Some critics think the curl project shouldn’t use GitHub. The reasons for being against GitHub hosting tend to be one or more of:
- it is an evil proprietary platform
- it is run by Microsoft and they are evil
- GitHub is American thus evil
Some have insisted on craziness like “we let GitHub hold our source code hostage”.
Why GitHub?
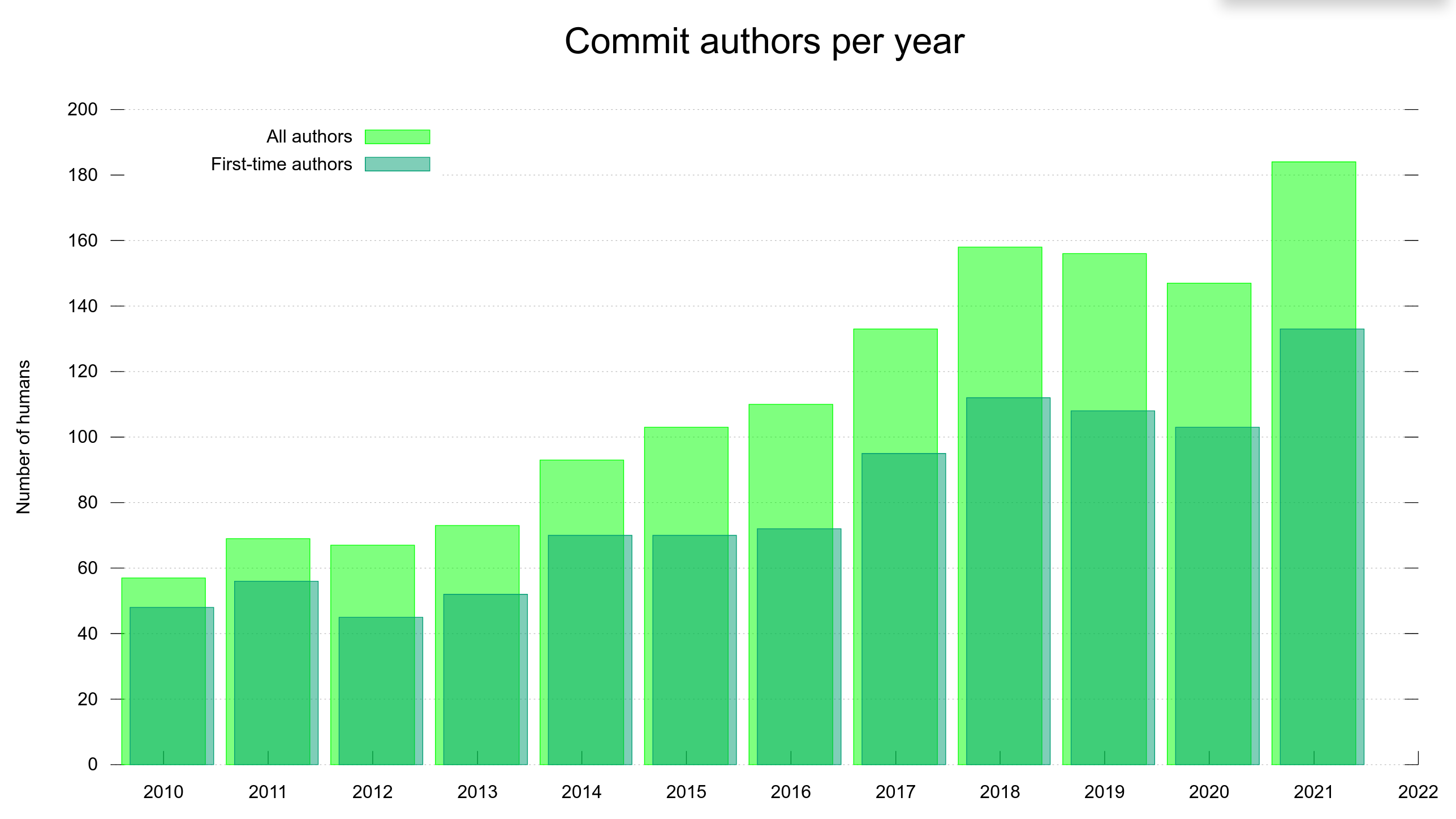
The curl project switched to GitHub (from Sourceforge) almost eleven years ago and it’s been a smooth ride ever since.
We’re on GitHub not only because it provides a myriad of practical features and is a stable and snappy service for hosting and managing source code. GitHub is also a developer hub for millions of developers who already have accounts and are familiar with the GitHub style of developing, the terms and the tools. By being on GitHub, we reduce friction from the contribution process and we maximize the ability for others to join in and help. We lower the bar. This is good for us.
I like GitHub.
Self-hosting is not better
Providing even close to the same uptime and snappy response times with a self-hosted service is a challenge, and it would take someone time and energy to volunteer that work – time and energy we now instead can spend of developing the project instead. As a small independent open source project, we don’t have any “infrastructure department” that would do it for us. And trust me: we already have enough infrastructure management to deal with without having to add to that pile.
… and by running our own hosted version, we would lose the “network effect” and convenience for people that already are on and know the platform. We would also lose the easy integration with cool services like the many different CI and code analyzer jobs we run.
Proprietary is not the issue
While git is open source, GitHub is a proprietary system. But the thing is that even if we would go with a competitor and get our code hosting done elsewhere, our code would still be stored on a machine somewhere in a remote server park we cannot physically access – ever. It doesn’t matter if that hosting company uses open source or proprietary code. If they decide to switch off the servers one day, or even just selectively block our project, there’s nothing we can do to get our stuff back out from there.
We have to work so that we minimize the risk for it and the effects from it if it still happens.
A proprietary software platform holds our code just as much hostage as any free or open source software platform would, simply by the fact that we let someone else host it. They run the servers our code is stored on.
If GitHub takes the ball and goes home
No matter which service we use, there’s always a risk that they will turn off the light one day and not come back – or just change the rules or licensing terms that would prevent us from staying there. We cannot avoid that risk. But we can make sure that we’re smart about it, have a contingency plan or at least an idea of what to do when that day comes.
If GitHub shuts down immediately and we get zero warning to rescue anything at all from them, what would be the result for the curl project?
Code. We would still have the entire git repository with all code, all source history and all existing branches up until that point. We’re hundreds of developers who pull that repository frequently, and many automatically, so there’s a very distributed backup all over the world.
CI. Most of our CI setup is done with yaml config files in the source repo. If we transition to another hosting platform, we could reuse them.
Issues. Bug reports and pull requests are stored on GitHub and a sudden exit would definitely make us lose some of them. We do daily “extractions” of all issues and pull-requests so a lot of meta-data could still be saved and preserved. I don’t think this would be a terribly hard blow either: we move long-standing bugs and ideas over to documents in the repository, so the currently open ones are likely possible to get resubmitted again within the nearest future.
There’s no doubt that it would be a significant speed bump for the project, but it would not be worse than that. We could bounce back on a new platform and development would go on within days.
Low risk
It’s a rare thing, that a service just suddenly with no warning and no heads up would just go black and leave projects completely stranded. In most cases, we get alerts, notifications and get a chance to transition cleanly and orderly.
There are alternatives
Sure there are alternatives. Both pure GitHub alternatives that look similar and provide similar services, and projects that would allow us to run similar things ourselves and host locally. There are many options.
I’m not looking for alternatives. I’m not planning to switch hosting anytime soon! As mentioned above, I think GitHub is a net positive for the curl project.
Nothing lasts forever
We’ve switched services several times before and I’m expecting that we will change again in the future, for all sorts of hosting and related project offerings that we provide to the work and to the developers and participators within the project. Nothing lasts forever.
When a service we use goes down or just turns sour, we will figure out the best possible replacement and take the jump. Then we patch up all the cracks the jump may have caused and continue the race into the future. Onward and upward. The way we know and the way we’ve done for over twenty years already.
Credits
Image by Elias Sch. from Pixabay
Updates
After this blog post went live, some users remarked than I’m “disingenuous” in the list of reasons at the top, that people have presented to me. This, because I don’t mention the moral issues staying on GitHub present – like for example previously reported workplace conflicts and their association with hideous American immigration authorities.
This is rather the opposite of disingenuous. This is the truth. Not a single person have ever asked me to leave GitHub for those reasons. Not me personally, and nobody has asked it out to the wider project either.
These are good reasons to discuss and consider if a service should be used. Have there been violations of “decency” significant enough that should make us leave? Have we crossed that line in the sand? I’m leaning to “no” now, but I’m always listening to what curl users and developers say. Where do you think the line is drawn?