On the curl website we of course list exactly what changes that go into each and every single release we do. In recent years I have even gone back and made sure we provide this information for every single release ever done. At the moment that means 258 releases, listing over 10,000 bugfixes and almost 1,000 changes. From 1996 until today.
This is literally a wall of changes.
Since we keep doing somewhere between 150 and 250 bugfixes per release and we do a new release very eight weeks, the page with all changes these keeps growing quite fast.
Right now, the HTML of this page is at 1.1 megabytes.
Use case
Most typically I think the use case for users visiting the changelog is to view what changes that were done in one specific curl release. Possibly checking out a few different ones. Very few users actually want tens of thousands of lines of text to scroll through. I believe.
Enter single release changelogs
To make sure that people can read the changes for a single release only, and to reduce the amount of data a user needs to download in order to view those single release changes, I worked on a setup that generates separate individual changelog pages for every release. Easy to bookmark, load fast, contain only information about the specific releases and they make it easy to skip back and forth between past and future releases.
I deployed these changes today and if you go to https://curl.se/ch/ now, you will see the changelog for the most recent release only.
The all changes changelog remains
The changelog showing everything will remain and is still an option to browse. I personally use it at times when I want to control-f and look for a change done in a previous curl version that I cannot remember exactly which. This all-changes page remains only a click away if you rather view that one instead of the single-version thing.
Design
I am not a web developer and I am not web designer. I know just enough HTML and CSS to be able to publish these things, but I do not do fancy and I am fully aware that I am not good at making “nice” or “attractive” designs. I focus on usable and practical.
As per curl website standards these pages are all static content using no JavaScript and only a few small images. Excellent for rendering fast and for caching well in the CDN.
Known vulnerabilities
I did not especially mention this before, but only a few days ago I added direct links from each version header to the page for known vulnerabilities for that specific version and that link of course is now also present in the single version changelog page. Next to the link that goes directly to the release presentation video.
Screenshot of the changelog page for curl 8.8.0
Feedback?
If you find problems or have ideas on how to further improve the curl website, let us know!
It isn’t actually going away. It’s just been thrown over the fence to the Apache project and Subversion itself to host and maintain going forward.
Mail archive
When the Subversion project started in the early year 2000, I was there. I joined the project and participated in the early days of its development as I really believed in creating an “improved CVS” and I thought I could contribute to it.
While I was involved with the project, I noticed the lack of a decent mailing list archive for the discussions and set one up under the name svn.haxx.se as a service for myself and for the entire community. I had the server and the means to do it, so why not?
After some years I drifted away from the project. It was doing excellently and I was never any significant contributor. Then git and some of the other distributed version control systems came along and in my mind they truly showed the world how version control should be done…
The mailing list archive however I left, and I had even added more subversion related lists to it over time. It kept chugging along without me having to do much. Mails flew in, got archived and were made available for the world to search for and link to. Today it has over 390,000 emails archived from over twenty years of rather active open source development on multiple mailing lists. It is fascinating that no less than 46 persons have written more than a thousand emails each on those lists during these two decades.
Transition complete
The physical machine that runs the website is going to be shut down and taken out of service soon, and instead of just shutting down this service I’ve worked with the good people in the Subversion project and the hosting of that site and archive has now been taken over by the Apache project instead. It is no longer running on my machine. If you discover any issues with it, you need to talk to them.
Today, January 20 2021, I updated the DNS to instead have the host name svn.haxx.se point to Apache’s web server. I believe the plan is to keep the site as an archive of past emails and not add any new emails to it as of now.
I’m out
I hereby sign off my twenty years of service as an svn email archive janitor. It was a pleasure to serve you.
The main physical server (we call it giant) we’ve been using at Haxx for a very long time to host sites and services for 20+ domains and even more mailing lists. The machine – a physical one – has been colocated in an ISP server room for over a decade and has served us very well. It has started to show its age.
Some of the more known sites and services it hosts are perhaps curl, c-ares, libssh2 and this blog (my entire daniel.haxx.se site). Some of these services are however primarily accessed via fronting CDN servers.
giant is a physical Dell PowerEdge 1850 server from 2005, which has undergone upgrades of CPU, disks and memory through the years.
giant featured an Intel X3440 Xeon CPU at 2.53GHz with 8GB of ram when decommissioned.
New host
The new host is of course entirely virtual and we’ve finally taken the step into the modern world of VPSes. The new machine is hosted by the same provider as before but as an entirely new instance.
We’ve upgraded the OS, all packages and we’ve remodeled how we run the web services and all our jobs and services from before have been moved into this new fresh server in an attempt to leave some of the worst legacies behind.
The former server will not be used anymore and will be powered down and sent for recycling.
Glitches in this new world
We’ve tried really hard to make this transition transparent and ideally not many users will notice anything or have a reason to bother about this, but of course we also realize that we probably have not managed this to 100% perfection. If you detect something on any of the services we run that used to work or exist but isn’t anymore, do let us know so that become aware of it and can work on a fix!
This site (daniel.haxx.se) already moved weeks ago and nobody noticed. The curl site changed on October 23 and are much more likely to get glitches because of all the many more scripts and automatic things setup for it. Both sites are served via Fastly so ordinary users will not detect or spot that there’s a new host in the back end.
Mar 31 2020, 11:13:38: I get a message from Frank in the #curl IRC channel over on Freenode. I’m always “hanging out” on IRC and Frank is a long time friend and fellow frequent IRCer in that channel. This time, Frank informs me that the curl web site is acting up:
“I’m getting 403s for some mailing list archive pages. They go away when I reload”
That’s weird and unexpected. An important detail here is that the curl web site is “CDNed” by Fastly. This means that every visitor of the web site is actually going to one of Fastly’s servers and in most cases they get cached content from those servers, and only infrequently do these servers come back to my “origin” server and ask for an updated file to send out to a web site visitor.
A 403 error for a valid page is not a good thing. I started checking out some of my logs – which then only are for the origin as I don’t do any logging at all at CDN level (more about that later) – and I could verify the 403 errors. So they’re in my log meaning it isn’t caused by (a misconfiguration of) the CDN. Why would a perfectly legitimate URL suddenly return 403 to have it go away again after a reload?
Why does he get a 403?
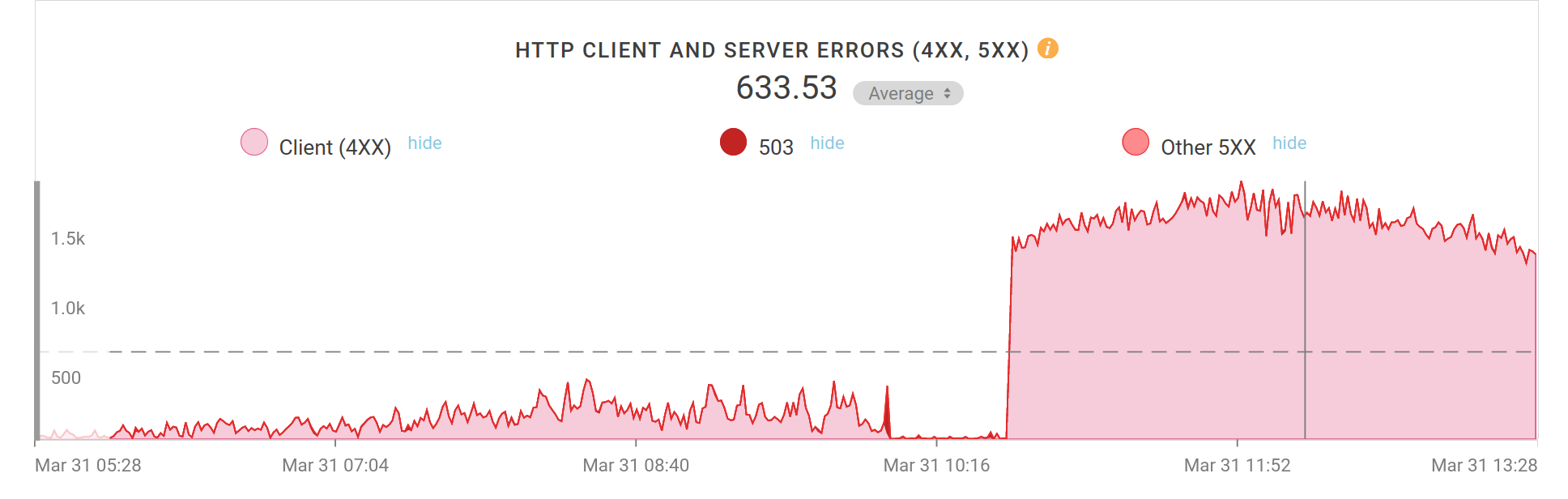
I took a look at Fastly’s management web interface and I spotted that the curl web site was sending out data at an unusual high speed at the moment. An average speed of around 50mbps, while we typically average at below 20. Hm… something is going on.
While I continued to look for the answers to these things I noted that my logs were growing really rapidly. There were POSTs being sent to the same single URL at a high frequency (10-20 reqs/second) and each of those would get some 225Kbytes of data returned. And they all used the same User-agent: QQGameHall. It seems this started within the last 24 hours or so. They’re POSTs so Fastly basically always pass them through to my server.
Before I could figure out Franks’s 403s, I decided to slow down this madness by temporarily forbidding this user-agent access so that the bot or program or whatever would notice it starts to fail, and it would of course then stop bombarding the site.
Deny
Ok, a quick deny of the user-agent made my server start responding with 403s to all those requests and instead of a 225K response it now sent back 465 bytes per request. The average bandwidth on the site immediately dropped down to below 20Mbps again. Back to looking for Frank’s 403-problem
First the 403s seen due to the ratelimiting, then I removed the ratelmiting and finally I added a block of the user-agent. Screenshotted error rates from Fastly’s admin interface. This is errors per minute.
The answer was pretty simple and I didn’t have to search a lot. The clues existed in the error logs and it turned out we had “mod_evasive” enabled since another heavy bot load “attack” a while back. It is a module for “rate limiting” incoming requests and since a lot of requests to our server now comes from Fastly’s limited set of IP addresses and we had this crazy QQ thing hitting us, my server would return a 403 every now and then when it considered the rate too high.
I whitelisted Fastly’s requests and Frank’s 403 problems were solved.
Deny a level up
The bot traffic showed no sign of slowing down. Easily 20 requests per second, to the same URL and they all get an error back and obviously they don’t care. I decided to up my game a little so with help, I moved my blocking of this service to Fastly. I now block their user-agent already there so the traffic doesn’t ever reach my server. Phew, my server was finally back to its regular calm state. They way it should be.
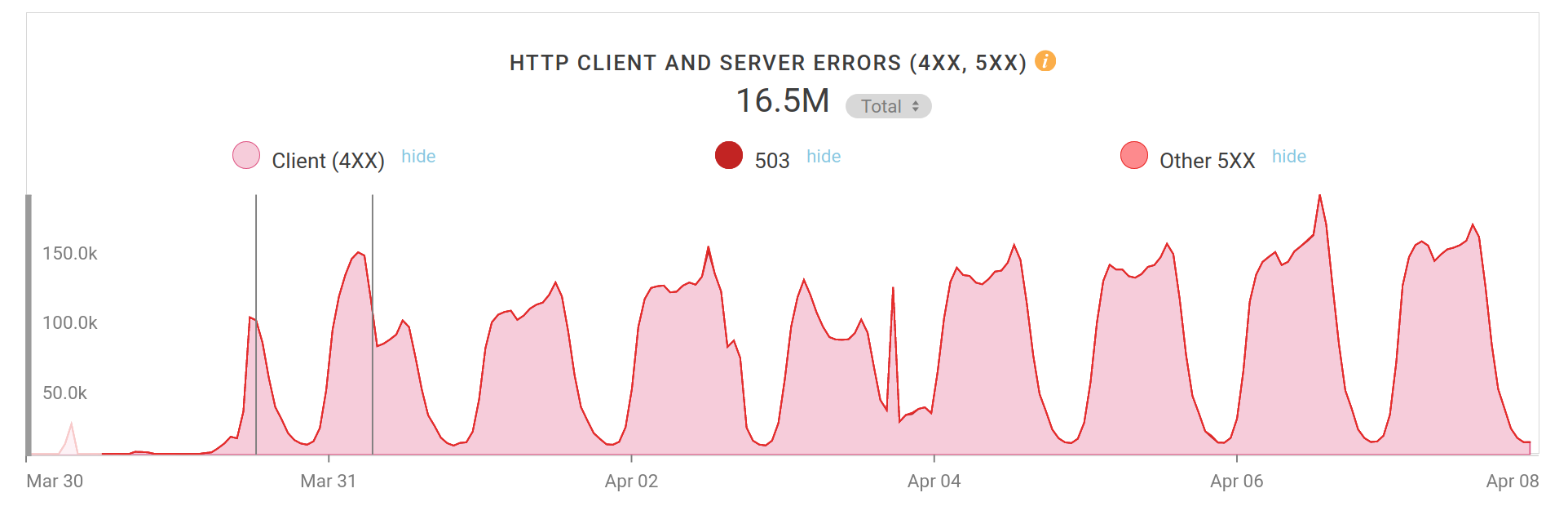
It doesn’t stop there. Here’s a follow-up graph I just grabbed, a little over a week since I started the blocking. 16.5 million blocked requests (and counting). This graph here shows number of requests/hour on the Y axis, peeking at almost 190k; around 50 requests/second. The load is of course not actually a problem, just a nuisance now. QQGameHall keeps on going.
Errors per hour over the period of several days.
QQGameHall
What we know about this.
Friends on Twitter and googling for this name informs us that this is a “game launcher” done by Tencent. I’ve tried to contact them via Twitter (as I have no means of contacting them otherwise that seems even remotely likely to work).
I have not checked what these user-agent POSTs, because I didn’t log that. I suspect it was just a zero byte POST.
The URL they post to is the CA cert bundle file with provide on the curl CA extract web page. The one we convert from the Mozilla version into a PEM for users of the world to enjoy. (Someone seems to enjoy this maybe just a little too much.)
The user-agents seemed to come (mostly) from China which seems to add up. Also, the look of the graph when it goes up and down could indicate an eastern time zone.
This program uses libcurl. Harry in the #curl channel found files in Virus Total and had a look. It is, I think, therefore highly likely that this “storm” is caused by an application using curl!
My theory: this is some sort of service that was deployed, or an upgrade shipped, that wants to get an updated CA store and they get that from our site with this request. Either they get it far too often or maybe there are just a very large amount them or similar. I cannot understand why they issue a POST though. If they would just have done a GET I would never have noticed and they would’ve fetched perfectly fine cached versions from the CDN…
Feel free to speculate further!
Logging, privacy, analytics
I don’t have any logging of the CDN traffic to the curl site. Primarily because I haven’t had to, but also because I appreciate the privacy gain for our users and finally because handling logs at this volume pretty much requires a separate service and they all seem to be fairly pricey – for something I really don’t want. So therefore I don’t see the source IP addresses these things. (But yes, I can ask Fastly to check and tell me if I really really wanted to know.)
Also: I don’t run any analytics (Google or otherwise) on the site, primarily for privacy reasons. So that won’t give me that data or other clues either.
Update: it has been proposed I could see the IP address in the X-Forwarded-For: headers and it seems accurate. Of course I didn’t log that header during this period but I will consider starting doing it for better control and info in the future.
Update 2: As of May 18 2020, this flood has not diminished. Logs show that we still block about 5 million requests/day from this service, peaking at over 100 requests/minute.
In July 2015, 40-something HTTP implementers and experts of the world gathered in the city of Münster, Germany, to discuss nitty gritty details about the HTTP protocol during four intense days. Representatives for major browsers, other well used HTTP tools and the most popular HTTP servers were present. We discussed topics like how HTTP/2 had done so far, what we thought we should fix going forward and even some early blue sky talk about what people could potentially see being subjects to address in a future HTTP/3 protocol.
You can relive the 2015 version somewhat from my daily blog entries from then that include a bunch of details of what we discussed: day one, two,three and four.
The HTTP Workshop was much appreciated by the attendees and it is now about to be repeated. In the summer of 2016, the HTTP Workshop is again taking place in Europe, but this time as a three-day event slightly further up north: in the capital of Sweden and my home town: Stockholm. During 25-27 July 2016, we intend to again dig in deep.
If you feel this is something for you, then please head over to the workshop site and submit your proposal and show your willingness to attend. This year, I’m also joining the Program Committee and I’ve signed up for arranging some of the local stuff required for this to work out logistically.
The HTTP Workshop 2015 was one of my favorite events of last year. I’m now eagerly looking forward to this year’s version. It’ll be great to meet you here!
Speaking the TCP protocol, we communicate between “ports” in the local and remote ends. Each of these port fields are 16 bits in the protocol header so they can hold values between 0 – 65535. (IPv4 or IPv6 are the same here.) We usually do HTTP on port 80 and we do HTTPS on port 443 and so on. We can even play around and use them on various other custom ports when we feel like it.
But what about port 0 (zero) ? Sure, IANA lists the port as “reserved” for TCP and UDP but that’s just a rule in a list of ports, not actually a filter implemented by anyone.
In the actual TCP protocol port 0 is nothing special but just another number. Several people have told me “it is not supposed to be used” or that it is otherwise somehow considered bad to use this port over the internet. I don’t really know where this notion comes from more than that IANA listing.
Frank Gevaerts helped me perform some experiments with TCP port zero on Linux.
In the Berkeley sockets API widely used for doing TCP communications, port zero has a bit of a harder situation. Most of the functions and structs treat zero as just another number so there’s virtually no problem as a client to connect to this port using for example curl. See below for a printout from a test shot.
Running a TCP server on port 0 however, is tricky since the bind() function uses a zero in the port number to mean “pick a random one” (I can only assume this was a mistake done eons ago that can’t be changed). For this test, a little iptables trickery was run so that incoming traffic on TCP port 0 would be redirected to port 80 on the server machine, so that we didn’t have to patch any server code.
Entering a URL with port number zero to Firefox gets this message displayed:
This address uses a network port which is normally used for purposes other than Web browsing. Firefox has canceled the request for your protection.
… but Chrome accepts it and tries to use it as given.
The only little nit that remains when using curl against port 0 is that it seems glibc’s getpeername() assumes this is an illegal port number and refuses to work. I marked that line in curl’s output in red below just to highlight it for you. The actual source code with this check is here. This failure is not lethal for libcurl, it will just have slightly less info but will still continue to work. I claim this is a glibc bug.
$ curl -v http://10.0.0.1:0 -H "Host: 10.0.0.1"
* Rebuilt URL to: http://10.0.0.1:0/
* Hostname was NOT found in DNS cache
* Trying 10.0.0.1... * getpeername() failed with errno 107: Transport endpoint is not connected * Connected to 10.0.0.1 () port 0 (#0)
> GET / HTTP/1.1
> User-Agent: curl/7.38.1-DEV
> Accept: */*
> Host: 10.0.0.1
>
< HTTP/1.1 200 OK
< Date: Fri, 24 Oct 2014 09:08:02 GMT
< Server: Apache/2.4.10 (Debian)
< Last-Modified: Fri, 24 Oct 2014 08:48:34 GMT
< Content-Length: 22
< Content-Type: text/html
<html>testpage</html>
Why doing this experiment? Just for fun to to see if it worked.
Back in the days when I participated in the starting of the Subversion project, I found the mailing list archive we had really dysfunctional and hard to use, so I set up a separate archive for the benefit of everyone who wanted an alternative way to find Subversion related posts.
This archive is still alive and it recently surpassed 370,000 archived emails, all related to Subversion, for seven different mailing lists.
Today I received a notice from Google (shown in its entirety below) that one of the mails received in 2009 is now apparently removed from a search using a name – if done within the European Union at least. It is hard to take this seriously when you look at the page in question, and as there aren’t that very many names involved in that page the possibilities of which name it is aren’t that many. As there are several different mail archives for Subversion mails I can only assume that the alternative search results also have been removed.
This is the first removal I’ve got for any of the sites and contents I host.
Notice of removal from Google Search
Hello,
Due to a request under data protection law in Europe, we are no longer able to show one or more pages from your site in our search results in response to some search queries for names or other personal identifiers. Only results on European versions of Google are affected. No action is required from you.
These pages have not been blocked entirely from our search results, and will continue to appear for queries other than those specified by individuals in the European data protection law requests we have honored. Unfortunately, due to individual privacy concerns, we are not able to disclose which queries have been affected.
Please note that in many cases, the affected queries do not relate to the name of any person mentioned prominently on the page. For example, in some cases, the name may appear only in a comment section.
If you believe Google should be aware of additional information regarding this content that might result in a reversal or other change to this removal action, you can use our form at https://www.google.com/webmasters/tools/eu-privacy-webmaster. Please note that we can’t guarantee responses to submissions to that form.
The following URLs have been affected by this action:
Allow as much as possible and only sanitize what’s absolutely necessary.
That has basically been the rule for the URL parser in curl and libcurl since the project was started in the 90s. The upside with this is that you can use curl to torture your web servers with tests and you can handicraft really imaginary stuff to send and thus subsequently to receive. It kind of assumes that the user truly gives curl a URL the user wants to use.
Why would you give curl a broken URL?
But of course life and internet protocols, and perhaps in particular HTTP, is more involved than that. It soon becomes more complicated.
Redirects
Everyone who’s writing a web user-agent based on RFC 2616 soon faces the fact that redirects based on the Location: header is a source of fun and head-scratching. It is defined in the spec as only allowing “absolute URLs” but the reality is that they were also provided as relative ones by web servers already from the start so the browsers of course support that (and the pending HTTPbis document is already making this clear). curl thus also adopted support for relative URLs, meaning the ability to “merge” or “add” a relative URL onto a previously used absolute one had to be implemented. And even illegally constructed URLs are done this way and in the grand tradition of web browsers, they have not tried to stop users from doing bad things, they have instead adapted and now instead try to convert it to what the user could’ve meant. Like for example using a white space within the URL you send in a Location: header. Even curl has to sanitize that so that it works more like the browsers.
Relative path segments
The path part of URLs are truly to be seen as a path, in that it is a hierarchical scheme where each slash-separated part adds a piece. Like “/first/second/third.html”
As it turns out, you can also include modifiers in the path that have special meanings. Like the “..” (two dots or periods next to each other) known from shells and command lines to mean “one directory level up” can also be used in the path part of a URL like “/one/three/../two/three.html” which equals “/one/two/three.html” when the dotdot sequence is handled. This dot removal procedure is documented in the generic URL specification RFC 3986 (published January 2005) and is completely protocol agnostic. It works like this for HTTP, FTP and every other protocol you provide a path part for.
In its traditional spirit of just accepting and passing along, curl didn’t use to treat “dotdots” in any particular way but handed it over to the server to deal with. There probably aren’t that terribly many such occurrences either so it never really caused any problems or made any users hit any particular walls (or they were too shy to report it); until one day back in February this year… so we finally had to do something about this. Some 8 years after the spec saying it must be done was released.
dotdot removal
Alas, libcurl 7.32.0 now features (once it gets released around August 12th) full traversal and handling of such sequences in the path part of URLs. It also includes single dot sequences like in “/one/./two”. libcurl will detect such uses and convert the path to a sequence without them and continue on. This of course will cause a limited altered behavior for the possible small portion of users out there in the world who would use dotdot sequences and actually want them to get sent as-is the way libcurl has been doing it. I decided against adding an option for disabling this behavior, but of course if someone would experience terrible pain and can reported about it convincingly to us we could possible reconsider that decision in the future.
I suspect (and hope) this will just be another little change along the way that will make libcurl act more standard and more like the browsers and thus cause less problems to users but without people much having to care about how or why.
Further reading: the dotdot.c file from the libcurl source tree!
Bonus kit
A dot to dot surprise drawing for you and your kids (click for higher resolution)
First, allow me to mention that I like FSCONS. I’ve been there several years, I’ve spoken there every year I’ve been there and I know and like a bunch of the persons in the team putting it together. Good stuff!
I wasn’t supposed to do any talk at FSCONS this year, and I did feel a little empty and lost because of it.
… then an empty slot appeared, a question was asked, a subject was suggested and suddenly I ended up having agreed to do a talk and the void has been filled again. I’m glad. I hope someone else will be too and I will try to excite the audience with a talk titled “SPDY: An experimental protocol for a faster web” or something like that. It will have to do for now. It is currently planned to take place at 17:15 on Saturday 12th of November.
My thinking is to explain SPDY in detail, explain the reasoning behind it, the problems that have lead up to its creation and I’ll try to shed the lights on the alternatives and make some guesses what I think the future will hold in terms of web transports and what we will NOT see… I might even manage to acquire further insights of this from my ventures into libspdy.
If you have any related thoughts or questions, feel free to ask me ahead of time and I might be able to adjust my talk for it.