
The purpose of the curl web site is to inform the world about what curl and libcurl are and provide as much information as possible about the project, the products and everything related to that.
The web site has existed in some form for as long as the project has, but it has of course developed and changed over time.
Independent
The curl project is completely independent and stands free from influence from any parent or umbrella organization or company. It is not even a legal entity, just a bunch of random people cooperating over the Internet. And a bunch of awesome sponsors to help us.
This means that we have no one that provides the infrastructure or marketing for us. We need to provide, run and care for our own servers and anything else we think we should offer our users.
I still do a lot of the work in curl and the curl web site and I work full time on curl, for wolfSSL. This might of course “taint” my opinions and views on matters, but doesn’t imply ownership or control. I’m sure we’re all colored by where we work and where we are in our lives right now.
Contents
Most of the web site is static content: generated HTML pages. They are served super-fast and very lightweight by any web server software.
The web site source exists in the curl-www repository (hosted on GitHub) and the web site syncs itself with the latest repository changes several times per hour. The parts of the site that aren’t static are mostly consisting of smaller scripts that run either on demand at the time of a request or on an interval in a cronjob in the background. That is part of the reason why pushing an update to the web site’s repository can take a little while until it shows up on the live site.
There’s a deliberate effort at not duplicating information so a lot of the web pages you can find on the web site are files that are converted and “HTMLified” from the source code git repository.
“Design”
Some people say the curl web site is “retro”, others that it is plain ugly. My main focus with the site is to provide and offer all the info, and have it be accurate and accessible. The look and the design of the web site is a constant battle, as nobody who’s involved in editing or polishing the web site is really interested in or particularly good at design, looks or UX. I personally have done most of the editing of it, including CSS etc and I can tell you that I’m not good at it and I don’t enjoy it. I do it because I feel I have to.
I get occasional offers to “redesign” the web site, but the general problem is that those offers almost always involve rebuilding the entire thing using some current web framework, not just fixing the looks, layout or hierarchy. By replacing everything like that we’d get a lot of problems to get the existing information in there – and again, the information is more important than the looks.
The curl logo is designed by a proper designer however (Adrian Burcea).
If you want to help out designing and improving the web site, you’d be most welcome!
Who
I’ve already touched on it: the web site is mostly available in git so “anyone” can submit issues and pull-requests to improve it, and we are around twenty persons who have push rights that can then make a change on the live site. In reality of course we are not that many who work on the site any ordinary month, or even year. During the last twelve month period, 10 persons authored commits in the web repository and I did 90% of those.
How
Technically, we build the site with traditional makefiles and we generate the web contents mostly by preprocessing files using a C-like preprocessor called fcpp. This is an old and rather crude setup that we’ve used for over twenty years but it’s functional and it allows us to have a mostly static web site that is also fairly easy to build locally so that we can work out and check improvements before we push them to the git repository and then out to the world.
The web site is of course only available over HTTPS.
Hosting
The curl web site is hosted on an origin VPS server in Sweden. The machine is maintained by primarily by me and is paid for by Haxx. The exact hosting is not terribly important because users don’t really interact with our server directly… (Also, as they’re not sponsors we’re just ordinary customers so I won’t mention their name here.)
CDN
A few years ago we experienced repeated server outages simply because our own infrastructure did not handle the load very well, and in particular not the traffic spikes that could occur when I would post a blog post that would suddenly reach a wide audience.
Enter Fastly. Now, when you go to curl.se (or daniel.haxx.se) you don’t actually reach the origin server we admin, you will instead reach one of Fastly’s servers that are distributed across the world. They then fetch the web contents from our origin, cache it on their edge servers and send it to you when you browse the site. This way, your client speaks to a server that is likely (much) closer to you than the origin server is and you’ll get the content faster and experience a “snappier” web site. And our server only gets a tiny fraction of the load.
Technically, this is achieved by the name curl.se resolving to a number of IP addresses that are anycasted. Right now, that’s 4 IPv4 addresses and 4 IPv6 addresses.
The fact that the CDN servers cache content “a while” is another explanation to why updated contents take a little while to “take effect” for all visitors.
DNS
When we just recently switched the site over to curl.se, we also adjusted how we handle DNS.

I run our own main DNS server where I control and admin the zone and the contents of it. We then have four secondary servers to help us really up our reliability. Out of those four secondaries, three are sponsored by Kirei and are anycasted. They should be both fast and reliable for most of the world.
With the help of fabulous friends like Fastly and Kirei, we hope that the curl web site and services shall remain stable and available.
DNS enthusiasts have remarked that we don’t do DNSSEC or registry-lock on the curl.se domain. I think we have reason to consider and possibly remedy that going forward.
Traffic
The curl web site is just the home of our little open source project. Most users out there in the world who run and use curl or libcurl will not download it from us. Most curl users get their software installation from their Linux distribution or operating system provider. The git repository and all issues and pull-requests are done on GitHub.
Relevant here is that we have no logging and we run no ads or any analytics. We do this for maximum user privacy and partly because of laziness, since handling logging from the CDN system is work. Therefore, I only have aggregated statistics.
In this autumn of 2020, over a normal 30 day period, the web site serves almost 11 TB of data to 360 million HTTP requests. The traffic volume is up from 3.5 TB the same time last year. 11 terabytes per 30 days equals about 4 megabytes per second on average.
Without logs we cannot know what people are downloading – but we can guess! We know that the CA cert bundle is popular and we also know that in today’s world of containers and CI systems, a lot of things out there will download the same packages repeatedly. Otherwise the web site is mostly consisting of text and very small images.
One interesting specific pattern on the server load that’s been going on for months: every morning at 05:30 UTC, the site gets over 50,000 requests within that single minute, during which 10 gigabytes of data is downloaded. The clients are distributed world wide as I see the same pattern on access points all over. The minute before and the minute after, the average traffic rate remains at 200MB/minute. It makes for a fun graph:
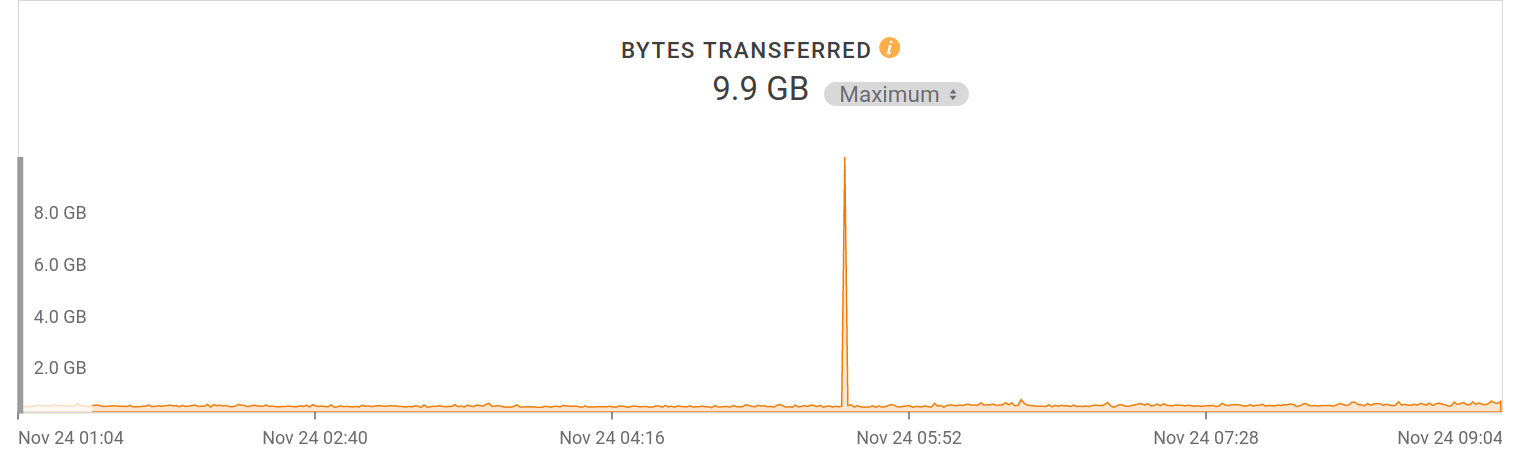
Our servers suffer somewhat from being the target of weird clients like qqgamehall that continuously “hammer” the site with requests at a high frequency many months after we started always returning error to them. An effect they have is that they make the admin dashboard to constantly show a very high error rate.
Software
The origin server runs Debian Linux and Apache httpd. It has a reverse proxy based on nginx. The DNS server is bind. The entire web site is built with free and open source. Primarily: fcpp, make, roffit, perl, curl, hypermail and enscript.
If you curl the curl site, you can see in response headers that Fastly uses Varnish.