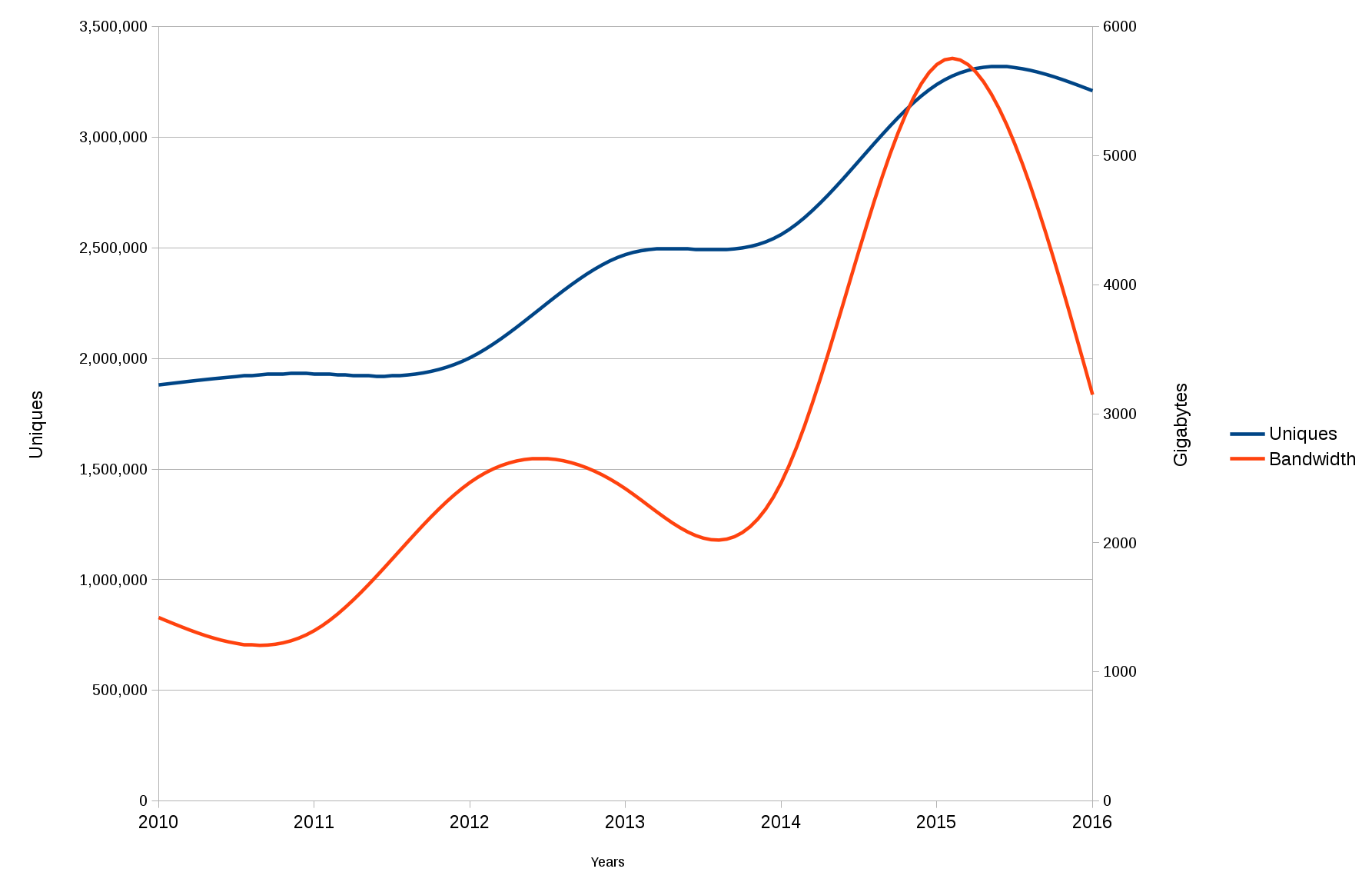
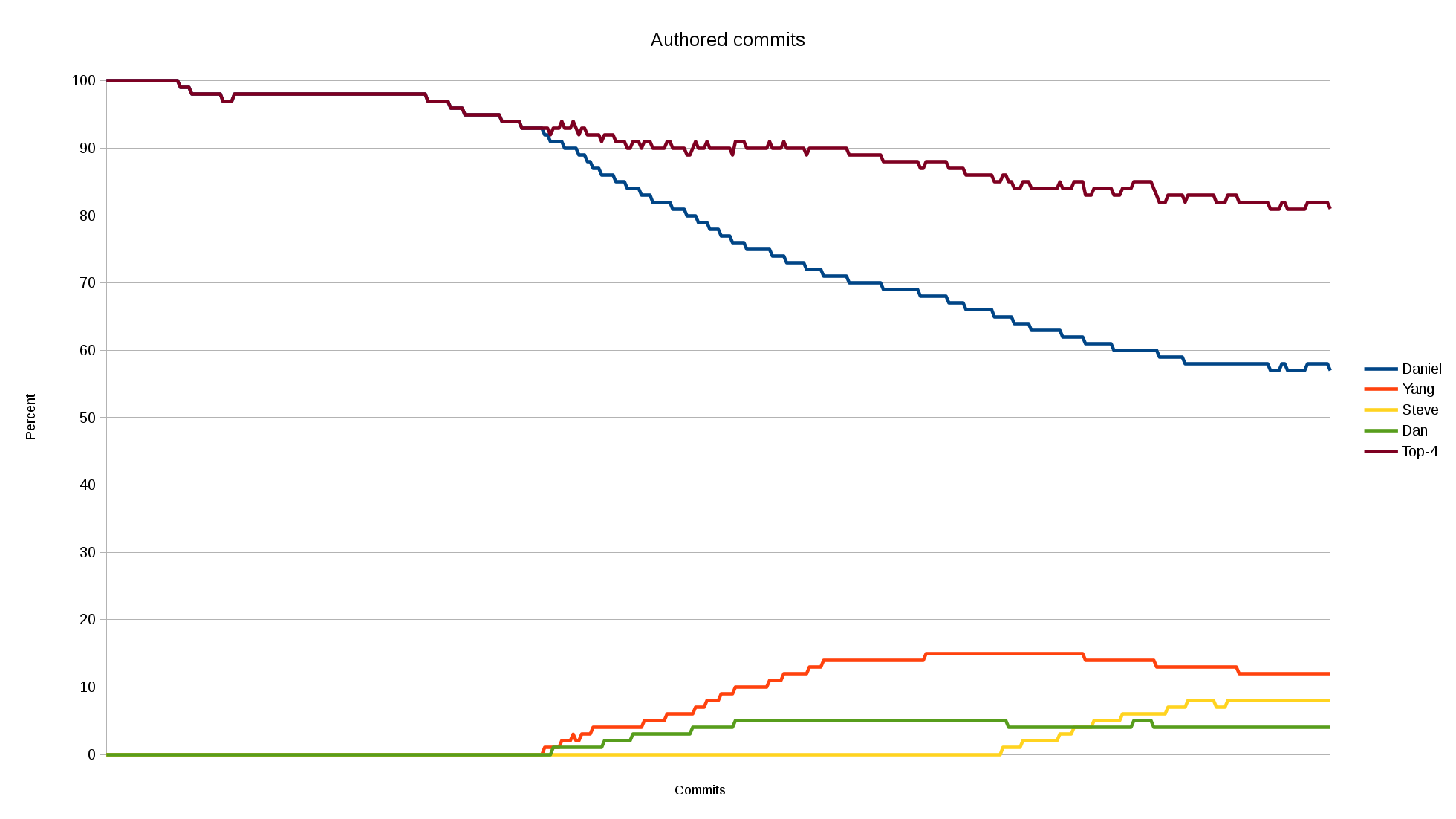
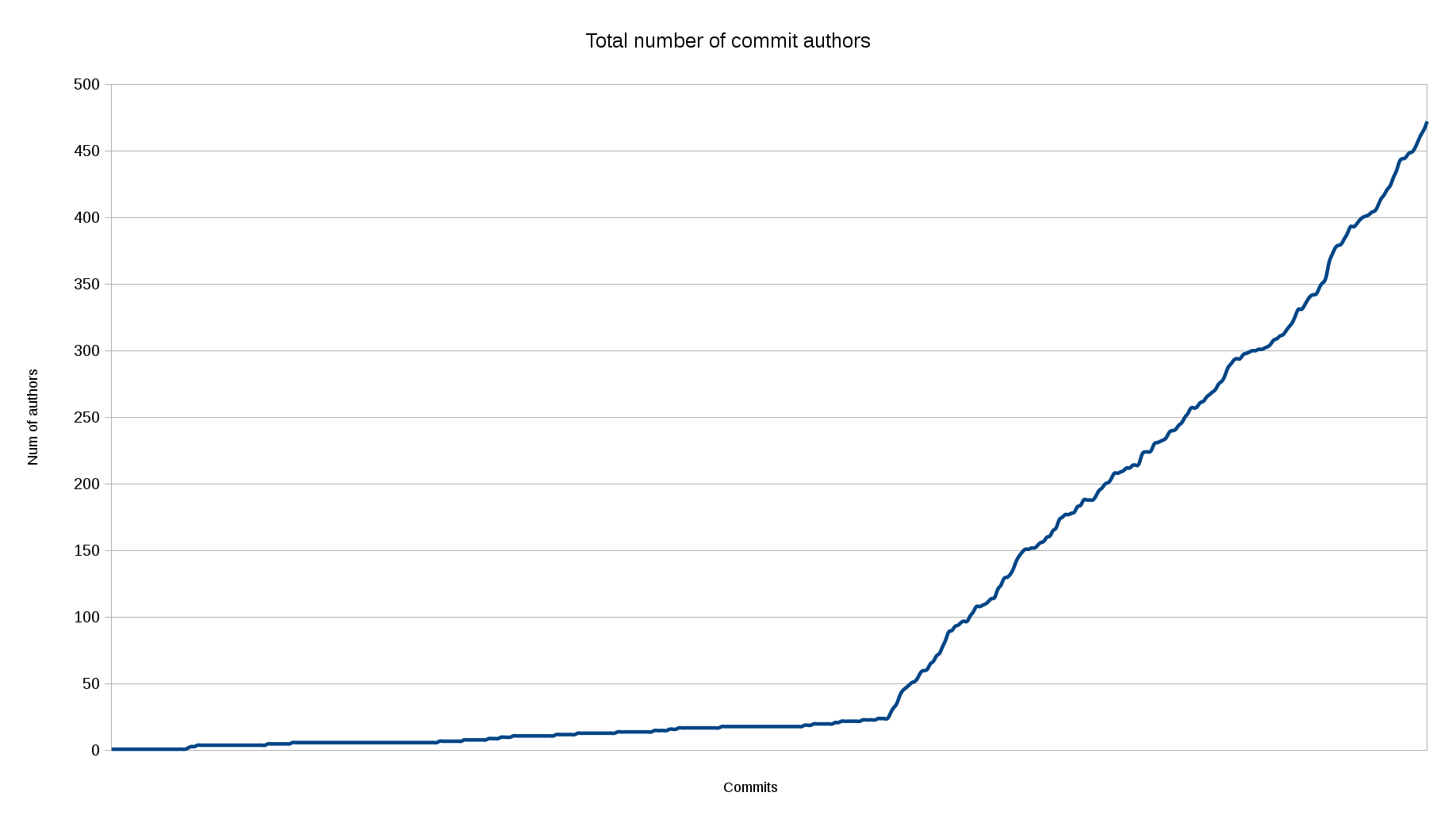
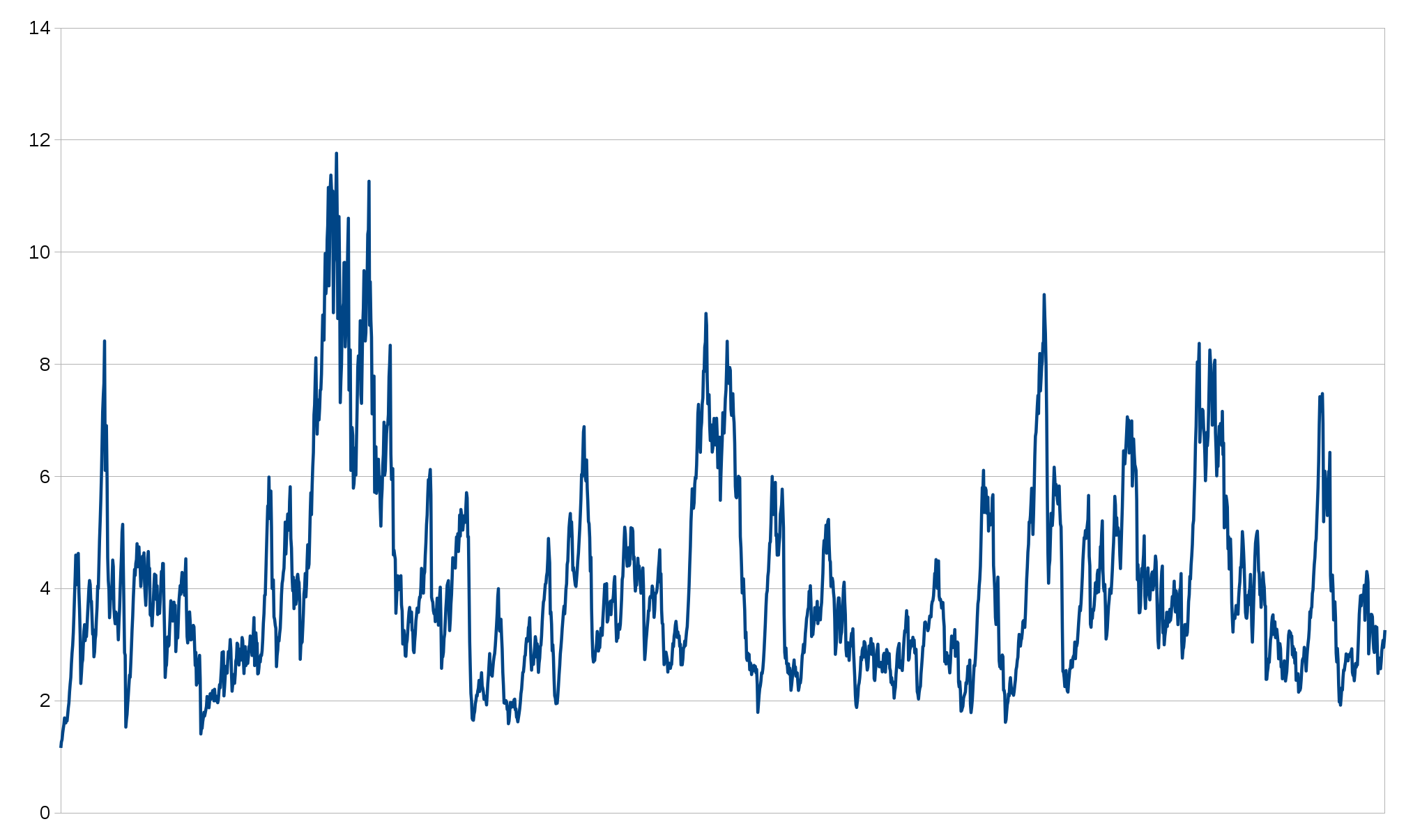
I posted curl is C a few days ago and it raced on hacker news, reddit and elsewhere and got well over a thousand comments in those forums alone. The blog post has been read more than 130,000 times so far.
Addendum a few days later
Many commenters of my curl is C post struck down on my claim that most of our security flaws aren’t due to curl being written in C. It turned out into some sort of CVE counting game in some of the threads.
I think that’s missing the point I was trying to make. Even if 75% of them happened due to us using C, that fact alone would still not be a strong enough reason for me to reconsider our language of choice (at this point in time). We use C for a whole range of reasons as I tried to lay out there in spite of the security challenges the language brings. We know C has tricky corners and we know we are likely to do more mistakes going forward.
curl is currently one of the most distributed and most widely used software components in the universe, be it open or proprietary and there are easily way over three billion instances of it running in appliances, servers, computers and devices across the globe. Right now. In your phone. In your car. In your TV. In your computer. Etc.
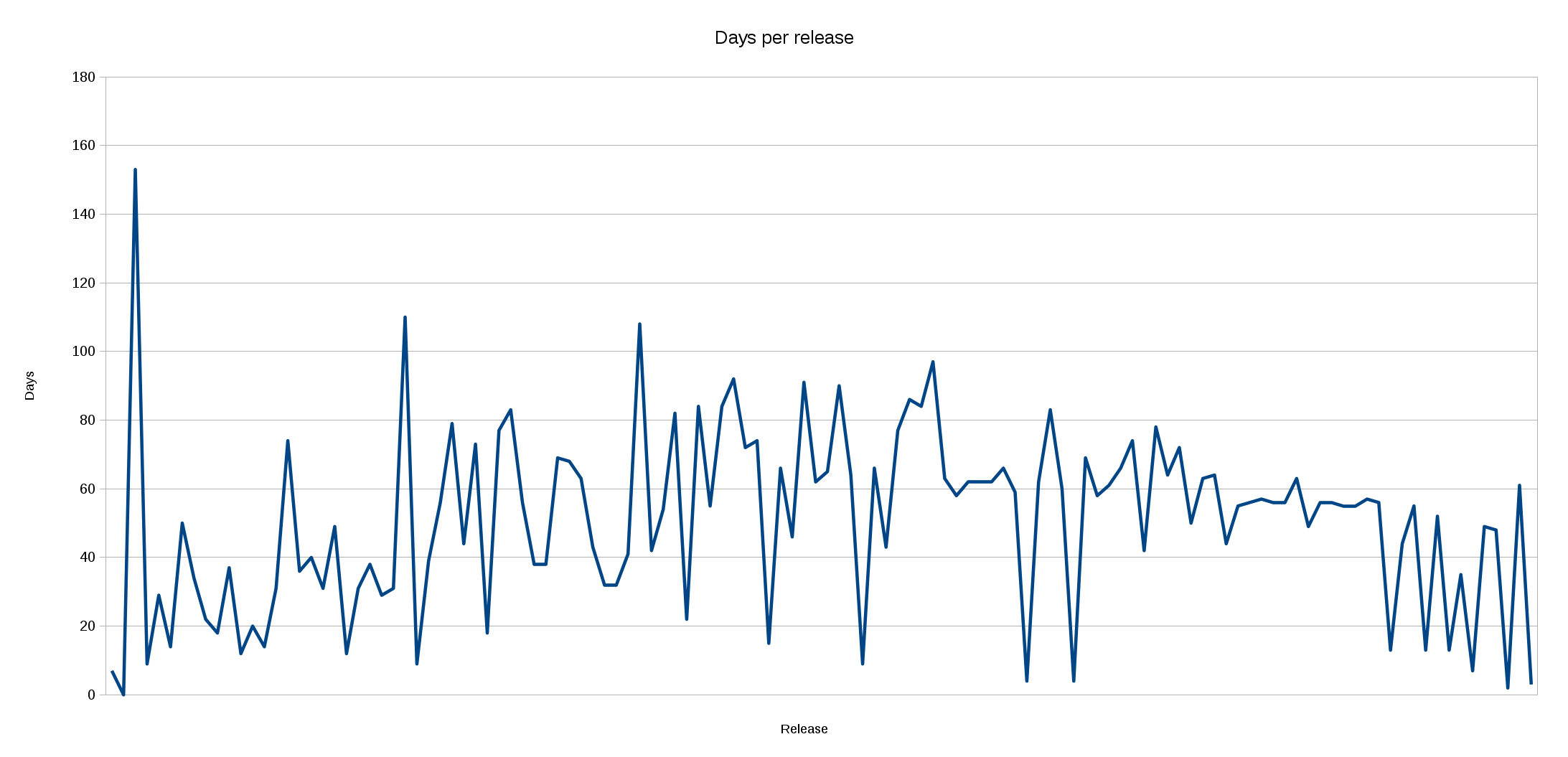
If we then have had 40, 50 or even 60 security problems because of us using C, through-out our 19 years of history, it really isn’t a whole lot given the scale and time we’re talking about here.
Using another language would’ve caused at least some problems due to that language, plus I feel a need to underscore the fact that none of the memory safe languages anyone would suggest we should switch to have been around for 19 years. A portion of our security bugs were even created in our project before those alternatives you would suggest were available! Let alone as stable and functional alternatives.
This is of course no guarantee that there isn’t still more ugly things to discover or that we won’t mess up royally in the future, but who will throw the first stone when it comes to that? We will continue to work hard on minimizing risks, detecting problems early by ourselves and work closely together with everyone who reports suspected problems to us.
Number of problems as a measurement
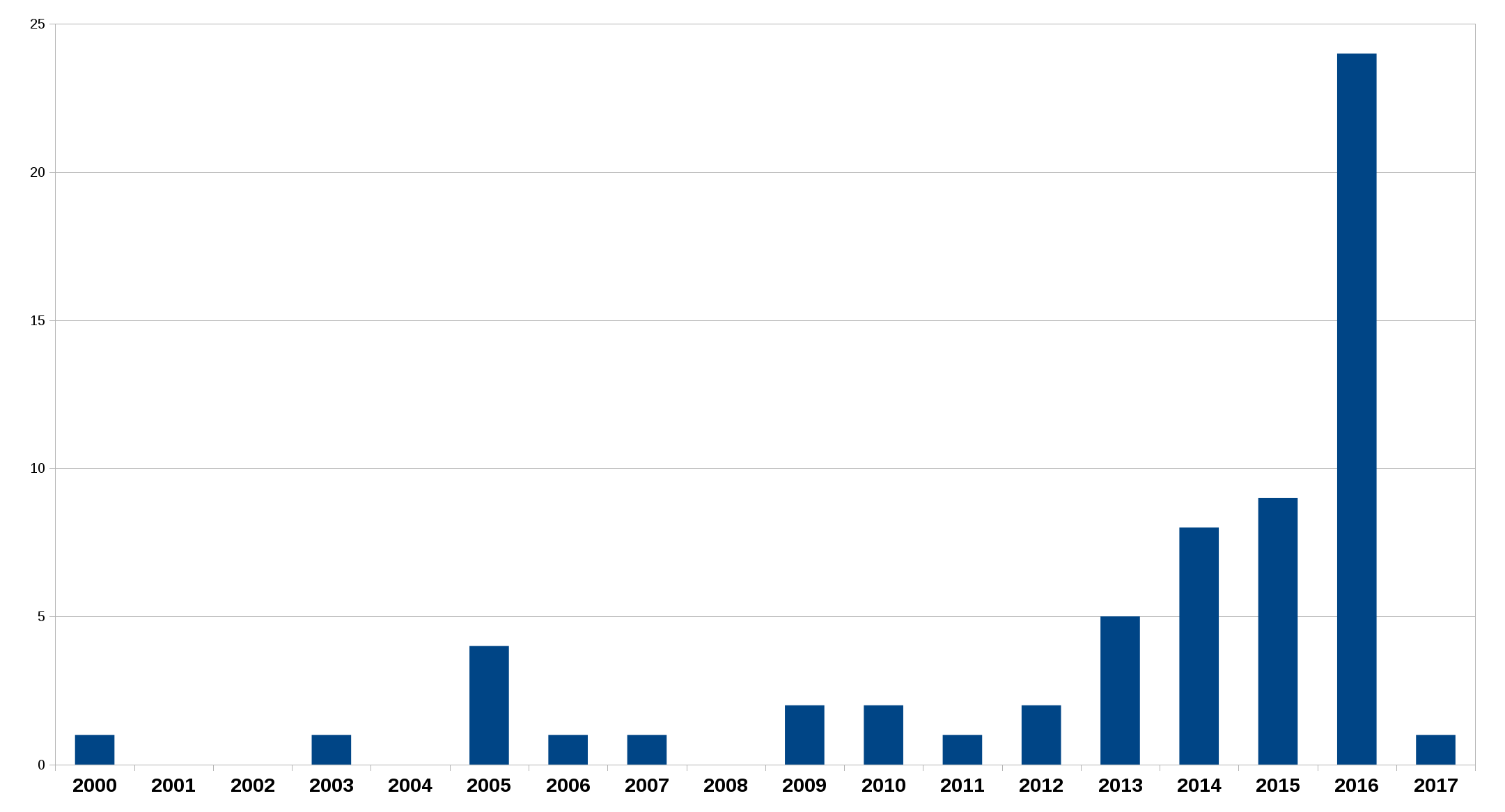
The fact that we have 62 CVEs to date (and more will follow surely) is rather a proof that we work hard on fixing bugs, that we have an open process that deals with the problems in the most transparent way we can think of and that people are on their toes looking for these problems. You should not rate a project in any way purely based on the number of CVEs – you really need to investigate what lies behind the numbers if you want to understand and judge the situation.
Future
Let me clarify this too: I can very well imagine a future where we transition to another language or attempt various others things to enhance the project further – security wise and more. I’m not really ruling anything out as I usually only have very vague ideas of what the future might look like. I just don’t expect it to be happening within the next few years.
These “you should switch language” remarks are strangely enough from the backseat drivers of the Internet. Those who can tell us with confidence how to run our project but who don’t actually show us any code.
Languages
What perhaps made me most sad in the aftermath of said previous post, is everyone who failed to hold more than one thought at a time in their heads. In my post I wrote 800 words on some of the reasoning behind us sticking to the language C in the curl project. I specifically did not say that I dislike certain other languages or that any of those alternative languages are bad or should be avoided. Please friends, I wrote about why curl uses C. There are many fine languages out there and you should all use them as much as you possibly can, and I will too – but not in the curl project (at the moment). So no, I don’t hate language XXXX. I didn’t say so, and I didn’t imply it either. Don’t put that label on me, thanks.