In this era of powerful tools to find software bugs, we now see tools find a lot of problems at a high speed. This causes problems for developers, as dealing with the growing list of issues is hard. It may take a longer time to address the problems than to find them – not to mention to put them into releases and then it takes yet another extended time until users out in the wild actually get that updated version into their hands.
In order to find many bugs fast, they have to already exist in source code. These new tools don’t add or create the problems. They just find them, filter them out and bring them to the surface for exposure. A better filter in the pool filters out more rubbish.
The more bugs we fix, the fewer bugs remain in the code. Assuming the developers manage to fix problems at a decent enough pace.
For every bugfix we merge, there is a risk that the change itself introduces one more more new separate problems. We also tend to keep adding features and changing behavior as we want to improve our products, and when doing so we occasionally slip up and introduce new problems as well.
Source code analyzing tools is a concept as old as source code itself. There has always existed tools that have tried to identify coding mistakes. Now they just recently got better so they can find more mistakes.
These new tools, similar to the old ones, don’t find all the problems. Even these new modern tools sometimes suggest fixes to the problems they find that are incomplete and in fact sometimes downright buggy.
Undoubtedly code analyzer tooling will improve further. The tools of tomorrow will find even more bugs, some of them were not found when the current generation of tools scanned the code yesterday.
Of course, we now also introduce these tools in CI and general development pipelines, which should make us land better code with fewer mistakes going forward. Ideally.
If we assume that we fix bugs faster than we introduce new ones and we assume that the AI tools can improve further, the question is then more how much more they can improve and for how long that improvement can go on. Will the tools find 10% more bugs? 100%? 1000%? Is the tool improving going to gradually continue for the next two, ten or fifty years? Can they actually find all bugs?
Can we reach the utopia where we have no bugs left in a given software project and when we do merge a new one, it gets detected and fixed almost instantly?
Are we close?
If we assume that there is at least a theoretical chance to reach that point, how would we know when we reach it? Or even just if we are getting closer?
I propose that one way to measure if we are getting closer to zero bugs is to check the age of reported and fixed bugs. If the tools are this good, we should soon only be fixing bugs we introduced very recently.
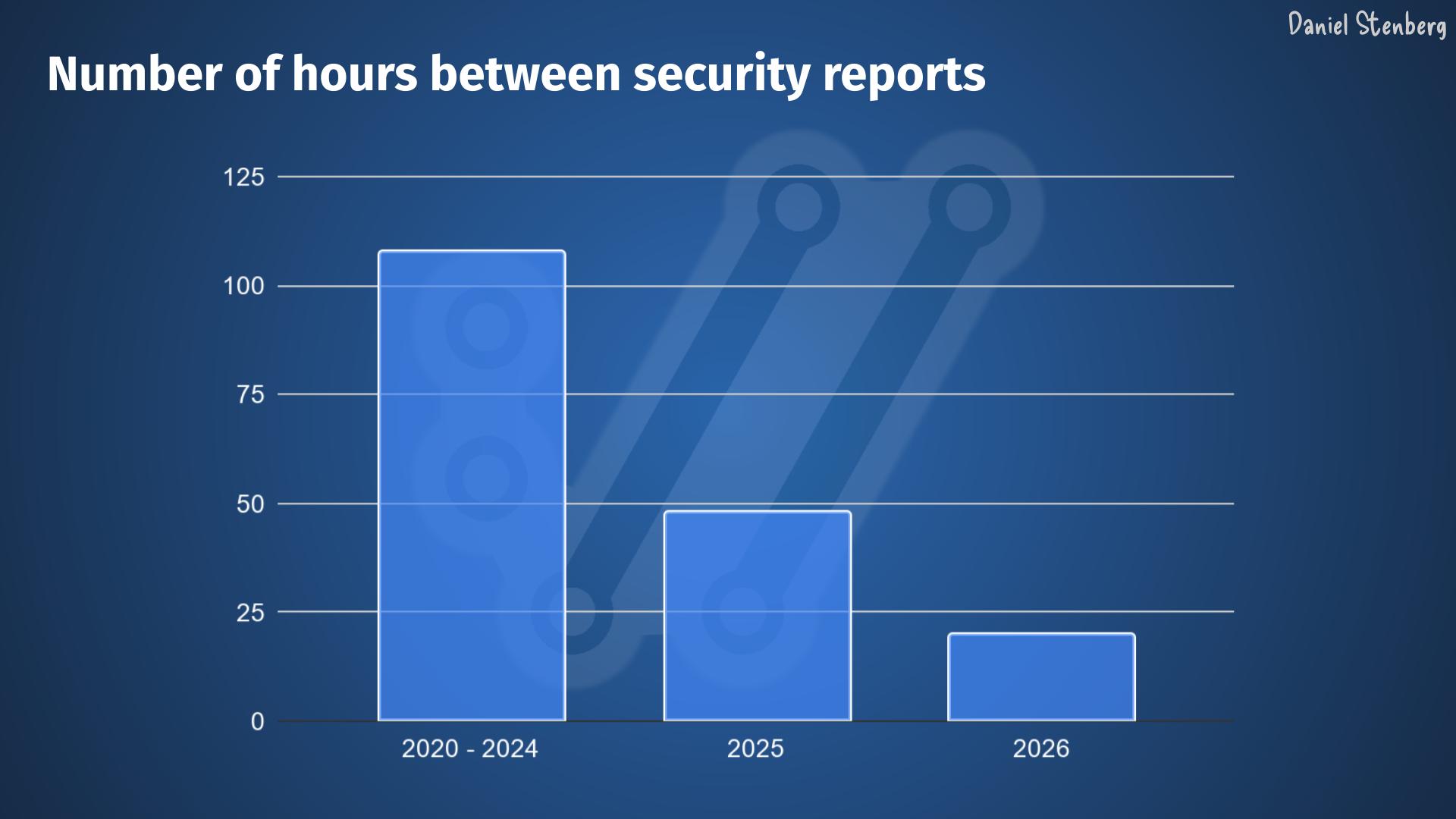
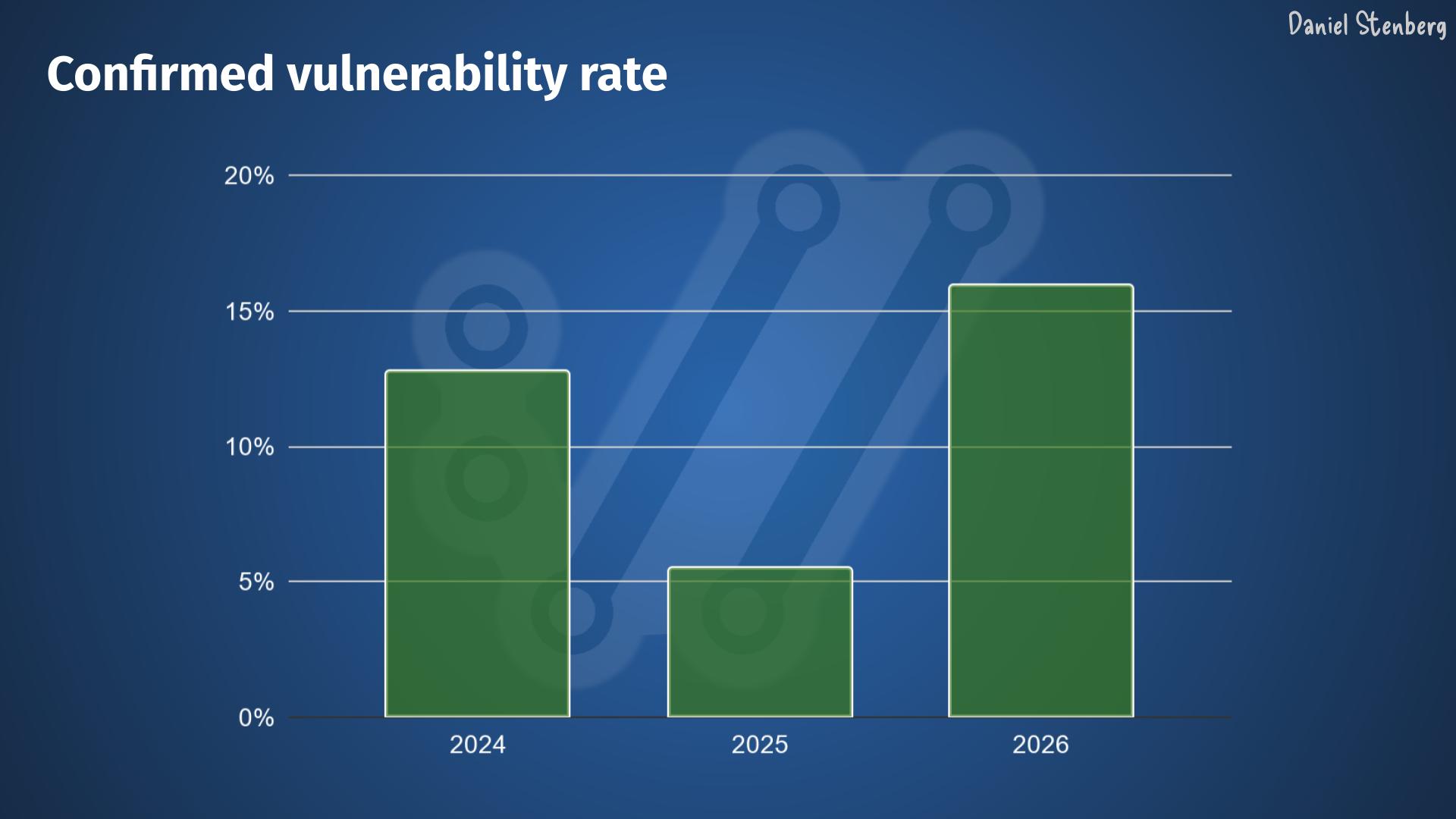
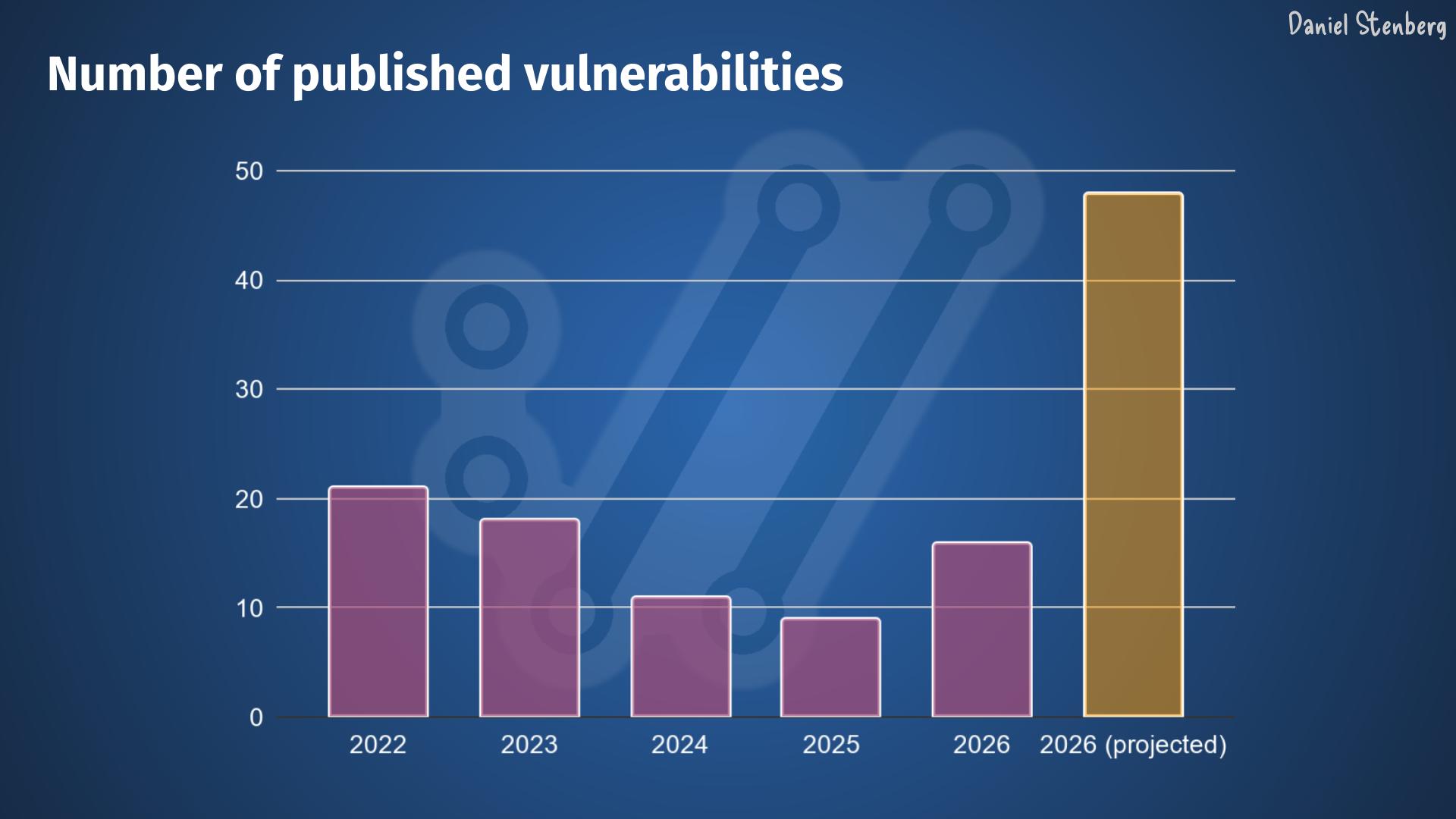
In the curl project we don’t keep track of the age of regular bugs, but we do for vulnerabilities. The worst kind of bugs. If the tools can find almost all problems, they should soon only be finding very recently added vulnerabilities too. The age of new finds should plummet and go towards zero.
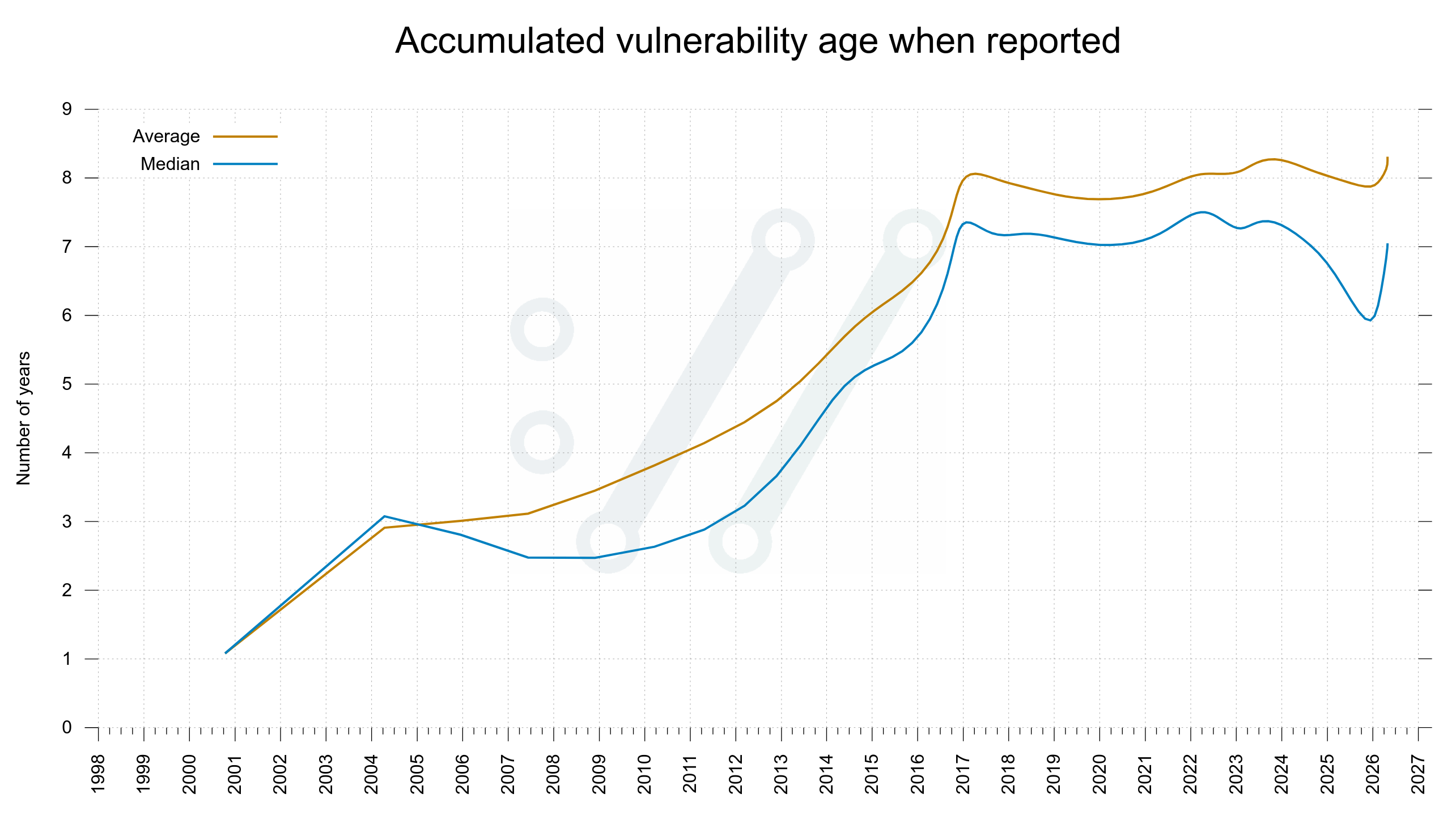
If the age of newly reported vulnerabilities are getting younger, it should make the average and median age of the total collection go down over time.
Average age of vulnerabilities
The average and median time vulnerabilities had existed in the curl source code by the time they were found and reported to the project.
Bugfixes
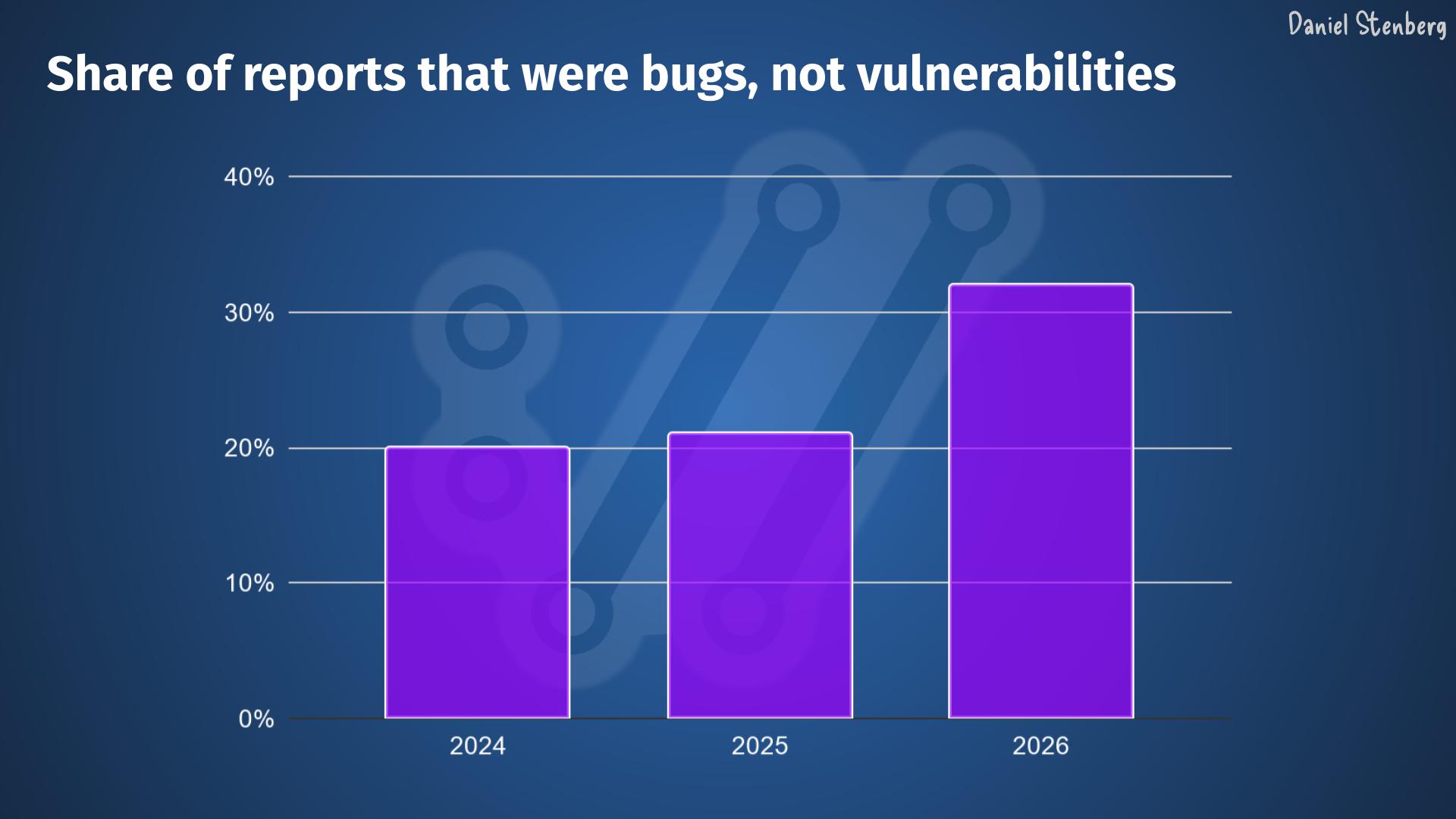
When the tools have found most problems there should be less bugs left to fix. The bugfix rate should go down rapidly – independently of how you count them or how liberal we are in counting exactly what is a bugfix.
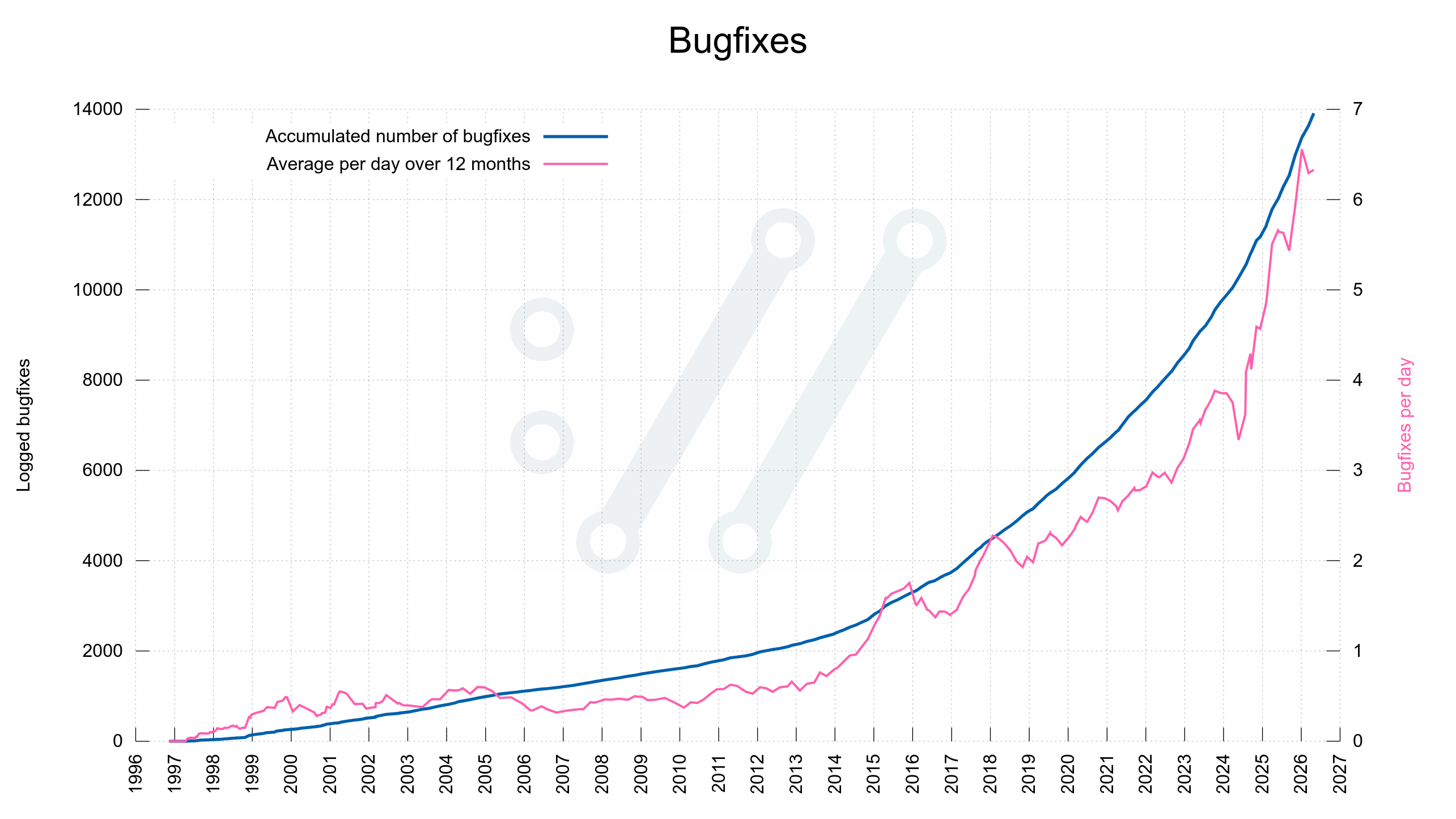
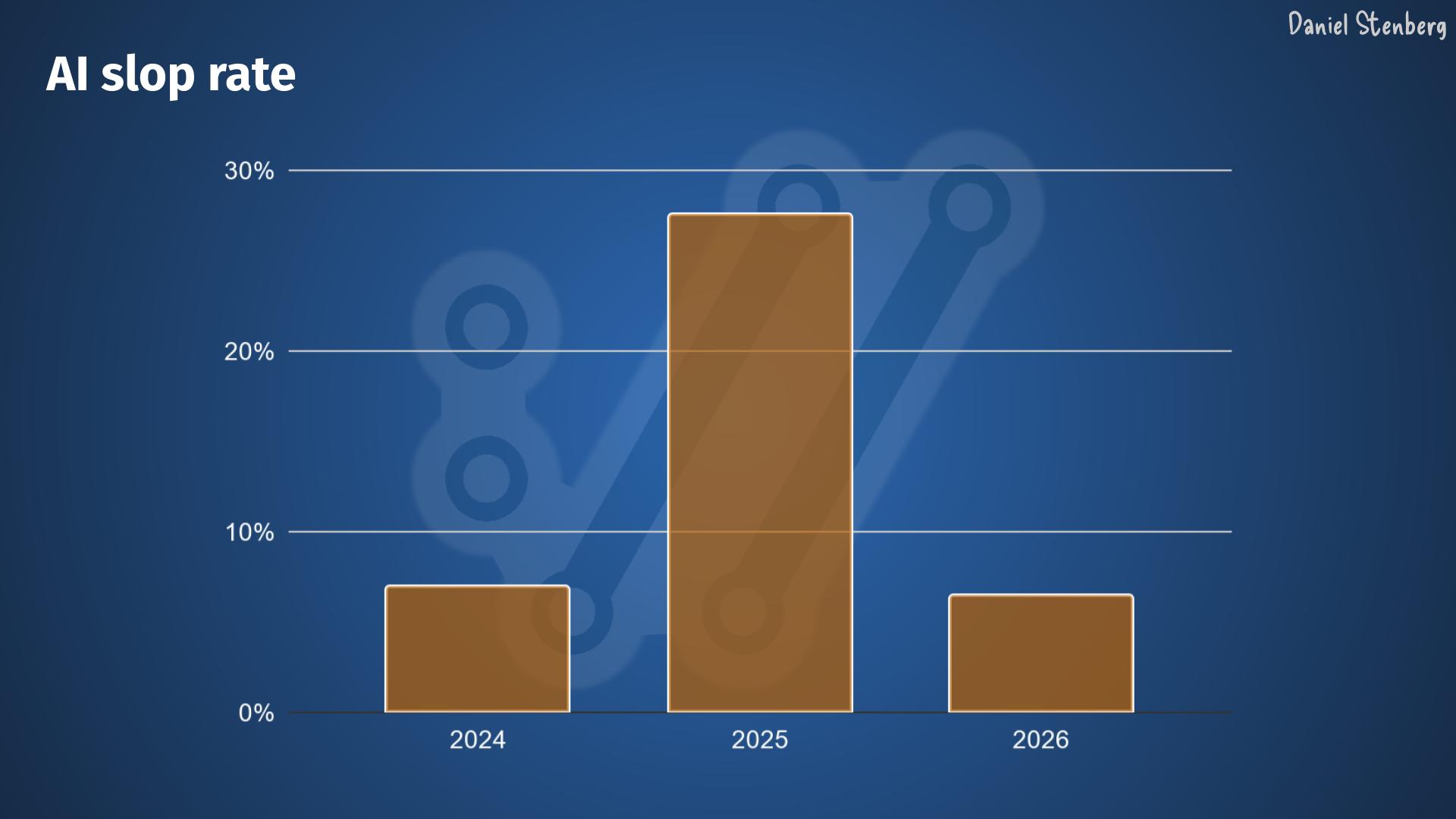
Given the data from the curl project, there does not seem to be fewer bugfixes done – yet. Maybe the bugfix speed goes up before it goes down?
We are not close
Given the look of these graphs I don’t think we are close to zero bugs yet. These two curves do not seem to even start to fall yet.
Yes, these graphs are based on data from a single project, which makes it super weak to draw statistical conclusions from, but this is all I have to work with.
So when?
I think that’s mostly an indication of what you believe the tooling can do and how good they can eventually end up becoming.
I don’t know. I will keep fixing bugs.