RFC 10008 is brand new a specification detailing the new HTTP method called QUERY:
This specification defines the QUERY method for HTTP. A QUERY requests that the request target process the enclosed content in a safe and idempotent manner and then respond with the result of that processing. This is similar to POST requests but can be automatically repeated or restarted without concern for partial state changes
A GET with body
For all practical purposes you can think of QUERY as a way to send a GET with a body. It looks exactly like POST, but done with another verb.
Contrary to POST, QUERY requests are idempotent – they can be retried or repeated when needed, for instance after a connection failure.
curl it
You can use curl to do HTTP requests with QUERY just fine. curl offers the --request option (also known as -X in the short form) that you can use like this:
curl -d "data to send" -X QUERY https://example.com/
But redirects!
There is one little caveat to remember with this curl option that changes the method. When also asking curl to follow any possible redirects, it is important that you use a new enough curl version because you want the --follow option. Not the old --location/-L one.
Why? Because the old option changes the HTTP method on all subsequent requests independently of what the server responds, which in many cases is not what you want.
The newer --follow option instead acts according to what the HTTP response code suggests in should do. Stick to the same method again, or maybe switch to GET in the following request.
Why?
Why or when would you use this? First of course you only want to use this if the server supports it, but the spec offers some reasons why this might be a good choice:
avoid or circumvent URL size limits. Somewhere around 8000 bytes they start to no longer work reliably because servers and intermediaries set limits.
expressing certain kinds of data in the URL is inefficient because encoding overhead
URLs are more likely to be logged than request content
The security email address will also be a dead end, as we will not process or otherwise care about security or vulnerability reports sent to us that way either.
Whatever issue you find that you feel a need to report to the curl project during this month has to wait. curl’s Hackerone form opens for submissions again on Monday August 3.
We do not accept vulnerability reports over email in general, and this fact remains during and after our vacation.
Vacation for real
The curl maintainers will use this time of less pressure to take in some extra air and to enjoy the summer. Maybe stroll outside a bit more. Breath. Some of us may spend some of this time to see other places.
We may get some extra time to spend on fixing bugs or working on new code. Fun stuff!
Side-effects
As a direct side-effect of this summer of bliss, to allow us some more time to handle the issues that might have piled up for us in early August, we also push the release date of 8.22.0 two weeks into the future. Now scheduled to happen on September 2, 2026.
Vulnerability rate
As previously mentioned, we have been under a huge pressure for the last four months or so. Now we need some rest. We do not expect this deluge to be over.
GitHub
curl’s issue and pull-request trackers on GitHub remain open and active like normal.
You too?
If you and your Open Source projects also want to participate in the summer of bliss 2026: just do it and let us know! I would of course encourage you to do so. To take care of yourself as a top priority.
The bad guys won’t rest
Probably not. But we will.
But what if there is an emergency
Then we get to read about it in August. Or you get a support contract and we get to read about it earlier.
Contracts excluded
Everyone with a paid support contracts will of course still get full and appropriate service even during this period.
There seems to be a fair amount of people in either extremes in the current AI landscape. At one side we see the “vibe coders” who use agents and allow them to merge code without any person even looking at the source, while on the other side of the field there are people who are against everything and anything even remotely associated with AI.
My personal stance is somewhere in between, as I suppose shouldn’t be too surprising to readers of this blog.
A work of love and pride
The core team behind curl, and that is more people than just me, consists of individuals to whom code quality and source code excellence is important. We do software development because it is a craft we love and we are proud of what we have accomplished this far. We do not hand over our responsibilities to any machines. We stand for every bit of code we merge – as humans.
AIs do mistakes
Blindly accepting code written by AI means that you merge a certain amount of errors, but this is certainly true for human written code as well, so this is not in itself special. Some data suggests that AI generated code might even contain more mistakes than the human versions.
We invented test cases and code review a long time ago as a means to help us combat and reduce mistakes to get merged. The particular way code was written does not take away the benefits from code review and getting additional checks and eyes on pending changes. A good code review helps spotting mistakes, omissions or slip-ups. It also helps reinforce the architecture and established design choices. This is true however the code was created.
This far, code reviews done by automatic AI bots and the likes have not yet managed to replace the humans. They are simply not good enough.
Human reviews are much better. They catch other things and they help make sure proposed changes stay on track.
Not to mention how I want to know how curl works, even if I don’t keep 100% intimate knowledge of every single angle and corner, I know most of it. I think it helps me make better decisions, debug better, help users better and keep the architecture sound.
Getting the initial code written is not the big deal. For curl, maintaining and polishing the landed code through decades is the real task.
Everything we merge in curl is determined fine and fitting by humans.
Humans do mistakes
In all living software projects we get bugs reported and we fix them. We do new releases and continue to iterate. We have done this since software was invented and we still do, as humans are quite fallible and easily make mistakes.
We try to reduce the error density and frequency by adding tests and by adding more human eyes on the code before we green-light it. It helps, but is not perfect.
To help us do better code we invent, introduce and enforce a wide variety of different tools. With tools that look at code and identify problems in the early stages, they help avoid landing bad code in the first place. They make us do better code. They reduce the bug frequency.
Some of the best tools for detecting coding mistakes today use AI. These tools might work on existing source code in a git repository or they might look at proposed changes in pull-requests.
Above I mentioned that human code reviews are better; but the opposite is also true. In a somewhat complicated change request, it is now common that after the humans can’t spot any more problems, the AI PR review bots can still find an issue or two to remark on. Sure, sometimes they are wrong and then the comment is easily dismissed, but more often than not the findings they point out are actually something worth addressing before merge.
curl is developed and driven by humans, assisted by tools.
Communication is for humans
Open Source is about sharing code and is a development model where we do things in the open. The communication part of this model is key. Share your ideas, your visions, your problems or maybe just your ideas for what to do this afternoon.
Express what you want or what the problem is, and the team can respond and we can work together on fixing and improving whatever needs to be done.
Effective communication, a condition for good Open Source, implies human-to-human interaction. Inserting a large AI generated tone-deaf large wall-of-text into such a flow can still work, but only in the same way humans can learn to work with difficult individuals as well. It is not ideal and it is not a smooth way of working. It introduces sand in the machine. Don’t do that. It is rude.
Effective Open Source work means we communicate as humans, even if parts of the work and the code is made with the help of AI.
The combination
Humans and machines excel at different things. We can complement each other in software development.
Everyone is free to act to their own will, but in the curl project we don’t hand over responsibility to machines. We stand for our product. We make it as good as we possibly can; using all the tools that are available to us. I claim that in order to do this, humans need to remain in control.
Getting curl developers and related enthusiasts into a single room to hang out in the real world for a whole weekend once a year is awesome.
We find inspiration, we share experiences, we learn from each other and we dream and plan of future endeavors and things to work on. Seeing faces, hearing voices and watching body language help us communicate better virtually and on video calls during the rest of the year.
We have gathered curl people like this annually since 2017, even if some years during Covid were “different”. To me, this is one of the best events of the year. I get to hang out and talk curl with good friends a whole weekend!
The 2026 edition was held in Prague in late May and kept the general style of past events. About 25 people got into the room. We had five curl maintainers present and quite a lot of local curious minds.
The curl up format is easy, casual and friendly. We do topical presentations, followed up with Q&A and discussions around the topics brought up – of course usually with reflections about curl’s role, both past and future. We live-stream and record the presentations to allow our friends who could not attend to keep up both in real-time but also after the fact.
Unfortunately the tech is not always on our side so the quality sometimes is a little lacking. This year I brought an HDMI-splitter and an HDMI-to-USB device to allow us to get better recordings, but they were not working as smoothly as intended so we had to use inferior backup solutions for most of the meetup.
Recorded talks
This presentation above was the “keynote”, the introduction talk to the event. We then also recorded another nine session that are all available in the curl up 2026 playlist on YouTube.
Photos
To give you all a little glimpse of what curl up is about, here’s a gallery showing some of the speakers and some scenery.
Daniel StenbergAlexandr NedvedickyDaniel StenbergJim FullerJim FullerCarlos Henrique Lima MelaraJim KlimovMoritz BuhlStanislav FortDaniel StenbergIgor ChubinIgor ChubinDaniel StenbergDaniel Stenberg and Frank Gevaerts
All photos taken by and donated to us by an anonymous curl fan present in the room.
I’m doing Open Source primarily because I love it. The social aspects, the for-the-good angle and for the challenge of engineering this to work for everyone. I also do it because it is my full-time job and getting food on the table and provide for my family is not unimportant. It may come as a shock, but I am not in this game for the money or the extravagant life style.
I have been working full-time on curl since 2019. For me, this typically means doing 50 hour work weeks, as I spend all days on it and then I top them off with a few more hours every late night – all days of the week, I spend all this time on curl because it is a work of love and it is both my job and my spare time hobby and no one counts my hours anyway. (And no, I do not recommend anyone else to do the same. I’m not suggesting this for others.)
I consider my primary work-related mission in life to be to make curl the best transfer library and tool possible and make it qualify as a top project in Open Source, quality, performance and not the least, security. I believe we generally meet these lofty goals.
I founded the curl project, I am still a lead developer in the project almost thirty years later. While I always clearly state that curl is not a one-man shop and that curl would absolutely not be what it is without my awesome curl team mates, a large part of the world still thinks of curl as my project and sometimes more or less equals curl with my person.
I cannot help to take curl issues personally. When someone critiques curl, it is by extension a complaint on decisions and choices I stand by and behind – and many cases I made the calls. curl is personal to me. curl has formed my life forever.
I have two kids. They were both born many years after I started working on curl and they are both adults and independent individuals now. I love them dearly. Life passes by but curl remains. We’ve had slow times and busy times. The decades pass.
Later this year the curl project celebrates thirty years. We typically repeat that the number of curl installations in the world is perhaps thirty billion.
Things changed
Over the last years I have done numerous blog posts on the state of security reports submitted to curl. They have gradually switched over from complaints on stupid LLMs, to stupid AI slop reports, closing the bug bounty over to the current high quality chaos which for us started maybe at some point in March 2026.
We have seen many spectacular security failures through the years, in Internet products, in software infrastructure and in Open Source. Every time we read about those events, we get reminded about how curl is everywhere and how we really really really do not want anything such to happen to us or our users. And we take another lap around the project, tighten every bolt a little more, add a few more checks, tests and guidelines to ideally make the curl ship ever so slightly less likely to ever leak or sink.
Scrutinized
Recently, after I pointed out that Mythos only found a single low severity problem in curl in its first scan, countless people have repeated the claim that curl is one of the most scrutinized, most reviewed, most fuzzed and most verified source codes you can imagine. Perhaps that’s true, but I just want to mention this: that’s not by mistake. That’s not an accident or a happy circumstance. That’s the result of relentless work and attention to details through decades. Software engineering done right. Iterative improvements over time that simply never ends is an effective method.
This does not however mean that we don’t have bugs or that we don’t have security problems left, because we do. We have hundreds of thousands of lines of source code that is doing highly parallel networking for many protocols on all imaginable operating systems and CPU architectures – in C. So we fix the problems, patch them up and ship new releases. Over and over.
Thirty billion installations world-wide means that everyone reading this blog post has curl installed multiple times in stuff they own. In phones, tablets, cars, TVs, printers, game consoles, kitchen equipment and more. Not to mention all the online digital services we use and those devices communicate with. I cannot stress the importance of curl security and I would guess that most of you agree with me.
I am jealous of those projects that shipped a horrible bug at some point in the past that made the world burn for a while. They got attention and some of them then got funding and financial muscles to get them staff and hire multiple full time engineers. I sometimes think we would be better off if we also had one of those.
Never-before experienced
A thirty years old project could make you think you’ve seen most things already, but we have not been in this situation before.
The rate of incoming security reports is 4-5 times higher than it was in 2024 and double the speed of 2025 – meaning that on average we now get more than one report per day. The quality is way higher than ever before. The reports are typically very detailed and long.
In order to manage this incoming flood of submissions, we need to make sure to handle them as soon as possible as we know there are more coming. If we don’t take care of them roughly at the same speed they arrive, the backlog just grows and having that list of potential security problems in a list that you don’t have control over takes a mental toll.
I spend almost all my days right now working through the list of reported security issues that we have on Hackerone. Verify the claim, assess the importance, write a patch, figure out when the bug was introduced, understand the vulnerability, write a detailed advisory explaining the problem to the world and communicate all this with the security researcher and the rest of the curl security team.
A health concern
For the first time in my life, my wife voiced concerns about my work hours and my imbalanced work/life situation. I work more than I’ve done before, but the flood keeps coming. People in my surrounding, I guess reading between the lines, have asked me how I and we cope with this deluge and want to make sure we don’t burn in the process. I am concerned for my team mates.
I might soon have to reduce my work hours to allow myself more breathing time.
This is a never-before seen or experienced pressure on the curl project and its security team members. An avalanche of high priority work that trumps all other things in the project that is primarily mental because we certainly could ignore them all if we wanted, but we feel a responsibility, we have a conscience and we are proud about our work. We feel obliged to fix security problems in the software we have helped shipped to every device on the globe. This is personal to us.
With about half the release cycle left until the pending release ships, we already have twelve confirmed vulnerabilities meaning twelve pending CVE announcements. That’s a new project record and it also means we will reach thirty published CVEs in 2026 even before half the calendar year has passed. The projected total amount of curl CVEs published through the whole year is therefore at least double this number!
Assistance
What help would we like? Short term it is a little late. We already have work up to our ears.
I wish more companies that use and depend upon curl or libcurl in commercial software and services would chime in their part to fund us. We could then pay more developers to distribute the work load across. That would be great. Feel free to contact me to discuss how you can contribute to this. Get your employer to pay for a support contract!
Fortunately we have customers who already do this, so some of us can work on curl full time.
I am a pragmatic (and a bit of a cynic) and I have danced this dance for a long time already. I have no illusions that anything significant is going to change in this area even if we are in an unparalleled situation and in a tighter spot than ever before. I totally expect us to ride out this storm by ourselves. Like we are used to. We will survive. We will endure. It might just be a bit of a shaky period in the project and in the world at large as we try to maneuver our way through this. There’s a tsunami coming over us and all we can do is swim, there are no life boats for us.
The curl project is not owned by a company. We are not part of any umbrella organization. This makes us a little under-powered at times, but it also gives us maximum freedom and flexibility. We act solely in the interest of making curl as good as possible for the world and curl users.
The good part
Fixing bugs and problems is good. Every reported problem implies a fixed issue. curl becomes a better product.
What is also a good trend: almost no one finds terrible vulnerabilities. All vulnerabilities found the last few years in curl have all been deemed severity LOW or MEDIUM. I’m not saying there won’t be any more HIGH ever, but at least they are rare. The most recent severity high curl CVE was published in October 2023.
Pressure
Right now we are under a little pressure. Forgive us if we are a little slow to respond sometimes.
One of the established power features of the curl command line tool is its support for “globbing”. It is a built-in way to specify ranges and sets in different ways and have curl iterate over them to simplify repeated transfers.
For example, you can easily download three images from the same host without having to repeat the almost same URL three times:
curl allows globs used in a single URL to create up to 263 permutations – which, if you can do one million transfers per second, would take 292 thousand years to complete.
(As an added bonus you can of course also add -Z to the command line to make curl transfer all those images in parallel rather than serially.)
Saving them
To help users save files when using globbing, curl provides a way to reference the globbed components using #[number] when setting the target filename. The number then references the specific glob, where the first is 1, the second 2 etc.
Saving the one thousand images using different filenames locally than they use remotely:
This allows a compact command line to also offer flexibility.
News coming in 8.21.0
All functionality mentioned above has existed in curl for years; decades even. It just so happened that one day when working with curl I fell over a use case that I could not solve with the existing command line functionality.
I wanted to do a globbed upload to a HTTP server and then save all the separate responses into their own dedicated files, preferably with names based on the glob.
I will admit that I at first had a hard time to accept the fact that we actually could not do this already, but that was then rather quickly instead turned into: how should I add support for this in the smoothest and most convenient way? Using what syntax?
The road to fixing it for uploads took a little detour.
Name instead of index
Starting in 8.21.0, curl can assign a name to each glob and then reference that glob by name instead of using just a glob index number. This allows command lines to get ever so slightly more readable I think.
The image range example from above, but instead using named globs:
The only way to refer to an upload glob is to set a name and refer to that name. There are no indexed references for uploads, only for URL globs.
Mixing URL globs and uploads globs
It is in fact possible to also use a mix of upload globs and URL globs in the same command line if you want to upload multiple files to multiple destinations. They set the names in the same namespace and you refer to the names the same way, independently of source.
This feels more like a thing to show off in a blog post like this rather than something people will actually find good use for:
Upload three files to three sites, save all nine response in separate files:
Back in April 2026 Anthropic caused a lot of media noise when they concluded that their new AI model Mythos is dangerously good at finding security flaws in source code. Apparently Mythos was so good at this that Anthropic would not release this model to the public yet but instead trickle it out to a selected few companies for a while to allow a few good ones(?) to get a head start and fix the most pressing problems first, before the general populace would get their hands on it.
The whole world seemed to lose its marbles. Is this the end of the world as we know it? An amazingly successful marketing stunt for sure.
My (non-) access
Part of the deal with project Glasswingwas that Anthropic also offered access to their latest AI model to “Open Source projects” via Linux Foundation. Linux Foundation let their project Alpha Omega handle this part, and I was contacted by their representatives. As lead developer of curl I was offered access to the magic model and I graciously accepted the offer. Sure, I’d like to see what it can find in curl.
I signed the contract for getting access, but then nothing happened. Weeks went past and I was told there was a hiccup somewhere and access was delayed.
Eventually, I was instead offered that someone else, who has access to the model, could run a scan and analysis on curl for me using Mythos and send me a report. To me, the distinction isn’t that important. It’s not that I would have a lot of time to explore lots of different prompts and doing deep dive adventures anyway. Getting the tool to generate a first proper scan and analysis would be great, whoever did it. I happily accepted this offer.
(I am purposely leaving out the identity of the individual(s) involved in getting the curl analysis done as it is not the point of this blog post.)
AI scans of curl
Before this first Mythos report, we had already scanned curl with several different very capable AI powered tools (I mean in addition to running a number of “normal” static code analyzers all the time, using the pickiest compiler options and doing fuzzing on it for years etc). Primarily AISLE, Zeropath and OpenAI’s Codex Security have been used to scrutinize the code with AI. These tools and the analyses they have done have triggered somewhere between two and three hundred bugfixes merged in curl through-out the recent 8-10 months or so. A bunch of the findings these AI tools reported were confirmed vulnerabilities and have been published as CVEs. Probably a dozen or more.
Nowadays we also use tools like GitHub’s Copilot and Augment code to review pull requests, and their remarks and complaints help us to land better code and avoid merging new bugs. I mean, we still merge bugs of course but the PR review bots regularly highlight issues that we fix: our merges would be worse without them. The AI reviews are used in addition to the human reviews. They help us, they don’t replace us.
Security is a toppriority for us in the curl project. We follow every guideline and we do software engineering properly, to reduce the number of flaws in code. Scanning for flaws is just one of many steps to keep this ship safe. You need to search long and hard to find another software project that makes as much or goes further than curl, for software security.
Steps involved in keeping curl secure
May 6, 2026
It was with great anticipation we received the first source code analysis report generated with Mythos. Another chance for us to find areas to improve and bugs to fix. To make an even better curl.
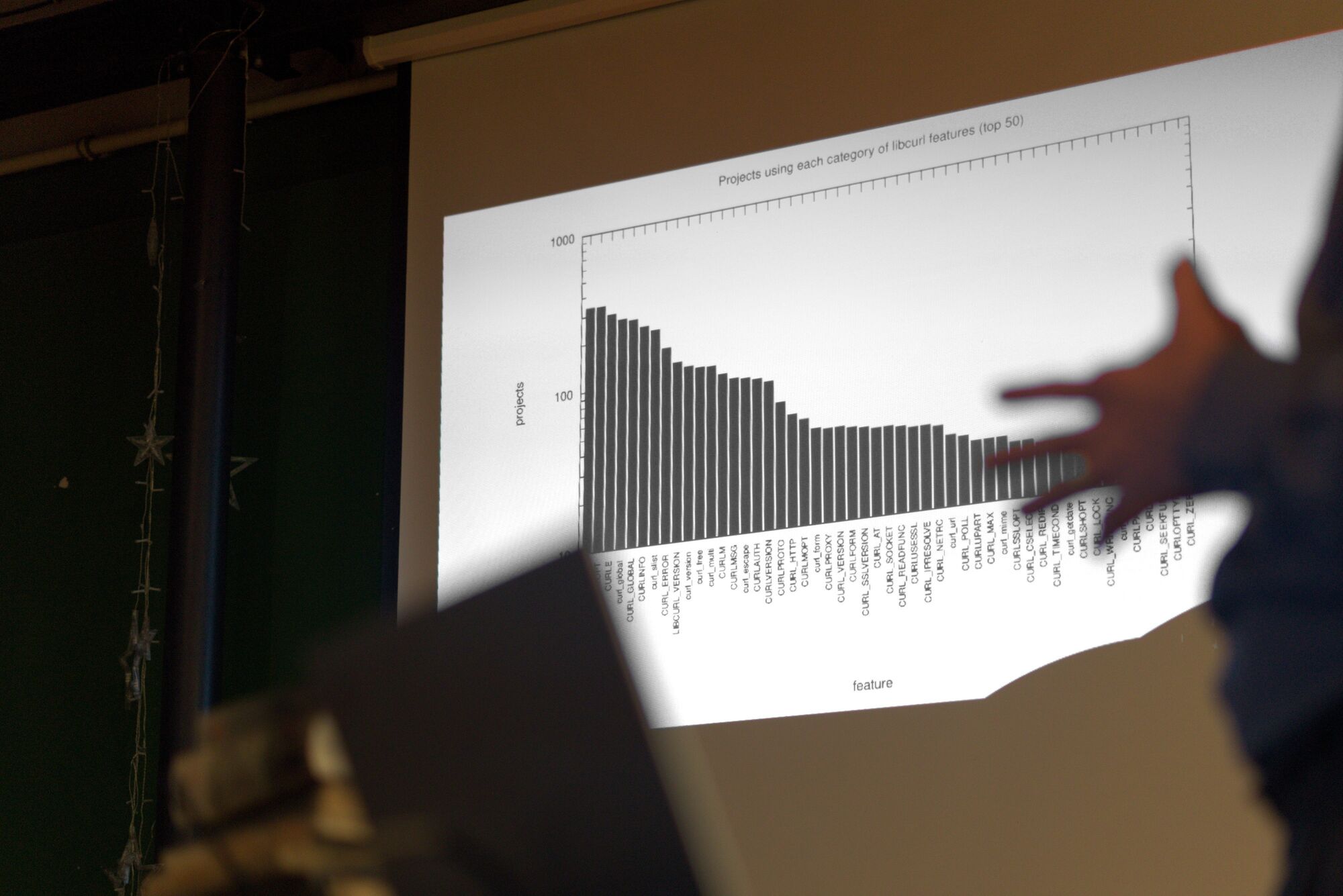
This initial scan was made on curl’s git repository and its master branch of a certain recent commit. It counted 178K lines of code analyzed in the src/ and lib/ subdirectories.
The analysis details several different approaches and methods it has performed the search, and how it has focused on trying to find which flaws. A fun note in the top of the report says:
curl is one of the most fuzzed and audited C codebases in existence (OSS-Fuzz, Coverity, CodeQL, multiple paid audits). Finding anything in the hot paths (HTTP/1, TLS, URL parsing core) is unlikely.
… and it correctly found no problems in those areas.
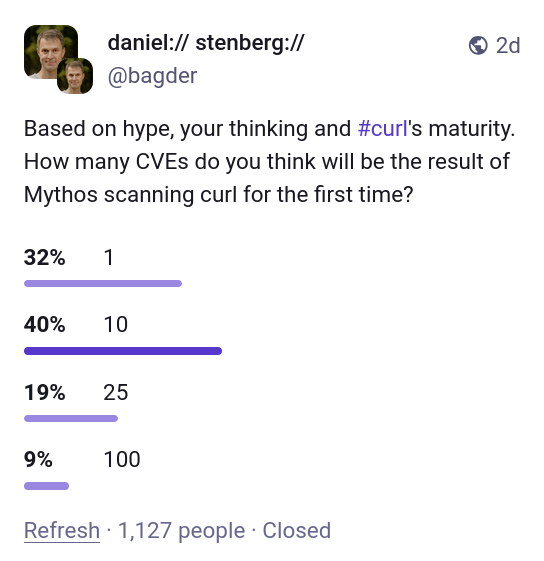
Completely unscientific poll on Mastodon about people’s expectations for Mythos scanning curl
The size of curl
curl is currently 176,000 lines of C code when we exclude blank lines. The source code consists of 660,000 words, which is 12% more words than the entire English edition of the novel War and Peace.
On average, every single production source code line of curl has been written (and then rewritten) 4.14 times. We have polished on this.
Right now, the existing production code in git master that still remains, has been authored by 573 separate individuals. Over time, a total of 1,465 individuals have so far had their proposed changes merged into curl’s git repository.
curl is installed in over twenty billion instances. It runs on over 110 operating systems and 28 CPU architectures. It runs in every smart phone, tablet, car, TV, game console and server on earth.
Five findings became one
The report concluded it found five “Confirmed security vulnerabilities”. I think using the term confirmed is a little amusing when the AI says it confidently by itself. Yes, the AI thinks they are confirmed, but the curl security team has a slightly different take.
Five issues felt like nothing as we had expected an extensive list. Once my curl security team fellows and I had poked on the this short list for a number of hours and dug into the details, we had trimmed the list down and were left with one confirmed vulnerability. The other four were three false positives (they highlighted shortcomings that are documented in API documentation) and the fourth we deemed “just a bug”.
The single confirmed vulnerability is going to end up a severity low CVE planned to get published in sync with our pending next curl release 8.21.0 in late June. The flaw is not going to make anyone grasp for breath. All details of that vulnerability will of course not get public before then, so you need to hold out for details on that.
The Mythos report on curl also contained a number of spotted bugs that it concluded were not vulnerabilities, much like any new code analyzer does when you run it on hundreds of thousands of lines of code. All the bugs in the report are being investigated and one by one we are fixing those that we agree with.
All in all about twenty bugs that are described and explained very nicely. Barely any false positives, so I presume they have had a rather high threshold for certainty.
curl is certainly getting better thanks to this report, but counted by the volume of issues found, all the previous AI tools we have used have resulted in larger bugfix amounts. This is only natural of course since the first tools we ran had many more and easier bugs to find. As we have fixed issues along the way, finding new ones are slowly becoming harder. Additionally, a bug can be small or big so it’s not always fair to just compare numbers
Not particularly “dangerous”
My personal conclusion can however not end up with anything else than that the big hype around this model so far was primarily marketing. I see no evidence that this setup finds issues to any particular higher or more advanced degree than the other tools have done before Mythos. Maybe this model is a little bit better, but even if it is, it is not better to a degree that seems to make a significant dent in code analyzing.
This is just one source code repository and maybe it is much better on other things. I can only tell and comment on what it found here.
Still very good
But allow me to highlight and reiterate what I have said before: AI powered code analyzers are significantly better at finding security flaws and mistakes in source code than any traditional code analyzers did in the past. All modern AI models are good at this now. Anyone with time and some experimental spirits can find security problems now. The high quality chaos is real.
Any project that has not scanned their source code with AI powered tooling will likely find huge number of flaws, bugs and possible vulnerabilities with this new generation of tools. Mythos will, and so will many of the others.
Not using AI code analyzers in your project means that you leave adversaries and attackers time and opportunity to find and exploit the flaws you don’t find.
How AI analyzers differ
They can spot when the comment says something about the code and then conclude that the code does not work as the comment says.
It can check code for platforms and configurations we otherwise cannot run analyzers for
It “knows” details about 3rd party libraries and their APIs so it can detect abuse or bad assumptions.
It “knows” details about protocols curl implements and can question details in the code that seem to violate or contradict protocol specifications
They are typically good at summarizing and explaining the flaw, something which can be rather tedious and difficult with old style analyzers.
They can often generate and offer a patch for its found issue (even if the patch usually is not a 100% fix).
More details from the report
Zero memory-safety vulnerabilities found.
Methodology note: this review is hand-driven analysis using LLM subagents for parallel file reads, with every candidate finding re-verified by direct source inspection in the main session before being recorded. The CVE to variant-hunt mapping was built from curl’s own vuln.json. No automated SAST tooling was used.
This outcome is consistent with curl’s status as one of the most heavily fuzzed and audited C codebases. The defensive infrastructure (capped dynbufs everywhere, curlx_str_number with explicit max on every numeric parse, curlx_memdup0 overflow guard, CURL_PRINTF format-string enforcement, per-protocol response-size caps, pingpong 64KB line cap) systematically closes the bug classes that would normally be productive in a codebase this size.
Coverage now includes: all minor protocols, all file parsers, all TLS backends’ verify paths, http/1/2/3, ftp full depth, mprintf, x509asn1, doh, all auth mechanisms, content encoding, connection reuse, session cache, CLI tool, platform-specific code, and CI/build supply chain.
AI finds existing kinds of errors
It should be noted that the AI tools find the usual and established kind of errors we already know about. It just finds new instances of them.
We have not seen any AI so far report a vulnerability that would somehow be of a novel kind or something totally new. They do not reinvent the field in that way, but they do dig up more issues than any other tools did before.
More to find
These were absolutely not the last bugs to find or report. Just while I was writing the drafts for this blog post we have received more reports from security researchers about suspected problems. The AI tools will improve further and the researchers can find new and different ways to prompt the existing AIs to make them find more.
We have not reached the end of this yet.
I hope we can keep getting more curl scans done with Mythos and other AIs, over and over until they truly stop finding new problems.
Credits
Thanks to Anthropic and Alpha Omega for providing the model, the tools and doing the scan for us. Thanks also to the individual who did the scan for us. Much appreciated!
In this era of powerful tools to find software bugs, we now see tools find a lot of problems at a high speed. This causes problems for developers, as dealing with the growing list of issues is hard. It may take a longer time to address the problems than to find them – not to mention to put them into releases and then it takes yet another extended time until users out in the wild actually get that updated version into their hands.
In order to find many bugs fast, they have to already exist in source code. These new tools don’t add or create the problems. They just find them, filter them out and bring them to the surface for exposure. A better filter in the pool filters out more rubbish.
The more bugs we fix, the fewer bugs remain in the code. Assuming the developers manage to fix problems at a decent enough pace.
For every bugfix we merge, there is a risk that the change itself introduces one more more new separate problems. We also tend to keep adding features and changing behavior as we want to improve our products, and when doing so we occasionally slip up and introduce new problems as well.
Source code analyzing tools is a concept as old as source code itself. There has always existed tools that have tried to identify coding mistakes. Now they just recently got better so they can find more mistakes.
These new tools, similar to the old ones, don’t find all the problems. Even these new modern tools sometimes suggest fixes to the problems they find that are incomplete and in fact sometimes downright buggy.
Undoubtedly code analyzer tooling will improve further. The tools of tomorrow will find even more bugs, some of them were not found when the current generation of tools scanned the code yesterday.
Of course, we now also introduce these tools in CI and general development pipelines, which should make us land better code with fewer mistakes going forward. Ideally.
If we assume that we fix bugs faster than we introduce new ones and we assume that the AI tools can improve further, the question is then more how much more they can improve and for how long that improvement can go on. Will the tools find 10% more bugs? 100%? 1000%? Is the tool improving going to gradually continue for the next two, ten or fifty years? Can they actually find all bugs?
Can we reach the utopia where we have no bugs left in a given software project and when we do merge a new one, it gets detected and fixed almost instantly?
Are we close?
If we assume that there is at least a theoretical chance to reach that point, how would we know when we reach it? Or even just if we are getting closer?
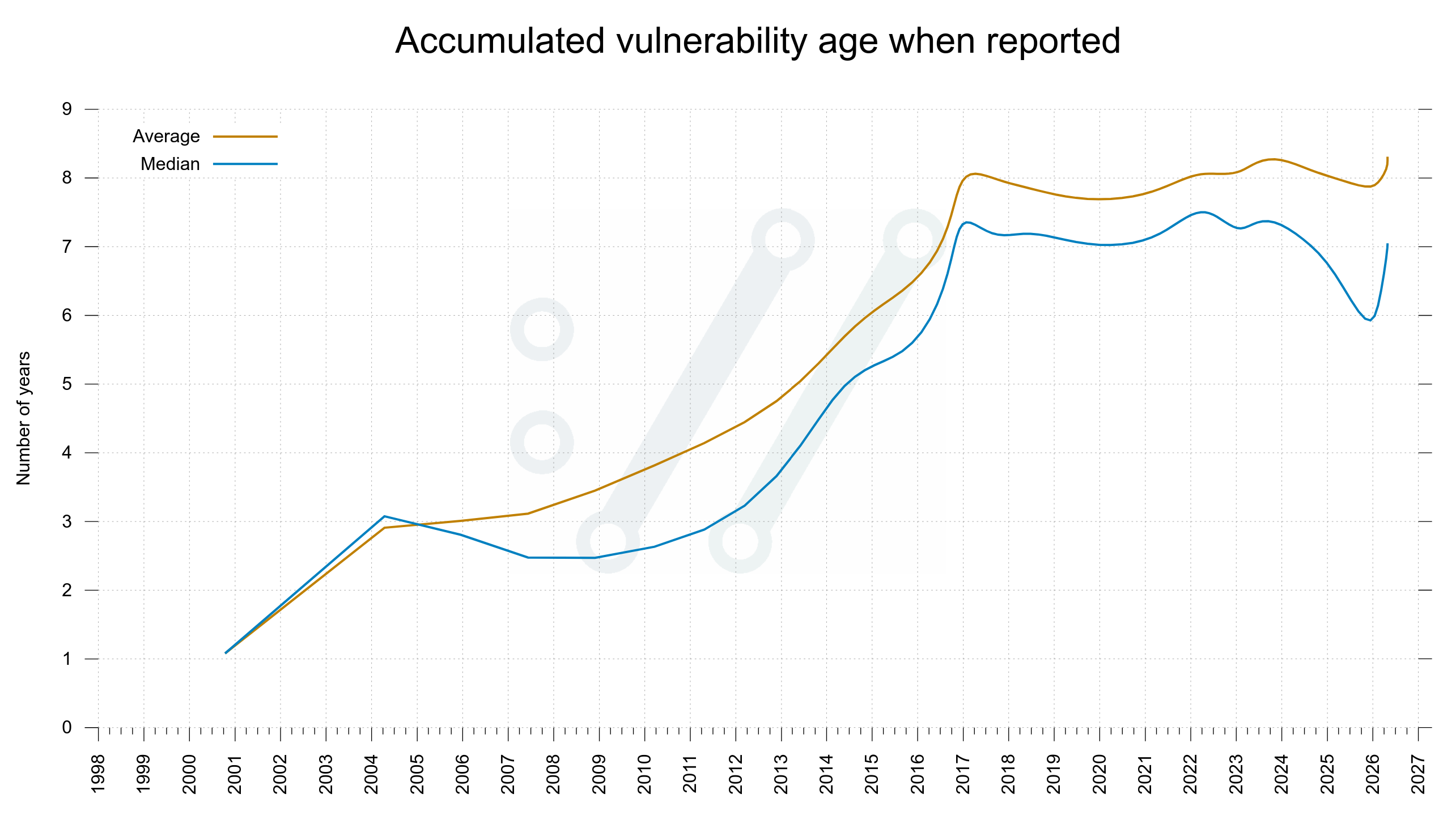
I propose that one way to measure if we are getting closer to zero bugs is to check the age of reported and fixed bugs. If the tools are this good, we should soon only be fixing bugs we introduced very recently.
In the curl project we don’t keep track of the age of regular bugs, but we do for vulnerabilities. The worst kind of bugs. If the tools can find almost all problems, they should soon only be finding very recently added vulnerabilities too. The age of new finds should plummet and go towards zero.
If the age of newly reported vulnerabilities are getting younger, it should make the average and median age of the total collection go down over time.
Average age of vulnerabilities
The average and median time vulnerabilities had existed in the curl source code by the time they were found and reported to the project.
Accumulated vulnerability age when reported
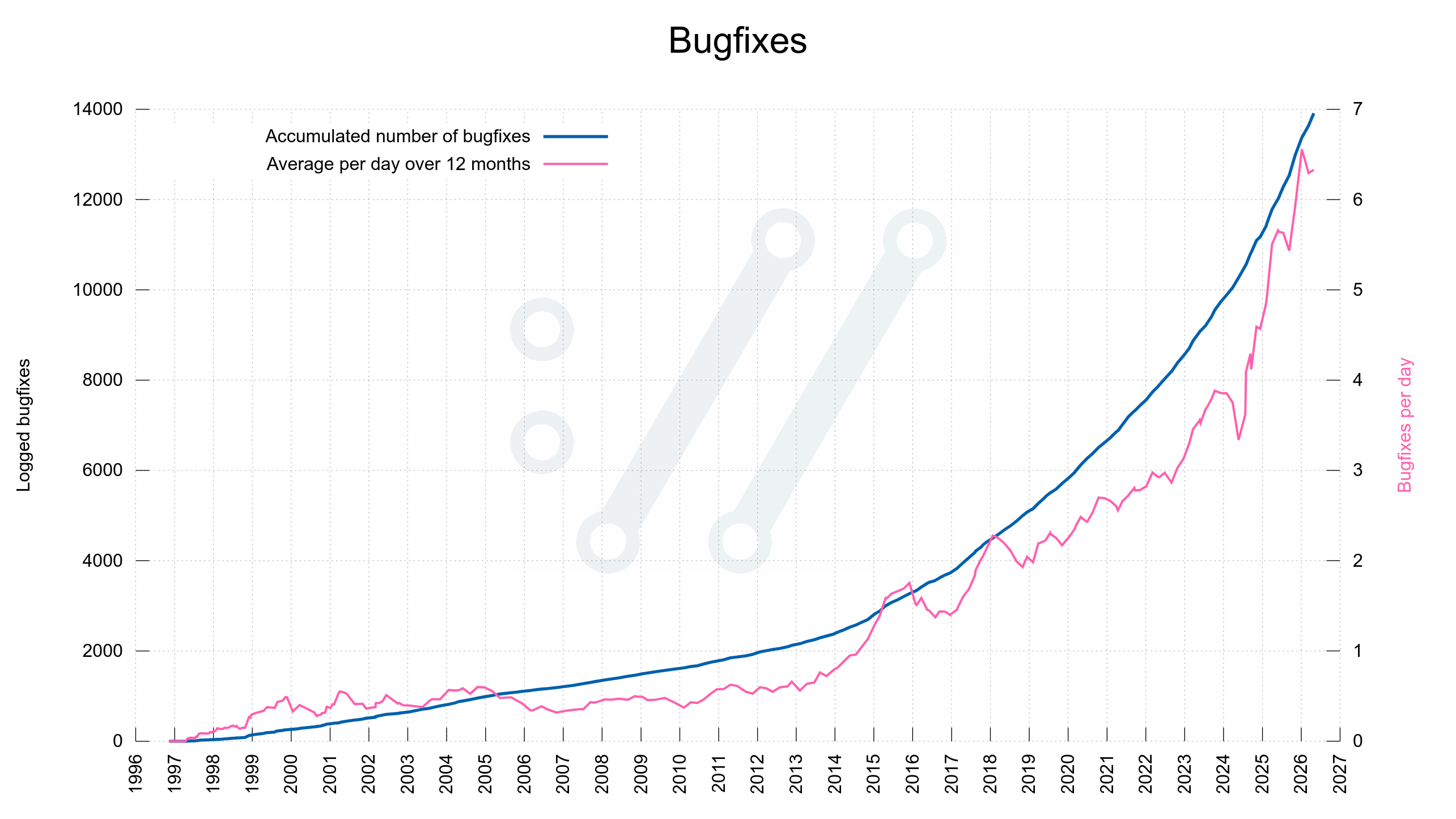
Bugfixes
When the tools have found most problems there should be less bugs left to fix. The bugfix rate should go down rapidly – independently of how you count them or how liberal we are in counting exactly what is a bugfix.
Bugfixes
Given the data from the curl project, there does not seem to be fewer bugfixes done – yet. Maybe the bugfix speed goes up before it goes down?
We are not close
Given the look of these graphs I don’t think we are close to zero bugs yet. These two curves do not seem to even start to fall yet.
Yes, these graphs are based on data from a single project, which makes it super weak to draw statistical conclusions from, but this is all I have to work with.
So when?
I think that’s mostly an indication of what you believe the tooling can do and how good they can eventually end up becoming.
Daniel Stenberg is a Swedish engineer and the creator of curl (cURL), one of the most widely used tools and libraries for fetching content over various protocols. I’ve always admired Daniel’s work, reading his blogs and watching his talks on YouTube. He is one of the engineers who inspired me to start my own YouTube channel and teach backend engineering.
It warms my heart to read this. Words like this give me energy and motivation. My work has meaning.