The official publication date of the relevant QUIC specifications is: May 27, 2021.
I’ve done many presentations about HTTP and related technologies over the years. HTTP/2 had only just shipped when the QUIC working group had been formed in the IETF and I started to mention and describe what was being done there.
I’ve explained HTTP/3
I started writing the document HTTP/3 explained in February 2018 before the protocol was even called HTTP/3 (and yeah the document itself was also called something else at first). The HTTP protocol for QUIC was just called “HTTP over QUIC” in the beginning and it took until November 2018 before it got the name HTTP/3. I did my first presentation using HTTP/3 in the title and on slides in early December 2018, My first recorded HTTP/3 presentation was in January 2019 (in Stockholm, Sweden).
In that talk I mentioned that the protocol would be “live” by the summer of 2019, which was an optimistic estimate based on the then current milestones set out by the IETF working group.
I think my optimism regarding the release schedule has kept up but as time progressed I’ve updated that estimation many times…
HTTP/3 – not yet
The first four RFC documentations to be ratified and published only concern QUIC, the transport protocol, and not the HTTP/3 parts. The two HTTP/3 documents are also in queue but are slightly delayed as they await some other prerequisite (“generic” HTTP update) documents to ship first, then the HTTP/3 ones can ship and refer to those other documents.
QUIC
QUIC is a new transport protocol. It is done over UDP and can be described as being something of a TCP + TLS replacement, merged into a single protocol.
Okay, the title of this blog is misleading. QUIC is actually documented in four different RFCs:
RFC 9002 – QUIC Loss Detection and Congestion Control
My role: I’m just a bystander
I initially wanted to keep up closely with the working group and follow what happened and participate on the meetings and interims etc. It turned out to be too difficult for me to do that so I had to lower my ambitions and I’ve mostly had a casual observing role. I just couldn’t muster the energy and spend the time necessary to do it properly.
I’ve participated in many of the meetings, I’ve been present in the QUIC implementers slack, I’ve followed lots of design and architectural discussions on the mailing list and in GitHub issues. I’ve worked on implementing support for QUIC and h3 in curl and thanks to that helped out iron issues and glitches in various implementations, but the now published RFCs have virtually no traces of me or my feedback in them.
tldr: the level of HTTP/3 support in servers is surprisingly high.
The specs
The specifications are all done. They’re now waiting in queues to get their final edits and approvals before they will get assigned RFC numbers and get published as such – they will not change any further. That’s a set of RFCs (six I believe) for various aspects of this new stack. The HTTP/3 spec is just one of those. Remember: HTTP/3 is the application protocol done over the new transport QUIC. (See http3 explained for a high-level description.)
The HTTP/3 spec was written to refer to, and thus depend on, two other HTTP specs that are in the works: httpbis-cache and https-semantics. Those two are mostly clarifications and cleanups of older HTTP specs, but this forces the HTTP/3 spec to have to get published after the other two, which might introduce a small delay compared to the other QUIC documents.
The working group has started to take on work on new specifications for extensions and improvements beyond QUIC version 1.
HTTP/3 Usage
In early April 2021, the usage of QUIC and HTTP/3 in the world is measured by a few different companies.
QUIC support
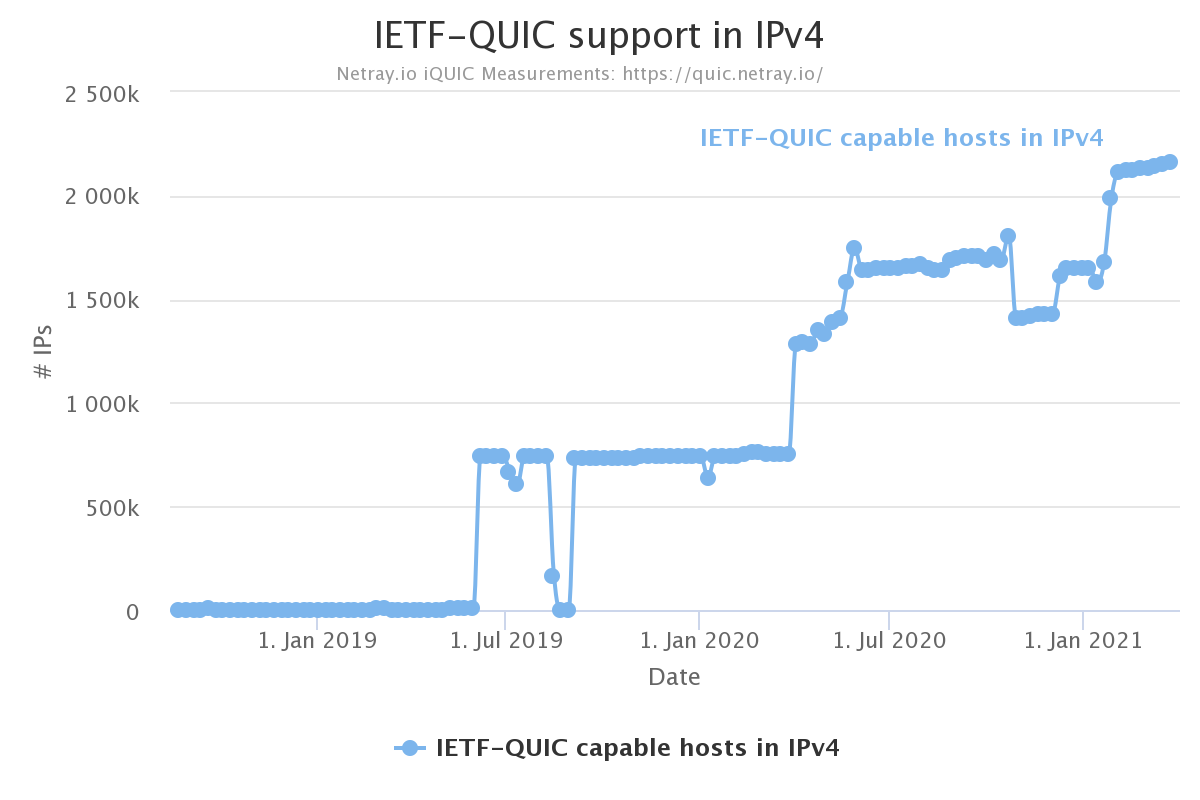
netray.io scans the IPv4 address space weekly and checks how many hosts that speak QUIC. Their latest scan found 2.1 million such hosts.
Arguably, the netray number doesn’t say much. Those two million hosts could be very well used or barely used machines.
HTTP/3 by w3techs
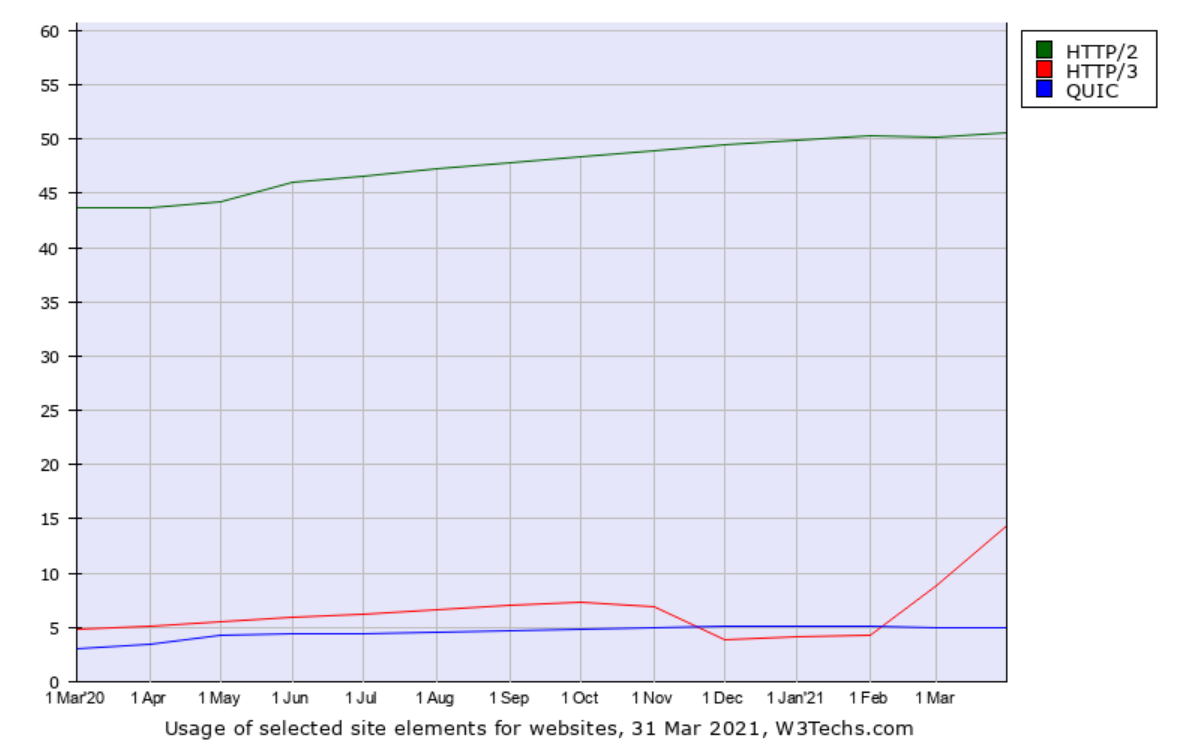
w3techs.com has been in the game of scanning web sites for stats purposes for a long time. They scan the top ten million sites and count how large share that runs/supports what technologies and they also check for HTTP/3. In their data they call the old Google QUIC for just “QUIC” which is confusing but that should be seen as the precursor to HTTP/3.
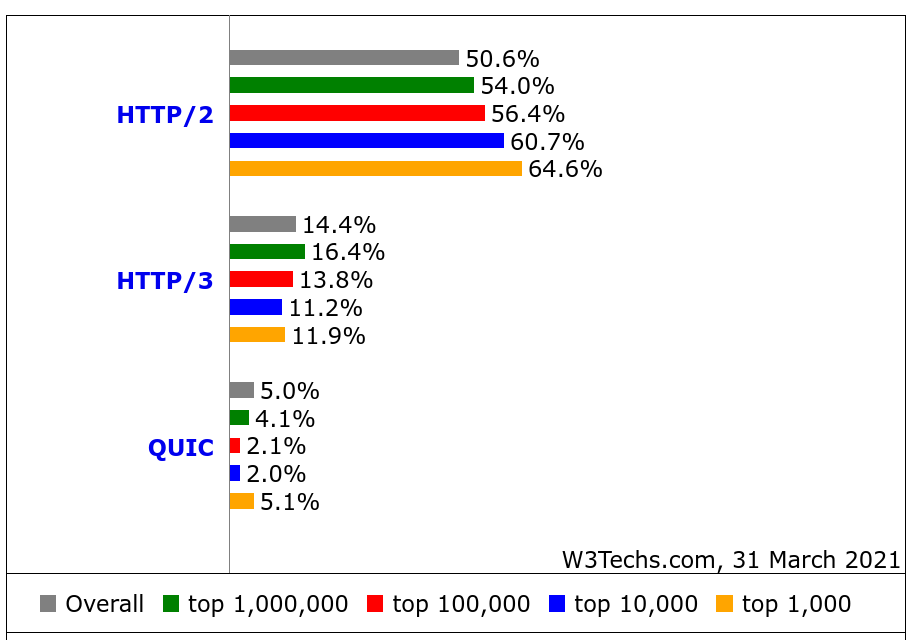
What stands out to me in this data except that the HTTP/3 usage seems very high: the top one-million sites are claimed to have a higher share of HTTP/3 support (16.4%) than the top one-thousand (11.9%)! That’s the reversed for HTTP/2 and not how stats like this tend to look.
It has been suggested that the growth starting at Feb 2021 might be explained by Cloudflare’s enabling of HTTP/3 for users also in their free plan.
HTTP/3 by Cloudflare
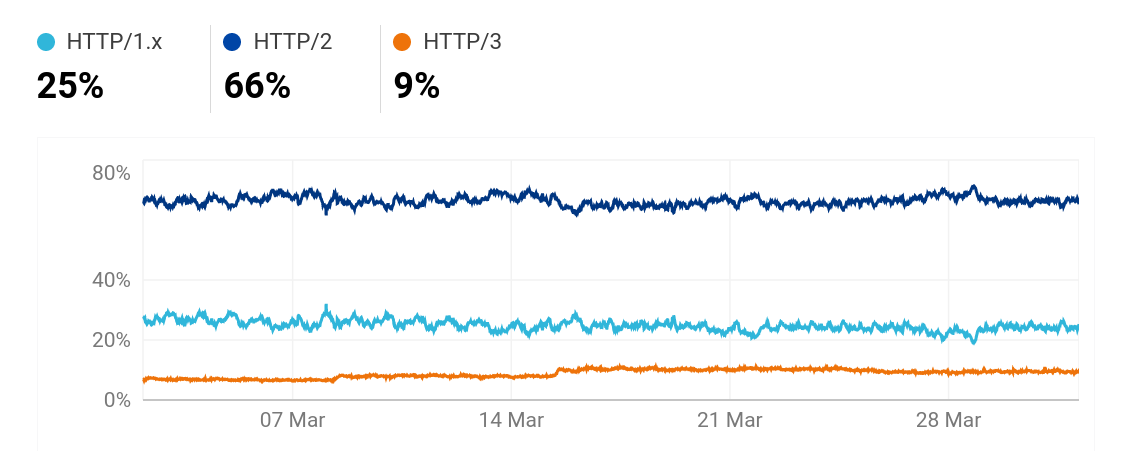
On radar.cloudflare.com we can see Cloudflare’s view of a lot of Internet and protocol trends over the world.
The last 30 days according to radar.cloudflare.com
This HTTP/3 number is significantly lower than w3techs’. Presumably because of the differences in how they measure.
Clients
The browsers
All the major browsers have HTTP/3 implementations and most of them allow you to manually enable it if it isn’t already done so. Chrome and Edge have it enabled by default and Firefox will so very soon. The caniuse.com site shows it like this (updated on April 4):
(Earlier versions of this blog post showed the previous and inaccurate data from caniuse.com. Not anymore.)
curl
curl supports HTTP/3 since a while back, but you need to explicitly enable it at build-time. It needs to use third party libraries for the HTTP/3 layer and it needs a QUIC capable TLS library. The QUIC/h3 libraries are still beta versions. See below for the TLS library situation.
curl’s HTTP/3 support is not even complete. There are still unsupported areas and it’s not considered stable yet.
curl supports 14 different TLS libraries at this time. Two of them have QUIC support landed: BoringSSL and GnuTLS. And a third would be the quictls OpenSSL fork. (There are also a few other smaller TLS libraries that support QUIC.)
OpenSSL
The by far most popular TLS library to use with curl, OpenSSL, has postponed their QUIC work:
At the same time they have delayed the OpenSSL 3.0 release significantly. Their release schedule page still today speaks of a planned release of 3.0.0 in “early Q4 2020”. That plan expects a few months from the beta to final release and we have not yet seen a beta release, only alphas.
Realistically, this makes QUIC in OpenSSL many months off until it can appear even in a first alpha. Maybe even 2022 material?
BoringSSL
The Google powered OpenSSL fork BoringSSL has supported QUIC for a long time and provides the OpenSSL API, but they don’t do releases and mostly focus on getting a library done for Google. People outside the company are generally reluctant to use and depend on this library for those reasons.
The quiche QUIC/h3 library from Cloudflare uses BoringSSL and curl can be built to use quiche (as well as BoringSSL).
quictls
Microsoft and Akamai have made a fork of OpenSSL available that is based on OpenSSL 1.1.1 and has the QUIC pull-request applied in order to offer a QUIC capable OpenSSL flavor to the world before the official OpenSSL gets their act together. This fork is called quictls. This should be compatible with OpenSSL in all other regards and provide QUIC with an API that is similar to BoringSSL’s.
The ngtcp2 QUIC library uses quictls. curl can be built to use ngtcp2 as well as with quictls,
Is HTTP/3 faster?
I realize I can’t blog about this topic without at least touching this question. The main reason for adding support for HTTP/3 on your site is probably that it makes it faster for users, so does it?
According to cloudflare’s tests, it does, but the difference is not huge.
We’ve seen other numbers say h3 is faster shown before but it’s hard to find up-to-date performance measurements published for the current version of HTTP/3 vs HTTP/2 in real world scenarios. Partly of course because people have hesitated to compare before there are proper implementations to compare with, and not just development versions not really made and tweaked to perform optimally.
I think there are reasons to expect h3 to be faster in several situations, but for people with high bandwidth low latency connections in the western world, maybe the difference won’t be noticeable?
Future
I’ve previously shown the slide below to illustrate what needs to be done for curl to ship with HTTP/3 support enabled in distros and “widely” and I think the same works for a lot of other projects and clients who don’t control their TLS implementation and don’t write their own QUIC/h3 layer code.
This house of cards of h3 is slowly getting some stable components, but there are still too many moving parts for most of us to ship.
I assume that the rest of the browsers will also enable HTTP/3 by default soon, and the specs will be released not too long into the future. That will make HTTP/3 traffic on the web increase significantly.
The QUIC and h3 libraries will ship their first non-beta versions once the specs are out.
The TLS library situation will continue to hamper wider adoption among non-browsers and smaller players.
The big players already deploy HTTP/3.
Updates
I’ve updated this post after the initial publication, and the biggest corrections are in the Chrome/Edge details. Thanks to immediate feedback from Eric Lawrence. Remaining errors are still all mine! Thanks also to Barry Pollard who filed the PR to update the previously flawed caniuse.com data.
We have started the work on extending wolfSSL to provide the necessary API calls to power QUIC and HTTP/3 implementations!
Small, fast and FIPS
The TLS library known as wolfSSL is already very often a top choice when users are looking for a small and yet very fast TLS stack that supports all the latest protocol features; including TLS 1.3 support – open source with commercial support available.
As manufacturers of IoT devices and other systems with memory, CPU and footprint constraints are looking forward to following the Internet development and switching over to upcoming QUIC and HTTP/3 protocols, wolfSSL is here to help users take that step.
A QUIC reminder
In case you have forgot, here’s a schematic view of HTTPS stacks, old vs new. On the right side you can see HTTP/3, QUIC and the little TLS 1.3 box there within QUIC.
ngtcp2
There are no plans to write a full QUIC stack. There are already plenty of those. We’re talking about adjustments and extensions of the existing TLS library API set to make sure wolfSSL can be used as the TLS component in a QUIC stack.
One of the leading QUIC stacks and so far the only one I know of that does this, ngtcp2 is written to be TLS library agnostic and allows different TLS libraries to be plugged in as different backends. I believe it makes perfect sense to make such a plugin for wolfSSL to be a sensible step as soon as there’s code to try out.
A neat effect of that, would be that once wolfSSL works as a backend to ngtcp2, it should be possible to do full-fledged HTTP/3 transfers using curl powered by ngtcp2+wolfSSL. Contact us with other ideas for QUIC stacks you would like us to test wolfSSL with!
FIPS 140-2
We expect wolfSSL to be the first FIPS-based implementation to add support for QUIC. I hear this is valuable to a number of users.
When
This work begins now and this is just a blog post of our intentions. We and I will of course love to get your feedback on this and whatever else that is related. We’re also interested to get in touch with people and companies who want to be early testers of our implementation. You know where to find us!
I can promise you that the more interest we can sense to exist for this effort, the sooner we will see the first code to test out.
It seems likely that we’re not going to support any older TLS drafts for QUIC than draft-29.
I want curl to be on the very bleeding edge of protocol development to aid the Internet protocol development community to test out protocols early and to work out kinks in the protocols and server implementations using curl’s vast set of tools and switches.
For this, curl supported HTTP/2 really early on and helped shaping the protocol and testing out servers.
For this reason, curl supports HTTP/3 already since August 2019. A convenient and well-known client that you can then use to poke on your brand new HTTP/3 servers too and we can work on getting all the rough edges smoothed out before the protocol is reaching its final state.
QUIC tooling
One of the many challenges QUIC and HTTP/3 have is that with a new transport protocol comes entirely new paradigms. With new paradigms like this, we need improved or perhaps even new tools to help us understand the network flows back and forth, to make sure we all have a common understanding of the protocols and to make sure we implement our end-points correctly.
QUIC only exists as an encrypted-only protocol, meaning that we can no longer easily monitor and passively investigate network traffic like before, QUIC also encrypts more of the protocol than TCP + TLS do, leaving even less for an outsider to see.
The current QUIC analyzer tool lineup gives us two options.
Wireshark
We all of course love Wireshark and if you get a very recent version, you’ll be able to decrypt and view QUIC network data.
With curl, and a few other clients, you can ask to get the necessary TLS secrets exported at run-time with the SSLKEYLOGFILE environment variable. You’ll then be able to see every bit in every packet. This way to extract secrets works with QUIC as well as with the traditional TCP+TLS based protocols.
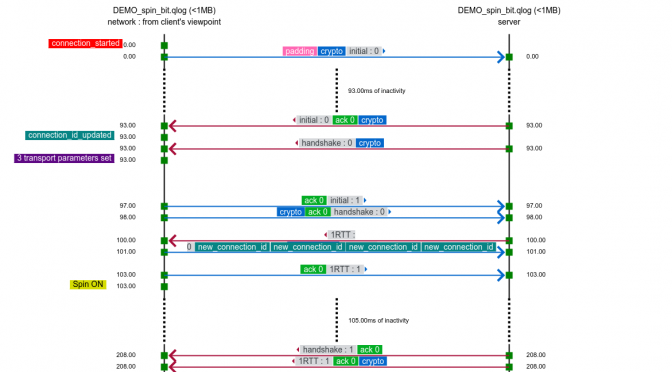
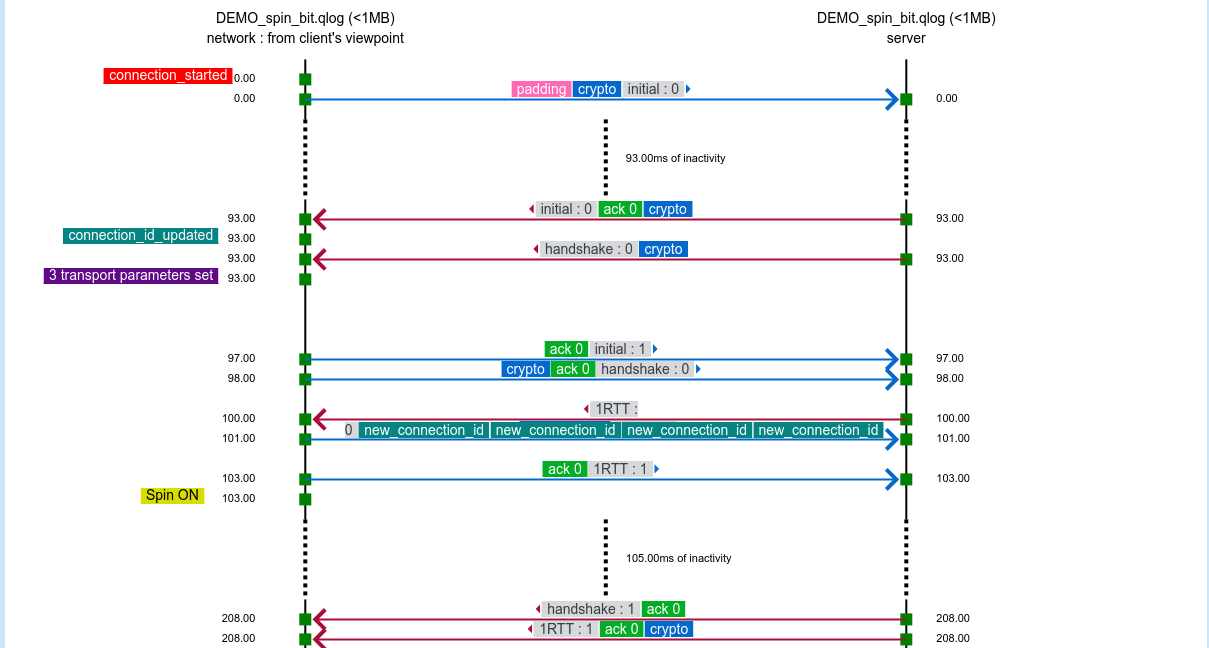
qvis/qlog
The qvis/qlog site. If you find the Wireshark network view a little bit too low level and leaving a lot for you to understand and draw conclusions from, the next-level tool here is the common QUIC logging format called qlog. This is an agreed-upon common standard to log QUIC traffic, which the accompanying qvis web based visualizer tool that lets you upload your logs and get visualizations generated. This becomes extra powerful if you have logs from both ends!
Starting with this commit (landed in the git master branch on May 7, 2020), all curl builds that support HTTP/3 – independent of what backend you pick – can be told to output qlogs.
Enable qlogging in curl by setting the new standard environment variable QLOGDIR to point to a directory in which you want qlogs to be generated. When you run curl then, you’ll get files creates in there named as [hex digits].log, where the hex digits is the “SCID” (Source Connection Identifier).
Credits
qlog and qvis are spear-headed by Robin Marx. qlogging for curl with Quiche was pushed for by Lucas Pardue and Alessandro Ghedini. In the ngtcp2 camp, Tatsuhiro Tsujikawa made it very easy for me to switch it on in curl.
The top image is snapped from the demo sample on the qvis web site.
FOSDEM 2020 is over for this time and I had an awesome time in Brussels once again.
Stickers
I brought a huge collection of stickers this year and I kept going back to the wolfSSL stand to refill the stash and it kept being emptied almost as fast. Hundreds of curl stickers were given away! The photo on the right shows my “sticker bag” as it looked before I left Sweden.
Lesson for next year: bring a larger amount of stickers! If you missed out on curl stickers, get in touch and I’ll do my best to satisfy your needs.
The talk
“HTTP/3 for everyone” was my single talk this FOSDEM. Just two days before the talk, I landed updated commits in curl’s git master branch for doing HTTP/3 up-to-date with the latest draft (-25). Very timely and I got to update the slide mentioning this.
As I talked HTTP/3 already last year in the Mozilla devroom, I also made sure to go through the slides I used then to compare and make sure I wouldn’t do too much of the same talk. But lots of things have changed and most of the content is updated and different this time around. Last year, literally hundreds of people were lining up outside wanting to get into room when the doors were closed. This year, I talked in the room Janson, which features 1415 seats. The biggest one on campus. It was pack full!
It is kind of an adrenaline rush to stand in front of such a wall of people. At one time in my talk I paused for a brief moment and then I felt I could almost hear the complete silence when a huge amount of attentive faces captured what I had to say.
I got a lot of positive feedback on the presentation. I also thought that my decision to not even try to take question in the big room was a correct and I ended up talking and discussing details behind the scene for a good while after my talk was done. Really fun!
The video
The video is also available from the FOSDEM site in webm and mp4 formats.
The slides
If you want the slides only, run over to slideshare and view them.
In the afternoon of August 5 2019, I successfully made curl request a document over HTTP/3, retrieve it and then exit cleanly again.
(It got a 404 response code, two HTTP headers and 10 bytes of content so the actual response was certainly less thrilling to me than the fact that it actually delivered that response over HTTP version 3 over QUIC.)
The components necessary for this to work, if you want to play along at home, are reasonably up-to-date git clones of curl itself and the HTTP/3 library called quiche (and of course quiche’s dependencies too, like boringssl), then apply pull-request 4193 (build everything accordingly) and run a command line like:
curl --http3-direct https://quic.tech:8443
The host name used here (“quic.tech”) is a server run by friends at Cloudflare and it is there for testing and interop purposes and at the time of this test it ran QUIC draft-22 and HTTP/3.
The command line option --http3-direct tells curl to attempt HTTP/3 immediately, which includes using QUIC instead of TCP to the host name and port number – by default you should of course expect a HTTPS:// URL to use TCP + TLS.
The official way to bootstrap into HTTP/3 from HTTP/1 or HTTP/2 is via the server announcing it’s ability to speak HTTP/3 by returning an Alt-Svc: header saying so. curl supports this method as well, it just needs it to be explicitly enabled at build-time since that also is still an experimental feature.
To use alt-svc instead, you do it like this:
curl --alt-svc altcache https://quic.tech:8443
The alt-svc method won’t “take” on the first shot though since it needs to first connect over HTTP/2 (or HTTP/1) to get the alt-svc header and store that information in the “altcache” file, but if you then invoke it again and use the same alt-svc cache curl will know to use HTTP/3 then!
Early days
Be aware that I just made this tiny GET request work. The code is not cleaned up, there are gaps in functionality, we’re missing error checks, we don’t have tests and chances are the internals will change quite a lot going forward as we polish this.
You’re of course still more than welcome to join in, play with it, report bugs or submit pull requests! If you help out, we can make curl’s HTTP/3 support better and getting there sooner than otherwise.
QUIC and TLS backends
curl currently supports two different QUIC/HTTP3 backends, ngtcp2 and quiche. Only the latter currently works this good though. I hope we can get up to speed with the ngtcp2 one too soon.
quiche uses and requires boringssl to be used while ngtcp2 is TLS library independent and will allow us to support QUIC and HTTP/3 with more TLS libraries going forward. Unfortunately it also makes it more complicated to use…
The official OpenSSL doesn’t offer APIs for QUIC. QUIC uses TLS 1.3 but in a way it was never used before when done over TCP so basically all TLS libraries have had to add APIs and do some adjustments to work for QUIC. The ngtcp2 team offers a patched version of OpenSSL that offers such an API so that OpenSSL be used.
Draft what?
Neither the QUIC nor the HTTP/3 protocols are entirely done and ready yet. We’re using the protocols as they are defined in the 22nd version of the protocol documents. They will probably change a little more before they get carved in stone and become the final RFC that they are on their way to.
The libcurl API so far
The command line options mentioned above of course have their corresponding options for libcurl using apps as well.
The 2019 HTTP Workshop ended today. In total over the years, we have now done 12 workshop days up to now. This day was not a full day and we spent it on only two major topics that both triggered long discussions involving large parts of the room.
Cookies
Mike West kicked off the morning with his cookies are bad presentation.
One out of every thousand cookie header values is 10K or larger in size and even at the 50% percentile, the size is 480 bytes. They’re a disaster on so many levels. The additional features that have been added during the last decade are still mostly unused. Mike suggests that maybe the only way forward is to introduce a replacement that avoids the issues, and over longer remove cookies from the web: HTTP state tokens.
A lot of people in the room had opinions and thoughts on this. I don’t think people in general have a strong love for cookies and the way they currently work, but the how-to-replace-them question still triggered lots of concerns about issues from routing performance on the server side to the changed nature of the mechanisms that won’t encourage web developers to move over. Just adding a new mechanism without seeing the old one actually getting removed might not be a win.
We should possibly “worsen” the cookie experience over time to encourage switch over. To cap allowed sizes, limit use to only over HTTPS, reduce lifetimes etc, but even just that will take effort and require that the primary cookie consumers (browsers) have a strong will to hurt some amount of existing users/sites.
(Related: Mike is also one of the authors of the RFC6265bis draft in progress – a future refreshed cookie spec.)
HTTP/3
Mike Bishop did an excellent presentation of HTTP/3 for HTTP people that possibly haven’t kept up fully with the developments in the QUIC working group. From a plain HTTP view, HTTP/3 is very similar feature-wise to HTTP/2 but of course sent over a completely different transport layer. (The HTTP/3 draft.)
Most of the questions and discussions that followed were rather related to the transport, to QUIC. Its encryption, it being UDP, DOS prevention, it being “CPU hungry” etc. Deploying HTTP/3 might be a challenge for successful client side implementation, but that’s just nothing compared the totally new thing that will be necessary server-side. Web developers should largely not even have to care…
One tidbit that was mentioned is that in current Firefox telemetry, it shows about 0.84% of all requests negotiates TLS 1.3 early data (with about 12.9% using TLS 1.3)
Thought-worthy quote of the day comes from Willy: “everything is a buffer”
Future Workshops
There’s no next workshop planned but there might still very well be another one arranged in the future. The most suitable interval for this series isn’t really determined and there might be reasons to try tweaking the format to maybe change who will attend etc.
The fact that almost half the attendees this time were newcomers was certainly good for the community but that not a single attendee traveled here from Asia was less good.
Thanks
Thanks to the organizers, the program committee who set this up so nicely and the awesome sponsors!
This year’s version of curl up started a little differently: With an afternoon of HTTP presentations. The event took place the same week the IETF meeting has just ended here in Prague so we got the opportunity to invite people who possibly otherwise wouldn’t have been here… Of course this was only possible thanks to our awesome sponsors, visible in the image above!
Lukáš Linhart from Apiary started out with “Web APIs: The Past, The Present and The Future”. A journey trough XML-RPC, SOAP and more. One final conclusion might be that we’re not quite done yet…
James Fuller from MarkLogic talked about “The Defenestration of Hypermedia in HTTP”. How HTTP web technologies have changed over time while the HTTP paradigms have survived since a very long time.
I talked about DNS-over-HTTPS. A presentation similar to the one I did before at FOSDEM, but in a shorter time so I had to talk a little faster!
Mike Bishop from Akamai (editor of the HTTP/3 spec and a long time participant in the HTTPbis work) talked about “The evolution of HTTP (from HTTP/1 to HTTP/3)” from HTTP/0.9 to HTTP/3 and beyond.
Robin Marx then rounded off the series of presentations with his tongue in cheek “HTTP/3 (QUIC): too big to fail?!” where we provided a long list of challenges for QUIC and HTTP/3 to get deployed and become successful.
We ended this afternoon session with a casual Q&A session with all the presenters discussing various aspects of HTTP, the web, REST, APIs and the benefits and deployment challenges of QUIC.
I think most of us learned things this afternoon and we could leave the very elegant Charles University room enriched and with more food for thoughts about these technologies.
We ended the evening with snacks and drinks kindly provided by Apiary.
(This event was not streamed and not recorded on video, you had to be there in person to enjoy it.)
The RFC 7838 was published already in April 2016. It describes the new HTTP header Alt-Svc, or as the title of the document says HTTP Alternative Services.
HTTP Alternative Services
An alternative service in HTTP lingo is a quite simply another server instance that can provide the same service and act as the same origin as the original one. The alternative service can run on another port, on another host name, on another IP address, or over another HTTP version.
An HTTP server can inform a client about the existence of such alternatives by returning this Alt-Svc header. The header, which has an expiry time, tells the client that there’s an optional alternative to this service that is hosted on that host name, that port number using that protocol. If that client is a browser, it can connect to the alternative in the background and if that works out fine, continue to use that host for the rest of the time that alternative is said to work.
In reality, this header becomes a little similar to the DNS records SRV or URI: it points out a different route to the server than what the A/AAAA records for it say.
The Alt-Svc header came into life as an attempt to help out with HTTP/2 load balancing, since with the introduction of HTTP/2 clients would suddenly use much more persistent and long-living connections instead of the very short ones used for traditional HTTP/1 web browsing which changed the nature of how connections are done. This way, a system that is about to go down can hint the clients on how to continue using the service, elsewhere.
Alt-Svc: h2="backup.example.com:443"; ma=2592000;
HTTP upgrades
Once that header was published, the by then already existing and deployed Google QUIC protocol switched to using the Alt-Svc header to hint clients (read “Chrome users”) that “hey, this service is also available over gQUIC“. (Prior to that, they used their own custom alternative header that basically had the same meaning.)
This is important because QUIC is not TCP. Resources on the web that are pointed out using the traditional HTTPS:// URLs, still imply that you connect to them using TCP on port 443 and you negotiate TLS over that connection. Upgrading from HTTP/1 to HTTP/2 on the same connection was “easy” since they were both still TCP and TLS. All we needed then was to use the ALPN extension and voila: a nice and clean version negotiation.
To upgrade a client and server communication into a post-TCP protocol, the only official way to it is to first connect using the lowest common denominator that the HTTPS URL implies: TLS over TCP, and only once the server tells the client what more there is to try, the client can go on and try out the new toys.
I want curl to support HTTP/3 as soon as possible and then as I’ve mentioned above, understanding Alt-Svc is a key prerequisite to have a working “bootstrap”. curl needs to support Alt-Svc. When we’re implementing support for it, we can just as well support the whole concept and other protocol versions and not just limit it to HTTP/3 purposes.
curl will only consider received Alt-Svc headers when talking HTTPS since only then can it know that it actually speaks with the right host that has the authority enough to point to other places.
Experimental
This is the first feature and code that we merge into curl under a new concept we do for “experimental” code. It is a way for us to mark this code as: we’re not quite sure exactly how everything should work so we allow users in to test and help us smooth out the quirks but as a consequence of this we might actually change how it works, both behavior and API wise, before we make the support official.
We strongly discourage anyone from shipping code marked experimental in production. You need to explicitly enable this in the build to get the feature. (./configure –enable-alt-svc)
But at the same time we urge and encourage interested users to test it out, try how it works and bring back your feedback, criticism, praise, bug reports and help us make it work the way we’d like it to work so that we can make it land as a “normal” feature as soon as possible.
Ship
The experimental alt-svc code has been merged into curl as of commit 98441f3586 (merged March 3rd 2019) and will be present in the curl code starting in the public release 7.64.1 that is planned to ship on March 27, 2019. I don’t have any time schedule for when to remove the experimental tag but ideally it should happen within just a few release cycles.
alt-svc cache
The curl implementation of alt-svc has an in-memory cache of known alternatives. It can also both save that cache to a text file and load that file back into memory. Saving the alt-svc cache to disk allows it to survive curl invokes and to truly work the way it was intended. The cache file stores the expire timestamp per entry so it doesn’t matter if you try to use a stale file.
curl –alt-svc
Caveat: I now talk about how a feature works that I’ve just above said might change before it ships. With the curl tool you ask for alt-svc support by pointing out the alt-svc cache file to use. Or pass a “” (empty name) to make it not load or save any file. It makes curl load an existing cache from that file and at the end, also save the cache to that file.
curl also already since a long time features fancy connection options such as –resolve and –connect-to, which both let a user control where curl connects to, which in many cases work a little like a static poor man’s alt-svc. Learn more about those in my curl another host post.
libcurl options for alt-svc
We start out the alt-svc support for libcurl with two separate options. One sets the file name to the alt-svc cache on disk (CURLOPT_ALTSVC), and the other control various aspects of how libcurl should behave in regards to alt-svc specifics (CURLOPT_ALTSVC_CTRL).
I’m quite sure that we will have reason to slightly adjust these when the HTTP/3 support comes closer to actually merging.
Yesterday, I had attracted audience enough to fill up the largest presentation room GOTO 10 has, which means about one hundred interested souls.
The subject of the day was HTTP/3. The event was filmed with a mevo camera and I captured the presentation directly from my laptop as well, and I then stitched together the two sources into this final version late last night. As you’ll notice, the sound isn’t awesome and the rest of the “production” isn’t exactly top notch either, but hey, I don’t think it matters too much.
I’ll talk about HTTP/3 (Photo by Jon Åslund)I’m Daniel Stenberg. I was handed a medal from the Swedish king in 2017 for my work on… (Photo by OpenTokix)HTTP/2 vs HTTP/3 (Photo by OpenTokix)Some of the challenges to deploy HTTP/3 are…. (Photo by Jonathan Sulo)