In the 2015 time frame I had come to the conclusion that the curl logo could use modernization and I was toying with ideas of how it could be changed. The original had served us well, but it definitely had a 1990s era feel to it.
On June 11th 2015, I posted this image in the curl IRC channel as a proof of concept for a new curl logo idea I had: since curl works with URLs and all the URLs curl supports have the colon slash slash separator. Obviously I am not a designer so it was rough. This was back in the day when we still used this logo:
Frank Gevarts had a go at it. He took it further and tried to make something out of the idea. He showed us his tweaked take.
When we met up at the following FOSDEM in the end of January 2016, we sat down together and discussed the logo idea a bit to see if we could make it work somehow. Left from that exercise is this version below. As you can see, basically the same one. It was hard to make it work.
Later that spring, I was contacted by Soft Dreams, a designer company, who offered to help us design a new logo at no cost to us. I showed them some of these rough outlines of the colon slash slash idea and we did a some back-and-forthing to see if we could make something work with it, but we could not figure out a way to get the colon slash slash sequence actually into the word curl in a way that would look good. It just kept on looking different kinds of weird. Eventually we gave that up and we ended up putting it after the word, making it look like curl is a URL scheme. It was ended up much easier and ultimately the better and right choice for us. The new curl logo was made public in May 2016. Made by Adrian Burcea.
Just months later in 2016, Mozilla announced that they were working on a revamp of their logo. They made several different skews and there was a voting process during which they would eventually pick a winner. One of the options used colon slash slash embedded in the name and during the process a number of person highlighted the fact that the curl project just recently changed logo to use the colon slash slash.
In the Mozilla all-hands meeting in Hawaii in December 2016, I was approached by the Mozilla logo design team who asked me if I (we?) would have any issues with them moving forward with the logo version using the colon slash slash.
I had no objections. I think that was the coolest of the new logo options they had and I also thought that it sort of validated our idea of using the symbols in our logo. I was perhaps a bit jealous how Mozilla is a better word to actually integrate the symbol into the name…. the way we tried so hard to do for curl, but had to give up.
It was a while since I last spoke Swedish on a podcast. I joined the friendly hosts Sebastian and Alex of the Trevlig Mjukvara (translates to something like “Nice Software”) podcast and we talked software development, open source, curl, Mozilla and a few other topics for an hour. I had a great time. (We had Jitsi act up on us more than once so we had to switch away from it mid-recording!)
I started learning how to program in my teens, well over thirty years ago and I’ve worked as a software engineer and developer since the early 1990s. My first employment as a developer was in 1993. I’ve since worked for and with lots of companies and I’ve worked on a huge amount of (proprietary) software products and devices over many years. Meaning: I certainly didn’t start my life open source. I had to earn it.
When I was 20 years old I did my (then mandatory) military service in Sweden. After having endured that, I applied to the university while at the same time I was offered a job at IBM. I hesitated, but took the job. I figured I could always go to university later – but life took other turns and I never did. I didn’t do a single day of university. I haven’t regretted it.
I learned to code in the mid 80s on a Commodore 64 and software development has been one of my primary hobbies ever since. One thing it taught me well, that I still carry with me, is to spend a few hours per day in front of my home computer.
And then I shipped curl
In the spring of 1998 I renamed my little pet project of the time again and I released the first ever curl release. I have told this story many times, but since then I have spent two hours or so of my spare time on that project – every day for over twenty years. While still working as a software engineer by day.
Over time, curl gradually grew popular and attracted more users. There was no sudden moment in time where I struck gold and everything took off. It was just slowly gaining ground while me and my fellow project members kept improving and polishing curl. At some point in time I happened to notice that curl and libcurl would appear in more and more acknowledgements and in open source license collections in products and devices.
It was still just a spare time project.
Proprietary Software for years
I’d like to emphasize that I worked as a contract and consultant developer for many years (over 20!), primarily on proprietary software and custom solutions, before I managed to land myself a position where I could primarily write open source as part of my job.
Mozilla
In 2014 I joined Mozilla and got the opportunity to work on the open source project Firefox for a living – and doing it entirely from my home. This was the first time in my career I actually spent most of my days on code that was made public and available to the world. They even allowed me to spend a part of my work hours on curl, even if that didn’t really help them and curl was not a fundamental part of any Mozilla work or products. It was still great.
I landed that job for Mozilla a lot thanks to my many years and long experience with portable network coding and running a successful open source project at this level.
My work setup with Mozilla made it possible for me to spend even more time on curl, apart from the (still going) two daily spare time hours. Nobody at Mozilla cared much about (my work with) curl and no one there even asked me about it. I worked on Firefox for a living.
For anyone wanting to do open source as part of their work, getting a job at a company that already does a lot of open source is probably the best path forward. Even if that might not be easy either, and it might also mean that you would have to accept working on some open source projects that you might not yourself be completely sold on.
In late 2018 I quit Mozilla, in part because I wanted to try to work with curl “for real” (and part other reasons that I’ll leave out here). curl was then already over twenty years old and was used more than ever before.
wolfSSL
I now work for wolfSSL. We sell curl support and related services to companies. Companies pay wolfSSL, wolfSSL pays me a salary and I get food on the table. This works as long as we can convince enough companies that this is a good idea.
The vast majority of curl users out there of course don’t pay anything and will never pay anything. We just need a small number of companies to do it – and it seems to be working. We help customers use curl better, we make curl better for them and we make them ship better products this way. It’s a win win. And I can work on open source all day long thanks to this.
My open source life-style
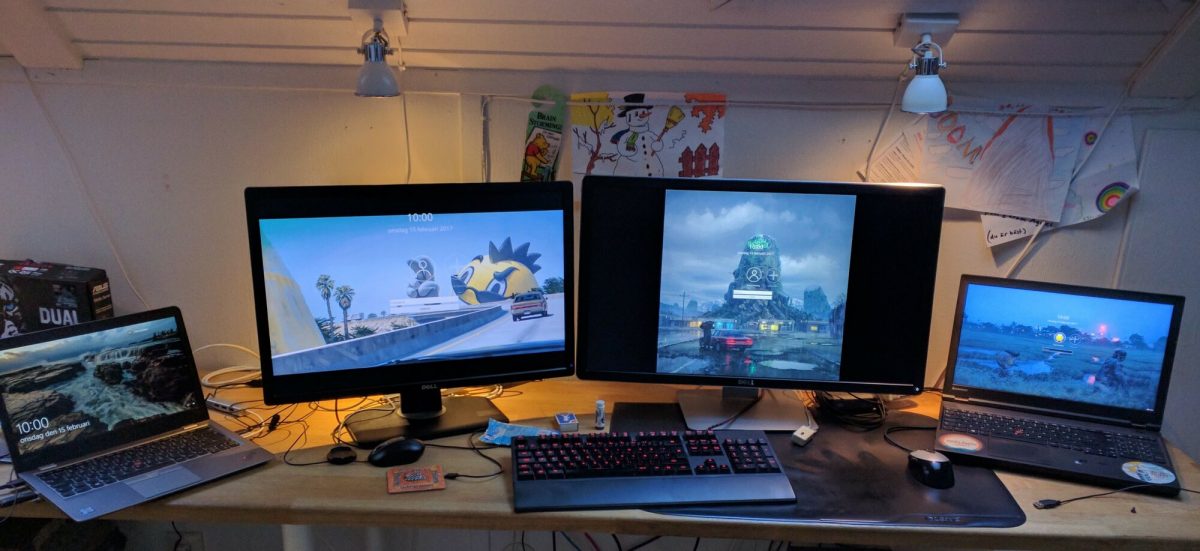
A normal day in the work week, I get up before 7 in the morning and I have breakfast with my family members: my wife and my two kids. Then I grab my first cup of coffee for the day and take the thirteen steps up the stairs to my “office”.
I sit down in front of my main development (Linux) machine with two 27″ screens and get to work.
Photo of my work desk from a few years ago but it looks very similar still today.
What work and in what order?
I lead the curl project. It means many questions and decisions fall down to me to have an opinion about or say on, and it’s a priority for me to make sure that I unblock such situations as soon as possible so that developers wanting to do things with curl can continue doing that.
Thus, I read and respond to email about curl all hours I’m awake and have network access. Of course incoming messages actually rarely require immediate responses and then I can queue them up and instead do them later. I also try to read and assess all new incoming curl issues as soon as possible to see if there’s something urgent I should deal with immediately, or otherwise figure out how to deal with them going forward.
I usually have a set of bugs or features to work on so when there’s no alarming email or GitHub issue left, I context-switch over to the curl source code tree and the particular branch in which I work on right now. I typically have 20-30 different branches of development of various stages and maturity going on. If I get stuck on something, or if I create a pull-request for one of them that needs time to get all the CI jobs done, I switch over to one of the others.
Customers and their needs of course have priority when I decide what to work on. The exception would perhaps be security vulnerabilities or other really serious bugs being reported, but thankfully they are rare. But after that, I go by ear and work on what I think is fun and what I think users might appreciate.
If I want to go forward with something, for my own sake or for a customer’s, and that entails touching or improving other software in other projects, then I don’t shy away from submitting pull requests for them – or at least filing an issue.
Spare time open source
Yes, I still spend my spare time hours on open source, mostly curl. This means I often end up spending 50-55 hours per week on curl and curl related activities. But I don’t count or measure work hours and I rarely have to report any to anyone. This is a work of love.
Lots of people will say that they don’t have time because of life, family, kids etc. I have of course been very fortunate over the years to have had the opportunity and ability to spend all this time on what I want to do, but let’s not forget that people in general spend lots of time on their hobbies; on watching TV, on playing computer games and on socializing with friends and why not: to sleep. If you cut down on all of those things (yes, including the sleeping) there could very well be opportunities. It’s often a question of priorities. I’ve made spare time development a priority in my life.
curl support?
Any company that uses curl or libcurl – and they are plenty – could benefit from buying support from us instead of wasting their own time and resources. We at wolfSSL are probably much better at curl already and we can find and fix the issues much faster, which ends up cheaper and better long-term.
Credits
The top photo is taken by Anja Stenberg, my wife. It’s me in a local forest, summer 2020.
It’s been five great years, but now it is time for me to move on and try something else.
During these five years I’ve met and interacted with a large number of awesome people at Mozilla, lots of new friends! I got the chance to work from home and yet work with a global team on a widely used product, all done with open source. I have worked on internet protocols during work-hours (in addition to my regular spare-time working with them) and its been great! Heck, lots of the HTTP/2 development and the publication of that was made while I was employed by Mozilla and I fondly participated in that. I shall forever have this time ingrained in my memory as a very good period of my life.
I had already before I joined the Firefox development understood some of the challenges of making a browser in the modern era, but that understanding has now been properly enriched with lots of hands-on and code-digging in sometimes decades-old messy C++, a spaghetti armada of threads and the wild wild west of users on the Internet.
A very big thank you and a warm bye bye go to everyone of my friends at Mozilla. I won’t be far off and I’m sure I will have reasons to see many of you again.
My last day as officially employed by Mozilla is December 11 2018, but I plan to spend some of my remaining saved up vacation days before then so I’ll hand over most of my responsibilities way before.
The future is bright but unknown!
I don’t yet know what to do next.
I have some ideas and communications with friends and companies, but nothing is firmly decided yet. I will certainly entertain you with a totally separate post on this blog once I have that figured out! Don’t worry.
Will it affect curl or other open source I do?
I had worked on curl for a very long time already before joining Mozilla and I expect to keep doing curl and other open source things even going forward. I don’t think my choice of future employer should have to affect that negatively too much, except of course in periods.
With me leaving Mozilla, we’re also losing Mozilla as a primary sponsor of the curl project, since that was made up of them allowing me to spend some of my work days on curl and that’s now over.
Short-term at least, this move might increase my curl activities since I don’t have any new job yet and I need to fill my days with something…
What about toying with HTTP?
I was involved in the IETF HTTPbis working group for many years before I joined Mozilla (for over ten years now!) and I hope to be involved for many years still. I still have a lot of things I want to do with curl and to keep curl the champion of its class I need to stay on top of the game.
I will continue to follow and work with HTTP and other internet protocols very closely. After all curl remains the world’s most widely used HTTP client.
Can I enter the US now?
No. That’s unfortunately not related, and I’m not leaving Mozilla because of this problem and I unfortunately don’t expect my visa situation to change because of this change. My visa counter is now showing more than 214 days since I applied.
your case is still going through administrative processing and we don’t know when that process will be completed.
Last year I was denied to go to the US when I was about to travel to San Francisco. Me and my employer’s legal team never got answers as to why this happened so I’ve personally tried to convince myself it was all because of some human screw-up. Because why would they suddenly block me? I’ve traveled to the US almost a dozen times over the years.
The fact that there was no reason or explanation given makes any theory as likely as the next. Whatever we think or guess might have happened can be true. Or not. We will probably never know. And I’ve been told a lot of different theories.
Denied again
In early April 2018 I applied for ESTA again to go to San Francisco in mid June for another Mozilla All Hands conference and… got denied. The craziness continues. This also ruled out some of the theories from last year that it was just some human error by the airline or similar…
As seen on the screenshot, this decision has no expire date… While they don’t provide any motivation for not accepting me, this result makes it perfectly clear that it wasn’t just a mistake last year. It makes me view last year with different eyes.
Put in this situation, I activated plan B.
Plan B
I then applied for a “real” non-immigrant visa – even though it feels that having been denied ESTA probably puts me in a disadvantage for that as well. Applying for this visa means filling in a 10-something-page “DS-160” form online on a site that sometimes takes minutes just to display the next page in the form where they ask for a lot of personal details. After finally having conquered that obstacle, I paid the 160 USD fee and scheduled an appointment to appear physically at the US embassy in Sweden.
I acquired an “extraction of the population register” (“personbevis” in Swedish) from the Swedish tax authorities – as required (including personal details of my parents and siblings), I got myself a new mugshot printed on photo paper and was lucky enough to find a date for an appointment not too far into the future.
Appointment
I spent the better part of a fine Tuesday morning in different waiting lines at my local US embassy where I eventually was called up to a man at a counter behind a window. I was fingerprinted, handed over my papers and told the clerk I have no idea why I was denied ESTA when asked, and no, I have not been on vacation in Iraq, Iran or Sudan. The clerk gave me the impression that’s the sort of thing that is the common reason for not getting ESTA.
When I answered the interviewer’s question that I work for Mozilla, he responded “Aha, Firefox?” – which brightened up my moment a little.
Apparently the process is then supposed to take “several weeks” until I get to know anything more. I explained that I needed my passport in three weeks (for another trip) and he said he didn’t expect them to be done that quickly. Therefore I got the passport back while they process my application and I’m expected to mail it to them when they ask for it.
The next form
When I got back home again, I got an email from “the visa unit” asking me to fill in another form (in the shape of a Word document). And what a form it is! It might be called “OMB 1405-0226” and has this fancy title:
“SUPPLEMENTAL QUESTIONS FOR VISA APPLICANTS”
Among other things it requires me to provide info about all trips abroad (with dates and duration) I’ve done over the last 15 years. What aliases I use on social media sites (hello mr US visa agent, how do you like this post so far?), every physical address I’ve lived at in the last 15 years, information about all my employers the last 15 years and every email address I’ve used during the last 5 years.
It took me many hours digging through old calendars, archives and memories and asking around in order to fill this in properly. (“hey that company trip we did to Germany back in 2005, can you remember the dates?”) As a side-note: it turns out I’ve been in the US no less than nine times the last fifteen years. In total I managed to list sixty-five different trips abroad for this period.
How do I submit my filled-in form, with all these specific and very private details from my life for the last 15 years, back to “the visa unit”? By email. Good old insecure, easy to snoop on, email! At least I’m using my own mail server (and it is configured to prefer TLS for connections) but that’s a small comfort.
Is it worth it?
This is a very time and energy consuming process – I understand why this puts people off and simply make them decide its not worth it to go there. And of course I understand that I’m in a lucky position where I’ve not had to deal with this much in the past.
I have many friends and contacts in the US in both my personal and professional life. I would be sad if I couldn’t go there ever again. It would give me grief personally since it’ll limit where I can go on vacation and who out of my friends I can visit, but it will also limit my professional life as interesting Mozilla, Internet, open source and curl related events that I’d like to attend are frequently hosted there.
What’s happening?
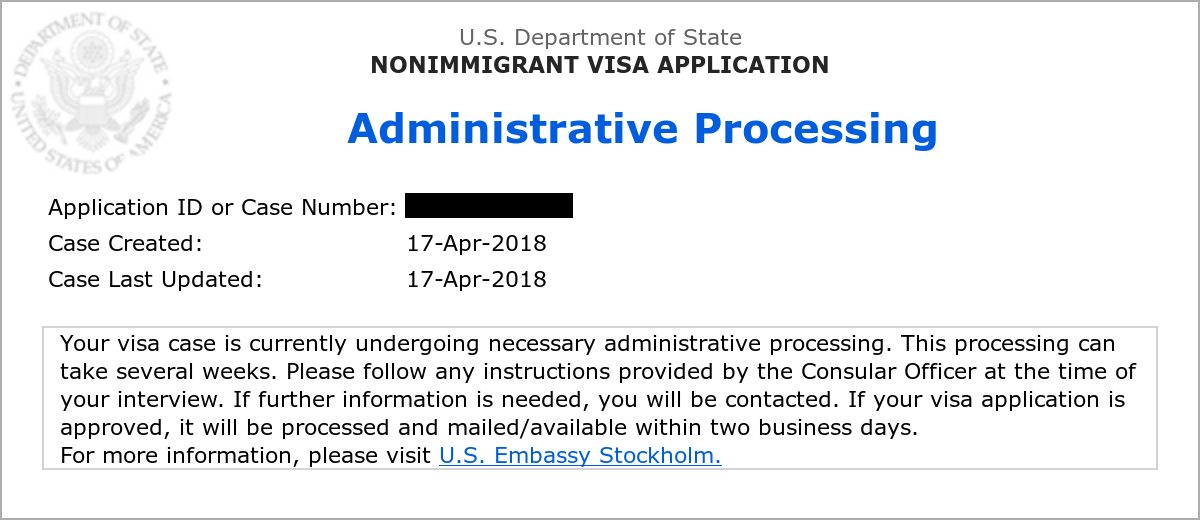
So the weeks came and went and on May 29th, six weeks after I was interviewed at the embassy, I checked the online service that allows me to check my application progress. It said “Case Created: April 17” and the following useful addition “Case Last Updated: April 17”.
Wat? Did something go fatally wrong here? I emailed the embassy to double-check. I got this single sentence response back:
Dear Sir,
You don't have to do anything, your case is still going through administrative processing and we don't know when that process will be completed.
In my life I’ve visited a whole series of countries for which I’ve been required to apply for a visa. None of them have ever taken more than a few weeks, including countries with complicated bureaucracy like India and China. What are they doing all this time?
At the time of this writing, more than 100 days have passed and I have still not heard back from them. I know this is unusually long and I have a strong suspicion this means they will deny me visa, but for some reason they want to keep me unaware for a while more.
No All Hands in the US
I clearly underestimated the time this required so I missed our meeting in SF this year again…
Mozilla has since then announced that a number of the forthcoming All Hands conferences in the coming years will be held outside of the US. Unfortunately several of them are to be held in Canada, and there are indications that having being denied entry to the US means that Canada will deny me as well. But I have yet to test that!
Why they deny me?
Me knowingly, I’ve never broken a law, rule or regulation that would explain this. Some speculations me and others can think of include…
I’m the main author of curl, a tool that is used in a lot of security research and proof of concept exploits of security vulnerabilities
I’m the main author of libcurl, a transfer library that is one of the world’s most widely used software components. It is subsequently also used extensively by malware and other offensive and undesired software.
It’s been suggested that my presence at multiple conferences in the US over the years could’ve been a violation of the ESTA rules – but the rules explicitly allow this. I have not violated the ESTA rules.
I’m about to take an extended vacation for the rest of the year and into the beginning of the next, so I decided I’d sum up the year from a curl angle already now, a few weeks early. (So some numbers will grow a bit more after this post.)
2017
So what did we do this year in the project, how did curl change?
The first curl release of the year was version 7.53.0 and the last one was 7.57.0. In the separate blog posts on 7.55.0, 7.56.0 and 7.57.0 you’ll note that we kept up adding new goodies and useful features. We produced a total of 9 releases containing 683 bug fixes. We announced twelve security problems. (Down from 24 last year.)
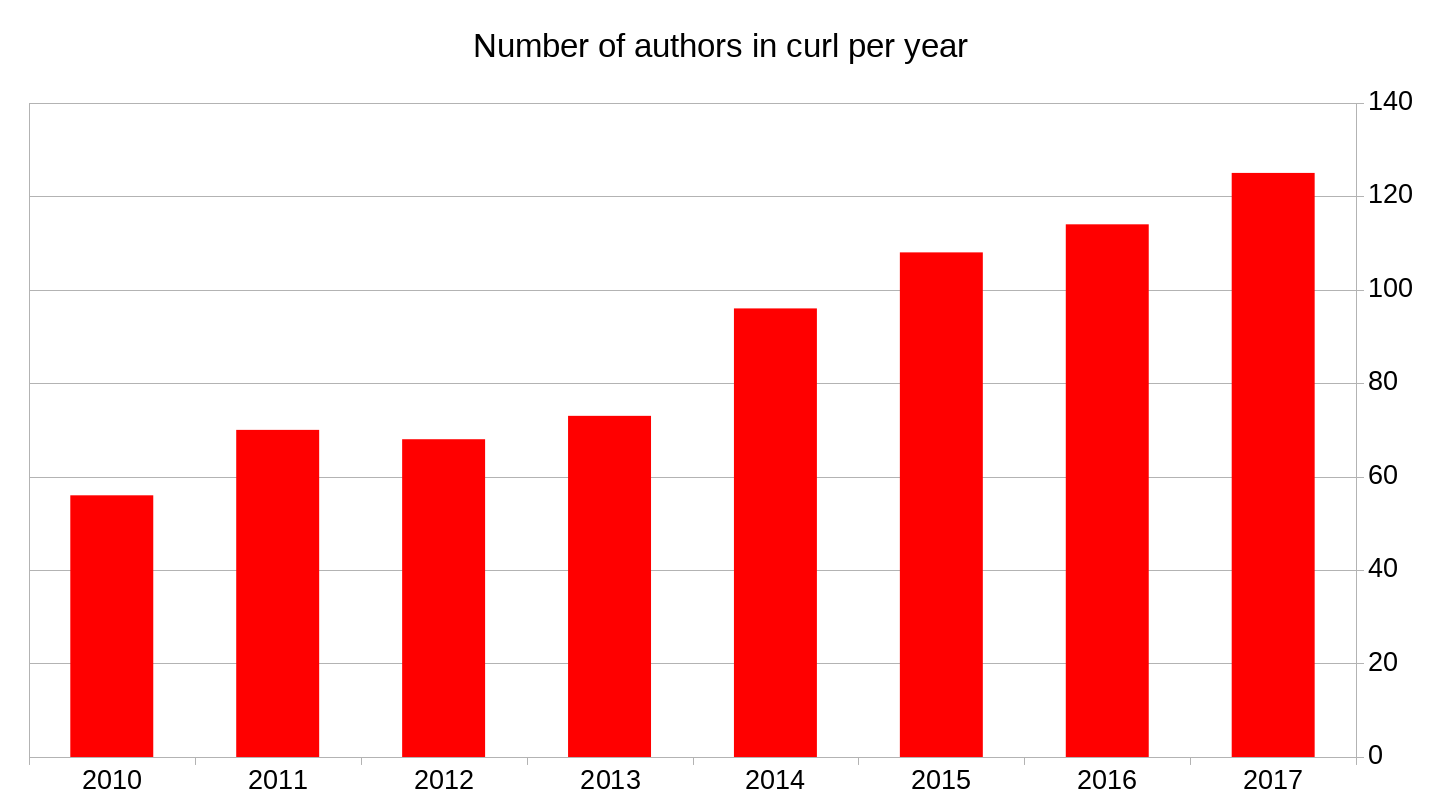
At least 125 different authors wrote code that was merged into curl this year, in the 1500 commits that were made. We never had this many different authors during a single year before in the project’s entire life time! (The 114 authors during 2016 was the previous all-time high.)
We added more than 160 new names to the THANKS document for their help in improving curl. The total amount of contributors is now over 1660.
This year we truly started to use travis for CI builds and grew from a mere two builds per commit and PR up to nineteen (with additional ones run on appveyor and elsewhere). The current build set is a very good verification that that most things still compile and work after a PR is merged. (see also the testing curl article).
In March 2017, we had our first ever curl get-together as we arranged curl up 2017 a weekend in Nuremberg, Germany. It was very inspiring and meeting parts of the team in real life was truly a blast. This was so good we intend to do it again: curl up 2018 will happen.
Also in May, we moved over the official curl site (and my personal site) to get hosted by Fastly. We were beginning to get problems to handle the bandwidth and load, and in one single step all our worries were graciously taken care of!
We got curl entered into the OSS-fuzz project, and Max Dymond even got a reward from Google for his curl-fuzzing integration work and thanks to that project throwing heaps of junk at libcurl’s APIs we’ve found and fixed many issues.
The source code (for the tool and library only) is now at about 143,378 lines of code. It grew around 7,057 lines during the year. The primary reasons for the code growth were:
the new libssh-powered SSH backend (not yet released)
the new mime API (in 7.56.0) and
the new multi-SSL backend support (also in 7.56.0).
Your maintainer’s view
Oh what an eventful year it has been for me personally.
The first interim meeting for QUIC took place in Japan, and I participated from remote. After all, I’m all set on having curl support QUIC and I’ll keep track of where the protocol is going! I’ve participated in more interim meetings after that, all from remote so far.
I talked curl on the main track at FOSDEM in early February (and about HTTP/2 in the Mozilla devroom). I’ve then followed that up and have also had the pleasure to talk in front of audiences in Stockholm, Budapest, Jönköping and Prague through-out the year.
I went to London and “represented curl” in the third edition of the HTTP workshop, where HTTP protocol details were discussed and disassembled, and new plans for the future of HTTP were laid out.
In late June I meant to go to San Francisco to a Mozilla “all hands” conference but instead I was denied to board the flight. That event got a crazy amount of attention and I received massive amounts of love from new and old friends. I have not yet tried to enter the US again, but my plan is to try again in 2018…
I wrote and published my h2c tool, meant to help developers convert a set of HTTP headers into a working curl command line.
The single occasion that overshadows all other events and happenings for me this year by far, was without doubt when I was awarded the Polhem Prize and got a gold medal medal from no other than his majesty the King of Sweden himself. For all my work and years spent on curl no less.
Not really curl related, but in November I was also glad to be part of the huge Firefox Quantum release. The biggest Firefox release ever, and one that has been received really well.
I’ve managed to commit over 800 changes to curl through the year, which is 54% of the totals and more commits than I’ve done in curl during a single year since 2005 (in which I did 855 commits). I explain this increase mostly on inspiration from curl up and the prize, but I think it also happened thanks to excellent feedback and motivation brought by my fellow curl hackers.
We’re running towards the end of 2017 with me being the individual who did most commits in curl every single month for the last 28 months.
Next week, Mozilla will release Firefox 57. Also referred to as Firefox Quantum, from the project name we’ve used for all the work that has been put into making this the most awesome Firefox release ever. This is underscored by the fact that I’ve gotten mailed release-swag for the first time during my four years so far as a Mozilla employee.
Firefox 57 is the major milestone hundreds of engineers have worked really hard toward during the last year or so, and most of the efforts have been focused on performance. Or perhaps perceived end user snappiness. Early comments I’ve read and heard also hints that it is also quite notable. I think every single Mozilla engineer (and most non-engineers as well) has contributed to at least some parts of this, and of course many have done a lot. My personal contributions to 57 are not much to write home about, but are mostly a stream of minor things that combined at least move the notch forward.
[edited out some secrets I accidentally leaked here.] I’m a proud Mozillian and being part of a crowd that has put together something as grand as Firefox 57 is an honor and a privilege.
Releasing a product to hundreds of millions of end users across the world is interesting. People get accustomed to things, get emotional and don’t particularly like change very much. I’m sure Firefox 57 will also get a fair share of sour feedback and comments written in uppercase. That’s inevitable. But sometimes, in order to move forward and do good stuff, we have to make some tough decisions for the greater good that not everyone will agree with.
This is however not the end of anything. It is rather the beginning of a new Firefox. The work on future releases goes on, we will continue to improve the web experience for users all over the world. Firefox 58 will have even more goodies, and I know there are much more good stuff planned for the releases coming in 2018 too…
Onwards and upwards!
(Update: as I feared in this text, I got a lot of negativism, vitriol and criticism in the comments to this post. So much that I decided to close down comments for this entry and delete the worst entries.)
– Sorry, you’re not allowed entry to the US on your ESTA.
The lady who delivered this message to me this early Monday morning, worked behind the check-in counter at the Arlanda airport. I was there, trying to check-in to my two-leg trip to San Francisco to the Mozilla “all hands” meeting of the summer of 2017. My chance for a while ahead to meet up with colleagues from all around the world.
This short message prevented me from embarking on one journey, but instead took me on another.
Returning home
I was in a bit of a shock by this treatment really. I mean, I wasn’t treated particularly bad or anything but just the fact that they downright refused to take me on for unspecified reasons wasn’t easy to swallow. I sat down for a few moments trying to gather my thoughts on what to do next. I then sent a few tweets out expressing my deep disappointment for what happened, emailed my manager and some others at Mozilla about what happened and that I can’t come to the meeting and then finally walked out the door again and traveled back home.
This tweet sums up what I felt at the time:
Going back home. To cry. To curse. To write code from home instead. Fricking miserable morning. No #sfallhands for me.
That Monday passed with some casual conversations with people of what I had experienced, and then…
Someone posted to hacker news about me. That post quickly rose to the top position and it began. My twitter feed suddenly got all crazy with people following me and retweeting my rejection tweets from yesterday. Several well-followed people retweeted me and that caused even more new followers and replies.
By the end of the Tuesday, I had about 2000 new followers and twitter notifications that literally were flying by at a high speed.
These articles of course helped boosting my twitter traffic even more.
In the flood of responses, the vast majority were positive and supportive of me. Lots of people highlighted the role of curl and acknowledged that my role in that project has been beneficial for quite a number of internet related software in the world. A whole bunch of the responses offered to help me in various ways. The one most highlighted is probably this one from Microsoft’s Chief Legal Officer Brad Smith:
I’d be happy to have one of our U.S. immigration legal folks talk with you to see if there’s anything we can do to help. Let me know.
I also received a bunch of emails. Some of them from people who offered help – and I must say I’m deeply humbled and grateful by the amount of friends I apparently have and the reach this got.
Some of the emails also echoed the spirit of some of the twitter replies I got: quite a few Americans feel guilty, ashamed or otherwise apologize for what happened to me. However, I personally do not at all think of this setback as something that my American friends are behind. And I have many.
Mozilla legal
Tuesday evening I had a phone call with our (Mozilla’s) legal chief about my situation and I helped to clarify exactly what I had done, what I’ve been told and what had happened. There’s a team working now to help me sort out what happened and why, and what I and we can do about it so that I don’t get to experience this again the next time I want to travel to the US. People are involved both on the US as well as on the Swedish side of things.
Personally I don’t have any plans to travel to the US in the near future so there’s no immediate rush. I had already given up attending this Mozilla all-hands.
You may have seen reports that someone who participates in this work was recently refused entry to the US*, for unspecified reasons.
…
We won’t hold any further interim meetings in the US, until there’s a change in this situation. This means that we’ll either need to find suitable hosts in Canada or Mexico, or our meeting rotation will need to change to be exclusively Europe and Asia.
I trust I don’t actually need to point out that I am that “someone” and again I’m impressed and humbled by the support and actions in my community.
Now what?
I’m now (end of Wednesday, 60 hours since the check-in counter) at 3000 more twitter followers than what I started out with this Monday morning. This turned out to be a totally crazy week and it has severally impacted my productivity. I need to get back to write code, I’m getting behind!
I hope we’ll get some answers soon as to why I was denied and what I can do to fix this for the future. When I get that, I will share all the info I can with you all.
So, back to work!
Thanks again
Before I forget: thank you all. Again. With all my heart. The amount of love I’ve received these last two days is amazing.
Update years later
I was eventually given a visa and can travel to the US again.
Today Mozilla revealed the new logo and “refreshed identity”. The new Mozilla logo uses the colon-slash-slash sequence already featured in curl’s logo as I’ve discussed previously here from back before the final decision (or layout) was complete.
The sentiment remains though. We don’t feel that we can in any way claim exclusivity to this symbol of internet protocols – on the contrary we believe this character sequence tells something and we’re nothing but happy that this belief is shared by such a great organization such as Mozilla.
Will the “://” in either logo make some users think of the other logo? Not totally unlikely, but I don’t consider that bad. curl and Mozilla share a lot of values and practices; open source, pro users, primarily client-side. I am leading the curl project and I am employed by Mozilla. Also, when talking and comparing brands and their recognition and importance in a global sense, curl is of course nothing next to Mozilla.
I’ve talked to the core team involved in the Mozilla logo revamping before this was all made public and I assured them that we’re nothing but thrilled.
An HTTPS client needs to do a whole lot of checks to make sure that the remote host is fine to communicate with to maintain the proper high security levels.
In this blog post, I will explain why and how the entire HTTPS ecosystem relies on the browsers to be good and strict and thanks to that, the rest of the HTTPS clients can get away with being much more lenient. And in fact that is good, because the browsers don’t help the rest of the ecosystem very much to do good verification at that same level.
Let me me illustrate with some examples.
CA certs
The server’s certificate must have been signed by a trusted CA (Certificate Authority). A client then needs the certificates from all the CAs that are trusted. Who’s a trusted CA and how would a client get their certs to use for verification?
You can say that you trust the same set of CAs that your operating system vendor trusts (which I’ve always thought is a bit of a stretch but hey, I can very well understand the convenience in this). If you want to do this as an HTTPS client you need to use native APIs in Windows or macOS, or you need to figure out where the cert bundle is stored if you’re using Linux.
If you’re not using the native libraries on windows and macOS or if you can’t find the bundle in your Linux distribution, or you’re in one of a large amount of other setups where you can’t use someone else’s bundle, then you need to gather this list by yourself.
How on earth would you gather a list of hundreds of CA certs that are used for the popular web sites on the net of today? Stand on someone else’s shoulders and use what they’ve done? Yeps, and conveniently enough Mozilla has such a bundle that is licensed to allow others to use it…
Mozilla doesn’t offer the set of CA certs in a format that anyone else can use really, which is the primary reason why we offer Mozilla’s cert bundle converted to PEM format on the curl web site. The other parties that collect CA certs at scale (Microsoft for Windows, Apple for macOS, etc) do even less.
Before you ask, Google doesn’t maintain their own list for Chrome. They piggyback the CA store provided on the operating system it runs on. (Update: Google maintains its own list for Android/Chrome OS.)
Further constraints
But the browsers, including Firefox, Chrome, Edge and Safari all add additional constraints beyond that CA cert store, on what server certificates they consider to be fine and okay. They blacklist specific fingerprints, they set a last allowed date for certain CA providers to offer certificates for servers and more.
These additional constraints, or additional rules if you want, are never exported nor exposed to the world in ways that are easy for anyone to mimic (in other ways than that everyone of course can implement the same code logic in their ends). They’re done in code and they’re really hard for anyone not a browser to implement and keep up with.
This makes every non-browser HTTPS client susceptible to okaying certificates that have already been deemed not OK by security experts at the browser vendors. And in comparison, not many HTTPS clients can compare or stack up the amount of client-side TLS and security expertise that the browser developers can.
HSTS preload
HTTP Strict Transfer Security is a way for sites to tell clients that they are to be accessed over HTTPS only for a specified time into the future, and plain HTTP should then not be used for the duration of this rule. This setup removes the Man-In-The-Middle (MITM) risk on subsequent accesses for sites that may still get linked to via HTTP:// URLs or by users entering the web site names directly into the address bars and so on.
The browsers have a “HSTS preload list” which is a list of sites that people have submitted and they are HSTS sites that basically never time out and always will be accessed over HTTPS only. Forever. No risk for MITM even in the first access to these sites.
There are no such HSTS preload lists being provided for non-browser HTTPS clients so there’s no easy way for non-browsers to avoid the first access MITM even for these class of forever-on-HTTPS sites.
I’m sure you’ve heard about the deprecation of SHA-1 as a certificate hashing algorithm and how the browsers won’t accept server certificates using this starting at some cut off date.
I’m not aware of any non-browser HTTPS client that makes this check. For services, API providers and others don’t serve “normal browsers” they can all continue to play SHA-1 certificates well into 2017 without tears or pain. Another ecosystem detail we rely on the browsers to fix for us since most of these providers want to work with browsers as well…
This isn’t really something that is magic or would be terribly hard for non-browsers to do, its just that it will make some users suddenly get errors for their otherwise working setups and that takes a firm attitude from the software provider that is hard to maintain. And you’d have to introduce your own cut-off date that you’d have to fight with your users about! 😉
TLS is hard to get right
TLS and HTTPS are full of tricky areas and dusty corners that are hard to get right. The more we can share tricks and rules the better it is for everyone.
I think the browser vendors could do much better to help the rest of the ecosystem. By making their meta data available to us in sensible formats mostly. For the good of the Internet.
Disclaimer
Yes I work for Mozilla which makes Firefox. A vendor and a browser that I write about above. I’ve been communicating internally about some of these issues already, but I’m otherwise not involved in those parts of Firefox.











 It’s been
It’s been  I was involved in the IETF HTTPbis working group for many years before I joined Mozilla (for over ten years now!) and I hope to be involved for many years still. I still have a lot of things I want to do with curl and to keep curl the champion of its class I need to stay on top of the game.
I was involved in the IETF HTTPbis working group for many years before I joined Mozilla (for over ten years now!) and I hope to be involved for many years still. I still have a lot of things I want to do with curl and to keep curl the champion of its class I need to stay on top of the game.





 intend to do it again:
intend to do it again: 




