

The other day I sent out this tweet
As it took off, got an amazing attention and I received many different comments and replies, I felt a need to elaborate a little. To add some meat to this.
Is this string really a legitimate URL? What is a URL? How is it parsed?
http://http://http://@http://http://?http://#http://
curl
Let’s start with curl. It parses the string as a valid URL and it does it like this. I have color coded the sections below a bit to help illustrate:
http://http://http://@http://http://?http://#http://
Going from left to right.
http – the scheme of the URL. This speaks HTTP. The “://” separates the scheme from the following authority part (that’s basically everything up to the path).
http – the user name up to the first colon
//http:// – the password up to the at-sign (@)
http: – the host name, with a trailing colon. The colon is a port number separator, but a missing number will be treated by curl as the default number. Browsers also treat missing port numbers like this. The default port number for the http scheme is 80.
//http:// – the path. Multiple leading slashes are fine, and so is using a colon in the path. It ends at the question mark separator (?).
http:// – the query part. To the right of the question mark, but before the hash (#).
http:// – the fragment, also known as “anchor”. Everything to the right of the hash sign (#).
To use this URL with curl and serve it on your localhost try this command line:
curl "http://http://http://@http://http://?http://#http://" --resolve http:80:127.0.0.1
The curl parser
The curl parser has been around for decades already and do not break existing scripts and applications is one of our core principles. Thus, some of the choices in the URL parser we did a long time ago and we stand by them, even if they might be slightly questionable standards wise. As if any standard meant much here.
The curl parser started its life as lenient as it could possibly be. While it has been made stricter over the years, traces of the original design still shows. In addition to that, we have also felt that we have been forced to make adaptions to the parser to make it work with real world URLs thrown at it. URLs that maybe once was not deemed fine, but that have become “fine” because they are accepted in other tools and perhaps primarily in browsers.
URL standards
I have mentioned it many times before. What we all colloquially refer to as a URL is not something that has a firm definition:
There is the URI (not URL!) definition from IETF RFC 3986, there is the WHATWG URL Specification that browsers (try to) adhere to and there are numerous different implementations of parsers being more or less strict when following one or both of the above mentioned specifications.
You will find that when you scrutinize them into the details, hardly any two URL parsers agree on every little character.
Therefore, if you throw the above mentioned URL on any random URL parser they may reject it (like the Twitter parser didn’t seem to think it was a URL) or they might come to a different conclusion about the different parts than curl does. In fact, it is likely that they will not do exactly as curl does.
Python’s urllib
April King threw it at Python’s urllib. A valid URL! While it accepted it as a URL, it split it differently:
ParseResult(scheme='http',
netloc='http:',
path='//http://@http://http://',
params='',
query='http://',
fragment='http://')
Given the replies to my tweet, several other parsers did the similar interpretation. Possibly because they use the same underlying parser…
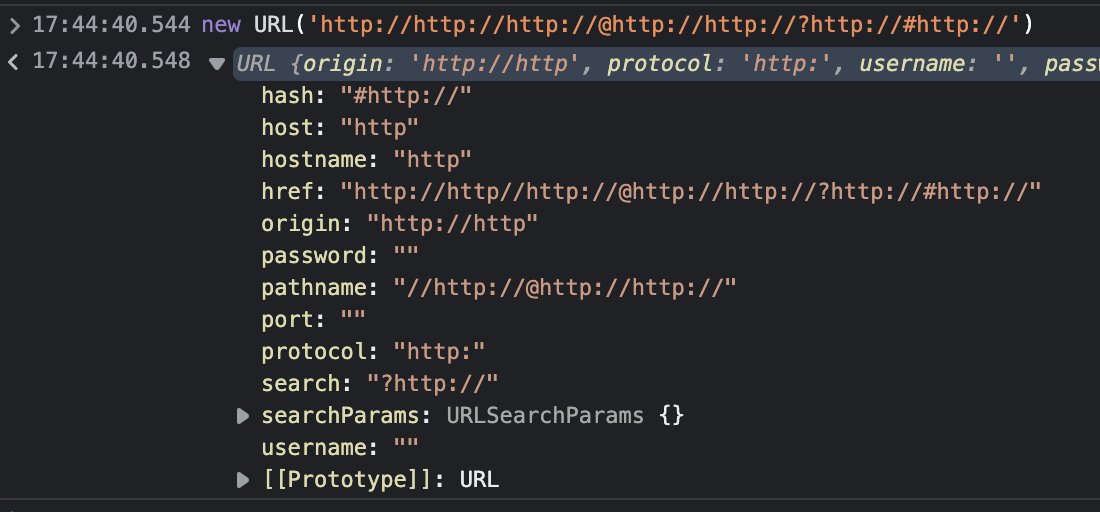
Javacript
Meduz showed how the JavaScript URL object treats it, and it looks quite similar to the Python above. Still a valid URL.
Firefox and Chrome
I added the host entry ‘127.0.0.1 http‘ into /etc/hosts and pasted the URL into the address bar of Firefox. It rewrote it to
http://http//http://@http://http://?http://#http://
(the second colon from the left is removed, everything else is the same)
… but still considered it a valid URL and showed the contents from my web server.
Chrome behaved exactly the same. A valid URL according to it, and a rewrite of the URL like Firefox does.
RFC 3986
Some commenters mentioned that the unencoded “unreserved” letters in the authority part make it not RFC 3986 compliant. Section 3.2 says:
The authority component is preceded by a double slash ("//") and is terminated by the next slash ("/"), question mark ("?"), or number sign ("#") character, or by the end of the URI.
Meaning that the password should have its slashes URL-encoded as %2f to make it valid. At least. So maybe not a valid URL?
Update: it actually still qualifies as “valid”, it just is parsed a little differently than how curl does it. I do not think there is any question that curl’s interpretation is not matching RFC 3986.
HTTPS
The URL works equally fine with https.
https://https://https://@https://https://?https://#https://
The two reasons I did not use https in the tweet:
- It made it 7 characters longer for no obvious extra fun
- It is harder to prove working by serving your own content as you would need
curl -kor similar to make the host name ‘https’ be OK vs the name used in the actual server you would target.
The URL Buffalo buffalo
A surprisingly large number of people thought it reminded them of the old buffalo buffalo thing.
I guess you had quite some fun at this, Daniel!
Just tested through haproxy and it’s properly parsed as well, however we do drop the userinfo part before fowarding it, as permitted by RFC3986 (and likely suggested in 7230 IIRC).
That could make a good interview test, though not very nice 🙂
Hehe, well yes it was a lot of fun creating it and realizing I could actually create something with so many repeated http:// sequences and still make it a parseable URL in the end.
It is a valid URL/URI, yes, but your curl parser is just plain wrong. The authority component is terminated by the next slash, as required by RFC3986 and shown by urllib. That has been the case since the very first definition of web addresses, no matter what acronym is used. You can see it in RFC1808 as well.
As I noted myself in the section on RFC 3986 …
I think it rarely actually has hurt users because if they truly put their passwords in the URL, then know to URL encode it anyway to avoid problems with spaces, at-signs and more and then they also encode the slashes.
The Rust url crate (https://docs.rs/url) parses it, but does not consider it to contain a username or password, presumably because they’re not URI-escaped.
Ok(
Url {
scheme: “http”,
cannot_be_a_base: false,
username: “”,
password: None,
host: Some(Domain(“http”)),
port: None,
path: “//http://@http://http://”,
query: Some(“http://”),
fragment: Some(“http://”),
},
)
@ilmari: thanks for testing and reporting. And yes, it makes perfect sense!
Ruby’s URI module also parses this like Python and Rust FWIW.
uri = URI.parse(“http://http://http://@http://http://?http://#http://“)
uri.path
#=> “//http://@http://http://”
Buffalo buffalo is ok, but did you see chinese “Lion-Eating Poet in the Stone Den” ?