DNS over HTTPS (DOH) is a feature where a client shortcuts the standard native resolver and instead asks a dedicated DOH server to resolve names.
Compared to regular unprotected DNS lookups done over UDP or TCP, DOH increases privacy, security and sometimes even performance. It also makes it easy to use a name server of your choice for a particular application instead of the one configured globally (often by someone else) for your entire system.
DNS over HTTPS is quite simply the same regular DNS packets (RFC 1035 style) normally sent in clear-text over UDP or TCP but instead sent with HTTPS requests. Your typical DNS server provider (like your ISP) might not support this yet.
To get the finer details of this concept, check out Lin Clark’s awesome cartoon explanation of DNS and DOH.
This new Firefox feature is planned to get ready and ship in Firefox release 62 (early September 2018). You can test it already now in Firefox Nightly by setting preferences manually as described below.
This article will explain some of the tweaks, inner details and the finer workings of the Firefox TRR implementation (TRR == Trusted Recursive Resolver) that speaks DOH.
Preferences
All preferences (go to “about:config”) for this functionality are located under the “network.trr” prefix.
network.trr.mode – set which resolver mode you want.
0 – Off (default). use standard native resolving only (don’t use TRR at all)
1 – Race native against TRR. Do them both in parallel and go with the one that returns a result first.
2 – TRR first. Use TRR first, and only if the name resolve fails use the native resolver as a fallback.
3 – TRR only. Only use TRR. Never use the native (after the initial setup).
4 – Shadow mode. Runs the TRR resolves in parallel with the native for timing and measurements but uses only the native resolver results.
5 – Explicitly off. Also off, but selected off by choice and not default.
network.trr.uri – (default: none) set the URI for your DOH server. That’s the URL Firefox will issue its HTTP request to. It must be a HTTPS URL (non-HTTPS URIs will simply be ignored). If “useGET” is enabled, Firefox will append “?ct&dns=….” to the URI when it makes its HTTP requests. For the default POST requests, they will be issued to exactly the specified URI.
“mode” and “uri” are the only two prefs required to set to activate TRR. The rest of them listed below are for tweaking behavior.
We list some publicly known DOH servers here. If you prefer to, it is easy to setup and run your own.
network.trr.credentials – (default: none) set credentials that will be used in the HTTP requests to the DOH end-point. It is the right side content, the value, sent in the Authorization: request header. Handy if you for example want to run your own public server and yet limit who can use it.
network.trr.wait-for-portal – (default: true) this boolean tells Firefox to first wait for the captive portal detection to signal “okay” before TRR is used.
network.trr.allow-rfc1918 – (default: false) set this to true to allow RFC 1918 private addresses in TRR responses. When set false, any such response will be considered a wrong response that won’t be used.
network.trr.useGET – (default: false) When the browser issues a request to the DOH server to resolve host names, it can do that using POST or GET. By default Firefox will use POST, but by toggling this you can enforce GET to be used instead. The DOH spec says a server MUST support both methods.
network.trr.confirmationNS – (default: example.com) At startup, Firefox will first check an NS entry to verify that TRR works, before it gets enabled for real and used for name resolves. This preference sets which domain to check. The verification only checks for a positive answer, it doesn’t actually care what the response data says.
network.trr.bootstrapAddress – (default: none) by setting this field to the IP address of the host name used in “network.trr.uri”, you can bypass using the system native resolver for it. This avoids that initial (native) name resolve for the host name mentioned in the network.trr.uri pref.
network.trr.blacklist-duration – (default: 60) is the number of seconds a name will be kept in the TRR blacklist until it expires and can be tried again. The default duration is one minute. (Update: this has been cut down from previous longer defaults.)
network.trr.request-timeout – (default: 3000) is the number of milliseconds a request to and corresponding response from the DOH server is allowed to spend until considered failed and discarded.
network.trr.early-AAAA – (default: false) For each normal name resolve, Firefox issues one HTTP request for A entries and another for AAAA entries. The responses come back separately and can come in any order. If the A records arrive first, Firefox will – as an optimization – continue and use those addresses without waiting for the second response. If the AAAA records arrive first, Firefox will only continue and use them immediately if this option is set to true.
network.trr.max-fails – (default: 5) If this many DoH requests in a row fails, consider TRR broken and go back to verify-NS state. This is meant to detect situations when the DoH server dies.
network.trr.disable-ECS – (default: true) If set, TRR asks the resolver to disable ECS (EDNS Client Subnet – the method where the resolver passes on the subnet of the client asking the question). Some resolvers will use ECS to the upstream if this request is not passed on to them.
Split-horizon and blacklist
With regular DNS, it is common to have clients in different places get different results back. This can be done since the servers know from where the request comes (which also enables quite a degree of spying) and they can then respond accordingly. When switching to another resolver with TRR, you may experience that you don’t always get the same set of addresses back. At times, this causes problems.
As a precaution, Firefox features a system that detects if a name can’t be resolved at all with TRR and can then fall back and try again with just the native resolver (the so called TRR-first mode). Ending up in this scenario is of course slower and leaks the name over clear-text UDP but this safety mechanism exists to avoid users risking ending up in a black hole where certain sites can’t be accessed. Names that causes such TRR failures are then put in an internal dynamic blacklist so that subsequent uses of that name automatically avoids using DNS-over-HTTPS for a while (see the blacklist-duration pref to control that period). Of course this fall-back is not in use if TRR-only mode is selected.
In addition, if a host’s address is retrieved via TRR and Firefox subsequently fails to connect to that host, it will redo the resolve without DOH and retry the connect again just to make sure that it wasn’t a split-horizon situation that caused the problem.
When a host name is added to the TRR blacklist, its domain also gets checked in the background to see if that whole domain perhaps should be blacklisted to ensure a smoother ride going forward.
TTL as a bonus!
With the implementation of DNS-over-HTTPS, Firefox now gets the TTL (Time To Live, how long a record is valid) value for each DNS address record and can store and use that for expiry time in its internal DNS cache. Having accurate lifetimes improves the cache as it then knows exactly how long the name is meant to work and means less guessing and heuristics.
When using the native name resolver functions, this time-to-live data is normally not provided and Firefox does in fact not use the TTL on other platforms than Windows and on Windows it has to perform some rather awkward quirks to get the TTL from DNS for each record.
Server push
 Still left to see how useful this will become in real-life, but DOH servers can push new or updated DNS records to Firefox. HTTP/2 Server Push being responses to requests the client didn’t send but the server thinks the client might appreciate anyway as if it sent requests for those resources.
Still left to see how useful this will become in real-life, but DOH servers can push new or updated DNS records to Firefox. HTTP/2 Server Push being responses to requests the client didn’t send but the server thinks the client might appreciate anyway as if it sent requests for those resources.
These pushed DNS records will be treated as regular name resolve responses and feed the Firefox in-memory DNS cache, making subsequent resolves of those names to happen instantly.
Bootstrap
You specify the DOH service as a full URI with a name that needs to be resolved, and in a cold start Firefox won’t know the IP address of that name and thus needs to resolve it first (or use the provided address you can set with network.trr.bootstrapAddress). Firefox will then use the native resolver for that, until TRR has proven itself to work by resolving the network.trr.confirmationNS test domain. Firefox will also by default wait for the captive portal check to signal “OK” before it uses TRR, unless you tell it otherwise.
As a result of this bootstrap procedure, and if you’re not in TRR-only mode, you might still get a few native name resolves done at initial Firefox startups. Just telling you this so you don’t panic if you see a few show up.
CNAME
The code is aware of CNAME records and will “chase” them down and use the final A/AAAA entry with its TTL as if there were no CNAMEs present and store that in the in-memory DNS cache. This initial approach, at least, does not cache the intermediate CNAMEs nor does it care about the CNAME TTL values.
Firefox currently allows no more than 64(!) levels of CNAME redirections.
about:networking
Enter that address in the Firefox URL bar to reach the debug screen with a bunch of networking information. If you then click the DNS entry in the left menu, you’ll get to see the contents of Firefox’s in-memory DNS cache. The TRR column says true or false for each name if that was resolved using TRR or not. If it wasn’t, the native resolver was used instead for that name.
Private Browsing
When in private browsing mode, DOH behaves similar to regular name resolves: it keeps DNS cache entries separately from the regular ones and the TRR blacklist is then only kept in memory and not persisted to disk. The DNS cache is flushed when the last PB session is exited.
Tools
 I wrote up dns2doh, a little tool to create DOH requests and responses with, that can be used to build your own toy server with and to generate requests to send with curl or similar.
I wrote up dns2doh, a little tool to create DOH requests and responses with, that can be used to build your own toy server with and to generate requests to send with curl or similar.
It allows you to manually issue a type A (regular IPv4 address) DOH request like this:
$ dns2doh --A --onlyq --raw daniel.haxx.se | \
curl --data-binary @- \
https://dns.cloudflare.com/.well-known/dns \
-H "Content-Type: application/dns-udpwireformat"
I also wrote doh, which is a small stand-alone tool (based on libcurl) that issues requests for the A and AAAA records of a given host name from the given DOH URI.
Why HTTPS
Some people giggle and think of this as a massive layer violation. Maybe it is, but doing DNS over HTTPS makes a lot of sense compared to for example using plain TLS:
- We get transparent and proxy support “for free”
- We get multiplexing and the use of persistent connections from the get go (this can be supported by DNS-over-TLS too, depending on the implementation)
- Server push is a potential real performance booster
- Browsers often already have a lot of existing HTTPS connections to the same CDNs that might offer DOH.
Further explained in Patrick Mcmanus’ The Benefits of HTTPS for DNS.
It still leaks the SNI!
Yes, the Server Name Indication field in the TLS handshake is still clear-text, but we hope to address that as well in the future with efforts like encrypted SNI.
Bugs?
File bug reports in Bugzilla! (in “Core->Networking:DNS” please)
If you want to enable HTTP logging and see what TRR is doing, set the environment variable MOZ_LOG component and level to “nsHostResolver:5”. The TRR implementation source code in Firefox lives in netwerk/dns.
Caveats
Credits
While I have written most of the Firefox TRR implementation, I’ve been greatly assisted by Patrick Mcmanus. Valentin Gosu, Nick Hurley and others in the Firefox Necko team.
DOH in curl?
Since I am also the lead developer of curl people have asked. The work on DOH for curl has not really started yet, but I’ve collected some thoughts on how DNS-over-HTTPS could be implemented in curl and the doh tool I mentioned above has the basic function blocks already written.
Other efforts to enhance DNS security
There have been other DNS-over-HTTPS protocols and efforts. Recently there was one offered by at least Google that was a JSON style API. That’s different.
There’s also DNS-over-TLS which shares some of the DOH characteristics, but lacks for example the nice ability to work through proxies, do multiplexing and share existing connections with standard web traffic.
DNScrypt is an older effort that encrypts regular DNS packets and sends them over UDP or TCP.





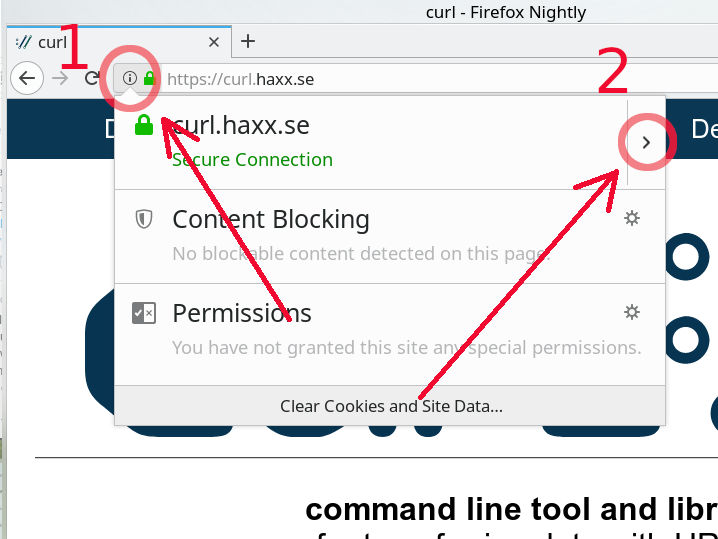
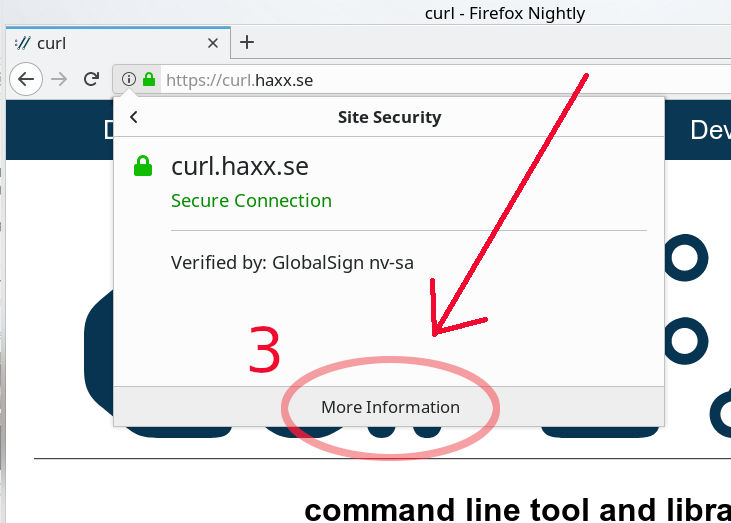



 The
The