The ride is coming to an end. The experiment is done. We tried, but we admit defeat.
Four years ago we started adding support for an alternative HTTP backend in curl. It would use a library written in rust, called hyper. The idea was to introduce an alternative implementation of HTTP internals that you could make curl/libcurl use instead of the native implementation.
This new backend that used a library written in rust would enable users to run a product where a larger piece of the total code than otherwise would be written in a memory-safe language: rust. Memory-safety being all the rage these days.
The initial work was generously sponsored by ISRG, the organization behind such excellent efforts such as Let’s Encrypt, which believes strongly in this concept. I cooperated intensely with Sean McArthur, the lead developer of hyper. We made it work.
We have shipped hyper support in curl labeled EXPERIMENTAL for several years by now, hoping to attract attention and trigger the experimental spirit in users out there. Seeing so many people seem to want more memory-safety, surely the users would come?
95% of the work is the easy part
I mean that we took it perhaps 95% of the way and almost the entire test suite ran identically independently of which backend we built curl to use. The final few percent would however turn out to be friction enough to now eventually make us admit defeat, give up and instead yank it all out again.
There simply were no users asking for it and there were almost no developers interested or knowledgeable enough to work on it. libcurl is written in C, hyper is written in rust and there is a C binding glue layer in between. It takes someone who is interested and good at both languages to dig in, understand the architectures, the challenges and the protocols to drive this all the way through.
But with no user demand, why do it?
It seems quite clear that rust users use hyper but few of them want to work on making it work for a C project like curl, and among existing curl users there is virtually no interest in hyper. The overlap in the Venn diagram of the two universes is not big enough.
With no expectation of seeing this work completed in the short to medium length term, the cost of keeping the hyper code is simply deemed too high. We gain code agility and reduce complexity by trimming this off.
We improved
While the experiment itself is deemed a failure, I think we learned from it and improved curl in the process. We had to rethink and reassess several implementation details when we aligned HTTP behavior with hyper. libcurl parses and handles HTTP stricter now. Better.
I also believe that hyper benefited from this journey and gained experiences and input from us that led to improvements in their end and in their HTTP library. Which then by extension have benefited the hyper users.
When we started this, even rust itself was not ready and over this time rust has improved and it is today a better language and it is better prepared to offer something like this. For us or for other projects.
Backends
With this amputation we are back to no separate HTTP/1 backends. We only provide the single native implementation.
I am not against revisiting the topic and the idea of providing alternative backends for HTTP/1 in the future, but I think we should proceed a little different next time. We also have a better internal architecture now to build on than what we had in 2020 when this attempt started.
Less rust (for now?)
Before this step, we supported three different backends backed up by libraries written in rust. Now we are down to two: rustls (for TLS) and quiche (for QUIC and HTTP/3). Both of them are still marked experimental.
These two backends use better internal APIs in curl and are hooked into libcurl in a cleaner way that makes them easier to support and less of burden to maintain over time.
Of course nothing prevents us from adding support for more and other rust libraries in the future. libcurl is a protocol engine using a plethora of different backends for many different protocols and services hooked into its core. Virtually all of those backends could be provided by a rust library.
Thanks
A big thank you go to Sean and all others who helped us take it as far as we did. You are great. Nothing of this should put any shade on you.
When
The hyper backend code has been removed in git as of December 21. There will be no traces left of it in the curl 8.12.0 release coming in February 2025.
In this presentation I talk about how libcurl’s most important aspect is the stable ABI and API. If we just maintain those, we can change the internals however we like.
libcurl has a system with build-time selected components, called backends. They are usually powered by third party libraries. With the recently added HTTP backend there are now seven “flavors” of backends.
A backend can be provided by a library written in rust, as long as that rust component provides a C interface that libcurl can use. When it does, it being rust or not is completely transparent and a non-issue for libcurl.
curl currently supports components written in rust for three different backends:
curl is an internet transfer engine. A rather modular one too. Parts of curl’s functionality is provided by selectable alternative implementations that we call backends. You select what backends to enable at build-time and in many cases the backends are enabled and powered by different 3rd party libraries.
Many backends
curl has a range of such alternative backends for various features:
International Domain Names
Name resolving
TLS
SSH
HTTP/3
HTTP content encoding
HTTP
Stable API and ABI
Maintaining a stable API and ABI is key to libcurl. As long as those promises are kept, changing internals such as switching between backends is perfectly fine.
The API is the armored front door that we don’t change. The backends is the garden on the back of the house that we can dig up and replant every year if we want, without us having to change the front door.
TLS backends
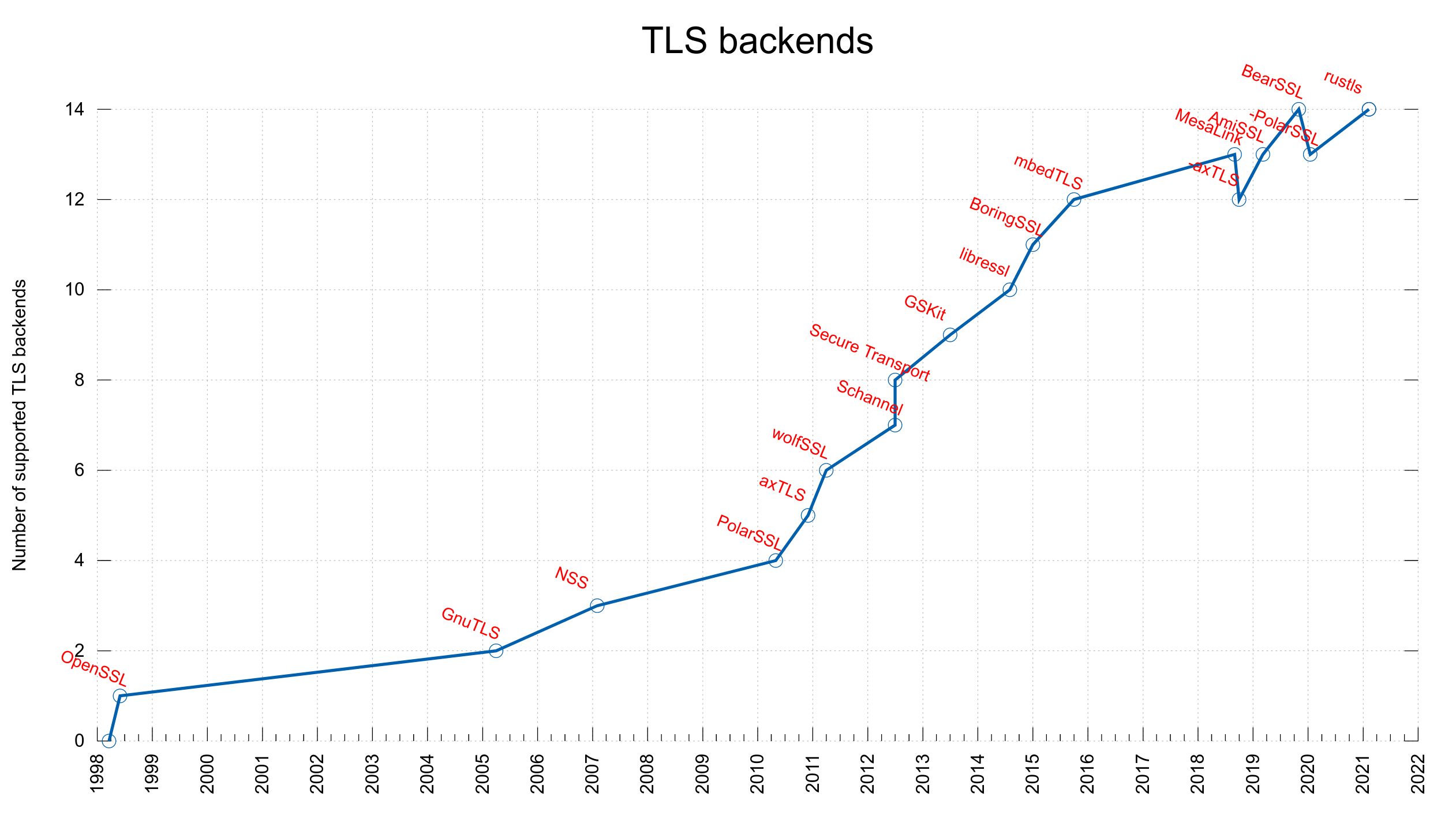
Already back in 2005 we added support for using an alternative TLS library in curl when we added support for GnuTLS in addition to OpenSSL, and since then we’ve added many more. We do this by having an internal API through which we do all the TLS related things and for each third party library we support we have code that does the necessary logic to connect the internal API with the corresponding TLS library.
rustls
Today, we merged support for yet another TLS library: rustls. This is a TLS library written in rust and it has a C API provided in a separate project called crustls. Strictly speaking, curl is built to use crustls.
This is still early days for the rustls backend and it is not yet feature complete. There’s more work to do and polish to apply before we can think of it as a proper competitor to the already established and well-used TLS backends, but with this merge it makes it much easier for more people to help out and test it out. Feel free and encouraged to join in!
We count this addition as the 14th concurrently supported TLS library in curl. I’m not aware of any other project, anywhere, that supports more or even this many TLS libraries.
rustls again!
The TLS library named mesalink is actually already using rustls, but under an OpenSSL API disguise and we support that since a few years back…
Credits
The TLS backend code for rustls was written and contributed by Jacob Hoffman-Andrews.
On February 11th, 2021 18:00 UTC (10am Pacific time, 19:00 Central Europe) we invite you to participate in a webinar we call “curl, Hyper and Rust”. To join us at the live event, please register via the link below:
https://www.wolfssl.com/isrg-partner-webinar/
What is the project about, how will this improve curl and Hyper, how was it done, what lessons can be learned, what more can we expect in the future and how can newcomers join in and help?
Participating speakers in this webinar are:
Daniel Stenberg. Founder of and lead developer of curl.
Josh Aas, Executive Director at ISRG / Let’s Encrypt.
The event went on for 60 minutes, including the Q&A session at the end.
Recording
Questions?
If you already have a question you want to ask, please let us know ahead of time. Either in a reply here on the blog, or as a reply on one of the many tweets that you will see about about this event from me and my fellow “webinarees”.
tldr: work has started to make Hyper work as a backend in curl for HTTP.
curl and its data transfer core, libcurl, is all written in C. The language C is known and infamous for not being memory safe and for being easy to mess up and as a result accidentally cause security problems.
At the same time, C compilers are very widely used and available and you can compile C programs for virtually every operating system and CPU out there. A C program can be made far more portable than code written in just about any other programming language.
curl is a piece of “insecure” C code installed in some ten billion installations world-wide. I’m saying insecure within quotes because I don’t think curl is insecure. We have our share of security vulnerabilities of course, even if I think the rate of them getting found has been drastically reduced over the last few years, but we have never had a critical one and with the help of busloads of tools and humans we find and fix most issues in the code before they ever land in the hands of users. (And “memory safety” is not the single explanation for getting security issues.)
I believe that curl and libcurl will remain in wide use for a long time ahead: curl is an established component and companion in scripts and setups everywhere. libcurl is almost a de facto standard in places for doing internet transfers.
A rewrite of curl to another language is not considered. Porting an old, established and well-used code base such as libcurl, which to a far degree has gained its popularity and spread due to a stable API, not breaking the ABI and not changing behavior of existing functionality, is a massive and daunting task. To the degree that so far it hasn’t been attempted seriously and even giant corporations who have considered it, have backpedaled such ideas.
Change, but not change
This preface above might make it seem like we’re stuck with exactly what we have for as long as curl and libcurl are used. But fear not: things are more complicated, or perhaps brighter, than it first seems.
What’s important to users of libcurl needs to be kept intact. We keep the API, the ABI, the behavior and all the documented options and features remain. We also need to continuously add stuff and keep up with the world going forward.
But we can change the internals! Refactor as the kids say.
Backends, backends, backends
Already today, you can build libcurl to use different “backends” for TLS, SSH, name resolving, LDAP, IDN, GSSAPI and HTTP/3.
A “backend” in this context is a piece of code in curl that lets you use a particular solution, often involving a specific third party library, for a certain libcurl functionality. Using this setup you can, for example, opt to build libcurl with one or more out of thirteen different TLS libraries. You simply pick the one(s) you prefer when you build it. The libcurl API remains the same to users, it’s just that some features and functionality might differ a bit. The number of TLS backends is of course also fluid over time as we add support for more libraries in the future, or even drop support for old ones as they fade away.
When building curl, you can right now make it use up to 33 different third party libraries for different functions. Many of them of course mutually exclusive, so no single build can use all 33.
Said differently: you can improve your curl and libcurl binaries without changing any code, by simply rebuilding it to use another backend combination.
Green boxes are possible third-party dependencies curl can be told to use. No Hyper in this map yet…
libcurl as a glorified switch
With an extensive set of backends that use third party libraries, the job of libcurl to a large extent becomes to act as a switch between the provided stable external API and the particular third party library that does the heavy lifting.
API <=> glue code in C <=> backend library
libcurl as the rock, with a door and the entry rules written in stone. The backends can come and go, change and improve, but the applications outside the entrance won’t notice that. They get a stable API and ABI that they know and trust.
Safe backends
This setup provides a foundation and infrastructure to offer backends written in other languages as part of the package. As long as those libraries have APIs that are accessible to libcurl, libraries used by the backends can be written in any language – but since we’re talking about memory safety in this blog post the most obvious choices would probably be one of the modern and safe languages. For example Rust.
With a backend library written in Rust , libcurl would lean on such a component to do low level protocol work and presumably, by doing this it increases the chances of the implementations to be safe and secure.
Two of the already supported third party libraries in the world map image above are written in Rust: quiche and Mesalink.
Hyper as a backend for HTTP
Hyper is a HTTP library written in Rust. It is meant to be fast, accurate and safe, and it supports both HTTP/1 and HTTP/2.
As another step into this world of an ever-growing number of backends to libcurl, work has begun to make sure curl (optionally) can get built to use Hyper.
This work is gracefully funded by ISRG, perhaps mostly known as the organization behind Let’s Encrypt. Thanks!
Many challenges remain
I want to emphasize that this is early days. We know what we want to do, we know basically how to do it but from there to actually getting it done and providing it in source code to the world is a little bit of work that hasn’t been done. I’m set out to do it.
Hyper didn’t have a C API, they’re working on making one so that C based applications such as curl can actually use it. I do my best at providing feedback from my point of view, but as I’m not really into Rust much I can’t assist much with the implementation parts there.
Once there’s an early/alpha version of the API to try out, I will first make sure curl can get built to use Hyper, and then start poking on the code to start using it.
In that work I expect me to have to go back to the API with questions, feedback and perhaps documentation suggestions. I also anticipate challenges in switching libcurl internals to using this. Mostly small ones, but possibly also larger ones.
I have created a git branch and make my work on this public and accessible early on to let everyone who wants to, to keep up with the development. A first milestone will be the ability to run a single curl test case (any test case) successfully – unmodified. The branch is here: https://github.com/curl/curl/tree/bagder/hyper – beware that it will be rebased frequently.
There’s no deadline for this project and I don’t yet have any guesses as when there will be anything to test.
Rust itself is not there yet
This project is truly ground work for future developers to build upon as some of the issues dealt with in here should benefit others as well down the road. For example it immediately became obvious that Rust in general encourages to abort on out-of-memory issues, while this is a big nono when the code is used in a system library (such as curl).
I’m a bit vague on the details here because it’s not my expertise, but Rust itself can’t even properly clean up its memory and just returns error when it hits such a condition. Clearly something to fix before a libcurl with hyper could claim identical behavior and never to leak memory.
By default?
Will Hyper be used by default in a future curl build near you?
We’re going to work on the project to make that future a possibility with the mindset that it could benefit users.
If it truly happens involve many different factors (for example maturity, feature set, memory footprint, performance, portability and on-disk footprint…) and in particular it will depend a lot on the people that build and ship the curl packages you use – which isn’t the curl project itself as we only ship source code. I’m thinking of Linux and operating system distributions etc.
When it might happen we can’t tell yet as we’re still much too early in this process.
Still a lot of C
This is not converting curl to Rust.
Don’t be fooled into believing that we are getting rid of C in curl by taking this step. With the introduction of a Hyper powered backend, we will certainly reduce the share of C code that is executed in a typical HTTP transfer by a measurable amount (for those builds), but curl is much more than that.
It’s not even a given that the Hyper backend will “win” the competition for users against the C implementation on the platforms you care about. The future is not set.
More backends in safe languages?
Sure, why not? There are efforts to provide more backends written in Rust. Gradually, we might move into a future where less and less of the final curl and libcurl executable code was compiled from C.
How and if that will happen will of course depend on a lot of factors – in particular funding of the necessary work.
Can we drive the development in this direction even further? I think it is much too early to speculate on that. Let’s first see how these first few episodes into the coming decades turn out.