Welcome to a new curl release, the result of a slightly extend release cycle this time.
Release presentation
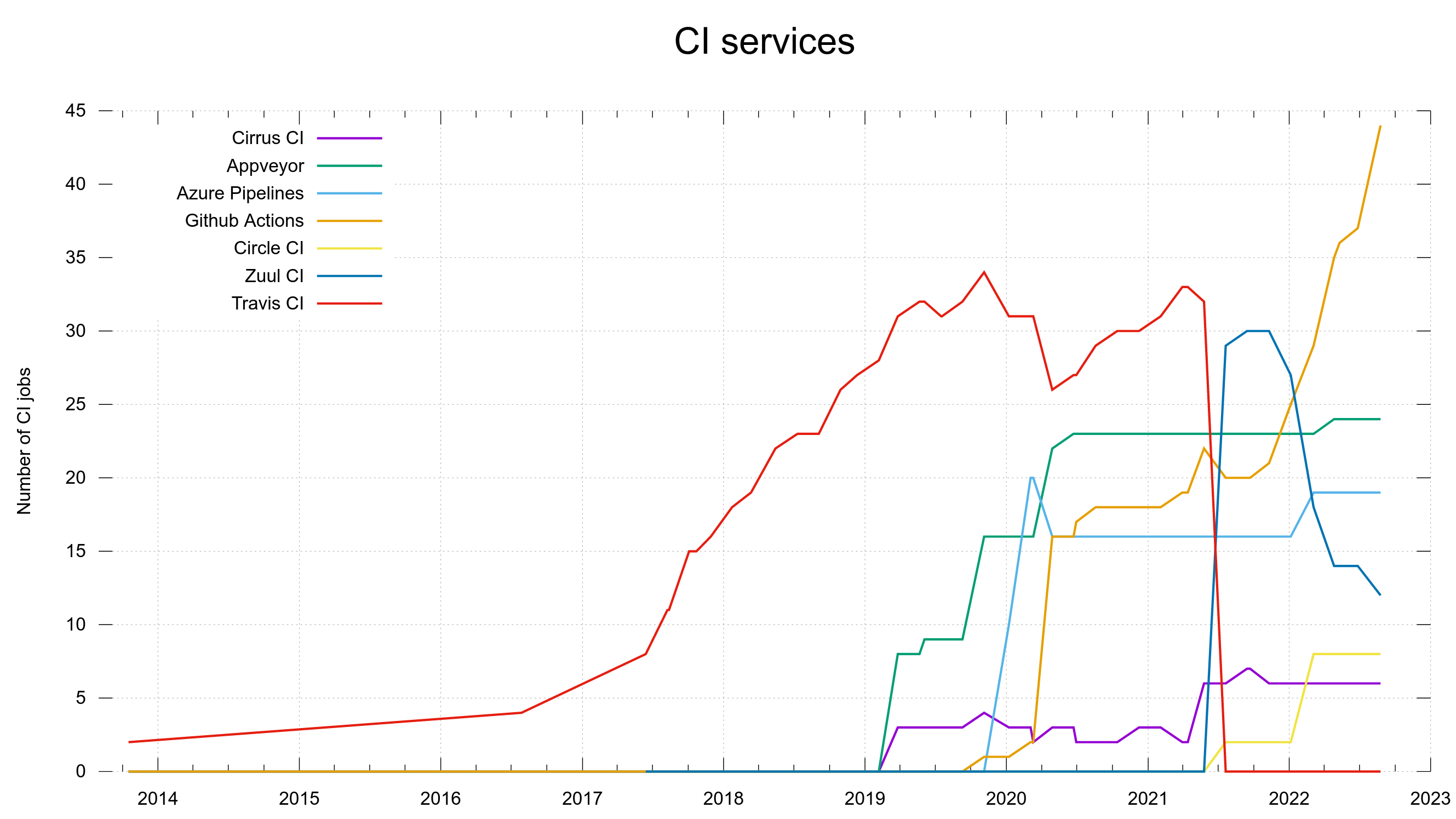
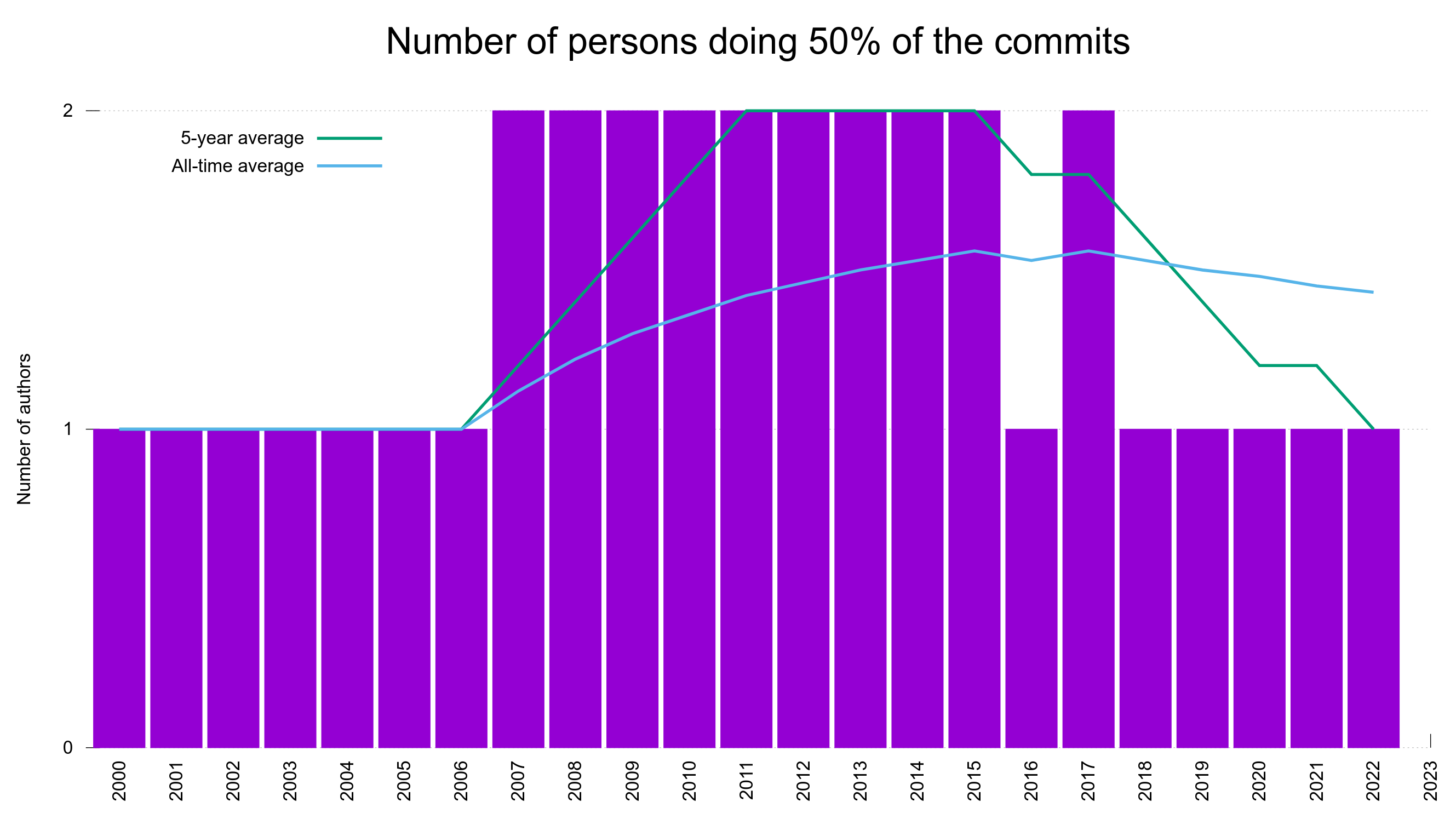
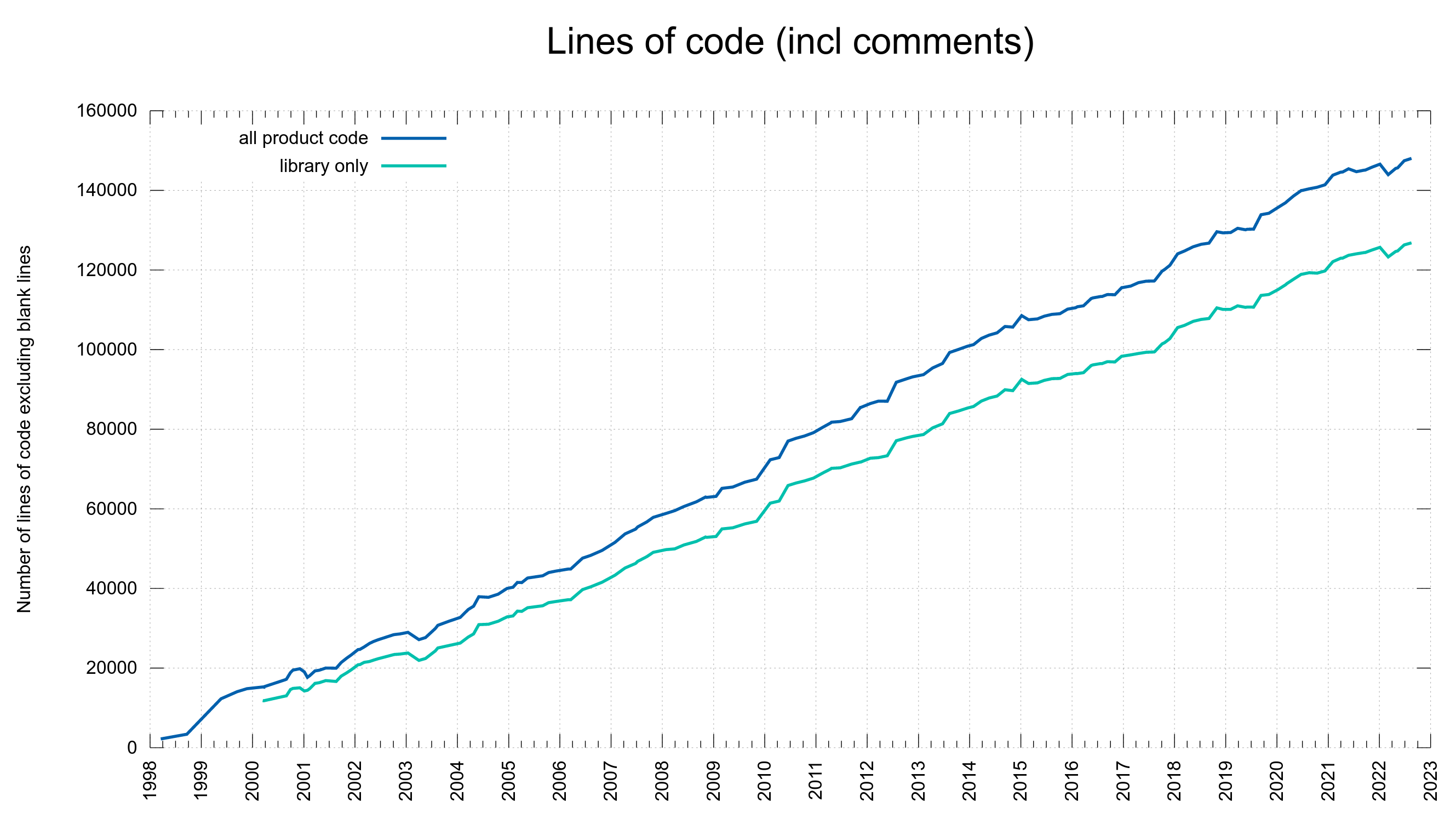
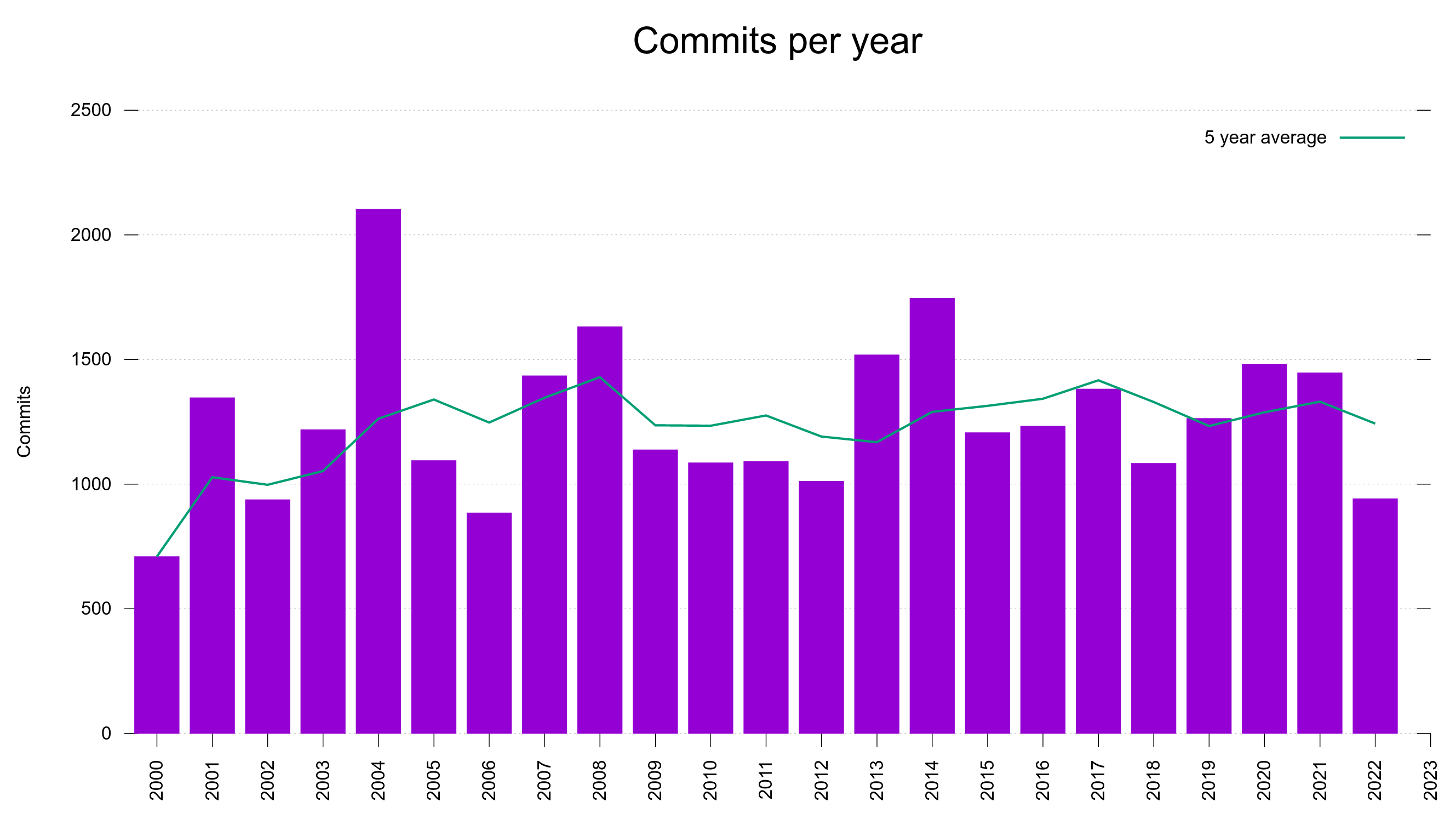
Numbers
the 210th release
3 changes
65 days (total: 8,930)
165 bug-fixes (total: 8,145)
230 commits (total: 29,017)
0 new public libcurl function (total: 88)
2 new curl_easy_setopt() option (total: 299)
0 new curl command line option (total: 248)
79 contributors, 38 new (total: 2,690)
44 authors, 22 new (total: 1,065)
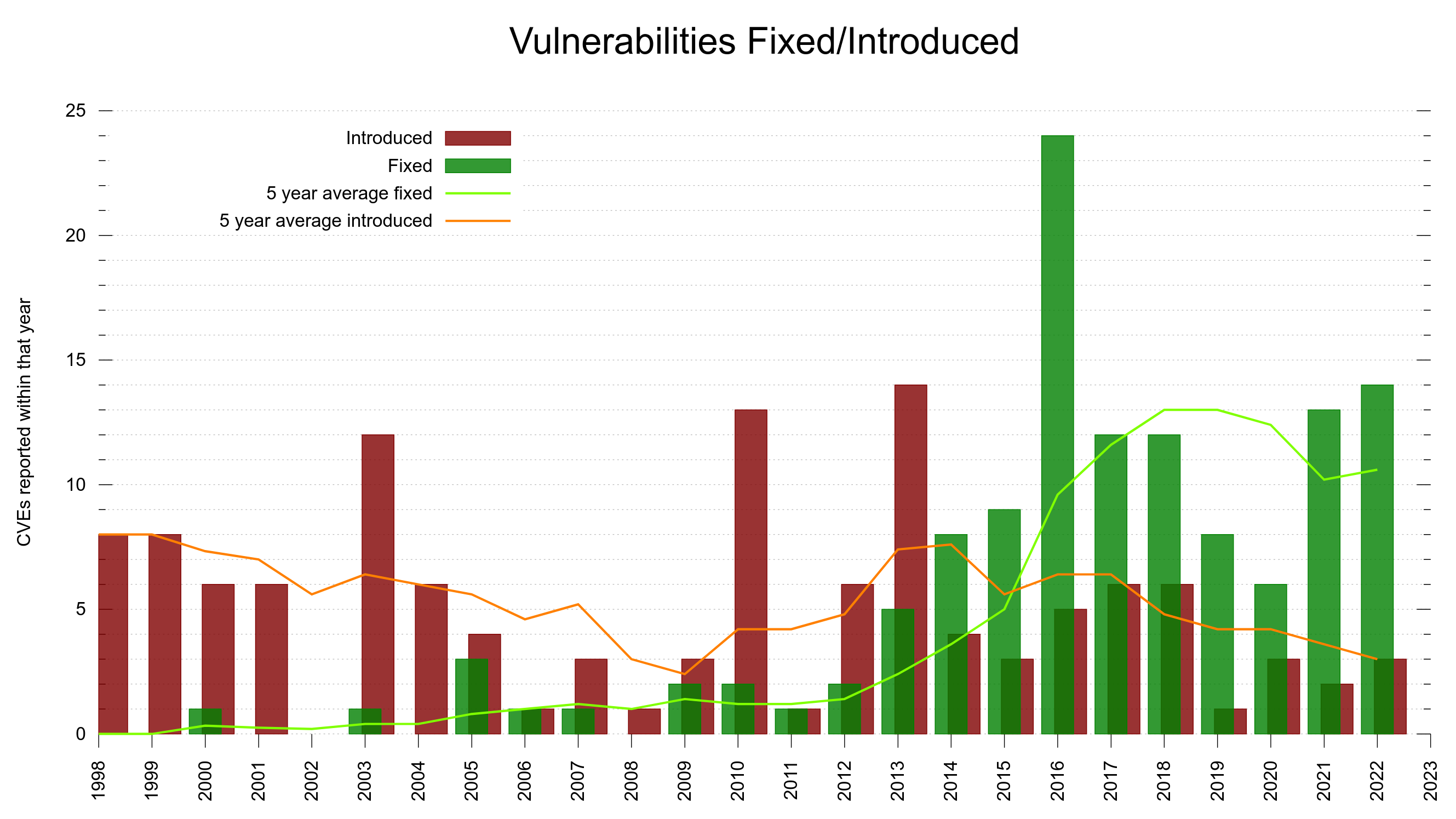
1 security fixes (total: 126)
Bug Bounties total: 40,900 USD
Security
We have yet another CVE to disclose.
control code in cookie denial of service
CVE-2022-35252 allows a server to send cookies to curl that contain ASCII control codes. When such cookies subsequently are sent back to a server, they will cause 400 responses from servers that downright refuse such requests. Severity: low. Reward: 480 USD.
Changes
This release counts three changes. They are:
schannel backend supports TLS 1.3
For everyone who uses this backend (which include everyone who uses the curl that Microsoft bundles with Windows) this is great news: now you too can finally use TLS 1.3 with curl. Assuming that you use a new enough version of Windows 10/11 that has the feature present. Let’s hope Microsoft updates the bundled version soon.
CURLOPT_PROTOCOLS_STR and CURLOPT_REDIR_PROTOCOLS_STR
These are two new options meant to replace and be used instead of the options with the same names without the “_STR” extension.
While working on support for new future protocols for libcurl to deal with, we realized that the old options were filled up and there was no way we could safely extend them with additional entries. These new functions instead work on text input and have no limit in number of protocols they can be made to support.
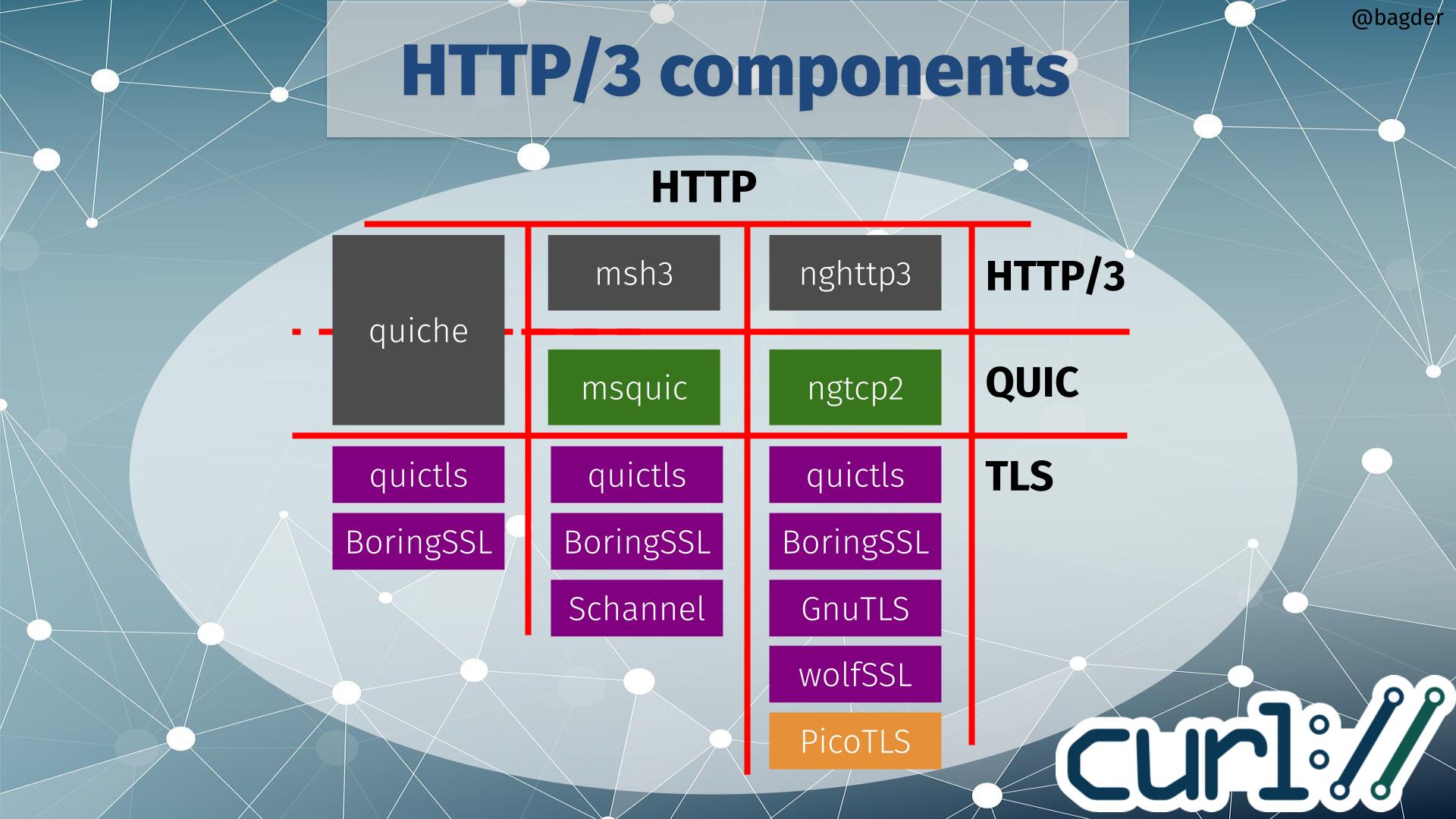
QUIC support via wolfSSL
The ngtcp2 backend can now also be built to use wolfSSL for the TLS parts.
Bugfixes
This was yet again a cycle packed with bugfixes. Here are some of my favorites:
asyn-thread: fix socket leak on OOM
Doing proper and complete memory cleanup even when we exist due to out of memory is sometimes difficult. I found and fixed this very old bug.
cmdline-opts/gen.pl: improve performance
The script that generates the curl.1 man page from all its sub components was improved and now typically executes several times faster then before. curl developers all over rejoice.
configure: if asked to use TLS, fail if no TLS lib was detected
Previously, the configure would instead just silently switch off TLS support which was not always easy to spot and would lead to users going further before they eventually realize this.
configure: introduce CURL_SIZEOF
The configure macro that checks for size of variable types was rewritten. It was the only piece left in the source tree that had the mention of GPL left. The license did not affect the product source code or the built outputs, but it caused questions and therefore some friction we could easily avoid by me completely writing away the need for the license mention.
close the happy eyeballs loser connection when using QUIC
A silly memory-leak when doing HTTP/3 connections on dual-stack machines.
treat a blank domain in Set-Cookie: as non-existing
Another one of those rarely used and tiny little details about following what the spec says.
configure: check whether atomics can link
This, and several other smaller fixes together improved the atomics support in curl quite a lot since the previous version. We conditionally use this C11 feature if present to make the library initialization function thread-safe without requiring a separate library for it.
digest: fix memory leak, fix not quoted ‘opaque’
There were several fixes and cleanups done in the digest department this time around.
remove examples/curlx.c
Another “victim” of the new license awareness in the project. This example was the only file present in the repository using this special license, and since it was also a bit convoluted example we decided it did not really have to be included.
resolve *.localhost to 127.0.0.1/::1
curl is now slightly more compliant with RFC 6761, follows in the browsers’ footsteps and resolves all host names in the “.localhost” domain to the fixed localhost addresses.
enable obs-folded multiline headers for hyper
curl built with hyper now also supports “folded” HTTP/1 headers.
libssh2:+libssh make atime/mtime date overflow return error
Coverity had an update in August and immediately pointed out these two long-standing bugs – in two separate SSH backends – related to time stamps and 32 bits.
curl_multi_remove_handle closes CONNECT_ONLY transfer
When an applications sets the CONNECT_ONLY option for a transfer within a multi stack, that connection was not properly closed until the whole multi handle was closed even if the associated easy handle was terminated. This lead to connections being kept around unnecessarily long (and wasting resources).
use pipe instead of socketpair on apple platforms
Apparently those platform likes to close socketpairs when the application is pushed into the background, while pipes survive the same happening… This is a change that might be preferred for other platforms as well going forward.
use larger dns hash table for multi interface
The hash table used for the DNS cache is now made larger for the multi interface than when created to be used by the easy interface, as it simply is more likely to be used by many host names then and then it performs better like this.
reject URLs with host names longer than 65535 bytes
URLs actually have no actual maximum size in any spec and neither does the host name within one, but the maximum length of a DNS name is 253 characters. Assuming you can resolve the name without DNS, another length limit is the SNI field in TLS that is an unsigned 16 bit number: 65535 bytes. This implies that clients cannot connect to any SNI-using TLS protocol with a longer name. Instead of checking for that limit in many places, it is now done early.
reduce size of several struct fields
As part of the repeated iterative work of making sure the structs are kept as small as possible, we have again reduced the size of numerous struct fields and rearranged the order somewhat to save memory.
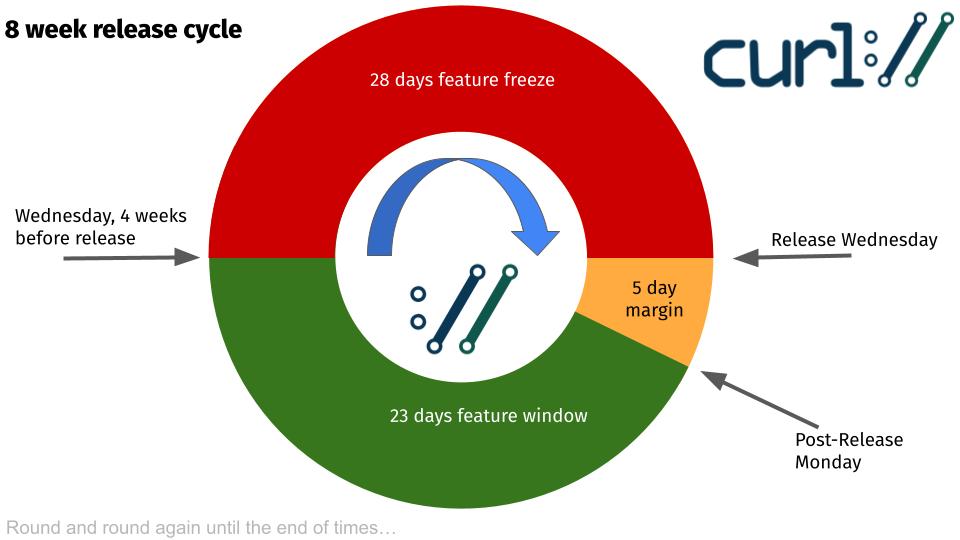
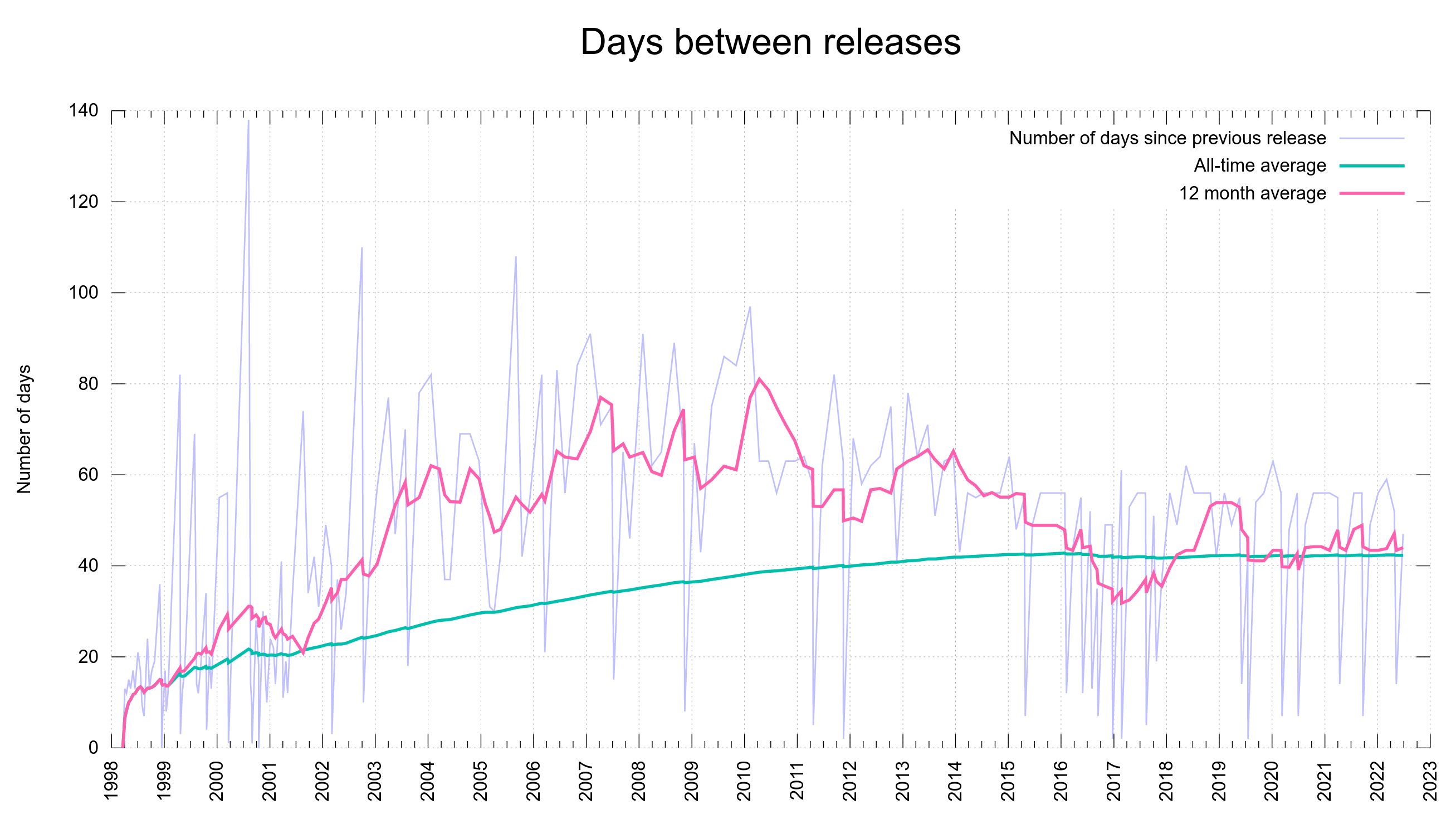
Next
The next release is planned to ship on October 25, 2022.