The other day we celebrated everything curlturning 5 years old, and not too long after that I got myself this printed copy of the Chinese translation in my hands!
If you would be interested in starting a translation of the book into another language, let me know and I’ll help you get started. Currently the English version consists of 72,798 words so it’s by no means an easy feat to translate! My other two other smaller books, http2 explained and HTTP/3 explained have been translated into twelve(!) and ten languages this way (and there might be more languages coming!).
A collection of printed works authored by yours truly!Inside the Chinese version – yes I can understand some headlines!
Unfortunately I don’t read Chinese so I can’t tell you how good the translation is!
I started learning how to program in my teens, well over thirty years ago and I’ve worked as a software engineer and developer since the early 1990s. My first employment as a developer was in 1993. I’ve since worked for and with lots of companies and I’ve worked on a huge amount of (proprietary) software products and devices over many years. Meaning: I certainly didn’t start my life open source. I had to earn it.
When I was 20 years old I did my (then mandatory) military service in Sweden. After having endured that, I applied to the university while at the same time I was offered a job at IBM. I hesitated, but took the job. I figured I could always go to university later – but life took other turns and I never did. I didn’t do a single day of university. I haven’t regretted it.
I learned to code in the mid 80s on a Commodore 64 and software development has been one of my primary hobbies ever since. One thing it taught me well, that I still carry with me, is to spend a few hours per day in front of my home computer.
And then I shipped curl
In the spring of 1998 I renamed my little pet project of the time again and I released the first ever curl release. I have told this story many times, but since then I have spent two hours or so of my spare time on that project – every day for over twenty years. While still working as a software engineer by day.
Over time, curl gradually grew popular and attracted more users. There was no sudden moment in time where I struck gold and everything took off. It was just slowly gaining ground while me and my fellow project members kept improving and polishing curl. At some point in time I happened to notice that curl and libcurl would appear in more and more acknowledgements and in open source license collections in products and devices.
It was still just a spare time project.
Proprietary Software for years
I’d like to emphasize that I worked as a contract and consultant developer for many years (over 20!), primarily on proprietary software and custom solutions, before I managed to land myself a position where I could primarily write open source as part of my job.
Mozilla
In 2014 I joined Mozilla and got the opportunity to work on the open source project Firefox for a living – and doing it entirely from my home. This was the first time in my career I actually spent most of my days on code that was made public and available to the world. They even allowed me to spend a part of my work hours on curl, even if that didn’t really help them and curl was not a fundamental part of any Mozilla work or products. It was still great.
I landed that job for Mozilla a lot thanks to my many years and long experience with portable network coding and running a successful open source project at this level.
My work setup with Mozilla made it possible for me to spend even more time on curl, apart from the (still going) two daily spare time hours. Nobody at Mozilla cared much about (my work with) curl and no one there even asked me about it. I worked on Firefox for a living.
For anyone wanting to do open source as part of their work, getting a job at a company that already does a lot of open source is probably the best path forward. Even if that might not be easy either, and it might also mean that you would have to accept working on some open source projects that you might not yourself be completely sold on.
In late 2018 I quit Mozilla, in part because I wanted to try to work with curl “for real” (and part other reasons that I’ll leave out here). curl was then already over twenty years old and was used more than ever before.
wolfSSL
I now work for wolfSSL. We sell curl support and related services to companies. Companies pay wolfSSL, wolfSSL pays me a salary and I get food on the table. This works as long as we can convince enough companies that this is a good idea.
The vast majority of curl users out there of course don’t pay anything and will never pay anything. We just need a small number of companies to do it – and it seems to be working. We help customers use curl better, we make curl better for them and we make them ship better products this way. It’s a win win. And I can work on open source all day long thanks to this.
My open source life-style
A normal day in the work week, I get up before 7 in the morning and I have breakfast with my family members: my wife and my two kids. Then I grab my first cup of coffee for the day and take the thirteen steps up the stairs to my “office”.
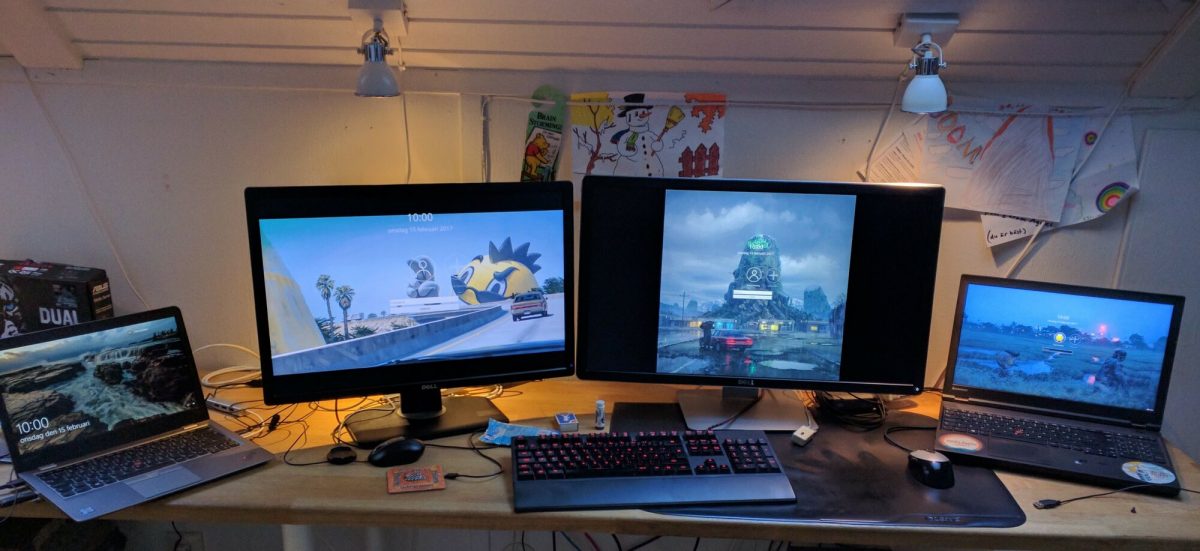
I sit down in front of my main development (Linux) machine with two 27″ screens and get to work.
Photo of my work desk from a few years ago but it looks very similar still today.
What work and in what order?
I lead the curl project. It means many questions and decisions fall down to me to have an opinion about or say on, and it’s a priority for me to make sure that I unblock such situations as soon as possible so that developers wanting to do things with curl can continue doing that.
Thus, I read and respond to email about curl all hours I’m awake and have network access. Of course incoming messages actually rarely require immediate responses and then I can queue them up and instead do them later. I also try to read and assess all new incoming curl issues as soon as possible to see if there’s something urgent I should deal with immediately, or otherwise figure out how to deal with them going forward.
I usually have a set of bugs or features to work on so when there’s no alarming email or GitHub issue left, I context-switch over to the curl source code tree and the particular branch in which I work on right now. I typically have 20-30 different branches of development of various stages and maturity going on. If I get stuck on something, or if I create a pull-request for one of them that needs time to get all the CI jobs done, I switch over to one of the others.
Customers and their needs of course have priority when I decide what to work on. The exception would perhaps be security vulnerabilities or other really serious bugs being reported, but thankfully they are rare. But after that, I go by ear and work on what I think is fun and what I think users might appreciate.
If I want to go forward with something, for my own sake or for a customer’s, and that entails touching or improving other software in other projects, then I don’t shy away from submitting pull requests for them – or at least filing an issue.
Spare time open source
Yes, I still spend my spare time hours on open source, mostly curl. This means I often end up spending 50-55 hours per week on curl and curl related activities. But I don’t count or measure work hours and I rarely have to report any to anyone. This is a work of love.
Lots of people will say that they don’t have time because of life, family, kids etc. I have of course been very fortunate over the years to have had the opportunity and ability to spend all this time on what I want to do, but let’s not forget that people in general spend lots of time on their hobbies; on watching TV, on playing computer games and on socializing with friends and why not: to sleep. If you cut down on all of those things (yes, including the sleeping) there could very well be opportunities. It’s often a question of priorities. I’ve made spare time development a priority in my life.
curl support?
Any company that uses curl or libcurl – and they are plenty – could benefit from buying support from us instead of wasting their own time and resources. We at wolfSSL are probably much better at curl already and we can find and fix the issues much faster, which ends up cheaper and better long-term.
Credits
The top photo is taken by Anja Stenberg, my wife. It’s me in a local forest, summer 2020.
The main physical server (we call it giant) we’ve been using at Haxx for a very long time to host sites and services for 20+ domains and even more mailing lists. The machine – a physical one – has been colocated in an ISP server room for over a decade and has served us very well. It has started to show its age.
Some of the more known sites and services it hosts are perhaps curl, c-ares, libssh2 and this blog (my entire daniel.haxx.se site). Some of these services are however primarily accessed via fronting CDN servers.
giant is a physical Dell PowerEdge 1850 server from 2005, which has undergone upgrades of CPU, disks and memory through the years.
giant featured an Intel X3440 Xeon CPU at 2.53GHz with 8GB of ram when decommissioned.
New host
The new host is of course entirely virtual and we’ve finally taken the step into the modern world of VPSes. The new machine is hosted by the same provider as before but as an entirely new instance.
We’ve upgraded the OS, all packages and we’ve remodeled how we run the web services and all our jobs and services from before have been moved into this new fresh server in an attempt to leave some of the worst legacies behind.
The former server will not be used anymore and will be powered down and sent for recycling.
Glitches in this new world
We’ve tried really hard to make this transition transparent and ideally not many users will notice anything or have a reason to bother about this, but of course we also realize that we probably have not managed this to 100% perfection. If you detect something on any of the services we run that used to work or exist but isn’t anymore, do let us know so that become aware of it and can work on a fix!
This site (daniel.haxx.se) already moved weeks ago and nobody noticed. The curl site changed on October 23 and are much more likely to get glitches because of all the many more scripts and automatic things setup for it. Both sites are served via Fastly so ordinary users will not detect or spot that there’s a new host in the back end.
Today, exactly three years ago, I received flowers, money and a gold medal at a grand prize ceremony that will forever live on in my mind and memory. I was awarded the Polhem Prize for my decades of work on curl. The prize itself was handed over to me by no one else than the Swedish king himself. One of the absolute top honors I can imagine in my little home country.
In some aspects, my life is divided into the life before this event and the life after. The prize has even made little me being presented on a poster in the Technical Museum in Stockholm. The medal itself still sits on my work desk and if I just stop starring at my monitors for a moment and glance a little over to the left – I can see it. I think the prize made my surroundings, my family and friends get a slightly different view and realization of what I actually do all these hours in front of my screens.
In the tree years since I received the prize, we’ve increased the total number of contributors and authors in curl by 50%. We’ve done over 3,700 commits and 25 releases since then. Upwards and onward.
Life moved on. It was not “peak curl”. There was no “prize curse” that left us unable to keep up the pace and development. It was possibly a “peak life moment” there for me personally. As an open source maintainer, I can’t imagine many bigger honors or awards to come my way ever again, but I’m not complaining. I got the prize and I still smile when I think about it.
In international curling competitions, each team is given 73 minutes to complete all of its throws. Welcome to curl 7.73.0.
Release presentation
Numbers
the 195th release 9 changes 56 days (total: 8,2XX) 135 bug fixes (total: 6,462) 238 commits (total: 26,316) 3 new public libcurl function (total: 85) 1 new curl_easy_setopt() option (total: 278) 2 new curl command line option (total: 234) 63 contributors, 31 new (total: 2,270) 35 authors, 17 new (total: 836) 0 security fix (total: 95) 0 USD paid in Bug Bounties(total: 2,800 USD)
Changes
We have to look back almost two years to find a previous release packed with more new features than this! The nine changes we’re bringing to the world this time are…
--output-dir
Tell curl where to store the file when you use -o or -O! Requested by users for a long time. Now available!
find .curlrc in $XDG_CONFIG_HOME
If this environment variable is set and there’s a .curlrc in there, it will now be used in preference to the other places curl will look for it.
--help has categories
The huge wall of text that --help previously gave us is now history. “curl --help” will now only show a few important options and the rest is provided if you tell curl which category you want to list help for. Requested by users for a long time.
API for meta-data about easy options
With three new functions, libcurl now provides an API for getting meta-data and information about all existing easy options that an application (possibly via a binding) can set for a transfer in libcurl.
CURLE_PROXY
We’ve introduced a new error code, and what makes this a little extra note-worthy besides just being a new way to signal a particular error, is that applications that receive this error code can also query libcurl for extended error information about what exactly in the proxy use or handshake that failed. The extended explanation is extracted with the new CURLINFO_PROXY_ERROR.
MQTT by default
This is the first curl release where MQTT support is enabled by default. We’ve had it marked experimental for a while, which had the effect that virtually nobody actually used it, tried it or even knew it existed. I’m very eager to get some actual feedback on this…
SFTP commands: atime and mtime
The “quote” functionality in curl which can sends custom commands to the SFTP server to perform various instructions now also supports atime and mtime for setting the access and modification times of a remote file.
knownhosts “fine replace” instruction
The “known hosts” feature is a SSH “thing” that lets an application get told if libcurl connects to a host that isn’t already listed in the known hosts file and what to do about it. This new feature lets the application return CURLKHSTAT_FINE_REPLACE which makes libcurl treat the host as “fine” and it will then replace the host key for that host in the known hosts file.
Elliptic curves
Assuming you use the supported backend, you can now select which curves libcurl should use in the TLS handshake, with CURLOPT_SSL_EC_CURVES for libcurl applications and with --curves for the command line tool.
Bug-fixes
As always, here follows a small selection of the many bug-fixes done this cycle.
buildconf: invoke ‘autoreconf -fi’ instead
Born in May 2001, this script was introduced to build configure etc so that you can run configure etc, when you’re building code straight from git (even if it was CVS back in 2001).
Starting now, the script just runs ‘autoreconf -fi‘ and no extra custom magic is needed.
checksrc: now even stricter
Our homegrown code style checker got better and now also verifies:
Mandatory space after do and before while in “do { } while“
No space allowed after an exclamation mark in if(!true) expressions
// comments are not allowed even on column 0
cmake: remove scary warning
The text that was previously output, saying that the cmake build has glitches has been removed. Not really because it has gotten much better, but to not scare people away, let them proceed and use cmake and then report problems and submit pull requests that fix them!
curl: lots of dynbuf in the tool
The libcurl internal system for doing “dynamic buffers” (strings) is now also used by the curl tool and a lot of custom realloc logic has been converted over.
curl: retry and delays in parallel mode
The --retry option didn’t work when doing parallel transfers, and when fixed, the retry delay option didn’t work either so that was also fixed!
etag: save and use the full received contents
We changed the handling of saving and loading etags a little bit, so that it now stores and loads the full etag contents and not just the bytes between double quotes. This has the added benefit that the etag functionality now also works with weak etags and when working with servers that don’t really follow the syntax rules for etags.
ftp: a 550 SIZE response returns CURLE_REMOTE_FILE_NOT_FOUND
Getting a 550 response back from a SIZE command will now make curl return at once saying the file is missing. Previously it would put that into the generic “SIZE doesn’t work” pool of errors, but that could lead to some inconsistent return codes.
ftp: make a 552 response return CURLE_REMOTE_DISK_FULL
Turns out that when uploading data to an FTP server, there’s a dedicated response code for the server to tell the client when the disk system is full (there was not room enough to store the file) and since there was also an existing libcurl return code for it, this new mapping thus made perfect sense…
ftp: separate FTPS from FTP over “HTTPS proxy”
The FTP code would previously wrongly consider a HTTPS proxy to euqal *using TLS” as if it was using TLS for its control channel, which made it wrongly use commands that are reserved for TLS connections.
libssh2: SSH protocols over HTTPS proxy
Some adjustments were necessary to make sure the SCP and SFTP work when spoken over an HTTPS proxy. Also note that this fix is only done for the libssh2 backend (primarily because I didn’t find out to do it in the others when I did a quick check).
pingpong: use dynbuf sending commands
I blogged about this malloc reducing adventure separately. The command sending function in curl for FTP, IMAP, POP3 and SMTP now reuses the same memory buffer much better over a transfer’s lifetime.
runtests: add %repeat[]% and %hex[]hex% for test files
One of the really nice benefits of “preprocessing” the text files and generate another file that is actually used for running tests, is that we now can provide meta-instructions to generate content when the test starts up. For example, we had tests that had a megabyte or several hundred kilobytes of text for test purposes, and how we can replace those with just a single %repeat% instruction. Makes test cases much smaller and much easier to read. %hex% can generate binary output given a hex string.
runtests: curl’s version as %VERSION
The test suite now knows which version of curl it tests, which means it can properly verify the User-Agent: headers in curl’s outgoing HTTP requests. We’ve previously had a filter system that would filter out such headers before comparing. Yours truly then got the pleasure of updating no less than 619 test cases to longer filter off that header for the comparison and instead use %VERSION!
win32: drop support for WinSock version 1
Apparently version 2 has been supported in Windows since Windows 95…
Future
Unless we’ve screwed up somewhere, the next release will be 7.74.0 and ship on December 9, 2020. We have several pending pull-requests already in the queue with new features and changes!
tldr: work has started to make Hyper work as a backend in curl for HTTP.
curl and its data transfer core, libcurl, is all written in C. The language C is known and infamous for not being memory safe and for being easy to mess up and as a result accidentally cause security problems.
At the same time, C compilers are very widely used and available and you can compile C programs for virtually every operating system and CPU out there. A C program can be made far more portable than code written in just about any other programming language.
curl is a piece of “insecure” C code installed in some ten billion installations world-wide. I’m saying insecure within quotes because I don’t think curl is insecure. We have our share of security vulnerabilities of course, even if I think the rate of them getting found has been drastically reduced over the last few years, but we have never had a critical one and with the help of busloads of tools and humans we find and fix most issues in the code before they ever land in the hands of users. (And “memory safety” is not the single explanation for getting security issues.)
I believe that curl and libcurl will remain in wide use for a long time ahead: curl is an established component and companion in scripts and setups everywhere. libcurl is almost a de facto standard in places for doing internet transfers.
A rewrite of curl to another language is not considered. Porting an old, established and well-used code base such as libcurl, which to a far degree has gained its popularity and spread due to a stable API, not breaking the ABI and not changing behavior of existing functionality, is a massive and daunting task. To the degree that so far it hasn’t been attempted seriously and even giant corporations who have considered it, have backpedaled such ideas.
Change, but not change
This preface above might make it seem like we’re stuck with exactly what we have for as long as curl and libcurl are used. But fear not: things are more complicated, or perhaps brighter, than it first seems.
What’s important to users of libcurl needs to be kept intact. We keep the API, the ABI, the behavior and all the documented options and features remain. We also need to continuously add stuff and keep up with the world going forward.
But we can change the internals! Refactor as the kids say.
Backends, backends, backends
Already today, you can build libcurl to use different “backends” for TLS, SSH, name resolving, LDAP, IDN, GSSAPI and HTTP/3.
A “backend” in this context is a piece of code in curl that lets you use a particular solution, often involving a specific third party library, for a certain libcurl functionality. Using this setup you can, for example, opt to build libcurl with one or more out of thirteen different TLS libraries. You simply pick the one(s) you prefer when you build it. The libcurl API remains the same to users, it’s just that some features and functionality might differ a bit. The number of TLS backends is of course also fluid over time as we add support for more libraries in the future, or even drop support for old ones as they fade away.
When building curl, you can right now make it use up to 33 different third party libraries for different functions. Many of them of course mutually exclusive, so no single build can use all 33.
Said differently: you can improve your curl and libcurl binaries without changing any code, by simply rebuilding it to use another backend combination.
Green boxes are possible third-party dependencies curl can be told to use. No Hyper in this map yet…
libcurl as a glorified switch
With an extensive set of backends that use third party libraries, the job of libcurl to a large extent becomes to act as a switch between the provided stable external API and the particular third party library that does the heavy lifting.
API <=> glue code in C <=> backend library
libcurl as the rock, with a door and the entry rules written in stone. The backends can come and go, change and improve, but the applications outside the entrance won’t notice that. They get a stable API and ABI that they know and trust.
Safe backends
This setup provides a foundation and infrastructure to offer backends written in other languages as part of the package. As long as those libraries have APIs that are accessible to libcurl, libraries used by the backends can be written in any language – but since we’re talking about memory safety in this blog post the most obvious choices would probably be one of the modern and safe languages. For example Rust.
With a backend library written in Rust , libcurl would lean on such a component to do low level protocol work and presumably, by doing this it increases the chances of the implementations to be safe and secure.
Two of the already supported third party libraries in the world map image above are written in Rust: quiche and Mesalink.
Hyper as a backend for HTTP
Hyper is a HTTP library written in Rust. It is meant to be fast, accurate and safe, and it supports both HTTP/1 and HTTP/2.
As another step into this world of an ever-growing number of backends to libcurl, work has begun to make sure curl (optionally) can get built to use Hyper.
This work is gracefully funded by ISRG, perhaps mostly known as the organization behind Let’s Encrypt. Thanks!
Many challenges remain
I want to emphasize that this is early days. We know what we want to do, we know basically how to do it but from there to actually getting it done and providing it in source code to the world is a little bit of work that hasn’t been done. I’m set out to do it.
Hyper didn’t have a C API, they’re working on making one so that C based applications such as curl can actually use it. I do my best at providing feedback from my point of view, but as I’m not really into Rust much I can’t assist much with the implementation parts there.
Once there’s an early/alpha version of the API to try out, I will first make sure curl can get built to use Hyper, and then start poking on the code to start using it.
In that work I expect me to have to go back to the API with questions, feedback and perhaps documentation suggestions. I also anticipate challenges in switching libcurl internals to using this. Mostly small ones, but possibly also larger ones.
I have created a git branch and make my work on this public and accessible early on to let everyone who wants to, to keep up with the development. A first milestone will be the ability to run a single curl test case (any test case) successfully – unmodified. The branch is here: https://github.com/curl/curl/tree/bagder/hyper – beware that it will be rebased frequently.
There’s no deadline for this project and I don’t yet have any guesses as when there will be anything to test.
Rust itself is not there yet
This project is truly ground work for future developers to build upon as some of the issues dealt with in here should benefit others as well down the road. For example it immediately became obvious that Rust in general encourages to abort on out-of-memory issues, while this is a big nono when the code is used in a system library (such as curl).
I’m a bit vague on the details here because it’s not my expertise, but Rust itself can’t even properly clean up its memory and just returns error when it hits such a condition. Clearly something to fix before a libcurl with hyper could claim identical behavior and never to leak memory.
By default?
Will Hyper be used by default in a future curl build near you?
We’re going to work on the project to make that future a possibility with the mindset that it could benefit users.
If it truly happens involve many different factors (for example maturity, feature set, memory footprint, performance, portability and on-disk footprint…) and in particular it will depend a lot on the people that build and ship the curl packages you use – which isn’t the curl project itself as we only ship source code. I’m thinking of Linux and operating system distributions etc.
When it might happen we can’t tell yet as we’re still much too early in this process.
Still a lot of C
This is not converting curl to Rust.
Don’t be fooled into believing that we are getting rid of C in curl by taking this step. With the introduction of a Hyper powered backend, we will certainly reduce the share of C code that is executed in a typical HTTP transfer by a measurable amount (for those builds), but curl is much more than that.
It’s not even a given that the Hyper backend will “win” the competition for users against the C implementation on the platforms you care about. The future is not set.
More backends in safe languages?
Sure, why not? There are efforts to provide more backends written in Rust. Gradually, we might move into a future where less and less of the final curl and libcurl executable code was compiled from C.
How and if that will happen will of course depend on a lot of factors – in particular funding of the necessary work.
Can we drive the development in this direction even further? I think it is much too early to speculate on that. Let’s first see how these first few episodes into the coming decades turn out.