trurl is a tool in a similar spirit of tr but for URLs. Here, tr stands for translate or transpose.
trurl is a small command line tool that parses and manipulates URLs, designed to help shell script authors everywhere.
URLs are tricky to parse and there are numerous security problems in software because of this. trurl wants to help soften this problem by taking away the need for script and command line authors everywhere to re-invent the wheel over and over.
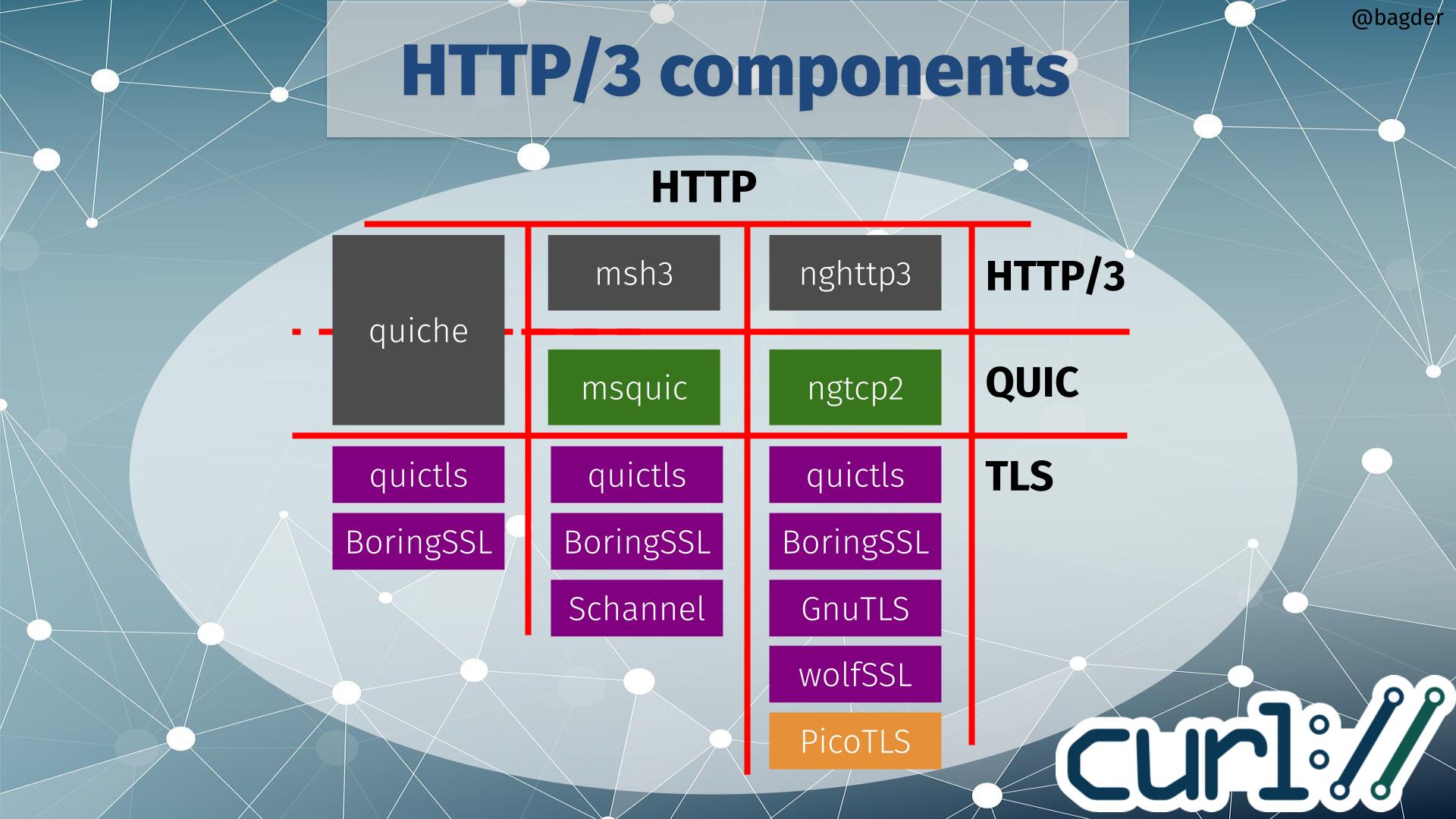
trurl uses libcurl’s URL parser and will thus parse and understand URLs exactly the same as curl the command line tool does – making it the perfect companion tool.
I created trurl on March 31, 2023.
Some command line examples
Given just a URL (even without scheme), it will parse it and output a normalized version:
$ trurl ex%61mple.com/ http://example.com/
The above command will guess on a http:// scheme when none was provided. The guess has basic heuristics, like for example FTP server host names often starts with ftp:
$ trurl ftp.ex%61mple.com/ ftp://ftp.example.com/
A user can output selected components of a provided URL. Like if you only want to extract the path or the query components from it.:
$ trurl https://curl.se/?search=foobar --get '{path}'
/
Or both (with extra text intermixed):
$ trurl https://curl.se/?search=foobar --get 'p: {path} q: {query}'
p: / q: search=foobar
A user can create a URL by providing the different components one by one and trurl outputs the URL:
$ trurl --set scheme=https --set host=fool.wrong https://fool.wrong/
Reset a specific previously populated component by setting it to nothing. Like if you want to clear the user component:
$ trurl https://daniel@curl.se/ --set user=
https://curl.se/
trurl tells you the full new URL when the first URL is redirected to a second relative URL:
$ trurl https://curl.se/we/are/here.html --redirect "../next.html" https://curl.se/we/next.html
trurl provides easy-to-use options for adding new segments to a URL’s path and query components. Not always easily done in shell scripts:
$ trurl https://curl.se/we/are --append path=index.html https://curl.se/we/are/index.html
$ trurl https://curl.se?info=yes --append query=user=loggedin https://curl.se/?info=yes&user=loggedin
trurl can work on a single URL or any amount of URLs passed on to it. The modifications and extractions are then performed on them all, one by one.
$ trurl https://curl.se localhost example.com https://curl.se/ http://localhost/ http://example.com/
trurl can read URLs to work on off a file or from stdin, and works on them in a streaming fashion suitable for filters etc.
$ cat many-urls.yxy | trurl --url-file - ...
More or different
trurl was born just a few days ago, this is what we have made it do so far. There is a high probability that it will change further going forward before it settles on exactly how things ideally should work.
It also means that we are extra open for and welcoming to feedback, ideas and pull-requests. With some luck, this could become a new everyday tool for all of us.
Tell us on GitHub!