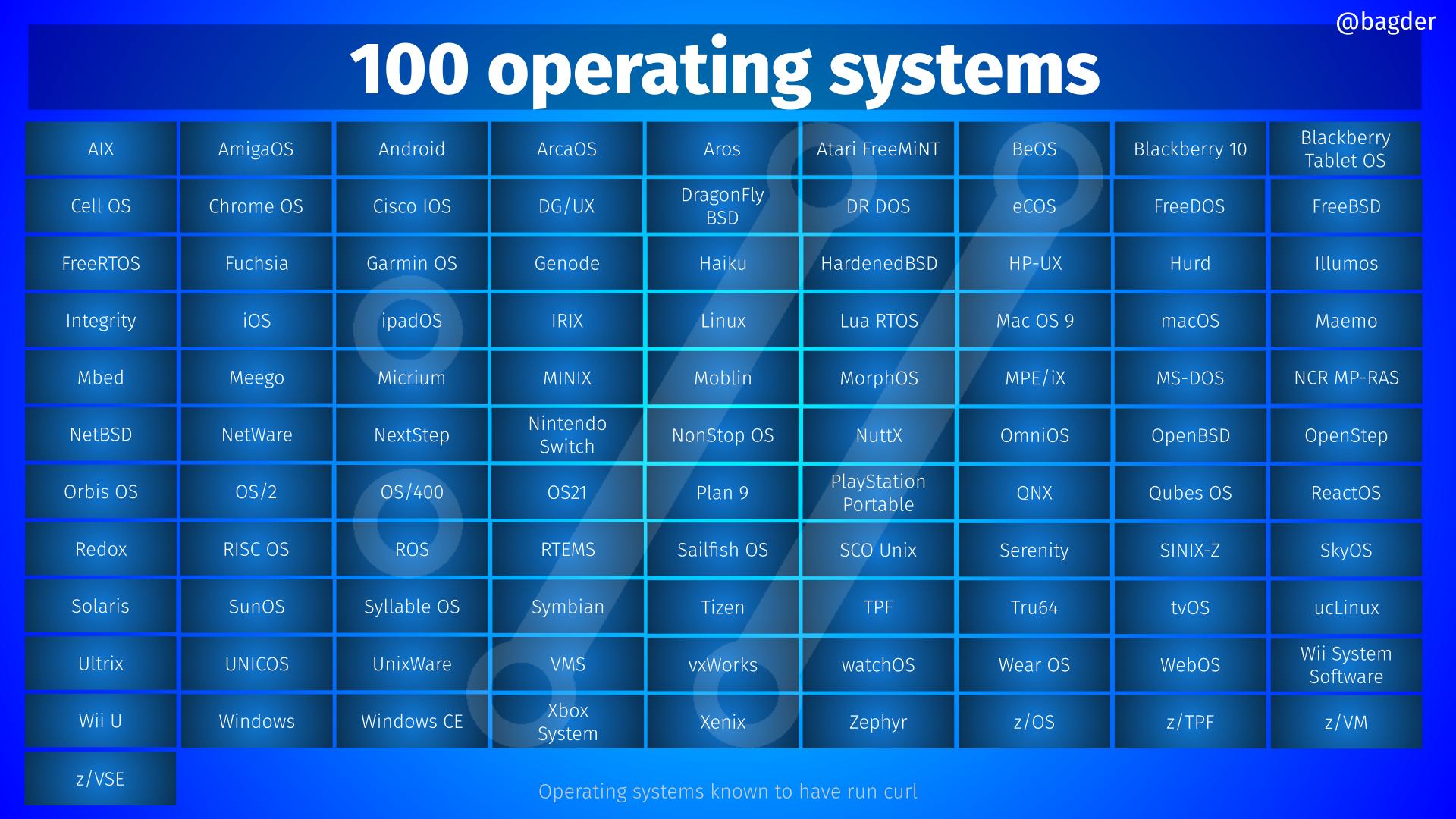
Precisely because we keep this strong focus on building, working and running everywhere, even sometimes with rather funny and weird configurations, is an explanation to how curl and libcurl has ended up in so many different operating systems, run on so many CPU architectures and is installed in so many things. We make sure it builds and runs. And keeps doing so.
And really. Countless users and companies insist on sticking to ancient, niche or legacy platforms and there is nothing we can do about that. If we don’t have to break functionality for them, having them stick to relying on curl for transfers is oftentimes much better security-wise than almost all other (often homegrown) alternatives.

We still deprecate things
In spite of the fancy words I just used above, we do remove support for things every now and then in curl. Mostly in the terms of dropping support for specific 3rd party libraries as they dwindle away and fall off like leaves in the fall, but also in other areas.
The key is to deprecate things slowly, with care and with an open communication. This ensures that everyone (who wants to know) is aware that it is happening and can prepare, or object if the proposal seems unreasonable.
If no user can detect a changed behavior, then it is not changed.
curl is made for its users. If users want it to keep doing something, then it shall do so.
The world changes
Internet protocols and versions come and go over time.
If you bring up your curl command lines from 2002, most of them probably fail to work. Not because of curl, but because the host names and the URLs used back then no longer work.
A huge reason why a curl command line written in 2002 will not work today exactly as it was written back then is the transition from HTTP to HTTPS that has happened since then. If the site actually used TLS (or SSL) back in 2002 (which certainly was not the norm), it used a TLS protocol version that nowadays is deemed insecure and modern TLS libraries (and curl) will refuse to connect to it if it has not been updated.
That is also the reason that if you actually have a saved curl executable from 2002 somewhere and manage to run that today, it will fail to connect to modern HTTPS sites. Because of changes in the transport protocol layers, not because of changes in curl.
Credits
Top image by Sepp from Pixabay


