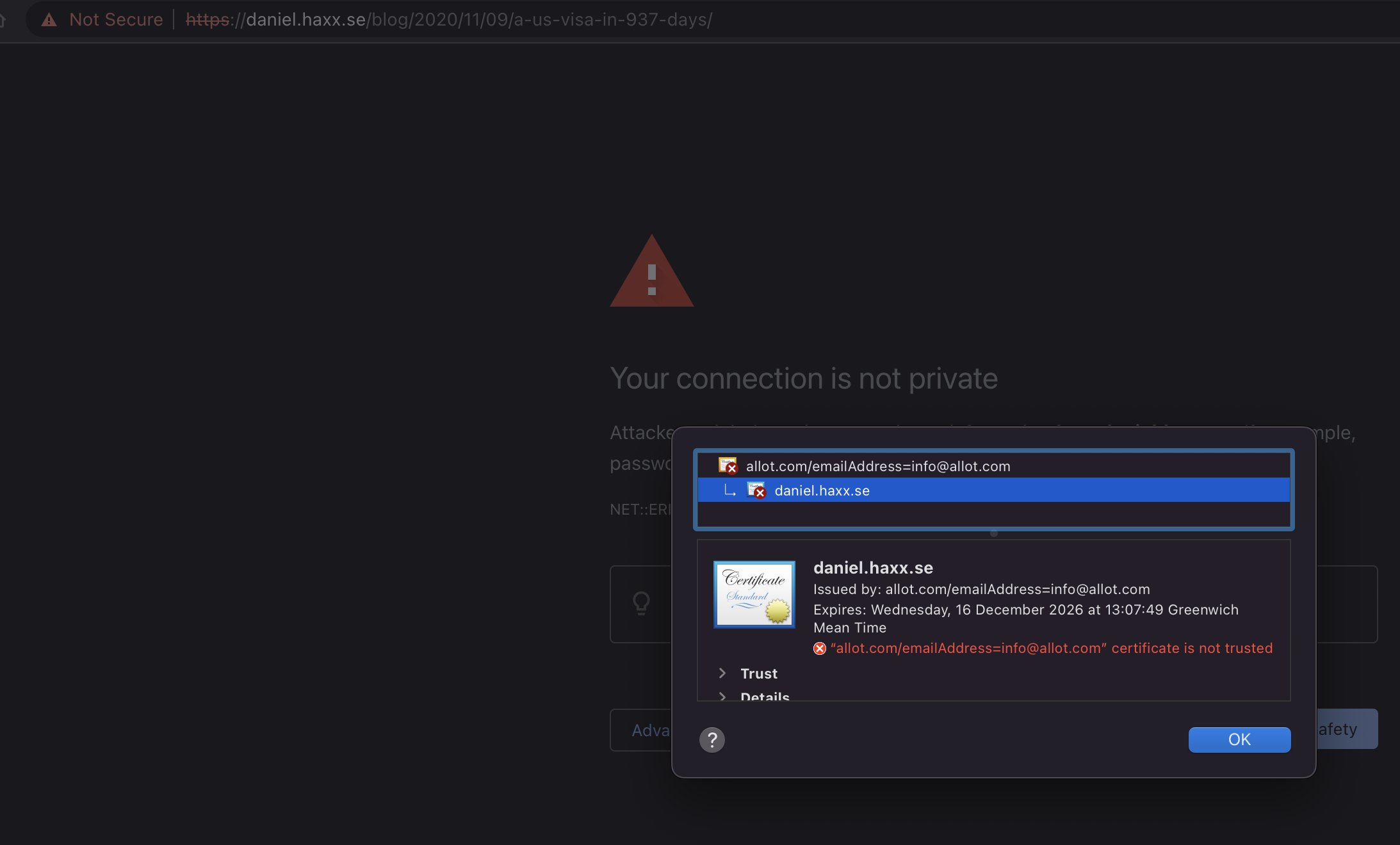
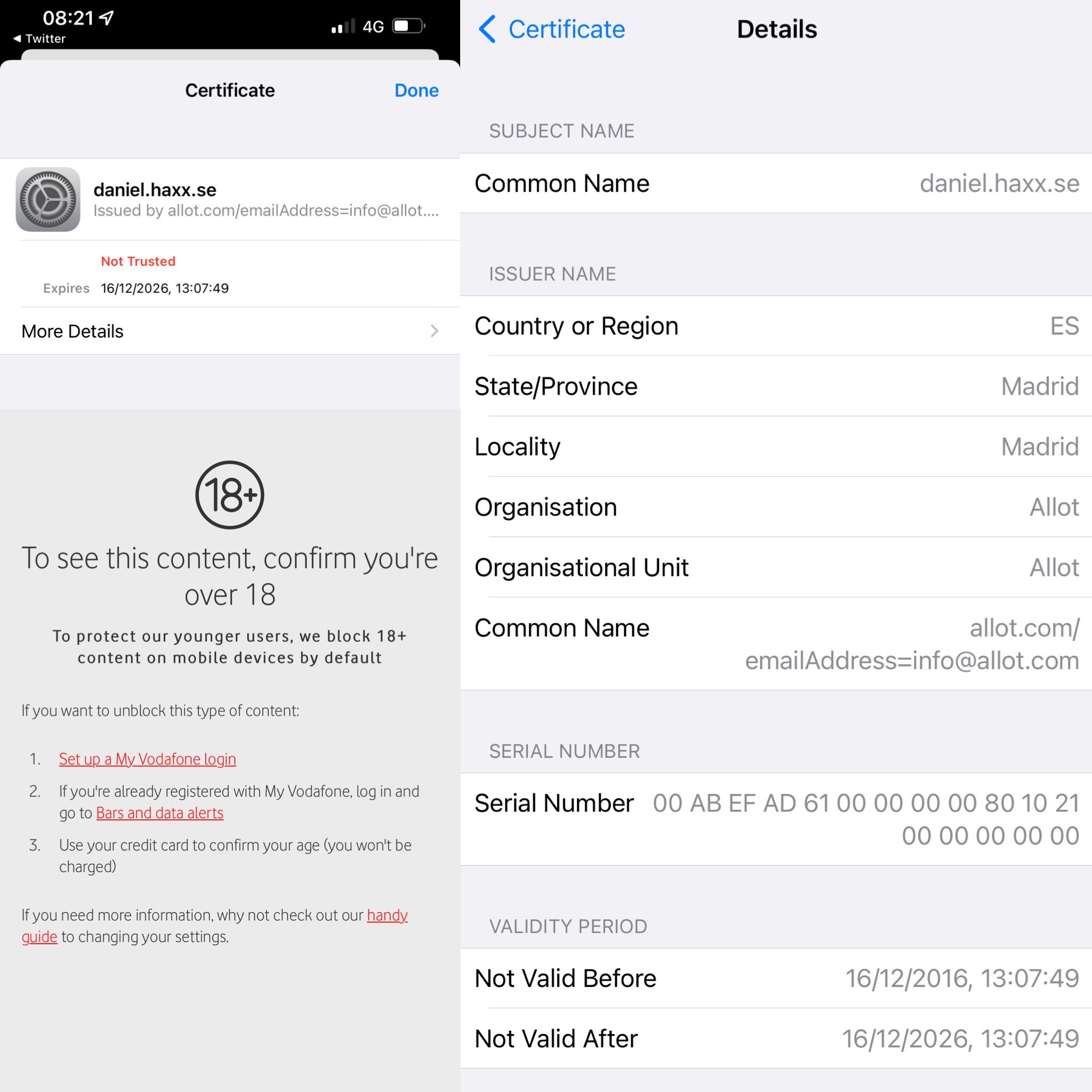
Every human has a unique fingerprint. With only an impression of a person’s fingertip, it is possible to follow the lead back to the single specific individual wearing that unique pattern.

TLS fingerprints
The phrase TLS fingerprint is of course in this spirit. A pattern in a TLS handshake that allows an involved party to tell or at least guess with a certain level of accuracy what client software that performed it – purely based on how exactly the TLS magic is done. There are numerous different ways and variations a client can perform a TLS handshake and still be standards compliant. There is a long list of extensions that can vary in content, the order of the list of extensions, the ciphers to accept, the allowed TLS versions, steps performed, the order and sequence of those steps and more.
When a network client connects to a remote site and makes a TLS handshake with the server, the server can basically add up all those details and make an educated guess exactly which client that connects to it. One method to do it is called JA3 and produces a 32 digit hexadecimal number as output. (The three creators of this algorithm all have JA as their initials!)
In use out there
I have recently talked with customers and users who have faced servers that refused them access when they connected to sites using curl, but allowed them access to the site when they instead use one of the popular browsers – or if curl was tweaked to look like one of those browsers. It might be a trend in the making. There might be more sites out there now that reject clients that produce the wrong fingerprint then there used to be.
Why
Presumably there are many reasons why servers want to limit access to a subset of clients, but I think the general idea is that they want to prevent “illegitimate” user agents from accessing their sites.

For example, I have seen online market sites use this method in an what I have perceived as an attempt to block bots and web scrapers. Or they do it to block malware or other hostile clients that scour their website.
How
There’s this JA3 page that shows lots of implementations for many services that can figure out clients’ TLS fingerprints and act on them. And there’s nothing that says you have to do it with JA3. There’s likely to be numerous other ways and algorithms as well.
There are also companies that offer commercial services to filter off mismatching clients from your site. This is real business.
Other fingerprinting
In the earlier days of the web, web sites used more basic ways to detect and filter out bots and non-browser user clients. The original and much simpler way is to check the User-Agent: field that HTTP clients pass on, but has also sometimes been extended to check the order of the sent HTTP headers and in some cases, servers have used elaborate JavaScript schemes in order to try to “smoke out” the clients that don’t seem to act like full-fledged browsers.
If the clients use HTTP/2, that too allows for more details to fingerprint.
As the web has transitioned over to almost exclusively use HTTPS, it has severely increased the ways a server can fingerprint clients, and at the same time made it harder for non-browser clients to look exactly like browsers.
Allow list or block list
Sites that use TLS fingerprints to allow access, of course do not want too many false positives. They want to allow all “normal” browser-based visitors, even if they use a little older versions and also if they use somewhat older or less common operating systems.
This means that they either have to work hard to get an extensive list of acceptable hashes in an accept list or they add known non-desired clients in a block list. I would imagine that if you go the accept list route, that’s how companies can sell this services as that is maintenance intensive work.
Users of alternative and niche browsers are sometimes also victims in this scheme if they stand out enough.
Altering the fingerprint
The TLS fingerprints have the interesting feature compared to human fingertip prints, that they are the result of a set of deliberate actions and not just a pattern you are born to wear. They are therefore a lot easier to change.
With curl version C using TLS library T of version V, the TLS fingerprint is a function that involves C, T and V. And the options O set by curl. By changing one or more of those variables, you are likely to alter the TLS fingerprint.
Match a browser exactly
To be most certain that no site will reject your curl request because of its TLS fingerprint, you would alter the print to look exactly like the one of a popular browser. You can suspect that most sites want their regular human browser-using visitors to be able to access them.
To make curl look exactly like a browser you also likely need to do more than just change C, O, T and V from the section above. You also need to make sure that the TLS library you use produces its lists of extensions and ciphers in exactly the same order etc. This may require that you alter options and maybe even source code.
curl-impersonate
This is a custom build of curl that can impersonate the four major browsers: Chrome, Edge, Safari & Firefox. curl-impersonate performs TLS and HTTP handshakes that are identical to that of a real browser.
curl-impersonate is a modified curl build and the project also provides docker images and more to help users to use it easily.
I cannot say right now if any of the changes done for curl-impersonate will get merged into the upstream curl project, but it will also depend on what users want and how the use of TLS fingerprinting spread or changes going forward.
Program a browser
Another popular way to work around this kind of blocking is to simply program a browser to do the job. Either a headless browser or with tools like Selenium. Since these methods make the TLS handshake using a browser “engine”, they are unlikely to get blocked by these filters.
Cat and mouse
Servers add more hurdles to attempt to block unwanted clients.
Clients change to keep up with the servers and to still access the sites in spite of what the server admins want.
Future
As early as only a few years ago I had never heard of any site that blocked clients because of their TLS handshake. Through recent years I have seen it happen and the use of it seems to have increased. I don’t know of any way to measure if this is actually true or just my feeling.
I cannot rule out that we are going to see this more going forward, even if I also believe that the work on circumventing these fingerprinting filters is just getting started. If the circumvention grows and becomes easy enough, maybe it will stifle servers from adding these filters as they will not be effective anyway?
Let us come back to this topic in a few years and see where it went.