I want curl to be on the very bleeding edge of protocol development to aid the Internet protocol development community to test out protocols early and to work out kinks in the protocols and server implementations using curl’s vast set of tools and switches.

For this, curl supported HTTP/2 really early on and helped shaping the protocol and testing out servers.
For this reason, curl supports HTTP/3 already since August 2019. A convenient and well-known client that you can then use to poke on your brand new HTTP/3 servers too and we can work on getting all the rough edges smoothed out before the protocol is reaching its final state.
QUIC tooling
One of the many challenges QUIC and HTTP/3 have is that with a new transport protocol comes entirely new paradigms. With new paradigms like this, we need improved or perhaps even new tools to help us understand the network flows back and forth, to make sure we all have a common understanding of the protocols and to make sure we implement our end-points correctly.
QUIC only exists as an encrypted-only protocol, meaning that we can no longer easily monitor and passively investigate network traffic like before, QUIC also encrypts more of the protocol than TCP + TLS do, leaving even less for an outsider to see.
The current QUIC analyzer tool lineup gives us two options.
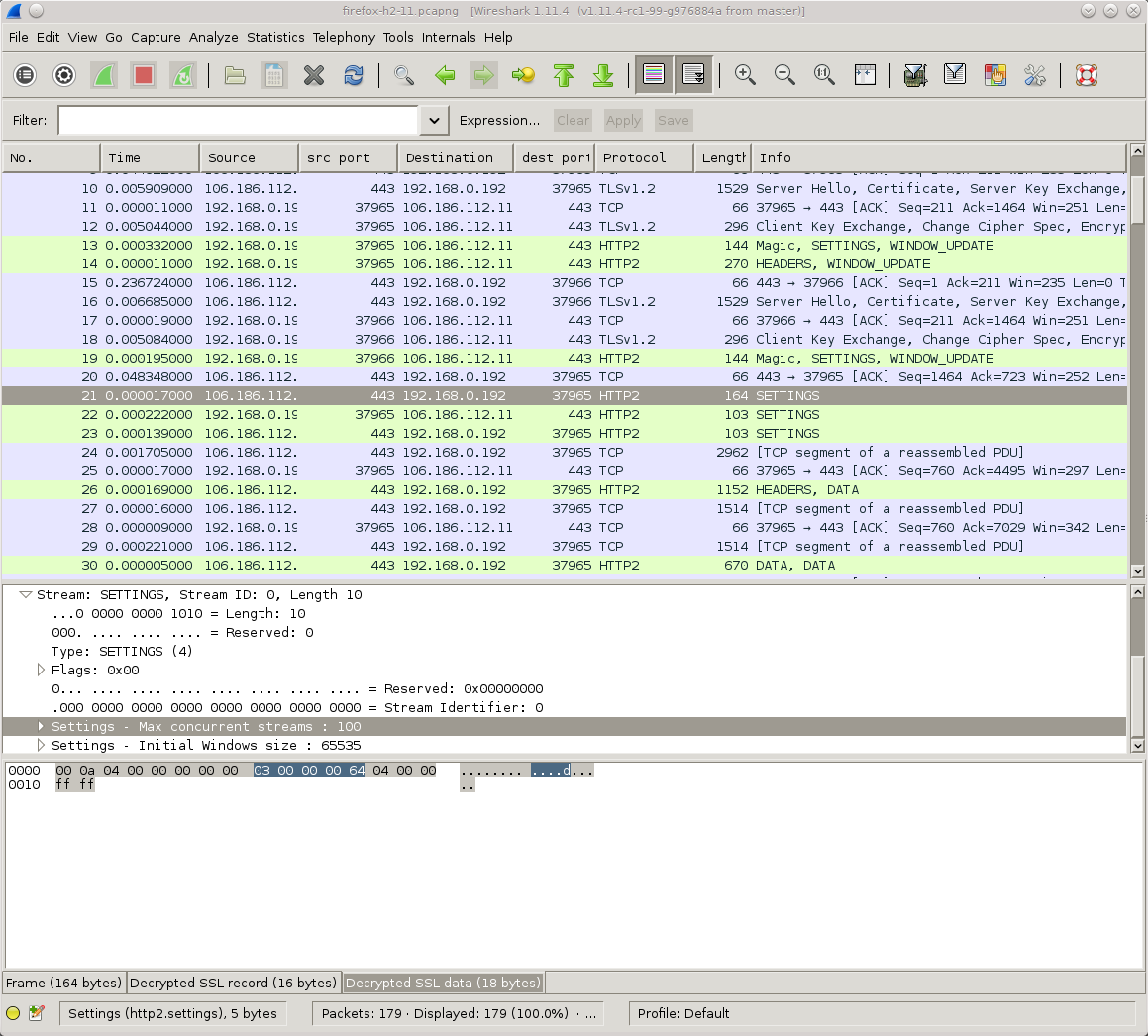
Wireshark
We all of course love Wireshark and if you get a very recent version, you’ll be able to decrypt and view QUIC network data.
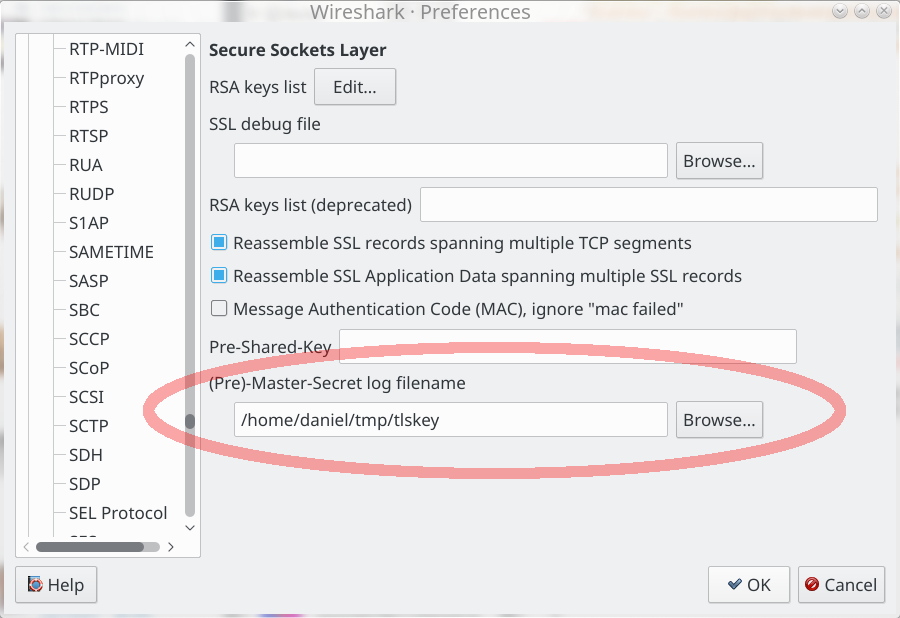
With curl, and a few other clients, you can ask to get the necessary TLS secrets exported at run-time with the SSLKEYLOGFILE environment variable. You’ll then be able to see every bit in every packet. This way to extract secrets works with QUIC as well as with the traditional TCP+TLS based protocols.
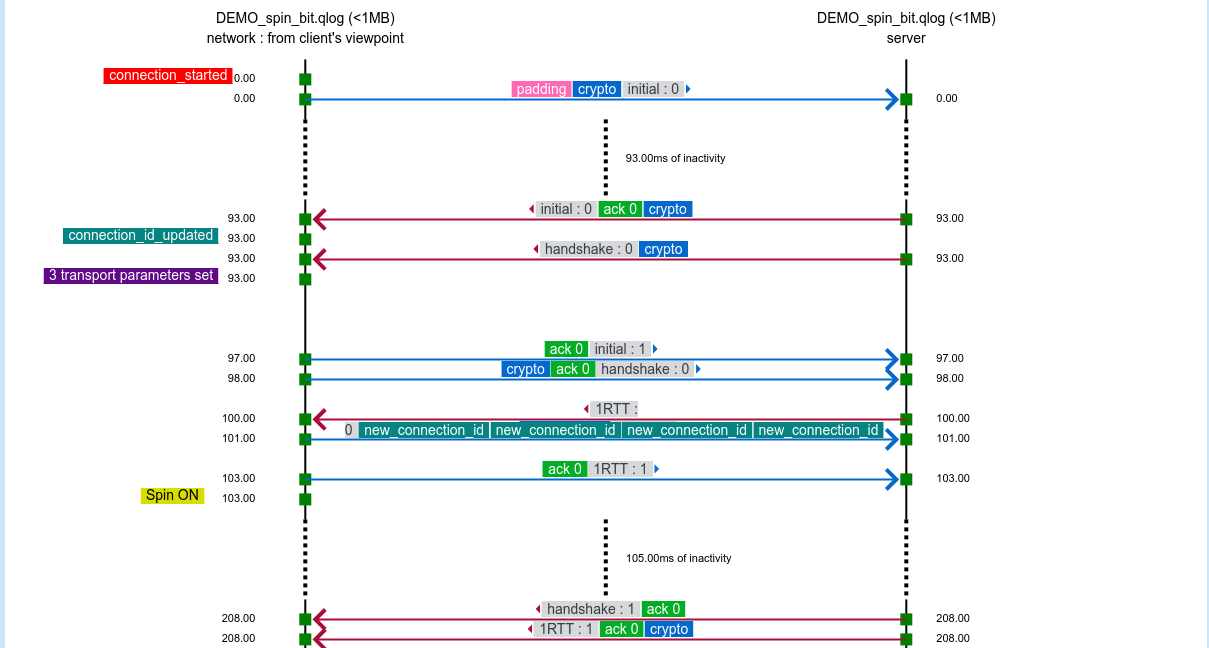
qvis/qlog
The qvis/qlog site. If you find the Wireshark network view a little bit too low level and leaving a lot for you to understand and draw conclusions from, the next-level tool here is the common QUIC logging format called qlog. This is an agreed-upon common standard to log QUIC traffic, which the accompanying qvis web based visualizer tool that lets you upload your logs and get visualizations generated. This becomes extra powerful if you have logs from both ends!
Starting with this commit (landed in the git master branch on May 7, 2020), all curl builds that support HTTP/3 – independent of what backend you pick – can be told to output qlogs.
Enable qlogging in curl by setting the new standard environment variable QLOGDIR to point to a directory in which you want qlogs to be generated. When you run curl then, you’ll get files creates in there named as [hex digits].log, where the hex digits is the “SCID” (Source Connection Identifier).
Credits
qlog and qvis are spear-headed by Robin Marx. qlogging for curl with Quiche was pushed for by Lucas Pardue and Alessandro Ghedini. In the ngtcp2 camp, Tatsuhiro Tsujikawa made it very easy for me to switch it on in curl.
The top image is snapped from the demo sample on the qvis web site.