

URLs is a dear subject of mine on this blog, as readers might have noticed.
“URL” is this mythical concept of a string that identifies a resource online and yet there is no established standard for its syntax. There are instead multiple ones out of which one is on purpose “moving” so it never actually makes up its mind but instead keeps changing.
This then leads to there being basically no two URL parsers that treat URLs the same, to the extent that mixing parsers is considered a security risk.
The standards
The browsers have established their WHATWG URL Specification as a “living document”, saying how browsers should parse URLs, gradually taking steps away from the earlier established RFC 3986 and RFC 3987 attempts.
The WHATWG standard keeps changing and the world that tries to stick to RFC 3986 still needs to sometimes get and adapt to WHATWG influences in order to interoperate with the browser-centric part of the web. It leaves URL parsing and “URL syntax” everywhere in a sorry state.
curl
In the curl project we decided in 2018 to help mitigate the mixed URL parser problem by adding a URL parser API so that applications that use libcurl can use the same parser for all its URL parser needs and thus avoid the dangerous mixing part.
The libcurl API for this purpose is designed to let users parse URLs, to extract individual components, to set/change individual components and finally to extract a normalized URL if wanted. Including some URL encoding/decoding and IDN support.
trurl
Thanks to the availability and functionality of the public libcurl URL API, we could build and ship the separate trurl tool earlier this year.
Ada
Some time ago I was made aware of an effort to (primarily) write a new URL parser for node js – although the parser is stand-alone and can be used by anyone else who wants to: The Ada URL Parser. The two primary developers behind this effort, Yagiz Nizipli and Daniel Lemire figured out that node does a large amount of URL parsing so by speeding up this parser alone it would apparently have a general performance impact.
Ada is C++ project designed to parse WHATWG URLs and the first time I was in contact with Yagiz he of course mentioned how much faster their parser is compared to curl’s.
You can also see them reproduce and talk about these numbers on this node js conference presentation.
Benchmarks
Everyone who ever tried to write code faster than some other code has found themselves in a position where they need to compare. To benchmark one code set against the other. Benchmarking is an art that is close to statistics and marketing: very hard to do without letting your own biases or presumptions affect the outcome.
Speed vs the rest
After I first spoke with Yagiz, I did go back to the libcurl code to see what obvious mistakes I had done and what low hanging fruit there was to pick in order to speed things up a little. I found a few flaws that maybe did a minor difference, but in my view there are several other properties of the API that is actually more important than sheer speed:
- non-breaking API and ABI
- readable and maintainable code
- sensible and consistent API
- error codes that help users understand what the problem is
Of course, there is also the thing that if you first figure out how to parse a URL the fastest way, maybe you can work out a smoother API that works better with that parsing approach. That’s not how I went about when creating the libcurl API.
If we can maintain those properties mentioned above, I still want the parser to run as fast as possible. There is no point in being slower than necessary.
URLs vs URLs
Ada parses WHATWG URLs and libcurl parses RFC 3986 URLs. They parse URLs differently and provide different feature sets. They are not interchangeable.
In Ada’s benchmarks they have ignored the parser differences. Throw the parsers against each other, and according to all their public data since early 2023 their parser is 7-8 times faster.
700% faster really?
So how on earth can you make such a simple thing as URL parsing 700% faster? It never sat right with me when they claimed those numbers but since I had not compared them myself I trusted them. After all, they should be fairly easy to compare and they seemed clueful enough.
Until recently when I decided to reproduce their claims and see how much their numbers depends on their specific choices of URLs to parse. It taught me something.
Reproduce the numbers
In my tests, their parser is fast. It is clearly faster than the libcurl parser, and I too of course ignored the parser results since they would not be comparable anyway.
In my tests on my development machine, Ada is 1.25 – 1.8 times faster than libcurl. There is no doubt Ada is faster, just far away from the enormous difference they claim. How come?
- You use the input data that most favorably shows a difference
- You run the benchmark on a hardware for which your parser has magic hardware acceleration
I run a decently modern 13th gen Intel Core-I7 i7-13700K CPU in my development machine. It’s really fast, especially on single-thread stuff like this. On my machine, the Ada parser can parse more URLs/second than even the Ada people themselves claim, which just tells us they used slower machines to test on. Nothing wrong with that.
The Ada parser has code that is using platform specific instructions on some environments and the benchmark they decide to use when boasting about their parser was done on such a platform. An Apple m1 CPU to be specific. In most aspects except performance per watt, not a speed monster CPU.
In itself this is not wrong, but maybe a little misleading as this is far from clearly communicated.
I have a script, urlgen. that generates URLs in as many combinations as possible so that the parser’s every corner and angle are suitably exercised and verified. Many of those combination therefor illegal in subtle ways. This is the set of URLs I have thrown at the curl parser mostly, which then also might explain why this test data is the set that makes Ada least favorable (at 1.26 x the libcurl speed). Again: their parser is faster, no doubt. I have not found a test case that does not show it running faster than libcurl’s parser.
A small part of the explanation of how they are faster is of course that they do not provide the result, the individual components, in their own separately allocated strings.
Here’s a separate detailed document how I compared.
More mistakes
They also repeatably insist curl does not handle International Domain Names (IDN) correctly, which I simply cannot understand and I have not got any explanation for. curl has handled IDN since 2004. I’m guessing a mistake, an old bug or that they used a curl build without IDN support.
Size
I would think a primary argument against using Ada vs libcurl’s parser is its size and code. Not that I believe that there are many situations where users are actually selecting between these two.
Ada header and source files are 22,774 lines of C++
libcurl URL API header and source files are 2,103 lines of C.
Comparing the code sizes like this is a little unfair since Ada has its own IDN management code included, which libcurl does not, and that part comes with several huge tables and more.
Improving libcurl?
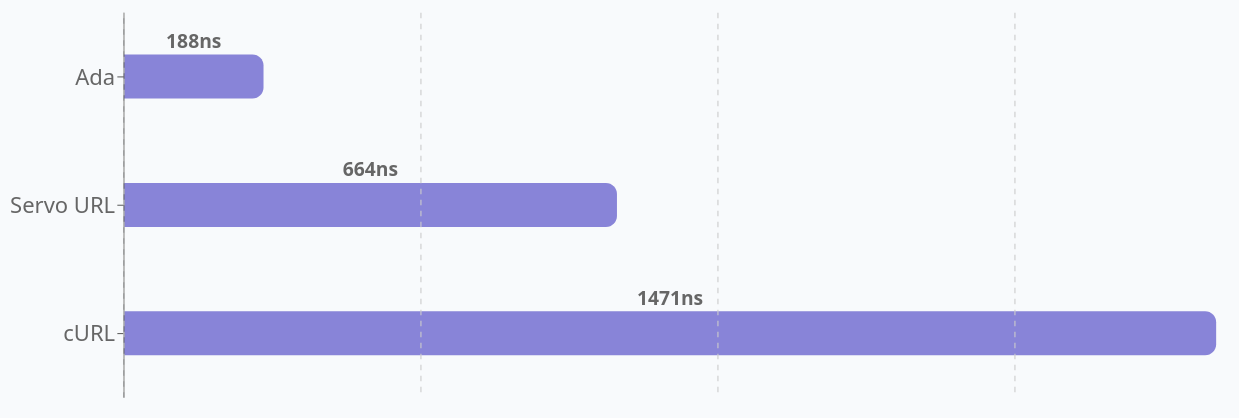
I am sure there is more that can be done to speed up the libcurl URL parser, but there is also the case of diminishing returns. I think it is pretty fast already. On Ada’s test case using 100K URLs from Wikipedia, libcurl parses them at an average of 178 nanoseconds per URL on my machine. More than 5.6 million real world URLs parsed per second per core.
This, while also storing each URL component in a separate allocation after each parse, and also returning an error code that helps identifying the problem if the URL fails to parse. With an established and well-documented API that has been working since 2018 .
The hardware specific magic Ada uses can possibly be used by libcurl too. Maybe someone can try that out one day.
I think we have other areas in libcurl where work and effort are better spent right now.
