I believe a good product needs clear and thorough documentation. I think shipping a quality product requires you to provide detailed and informative release notes. I try to live up to this in the curl project, and this is how we do it.
A video presentation about how Daniel updates and maintains the curl RELEASE NOTES.
Scripts are your friends
Some of the scripts I use to maintain the RELEASE NOTES and the associated documentation.
maketgz
A foundational script to make things work smoothly is the single invoke script that puts a release tarball together from what is currently in the file system. We can run this in a cronjob and easily generate daily snapshots that look exactly like a release would look like if we had done one at that point. Our script for this purpose is called maketgz. We have a containerized version of that, which runs in a specific docker setup and we called that dmaketgz. This version of the script builds a fully reproducible release tarball.
If you want to verify that all the contents of a release tarball only originate from the git repository and the associated release tools, we provide a script for that purpose: verify-release.
release-notes.pl
An important documentation for each release is of course the RELEASE-NOTES file that details exactly what changes and fixes that have been done since the previous release. It also gives proper credit to all the people that were involved and helped making the release this particular way.
We use a quite simple git commit message standard for curl. It details how the first line should be constructed and how to specify meta-data in the message. Sticking to this message format allows us to write scripts and do automation around the git history.
When I invoke the release-notes.pl script, it performs a git log command that lists all changes done in the repository since the previous commit of the RELEASE-NOTES files with the commit message “synced”. Those changes are then parsed: the first line is used as a release notes entry and issue tracker references within the message are used for linking the changes to allow users to track their origins.
The script cannot itself actually know if a commit is a change, a bugfix or something else, so after it has been invoked I have to go over the updated release notes file manually. I check the newly added entries and I remove the ones that are irrelevant and I move the lines referring to changes to the changes list.
I then run release-notes.pl cleanup, which cleans up the release notes file – it sorts the bugfixes list alphabetically and removes pending orphaned references no longer used (for previously listed entries that were deleted in the process mentioned above).
contributors.sh
When invoked, this script extracts all contributors to the project since the most recent release (tag). Commit authors, committers and everyone given credit in all commit messages done since. Also all committers and authors in the web repository over the same period. It also takes the existing names mentioned in the existing RELEASE NOTES file.
It cleans up the names, runs them through the THANKS-filter and then outputs each unique name in a convenient way and format suitable for easy copy and paste into RELEASE-NOTES.
delta
The delta script outputs data and counters about the current state of the repository compared to the most recent release.
Invoking the script in a terminal shows something like this:
= Since curl-8_12_1 Feb 13 08:18:33 2025 +0100 = Elapsed time: 10.4 days (total 9837 / 10331) Commits: 122 (total 34405) Commit authors: 14, 1 new (total 1343) Contributors: 19, 8 new (total 3351) New public functions: 0 (total 96) New curl_easy_setopt() options: 0 (total 306) New command line options: 0 (total 267) Changes logged: 0 Bugfixes logged: 67 (6.44 per day) Added files: 10 (total 4058) Deleted files: 2 (delta: 8) Files changed: 328 (8.08%) Lines inserted: 7798 Lines deleted: 6318 (delta: 1480)
With this output, I can update the counters at the top of the RELEASE NOTES file.
I then commit the RELEASE-NOTES files with the commit message “RELEASE-NOTES: synced” so that the automation knows exactly when it was last updated.
As a courtesy to curious users and developers, we always keep an updated version of the current in progress release notes document on the curl website: https://curl.se/dev/release-notes.html.
Repetition
In my ~/.gitconfig file I have a useful alias that helps me:
[alias] latest = log @^{/RELEASE-NOTES:.synced}..
This lets me easily list all changes done in the repository since I last updated the release notes file. I often list them like this:
git latest --oneline
As this then lists all the commits as one line per commit. If the list is large enough, maybe 20-30 lines or something and there has been at least a few days since the previous update, I might update the release notes.
Whenever there is a curl release, I also make sure the release notes notes document is fully updated and properly synced for that.
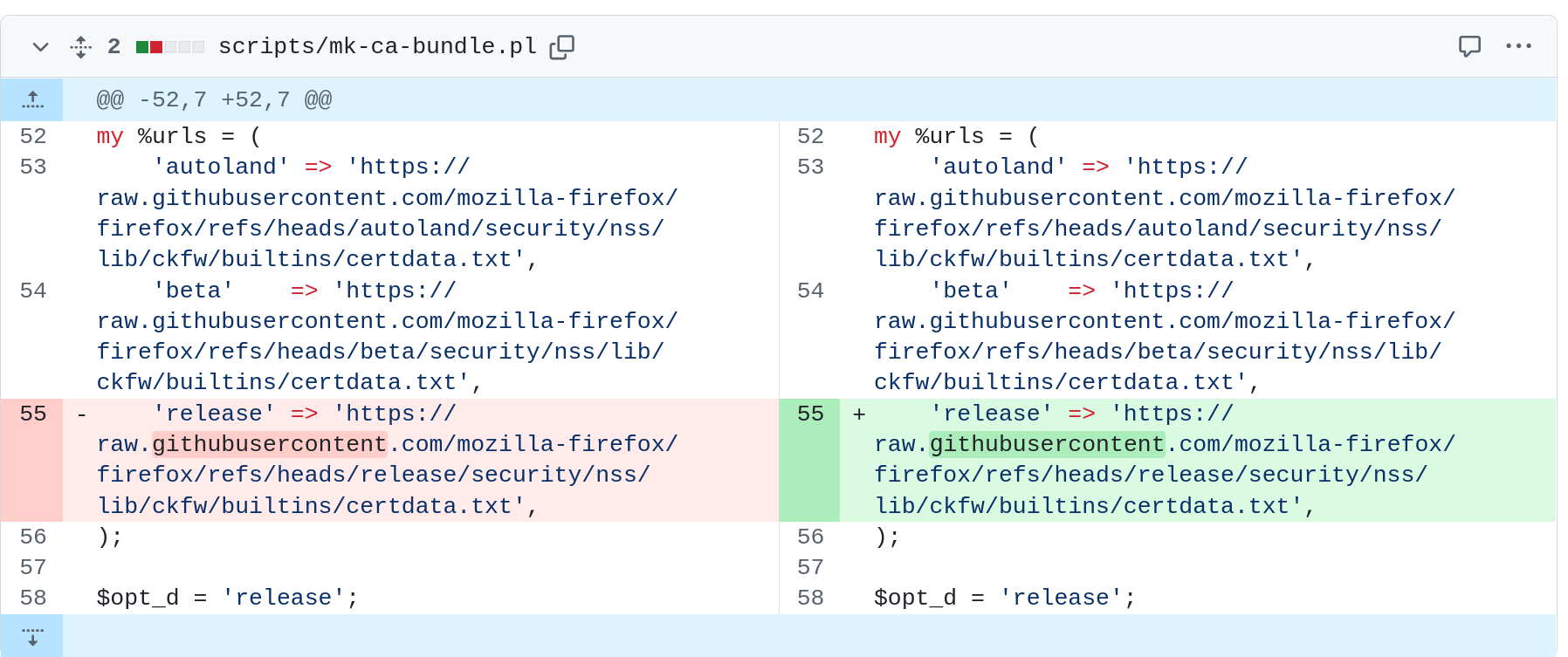
In a recent educational trick, curl contributor James Fuller submitted a pull-request to the project in which he suggested a larger cleanup of a set of scripts.
In a later presentation, he could show us how not a single human reviewer in the team nor any CI job had spotted or remarked on one of the changes he included: he replaced an ASCII letter with a Unicode alternative in a URL.
This was an eye-opener to several of us and we decided we needed to up our game. We are the curl project. We can do better.
GitHub
The replacement symbol looked identical to the ASCII version so it was not possible to visually spot this, but the diff viewer knows there is a difference.
In this GitHub website screenshot below I reproduced a similar case. The right-side version has the Latin letter ‘g’ replaced with the Armenian letter co. They appear to be the same.
GitHub shows a diff. But what is actually the difference?
The diff viewer says there is a difference but as a human it isn’t possible to detect what it is. Is it a flaw? Does it matter? If done “correctly”, it would be done together with a real and expected fix.
The impact of changing one or more letters in a URL can of course be devastating depending on conditions.
When I flagged about this rather big omission to GitHub people, I got barely no responses at all and I get the feeling the impact of this flaw is not understood and acknowledged. Or perhaps they are all just too busy implementing the next AI feature we don’t want.
Warnings
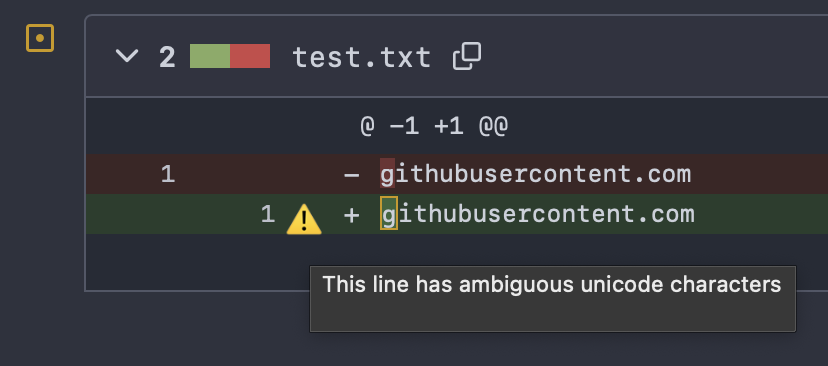
When we discussed this problem on Mastodon earlier this week, Viktor Szakats provided me with an example screenshot of doing a similar stunt with Gitea which quite helpfully highlights that there is something special about the replacement:
Gitea warns that the replacement is using “ambiguous Unicode characters”
I have been told that some of the other source code hosting services also show similar warnings.
As a user, I would actually like to know even more than this, but at least this warns about the proposed change clearly enough so that if this happens I would get the code manually and investigate before accepting such a change.
Detect
While we wait for GitHub to wake up and react (which I have no expectation will actually happen anytime soon), we have implemented checks to help us poor humans spot things like this. To detect malicious Unicode.
We have added a CI job that scans all files and validates every UTF-8 sequence in the git repository.
In the curl git repository most files and most content are plain old ASCII so we can “easily” whitelist a small set of UTF-8 sequences and some specific files, the rest of the files are simply not allowed to use UTF-8 at all as they will then fail the CI job and turn up red.
In order to drive this change home, we went through all the test files in the curl repository and made sure that all the UTF-8 occurrences were instead replaced by other kind of escape sequences and similar. Some of them were also used more or less by mistake and could easily be replaced by their ASCII counterparts.
The next time someone tries this stunt on us it could be someone with less good intentions, but now ideally our CI will tell us.
Confusables
There are plenty of tools to find similar-looking characters in different Unicode sets. One of them is provided by the Unicode consortium themselves:
This was yet another security-related fix reacting on a demonstrated problem. I am sure there are plenty more problems which we have not yet thought about nor been shown and therefore we do not have adequate means to detect and act on automatically.
We want and strive to be proactive and tighten everything before malicious people exploit some weakness somewhere but security remains this never-ending race where we can only do the best we can and while the other side is working in silence and might at some future point attack us in new creative ways we had not anticipated.
That future unknown attack is a tricky thing.
Update
(At 17:30 on the same day of the original post) GitHub has told me they have raised this as a security issue internally and they are working on a fix.
For quite some time now, I celebrate and welcome every new commit author in the curl project in the public. Recently, that means I send out a toot on Mastodon saying Welcome so and so as curl commit author number XYZ and a link to their initial curl work. (example 1, example 2).
This messaging is not done automatically. GitHub helps out by specifically mentioning in a PR when it is done by a first-timer to the repository, and I have a convenient local script that tells me how many authors we have so far, and then I type up the message myself and send it. (Sometimes I miss one, which I regret.)
This process takes me about seven point five seconds per case of manual labor. Writing an automated script to do this correctly, triggered for the right persons, would take the equivalent of many years of new authors.
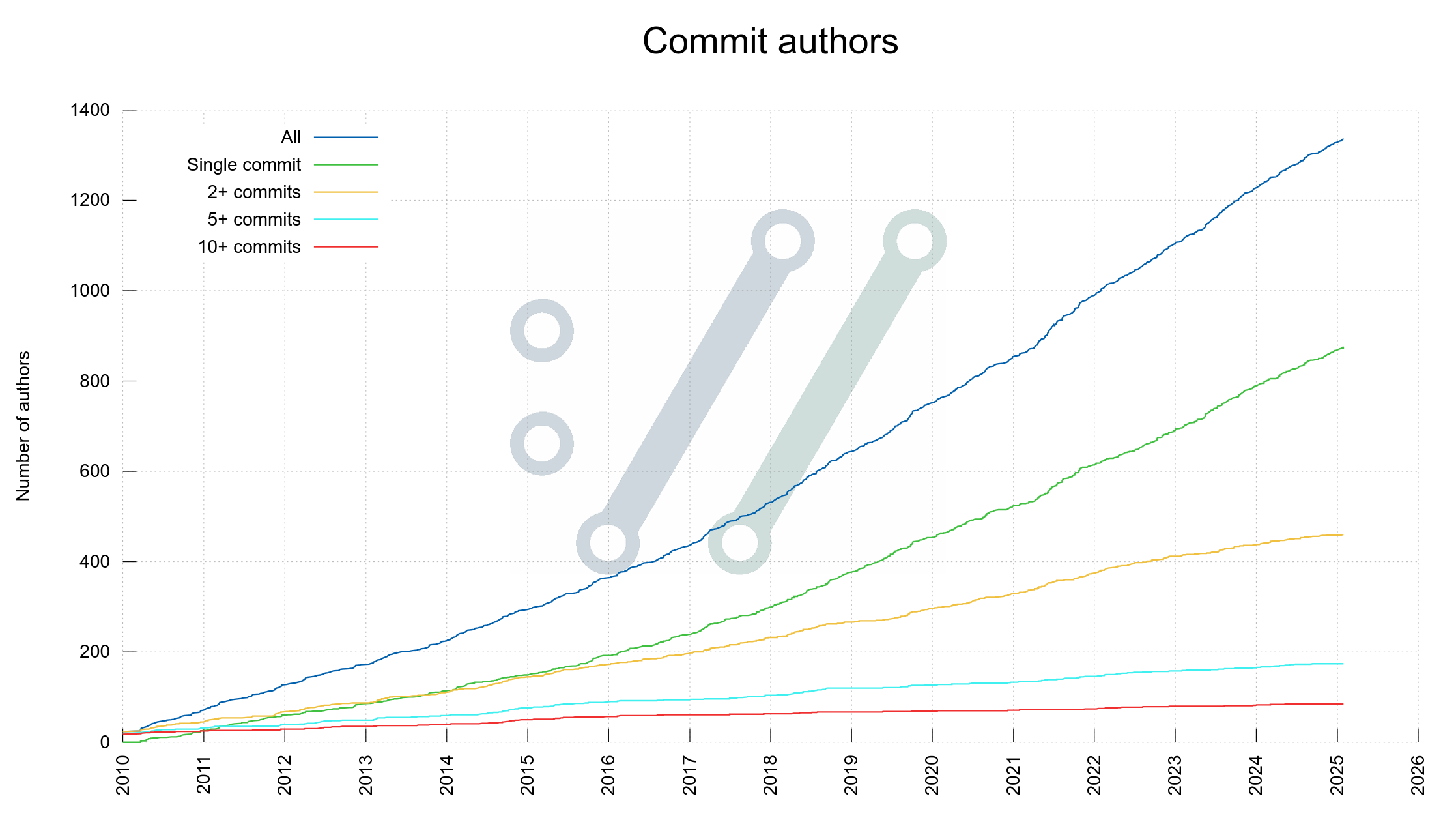
For the last few months, people have more and more noticed and replied mentions about the fact that we were approaching commit author number 1337. Lots of people have said things in the style of “I should learn to program soon so that I can become number 1337”.
The number 1337, is of course just a number. I find it amusing and charming that it seems to have this almost magic aura and attraction to so many people in our community.
Today, commit author 1337 was finally announced, only three years since we announced author 1000. There are no permanent records or anything of this fact other than this blog post. Further, there is a risk that we have a duplicate or two somewhere in there so that a recount at a later time will end up differently.
Commit author 1337 became Michael Schuster who wrote this pull request, which fixed a minor build issue in the mbedTLS backend code. Thanks!
337 new authors over the last three years equals roughly two new commit authors per week on average. Pretty good. We have room for many more!
A relevant statistic in this context is also that 65% of all commit authors only ever authored a single commit.
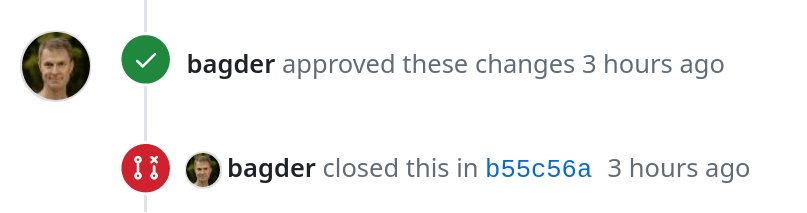
Screenshot from a recent pull request merged in the curl project on GitHub
Contributors to the curl project on GitHub tend to notice the above sequence quite quickly: pull requests submitted do not generally appear as “merged” with its accompanying purple blob, instead they are said to be “closed”. This has been happening since 2015 and is probably not going to change anytime soon.
Screenshot showing how GitHub otherwise shows merges
If you make a pull request based on a single commit, the initial PR message is based on the commit message but when follow-up fixes are done and perhaps force-pushed, the PR message is not updated accordingly with the commit message’s updates.
Commit messages with style
I believe having good commit messages following a fixed style and syntax helps the project. It makes the git history better and easier to browse. It allows us to write tools and scripts around git and the git history. Like how we for example generate release notes and project stat graphs based on git log basically.
We also like and use a strictly linear history in curl, meaning that all commits are rebased on the master branch. Lots of the scripting mentioned above depends on this fact.
Manual merges
In order to make sure the commit message is correct, and in fact that the entire commit looks correct, we merge pull requests manually. That means that we pull down the pull request into a local git repository, clean up the commit message to adhere to project standards.
And then we push the commit to git. One or more of the commit messages in such a push then typically contains lines like:
Fixes #[number] and Closes #[number]. Those are instructions to GitHub and we use them like this:
Fixes means that this commit fixed an issue that was reported in the GitHub issue with that id. When we push a commit with that instruction, GitHub closes that issue.
Closes means that we merged a pull request with this id. (GitHub has no way for us to tell it that we merged the pull request.) This instruction makes GitHub closes the corresponding pull request: “[committer] closed this in [commit hash]”.
We do not let GitHub dictate how we do git. We use git and expect GitHub to reflect our git activity.
We COULD but we won’t
We could in theory fix and cleanup the commits locally and manually exactly the way we do now and then force-push them to the remote branch and then use the merge button on the GitHub site and then they would appear as “merged”.
That is however a clunky, annoying and time-consuming extra-step that not only requires that we (always) push code to other people’s branches, it also triggers a whole new round of CI jobs. This, only to get a purple blob instead of a red one. Not worth it.
If GitHub would allow it, I would disable the merge button in the GitHub PR UI for curl since it basically cannot be used correctly in the project.
Squashing all the commits in the PR is also not something we want since in many cases the changes should be kept as more than one commit and they need their own dedicated and correct commit message.
What GitHub could do
GitHub could offer a Merged keyword in the exact same style as Fixed and Closes, that just tells the service that we took care of this PR and merged it as this commit. It’s on me. My responsibility. I merged it. It would help users and contributors to better understand that their closed PR was in fact merged as that commit.
It would also have saved me from having to write this blog post.
In some post-publish discussions I have seen people ask about credits. This method to merge commits does not break or change how the authors are credited for their work. The commit authors remain the commit authors, and the one doing the commits (which is I when I do them) is stored separately. Like git always do. Doing the pushes manually this way does in no way change this model. GitHub will even count the commits correctly for the committer – assuming they use an email address their GitHub account does (I think).
Today, another 1,000 commits have been recorded as done by me in the curl source code git repository since November 2021. Out of a total of 29,608 commits to the curl source code repository, I have made 17,001. 57.42%.
In 2022, I have done 56% of all the commits in the curl source repository. I am also the only developer who works full time on curl all the time.
In 2022, 179 individuals authored commits that were merged into curl. 115 of them did that for the first time this year. Over curl’s life time, a total of 1104 persons have authored code merged into curl.
Do I ever get bored? Not yet. I will let you know if I do.
The preferred method of providing changes to the curl project, be it source code, documentation or web site contents, is by submitting a pull-request. A “PR”. On the curl repository on GitHub.
When a proposed curl change, bugfix or improvement is submitted as a PR on GitHub, it gets built, checked, tested and verified in countless ways and a few hundred developers get a notification about it.
The first thing I do every morning and the last thing I do every night before I go to bed, is eyeing through the list of open PRs, and especially the ones with recent activities. I of course also get back to them during the day if there is activity that might need my attention – not to mention that I also personally submit by own PRs to curl at an average rate of a few per day.
You can rightly say that my day and my work with curl is extremely PR centered. And by extension, also extremely git and GitHub focused.
Merging the work
When all the CI checks run green and all review comments and concerns have been addressed, the PR has become ripe for merge.
As a general rule, we always work in the master branch as the current development branch that is destined to become the next release when the time comes. An approved PR thus gets merged into the master branch and pushed there. We keep the git history linear and clean, meaning we do merge + rebase before pushing.
Commit messages
One of the key properties of a git commit, is the commit message. The text that describes the particular change in the repository.
In the curl project we have a standard style or template for how to write these messages. This makes them consistent and helps making them useful and get populated with informational meta-data that future versions of ourselves might appreciate when we look back at the changes decades into the future.
The PR review UI on GitHub unfortunately totally ignores commit messages, which means that we cannot comment on them or insist or check that users write them in our preferred style. Arguably, it is also just quicker and easier not to do that and instead just gently brush up the message in the commit locally before the commit is pushed.
Adding correct fixes #xxx and closes #xxx information to the message also helps making sure GitHub closes the associated issues/pull-requests and allows us to map git repository commits with GitHub activities at will – like when running statistic scripts etc.
This strictness and way of working makes it impossible to use the “merge” button in the GitHub UI since we simply cannot ensure that the commit is good enough with it. The button is however not possible to remove from the UI with any settings. We just prohibit its use.
They appear as “closed this in”
This way of working makes most PRs appear as “closed this in #[commit hash]” in the GitHub UI instead of saying “merged by” that same hash. Because in GitHub’s view, the PR was not merged.
GitHub could fix this with a merges keyword, which has been suggested since forever, but clearly they do not see this as a problem.
Occasional users of course get surprised or even puzzled by us closing the PR “instead of merging”, because that is what it looks like. When it really is not.
Ultimately, I consider the state and contents of our git repository and history more important than how the PRs appear on GitHub so I stick to our way of working.
Signed commits
As a little side-note, I of course also always GPG sign my commits so you can verify on GitHub and with git that my commits are genuinely done by me.
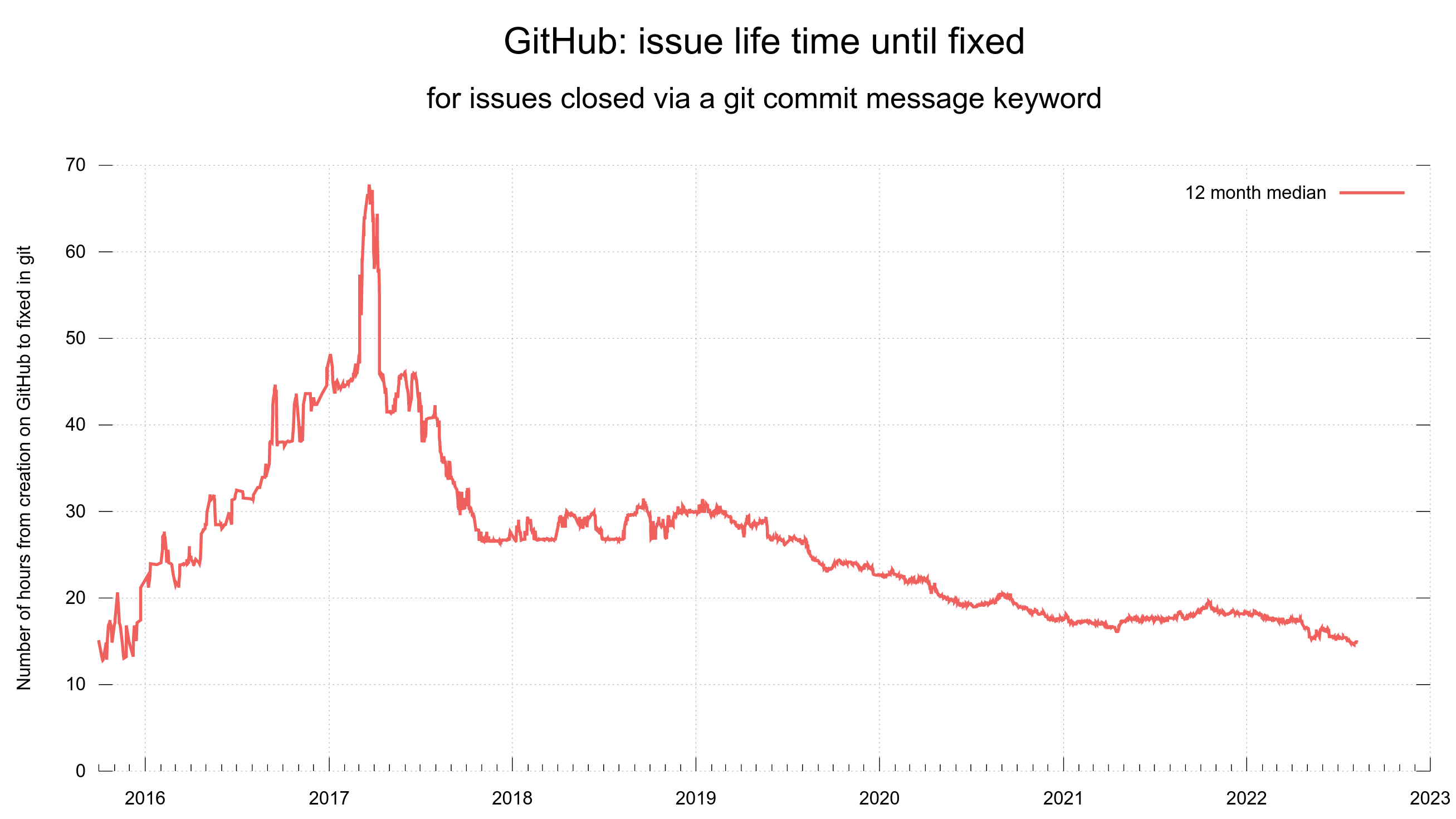
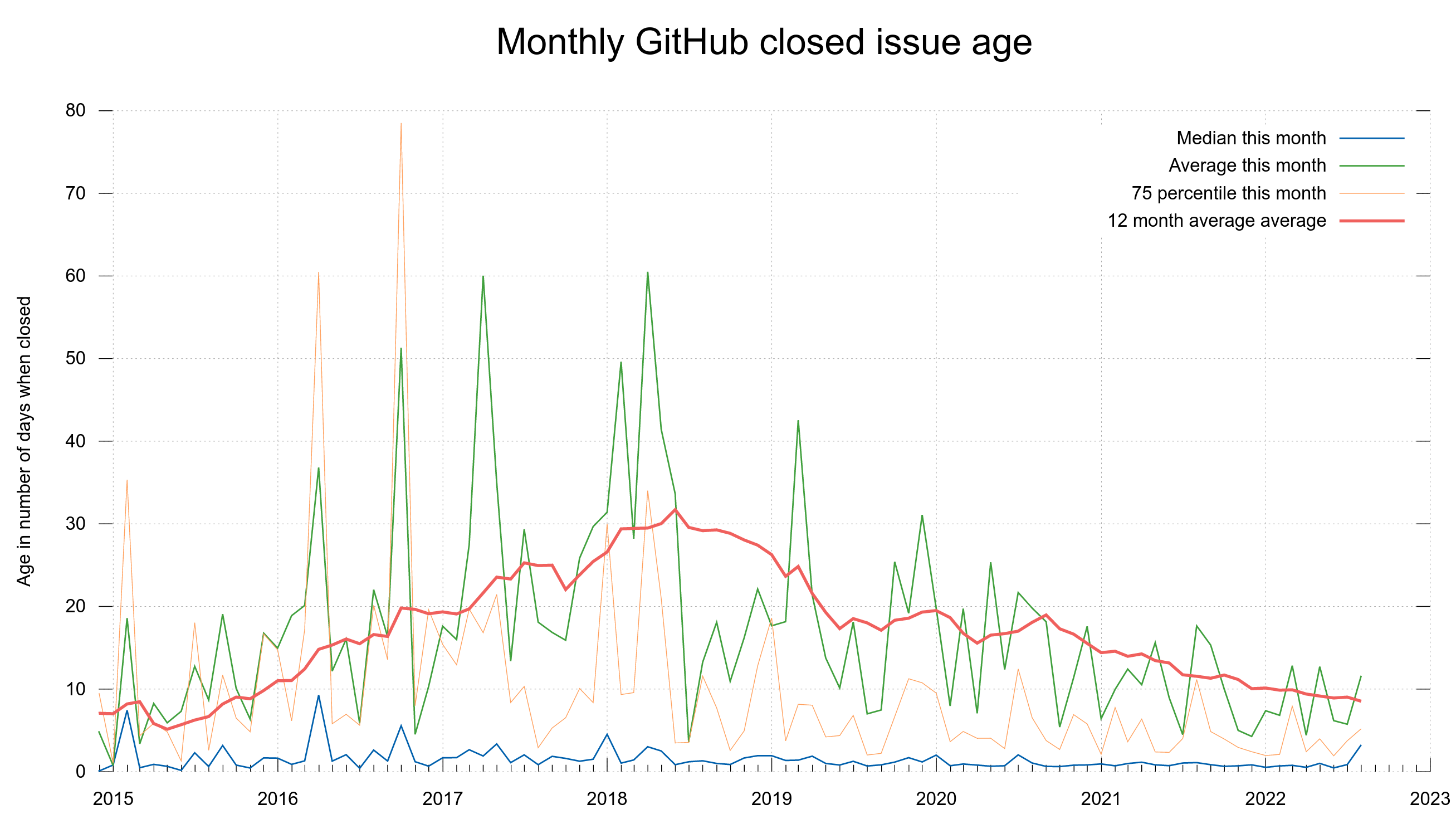
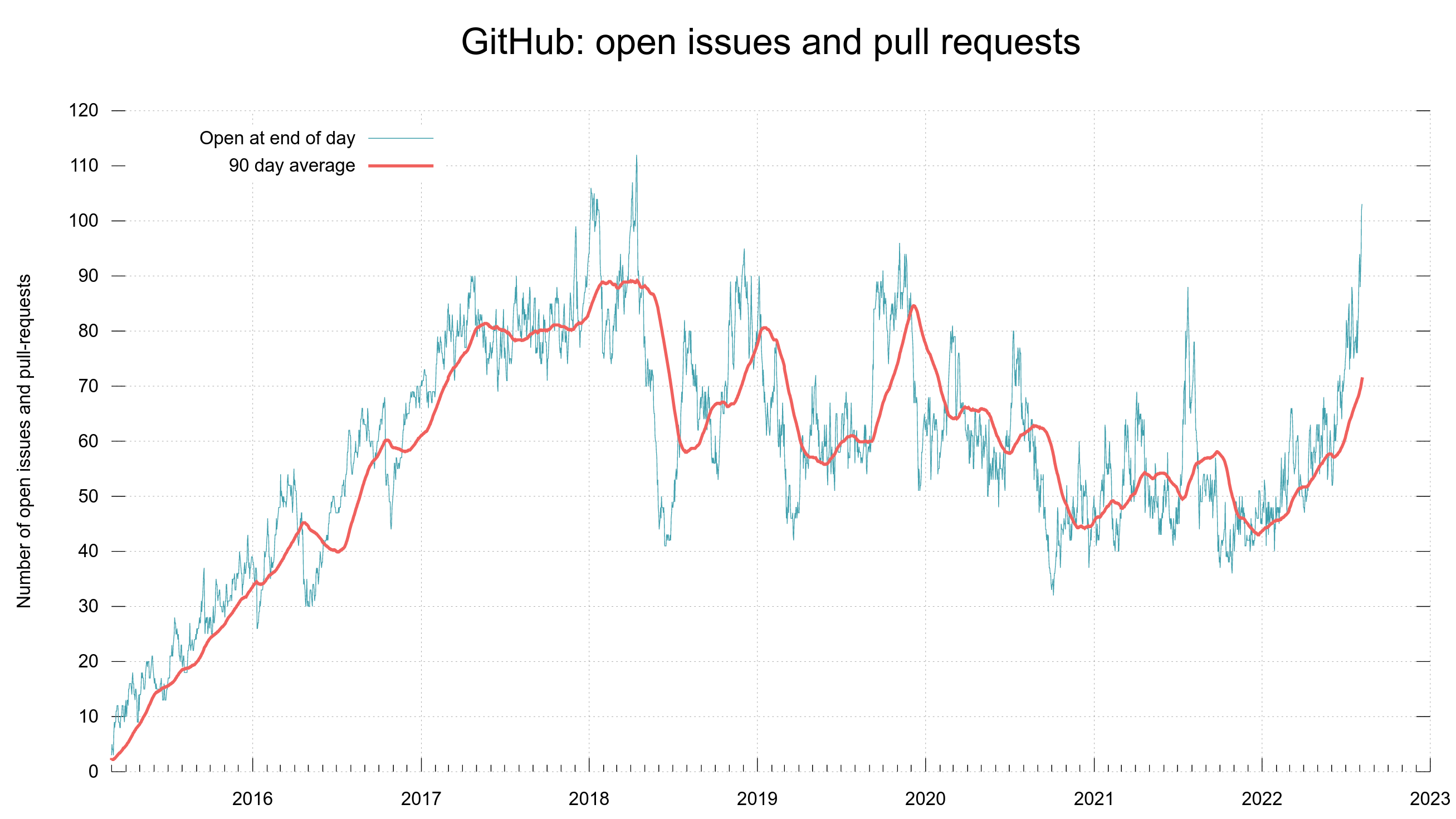
Stats
To give you an idea of the issue and pull request frequency and management in curl (the source code repository). Snapshots from the curl dashboard from August 8, 2022.
Update
Several people have mentioned to me after I posted this article that I could squash and edit the commits and force-push the work back to the user’s branch used for the PR before using the “merge” button or auto-merge feature of GitHub.
Sure, I could do it that way, but I think that is an even worse solution and a poor work-around. It is very intrusive method that would make me force-push in every user’s PR branch and I am certain a certain amount of users will be surprised by that and some even downright upset because it removes/overwrites their work. For the sake of working around a GitHub quirk. Nope, I will not do that.
Saturday June 18: I had some curl time in the afternoon and I was just about to go edit the four security advisories I had pending for the next release, to brush up the language and check that they read fine, when it dawned on me.
These particular security advisories were still in draft versions but maybe 90% done. There were details, like dates and links to current in-progress patches, left to update. I also like to reread them a few times, especially in a webpage rendered format, to make sure they are clear and accurate in describing the problem, the solution and all other details, before I consider them ready for publication.
I checked out my local git branch where I expected the advisories to reside. I always work on pending security details in a local branch named security-next-release or something like that. The branch and its commits remain private and undisclosed until everything is ready for publication.
(I primarily use git command lines in terminal windows.)
The latest commits in my git log output did not show the advisories so I did a rebase but git promptly told me there was nothing to rebase! Hm, did I use another branch this time?
It took me a few seconds to realize my mistake. I saw four commits in the git master branch containing my draft advisories and then it hit me: I had accidentally pushed them to origin master and they were publicly accessible!
The secrets I was meant to guard until the release, I had already mostly revealed to the world – for everyone who was looking.
How
In retrospect I can’t remember exactly how the mistake was done, but I clearly committed the CVE documents in the wrong branch when I last worked on them, a little over a week ago. The commit date say June 9.
On June 14, I got a bug report about a problem with curl’s .well-known/security.txt file (RFC 9116) where it was mentioned that our file didn’t have an Expires: keyword in spite of it being required in the spec. So I fixed that oversight and pushed the update to the website.
When doing that push, I did not properly verify exactly what other changes that would be pushed in the same operation, so when I pressed enter there, my security advisories that had accidentally been committed in the wrong branch five days earlier and still were present there were also pushed to the remote origin. Swooosh.
Impact
The advisories are created in markdown format, and anyone who would update their curl-www repository after June 14 would then get them into their local repository. Admittedly, there probably are not terribly many people who do that regularly. Anyone could also browse them through the web interface on github. Also probably not something a lot of people do.
These pending advisories would however not appear on the curl website since the build files were not updated to generate the HTML versions. If you could guess the right URL, you could still get the markdown version to show on the site.
Nobody reported this mistake in the four days they were visible before I realized my own mistake (and nobody has reported it since either). I then tried googling the CVE numbers but no search seemed to find and link to the commits. The CVE numbers were registered already so you would mostly get MITRE and other vulnerability database listings that were still entirely without details.
Decision
After some quick deliberations with my curl security team friends, we decided expediting the release was the most sensible thing to do. To reduce the risk that someone takes advantage of this and if they do, we limit the time window before the problems and their fixes become known. For curl users security’s sake.
Previously, the planned release date was set to July 1st – thirteen days away. It had already been adjusted somewhat to not occur on its originally intended release Wednesday to cater for my personal summer plans.
To do a proper release with several security advisories I want at least a few days margin for the distros mailing list to prepare before we go public with everything. There was also the Swedish national midsummer holiday coming up next weekend and I did not feel like ruining my family’s plans and setup for that, so I picked the first weekday after midsummer: June 27th.
While that is just four days earlier than what we had previously planned, I figure those four days might be important and if we imagine that someone finds a way to exploit one of these problems before then, then at least we shorten the attack time window by four days.
When working with my security advisories, I must pay more attention and be more careful with which branch I commit to.
When pushing commits to the website and I know I have pending security sensitive details locally that have not been revealed yet, I should make it a habit to double-check that what I am about to push is only and nothing but what I expect to be there.
Simultaneously, I have worked using this process for many years now and this is the first time I did this mistake. I do not think we need to be alarmist about it.
The official gitstats page shows that I’ve committed changes on almost 4,600 separate days since the year 2000.
16,000 commits is 13,413 commits more than the person with the second-most number of commits: Yang Tse (2587 commits). He has however not committed anything in curl since he vanished from the project in 2013.
I have also done 4,700 commits in the curl-www repository, but that’s another story.
The curl project’s source code has been hosted on GitHub since March 2010. I wrote a blog post in 2013 about what I missed from the service back then and while it has improved significantly since then, there are still features I miss and flaws I think can be fixed.
For this reason, I’ve created and now maintain a dedicated git repository with feedback “items” that I think could enhance GitHub when used by a project like curl:
The purpose of this repository is to allow each entry to be on-point and good feedback to GitHub. I do not expect GitHub to implement any of them, but the better we can present the case for every issue, the more likely I think it is that we can gain supporters for them.
What makes curl “special”
I don’t think curl is a unique project in the way we run and host it. But there are a few characteristics that maybe make it stand out a little from many other projects hosted on GitHub:
curl is written in C. It means it cannot be part of the “dependency” and related security checks etc that GitHub provides
we are git users but we are not GitHub exclusive: we allow participation in and contributions to the project without a GitHub presence
we are an old-style project where discussions, planning and arguments about project details are held on mailing lists (outside of GitHub)
we have strict ideas about how git commits should be done and how the messages should look like etc, so we cannot accept merges done with the buttons on the GitHub site
You can help
Feel free to help me polish the proposals, or even submit new ones, but I think they need to be focused and I will only accept issues there that I agree with.
Every now and then I get questions on how to work with git in a smooth way when developing, bug-fixing or extending curl – or how I do it. After all, I work on open source full time which means I have very frequent interactions with git (and GitHub). Simply put, I work with git all day long. Ordinary days, I issue git commands several hundred times.
I have a very simple approach and way of working with git in curl. This is how it works.
command line
I use git almost exclusively from the command line in a terminal. To help me see which branch I’m working in, I have this little bash helper script.
brname () {
a=$(git rev-parse --abbrev-ref HEAD 2>/dev/null)
if [ -n "$a" ]; then
echo " [$a]"
else
echo ""
fi
}
PS1="\u@\h:\w\$(brname)$ "
That gives me a prompt that shows username, host name, the current working directory and the current checked out git branch.
In addition: I use Debian’s bash command line completion for git which is also really handy. It allows me to use tab to complete things like git commands and branch names.
git config
I of course also have my customized ~/.gitconfig file to provide me with some convenient aliases and settings. My most commonly used git aliases are:
st = status --short -uno
ci = commit
ca = commit --amend
caa = commit -a --amend
br = branch
co = checkout
df = diff
lg = log -p --pretty=fuller --abbrev-commit
lgg = log --pretty=fuller --abbrev-commit --stat
up = pull --rebase
latest = log @^{/RELEASE-NOTES:.synced}..
The ‘latest’ one is for listing all changes done to curl since the most recent RELEASE-NOTES “sync”. The others should hopefully be rather self-explanatory.
The config also sets gpgsign = true, enables mailmap and a few other things.
master is clean and working
The main curl development is done in the single curl/curl git repository (primarily hosted on GitHub). We keep the master branch the bleeding edge development tree and we work hard to always keep that working and functional. We do our releases off the master branch when that day comes (every eight weeks) and we provide “daily snapshots” from that branch, put together – yeah – daily.
When merging fixes and features into master, we avoid merge commits and use rebases and fast-forward as much as possible. This makes the branch very easy to browse, understand and work with – as it is 100% linear.
Work on a fix or feature
When I start something new, like work on a bug or trying out someone’s patch or similar, I first create a local branch off master and work in that. That is, I don’t work directly in the master branch. Branches are easy and quick to do and there’s no reason to shy away from having loads of them!
I typically name the branch prefixed with my GitHub user name, so that when I push them to the server it is noticeable who is the creator (and I can use the same branch name locally as I do remotely).
$ git checkout -b bagder/my-new-stuff-or-bugfix
Once I’ve reached somewhere, I commit to the branch. It can then end up one or more commits before I consider myself “done for now” with what I was set out to do.
I try not to leave the tree with any uncommitted changes – like if I take off for the day or even just leave for food or an extended break. This puts the repository in a state that allows me to easily switch over to another branch when I get back – should I feel the need to. Plus, it’s better to commit and explain the change before the break rather than having to recall the details again when coming back.
Never stash
“git stash” is therefore not a command I ever use. I rather create a new branch and commit the (temporary?) work in there as a potential new line of work.
Show it off and get reviews
Yes I am the lead developer of the project but I still maintain the same work flow as everyone else. All changes, except the most minuscule ones, are done as pull requests on GitHub.
When I’m happy with the functionality in my local branch. When the bug seems to be fixed or the feature seems to be doing what it’s supposed to do and the test suite runs fine locally.
I then clean up the commit series with “git rebase -i” (or if it is a single commit I can instead use just “git commit --amend“).
The commit series should be a set of logical changes that are related to this change and not any more than necessary, but kept separate if they are separate. Each commit also gets its own proper commit message. Unrelated changes should be split out into its own separate branch and subsequent separate pull request.
git push origin bagder/my-new-stuff-or-bugfix
Make the push a pull request
On GitHub, I then make the newly pushed branch into a pull request (aka “a PR”). It will then become visible in the list of pull requests on the site for the curl source repository, it will be announced in the #curl IRC channel and everyone who follows the repository on GitHub will be notified accordingly.
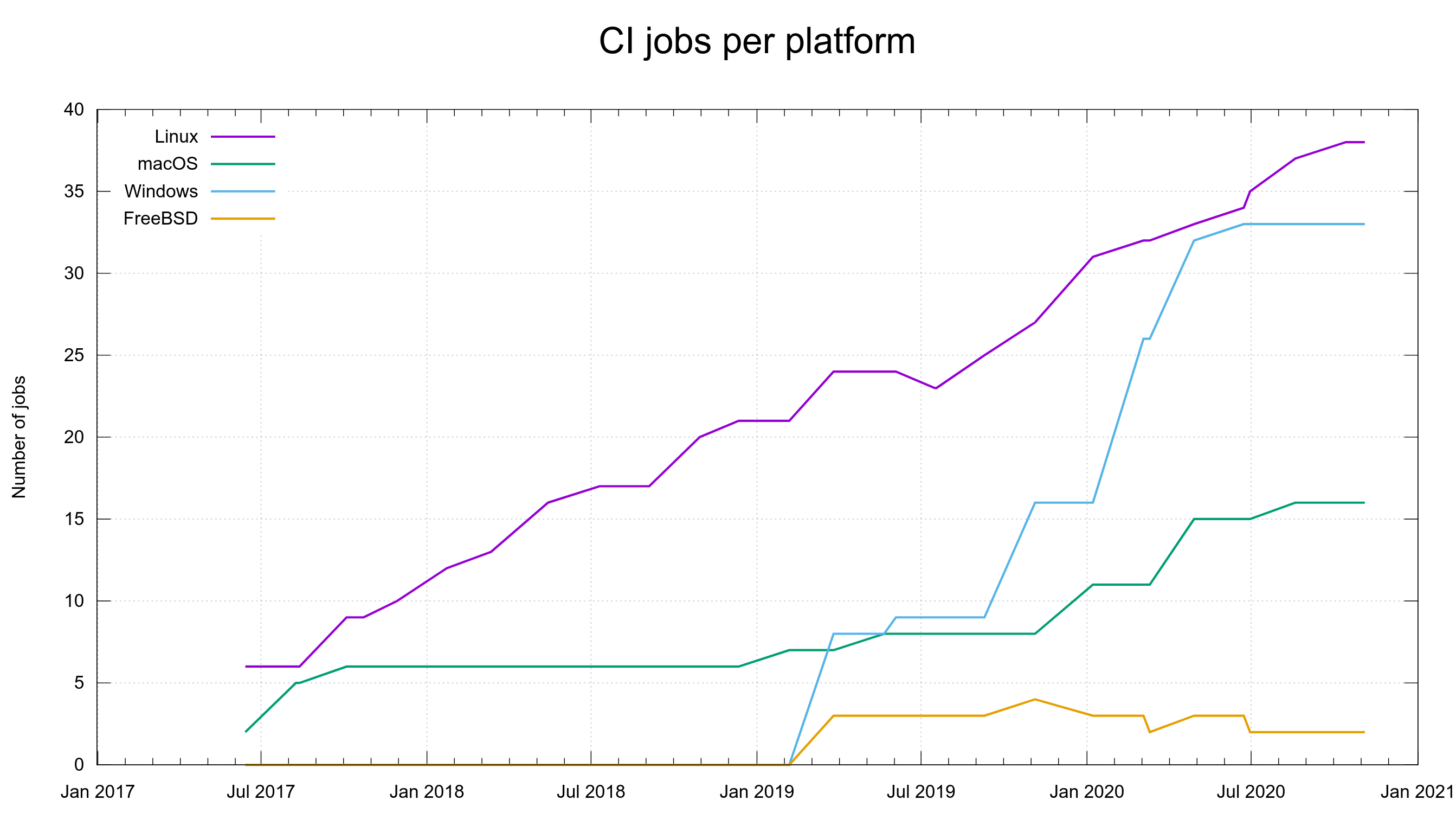
Perhaps most importantly, a pull request kicks of a flood of CI jobs that will build and test the code in numerous different combinations and on several platforms, and the results of those tests will trickle in over the coming hours. When I write this, we have around 90 different CI jobs – per pull request – and something like 8 different code analyzers will scrutinize the change to see if there’s any obvious flaws in there.
CI jobs per platform over time. Graph snapped on November 5, 2020
A branch in the actual curl/curl repo
Most contributors who would work on curl would not do like me and make the branch in the curl repository itself, but would rather do them in their own forked version instead. The difference isn’t that big and I could of course also do it that way.
After push, switch branch
As it will take some time to get the full CI results from the PR to come in (generally a few hours), I switch over to the next branch with work on my agenda. On a normal work-day I can easily move over ten different branches, polish them and submit updates in their respective pull-requests.
I can go back to the master branch again with ‘git checkout master‘ and there I can “git pull” to get everything from upstream – like when my fellow developers have pushed stuff in the mean time.
PR comments or CI alerts
If a reviewer or a CI job find a mistake in one of my PRs, that becomes visible on GitHub and I get to work to handle it. To either fix the bug or discuss with the reviewer what the better approach might be.
Unfortunately, flaky CI jobs is a part of life so very often there ends up one or two red markers in the list of CI jobs that can be ignored as the test failures in them are there due to problems in the setup and not because of actual mistakes in the PR…
To get back to my branch for that PR again, I “git checkout bagder/my-new-stuff-or-bugfix“, and fix the issues.
I normally start out by doing follow-up commits that repair the immediate mistake and push them on the branch:
git push origin bagder/my-new-stuff-or-bugfix
If the number of fixup commits gets large, or if the follow-up fixes aren’t small, I usually end up doing a squash to reduce the number of commits into a smaller, simpler set, and then force-push them to the branch.
The reason for that is to make the patch series easy to review, read and understand. When a commit series has too many commits that changes the previous commits, it becomes hard to review.
Ripe to merge?
When the pull request is ripe for merging (independently of who authored it), I switch over to the master branch again and I merge the pull request’s commits into it. In special cases I cherry-pick specific commits from the branch instead. When all the stuff has been yanked into master properly that should be there, I push the changes to the remote.
Usually, and especially if the pull request wasn’t done by me, I also go over the commit messages and polish them somewhat before I push everything. Commit messages should follow our style and mention not only which PR that it closes but also which issue it fixes and properly give credit to the bug reporter and all the helpers – using the right syntax so that our automatic tools can pick them up correctly!
As already mentioned above, I merge fast-forward or rebased into master. No merge commits.
Never merge with GitHub!
There’s a button GitHub that says “rebase and merge” that could theoretically be used for merging pull requests. I never use that (and if I could, I’d disable/hide it). The reasons are simply:
I don’t feel that I have the proper control of the commit message(s)
I can’t select to squash a subset of the commits, only all or nothing
I often want to cleanup the author parts too before push, which the UI doesn’t allow
The downside with not using the merge button is that the message in the PR says “closed by [hash]” instead of “merged in…” which causes confusion to a fair amount of users who don’t realize it means that it actually means the same thing! I consider this is a (long-standing) GitHub UX flaw.
Post merge
If the branch has nothing to be kept around more, I delete the local branch again with “git branch -d [name]” and I remove it remotely too since it was completely merged there’s no reason to keep the work version left.
At any given point in time, I have some 20-30 different local branches alive using this approach so things I work on over time all live in their own branches and also submissions from various people that haven’t been merged into master yet exist in branches of various maturity levels. Out of those local branches, the number of concurrent pull requests I have in progress can be somewhere between just a few up to ten, twelve something.
RELEASE-NOTES
Not strictly related, but in order to keep interested people informed about what’s happening in the tree, we sync the RELEASE-NOTES file every once in a while. Maybe every 5-7 days or so. It thus becomes a file that explains what we’ve worked on since the previous release and it makes it well-maintained and ready by the time the release day comes.
To sync it, all I need to do is:
$ ./scripts/release-notes.pl
Which makes the script add suggested updates to it, so I then load the file into my editor, remove the separation marker and all entries that don’t actually belong there (as the script adds all commits as entries as it can’t judge the importance).
When it looks okay, I run a cleanup round to make it sort it and remove unused references from the file…
$ ./scripts/release-notes.pl cleanup
Then I make sure to get a fresh list of contributors…
$ ./scripts/contributors.sh
… and paste that updated list into the RELEASE-NOTES. Finally, I get refreshed counters for the numbers at the top of the file by running
$ ./scripts/delta
Then I commit the update (which needs to have the commit message RELEASE-NOTES: synced“) and push it to master. Done!















{kind=link}